Book Review: Design Principles of Biological Circuits
post by johnswentworth · 2019-11-05T06:49:58.329Z · LW · GW · 24 commentsContents
Chapters 1-4: Bacterial Transcription Networks and Motifs Chapters 5-6: Feedback and Motifs in Other Biological Networks Chapters 7-8: Robust Recognition and Signal-Passing Chapters 9-11: Exact Adaptation, Fold Change and Related Topics Exact Adaptation Fold-Change Detection Extracellular/Decentralized Adaptation Chapter 12: Morphological Patterning Takeaway None 24 comments
I remember seeing a talk by a synthetic biologist, almost a decade ago. The biologist used a genetic algorithm to evolve an electronic circuit, something like this:
(source)
He then printed out the evolved circuit, brought it to his colleague in the electrical engineering department, and asked the engineer to analyze the circuit and figure out what it did.
“I refuse to analyze this circuit,” the colleague replied, “because it was not designed to be understandable by humans.” He has a point - that circuit is a big, opaque mess.
This, the biologist argued, is the root problem of biology: evolution builds things from random mutation, connecting things up without rhyme or reason, into one giant spaghetti tower [LW · GW]. We can take it apart and look at all the pieces, we can simulate the whole thing and see what happens, but there’s no reason to expect any deeper understanding. Organisms did not evolve to be understandable by humans.
I used to agree with this position. I used to argue that there was no reason to expect human-intelligible structure inside biological organisms, or deep neural networks, or other systems not designed to be understandable. But over the next few years after that biologist’s talk, I changed my mind, and one major reason for the change is Uri Alon’s book An Introduction to Systems Biology: Design Principles of Biological Circuits.
Alon’s book is the ideal counterargument to the idea that organisms are inherently human-opaque: it directly demonstrates the human-understandable structures which comprise real biological systems. Right from the first page of the introduction:
… one can, in fact, formulate general laws that apply to biological networks. Because it has evolved to perform functions, biological circuitry is far from random or haphazard. ... Although evolution works by random tinkering, it converges again and again onto a defined set of circuit elements that obey general design principles.
The goal of this book is to highlight some of the design principles of biological systems... The main message is that biological systems contain an inherent simplicity. Although cells evolved to function and did not evolve to be comprehensible, simplifying principles make biological design understandable to us.
It’s hard to update one’s gut-level instinct that biology is a giant mess of spaghetti without seeing the structure first hand, so the goal of this post is to present just enough of the book to provide some intuition that, just maybe, biology really is human-understandable.
This review is prompted by the release of the book’s second edition, just this past August, and that’s the edition I’ll follow through. I will focus specifically on the parts I find most relevant to the central message: biological systems are not opaque. I will omit the last three chapters entirely, since they have less of a gears-level [LW · GW] focus and more of an evolutionary focus, although I will likely make an entire separate post on the last chapter (evolution of modularity).
Chapters 1-4: Bacterial Transcription Networks and Motifs
E-coli has about 4500 proteins, but most of those are chunked together into chemical pathways which work together to perform specific functions. Different pathways need to be expressed depending on the environment - for instance, e-coli won’t express their lactose-metabolizing machinery unless the environment contains lots of lactose and not much glucose (which they like better).
In order to activate/deactivate certain genes depending on environmental conditions, bacteria use transcription factors: proteins sensitive to specific conditions, which activate or repress transcription of genes. We can think of the transcription factor activity as the cell’s internal model of its environment. For example, from Alon:
Many different situations are summarized by a particular transcription factor activity that signifies “I am starving”. Many other situations are summarized by a different transcription factor activity that signifies “My DNA is damaged”. These transcription factors regulate their target genes to mobilize the appropriate protein responses in each case.
The entire state of the transcription factors - the e-coli’s whole model of its environment - has about 300 degrees of freedom. That’s 300 transcription factors, each capturing different information, and regulating about 4500 protein genes.
