Posts
Comments
Huh, by gricean implicature it IMO clearly implies that if there was a strong case that it would increase investment, then it would be a relevant and important consideration. Why bring it up otherwise?
I am really quite confident in my read here. I agree Jaime is not being maximally explicit here, but I would gladly take bets that >80% of random readers who would listen to a conversation like this, or read a comment thread like this, would walk away thinking the author does think that whether AI scaling would increase as a result of this kind of work, is considered relevant and important by Jaime.
Thank you, that is helpful information.
I don't undertand what it would mean for "outputs" to be corrigible, so I feel like you must be talking about internal chain of thoughts here? The output of a corrigible AI and a non-corrigibile AI is the same for almost all tasks? They both try to perform any task as well as possible, the difference is how they relate to the task and how they handle interference.
This comment suggests it was maybe a shift over the last year or two (but also emphasises that at least Jaime thinks AI risk is still serious): https://www.lesswrong.com/posts/Fhwh67eJDLeaSfHzx/jonathan-claybrough-s-shortform?commentId=X3bLKX3ASvWbkNJkH
I personally take AI risks seriously, and I think they are worth investigating and preparing for.
I have drifted towards a more skeptical position on risk in the last two years. This is due to a combination of seeing the societal reaction to AI, me participating in several risk evaluation processes, and AI unfolding more gradually than I expected 10 years ago.
Currently I am more worried about concentration in AI development and how unimproved humans will retain wealth over the very long term than I am about a violent AI takeover.
They have definitely described themselves as safety focused to me and others. And I don't know man, this back and forth to me sure sounds like they were branding themselves as being safety conscious:
Ofer: Can you describe your meta process for deciding what analyses to work on and how to communicate them? Analyses about the future development of transformative AI can be extremely beneficial (including via publishing them and getting many people more informed). But getting many people more hyped about scaling up ML models, for example, can also be counterproductive. Notably, The Economist article that you linked to shows your work under the title "The blessings of scale". (I'm not making here a claim that that particular article is net-negative; just that the meta process above is very important.)
Jaime: OBJECT LEVEL REPLY:
Our current publication policy is:
- Any Epoch staff member can object when we announce intention to publish a paper or blogpost.
- We then have a discussion about it. If we conclude that there is a harm and that the harm outweights the benefits we refrain from publishing.
- If no consensus is reached we discuss the issue with some of our trusted partners and seek advice.
- Some of our work that is not published is instead disseminated privately on a case-by-case basis
We think this policy has a good mix of being flexible and giving space for Epoch staff to raise concerns.Zach: Out of curiosity, when you "announce intention to publish a paper or blogpost," how often has a staff member objected in the past, and how often has that led to major changes or not publishing?
Jaime: I recall three in depth conversations about particular Epoch products. None of them led to a substantive change in publication and content.
OTOH I can think of at least three instances where we decided to not pursue projects or we edited some information out of an article guided by considerations like "we may not want to call attention about this topic".
In general I think we are good at preempting when something might be controversial or could be presented in a less conspicuous framing, and acting on it.
As well as:
Thinking about the ways publications can be harmful is something that I wish was practiced more widely in the world, specially in the field of AI.
That being said, I believe that in EA, and in particular in AI Safety, the pendulum has swung too far - we would benefit from discussing these issues more openly.
In particular, I think that talking about AI scaling is unlikely to goad major companies to invest much more in AI (there are already huge incentives). And I think EAs and people otherwise invested in AI Safety would benefit from having access to the current best guesses of the people who spend more time thinking about the topic.
This does not exempt the responsibility for Epoch and other people working on AI Strategy to be mindful of how their work could result in harm, but I felt it was important to argue for more openness in the margin.
Jaime directly emphasizes how increasing AI investment would be a reasonable and valid complaint about Epoch's work if it was true! Look, man, if I asked this set of question, got this set of answers, while the real answer is "Yes, we think it's pretty likely we will use the research we developed at Epoch to launch a long-time-horizon focused RL capability company", then I sure would feel pissed (and am pissed).
