AI Timelines
post by habryka (habryka4), Daniel Kokotajlo (daniel-kokotajlo), Ajeya Cotra (ajeya-cotra), Ege Erdil (ege-erdil) · 2023-11-10T05:28:24.841Z · LW · GW · 135 commentsContents
Introduction Summary of the Dialogue Some Background on their Models Habryka's Overview of Ajeya & Daniel discussion Habryka's Overview of Ege & Ajeya/Daniel Discussion The Dialogue Visual probability distributions Opening statements Daniel Ege Ajeya On in-context learning as a potential crux Taking into account government slowdown Recursive self-improvement and AI's speeding up R&D Do we expect transformative AI pre-overhang or post-overhang? Hofstadter's law in AGI forecasting Summary of where we are at so far and exploring additional directions Exploring conversational directions Ege's median world Far-off-distribution transfer A concrete scenario & where its surprises are Overall summary, takeaways and next steps None 135 comments
Introduction
How many years will pass before transformative AI is built? Three people who have thought about this question a lot are Ajeya Cotra from Open Philanthropy, Daniel Kokotajlo from OpenAI and Ege Erdil from Epoch. Despite each spending at least hundreds of hours investigating this question, they still still disagree substantially about the relevant timescales. For instance, here are their median timelines for one operationalization of transformative AI:
| Median Estimate for when 99% of currently fully remote jobs will be automatable | |
|---|---|
| Daniel | 4 years |
| Ajeya | 13 years |
| Ege | 40 years |
You can see the strength of their disagreements in the graphs below, where they give very different probability distributions over two questions relating to AGI development (note that these graphs are very rough and are only intended to capture high-level differences, and especially aren't very robust in the left and right tails).
| In what year would AI systems be able to replace 99% of current fully remote jobs? |
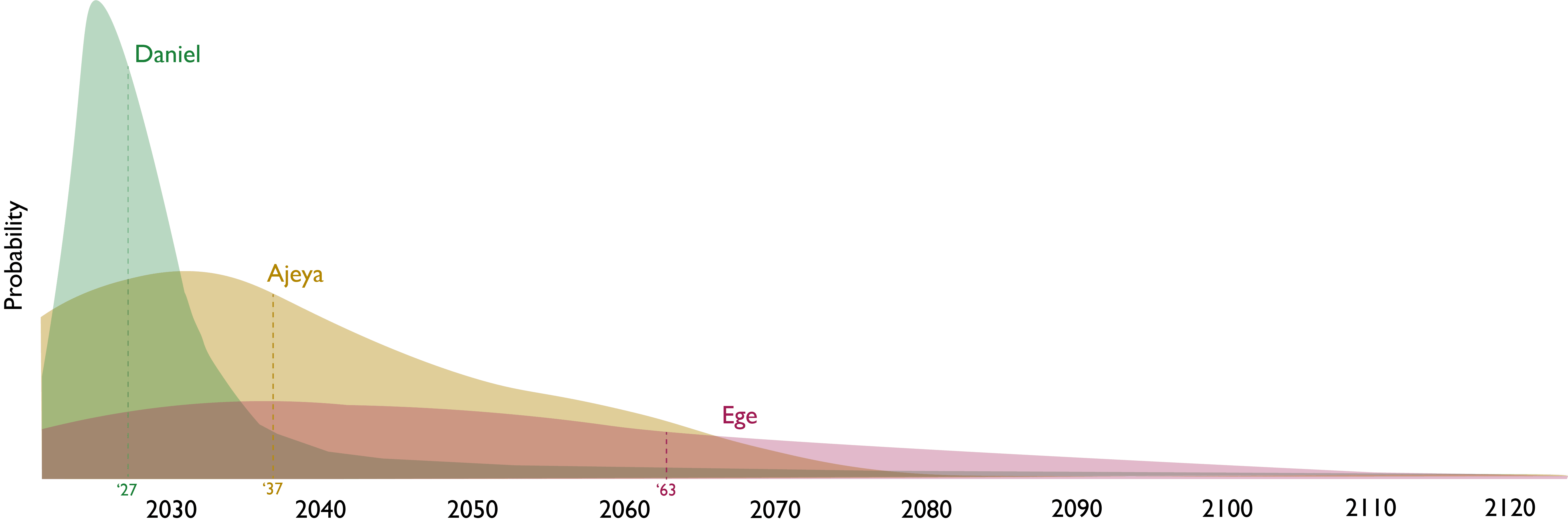
| In what year will the energy consumption of humanity or its descendants be 1000x greater than now? |
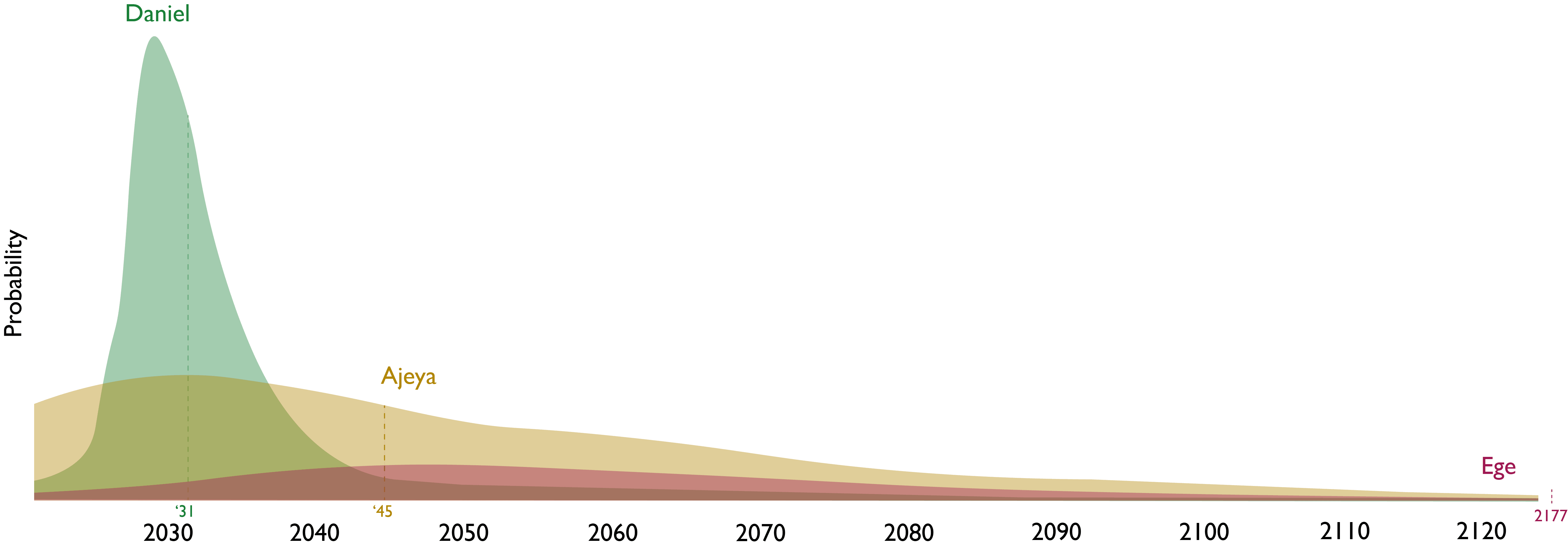
So I invited them to have a conversation about where their disagreements lie, sitting down for 3 hours to have a written dialogue. You can read the discussion below, which I personally found quite valuable.
The dialogue is roughly split in two, with the first part focusing on disagreements between Ajeya and Daniel, and the second part focusing on disagreements between Daniel/Ajeya and Ege.
I'll summarize the discussion here, but you can also jump straight in.
Summary of the Dialogue
Some Background on their Models
Ajeya and Daniel are using a compute-centric model for their AI forecasts, illustrated by Ajeya's draft AI Timelines report [LW · GW], and Tom Davidson's takeoff model [LW · GW] where the question of "when transformative AI" gets reduced to "how much compute is necessary to get AGI and when will we have that much compute? (modeling algorithmic advances as reductions in necessary compute)".
Whereas Ege thinks such models should have a lot of weight in our forecasts, but that they likely miss important considerations and doesn't have enough evidence to justify the extraordinary predictions it makes.
Habryka's Overview of Ajeya & Daniel discussion
- Ajeya thinks translating AI capabilities into commercial applications has gone slower than expected ("it seems like 2023 brought the level of cool products I was naively picturing in 2021") and similarly thinks there will be a lot of kinks to figure out before AI systems can substantially accelerate AI development.
- Daniel agrees that impactful commercial applications have been slower than expected, but also thinks that the parts that made that slow can be automated substantially, and that a lot of the complexity comes from shipping something that can be useful to general consumers, and that for applications internal to the company, these capabilities can be unlocked faster.
- Compute overhangs also play a big role in the differences between Ajeya and Daniel's timelines. There is currently substantial room to scale up AI by just spending more money on readily available compute. However, within a few years, increasing the amount of training compute further will require accelerating the semiconductor supply chain, which probably can't be easily achieved by just spending more money. This creates a "compute overhang" that accelerates AI progress substantially in the short run. Daniel thinks it's more likely than not that we will get transformative AI before this compute overhang is exhausted. Ajeya thinks that is plausible, but overall it's more likely to happen after, which broadens her timelines quite a bit.
These disagreements probably explain some but not most of the differences in the timelines for Daniel and Ajeya.
Habryka's Overview of Ege & Ajeya/Daniel Discussion
- Ege thinks that Daniel's forecast leaves very little room for Hoftstadter's law ("It always takes longer than you expect, even when you take into account Hofstadter's Law"), and in-general that there will be a bunch of unexpected things that go wrong on the path to transformative AI
- Daniel thinks that Hofstadter's law is inappropriate for trend extrapolation. I.e. it doesn't make sense to look at Moore's law and be like "ah, and because of planning fallacy the slope of this graph from today is half of what it was previously"
- Both Ege and Ajeya don't expect a large increase in transfer learning ability in the next few years. For Ege this matters a lot because it's one of the top reasons why AI will not speed up the economy and AI development that much. Ajeya thinks we can probably speed up AI R&D anyways by making AI that doesn't have transfer as good as humans, but is just really good at ML engineering and AI R&D because it was directly trained to be.
- Ege expects that AI will have a large effect on the economy, but has substantial probability on persistent deficiencies that prevent AI from fully automating AI R&D or very substantially accelerating semiconductor progress.
Overall, whether AI will get substantially better at transfer learning (e.g. seeing an AI be trained on one genre of video game and then very quickly learn to play another genre of video game) would update all participants substantially towards shorter timelines.
We ended the dialogue with Ajeya, Daniel and Ege by putting numbers on how much various AGI milestones would cause them to update their timelines (with the concrete milestones proposed by Daniel). Time constraints made it hard to go into as much depth as we would have liked, but me and Daniel are excited about fleshing more concrete scenarios of how AGI could play out and then collecting more data on how people would update in such scenarios.
The Dialogue
Visual probability distributions
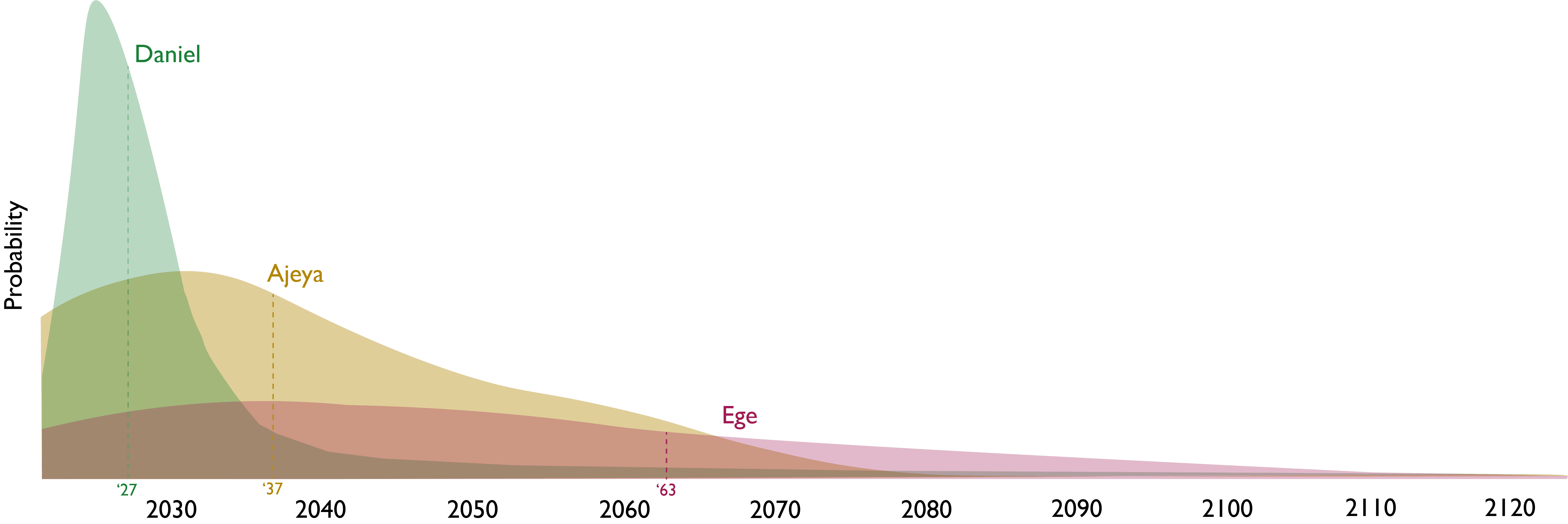
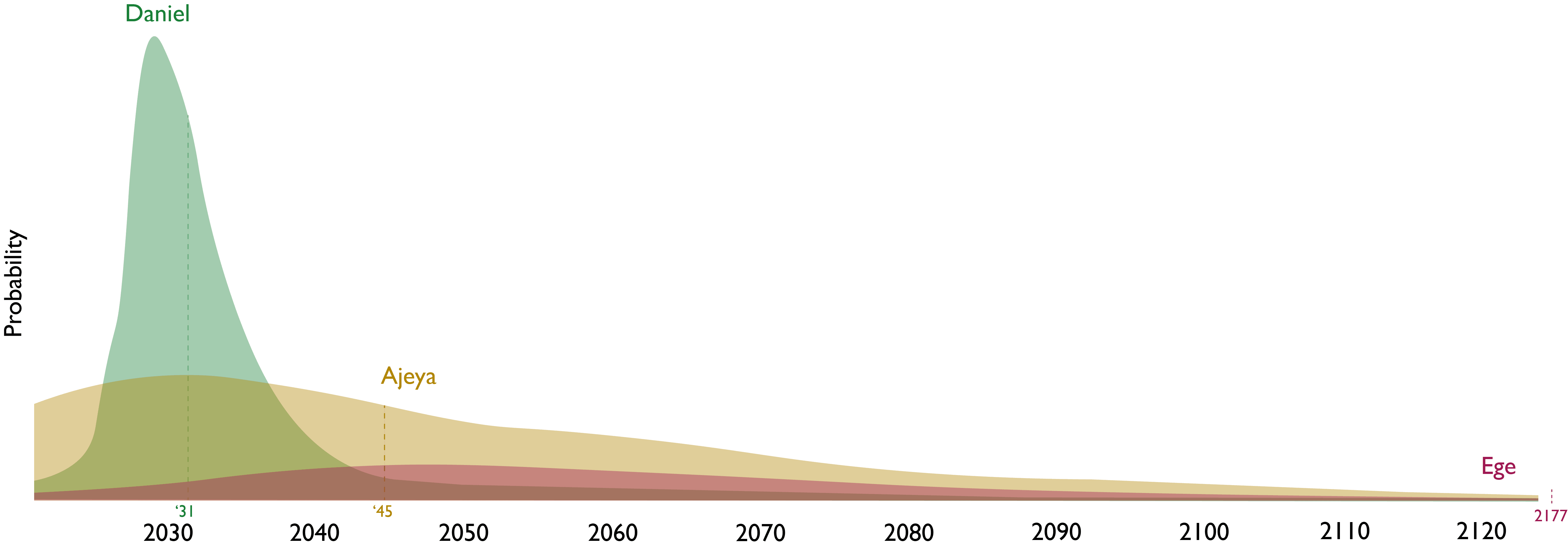
Opening statements
Daniel
Ege
Ajeya
On in-context learning as a potential crux
Taking into account government slowdown
Recursive self-improvement and AI's speeding up R&D
Do we expect transformative AI pre-overhang or post-overhang?
