What will GPT-2030 look like?
post by jsteinhardt · 2023-06-07T23:40:02.925Z · LW · GW · 43 commentsContents
1. Specific Capabilities 2. Inference Speed 3. Throughput and Parallel Copies 4. Knowledge Sharing 5. Modalities, Tools, and Actuators 6. Implications of GPT-2030 Appendix: Runtime and Training Estimates for Future Models A. Words per minute B. Training overhang None 43 comments
GPT-4 surprised many people with its abilities at coding, creative brainstorming, letter-writing, and other skills. Surprises in machine learning are not restricted to GPT-4: I was previously surprised by Minerva’s mathematical abilities, as were many competitive forecasters.
How can we be less surprised by developments in machine learning? Our brains often implicitly make a zeroth-order forecast: looking at the current state of the art, and adding on improvements that “feel reasonable”. But what “seems reasonable” is prone to cognitive bias, and will underestimate progress in a fast-moving field like ML. A more effective approach is first-order forecasting: quantifying the historical rate of progress and extrapolating it forward, while also considering reasons for possible slowdowns or speedups.[1]
In this post, I’ll use this approach to forecast the properties of large pretrained ML systems in 2030. I’ll refer throughout to “GPT2030”, a hypothetical system that has the capabilities, computational resources, and inference speed that we’d project for large language models in 2030 (but which was likely trained on other modalities as well, such as images). To forecast GPT2030’s properties, I consulted a variety of sources, including empirical scaling laws, projections of future compute and data availability, velocity of improvement on specific benchmarks, empirical inference speed of current systems, and possible future improvements in parallelism.
GPT2030’s capabilities turn out to be surprising (to me at least). In particular, GPT2030 will enjoy a number of significant advantages over current systems[2], as well as (in at least some important respects) current human workers:
- GPT2030 will likely be superhuman at various specific tasks, including coding, hacking, and math, and potentially protein engineering (Section 1).
- GPT2030 can “work” and “think” quickly: I estimate it will be 5x as fast as humans as measured by words processed per minute [range: 0.5x-20x][3], and that this could be increased to 125x by paying 5x more per FLOP (Section 2).
- GPT2030 can be copied arbitrarily and run in parallel. The organization that trains GPT2030 would have enough compute to run many parallel copies: I estimate enough to perform 1.8 million years of work when adjusted to human working speeds [range: 0.4M-10M years] (Section 3). Given the 5x speed-up in the previous point, this work could be done in 2.4 months.
- GPT2030's copies can share knowledge due to having identical model weights, allowing for rapid parallel learning: I estimate 2,500 human-equivalent years of learning in 1 day (Section 4).
- GPT2030 will be trained on additional modalities beyond text and images, possibly including counterintuitive modalities such as molecular structures, network traffic, low-level machine code, astronomical images, and brain scans. It may therefore possess a strong intuitive grasp of domains where we have limited experience, including forming concepts that we do not have (Section 5).
These capabilities would, at minimum, accelerate many areas of research while also creating serious vectors for misuse (Section 6). Regarding misuse, GPT2030's programming abilities, parallelization, and speed would make it a potent cyberoffensive threat. Additionally, its rapid parallel learning could be turned towards human behavior and thus used to manipulate and misinform with the benefit of thousands of "years" of practice.
On acceleration, a main bottleneck will be autonomy. In a domain like mathematics research where work can be checked automatically, I’d predict that GPT2030 will outcompete most professional mathematicians. In machine learning, I’d predict that GPT2030 will independently execute experiments and generates plots and write-ups, but that graduate students and research scientists will provide direction and evaluate results. In both cases, GPT2030 will be an integral part of the research process.
My forecast of GPT2030’s properties are not intuitive from looking at today’s systems, and they may be wrong, since there is significant uncertainty about how ML will look in 2030. However, properties (1.-5.) above are my median bet, and whatever GPT2030 is like, I doubt it will be “GPT-4 but a bit better”.