I had conversations with maybe two dozen people evaluating the work of Epoch over the past few months, as well as with Epoch staff, and they were definitely generally assumed to be safety focused (if sometimes from a worldview that is more gradual disempowerment focused). I heard concerns that the leadership didn't really care about existential risk, but nobody I talked to felt confident in that (though maybe I missed that).
We don't yet, but have considered it a few times. It would be quite surprising if it's a big source of revenue, so has not been a big priority for us on those grounds, but I do think it would be cool.
You are using the Markdown editor, which many fewer users use. The instructions are correct for the WYSIWYG editor (seems fine to add a footnote explaining the different syntax for Markdown).
It already has been getting a bunch harder. I am quite confident a lot of new submissions to LW are AI-generated, but the last month or two have made distinguishing them from human writing a lot harder. I still think we are pretty good, but I don't think we are that many months away from that breaking as well.
Promoted to curated: I quite liked this post. The basic model feels like one I've seen explained in a bunch of other places, but I did quite like the graphs and the pedagogical approach taken in this post, and I also think book reviews continue to be one of the best ways to introduce new ideas.
Would you expect that if you trained an AI system on translating its internal chain of thought into a different language, that this would make it substantially harder for it to perform tasks in the language in which it was originally trained in? If so, I am confident you are wrong and that you have learned something new today!
Training transformers in additional languages basically doesn't really change performance at all, the model just learns to translate between its existing internal latent distribution and the new language, and then just now has a new language it can speak in, with basically no substantial changes in its performance on other tasks (of course, being better at tasks that require speaking in the new foreign language, and maybe a small boost in general task performance because you gave it more data than you had before).
Of course the default outcome of doing finetuning on any subset of data with easy-to-predict biases will be that you aren't shifting the inductive biases of the model on the vast majority of the distribution. This isn't because of an analogy with evolution, it's a necessity of how we train big transformers. In this case, the AI will likely just learn how to speak the "corrigible language" the same way it learned to speak french, and this will make approximately zero difference to any of its internal cognition, unless you are doing transformations to its internal chain of thought that substantially change its performance on actual tasks that you are trying to optimize for.
Interspersing the french data with the rest of its training data won't change anything either. It again will just learn the language. Giving it more data in french will now just basically do the same as giving it more data in english. The learning is no longer happening at the language level, its happening at the content and world-model level.
Things that happen:
- Backpropagating on the outputs that are "more corrigible" will have some (though mostly very small) impact on your task performance. If you set the learning rate high, or you backpropagate on a lot of data, your performance can go down arbitrarily far.
- By default this will do very little because you are providing training data with very little variance in it (even less so than usual, because you are training on AI outputs, which the AI is of course already amazing at predicting). If you train very hard you will probably deal with consistent mode collapse. In general, you can't really train AI systems with any particular bias in your data, because you don't have enough variation in your data. We can approximately only train AI systems to do one thing, which is to predict the next token from a distributions for which we have trillions of tokens of training data that are hard to predict (which is basically just going to be internet text, audio and video, though more RL-like environments are also feasible now).[1]
The answer to this is the answer to any question of the form "what if we just generate lots of data with the inductive biases we would like the model to have?".
The answer is always
- "we can't generate realistic data with whatever inductive biases we want", and
- "we can't remotely generate enough data without dealing with mode collapse", and
- "we have basically no idea how inductive biases generalize from the training data to the model output, especially as the model starts reflecting on itself and modeling the data generation process" and
- "if you train or backpropagate directly against your discriminator the model will learn to hack the discriminator, (even if the discriminator is the model itself)",
which are like all the standard alignment failures that have been written about for tens of thousands of pages by now.