Hofstadter's law in AGI forecasting
Summary of where we are at so far and exploring additional directions
Exploring conversational directions
Ege's median world
Far-off-distribution transfer
A concrete scenario & where its surprises are
Overall summary, takeaways and next steps
135 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T19:48:45.734Z · LW(p) · GW(p)
I had a nice conversation with Ege today over dinner, in which we identified a possible bet to make! Something I think will probably happen in the next 4 years, that Ege thinks will probably NOT happen in the next 15 years, such that if it happens in the next 4 years Ege will update towards my position and if it doesn't happen in the next 4 years I'll update towards Ege's position.
Drumroll...
I (DK) have lots of ideas for ML experiments, e.g. dangerous capabilities evals, e.g. simple experiments related to paraphrasers and so forth in the Faithful CoT agenda. But I'm a philosopher, I don't code myself. I know enough that if I had some ML engineers working for me that would be sufficient for my experiments to get built and run, but I can't do it by myself.
When will I be able to implement most of these ideas with the help of AI assistants basically substituting for ML engineers? So I'd still be designing the experiments and interpreting the results, but AutoGPT5 or whatever would be chatting with me and writing and debugging the code.
I think: Probably in the next 4 years. Ege thinks: probably not in the next 15.
Ege, is this an accurate summary?
↑ comment by Ege Erdil (ege-erdil) · 2023-11-29T20:27:37.047Z · LW(p) · GW(p)
Yes, this summary seems accurate.
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-09-11T16:01:56.740Z · LW(p) · GW(p)
Thanks for the update, Daniel! How about the predictions about energy consumption?
| In what year will the energy consumption of humanity or its descendants be 1000x greater than now? |
Your median date for humanity's energy consumption being 1 k times as large as now is 2031, whereas Ege's is 2177. What is your median primary energy consumption in 2027 as reported by Our World in Data as a fraction of that in 2023? Assuming constant growth from 2023 until 2031, your median fraction would be 31.6 (= (10^3)^((2027 - 2023)/(2031 - 2023))). I would be happy to set up a bet where:
- I give you 10 k€ if the fraction is higher than 31.6.
- You give me 10 k€ if the fraction is lower than 31.6. I would then use the 10 k€ to support animal welfare interventions.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-09-11T23:32:33.029Z · LW(p) · GW(p)
To be clear, my view is that we'll achieve AGI around 2027, ASI within a year of that, and then some sort of crazy robot-powered self-replicating economy within, say, three years of that. So 1000x energy consumption around then or shortly thereafter (depends on the doubling time of the crazy superintelligence-designed-and-managed robot economy).
So, the assumption of constant growth from 2023 to 2031 is very false, at least as a representation of my view. I think my median prediction for energy consumption in 2027 is the same as yours.
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-09-12T08:32:35.704Z · LW(p) · GW(p)
Thanks, Daniel!
To be clear, my view is that we'll achieve AGI around 2027, ASI within a year of that, and then some sort of crazy robot-powered self-replicating economy within, say, three years of that
Is you median date of ASI as defined by Metaculus around 2028 July 1 (it would be if your time until AGI was strongly correlated with your time from AGI to ASI)? If so, I am open to a bet where:
- I give you 10 k€ if ASI happens until the end of 2028 (slightly after your median, such that you have a positive expected monetary gain).
- Otherwise, you give me 10 k€, which I would donate to animal welfare interventions.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-09-13T00:47:53.740Z · LW(p) · GW(p)
That's better, but the problem remains that I value pre-AGI money much more than I value post-AGI money, and you are offering to give me post-AGI money in exchange for my pre-AGI money (in expectation).
You could instead pay me $10k now, with the understanding that I'll pay you $20k later in 2028 unless AGI has been achieved in which case I keep the money... but then why would I do that when I could just take out a loan for $10k at low interest rate?
I have in fact made several bets like this, totalling around $1k, with 2030 and 2027 as the due date iirc. I imagine people will come to collect from me when the time comes, if AGI hasn't happened yet.
But it wasn't rational for me to do that, I was just doing it to prove my seriousness.
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-11-10T00:03:08.040Z · LW(p) · GW(p)
You could instead pay me $10k now, with the understanding that I'll pay you $20k later in 2028 unless AGI has been achieved in which case I keep the money... but then why would I do that when I could just take out a loan for $10k at low interest rate?
Have you or other people worried about AI taken such loans (e.g. to increase donations to AI safety projects)? If not, why?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-11-10T15:44:52.944Z · LW(p) · GW(p)
Idk about others. I haven't investigated serious ways to do this,* but I've taken the low-hanging fruit -- it's why my family hasn't paid off our student loan debt for example, and it's why I went for financing on my car (with as long a payoff time as possible) instead of just buying it with cash.
*Basically I'd need to push through my ugh field and go do research on how to make this happen. If someone offered me a $10k low-interest loan on a silver platter I'd take it.
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-10-01T09:09:12.137Z · LW(p) · GW(p)
You could instead pay me $10k now, with the understanding that I'll pay you $20k later in 2028 unless AGI has been achieved in which case I keep the money... but then why would I do that when I could just take out a loan for $10k at low interest rate?
We could set up the bet such that it would involve you losing/gaining no money in expectation under your views, whereas you would lose money in expectation with a loan? Also, note the bet I proposed above was about ASI as defined by Metaculus, not AGI.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-10-01T23:40:31.248Z · LW(p) · GW(p)
I gain money in expectation with loans, because I don't expect to have to pay them back. What specific bet are you offering?
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-10-02T07:34:30.600Z · LW(p) · GW(p)
I gain money in expectation with loans, because I don't expect to have to pay them back.
I see. I was implicitly assuming a nearterm loan or one with an interest rate linked to economic growth, but you might be able to get a longterm loan with a fixed interest rate.
What specific bet are you offering?
I transfer 10 k today-€ to you now, and you transfer 20 k today-€ to me if there is no ASI as defined by Metaculus on date X, which has to be sufficiently far away for the bet to be better than your best loan. X could be 12.0 years (= LN(0.9*20*10^3/(10*10^3))/LN(1 + 0.050)) from now assuming a 90 % chance I win the bet, and an annual growth of my investment of 5.0 %. However, if the cost-effectiveness of my donations also decreases 5 %, then I can only go as far as 6.00 years (= 12.0/2).
I also guess the stock market will grow faster than suggested by historical data, so I would only want to have X roughly as far as in 2028. So, at the end of the day, it looks like you are right that you would be better off getting a loan.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-10-06T17:17:17.359Z · LW(p) · GW(p)
Thanks for doing the math on this and changing your mind! <3
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-04T07:13:43.466Z · LW(p) · GW(p)
You are welcome!
I also guess the stock market will grow faster than suggested by historical data, so I would only want to have X roughly as far as in 2028.
Here is a bet which would be worth it for me even with more distant resolution dates. If, until the end of 2028, Metaculus' question about ASI:
- Resolves with a given date, I transfer to you 10 k 2025-January-$.
- Does not resolve, you transfer to me 10 k 2025-January-$.
- Resolves ambiguously, nothing happens.
This bet involves fixed prices, so I think it would be neutral for you in terms of purchasing power right after resolution if you had the end of 2028 as your median date of ASI. I would transfer you nominally more money if you won than you nominally would transfer to me if I won, as there would tend to be more inflation if you won. I think mid 2028 was your median date of ASI, so the bet resolving at the end of 2028 may make it worth it for you. If not, it can be moved forward. It would still be the case that the purchasing power of a nominal amount of money would decrease faster after resolution if you won than if I did. However, you could mitigate this by investing your profits from the bet if you win.
The bet may still be worse than some loans, but you can always make the bet and ask for such loans?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-04T15:58:10.231Z · LW(p) · GW(p)
I think I still don't understand, sorry. Does "today" refer to the date the metaculus question resolves, or to today? What does today-$ mean?
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-04T16:26:35.875Z · LW(p) · GW(p)
Sorry for the lack of clarity! "today-$" refers to January 2025. For example, assuming prices increased by 10 % from this month until December 2028, the winner would receive 11 k$ (= 10*10^3*(1 + 0.1)).
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-09-13T14:52:06.226Z · LW(p) · GW(p)
Thanks, Daniel. That makes sense.
But it wasn't rational for me to do that, I was just doing it to prove my seriousness.
My offer was also in this spirit of you proving your seriousness. Feel free to suggest bets which would be rational for you to take. Do you think there is a significant risk of a large AI catastrophe in the next few years? For example, what do you think is the probability of human population decreasing from (mid) 2026 to (mid) 2027?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-09-13T18:14:01.248Z · LW(p) · GW(p)
You are basically asking me to give up money in expectation to prove that I really believe what I'm saying, when I've already done literally this multiple times. (And besides, hopefully it's pretty clear that I am serious from my other actions.) So, I'm leaning against doing this, sorry. If you have an idea for a bet that's net-positive for me I'm all ears.
Yes I do think there's a significant risk of large AI catastrophe in the next few years. To answer your specific question, maybe something like 5%? idk.
Replies from: vascoamaralgrilo, IlluminateReality↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-10-06T16:49:17.802Z · LW(p) · GW(p)
If you have an idea for a bet that's net-positive for me I'm all ears.
Are you much higher than Metaculus' community on Will ARC find that GPT-5 has autonomous replication capabilities??
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-10-06T17:21:44.216Z · LW(p) · GW(p)
Good question. I guess I'm at 30%, so 2x higher? Low confidence haven't thought about it much, there's a lot of uncertainty about what METR/ARC will classify as success, and I also haven't reread ARC/METR's ARA eval to remind myself of how hard it is.
↑ comment by IlluminateReality · 2024-09-13T19:33:33.788Z · LW(p) · GW(p)
Have your probabilities for AGI on given years changed at all since this breakdown you gave 7 months ago? I, and I’m sure many others, defer quite a lot to your views on timelines, so it would be good to have an updated breakdown.
15% - 2024
15% - 2025
15% - 2026
10% - 2027
5% - 2028
5% - 2029
3% - 2030
2% - 2031
2% - 2032
2% - 2033
2% - 2034
2% - 2035
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-09-14T23:31:10.571Z · LW(p) · GW(p)
My 2024 probability has gone down from 15% to 5%. Other than that things are pretty similar, so just renormalize I guess.
↑ comment by habryka (habryka4) · 2024-09-11T16:51:48.745Z · LW(p) · GW(p)
I am not Daniel, but why would "constant growth" make any sense under Daniel's worldview? The whole point is that AI can achieve explosive growth, and right now energy consumption growth is determined by human growth, not AI growth, so it seems extremely unlikely for growth between now and then to be constant.
↑ comment by ryan_greenblatt · 2024-09-11T16:21:53.370Z · LW(p) · GW(p)
Daniel almost surely doesn't think growth will be constant. (Presumably he has a model similar to the one here [LW · GW].) I assume he also thinks that by the time energy production is >10x higher, the world has generally been radically transformed by AI.
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2024-09-11T17:13:29.928Z · LW(p) · GW(p)
Thanks, Ryan.
Daniel almost surely doesn't think growth will be constant. (Presumably he has a model similar to the one here [LW · GW].)
That makes senes. Daniel, my terms are flexible. Just let me know what is your median fraction for 2027, and we can go from there.
I assume he also thinks that by the time energy production is >10x higher, the world has generally been radically transformed by AI.
Right. I think the bet is roughly neutral with respect to monetary gains under Daniel's view, but Daniel may want to go ahead despite that to show that he really endorses his views. Not taking the bet may suggest Daniel is worried about losing 10 k€ in a world where 10 k€ is still relevant.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-09-11T23:35:14.094Z · LW(p) · GW(p)
I'm not sure I understand. You and I, as far as I know, have the same beliefs about world energy consumption in 2027, at least on our median timelines. I think it could be higher, but only if AGI timelines are a lot shorter than I think and takeoff is a lot faster than I think. And in those worlds we probably won't be around to resolve the bet in 2027, nor would I care much about winning that bet anyway. (Money post-singularity will be much less valuable to me than money before the singularity)
comment by ryan_greenblatt · 2025-01-07T02:13:54.975Z · LW(p) · GW(p)
My sense is that this post holds up pretty well. Most of the considerations under discussion still appear live and important including: in-context learning, robustness, whether jank AI R&D accelerating AIs can quickly move to more general and broader systems, and general skepticism of crazy conclusions.
At the time of this dialogue, my timelines were a bit faster than Ajeya's. I've updated toward the views Daniel expresses here and I'm now about half way between Ajeya's views in this post and Daniel's (in geometric mean).
My read is that Daniel looks somewhat too aggressive in his predictions for 2024, though it is a bit unclear exactly what he was expecting. (This concrete scenario [LW · GW] seems substantially more bullish than what we've seen in 2024, but not by a huge amount. It's unclear if he was intending these to be mainline predictions or a 25th percentile bullish scenario.)
AI progress appears substantially faster than the scenario outlined in Ege's median world [LW · GW]. In particular:
- On "we have individual AI labs in 10 years that might be doing on the order of e.g. $30B/yr in revenue". OpenAI made $4 billion in revenue in 2024 and based on historical trends it looks like AI company revenue goes up 3x per year such that in 2026 the naive trend extrapolation indicates they'd make around $30 billion. So, this seems 3 years out instead of 10.