Transcription factors often regulate the transcription of other transcription factors. This allows information processing in the transcription factor network. For instance, if either of two different factors (X, Y) can block transcription of a third (Z), then that’s effectively a logical NOR gate: Z levels will be high when neither X nor Y is high. In general, transcription factors can either repress or promote (though rarely both), and arbitrarily complicated logic is possible in principle - including feedback loops.
Now we arrive at our first major piece of evidence that organisms aren’t opaque spaghetti piles: bacterial transcription network motifs.
Random mutations form random connections between transcription factors - mutations can make any given transcription factor regulate any other very easily. But actual transcription networks do not look like random graphs. Here’s a visualization from the book:
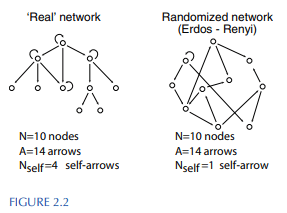
A few differences are immediately visible:
- Real networks have much more autoregulation (transcription factors activating/repressing their own transcription) than random networks
- Other than self-loops (aka autoregulation), real networks contain almost no feedback loops (at least in bacteria), though such loops are quite common in random networks
- Real networks are mostly tree-shaped; most nodes have at most a single parent.
These patterns can be quantified and verified statistically via “motifs” (or “antimotifs”): connection patterns which occur much more frequently (or less frequently) in real transcription factor networks than in random networks.
Alon uses an e-coli transcription network with 424 nodes and 519 connections to quantify motifs. Chapters 2-4 each look at a particular class of motifs in detail:
- Chapter 2 looks at autoregulation. If the network were random, we’d expect about 1.2 ± 1.1 autoregulatory loops. The actual network has 40.
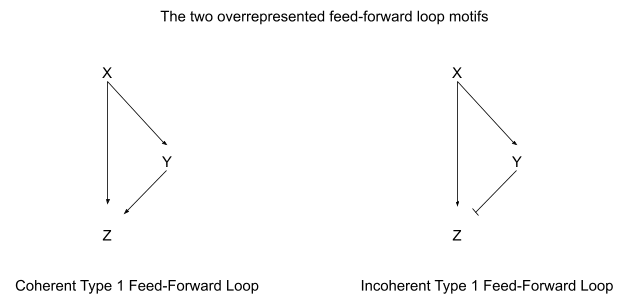
- Chapter 3 looks at three-node motifs. There is one massively overrepresented motif: the feed-forward loop (see diagram below), with 42 instances in the real network and only 1.7 ± 1.3 in a random network. Distinguishing activation from repression, there are eight possible feed-forward loop types, and two of the eight account for 80% of the feed-forward loops in the real network.
- Chapter 4 looks at larger motifs, though it omits the statistics. Fan-in and fan-out patterns, as well as fanned-out feed-forward loops, are analyzed.
Alon analyzes the chemical dynamics of each pattern, and discusses what each is useful for in a cell - for instance, autoregulatory loops can fine-tune response time, and feed-forward loops can act as filters or pulse generators.
Chapters 5-6: Feedback and Motifs in Other Biological Networks
Chapter 5 opens with developmental transcription networks, the transcription networks which lay out the body plan and differentiate between cell types in multicellular organisms. These are somewhat different from the bacterial transcription networks discussed in the earlier chapters. Most of the overrepresented motifs in bacteria are also overrepresented in developmental networks, but there are also new overrepresented motifs - in particular, positive autoregulation and two-node positive feedback.
Both of these positive feedback patterns are useful mainly for inducing bistability - i.e. multiple stable steady states. A bistable system with steady states A and B will stay in A if it starts in A, or stay in B if it starts in B, meaning that it can be used as a stable memory element. This is especially important to developmental systems, where cells need to decide what type of cell they will become (in coordination with other cells) and then stick to it - we wouldn’t want a proto-liver cell changing its mind and becoming a proto-kidney cell instead.
After discussing positive feedback, Alon includes a brief discussion of motifs in other biological networks, including protein-protein interactions and neuronal networks. Perhaps surprisingly (especially for neuronal networks), these include many of the same overrepresented motifs as transcription factor networks - suggesting universal principles at work.