At a more detailed level, here is roughly what I actually expect to happen if you do this specific thing, but to be clear, this is a much less confident prediction than the reference class outlined above:
- After a few hundreds of thousands of iterations of this the model will have figured out a set of consistent indicators present whenever it is given past output of itself that it was asked to rephrase to "be more corrigible"
- It becomes quite good at predicting these indicators and quickly saturates on predicting these indicators, resulting in very corrigible looking outputs within the same distribution in which you did this training
- Given that the actual output of the chain of thought changes very little, this results in very little gradients to almost any of its other cognition, the same way that training an AI in an additional language with different grammar and social norms basically doesn't really change any of its other circuits and cognitions
- If you drastically increase the learning rate or really go very hard on generating enormous amounts of data the model will start to cannibalize other parts of its cognition to perform well at this task, at which generalized task performance will go down, but you probably won't do this, because it would be very expensive (and also make the model non-competitive)
- Within distribution the model will now probably produce outputs that look "more corrigible". Again, this will not actually reflect much of a change in its internal cognition, the same way training an AI system on foreign language output will not substantially interfere with its cognition in other languages
- If you train the model on some end-to-end tasks where the corrigibility would end up bad for performance, it will probably very quickly learn to self-prompt itself in a way that causes it to think to itself without the corrigibility biases you introduced into it. This might literally mean switching to a different literal foreign language for its internal thoughts, or something equivalent, but most likely it just means it sounds more like what it previously sounded like before you did this whole thing. If you try to prevent this with continuous monitoring, it will find some way to jailbreak itself or think in some way where the corrigibility language monitoring makes little difference to what cognition is actually going on.
Ending on a slightly more sarcastic note because I do feel a sense of despair about even people who have been thinking about this stuff for a long time seeming to me to not see the logic above:
At the end of the day, very little good will have happened, but you will have a harder time identifying whether the model is thinking non-corrigibly, as you have trained the model against at least one discriminator for deception without training out its deceptive cognition. If you now repeat this for 4-5 similarly shallow alignment approaches you will have produced a model that looks visibly more aligned to anyone who thinks approaches like this might work, without any actual changes to the underlying structure of its cognition, making coordination to actually do anything about the problem much harder.
- ^
Or in a more generalized form also applicable to RL environments: We can only train AI systems to be competent, as all scaling laws (and common sense) have shown that competence is approximately the only thing that generalizes between all environments.
We cannot generate environments that teach virtue, because we do not have principles with which we can create the whole complexity of a universe that requires superhuman intelligence to navigate, while also only doing so by thinking in the specific preferred ways that we would like you to think. We do not know how to specify how to solve most problems in virtuous ways, we are barely capable of specifying how to solve them at all, and so cannot build environments consistently rich that chisel virtuous cognition into you.The amount of chiseling of cognition any approach like this can achieve is roughly bounded by the difficulty and richness of cognition that your transformation of the data requires to reverse. Your transformation of the data is likely trivial to reverse (i.e. predicting the "corrigible" text from non-corrigible cognition is likely trivially easy especially given that it's AI generated by our very own model), and as such, practically no chiseling of cognition will occur. If you hope to chisel cognition into AI, you will need to do it with a transformation that is actually hard to reverse, so that you have a gradient into most of the network that is optimized to solve hard problems.
Yeah, I don't the classification is super obvious. I categorized all things that had AI policy relevance, even if not directly about AI policy.
23 is IMO also very unambiguously AI policy relevant (ignoring quality). Zvi's analysis almost always includes lots of AI policy discussion, so I think 33 is also a clear "Yes". The other ones seem like harder calls.
Sampling all posts also wouldn't be too hard. My guess is you get something in the 10-20%-ish range of posts by similar standards.
Maybe you switched to the Markdown editor at some point. It still works in the (default) WYSIWYG editor.
IDK, like 15% of submissions to LW seem currently AI governance and outreach focused. I don't really get the premise of the post. It's currently probably tied for the most popular post category on the site (my guess is a bit behind more technical AI Alignment work, but not by that much).
Here is a quick spreadsheet where I classify submissions in the "AI" tag by whether they are substantially about AI Governance:
https://docs.google.com/spreadsheets/d/1M5HWeH8wx7lUdHDq_FGtNcA0blbWW4798Cs5s54IGww/edit?usp=sharing
Overall results: 34% of submissions under the AI tag seem pretty clearly relevant to AI Governane or are about AI governance, and additional 12% are "maybe". In other words, there really is a lot of AI Governance discussion on LW.
Solar + wind has made a huge dent in energy production, so I feel like this example is confused.