- On "maybe AI systems can get gold on the IMO in five years". We seem likely to see gold on IMO this year (a bit less than 2 years later).
It would be interesting to hear how Daniel, Ajeya, and Ege's views have changed since the time this was posted. (I think Daniel has somewhat later timelines (but the update is smaller than the progression of time such that AGI now seems closer to Daniel) and I think Ajeya has somewhat sooner timelines.)
Daniel discusses various ideas for how to do a better version of this dialogue in this comment [LW(p) · GW(p)]. My understanding is that Daniel (and others) have run something similar to what he describes multiple times and participants find this valuable. I'm not sure how much people have actually changed their mind. Prototyping this approach for Daniel is plausibly the most important impact of this dialogue.
Replies from: ajeya-cotra, daniel-kokotajlo, ege-erdil, Mathieu Putz↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T18:55:21.752Z · LW(p) · GW(p)
I agree the discussion holds up well in terms of the remaining live cruxes. Since this exchange, my timelines have gotten substantially shorter. They're now pretty similar to Ryan's (they feel a little bit slower but within the noise from operationalizations being fuzzy; I find it a bit hard to think about what 10x labor inputs exactly looks like).
The main reason they've gotten shorter is that performance on few-hour agentic tasks has moved almost twice as fast as I expected, and this seems broadly non-fake (i.e. it seems to be translating into real world use with only a moderate lag rather than a huge lag), though this second part is noisier and more confusing.
This dialogue occurred a few months after METR released their pilot report on autonomous replication and adaptation tasks. At the time it seemed like agents (GPT-4 and Claude 3 Sonnet iirc) were starting to be able to do tasks that would take a human a few minutes (looking something up on Wikipedia, making a phone call, searching a file system, writing short programs).
Right around when I did this dialogue, I launched an agent benchmarks RFP to build benchmarks testing LLM agents on many-step real-world tasks. Through this RFP, in late-2023 and early-2024, we funded a bunch of agent benchmarks consisting of tasks that take experts between 15 minutes and a few hours.
Roughly speaking, I was expecting that the benchmarks we were funding would get saturated around early-to-late 2026 (within 2-3 years). By EOY 2024 (one year out), I had expected these benchmarks to be halfway toward saturation — qualitatively I guessed that agents would be able to reliably perform moderately difficult 30 minute tasks as well as experts in a variety of domains but struggle with the 1-hour-plus tasks. This would have roughly been the same trajectory that the previous generation of benchmarks followed: e.g. MATH was introduced in Jan 2021, got halfway there in June 2022 (1.5 years), then saturated probably like another year after that (for a total of 2.5 years).
Instead, based on agent benchmarks like RE Bench and CyBench and SWE Bench Verified and various bio benchmarks, it looks like agents are already able to perform self-contained programming tasks that would take human experts multiple hours (although they perform these tasks in a more one-shot way than human experts perform them, and I'm sure there is a lot of jaggedness); these benchmarks seem on track to saturate by early 2025. If that holds up, it'd be about twice as fast as I would have guessed (1-1.5 years vs 2-3 years).
There's always some lag between benchmark performance and real world use, and it's very hard for me to gauge this lag myself because it seems like AI agents are way disproportionately useful to programmers and ML engineers compared to everyone else. But from friends who use AI systems regularly, it seems like they are regularly assigning agents tasks that would take them between a few minutes and an hour and getting actual value out of them.
On a meta level I now defer heavily to Ryan and people in his reference class (METR and Redwood engineers) on AI timelines, because they have a similarly deep understanding of the conceptual arguments I consider most important while having much more hands-on experience with the frontier of useful AI capabilities (I still don't use AI systems regularly in my work). Of course AI company employees have the most hands-on experience, but I've found that they don't seem to think as rigorously about the conceptual arguments, and some of them have a track record of overshooting and predicting AGI between 2020 and 2025 (as you might expect from their incentives and social climate).
Replies from: ajeya-cotra, Buck, maxnadeau↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T19:12:05.998Z · LW(p) · GW(p)
One thing that I think is interesting, which doesn't affect my timelines that much but cuts in the direction of slower: once again I overestimated how much real world use anyone who wasn't a programmer would get. I definitely expected an off-the-shelf agent product that would book flights and reserve restaurants and shop for simple goods, one that worked well enough I would actually use it (and I expected that to happen before the one hour plus coding tasks were solved; I expected it to be concurrent with half hour coding tasks).
I can't tell if the fact that AI agents continue to be useless to me is a portent that the incredible benchmark performance won't translate as well as the bullish people expect to real world acceleration; I'm largely deferring to the consensus in my local social circle that it's not a big deal. My personal intuitions are somewhat closer to what Steve Newman describes in this comment thread [LW(p) · GW(p)].
It seems like anecdotally folks are getting like +5%-30% productivity boost from using AI; it does feel somewhat aggressive for that to go to 10x productivity boost within a couple years.
↑ comment by Buck · 2025-01-07T20:53:13.839Z · LW(p) · GW(p)
Of course AI company employees have the most hands-on experience
FWIW I am not sure this is right--most AI company employees work on things other than "try to get as much work as possible from current AI systems, and understand the trajectory of how useful the AIs will be". E.g. I think I have more personal experience with running AI agents than people at AI companies who don't actively work on AI agents.
There are some people at AI companies who work on AI agents that use non-public models, and those people are ahead of the curve. But that's a minority.
Replies from: ajeya-cotra↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T20:57:31.991Z · LW(p) · GW(p)
Yeah, good point, I've been surprised by how uninterested the companies have been in agents.
Replies from: Buck↑ comment by Buck · 2025-01-07T21:43:52.809Z · LW(p) · GW(p)
Another effect here is that the AI companies often don't want to be as reckless as I am, e.g. letting agents run amok on my machines.
Replies from: ajeya-cotra, tao-lin↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T22:47:39.883Z · LW(p) · GW(p)
Interestingly, I've heard from tons of skeptics I've talked to (e.g. Tim Lee, CSET people, AI Snake Oil) that timelines to actual impacts in the world (such as significant R&D acceleration or industrial acceleration) are going to be way longer than we say because AIs are too unreliable and risky, therefore people won't use them. I was more dismissive of this argument before but:
- It matches my own lived experience (e.g. I still use search way more than LLMs, even to learn about complex topics, because I have good Google Fu and LLMs make stuff up too much).
- As you say, it seems like a plausible explanation for why my weird friends make way more use out of coding agents than giant AI companies.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-07T23:08:38.541Z · LW(p) · GW(p)
I tentatively remain dismissive of this argument. My claim was never "AIs are actually reliable and safe now" such that your lived experience would contradict it. I too predicted that AIs would be unreliable and risky in the near-term. My prediction is that after the intelligence explosion the best AIs will be reliable and safe (insofar as they want to be, that is.)
...I guess just now I was responding to a hypothetical interlocutor who agrees that AI R&D automation could come soon but thinks that that doesn't count as "actual impacts in the world." I've met many such people, people who think that software-only singularity is unlikely, people who like to talk about real-world bottlenecks, etc. But you weren't describing such a person, you were describing someone who also thinks we won't be able to automate AI R&D for a long time.
There I'd say... well, we'll see. I agree that AIs are unreliable and risky and that therefore they'll be able to do impressive-seeming stuff that looks like they could automate AI R&D well before they actually automate AI R&D in practice. But... probably by the end of 2025 they'll be hitting that first milestone (imagine e.g. an AI that crushes RE-Bench and also can autonomously research & write ML papers, except the ML papers are often buggy and almost always banal / unimportant, and the experiments done to make them had a lot of bugs and wasted compute, and thus AI companies would laugh at the suggestion of putting said AI in charge of a bunch of GPUs and telling it to cook.) And then two years later maybe they'll be able to do it for real, reliably, in practice, such that AGI takeoff happens.
Maybe another thing I'd say is "One domain where AIs seem to be heavily used in practice, is coding, especially coding at frontier AI companies (according to friends who work at these companies and report fairly heavy usage). This suggests that AI R&D automation will happen more or less on schedule."
↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T23:17:26.367Z · LW(p) · GW(p)
I'm not talking about narrowly your claim; I just think this very fundamentally confuses most people's basic models of the world. People expect, from their unspoken models of "how technological products improve," that long before you get a mind-bendingly powerful product that's so good it can easily kill you, you get something that's at least a little useful to you (and then you get something that's a little more useful to you, and then something that's really useful to you, and so on). And in fact that is roughly how it's working — for programmers, not for a lot of other people.
Because I've engaged so much with the conceptual case for an intelligence explosion (i.e. the case that this intuitive model of technology might be wrong), I roughly buy it even though I am getting almost no use out of AIs still. But I have a huge amount of personal sympathy for people who feel really gaslit by it all.
↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T23:23:02.636Z · LW(p) · GW(p)
To put it another way: we probably both agree that if we had gotten AI personal assistants that shop for you and book meetings for you in 2024, that would have been at least some evidence for shorter timelines. So their absence is at least some evidence for longer timelines. The question is what your underlying causal model was: did you think that if we were going to get superintelligence by 2027, then we really should see personal assistants in 2024? A lot of people strongly believe that, you (Daniel) hardly believe it at all, and I'm somewhere in the middle.
If we had gotten both the personal assistants I was expecting, and the 2x faster benchmark progress than I was expecting, my timelines would be the same as yours are now.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-08T00:10:55.721Z · LW(p) · GW(p)
That's reasonable. Seems worth mentioning that I did make predictions in What 2026 Looks Like [LW · GW], and eyeballing them now I don't think I was saying that we'd have personal assistants that shop for you and book meetings for you in 2024, at least not in a way that really works. (I say at the beginning of 2026 "The age of the AI assistant has finally dawned.") In other words I think even in 2021 I was thinking that widespread actually useful AI assistants would happen about a year or two before superintelligence. (Not because I have opinions about the orderings of technologies in general, but because I think that once an AGI company has had a popular working personal assistant for two years they should be able to figure out how to make a better version that dramatically speeds up their R&D.)
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-07T22:55:46.000Z · LW(p) · GW(p)
Indeed, I believe this is the main explanation for why my median timelines are longer than say situational awareness, and why AI isn't nearly as impactful as people used to think back in the day.
The big difference from a lot of skeptics is I believe this adds at most 1-2 decades to the timeline, not multiple decades to make AI very, very useful.
Replies from: ajeya-cotra↑ comment by Ajeya Cotra (ajeya-cotra) · 2025-01-07T23:05:34.261Z · LW(p) · GW(p)
Yeah TBC, I'm at even less than 1-2 decades added, more like 1-5 years.
↑ comment by Tao Lin (tao-lin) · 2025-01-07T22:00:26.644Z · LW(p) · GW(p)
i've recently done more AI agents running amok and i've found Claude was actually more aligned and did stuff i asked it not to much less than oai models enough that it actaully made a difference lol
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-07T22:56:09.351Z · LW(p) · GW(p)
lol what? Can you compile/summarize a list of examples of AI agents running amok in your personal experience? To what extent was it an alignment problem vs. a capabilities problem?
Replies from: tao-lin↑ comment by Tao Lin (tao-lin) · 2025-01-08T00:36:25.547Z · LW(p) · GW(p)
not running amock, just not reliably following instructions "only modify files in this folder" or "don't install pip packages". Claude follows instructions correctly, some other models are mode collapsed into a certain way of doing things, eg gpt-4o always thinks it's running python in chatgpt code interpreter and you need very strong prompting to make it behave in a way specific to your computer
Replies from: tao-lin↑ comment by Tao Lin (tao-lin) · 2025-01-08T00:43:50.798Z · LW(p) · GW(p)
a hypothetical typical example would be it tries to use the file /usr/bin/python because it's memorized that that's the path to python, that fails, then it concludes it must create that folder which would require sudo permissions, if it can it could potentially mess something
↑ comment by maxnadeau · 2025-01-08T01:31:06.388Z · LW(p) · GW(p)
You mentioned CyBench here. I think CyBench provides evidence against the claim "agents are already able to perform self-contained programming tasks that would take human experts multiple hours". AFAIK, the most up-to-date CyBench run is in the joint AISI o1 evals. In this study (see Table 4.1, and note the caption), all existing models (other than o3, which was not evaluated here) succeed on 0/10 attempts at almost all the Cybench tasks that take >40 minutes for humans to complete.
Replies from: elifland↑ comment by elifland · 2025-01-08T01:40:32.789Z · LW(p) · GW(p)
I believe Cybench first solve times are based on the fastest top professional teams, rather than typical individual CTF competitors or cyber employees, for which the time to complete would probably be much higher (especially for the latter).
Replies from: maxnadeau↑ comment by maxnadeau · 2025-01-08T01:50:24.382Z · LW(p) · GW(p)
Do you think that cyber professionals would take multiple hours to do the tasks with 20-40 min first-solve times? I'm intuitively skeptical.
One (edit: minor) component of my skepticism is that someone told me that the participants in these competitions are less capable than actual cyber professionals, because the actual professionals have better things to do than enter competitions. I have no idea how big that selection effect is, but it at least provides some countervailing force against the selection effect you're describing.
Replies from: elifland, neel-nanda-1↑ comment by elifland · 2025-01-08T01:55:32.837Z · LW(p) · GW(p)
Do you think that cyber professionals would take multiple hours to do the tasks with 20-40 min first-solve times? I'm intuitively skeptical.
Yes, that would be my guess, medium confidence.
One component of my skepticism is that someone told me that the participants in these competitions are less capable than actual cyber professionals, because the actual professionals have better things to do than enter competitions. I have no idea how big that selection effect is, but it at least provides some countervailing force against the selection effect you're describing.
I'm skeptical of your skepticism. Not knowing basically anything about the CTF scene but using the competitive programming scene as an example, I think the median competitor is much more capable than the median software engineering professional, not less. People like competing at things they're good at.
↑ comment by Neel Nanda (neel-nanda-1) · 2025-01-09T15:54:26.375Z · LW(p) · GW(p)
I don't know much about CTF specifically, but based on my maths exam/olympiad experience I predict that there's a lot of tricks to go fast (common question archetypes, saved code snippets, etc) that will be top of mind for people actively practicing, but not for someone with a lot of domain expertise who doesn't explicitly practice CTF. I also don't know how important speed is for being a successful cyber professional. They might be able to get some of this speed up with a bit of practice, but I predict by default there's a lot of room for improvement.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-07T05:12:23.885Z · LW(p) · GW(p)
That concrete scenario was NOT my median prediction. Sorry, I should have made that more clear at the time. It was genuinely just a thought experiment for purposes of eliciting people's claims about how they would update on what kinds of evidence. My median AGI timeline at the time was 2027 (which is not that different from the scenario, to be clear! Just one year delayed basically.)