Finally, chapter 6 is devoted entirely to biological oscillators, e.g. circadian rhythms or cell-cycle regulation or heart beats. The relevant motifs involve negative feedback loops. The main surprise is that oscillations can sometimes be sustained even when it seems like they should die out over time - thermodynamic noise in chemical concentrations can “kick” the system so that the oscillations continue indefinitely.
At this point, the discussion of motifs in biological networks wraps up. Needless to say, plenty of references are given which quantify motifs in various biological organisms and network types.
Chapters 7-8: Robust Recognition and Signal-Passing
There’s quite a bit of hidden purpose in biological systems - seemingly wasteful side-reactions or seemingly arbitrary reaction systems turn out to be functionally critical. Chapters 7-8 show that robustness is one such “hidden” purpose: biological systems are buffeted by thermodynamic noise, and their functions need to be robust to that noise. Once we know to look for it, robustness shows up all over, and many seemingly-arbitrary designs don’t look so random anymore.
Chapter 7 mainly discusses kinetic proofreading, a system used by both ribosomes (RNA-reading machinery) and the immune system to reduce error rates. At first glance, kinetic proofreading just looks like a wasteful side-reaction: the ribosome/immune cell binds its target molecule, then performs an energy-consuming side reaction and just waits around a while before it can move on to the next step. And if the target unbinds at any time, then it has to start all over again!
Yet this is exactly what’s needed to reduce error rates.
The key is that the correct target is always most energetically stable to bind, so it stays bound longer (on average) than incorrect targets. At equilibrium, maybe 1% of the bound targets are incorrect. The irreversible side-reaction acts as a timer: it marks that some target is bound, and starts time. If the target falls off, then the side-reaction is undone and the whole process starts over… but the incorrect targets fall off much more quickly that the correct targets. So, we end up with correct targets “enriched”: the fraction of incorrect targets drops well below its original level of 1%. Both the delay and the energy consumption are necessary in order for this to work: the delay to give the incorrect targets time to fall off, and the energy consumption to make the timer irreversible (otherwise everything just equilibrates back to 1% error).
Alon offers an analogy, in which a museum curator wants to separate the true Picasso lovers from the non-lovers. The Picasso room usually has about 10x more lovers than non-lovers (since the lovers spend much more time in the room), but the curator wants to do better. So, with a normal mix of people in there, he locks the incoming door and opens a one-way door out. Over the next few minutes, only a few of the picasso lovers leave, but practically all the non-lovers leave - Picasso lovers end up with much more than the original 10x enrichment in the room. Again, we see both key pieces: irreversibility and a delay.
It’s also possible to stack such systems, performing multiple irreversible side-reactions in sequence, in order to further lower the error rate. Alon goes into much more depth, and explains the actual reactions involved in more detail.
Chapter 8 then dives into a different kind of robustness: robust signal-passing. The goal here is to pass some signal from outside the cell to inside. The problem is, there’s a lot of thermodynamic noise in the number of receptors - if there happen to be 20% more receptors than average, then a simple detection circuit would measure 20% stronger signal. This problem can be avoided, but it requires a specific - and nontrivial - system structure.
In this case, the main trick is to have the receptor both activate and deactivate (i.e. phosphorylate and dephosphorylate) the internal signal molecule, with rates depending on whether the receptor is bound. At first glance, this might seem wasteful: what’s the point of a receptor which undoes its own effort? But for robustness, it’s critical - because the receptor both activates and deactivates the internal signal, its concentration cancels out in the equilibrium expression. That means that the number of receptors won’t impact the equilibrium activity level of the signal molecule, only how fast it reaches equilibrium.
The trick can also be extended to provide robustness to the background level of the signal molecule itself - Alon provides more detail. As you might expect, this type of structure is a common pattern in biological signal-receptor circuits.
For our purposes, the main takeaway from these two chapters is that, just because the system looks wasteful/arbitrary, does not mean it is. Once we know what to look for, it becomes clear that the structure of biological systems is not nearly so arbitrary as it looks.