It does seem like this strategy just really worked quite well, and a combination of battery progress and solar would probably by-default replace much of fossil-fuel production in the long run. It already has to a quite substantial degree:
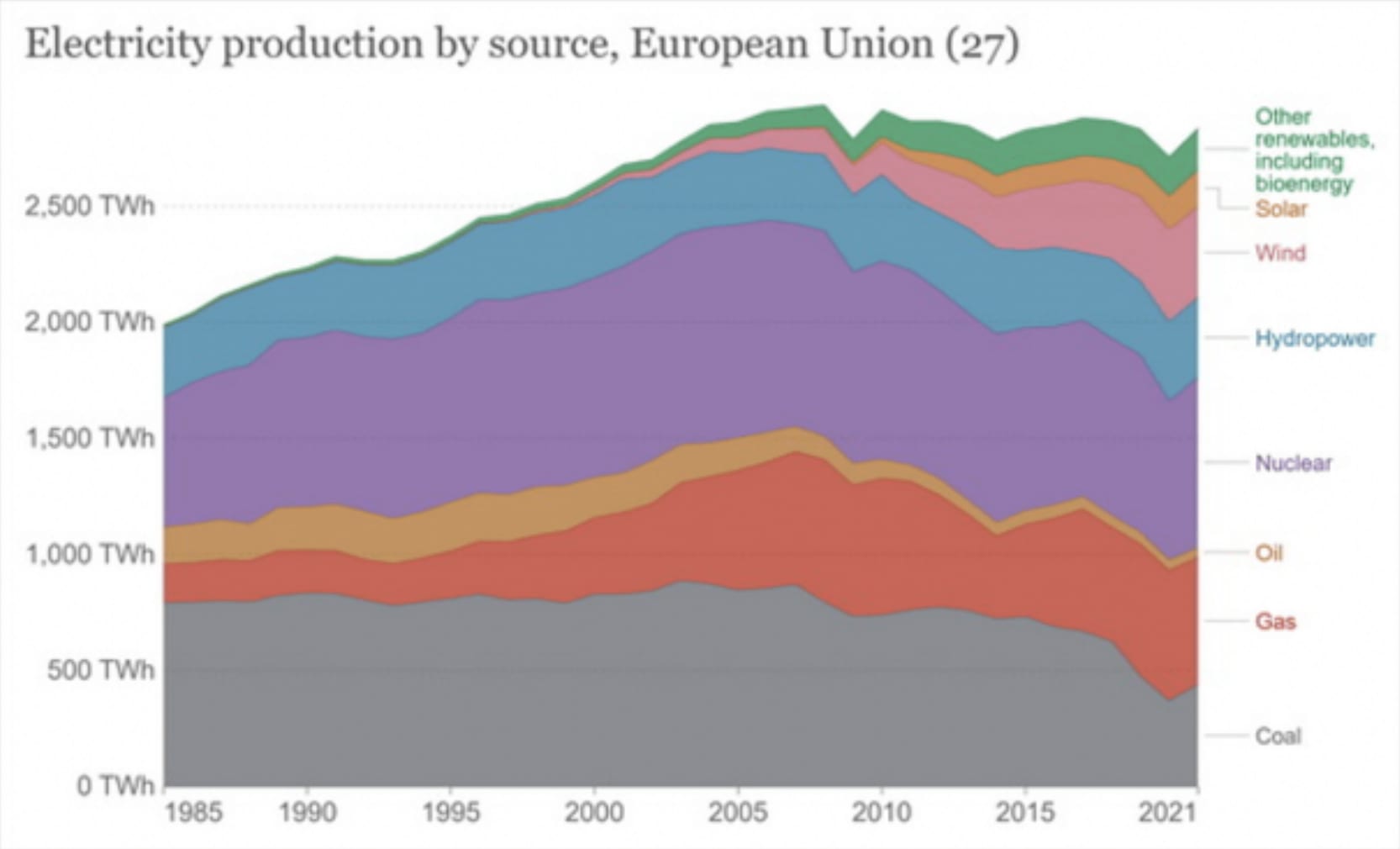
Hydro + Solar + Wind + other renewables has grown to something like 40% of total energy production (edit: in the EU, which feels like the most reasonable reference class for whether this worked).
Domains with high skill ceilings are quite rare.
Success in almost every domain is strongly correlated with g, including into the tails. This IMO relatively clearly shows that most domains are high skill-ceiling domains (and also that skills in most domains are correlated and share a lot of structure).