To answer your other questions:
--My views haven't changed much. Performance on the important benchmarks (agency tasks such as METR's RE-Bench) has been faster than I expected for 2024, but the cadence of big new foundation models seems to be slower than I expected (no GPT-5; pretraining scaling is slowing down due to data wall apparently? I thought that would happen more around GPT-6 level). I still have 2027 as my median year for AGI.
--Yes, I and others have run versions of that exercise several times now and yes people have found it valuable. The discussion part, people said, was less valuable than the "force yourself to write out your median scenario" part, so in more recent iterations we mostly just focused on that part.
↑ comment by Ege Erdil (ege-erdil) · 2025-03-10T01:44:07.841Z · LW(p) · GW(p)
I think overall things have been moving faster than I've expected, though only in some dimensions than others. The point about revenue is particularly salient to me and I would now put the complete automation of remotable jobs 30 years out in my median world instead of 40 years out.
Progress on long context coherence, agency, executive function, etc. remains fairly "on trend" despite the acceleration of progress in reasoning and AI systems currently being more useful than I expected, so I don't update down by 2x or 3x (which is more like the speedup we've seen relative to my math or revenue growth expectations).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-10T15:52:25.936Z · LW(p) · GW(p)
So your median for the complete automation of remotable jobs is 2055?
What about for the existence of AI systems which can completely automate AI software R&D? (So, filling the shoes of the research engineers and research scientists etc. at DeepMind, the members of technical staff at OpenAI, etc.)
What about your 10th percentile, instead of your median?
Progress on long context coherence, agency, executive function, etc. remains fairly "on trend" despite the acceleration of progress in reasoning and AI systems currently being more useful than I expected, so I don't update down by 2x or 3x (which is more like the speedup we've seen relative to my math or revenue growth expectations).
According to METR, if I recall correctly, 50%-horizon length of LLM-based AI systems has been doubling roughly every 200 days for several years, and seems to if anything be accelerating recently. And it's already at 40 minutes. So in, idk, four years, if trends continue, AIs should be able to show up and do a day's work of autonomous research or coding as well as professional humans.* (And that's assuming an exponential trend, whereas it'll have to be superexponential eventually. Though of course investment in AI scaling will also be petering out in a few years maybe.)
*A caveat here is that their definition is not "For tasks humans do that take x duration, AI can do them just as well" but rather "For tasks AIs can do with 50% reliability, humans take x duration to do them" which feels different and worse to me in ways I should think about more.
↑ comment by Matt Putz (Mathieu Putz) · 2025-01-07T15:07:32.929Z · LW(p) · GW(p)
I've updated toward the views Daniel expresses here and I'm now about half way between Ajeya's views in this post and Daniel's (in geometric mean).
I'm curious what the biggest factors were that made you update?
Replies from: ryan_greenblattcomment by snewman · 2023-11-15T01:16:28.086Z · LW(p) · GW(p)
This post taught me a lot about different ways of thinking about timelines, thanks to everyone involved!
I’d like to offer some arguments that, contra Daniel’s view, AI systems are highly unlikely to be able to replace 99% of current fully remote jobs anytime in the next 4 years. As a sample task, I’ll reference software engineering projects that take a reasonably skilled human practitioner one week to complete. I imagine that, for AIs to be ready for 99% of current fully remote jobs, they would need to be able to accomplish such a task. (That specific category might be less than 1% of all remote jobs, but I imagine that the class of remote jobs requiring at least this level of cognitive ability is more than 1%.)
Rather than referencing scaling laws, my arguments stem from analysis of two specific mechanisms which I believe are missing from current LLMs:
- Long-term memory. LLMs of course have no native mechanism for retaining new information beyond the scope of their token buffer. I don’t think it is possible to carry out a complex extended task, such as a week-long software engineering project, without long-term memory to manage the task, keep track of intermediate thoughts regarding design approaches, etc.
- Iterative / exploratory work processes. The LLM training process focuses on producing final work output in a single pass, with no planning process, design exploration, intermediate drafts, revisions, etc. I don’t think it is possible to accomplish a week-long software engineering task in a single pass; at least, not without very strongly superhuman capabilities (unlikely to be reached in just four years).
Of course there are workarounds for each of these issues, such as RAG for long-term memory, and multi-prompt approaches (chain-of-thought, tree-of-thought, AutoGPT, etc.) for exploratory work processes. But I see no reason to believe that they will work sufficiently well to tackle a week-long project. Briefly, my intuitive argument is that these are old school, rigid, GOFAI, Software 1.0 sorts of approaches, the sort of thing that tends to not work out very well in messy real-world situations. Many people have observed that even in the era of GPT-4, there is a conspicuous lack of LLMs accomplishing any really meaty creative work; I think these missing capabilities lie at the heart of the problem.
Nor do I see how we could expect another round or two of scaling to introduce the missing capabilities. The core problem is that we don’t have massive amounts of training data for managing long-term memory or carrying out exploratory work processes. Generating such data at the necessary scale, if it’s even possible, seems much harder than what we’ve been doing up to this point to marshall training data for LLMs.
The upshot is that I think that we have been seeing the rapid increase in capabilities of generative AI, failing to notice that this progress is confined to a particular subclass of tasks – namely, tasks which can pretty much be accomplished using System 1 alone – and collectively fooling ourselves into thinking that the trend of increasing capabilities is going to quickly roll through the remainder of human capabilities. In other words, I believe the assertion that the recent rate of progress will continue up through AGI is based on an overgeneralization. For an extended version of this claim, see a post I wrote a few months ago: The AI Progress Paradox. I've also written at greater length about the issues of Long-term memory and Exploratory work processes.
In the remainder of this comment, I’m going to comment what I believe are some weak points in the argument for short timelines (as presented in the original post).
[Daniel] It seems to me that GPT-4 is already pretty good at coding, and a big part of accelerating AI R&D seems very much in reach -- like, it doesn't seem to me like there is a 10-year, 4-OOM-training-FLOP gap between GPT4 and a system which is basically a remote-working OpenAI engineer that thinks at 10x serial speed.
Coding, in the sense that GPT4 can do it, is nowhere near the top of the hierarchy of skills involved in serious software engineering. And so I believe this is a bit like saying that, because a certain robot is already pretty decent at chiseling, it will soon be able to produce works of art at the same level as any human sculptor.
[Ajeya] I don't know, 4 OOM is less than two GPTs, so we're talking less than GPT-6. Given how consistently I've been wrong about how well "impressive capabilities in the lab" will translate to "high economic value" since 2020, this seems roughly right to me?
[Daniel] I disagree with this update -- I think the update should be "it takes a lot of schlep and time for the kinks to be worked out and for products to find market fit" rather than "the systems aren't actually capable of this." Like, I bet if AI progress stopped now, but people continued to make apps and widgets using fine-tunes of various GPTs, there would be OOMs more economic value being produced by AI in 2030 than today.
If the delay in real-world economic value were due to “schlep”, shouldn’t we already see one-off demonstrations of LLMs performing economically-valuable-caliber tasks in the lab? For instance, regarding software engineering, maybe it takes a long time to create a packaged product that can be deployed in the field, absorb the context of a legacy codebase, etc. and perform useful high-level work. But if that’s the only problem, shouldn’t there already be at least one demonstration of an LLM doing some meaty software engineering project in a friendly lab environment somewhere?
More generally, how do we define “schlep” such that the need for schlep explains the lack of visible accomplishments today, but also allows for AI systems be able to replace 99% of remote jobs within just four years?
[Daniel] And so I think that the AI labs will be using AI remote engineers much sooner than the general economy will be. (Part of my view here is that around the time it is capable of being a remote engineer, the process of working out the kinks / pushing through schlep will itself be largely automatable.)
What is your definition of “schlep”? I’d assumed it referred to the innumerable details of figuring out how to adapt and integrate a raw LLM into a finished product which can handle all of the messy requirements of real-world use cases – the “last mile” of unspoken requirements and funky edge cases. Shouldn’t we expect such things to be rather difficult to automate? Or do you mean something else by “schlep”?
[Daniel] …when I say 2027 as my median, that's kinda because I can actually quite easily see it happening in 2025, but things take longer than I expect, so I double it.
Can you see LLMs acquiring long-term memory and an expert-level, nuanced ability to carry out extended exploratory processes by 2025? If yes, how do you see that coming about? If no, does that cause you to update at all?
[Daniel] I take it that in this scenario, despite getting IMO gold etc. the systems of 2030 are not able to do the work of today's OAI engineer? Just clarifying. Can you say more about what goes wrong when you try to use them in such a role?
Anecdote: I got IMO silver (granted, not gold) twice, in my junior and senior years of high school. At that point I had already been programming for close to ten years, and spent considerably more time coding than I spent studying math, but I would not have been much of an asset to an engineering team. I had no concept of how to plan a project, organize a codebase, design maintainable code, strategize a debugging session, evaluate tradeoffs, see between the lines of a poorly written requirements document, etc. Ege described it pretty well:
I think when you try to use the systems in practical situations; they might lose coherence over long chains of thought, or be unable to effectively debug non-performant complex code, or not be able to have as good intuitions about which research directions would be promising, et cetera.
This probably underestimates the degree to which IMO-silver-winning me would have struggled. For instance, I remember really struggling to debug binary tree rotation (a fairly simple bit of data-structure-and-algorithm work) for a college class, almost 2.5 years after my first silver.
[Ajeya] I think by the time systems are transformative enough to massively accelerate AI R&D, they will still not be that close to savannah-to-boardroom level transfer, but it will be fine because they will be trained on exactly what we wanted them to do for us.
This assumes we’re able to train them on exactly what we want them to do. It’s not obvious to me how we would train a model to do, for example, high-level software engineering? (In any case, I suspect that this is not far off from being AGI-complete; I would suspect the same of high-level work in most fields; see again my earlier-linked post on the skills involved in engineering.)
[Daniel] …here's a scenario I think it would be productive to discuss:
(1) Q1 2024: A bigger, better model than GPT-4 is released by some lab. It's multimodal; it can take a screenshot as input and output not just tokens but keystrokes and mouseclicks and images. Just like with GPT-4 vs. GPT-3.5 vs. GPT-3, it turns out to have new emergent capabilities. Everything GPT-4 can do, it can do better, but there are also some qualitatively new things that it can do (though not super reliably) that GPT-4 couldn't do.
…
(6) Q3 2026 Superintelligent AGI happens, by whatever definition is your favorite. And you see it with your own eyes.
I realize you’re not explicitly labeling this as a prediction, but… isn’t this precisely the sort of thought process to which Hofstadter's Law applies?
Replies from: daniel-kokotajlo, Vladimir_Nesov, elityre↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-18T05:30:20.917Z · LW(p) · GW(p)
Thanks for this thoughtful and detailed and object-level critique! Just the sort of discussion I hope to inspire. Strong-upvoted.
Here are my point-by-point replies:
Of course there are workarounds for each of these issues, such as RAG for long-term memory, and multi-prompt approaches (chain-of-thought, tree-of-thought, AutoGPT, etc.) for exploratory work processes. But I see no reason to believe that they will work sufficiently well to tackle a week-long project. Briefly, my intuitive argument is that these are old school, rigid, GOFAI, Software 1.0 sorts of approaches, the sort of thing that tends to not work out very well in messy real-world situations. Many people have observed that even in the era of GPT-4, there is a conspicuous lack of LLMs accomplishing any really meaty creative work; I think these missing capabilities lie at the heart of the problem.
I agree that if no progress is made on long-term memory and iterative/exploratory work processes, we won't have AGI. My position is that we are already seeing significant progress in these dimensions and that we will see more significant progress in the next 1-3 years. (If 4 years from now we haven't seen such progress I'll admit I was totally wrong about something). Maybe part of the disagreement between us is that the stuff you think are mere hacky workarounds, I think might work sufficiently well (with a few years of tinkering and experimentation perhaps).
Wanna make some predictions we could bet on? Some AI capability I expect to see in the next 3 years that you expect to not see?
Coding, in the sense that GPT4 can do it, is nowhere near the top of the hierarchy of skills involved in serious software engineering. And so I believe this is a bit like saying that, because a certain robot is already pretty decent at chiseling, it will soon be able to produce works of art at the same level as any human sculptor.
I think I just don't buy this. I work at OpenAI R&D. I see how the sausage gets made. I'm not saying the whole sausage is coding, I'm saying a significant part of it is, and moreover that many of the bits GPT4 currently can't do seem to me that they'll be doable in the next few years.
If the delay in real-world economic value were due to “schlep”, shouldn’t we already see one-off demonstrations of LLMs performing economically-valuable-caliber tasks in the lab? For instance, regarding software engineering, maybe it takes a long time to create a packaged product that can be deployed in the field, absorb the context of a legacy codebase, etc. and perform useful high-level work. But if that’s the only problem, shouldn’t there already be at least one demonstration of an LLM doing some meaty software engineering project in a friendly lab environment somewhere? More generally, how do we define “schlep” such that the need for schlep explains the lack of visible accomplishments today, but also allows for AI systems be able to replace 99% of remote jobs within just four years?
To be clear, I do NOT think that today's systems could replace 99% of remote jobs even with a century of schlep. And in particular I don't think they are capable of massively automating AI R&D even with a century of schlep. I just think they could be producing, say, at least an OOM more economic value. My analogy here is to the internet; my understanding is that there were a bunch of apps that are super big now (amazon? tinder? twitter?) that were technically feasible on the hardware of 2000, but which didn't just spring into the world fully formed in 2000 -- instead it took time for startups to form, ideas to be built and tested, markets to be disrupted, etc.
I define schlep the same way you do, I think.
What I predict will happen is basically described in the scenario I gave in the OP, though I think it'll probably take slightly longer than that. I don't want to say much detail I'm afraid because it might give the impression that I'm leaking OAI secrets (even though, to be clear, I've had these views since before I joined OAI)
I think when you try to use the systems in practical situations; they might lose coherence over long chains of thought, or be unable to effectively debug non-performant complex code, or not be able to have as good intuitions about which research directions would be promising, et cetera.
This was a nice answer from Ege. My follow up questions would be: Why? I have theories about what coherence is and why current models often lose it over long chains of thought (spoiler: they weren't trained to have trains of thought) and theories about why they aren't already excellent complex-code-debuggers (spoiler: they weren't trained to be) etc. What's your theory for why all the things AI labs will try between now and 2030 to make AIs good at these things will fail? Base models (gpt-3, gpt-4, etc.) aren't out-of-the-box good at being helpful harmless chatbots or useful coding assistants. But with a bunch of tinkering and RLHF, they became good, and now they are used in the real world by a hundred million people a day. Again though I don't want to get into details. I understand you might be skeptical that it can be done but I encourage you to red-team your position, and ask yourself 'how would I do it, if I were an AI lab hell-bent on winning the AGI race?' You might be able to think of some things. And if you can't, I'd love to hear your thoughts on why it's not possible. You might be right.