Chapters 9-11: Exact Adaptation, Fold Change and Related Topics
When we move from an indoor room into full sunlight, our eyes quickly adjust to the brightness. A bacteria swimming around in search of food can detect chemical gradients among background concentrations varying by three orders of magnitude. Beta cells in the pancreas regulate glucose usage, bringing the long-term blood glucose concentration back to 5 mM, even when we shift to eating or exercising more. In general, a wide variety of biological sensing systems need to be able to detect changes and then return to a stable baseline, across a wide range of background intensity levels.
Alon discusses three problems in this vein, each with its own chapter:
- Exact adaptation: the “output signal” of a system always returns to the same baseline when the input stops changing, even if the input settles at a new level.
- Fold change: the system responds to percentage changes, across several decibels of background intensity.
- Extracellular versions of the above problems, in which control is decentralized.
Main takeaway: fairly specific designs are needed to achieve robust behavior.
Exact Adaptation
The main tool used for exact adaptation will be immediately familiar to engineers who’ve seen some linear control theory: integral feedback control. There are three key pieces:
- Some internal state variable - e.g. concentration/activation of some molecule type or count of some cell type - used to track “error” over time
- An “internal” signal
- An “external” signal and a receptor, which increases production/activation of the internal signal whenever it senses the external signal
The “error” tracked by the internal state is the difference between the internal signal’s concentration and its long-term steady-state concentration . The internal state increases/decreases in direct proportion to that difference, so that over time, the is proportional to the integral . Then, itself represses production/activation of the internal signal .
The upshot: if the external signal increases, then at first the internal signal also increases, as the external receptor increases production/activation of . But this pushes above its long-term steady-state , so gradually increases, repressing . The longer and further is above its steady-state, the more increases, and the more is repressed. Eventually, reaches a level which balances the new average level of the external signal, and returns to the baseline.
Alon then discusses robustness of this mechanism compared to other possible mechanisms. Turns out, this kind of feedback mechanism is robust to changes in the background level of , , etc - steady-state levels shift, but the qualitative behavior of exact adaptation remains. Other, “simpler” mechanisms do not exhibit such robustness.
Fold-Change Detection
Fold-change detection is a pretty common theme in biological sensory systems, from eyes to bacterial chemical receptors. Weber’s Law is the general statement: sensory systems usually respond to changes on a log scale.
There’s two important pieces here:
- “Respond to changes” means exact adaption - the system returns to a neutral steady-state value in the long run when nothing is changing.
- “Log scale” means it’s percent changes which matter, and the system can work across several orders of magnitude of external signal
Alon gives an interesting example: apparently if you use a screen and an eye-tracker to cancel out a person’s rapid eye movements, their whole field of vision turns to grey and they can’t see anything. That’s responding to changes. On the other hand, if we step into bright light, background intensity can easily jump by an order of magnitude - yet a 10% contrast looks the same in low light or bright light. That’s operating on a log-scale.
Again, there’s some pretty specific criteria for systems to exhibit fold-change detection - few systems have consistent, useful behavior over multiple orders of magnitude of input values. Alon gives two particular circuits, as well as a general criterion.
Extracellular/Decentralized Adaptation
Alon moves on to the example of blood glucose regulation. Blood glucose needs to be kept at a pretty steady 5 mM level long-term; too low will starve the brain, and too high will poison the brain. The body uses an integral feedback mechanism to achieve robust exact adaptation of glucose levels, with the count of pancreatic beta cells serving as the state variable: when glucose is too low, the cells (slowly) die off, and when glucose is too high, the cells (slowly) proliferate.
The main new player is insulin. Beta cells do not themselves produce or consume much glucose; rather, they produce insulin, which we can think of as an inverse-price signal for glucose. When insulin levels are low (so the “price” of glucose is high), many cells throughout the body cut back on their glucose consumption. The beta cells serve as market-makers: they adjust the insulin/price level until the glucose market clears - meaning that there is no long-term increase or decrease in blood glucose.
A very similar system exists for many other metabolite/hormone pairs. For instance, calcium and parathyroid uses a nearly-identical system: integral feedback mechanism using cell count as a state variable with a hormone serving as price-signal to provide decentralized feedback control throughout the body.