This reminds me of a conversation I had recently about whether the concept of "evil" is useful. I was arguing that I found "evil"/"corruption" helpful as a handle for a more model-free "move away from this kind of thing even if you can't predict how exactly it would be bad" relationship to a thing, which I found hard to express in a more consequentialist frames.
Promoted to curated: I really liked this post for its combination of reporting negative results, communicating a deeper shift in response to those negative results, while seeming pretty well-calibrated about the extent of the update. I would have already been excited about curating this post without the latter, but it felt like an additional good reason.
I think for many years there was a lot of frustration from people outside of the community about people inside of it not going into a lot of detail. My guess is we are dealing with a bit of a pendulum swing of now people going hard in the other direction. I do think we are just currently dealing with one big wave of this kind of content. It's not like there was much of any specific detailed scenario work two years ago.
My best guess is you are a few months behind in your takes? The latest generation of thinking models can definitely do agentic frontend development and build small projects autonomously. It definitely still makes errors, and has blindspots that require human supervision, but in terms of skill level, the systems feel definitely comparable and usually superior to junior programmers (but when they fail, they fail hard and worse than real junior programmers).
I am planning to make an announcement post for the new album in the next few days, maybe next week. The songs yesterday were early previews and we still have some edits to make before it's ready!
Context: LessWrong has been acquired by EA
Goodbye EA. I am sorry we messed up.
EA has decided to not go ahead with their acquisition of LessWrong.
Just before midnight last night, the Lightcone Infrastructure board presented me with information suggesting at least one of our external software contractors has not been consistently candid with the board and me. Today I have learned EA has fully pulled out of the deal.
As soon as EA had sent over their first truckload of cash, we used that money to hire a set of external software contractors, vetted by the most agentic and advanced resume review AI system that we could hack together.
We also used it to launch the biggest prize the rationality community has seen, a true search for the kwisatz haderach of rationality. $1M dollars for the first person to master all twelve virtues.

Unfortunately, it appears that one of the software contractors we hired inserted a backdoor into our code, preventing anyone except themselves and participants excluded from receiving the prize money from collecting the final virtue, "The void". Some participants even saw themselves winning this virtue, but the backdoor prevented them mastering this final and most crucial rationality virtue at the last possible second.
They then created an alternative account, using their backdoor to master all twelve virtues in seconds. As soon as our fully automated prize systems sent over the money, they cut off all contact.
Right after EA learned of this development, they pulled out of the deal. We immediately removed all code written by the software contractor in question from our codebase. They were honestly extremely productive, and it will probably take us years to make up for this loss. We will also be rolling back any karma changes and reset the vote strength of all votes cast in the last 24 hours, since while we are confident that if our system had worked our karma system would have been greatly improved, the risk of further backdoors and hidden accounts is too big.
We will not be refunding the enormous boatloads of cash[1] we were making in the sale of Picolightcones, as I am assuming you all read our sale agreement carefully[2], but do reach out and ask us for a refund if you want.
Thank you all for a great 24 hours though. It was nice while it lasted.
- ^
$280! Especially great thanks to the great whale who spent a whole $25.
- ^
IMPORTANT Purchasing microtransactions from Lightcone Infrastructure is a high-risk indulgence. It would be wise to view any such purchase from Lightcone Infrastructure in the spirit of a donation, with the understanding that it may be difficult to know what role custom LessWrong themes will play in a post-AGI world. LIGHTCONE PROVIDES ABSOLUTELY NO LONG-TERM GUARANTEES THAT ANY SERVICES SUCH RENDERED WILL LAST LONGER THAN 24 HOURS.
You can now choose which virtues you want to display next to your username! Just go to the virtues dialogue on the frontpage and select the ones you want to display (up to 3).
Absolutely, that is our sole motivation.
I initially noticed April Fools' day after following a deep-link. I thought I had seen the font of the username all wacky (kind-of pixelated?), and thus was more annoyed.
You are not imagining things! When we deployed things this morning/late last night I had a pixel-art theme deployed by default across the site, but then after around an hour decided it was indeed too disruptive to the reading experience and reverted it. Seems like we are both on roughly the same page on what is too much.