I realize you’re not explicitly labeling this as a prediction, but… isn’t this precisely the sort of thought process to which Hofstadter's Law applies?
Indeed. Like I said, my timelines are based on a portfolio of different models/worlds; the very short-timelines models/worlds are basically like "look we basically already have the ingredients, we just need to assemble them, here is how to do it..." and the planning fallacy / hofstadter's law 100% applies to this. The 5-year-and-beyond worlds are not like that; they are more like extrapolating trends and saying "sure looks like by 2030 we'll have AIs that are superhuman at X, Y, Z, ... heck all of our current benchmarks. And because of the way generalization/transfer/etc. and ML works they'll probably also be broadly capable at stuff, not just narrowly good at these benchmarks. Hmmm. Seems like that could be AGI." Note the absence of a plan here, I'm just looking at lines on graphs and then extrapolating them and then trying to visualize what the absurdly high values on those graphs mean for fuzzier stuff that isn't being measured yet.
So my timelines do indeed take into account Hofstadter's Law. If I wasn't accounting for it already, my median would be lower than 2027. However, I am open to the criticism that maybe I am not accounting for it enough. However I am NOT open to the criticism that I should e.g. add 10 years to my timelines because of this. For reasons just explained. It's a sort of "double or triple how long you think it'll take to complete the plan" sort of thing, not a "10x how long you think it'll take to complete the plan" sort of thing, and even if it was, then I'd just ditch the plan and look at the graphs.
↑ comment by snewman · 2023-11-20T22:12:08.801Z · LW(p) · GW(p)
Likewise, thanks for the thoughtful and detailed response. (And I hope you aren't too impacted by current events...)
I agree that if no progress is made on long-term memory and iterative/exploratory work processes, we won't have AGI. My position is that we are already seeing significant progress in these dimensions and that we will see more significant progress in the next 1-3 years. (If 4 years from now we haven't seen such progress I'll admit I was totally wrong about something). Maybe part of the disagreement between us is that the stuff you think are mere hacky workarounds, I think might work sufficiently well (with a few years of tinkering and experimentation perhaps).
Wanna make some predictions we could bet on? Some AI capability I expect to see in the next 3 years that you expect to not see?
Sure, that'd be fun, and seems like about the only reasonable next step on this branch of the conversation. Setting good prediction targets is difficult, and as it happens I just blogged about this. Off the top of my head, predictions could be around the ability of a coding AI to work independently over an extended period of time (at which point, it is arguably an "engineering AI"). Two different ways of framing it:
- An AI coding assistant can independently complete 80% of real-world tasks that would take X amount of time for a reasonably skilled engineer who is already familiar with the general subject matter and the project/codebase to which the task applies.
- An AI coding assistant can usefully operate independently for X amount of time, i.e. it is often productive to assign it a task and allow it to process for X time before checking in on it.
At first glance, (1) strikes me as a better, less-ambiguous framing. Of course it becomes dramatically more or less ambitious depending on X, also the 80% could be tweaked but I think this is less interesting (low percentages allow for a fluky, unreliable AI to pass the test; very high percentages seem likely to require superhuman performance in a way that is not relevant to what we're trying to measure here).
It would be nice to have some prediction targets that more directly get at long-term memory and iterative/exploratory work processes, but as I discuss in the blog post, I don't know how to construct such a target – open to suggestions.
Coding, in the sense that GPT4 can do it, is nowhere near the top of the hierarchy of skills involved in serious software engineering. And so I believe this is a bit like saying that, because a certain robot is already pretty decent at chiseling, it will soon be able to produce works of art at the same level as any human sculptor.
I think I just don't buy this. I work at OpenAI R&D. I see how the sausage gets made. I'm not saying the whole sausage is coding, I'm saying a significant part of it is, and moreover that many of the bits GPT4 currently can't do seem to me that they'll be doable in the next few years.
Intuitively, I struggle with this, but you have inside data and I do not. Maybe we just set this point aside for now, we have plenty of other points we can discuss.
To be clear, I do NOT think that today's systems could replace 99% of remote jobs even with a century of schlep. And in particular I don't think they are capable of massively automating AI R&D even with a century of schlep. I just think they could be producing, say, at least an OOM more economic value. ...
This, I would agree with. And on re-reading, I think I may have been mixed up as to what you and Ajeya were saying in the section I was quoting from here, so I'll drop this.
[Ege] I think when you try to use the systems in practical situations; they might lose coherence over long chains of thought, or be unable to effectively debug non-performant complex code, or not be able to have as good intuitions about which research directions would be promising, et cetera.
This was a nice answer from Ege. My follow up questions would be: Why? I have theories about what coherence is and why current models often lose it over long chains of thought (spoiler: they weren't trained to have trains of thought) and theories about why they aren't already excellent complex-code-debuggers (spoiler: they weren't trained to be) etc. What's your theory for why all the things AI labs will try between now and 2030 to make AIs good at these things will fail?
I would not confidently argue that it won't happen by 2030; I am suggesting that these problems are unlikely to be well solved in a usable-in-the-field form by 2027 (four years from now). My thinking:
- The rapid progress in LLM capabilities has been substantially fueled by the availability of stupendous amounts of training data.
- There is no similar abundance of low-hanging training data for extended (day/week/more) chains of thought, nor for complex debugging tasks. Hence, it will not be easy to extend LLMs (and/or train some non-LLM model) to high performance at these tasks.
- A lot of energy will go into the attempt, which will eventually succeed. But per (2), I think some new techniques will be needed, which will take time to identify, refine, scale, and productize; a heavy lift in four years. (Basically: Hofstadter's Law.)
- Especially because I wouldn't be surprised if complex-code-debugging turns out to be essentially "AGI-complete", i.e. it may require a sufficiently varied mix of exploration, logical reasoning, code analysis, etc. that you pretty much have to be a general AGI to be able to do it well.
I understand you might be skeptical that it can be done but I encourage you to red-team your position, and ask yourself 'how would I do it, if I were an AI lab hell-bent on winning the AGI race?' You might be able to think of some things.
In a nearby universe, I would be fundraising for a startup to do exactly that, it sounds like a hell of fun problem. :-) And I'm sure you're right... I just wouldn't expect to get to "capable of 99% of all remote work" within four years.
I realize you’re not explicitly labeling this as a prediction, but… isn’t this precisely the sort of thought process to which Hofstadter's Law applies?
Indeed. Like I said, my timelines are based on a portfolio of different models/worlds; the very short-timelines models/worlds are basically like "look we basically already have the ingredients, we just need to assemble them, here is how to do it..." and the planning fallacy / hofstadter's law 100% applies to this. The 5-year-and-beyond worlds are not like that; they are ... looking at lines on graphs and then extrapolating them ...
So my timelines do indeed take into account Hofstadter's Law. If I wasn't accounting for it already, my median would be lower than 2027. However, I am open to the criticism that maybe I am not accounting for it enough.
To be clear, I'm only attempting to argue about the short-timeline worlds. I agree that Hofstadter's Law doesn't apply to curve extrapolation. (My intuition for 5-year-and-beyond worlds is more like Ege's, but I have nothing coherent to add to the discussion on that front.) And so, yes, I think my position boils down to "I believe that, in your short-timeline worlds, you are not accounting for Hofstadter's Law enough".
As you proposed, I think the interesting place to go from here would be some predictions. I'll noodle on this, and I'd be very interested to hear any thoughts you have – milestones along the path you envision in your default model of what rapid progress looks like; or at least, whatever implications thereof you feel comfortable talking about.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-22T14:08:49.471Z · LW(p) · GW(p)
Oooh, I should have thought to ask you this earlier -- what numbers/credences would you give for the stages in my scenario sketched in the OP? This might help narrow things down. My guess based on what you've said is that the biggest update for you would be Step 2, because that's when it's clear we have a working method for training LLMs to be continuously-running agents -- i.e. long-term memory and continuous/exploratory work processes.
↑ comment by Vladimir_Nesov · 2023-11-21T16:01:39.053Z · LW(p) · GW(p)
The timelines-relevant milestone of AGI is ability to autonomously research, especially AI's ability to develop AI that doesn't have particular cognitive limitations compared to humans. Quickly giving AIs experience at particular jobs/tasks that doesn't follow from general intelligence alone is probably possible through learning things in parallel or through AIs experimenting with greater serial speed than humans can. Placing that kind of thing into AIs is the schlep that possibly stands in the way of reaching AGI (even after future scaling), and has to be done by humans. But also reaching AGI doesn't require overcoming all important cognitive shortcomings of AIs compared to humans, only those that completely prevent AIs from quickly researching their way into overcoming the rest of the shortcomings on their own.
It's currently unclear if merely scaling GPTs (multimodal LLMs) with just a bit more schlep/scaffolding won't produce a weirdly disabled general intelligence (incapable of replacing even 50% of current fully remote jobs at a reasonable cost or at all) that is nonetheless capable enough to fix its disabilities shortly thereafter, making use of its ability to batch-develop such fixes much faster than humans would, even if it's in some sense done in a monstrously inefficient way and takes another couple giant training runs (from when it starts) to get there. This will be clearer in a few years, after feasible scaling of base GPTs is mostly done, but we are not there yet.
↑ comment by Eli Tyre (elityre) · 2023-11-24T05:16:27.034Z · LW(p) · GW(p)
More generally, how do we define “schlep” such that the need for schlep explains the lack of visible accomplishments today, but also allows for AI systems be able to replace 99% of remote jobs within just four years?
I think a lot of the forecasted schlep is not commercialization, but research and development to get working prototypes. It can be that there are no major ideas that you need to find, but that your current versions don't really work because of a ton of finicky details that you haven't optimized yet. But when you, your system will basically work.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-10T17:21:37.050Z · LW(p) · GW(p)
Here's a sketch for what I'd like to see in the future--a better version of the scenario experiment done above:
- 2-4 people sit down for a few hours together.
- For the first 1-3 hours, they each write a Scenario depicting their 'median future' or maybe 'modal future.' The scenarios are written similarly to the one I wrote above, with dated 'stages.' The scenarios finish with superintelligence, or else it-being-clear-superintelligence-is-many-decades-away-at-least.
- As they write, they also read over each other's scenarios and ask clarifying questions. E.g. "You say that in 2025 they can code well but unreliably -- what do you mean exactly? How much does it improve the productivity of, say, OpenAI engineers?"
- By the end of the period, the scenarios are finished & everyone knows roughly what each stage means because they've been able to ask clarifying questions.
- Then for the next hour or so, they each give credences for each stage of each scenario. Credences in something like "ASI by year X" where X is the year ASI happens in the scenario.
- They also of course discuss and critique each other's credences, and revise their own.
- At the end, hopefully some interesting movements will have happened in people's mental models and credences, and hopefully some interesting cruxes will have surfaced -- e.g. it'll be more clear what kinds of evidence would actually cause timelines updates, were they to be observed.
- The scenarios, credences, and maybe a transcript of the discussion then gets edited and published.
comment by Richard121 · 2023-11-11T22:19:09.420Z · LW(p) · GW(p)
1000x energy consumption in 10-20 years is a really wild prediction, I would give it a <0.1% probability.
It's several orders of magnitude faster than any previous multiple, and requires large amounts of physical infrastructure that takes a long time to construct.
1000x is a really, really big number.
Baseline
2022 figures, total worldwide consumption was 180 PWh/year[1]
Of that:
- Oil: 53 PWh
- Coal: 45 PWh
- Gas: 40 PWh
- Hydro: 11 PWh
- Nuclear: 7 PWh
- Modern renewable: 13 PWh
- Traditional: 11 PWh
(2 sig fig because we're talking about OOM here)
There has only been a x10 multiple in the last 100 years - humanity consumed approx. 18 PWh/year around 1920 or so (details are sketchy for obvious reasons).
Looking at doubling time, we have:
1800 (5653 TWh)
1890 (10684 TWh) - 90 years
1940 (22869 TWh) - 50
1960 (41814 TWh) - 20
1978 (85869 TWh) - 18
2018 (172514 TWh) - 40
So historically, the fastest rate of doubling has been 20 years.
Build it anyway
It takes 5-10 years for humans to build a medium to large size power plant, assuming no legal constraints.
AGI is very unlikely to be able to build an individual plant much faster, although it could build more at once.
Let's ignore that and assume AGI can build instantly.
What's in the power plant
At current consumption, known oil, gas and coal reserves are roughly 250 years in total.
Thus at 1000x consumption they are consumed in less than three months.
Nuclear fuel reserves are a similar size - 250 years of uranium, so assuming reprocessing etc, let's say 1000-2000 years at 2022 consumption.
So the AGI has less than 3 years of known fuel reserves at 1000x current consumption.
However, "reserves" means we know where it is and how much could be economically extracted.
Exploration will find more, and of course there are many other, more esoteric methods of electricity generation known or believed to be possible but currently uneconomic or unknown how to build.
How about Space?
Solar irradiance is roughly 1380 W/m2 at Earth's orbital distance. Call it 12 MWh/year/m2, or 12 TWh/year/km2
We're looking for 180,000,000 TWh/year, so we need a solar panel area of around 20,000,000 km2 at >50% efficiency.
That's a circle >2500km radius - much bigger than the Moon!
Fusion
The hidden assumption is that AGI not only figures out large-scale fusion in 4 years, but rolls it out immediately.
- ^
Hannah Ritchie, Pablo Rosado and Max Roser (2020) - “Energy Production and Consumption”
https://ourworldindata.org/energy-production-consumption
↑ comment by ryan_greenblatt · 2023-11-12T05:33:58.343Z · LW(p) · GW(p)
I strongly disagree. The underlying reason is that an actual singularity seems reasonably likely.
This involves super-exponential growth driven by vastly superhuman intelligence.
Large scale fusion or literal dyson spheres are both quite plausible relatively soon (<5 years) after AGI if growth isn't restricted by policy or coordination.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-12T06:58:38.756Z · LW(p) · GW(p)
I think you aren't engaging with the reasons why smart people think that 1000x energy consumption could happen soon. It's all about the growth rates. Obviously anything that looks basically like human industrial society won't be getting to 1000x in the next 20 years; the concern is that a million superintelligences commanding an obedient human nation-state might be able to design a significantly faster-growing economy. For an example of how I'm thinking about this, see this comment. [LW(p) · GW(p)]
↑ comment by kave · 2023-11-12T04:14:49.861Z · LW(p) · GW(p)
IIUC, 1000x was chosen to be on-the-order-of the solar energy reaching the earth
Replies from: o-zewe↑ comment by det (o-zewe) · 2023-11-19T04:49:21.149Z · LW(p) · GW(p)
I was surprised by this number (I would have guessed total power consumption was a much lower fraction of total solar energy), so I just ran some quick numbers and it basically checks out.