Alon also spends a fair bit of time on one particular issue with this set-up: mutant cells which mismeasure the glucose concentration could proliferate and take over the tissue. One defense against this problem is for the beta cells to die when they measure very high glucose levels (instead of proliferating very quickly). This handles must mutations, but it also means that sufficiently high glucose levels can trigger an unstable feedback loop: beta cells die, which reduces insulin, which means higher glucose “price” and less glucose usage throughout the body, which pushes glucose levels even higher. That’s type-2 diabetes.
Chapter 12: Morphological Patterning
The last chapter we’ll cover here is on morphological patterning: the use of chemical reactions and diffusion to lay out the body plans of multicellular organisms.
The basic scenario involves one group of cells (A) producing some signal molecule, which diffuses into a neighboring group of cells (B). The neighbors then differentiate themselves based on how strong the signal is: those nearby A will see high signal, so they adopt one fate, while those farther away see lower signal, so they adopt another fate, with some cutoff in between.
This immediately runs into a problem: if A produces too much or too little of the signal molecule, then the cutoff will be too far to one side or the other - e.g. the organism could end up with a tiny rib and big space between ribs, or a big rib and a tiny space between. It’s not robust.
Once again, the right design can mitigate the problem.
Apparently one group ran a brute-force search over parameter space, looking for biologically-plausible systems which produced robust patterning. Only a few tiny corners of the parameter space worked, and those tiny corners all used a qualitatively similar mechanism. Alon explains the mechanism in some depth, but I’m gonna punt on it - much as I enjoy nonlinear PDEs (and this one is even analytically tractable), I’m not going to inflict them on readers here.
Once again, though it may seem that evolution can solve problems a million different ways and it’s hopeless to look for structure, it actually turns out that only a few specific designs work - and those are understandable by humans.
Takeaway
Let’s return to the Alon quote from the introduction:
Because it has evolved to perform functions, biological circuitry is far from random or haphazard. ... Although evolution works by random tinkering, it converges again and again onto a defined set of circuit elements that obey general design principles.
The goal of this book is to highlight some of the design principles of biological systems... The main message is that biological systems contain an inherent simplicity. Although cells evolved to function and did not evolve to be comprehensible, simplifying principles make biological design understandable to us.
We’ve now seen both general evidence and specific examples of this.
In terms of general evidence, we’ve seen that biological regulatory networks do not look statistically random. Rather, a handful of patterns - “motifs” - repeat often, lending the system a lot of consistent structure. Even though the system was not designed to be understandable, there’s still a lot of recognizable internal structure.
In terms of specific examples, we’ve seen that only a small subset of possible designs can achieve certain biological goals:
- Robust recognition of molecules
- Robust signal-passing
- Robust exact adaptation and distributed exact adaptation
- Fold-change detection
- Robust morphological patterning
The designs which achieve robustness are exactly the designs used by real biological systems. Even though the system was not designed to be understandable, the simple fact that it works robustly forces the use of a handful of understandable structures.
A final word: when we do not understand something, it does not look like there is anything to be understood at all - it just looks like random noise. Just because it looks like noise does not mean there is no hidden structure.

24 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2019-11-08T05:35:05.794Z · LW(p) · GW(p)
Curated. Just discussed this with Oli a bunch. Some reasons for curation:
- High quality book reviews are very valuable and a key step in being able to interface with expertise in other communities and fields.
- Biology is a field that is a major blindspot on LessWrong, where most of us have relatively little expertise. One reason for this is that we take a very reductionistic approach to understanding the world, and biology often seems very messy and unprincipled. This post really shocked me with the level of principle that apparently can be found in such systems. Not only were things that seemed like wasted energy actually useful, and not only were they useful in ways common to a wide variety of biological systems, but their use is to enforce abstractions so that the whole system becomes more reliable and easier for us to model. This is quite something. I hope others here on LW who look into biology are able to build on this.
Excellent post, looking forward to further on this topic.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2019-11-13T14:28:50.527Z · LW(p) · GW(p)
This post really shocked me with the level of principle that apparently can be found in such systems.