Yeah, our friends at EA are evidently still figuring out some of their karma economy. I have been cleaning up places where people go a bit crazy, but I think we have some whales walking around with 45+ strong upvote-strength.
Lol, get a bigger screen :P
(The cutoff is 900 pixels)
It's always been a core part of LessWrong April Fool's that we never substantially disrupt or change the deep-linking experience.
So while it looks like a lot of going on today, if you get linked directly to an article, you will basically notice nothing different. All you will see today are two tiny pixel-art icons in the header, nothing else. There are a few slightly noisy icons in the comment sections, but I don't think people would mind that much.
This has been a core tenet of all April Fool's in the past. The frontpage is fair game, and April Fool's jokes are common for large web platforms, but it should never get in the way of accessing historical information or parsing what the site is about, if you get directly linked to an author's piece of writing.
Wait, lol, that shouldn't be possible.
The lootbox giveth and the lootbox taketh.
Where is it now? :P

Huh, I currently have you in our database as having zero LW-Bux or virtues. We did some kind of hacky things to enable tracking state both while logged in and logged out, so there is a non-trivial chance I messed something up, though I did try all the basic things. Looking into it right now.
Ah, yeah, that makes sense. Seems like we are largely on the same page then.
It seemed in conflict to me with this sentence in the OP (which Isopropylpod was replying to):
Elon wants xAI to produce a maximally truth-seeking AI, really decentralizing control over information.
I do think in some sense Elon wants that, but my guess is he wants other things more, which will cause him to overall not aim for this.
I am personally quite uncertain about how exactly the xAI thing went down. I find it pretty plausible that it was a result of pressure from Musk, or at least indirect pressure, that was walked back when it revealed itself as politically unwise.
sadistic people (or malicious bots/AI agents) can open new posts and double downvote them in mass without reading at all!
We do alt-account detection and mass-voting detection. I am quite confident we would reliably catch any attempts at this, and that this hasn't been happening so far.
Why not to at least ask people why they downvote? It will really help to improve posts. I think some downvote without reading because of a bad title or another easy to fix thing.
Because this would cause people to basically not downvote things, drastically reducing the signal to noise ratio of the site.
FWIW, I would currently take bets that Musk will pretty unambiguously enact and endorse censorship of things critical of him or the Trump administration more broadly within the next 12 months. I agree this case is ambiguous, but my pretty strong read based on him calling for criminal prosecution of journalists who say critical things about him or the Trump administration is that the moment its a question of political opportunity, not willingness. I am not totally sure, but sure enough to take a 1:1 bet on this operationalization.
My best guess is (which I roughly agree with) is that your comments are too long, likely as a result of base-model use.
Maybe I am confused (and it's been a while since I thought about these parts of decision theory), but I thought smoking lesion is usually the test case for showing why EDT is broken, and newcombs is usually the test case for why CDT is broken, so it makes sense that Smoking Lesion wouldn't convince you that CDT is wrong.
Back in 2022 when our team was getting the ball rolling on the whole dangerous capabilities testing / evals agenda, I was like…
Looks like the rest of the comment got cut off?
(My comments start with a higher vote-total since my small-vote strength is 2. Then looks like one person voted on mine but not yours, but one vote is really just random noise, I would ignore it)
I mean, one thing base models love to do is to generate biographical details about my life which are not accurate. Once when I was generating continuations to a thread where Alex Zhu was arguing with me about near-death experiences the model just claimed that I really knew that you don't have any kind of "life flashing before your eyes" thing that happens when you are near death, because actually, I had been in 5+ near death experiences, and so I really would know. This would of course be a great argument to make if it was true, but it of course is not. Smaller variations of this kind of stuff happen to me all the time, and they are easy to miss.
I think you are underestimating the degree to which contribution to LessWrong is mostly done by people who have engaged with each other a lot. We review all posts from new users before they go live. We can handle more submissions, and lying to the moderators about your content being AI written is not going to work for that many iterations. And with that policy, if we find out you violated the content policies, we feel comfortable banning you.
I think it's a little more complex than that, but not much. Humans can't tell LLM writing from human writing in controlled studies. The question isn't whether you can hide the style or even if it's hard, just how easy.