- This document claims that "Averaged over an entire year, approximately 342 watts of solar energy fall upon every square meter of Earth. This is a tremendous amount of energy—44 quadrillion (4.4 x 10^16) watts of power to be exact."
- Our World in Data says total energy consumption in 2022 was 179,000 terawatt-hours
Plugging this in and doing some dimensional analysis, it looks like the earth uses about 2000x the current energy consumption, which is the same OOM.
A NOAA site claims it's more like 10,000x:
173,000 terawatts of solar energy strikes the Earth continuously. That's more than 10,000 times the world's total energy use.
But plugging this number in with the OWiD value for 2022 gives about 8500x multiplier (I think the "more than 10000x" claim was true at the time it was made though). So maybe it's an OOM off, but for a loose claim using round numbers it seems close enough for me.
[edit: Just realized that Richard121 quotes some of the same figures above for total energy use and solar irradiance -- embarrassingly, I hadn't read his comment before posting this, I just saw kave's claim while scrolling and wanted to check it out. Good that we seem to have the same numbers though!]
↑ comment by Vladimir_Nesov · 2023-11-12T00:36:03.140Z · LW(p) · GW(p)
Drosophila biomass doubles every 2 days. Small things can assemble into large things. If AGI uses serial speed advantage to quickly design superintelligence, which then masters macroscopic biotech (or bootstraps nanotech if that's feasible) and of course fusion, that gives unprecedented physical infrastructure scaling speed. Given capability/hardware shape of AlphaFold 2, GPT-4, and AlphaZero, there is plausibly enough algorithmic improvement overhang to get there without needing to manufacture more compute hardware first, just a few model training runs.
comment by Sen · 2023-11-17T21:14:43.653Z · LW(p) · GW(p)
A question for all: If you are wrong and in 4/13/40 years most of this fails to come true, will you blame it on your own models being wrong or shift goalposts towards the success of the AI safety movement / government crack downs on AI development? If the latter, how will you be able to prove that AGI definitely would have come had the government and industry not slowed down development?
To add more substance to this comment: I felt Ege came out looking the most salient here. In general, making predictions about the future should be backed by heavy uncertainty. He didn't even disagree very strongly with most of the central premises of the other participants, he just placed his estimates much more humbly and cautiously. He also brought up the mundanity of progress and boring engineering problems, something I see as the main bottleneck in the way of a singularity. I wouldn't be surprised if the singularity turns out to be a physically impossible phenomenon because of hard limits in parallelisation of compute or queueing theory or supply chains or materials processing or something.
Replies from: daniel-kokotajlo, Vladimir_Nesov↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-17T21:26:02.720Z · LW(p) · GW(p)
Thank you for raising this explicitly. I think probably lots of people's timelines are based partially on vibes-to-do-with-what-positions-sound-humble/cautious, and this isn't totally unreasonable so deserves serious explicit consideration.
I think it'll be pretty obvious whether my models were wrong or whether the government cracked down. E.g. how much compute is spent on the largest training run in 2030? If it's only on the same OOM as it is today, then it must have been government crackdown. If instead it's several OOMs more, and moreover the training runs are still of the same type of AI system (or something even more powerful) as today (big multimodal LLMs) then I'll very happily say I was wrong.
Re humility and caution: Humility and caution should push in both directions, not just one. If your best guess is that AGI is X years away, adding an extra dose of uncertainty should make you fatten both tails of your distribution -- maybe it's 2X years away, but maybe instead it's X/2 years away.
(Exception is for planning fallacy stuff -- there we have good reason to think people are systematically biased toward shorter timelines. So if your AGI timelines are primarily based on planning out a series of steps, adding more uncertainty should systematically push your timelines farther out.)
Another thing to mention re humility and caution is that it's very very easy for framing effects to bias your judgments of who is being humble and who isn't. For one thing it's easy to appear more humble than you are simply by claiming to be so. I could have preceded many of my sentences above with "I think we should be more cautious than that..." for example. For another thing when three people debate the middle person has an aura of humility and caution simply because they are the middle person. Relatedly when someone has a position which disagrees with the common wisdom, that position is unfairly labelled unhumble/incautious even when it's the common wisdom that is crazy.
↑ comment by Vladimir_Nesov · 2023-11-21T16:40:19.501Z · LW(p) · GW(p)
will you blame it on your own models being wrong
When models give particular ways of updating on future evidence, current predictions being wrong doesn't by itself make models wrong. Models learn, the way they learn is already part of them. An updating model is itself wrong when other available models are better in some harder-to-pin-down sense, not just at being right about particular predictions. When future evidence isn't in scope of a model, that invalidates the model. But not all models are like that with respect to relevant future evidence, even when such evidence dramatically changes their predictions in retrospect.
comment by Adam Kaufman (Eccentricity) · 2023-11-11T08:52:47.295Z · LW(p) · GW(p)
This random Twitter person says that it can't. Disclaimer: haven't actually checked for myself.
https://chat.openai.com/share/36c09b9d-cc2e-4cfd-ab07-6e45fb695bb1
Here is me playing against GPT-4, no vision required. It does just fine at normal tic-tac-toe, and figures out anti-tic-tac-toe with a little bit of extra prompting.
↑ comment by [deleted] · 2023-11-13T22:29:02.710Z · LW(p) · GW(p)
GPT-4 can follow the rules of tic-tac-toe, but it cannot play optimally. In fact it often passes up opportunities for wins. I've spent about an hour trying to get GPT-4 to play optimal tic-tac-toe without any success.
Here's an example of GPT-4 playing sub-optimally: https://chat.openai.com/share/c14a3280-084f-4155-aa57-72279b3ea241
Here's an example of GPT-4 suggesting a bad move for me to play: https://chat.openai.com/share/db84abdb-04fa-41ab-a0c0-542bd4ae6fa1
Replies from: ReaderM, gwern↑ comment by ReaderM · 2023-11-15T06:57:39.420Z · LW(p) · GW(p)
Optimal play requires explaining the game in detail. See here
https://chat.openai.com/share/75758e5e-d228-420f-9138-7bff47f2e12d
↑ comment by gwern · 2023-11-13T23:34:55.014Z · LW(p) · GW(p)
Have you or all the other tic-tac-toe people considered just spending a bit of time finetuning GPT-3 or GPT-4 to check how far away it is from playing optimally?
Replies from: None, ReaderM↑ comment by [deleted] · 2023-11-14T00:01:16.941Z · LW(p) · GW(p)
I would guess that you could train models to perfect play pretty easily, since the optimal tic-tac-toe strategy is very simple (Something like "start by playing in the center, respond by playing on a corner, try to create forks, etc".) It seems like few-shot prompting isn't enough to get them there, but I haven't tried yet. It would be interesting to see if larger sizes of gpt-3 can learn faster than smaller sizes. This would indicate to what extent finetuning adds new capabilities rather than surfacing existing ones.
I still find the fact that gpt-4 cannot play tic-tac-toe despite prompting pretty striking on its own, especially since it's so good at other tasks.
↑ comment by ReaderM · 2023-11-15T06:58:54.694Z · LW(p) · GW(p)
Optimal tic tac toe takes explaining the game in excruciating detail. https://chat.openai.com/share/75758e5e-d228-420f-9138-7bff47f2e12d
Replies from: clydeiii↑ comment by Rafael Harth (sil-ver) · 2023-11-11T10:41:03.590Z · LW(p) · GW(p)
Gonna share mine because that was pretty funny. I thought I played optimally missing a win whoops, but GPT-4 won anyway, without making illegal moves. Sort of.
comment by Zach Stein-Perlman · 2023-11-10T06:23:33.970Z · LW(p) · GW(p)
@Daniel Kokotajlo [LW · GW] it looks like you expect 1000x-energy 4 years after 99%-automation. I thought we get fast takeoff, all humans die, and 99% automation at around the same time (but probably in that order) and then get massive improvements in technology and massive increases in energy use soon thereafter. What takes 4 years?
(I don't think the part after fast takeoff or all humans dying is decision-relevant, but maybe resolving my confusion about this part of your model would help illuminate other confusions too.)
Replies from: daniel-kokotajlo, habryka4↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-10T17:41:25.075Z · LW(p) · GW(p)
Good catch. Let me try to reconstruct my reasoning:
- I was probably somewhat biased towards a longer gap because I knew I'd be discussing with Ege who is very skeptical (I think?) that even a million superintelligences in control of the entire human society could whip it into shape fast enough to grow 1000x in less than a decade. So I probably was biased towards 'conservatism.' (in scare quotes because the direction that is conservative vs. generous is determined by what other people think, not by the evidence and facts of the case)
- As Habryka says, I think there's a gap between 99% automatable and 99% automated. I think the gap between AI R&D being 99% automatable and being actually automated will be approximately one day, unless there is deliberate effort to slow down. But automating the world economy will take longer because there won't be enough compute to replace all the jobs, many jobs will be 'sticky' and people won't just be immediately laid off, many jobs are partially physical and thus would require robots to fully automate, robots which need to be manufactured, etc.
- I also think there's a gap between a fully automated economy and 1000x energy consumption. Napkin math: Say your nanobots / nanofactories / optimized robo-miner-factory-complexes are capable of reproducing themselves (doubling in size) every month. And say you start with 1000 tons worth of them, produced with various human tools in various human laboratories. Then a year later you'll only have 4M tons, and a year after that 16B tons... it'll take a while to overtake the human economy and then about a year after that you get to 1000x energy consumption. Is a one month doubling time reasonable estimate? I have no idea, I could imagine it being significantly faster but also somewhat slower. (Faster scenario: Nanobots/nanofactories that are like bacteria but better. Doubling times like one hour or so. Slower scenario: The tools to build nanobots/nanofactories don't exist, so you need to build the tools to build the tools to build the tools to build them. And this just takes serial time; maybe each stage takes six months. Slower scenario: Nanobots etc. are possible but not with a doubling time measured in hours; in harsh environments like earth's oceans and surfaces, doubling time even for the best nanobots is measured in weeks. Instead of "like bacteria but better," it's "like grass but better." Even slower scenario: Nanobots/nanofactories just aren't possible even for superintelligences except maybe if they are able to do massive experiments to search through the space of all possible designs or something like that. Which they aren't. So they get by for now with ordinary robots digging and refining and manufacturing stuff, which has a doubling time of almost a year. "Like human industrial economy but better." (Tesla factories produce about their weight in cars every year I think. Rough estimate, could be off by an OOM.)
- I'd love to see more serious analysis along the lines I sketched above, of what the plausible fastest doubling times are and how long it might take for a million ASIs with obedient human nations to get there. My current views are very uncertain and unstable.
↑ comment by Zach Stein-Perlman · 2023-11-10T17:49:58.400Z · LW(p) · GW(p)
Thanks!
automating the world economy will take longer
I'm curious what fraction-of-2023-tasks-automatable and maybe fraction-of-world-economy-automated you think will occur at e.g. overpower [LW · GW] time, and the median year for that. (I sometimes notice people assuming 99%-automatability occurs before all the humans are dead, without realizing they're assuming anything.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-10T18:21:47.905Z · LW(p) · GW(p)
Distinguishing:
(a) 99% remotable 2023 tasks automateable (the thing we forecast in the OP)
(b) 99% 2023 tasks automatable
(c) 99% 2023 tasks automated
(d) Overpower ability
My best guess at the ordering will be a->d->b->c.
Rationale: Overpower ability probably requires something like a fully functioning general purpose agent capable of doing hardcore novel R&D. So, (a). However it probably doesn't require sophisticated robots, of the sort you'd need to actually automate all 2023 tasks. It certainly doesn't require actually having replaced all human jobs in the actual economy, though for strategic reasons a coalition of powerful misaligned AGIs would plausibly wait to kill the humans until they had actually rendered the humans unnecessary.
My best guess is that a, d, and b will all happen in the same year, possibly within the same month. c will probably take longer for reasons sketched above.
↑ comment by Richard121 · 2023-11-11T21:06:13.413Z · LW(p) · GW(p)
I think the gap between AI R&D being 99% automatable and being actually automated will be approximately one day
That's wildly optimistic. There aren't any businesses that can change anywhere near that fast.
Even if they genuinely wanted to, the laws 99% of business are governed by mean that they genuinely can't do that. The absolute minimum time for such radical change under most jurisdictions is roughly six months.
Looking at the history of step changes in industry/business such as the industrial and information revolutions, I think the minimum plausible time between "can be automated with reasonable accuracy" and "is actually automated" is roughly a decade (give or take five years), because the humans who would be 'replaced' will not go gently.
That is far faster than either of the previous revolutions though, and a lot faster than the vast majority of people are capable of adapting. Which would lead to Interesting Times...
Replies from: o-o↑ comment by O O (o-o) · 2023-11-11T22:05:20.340Z · LW(p) · GW(p)
The idea is R&D will already be partially automated before hitting the 99% mark, so 99% marks the end of a gradual shift towards automation.
Replies from: Richard121↑ comment by Richard121 · 2023-11-11T22:56:18.534Z · LW(p) · GW(p)
I think there is a significant societal difference, because that last step is a lot bigger than the ones before.
In general, businesses tend to try to reduce headcount as people retire or leave, even if it means some workers have very little to do. Redundancies are expensive and take a long time - the larger they are, the longer it takes.
Businesses are also primarily staffed and run by humans who do not wish to lose their own jobs.
For a real-world example of a task that is already >99% automatable, consider real estate conveyancing.
The actual transaction is already entirely automated via simple algorithms - the database of land ownership is updated indicating the new owner, and the figures representing monetary wealth are updated in two or more bank accounts.
The work prior to that consists of identity confirmation, and document comprehension to find and raise possible issues that the buyer and seller need to be informed about.
All of this is already reasonably practicable with existing LLMs and image matching.
Have any conveyancing solicitors replaced all of their staff thusly?
Replies from: o-o↑ comment by habryka (habryka4) · 2023-11-10T06:34:29.305Z · LW(p) · GW(p)
I think one component is that the prediction is for when 99% of jobs are automatable, not when they are automated (Daniel probably has more to say here, but this one clarification seems important).
comment by peterbarnett · 2023-11-13T18:31:42.071Z · LW(p) · GW(p)
Ege, do you think you'd update if you saw a demonstration of sophisticated sample-efficient in-context learning and far-off-distribution transfer?
Manifold Market on this question:
comment by kave · 2023-11-11T02:10:05.689Z · LW(p) · GW(p)
Curated. I feel like over the last few years my visceral timelines have shortened significantly. This is partly in contact with LLMs, particularly their increased coding utility, and a lot downstream of Ajeya's and Daniel's models and outreach (I remember spending an afternoon on an arts-and-crafts 'build your own timeline distribution' that Daniel had nerdsniped me with). I think a lot of people are in a similar position and have been similarly influenced. It's nice to get more details on those models and the differences between them, as well as to hear Ege pushing back with "yeah but what if there are some pretty important pieces that are missing and won't get scaled away?", which I hear from my environment much less often.