If I’m right, then whatever the impacts of AI are, they won’t be small. We should be preparing for those impacts now, asking what will happen at the largest scales (on the order of $1T, 10M lives, or significant disruptions to social processes). It’s better to be surprised now, rather than in 7 years when the system is already being rolled out.
1. Specific Capabilities
I expect GPT2030 to have superhuman coding, hacking, and mathematical abilities. I also expect it to be superhuman in its ability to read and process large corpora for patterns and insights and to recall facts. Finally, since AlphaFold and AlphaZero had superhuman abilities in protein engineering and game-playing, GPT2030 could as well, for instance if it was trained multimodally on similar data to the AlphaFold/AlphaZero models.
Programming. GPT-4 outperformed a strong human baseline on LeetCode problems posed after its training cutoff (Bubeck et al. 2023, Table 2), and passed the mock interview for several major tech companies (Figure 1.5). The velocity of improvement remains high, with a 19% jump from GPT-3 to 4. On the more challenging CodeForces competition, GPT-4 does less well, but AlphaCode is on par with the median CodeForces competitor. On the even more challenging APPS dataset, Parsel further outperforms AlphaCode (7.8%->25.5%). Looking forward, the forecasting platform Metaculus gives a median year of 2027 for 80% on APPS, which would exceed all but the very best humans.[4]
Hacking. I expect hacking to improve with general coding ability, plus ML models can scour large codebases for vulnerabilities much more scalably and conscientiously than humans. ChatGPT has already been used to generate exploits, including polymorphic malware, which is typically considered to be an advanced offensive capability.
Math. Minerva achieved 50% accuracy on a competition math benchmark (MATH), which is better than most human competitors. The velocity of progress is high (>30% in 1 year), and there is significant low-hanging fruit via autoformalization, reducing arithmetic errors, improving chain-of-thought, and better data[5]. Metaculus predicts 92% on MATH by 2025, and gives a median year of 2028 for AI winning a gold medal at the International Math Olympiad, on par with the best high school students in the world. I personally expect GPT2030 to be better than most professional mathematicians at proving well-posed theorems.[6]
Information processing. Factual recall and processing large corpora are natural consequences of language models’ memorization capabilities and large context windows. Empirically, GPT-4 achieves 86% accuracy on MMLU, a broad suite of standardized exams including the bar exam, MCAT, and college math, physics, biochemistry, and philosophy; even accounting for likely train-test contamination, this probably exceeds the breadth of knowledge of any living human. Regarding large corpora, Zhong et al. (2023) used GPT-3 to construct a system that discovered and described several previously unknown patterns in large text datasets, and scaling trends on a related task in Bills et al. (2023) suggest that models will soon be superhuman. Both of these works exploit the large context windows of LLMs, which are now over 100,000 tokens and growing.
More generally, ML models have a different skill profile than humans, since humans and ML were adapted to very different data sources (evolution vs. massive internet data). At the point that models are human-level at tasks such as video recognition, they will likely be superhuman at many other tasks (such as math, programming, and hacking). Furthermore, additional strong capabilities will likely emerge over time due to larger models and better data, and there is no strong reason to expect model capabilities to “level out” at or below human-level. While it is possible that current deep learning approaches will fall short of human-level capabilities in some domains, it is also possible that they will surpass them, perhaps significantly, especially in domains such as math that humans are not evolutionarily specialized for.
2. Inference Speed
(Thanks to Lev McKinney for running the performance benchmarks for this section.)
To study the speed of ML models, we’ll measure how quickly ML models generate text, benchmarking against the human thinking rate of 380 words per minute (Korba (2016), see also Appendix A). Using OpenAI's chat completions API, we estimate that gpt-3.5-turbo can generate 1200 words per minute (wpm), while gpt-4 generates 370 wpm, as of early April 2023. Smaller open source models like pythia-12b achieve at least 1350 wpm with out-of-the-box tools on an A100 GPU, and twice this appears possible with further optimization.