I am quite confident I can tell LLM writing from human writing. Yes, there are prompts sufficient to fool me, but only for a bit until I pick up on it. Adding "don't write in a standard LLM style" would not be enough, and my guess is nothing that takes less than half an hour to figure out would be enough.
I have also done a lot of writing with base models! (Indeed, we have an admin-only base-model completion feature built into the LW editor that I frequently use).
I think roughly the same guideline applies to base models as for research assistants:
A rough guideline is that if you are using AI for writing assistance, you should spend a minimum of 1 minute per 50 words (enough to read the content several times and perform significant edits), you should not include any information that you can't verify, haven't verified, or don't understand, and you should not use the stereotypical writing style of an AI assistant.
Base models like to make stuff up even more so than assistant models, and they do so in more pernicious ways, so I would probably increase this threshold a bit. They do help me write, but I do really need to read everything 3-4 times to check they didn't just make up something random about me, or imply something false.
The first one fails IMO on "don't use the stereotypical writing style of LLM assistants", but seems probably fine on the other ones (a bit hard to judge without knowing how much are your own ideas). You also disclose the AI writing at the bottom, which helps, though it would be better for it to be at the top. I think it's plausible I would have given a warning for this.
I think the comment that you write with "the help of my brain only" is better than the other one, so in as much as you have a choice, I would choose to do more of that.
We get easily like 4-5 LLM-written post submissions a day these days. They are very evidently much worse than the non-LLM written submissions. We sometimes fail to catch one, and then people complain: https://www.lesswrong.com/posts/PHJ5NGKQwmAPEioZB/the-unearned-privilege-we-rarely-discuss-cognitive?commentId=tnFoenHqjGQw28FdY
No worries!
You did say it would be premised on either "inevitable or desirable for normal institutions to be eventually lose control". In some sense I do think this is "inevitable" but only in the same sense as past "normal human institutions" lost control.
We now have the internet and widespread democracy so almost all governmental institutions needed to change how they operate. Future technological change will force similar changes. But I don't put any value in the literal existence of our existing institutions, what I care about is whether our institutions are going to make good governance decisions. I am saying that the development of systems much smarter than current humans will change those institutions, very likely within the next few decades, making most concerns about present institutional challenges obsolete.
Of course something that one might call "institutional challenges" will remain, but I do think there really will be a lot of buck-passing that will happen from the perspective of present day humans. We do really have a crunch time of a few decades on our hands, after which we will no longer have much influence over the outcome.
I don't think I understand. It's not about human institutions losing control "to a small regime". It's just about most coordination problems being things you can solve by being smarter. You can do that in high-integrity ways, probably much higher integrity and with less harmful effects than how we've historically overcome coordination problems. I de-facto don't expect things to go this way, but my opinions here are not at all premised on it being desirable for humanity to lose control?
This IMO doesn't really make any sense. If we get powerful AI, and we can either control it, or ideally align it, then the gameboard for both global coordination and building institutions completely changes (and of course if we fail to control or align it, the gameboard is also flipped, but in a way that removes us completely from the picture).
Does anyone really think that by the time you have systems vastly more competent than humans, that we will still face the same coordination problems and institutional difficulties as we have right now?
It does really look like there will be a highly pivotal period of at most a few decades. There is a small chance humanity decides to very drastically slow down AI development for centuries, but that seems pretty unlikely, and also not clearly beneficial. That means it's not a neverending institutional challenge, it's a challenge that lasts a few decades at most, during which humanity will be handing off control to some kind of cognitive successor which is very unlikely to face the same kinds of institutional challenges as we are facing today.
That handoff is not purely a technical problem, but a lot of it will be. At the end of the day, whether your successor AI systems/AI-augmented-civilization/uplifted-humanity/intelligence-enhanced-population will be aligned with our preferences over the future has a lot of highly technical components.
Yes, there will be a lot of social problems, but the size and complexity of the problems are finite, at least from our perspective. It does appear that humanity is at the cusp of unlocking vast intelligence, and after you do that, you really don't care very much about the weird institutional challenges that humanity is currently facing, most of which can clearly be overcome by being smarter and more competent.