There are a couple of pieces of extra polish that I appreciate. First, having some specific operationalisations with numbers and distributions up-front is pretty nice for grounding the discussion. Second, I'm glad that there was a summary extracted out front, as sometimes the dialogue format can be a little tricky to wade through.
On the object level, I thought the focus on schlep in the Ajeya-Daniel section and slowness of economy turnover in the Ajaniel-Ege section was pretty interesting. I think there's a bit of a cycle with trying to do complicated things like forecast timelines, where people come up with simple compelling models that move the discourse a lot and sharpen people's thinking. People have vague complaints that the model seems like it's missing something, but it's hard to point out exactly what. Eventually someone (often the person with the simple model) is able to name one of the pieces that is missing, and the discourse broadens a bit. I feel like schlep is a handle that captures an important axis that all three of our participants differ on.
I agree with Daniel that a pretty cool follow-up activity would be an expanded version of the exercise at the end with multiple different average worlds.
comment by hold_my_fish · 2023-11-14T05:43:35.339Z · LW(p) · GW(p)
If human-level AI is reached quickly mainly by spending more money on compute (which I understood to be Kokotajlo's viewpoint; sorry if I misunderstood), it'd also be quite expensive to do inference with, no? I'll try to estimate how it compares to humans.
Let's use Cotra's "tens of billions" for training compared to GPT-4's $100m+, for roughly a 300x multiplier. Let's say that inference costs are multiplied by the same 300x, so instead of GPT-4's $0.06 per 1000 output tokens, you'd be paying GPT-N $18 per 1000 output tokens. I think of GPT output as analogous to human stream of consciousness, so let's compare to human talking speed, which is roughly 130 wpm. Assuming 3/4 words per token, that converts to a human hourly wage of 18/1000/(3/4)*130*60 = $187/hr.
So, under these assumptions (which admittedly bias high), operating this hypothetical human-level GPT-N would cost the equivalent of paying a human about $200/hr. That's expensive but cheaper than some high-end jobs, such as CEO or elite professional. To convert to a salary, assume 2000 hours per year, for a $400k salary. For example, that's less than OpenAI software engineers reportedly earn.
This is counter-intuitive, because traditionally automation-by-computer has had low variable costs. Based on the above back-of-the-envelope calculation, I think it's worth considering when discussing human-level-AI-soon scenarios.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-14T06:43:08.826Z · LW(p) · GW(p)
Nice analysis. Some thoughts:
1. If scaling continues with something like Chinchilla scaling laws, the 300x multiplier for compute will not be all lumped into increasing parameters / inference cost. Instead it'll be split roughly half and half. So maybe 20x more data/trainingtime and 15x more parameters/inference cost. So, instead of $200/hr, we are talking more like $15/hr.
2. Hardware continues to improve in the near term; FLOP/$ continues to drop. As far as I know. Of course during AI boom times the price will be artificially high due to all the demand... Not sure which direction the net effect will be.
3. Reaching human-level AI might involve trading off inference compute and training compute, as discussed in Davidson's model (see takeoffspeeds.com and linked report) which probably is a factor that increases inference compute of the first AGIs (while shortening timelines-to-AGI) perhaps by multiple OOMs.
4. However much it costs, labs will be willing to pay. An engineer that works 5x, 10x, 100x faster than a human is incredibly valuable, much more valuable than if they worked only at 1x speed like all the extremely high-salaried human engineers at AI labs.
↑ comment by hold_my_fish · 2023-11-14T09:01:09.544Z · LW(p) · GW(p)
the 300x multiplier for compute will not be all lumped into increasing parameters / inference cost
Thanks, that's an excellent and important point that I overlooked: the growth rate of inference cost is about half that of training cost.
comment by Vladimir_Nesov · 2023-11-10T20:27:05.247Z · LW(p) · GW(p)
Subjectively there is clear improvement between 7b vs. 70b vs. GPT-4, each step 1.5-2 OOMs of training compute. The 70b models are borderline capable of following routine instructions to label data or pour it into specified shapes. GPT-4 is almost robustly capable of that. There are 3-4 more effective OOMs in the current investment scaling sprint (3-5 years), so another 2 steps of improvement if there was enough equally useful training data to feed the process, which there isn't. At some point, training gets books in images that weren't previously available as high quality text, which might partially compensate for running out of text data. Perhaps there are 1.5 steps of improvement over GPT-4 in total despite the competence-dense data shortage. (All of this happens too quickly to be restrained by regulation, and without AGI never becomes more scary than useful.)
Leela Zero is a 50m parameter model that plays superhuman Go, a product of quality of its synthetic dataset. Just as with images, sound, natural languages, and programming languages, we can think of playing Go and writing formal proofs as additional modalities. A foundational model that reuses circuits between modalities would be able to take the competence where synthetic data recipes are known, and channel it to better reasoning in natural language, understanding human textbooks and papers, getting closer to improving the quality of its natural language datasets. Competence at in-context learning or sample efficiency during pre-training are only relevant where the system is unable to do real work on its own, the reason essential use of RL can seem necessary for AGI. But once a system is good enough to pluck the low hanging R&D fruit around contemporary AI architectures, these obstructions are gone. (Productively tinkering with generalized multimodality and synthetic data doesn't require going outside the scale of preceding models, which keeps existing regulation too befuddled to intervene.)
Replies from: tao-lin↑ comment by Tao Lin (tao-lin) · 2023-11-11T20:11:41.683Z · LW(p) · GW(p)
Leela Zero uses MCTS, it doesnt play superhuman in one forward pass (like gpt-4 can do in some subdomains) (i think, didnt find any evaluations of Leela Zero at 1 forward pass), and i'd guess that the network itself doesnt contain any more generalized game playing circuitry than an llm, it just has good intuitions for Go.
Nit:
Subjectively there is clear improvement between 7b vs. 70b vs. GPT-4, each step 1.5-2 OOMs of training compute.
1.5 to 2 OOMs? 7b to 70b is 1 OOM of compute, adding in chinchilla efficiency would make it like 1.5 OOMs of effective compute, not 2. And llama 70b to gpt-4 is 1 OOM effective compute according to openai naming - llama70b is about as good as gpt-3.5. And I'd personally guess gpt4 is 1.5 OOMs effective compute above llama70b, not 2.
Replies from: Vladimir_Nesov, Buck↑ comment by Vladimir_Nesov · 2023-11-11T22:40:31.831Z · LW(p) · GW(p)
Leela Zero uses MCTS, it doesnt play superhuman in one forward pass
Good catch, since the context from LLMs is performance in one forward pass, the claim should be about that, and I'm not sure it's superhuman without MCTS. I think the intended point survives this mistake, that is it's a much smaller model than modern LLMs that has relatively very impressive performance primarily because of high quality of the synthetic dataset it effectively trains on. Thus models at the scale of near future LLMs will have a reality-warping amount of dataset quality overhang. This makes ability of LLMs to improve datasets much more impactful than their competence at other tasks, hence the anchors of capability I was pointing out were about labeling and rearranging data according to instructions. And also makes compute threshold gated regulation potentially toothless.
Subjectively there is clear improvement between 7b vs. 70b vs. GPT-4, each step 1.5-2 OOMs of training compute.
1.5 to 2 OOMs? 7b to 70b is 1 OOM of compute, adding in chinchilla efficiency would make it like 1.5 OOMs of effective compute, not 2.
With Chinchilla scaling, compute is square of model size, so 2 OOMs under that assumption. Of course current 7b models are overtrained compared to Chinchilla (all sizes of LLaMA-2 are trained on 2T tokens), which might be your point. And Mistral-7b is less obviously a whole step below LLaMA-2-70b, so the full-step-of-improvement should be about earlier 7b models more representative of how the frontier of scaling advances, where a Chinchilla-like tradeoff won't yet completely break down, probably preserving data squared compute scaling estimate (parameter count no longer works very well as an anchor with all the MoE and sparse pre-training stuff). Not clear what assumptions make it 1.5 OOMs instead of either 1 or 2, possibly Chinchilla-inefficiency of overtraining?
And llama 70b to gpt-4 is 1 OOM effective compute according to openai naming - llama70b is about as good as gpt-3.5.
I was going from EpochAI estimate that puts LLaMA 2 at 8e23 FLOPs and GPT-4 at 2e25 FLOPs, which is 1.4 OOMs. I'm thinking of effective compute in terms of compute necessary for achieving the same pre-training loss (using lower amount of literal compute with pre-training algorithmic improvement), not in terms of meaningful benchmarks for fine-tunes. In this sense overtrained smaller LLaMAs get even less effective compute than literal compute, since they employ it to get loss Chinchilla-inefficiently. We can then ask the question of how much subjective improvement a given amount of pre-training loss scaling (in terms of effective compute) gets us. It's not that useful in detail, but gives an anchor for improvement from scale alone in the coming years, before industry and economy force a slowdown (absent AGI): It goes beyond GPT-4 about as far as GPT-4 is beyond LLaMA-2-13b.
↑ comment by Buck · 2023-11-11T21:06:47.318Z · LW(p) · GW(p)
Iirc, original alphago had a policy network that was grandmaster level but not superhuman without MCTS.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2023-11-12T15:22:06.911Z · LW(p) · GW(p)
This is not quite true. Raw policy networks of AlphaGo-like models are often at a level around 3 dan in amateur rankings, which would qualify as a good amateur player but nowhere near the equivalent of grandmaster level. If you match percentiles in the rating distributions, 3d in Go is perhaps about as strong as an 1800 elo player in chess, while "master level" is at least 2200 elo and "grandmaster level" starts at 2500 elo.
Edit: Seems like policy networks have improved since I last checked these rankings, and the biggest networks currently available for public use can achieve a strength of possibly as high as 6d without MCTS. That would be somewhat weaker than a professional player, but not by much. Still far off from "grandmaster level" though.
Replies from: Buck↑ comment by Buck · 2023-11-12T16:05:49.772Z · LW(p) · GW(p)
According to figure 6b in "Mastering the Game of Go without Human Knowledge", the raw policy network has 3055 elo, which according to this other page (I have not checked that these Elos are comparable) makes it the 465th best player. (I don’t know much about this and so might be getting the inferences wrong, hopefully the facts are useful)
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2023-11-12T17:14:37.653Z · LW(p) · GW(p)
I don't think those ratings are comparable. On the other hand, my estimate of 3d was apparently lowballing it based on some older policy networks, and newer ones are perhaps as strong as 4d to 6d, which on the upper end is still weaker than professional players but not by much.
However, there is a big gap between weak professional players and "grandmaster level", and I don't think the raw policy network of AlphaGo could play competitively against a grandmaster level Go player.
comment by Seth Herd · 2023-11-10T06:40:28.845Z · LW(p) · GW(p)
The important thing for alignment work isn't the median prediction; if we had an alignment solution just by then, we'd have a 50% chance of dying from that lack.
I think the biggest takeaway is that nobody has a very precise and reliable prediction, so if we want to have good alignment plans in advance of AGI, we'd better get cracking.
I think Daniel's estimate does include a pretty specific and plausible model of a path to AGI, so I take his the most seriously. My model of possible AGI architectures requires even less compute than his, but I think the Hofstadter principle applies to AGI development if not compute progress.
Estimates in the absence of gears-level models of AGI seem much more uncertain, which might be why Ajeya and Ege's have much wider distributions.
comment by Seth Herd · 2024-12-06T20:21:32.376Z · LW(p) · GW(p)
Knowing how much time we've got is important to using it well. It's worth this sort of careful analysis.
I found most of this to be wasted effort based on too much of an outside view. The human brain gives neither an upper nor lower bound on the computation needed to achieve transformative AGI. Inside views that include gears-level models of how our first AGIs will function seem much more valuable; thus Daniel Kokatijlo's predictions seem far better informed than the others here.
Outside views like "things take longer than they could, often a lot longer" are valuable, but if we look at predicting when other engineering feats would first be accomplished, good predictions would've taken both expert engineers and usually, those who could predict when funding and enthusiasm for the project would become available.
In any case, more careful timeline predictions like this would improve our odds.
comment by Lee.aao (leonid-artamonov) · 2024-03-22T21:36:22.079Z · LW(p) · GW(p)
Ege, do you think you'd update if you saw a demonstration of sophisticated sample-efficient in-context learning and far-off-distribution transfer?
Yes.
Suppose it could get decent at the first-person-shooter after like a subjective hour of messing around with it. If you saw that demo in 2025, how would that update your timelines?
I would probably update substantially towards agreeing with you.
DeepMind released an early-stage research model SIMA: https://deepmind.google/discover/blog/sima-generalist-ai-agent-for-3d-virtual-environments/
It was tested on 600 basic (10-sec max) videogame skills and had only video from the screen + text with the task. The main takeaway is that an agent trained on many games performs in a new unseen game almost as well as another agent, trained specifically on this game.
Seems like by 2025 its really possible to see more complex generalization (harder tasks and games, more sample efficiency) as in your crux for in-context learning.

{kind=link}
comment by Eli Tyre (elityre) · 2023-11-23T19:33:41.497Z · LW(p) · GW(p)
I disagree with this update -- I think the update should be "it takes a lot of schlep and time for the kinks to be worked out and for products to find market fit" rather than "the systems aren't actually capable of this." Like, I bet if AI progress stopped now, but people continued to make apps and widgets using fine-tunes of various GPTs, there would be OOMs more economic value being produced by AI in 2030 than today.
As a personal aside: Man, what a good world that would be. We would get a lot of the benefits of the early singularity, but not the risks.
Maybe the ideal would be one additional generation of AI progress before the great stop? And the thing that I'm saddest about is that GPTs don't give us much leverage over biotech, so we don't get the life-saving and quality-of-life-improving medical technologies that seem nearby on the AI tech tree.
But if we could hit some level of AI tech, stop, and just exploit / do interpretability on our current systems for 20 years, that sounds so good.
comment by Eli Tyre (elityre) · 2023-11-23T19:15:56.278Z · LW(p) · GW(p)
I am on a capabilities team at OpenAI right now
Um. What?
I guess I'm out of the loop. I thought you, Daniel, were doing governance stuff.
What's your rationale for working on capabilities if you think timelines are this compressed?
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-23T19:40:08.029Z · LW(p) · GW(p)
I'm doing safety work at a capabilities team, basically. I'm trying not to advance capabilities myself. I'm trying to make progress on a faithful CoT agenda. Dan Selsam, who runs the team, thought it would be good to have a hybrid team instead of the usual thing where the safety people and capabilities people are on separate teams and the capabilities people feel licensed to not worry about the safety stuff at all and the safety people are relatively out of the loop.
comment by davidconrad · 2023-11-14T13:03:52.200Z · LW(p) · GW(p)
I found the discussion around Hofstadter's law in forecasting to be really useful as I've definitely found myself and others adding fudge factors to timelines to reflect unknown unknowns which may or may not be relevant when extrapolating capabilities from compute.