If you're interested in this theme, I recommend reading up on convergent evolution, which I find really fascinating. Here's Dawkins in The Blind Watchmaker:
The primitive mammals that happened to be around in the three areas [of Australia, South America and the Old World] when the dinosaurs more or less simultaneously vacated the great life trades, were all rather small and insignificant, probably nocturnal, previously overshadowed and overpowered by the dinosaurs. They could have evolved in radically different directions in the three areas. To some extent this is what happened. … But although the separate continents each produced their unique mammals, the general pattern of evolution in all three areas was the same. In all three areas the mammals that happened to be around at the start fanned out in evolution, and produced a specialist for each trade which, in many cases, came to bear a remarkable resemblance to the corresponding specialist in the other two areas.
Dawkins goes on to describe the many ways in which marsupials in Australia, placentals in the Old World, and a mix of both in South America underwent convergent evolution to fill similar roles in their ecosystems. Some examples are very striking: separate evolutions of moles, anteaters, army ants, etc.
I'm also working my way through Jonathan Losos' Improbable Destinies now, which isn't bad but a bit pop-sciencey. For more detail, Losos mentions https://mitpress.mit.edu/books/convergent-evolution and https://www.amazon.co.uk/Lifes-Solution-Inevitable-Humans-Universe/dp/0521603250.
comment by Ofer (ofer) · 2019-11-05T16:02:55.619Z · LW(p) · GW(p)
Thanks for writing this!
I used to agree with this position. I used to argue that there was no reason to expect human-intelligible structure inside biological organisms, or deep neural networks, or other systems not designed to be understandable. But over the next few years after that biologist’s talk, I changed my mind, and one major reason for the change is Uri Alon’s book An Introduction to Systems Biology: Design Principles of Biological Circuits.
I'm curious what you think about the following argument:
The examples in this book are probably subject to a strong selection effect: examples for mechanisms that researchers currently understand were more likely to be included in the book than those that no one has a clue about. There might be a large variance in the "opaqueness" of biological mechanisms (in different levels of abstraction). So perhaps this book provides little evidence on the (lack of) opaqueness of, say, the mechanisms that allowed John von Neumann to create the field of cellular automata, at a level of abstraction that is analogous to artificial neural networks.
Replies from: johnswentworth, Davidmanheim↑ comment by johnswentworth · 2019-11-05T18:19:15.642Z · LW(p) · GW(p)
Yeah, that's a natural argument. The counterargument which immediately springs to mind is that, until we've completely and totally solved biology, there's always going to be some systems we don't understand yet - just because they haven't been understood yet does not mean they're opaque. It boils down to priors: do we have reasons to expect large variance in opaqueness? Do we have reason to expect low variance in opaqueness?
My own thoughts can be summarized by three main lines of argument:
- If we look at the entire space of possible programs, it's not hard to find things which are pretty darn opaque to humans. Crypto and computational complexity theory provide some degree of foundation to that idea. So human-opaque systems do exist.
- We can know that something is non-opaque (by understanding it), but we can't know for sure that something is opaque. Lack of understanding is Bayesian evidence in favor of opaqueness, but the strength of that evidence depends a lot on who's tried to understand it, how much effort was put in, what the incentives look like, etc.
- I personally have made arguments of the form "X is intractably opaque to humans" about many different systems in multiple different fields in the past (not just biology). In most cases, I later turned out to be wrong. So at this point I have a pretty significant prior against opacity.
So I'd say the book provides evidence in favor of a generally-low prior on opaqueness, but people trying and failing to understand a system is the main type of evidence regarding opacity of particular systems.
Unfortunately, these are all outside-view arguments. I do think an inside view is possible here - it intuitively feels like the kinds of systems which turned out not to be opaque (e.g. biological circuits) have visible, qualitative differences from the kinds of systems which we have some theoretical reasons to consider opaque (e.g. pseudorandom number generators). They're the sort of systems people call "emergent". Problem is, we don't have a useful formalization of that idea, and I expect that figuring it out requires solving a large chunk of the problems in the embedded agency [? · GW] cluster.