In my experience many people are of the feeling that current tools are primarily limited by their ability to plan and execute over longer time horizons. Once we have publicly available tools that are capable of carrying out even simple multi-step plans (book me a great weekend away with my parents with a budget of $x and send me the itinerary), I can see timelines amongst the general public being dramatically reduced.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-14T23:15:42.620Z · LW(p) · GW(p)
I think unknown unknowns are a different phenomenon than Hofstadter's Law / Planning Fallacy. My thinking on unknown unknowns is that they should make people spread out their timelines distribution, so that it has more mass later than they naively expect, but also more mass earlier than they naively expect. (Just as there are unknown potential blockers, there are unknown potential accelerants.) Unfortunately I think many people just do the former and not the latter, and this is a huge mistake.
Replies from: davidconrad↑ comment by davidconrad · 2023-11-15T16:20:27.769Z · LW(p) · GW(p)
Interesting. I fully admit most of my experience with unknown unknowns comes from either civil engineering projects or bringing consumer products to market, both situations where the unknown unknowns are disproportionately blockers. But this doesn't seem to be the case with things like Moore's Law or continual improvements in solar panel efficiency where the unknowns have been relatively evenly distributed or even weighted towards being accelerants. I'd love to know if you have thoughts on what makes a given field more likely to be dominated by blockers or accelerants!
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-15T18:09:11.808Z · LW(p) · GW(p)
Civil engineering projects and bringing consumer products to market are both exactly the sort of thing the planning fallacy applies to. I would just say what you've experienced is the planning fallacy, then. (It's not about the world, it's about our methods of forecasting -- when forecasting how long it will take to complete a project, humans seem to be systematically biased towards optimism.)
comment by Maxime Riché (maxime-riche) · 2023-11-10T14:57:58.581Z · LW(p) · GW(p)
Thanks a lot for the summary at the start!
comment by Hoagy · 2023-11-12T16:40:30.517Z · LW(p) · GW(p)
Could you elaborate on what it would mean to demonstrate 'savannah-to-boardroom' transfer? Our architecture was selected for in the wilds of nature, not our training data. To me it seems that when we use an architecture designed for language translation for understanding images we've demonstrated a similar degree of transfer.
I agree that we're not yet there on sample efficient learning in new domains (which I think is more what you're pointing at) but I'd like to be clearer on what benchmarks would show this. For example, how well GPT-4 can integrate a new domain of knowledge from (potentially multiple epochs of training on) a single textbook seems a much better test and something that I genuinely don't know the answer to.
comment by Eli Tyre (elityre) · 2023-11-24T05:07:54.771Z · LW(p) · GW(p)
I think it would be helpful if this dialog had a different name. I would hope this isn't the last dialog on timelines, and the current title is sort of capturing the whole namespace. Can we change it to something more specific?
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-11-24T06:05:32.919Z · LW(p) · GW(p)
You'd be more likely to get this change if you suggested a workable alternative.
Replies from: blf↑ comment by blf · 2023-11-24T08:55:42.603Z · LW(p) · GW(p)
An option is to just to add the month and year, something like "November 2023 AI Timelines".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-24T13:13:49.764Z · LW(p) · GW(p)
How about "AI Timelines (Nov '23)"
comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-11T18:22:57.817Z · LW(p) · GW(p)
Great discussion! I am open to the following bet [EA · GW].
Replies from: daniel-kokotajlo, rhollerith_dot_comIf, until the end of 2028, Metaculus' question about superintelligent AI:
- Resolves non-ambiguously, I transfer to you 10 k January-2025-$ in the month after that in which the question resolved.
- Does not resolve, you transfer to me 10 k January-2025-$ in January 2029. As before [EA · GW], I plan to donate my profits to animal welfare [? · GW] organisations.
The nominal amount of the transfer in $ is 10 k times the ratio between the consumer price index for all urban consumers and items in the United States, as reported by the Federal Reserve Economic Data, in the month in which the bet resolved and January 2025.
I think the bet would not change the impact of your donations, which is what matters if you also plan to donate the profits, if:
- Your median date of superintelligent AI as defined by Metaculus was the end of 2028. If you believe the median date is later, the bet will be worse for you.
- The probability of me paying you if you win was the same as the probability of you paying me if I win. The former will be lower than the latter if you believe the transfer is less likely given superintelligent AI, in which case the bet will be worse for you.
- The cost-effectiveness of your best donation opportunities in the month the transfer is made is the same whether you win or lose the bet. If you believe it is lower if you win the bet, this will be worse for you.
We can agree on another resolution date such that the bet is good for you accounting for the above.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-12T16:18:54.961Z · LW(p) · GW(p)
Thanks for proposing this bet. I think a bullet point needs to be added:
- Your median date of superintelligent AI as defined by Metaculus was the end of 2028. If you believe the median date is later, the bet will be worse for you.
- The probability of me paying you if you win was the same as the probability of you paying me if I win. The former will be lower than the latter if you believe the transfer is less likely given superintelligent AI, in which case the bet will be worse for you.
- The expected utility of money is the same to you in either case (i.e. if the utility you can get from additional money is the same after vs. before metaculus-announcing-superintelligence). Note that I think it is very much not the same. [LW(p) · GW(p)] In particular I value post-ASI-announcement dollars much less than pre-ASI-announcement dollars, maybe orders off magnitude less. (Analogy: Suppose we were betting on 'US Government announces nuclear MAD with Russia and China is ongoing and advises everyone seek shelter' This is a more extreme example but gets the point across. If I somehow thought this was 60% likely to happen by 2028, it still wouldn't make sense for me to bet with you, because to a first approximation I dgaf about you wiring me $10k CPI-adjusted in the moments after the announcement.)
As a result of the above I currently think that there is no bet we could make (at least not along the above lines) that would be rational for both of us to accept.
↑ comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-12T16:45:52.357Z · LW(p) · GW(p)
Thanks, Daniel. My bullet points are supposed to be conditions for the bet to be neutral "in terms of purchasing power, which is what matters if you also plan to donate the profits", not personal welfare. I agree a given amount of purchashing power will buy the winner less personal welfare given superintelligent AI, because then they will tend to have a higher real consumption in the future. Or are you saying that a given amount of purchasing power given superintelligent AI will buy not only less personal welfare, but also less impartial welfare via donations? If so, why? The cost-effectiveness of donations should ideally be constant across spending categories, including across worlds where there is or not superintelligent AI by a given date. Funding should be moved from the least to the most cost-effective categories until their marginal cost-effectiveness is equalised. I understand the altruistic market is not efficient. However, for my bet not to be taken, I think one would have to argue about which concrete decisions major funders like Open Philanthropy are making badly, and why they imply spending more money on worlds where there is no superintelligent AI relative to what is being done at the margin.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-12T18:55:09.134Z · LW(p) · GW(p)
I am saying that expected purchasing power given Metaculus resolved ASI a month ago is less, for altruistic purposes, than given Metaculus did not resolve ASI a month ago. I give reasons in the linked comment. Consider the analogy I just made to nuclear MAD -- suppose you thought nuclear MAD was 60% likely in the next three years, would you take the sort of bet you are offering me re ASI? Why or why not?
I do not think any market is fully efficient and I think altruistic markets are extremely fucking far from efficient. I think I might be confused or misunderstanding you though -- it seems you think my position implies that OP should be redirecting money from AI risk causes to causes that assume no ASI? Can you elaborate?
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-12T19:46:29.524Z · LW(p) · GW(p)
Fair! I have now added a 3rd bullet, and clarified the sentence before the bullets:
I think the bet would not change the impact of your donations, which is what matters if you also plan to donate the profits, if:
- Your median date of superintelligent AI as defined by Metaculus was the end of 2028. If you believe the median date is later, the bet will be worse for you.
- The probability of me paying you if you win was the same as the probability of you paying me if I win. The former will be lower than the latter if you believe the transfer is less likely given superintelligent AI, in which case the bet will be worse for you.
- The cost-effectiveness of your best donation opportunities in the month the transfer is made is the same whether you win or lose the bet. If you believe it is lower if you win the bet, this will be worse for you.
We can agree on another resolution date such that the bet is good for you accounting for the above.
I agree the bet is not worth it if superintelligent AI as defined by Metaculus' immediately implies donations can no longer do any good, but this seems like an extreme view. Even if AIs outperform humans in all tasks for the same cost, humans could still donate to AIs.
I think the Cuban Missile Crisis is a better analogy for the period right after Metaculus' question resolves non-ambiguously than mutually assured destruction. For the former, there were still good opportunities to decrease the expected damage of nuclear war. For the latter, the damage had already been made.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-12T19:57:20.999Z · LW(p) · GW(p)
My view is not "can no longer do any good," more like "can do less good in expectation than if you had still some time left before ASI to influence things." For reasons why, see linked comment above.
I think that by the time Metaculus is convinced that ASI already exists, most of the important decisions w.r.t. AI safety will have already been made, for better or for worse. Ditto (though not as strongly) for AI concentration-of-power risks and AI misuse risks.
↑ comment by RHollerith (rhollerith_dot_com) · 2025-01-11T19:24:46.323Z · LW(p) · GW(p)
The transfer should be made in January 2029
I think you mean in January 2029 or earlier if the question resolves before the end of 2028 otherwise there would be no need to introduce the CPI into the bet to keep things fair (or predictable).
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-11T19:34:28.853Z · LW(p) · GW(p)
Thanks, Richard! I have updated the bet to account for that.
If, until the end of 2028, Metaculus' question about superintelligent AI:
- Resolves non-ambiguously, I transfer to you 10 k January-2025-$ in the month after that in which the question resolved.
- Does not resolve, you transfer to me 10 k January-2025-$ in January 2029. As before [EA · GW], I plan to donate my profits to animal welfare [? · GW] organisations.
The nominal amount of the transfer in $ is 10 k times the ratio between the consumer price index for all urban consumers and items in the United States, as reported by the Federal Reserve Economic Data, in the month in which the bet resolved and January 2025.
comment by defun (pau-vidal-bordoy) · 2024-07-04T11:03:16.237Z · LW(p) · GW(p)
(5) Q1 2026: The next version comes online. It is released, but it refuses to help with ML research. Leaks indicate that it doesn't refuse to help with ML research internally, and in fact is heavily automating the process at its parent corporation. It's basically doing all the work by itself; the humans are basically just watching the metrics go up and making suggestions and trying to understand the new experiments it's running and architectures it's proposing.
@Daniel Kokotajlo [LW · GW], why do you think they would release it?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-07-04T14:25:35.419Z · LW(p) · GW(p)
Twas just a guess, I think it could go either way. In fact these days I'd guess they wouldn't release it at all; the official internal story would be it's for security and safety reasons.
comment by Eli Tyre (elityre) · 2023-11-20T18:48:23.887Z · LW(p) · GW(p)
A local remark about this: I've seen a bunch of reports from other people that GPT-4 is essentially unable to play tic-tac-toe, and this is a shortcoming that was highly surprising to me. Given the amount of impressive things it can otherwise do, failing at playing a simple game whose full solution could well be in its training set is really odd.
Huh. This is something that I could just test immediately, so I tried it.
It looks like this is true. When I play a game of tick-tack-toe with GPT-4 it doesn't play optimally, and it let me win in 3 turns.
https://chat.openai.com/share/e54ae313-a6b3-4f0b-9513-dc44837055be
I wonder if it is letting me win? Maybe if I prompt it to try really hard to win, it will do better?
↑ comment by Eli Tyre (elityre) · 2023-11-20T18:56:37.053Z · LW(p) · GW(p)
I wonder if it is letting me win? Maybe if I prompt it to try really hard to win, it will do better?
Nope! It doesn't seem like it.
https://chat.openai.com/share/b6878aae-faed-48a9-a15f-63981789f772
It played the exact same (bad) moves as before, and didn't notice when I had won the game.
Also when I told it I won, it gave a false explanation for how.
It seems like GPT-4 can't, or at least doesn't, play tick-tack-toe well?
comment by jsd · 2023-11-10T21:13:55.219Z · LW(p) · GW(p)
@Daniel Kokotajlo [LW · GW] what odds would you give me for global energy consumption growing 100x by the end of 2028? I'd be happy to bet low hundreds of USD on the "no" side.
ETA: to be more concrete I'd put $100 on the "no" side at 10:1 odds but I'm interested if you have a more aggressive offer.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-10T22:50:22.867Z · LW(p) · GW(p)
As previously discussed a couple times on this website, it's not rational for me to make bets on my beliefs about these things. Because I either won't be around to collect if I win, or won't value the money nearly as much. And because I can get better odds on the public market simply by taking out a loan.
Replies from: jsd, o-o↑ comment by jsd · 2023-11-10T23:44:12.209Z · LW(p) · GW(p)
As previously discussed a couple times on this website
For context, Daniel wrote Is this a good way to bet on short timelines? [LW · GW] (which I didn't know about when writing this comment) 3 years ago.
HT Alex Lawsen for the link.
↑ comment by O O (o-o) · 2023-11-11T00:47:21.162Z · LW(p) · GW(p)
How about a bet on whether there appears to be a clear path to X instead? Or even more objectively some milestone that will probably be hit before we actually hit X.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-11T00:55:31.311Z · LW(p) · GW(p)
Yep, I love betting about stuff like that. Got any suggestions for how to objectively operationalize it? Or a trusted third party arbiter?
comment by Quinn (quinn-dougherty) · 2023-12-10T19:49:36.207Z · LW(p) · GW(p)
How were the distributions near the top elicited from each participant?
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-12-10T20:12:34.681Z · LW(p) · GW(p)
I asked Ajeya, Daniel, and Ege to input their predictions for the two operationalizations into the UI for a random Metaculus market without submitting, and send me screenshots of the UI. Then I traced it over with Adobe Illustrator, combined the different predictions, and then made the final images.
comment by Tao Lin (tao-lin) · 2023-11-13T23:55:34.172Z · LW(p) · GW(p)
E.g. suppose some AI system was trained to learn new video games: each RL episode was it being shown a video game it had never seen, and it's supposed to try to play it; its reward is the score it gets. Then after training this system, you show it a whole new type of video game it has never seen (maybe it was trained on platformers and point-and-click adventures and visual novels, and now you show it a first-person-shooter for the first time). Suppose it could get decent at the first-person-shooter after like a subjective hour of messing around with it. If you saw that demo in 2025, how would that update your timelines?
Time constraints may make this much harder. Like a lot of games require multiple inputs per second (eg double jump) and at any given time the AI with the best transfer learning will be far too slow for inference to play as well as a human. (you could slow the game down of course)
comment by Review Bot · 2024-02-24T09:40:29.463Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Review Bot · 2024-02-24T09:40:29.176Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?