When I get around to writing a separate post on Alon's last chapter (evolution of modularity), that will include some additional relevant insight to the question.
↑ comment by Davidmanheim · 2019-11-20T08:20:12.413Z · LW(p) · GW(p)
It's not just selection effects on organisms - it's within organisms. The examples given are NOT fully understood, so (for example,) the bacterial transcription network motifs only contain the relationships that we understand. Given that loops and complex connections are harder to detect, that has selected for simplicity.
Given that, I still want to read the book and see the argument more fully.
comment by Rohin Shah (rohinmshah) · 2019-11-05T01:02:14.753Z · LW(p) · GW(p)
It seems like there are two claims here:
- Biological systems are not random, in the sense that they have purpose
- Biological systems are human-understandable with enough effort
The first one seems to be expected even under the "everything is a mess" model -- even though evolution is just randomly trying things, the only things that stick around are the ones that are useful, so you'd expect that most things that appear on first glance to be useless actually do have some purpose.
The second one is the claim I'm most interested in.
Some of your summaries seem to be more about the first claim. For Chapters 7-8:
For our purposes, the main takeaway from these two chapters is that, just because the system looks wasteful/arbitrary, does not mean it is. Once we know what to look for, it becomes clear that the structure of biological systems is not nearly so arbitrary as it looks.
This seems to be entirely the first claim.
The other chapters seem like they do mostly address the second claim, but it's a bit hard to tell. I'm curious if, now knowing about these two distinct claims, you still think the book is strong evidence for the second claim? What about chapters 7-8 in particular?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-05T01:40:42.096Z · LW(p) · GW(p)
I intended the claim to be entirely the second. The first is relevant mainly as a precondition for the second, and as a possible path to human understanding.
Chapters 7-8 are very much aimed at human understanding of the systems used for robust recognition and signal-passing, and I consider both those chapters and the book to be strong evidence that human understanding is tractable.
Regarding the "not random" claim, I'm guessing you're looking at many of the statistical claims? E.g. things like "only a handful of specific designs work". Those are obviously evidence of biological systems not being random, but more importantly, they're evidence that humans can see and understand ways in which biological systems are not random. Not only is there structure, that structure is human-understandable - i.e. repeated biochemical circuit designs.
Replies from: redlizard, rohinmshah↑ comment by redlizard · 2019-11-06T07:05:41.412Z · LW(p) · GW(p)
This second claim sounds to me as being a bit trivial. Perhaps it is my reverse engineering background, but I have always taken it for granted that approximately any mechanism is understandable by a clever human given enough effort.
This book [and your review] explains a number of particular pieces of understanding of biological systems in detail, which is super interesting; but the mere point that these things can be understood with sufficient study almost feels axiomatic. Ignorance is in the map, not the territory; there are no confusing phenomena, only minds confused by phenomena; etc. Even when I knew nothing about this biological machinery, I never imagined for a second that no understanding was attainable in principle. I only saw *systems that are not optimized for ease of understanding*, and therefore presumably more challenging to understand than systems designed by human engineers which *are* optimized for ease of understanding.
But I get the impression that the real point you are shooting for (and possibly, the point the book is shooting for) is a stronger point than this. Not so much "there is understanding to be had here, if you look deeply enough", but rather a claim about what *particular type of structure* we are likely to find, and how this may or may not conform to the type of structure that humans are trained to look for.
Is this true? If it is, could you expand on this distinction?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-06T18:03:05.731Z · LW(p) · GW(p)
The second claim was actually my main goal with this post. It is a claim I have heard honest arguments against, and even argued against myself, back in the day. A simple but not-particularly-useful version of the argument would be something like "the shortest program which describes biological behavior may be very long", i.e. high Kolmogorov complexity. If that program were too long to fit in a human brain, then it would be impossible for humans to "understand" the system, in some sense. We could fit the program in a long book, maybe, but since the program itself would be incompressible it would just look like thousands of pages of random noise - indeed, it would be random noise, in a very rigorous sense.
That said, while I don't think either Alon or I were making claims about what particular structure we're likely to find here, I do think there is a particular kind of structure here. I do not currently know what that structure is, but I think answering that question (or any of several equivalent questions, e.g. formalizing abstraction) is the main problem [LW · GW] required to solve embedded agency [? · GW] and AGI in general.
Also see my response to Ofer [LW(p) · GW(p)], which discusses the same issues from a different starting point.
↑ comment by Rohin Shah (rohinmshah) · 2019-11-05T07:57:35.227Z · LW(p) · GW(p)
Thanks!
comment by [deleted] · 2020-01-06T04:05:21.468Z · LW(p) · GW(p)
Excited to see that the author of this book, Uri Alon, just tweeted about this review.
A beautiful and insightful review of Introduction to Systems Biology, 2nd edition, emphasizing the routes to simplicity in biological systems:
https://lesswrong.com/posts/bNXdnRTpSXk9p4zmi/book-review-design-principles-of-biological-circuits.
comment by Michael McLaren (michael-mclaren) · 2019-12-21T00:27:34.783Z · LW(p) · GW(p)
For those who are interested, the class that Uri Alon teaches that goes with this textbook is on YouTube
comment by habryka (habryka4) · 2021-01-11T03:04:17.973Z · LW(p) · GW(p)
This post surprised me a lot. It still surprises me a lot, actually. I've also linked it a lot of times in the past year.
The concrete context where this post has come up is in things like ML transparency research, as well as lots of theories about what promising approaches to AGI capabilities research are. In particular, there is a frequently recurring question of the type "to what degree do optimization processes like evolution and stochastic gradient descent give rise to understandable modular algorithms?".
comment by Ben Pace (Benito) · 2020-12-10T00:55:41.546Z · LW(p) · GW(p)
This post was a qualitative step forward in how understandable I expected biology to be. I’d like to see it reviewed and voted on in the review.
comment by NancyLebovitz · 2019-11-06T15:53:09.510Z · LW(p) · GW(p)
I never would have thought biological systems are random, but spaghetti code isn't about randomness, it's about complex interdependence. This being said, the book looks really valuable-- even if can only help sort out the simpler parts of biology, that's quite a bit.
comment by [deleted] · 2019-11-04T23:17:58.749Z · LW(p) · GW(p)
Note: the talk you mentioned was by Drew Endy and the electrical engineering colleague was the one and only Gerald Sussman of SICP fame (source: I don't remember but I'm very confident about being right).
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-04T23:36:20.855Z · LW(p) · GW(p)
Thanks. I'm also pretty sure you're right; I thought it was Endy but wasn't 100% sure because it's been a while.
Replies from: Nonecomment by DanielFilan · 2020-12-10T04:21:42.564Z · LW(p) · GW(p)
I think that if you want to understand what structure might exist in neural networks and how comprehensible it's likely to be (which I do), looking at biology is a good place to start. This appears to be a pretty good overview of the structure of biological circuits, and hopefully gives one a taste of their degree of comprehensibility.
comment by mako yass (MakoYass) · 2019-11-24T04:58:55.968Z · LW(p) · GW(p)
A large part of the reason this is interesting is that it bears on the alignment problem; if evolved mechanisms of complex systems tend to end up being comprehensible, alignment techniques that rely on inspecting the mind of an AGI become a lot easier to imagine than they currently are.
From a comment I made response to Rohin Shah on reasons for AI optimism [LW(p) · GW(p)].
One way of putting it is that in order for an agent to be recursively self-improving in any remotely intelligent way, it needs to be legible to itself. Even if we can't immediately understand its components in the same way that it does, it must necessarily provide us with descriptions of its own ways of understanding them, which we could then potentially co-opt.
comment by Thomas Kwa (thomas-kwa) · 2022-04-04T18:01:05.837Z · LW(p) · GW(p)
Fold change: the system responds to percentage changes, across several decibels of background intensity.
Should this be "several orders of magnitude of background intensity"?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-04-04T18:28:11.959Z · LW(p) · GW(p)
Yes, I guess I should have said "several tens of decibels" or "many decibels" or something like that.