Thus, if we consider OpenAI models as of April, we are either at roughly 3x human speed, or equal to human speed. I predict that models will have faster inference speed in the future, as there are strong commercial and practical pressures towards speeding up inference. Indeed, in the week leading up to this post, GPT-4’s speed already increased to around 540wpm (12 tokens/second), according to Fabien Roger’s tracking data; this illustrates that there is continuing room and appetite for improvement.
My median forecast is that models will have 5x the words/minute of humans (range: [0.5x, 20x]), as that is roughly where there would be diminishing practical benefits to further increases, though there are considerations pointing to both higher or lower numbers. I provide a detailed list of these considerations in Appendix A, as well as comparisons of speeds across model scales and full details of the experiments above.
Importantly, the speed of an ML model is not fixed. Models’ serial inference speed can be increased by $k^2$ at a cost of a $k$-fold reduction in throughput (in other words, $k^3$ parallel copies of a model can be replaced with a single model that is $k^2$ times faster). This can be done via a parallel tiling scheme that theoretically works even for large values of $k^2$, likely at least 100 and possibly more. Thus, a model that is 5x human speed could be sped up to 125x human speed by setting $k=5$.
An important caveat is that speed is not necessarily matched by quality: as discussed in Section 1, GPT2030 will have a different skill profile than humans, failing at some tasks we find easy and mastering some tasks we find difficult. We should therefore not think of GPT2030 as a "sped-up human", but as a "sped-up worker" with a potentially counterintuitive skill profile.
Nevertheless, considering speed-ups is still informative, especially when they are large. For language models with a 125x speed-up, cognitive actions that take us a day could be completed in minutes, assuming they were within GPT2030's skill profile. Using the earlier example of hacking, exploits or attacks that are slow for us to generate could be created quickly by ML systems.
3. Throughput and Parallel Copies
Models can be copied arbitrarily subject to available compute and memory. This allows them to quickly do any work that can be effectively parallelized. In addition, once one model is fine-tuned to be particularly effective, the change could be immediately propagated to other instances. Models could also be distilled for specialized tasks and thus run faster and more cheaply.
There will likely be enough resources to run many copies of a model once it has been trained. This is because training a model requires running many parallel copies of it, and whatever organization trained the model will still have those resources at deployment time. We can therefore lower bound the number of copies by estimating training costs.
As an example of this logic, the cost of training GPT-3 was enough to run it for 9 x 1011 forward passes. To put that into human-equivalent terms, humans think at 380 words per minute (see Appendix A) and one word is 1.33 tokens on average, so 9 x 1011 forward passes corresponds to ~3400 years of work at human speed. Therefore, the organization could run 3400 parallel copies of the model for a full year at human working-speeds, or the same number of copies for 2.4 months at 5x human speed.
Let's next project this same “training overhang” (ratio of training to inference cost) for future models. It should be larger: the main reason is that training overhang is roughly proportional to dataset size, and datasets are increasing over time. This trend will be slowed as we run out of naturally-occuring language data, but new modalities as well as synthetic or self-generated data will still push it forward.[7] In Appendix B, I consider these factors in detail to project forward to 2030. I forecast that models in 2030 will be trained with enough resources to perform 1,800,000 years of work adjusted to human speed [range: 400k-10M].
Note that Cotra (2020) [LW · GW] and Davidson (2023) estimate similar quantities and arrive at larger numbers than me; I'd guess the main difference is how I model the effect of running out of natural language data.
The projection above is somewhat conservative, since models may be run on more resources than they were trained on if the organization buys additional compute. A quick ballpark estimate suggests that GPT-4 was trained on about 0.01% of all computational resources in the world, although I expect future training runs to use up a larger share of total world compute and therefore have less room to scale up further after training. Still, an organization could possibly increase the number of copies they run by another order of magnitude if they had strong reasons to do so.
4. Knowledge Sharing
(Thanks to Geoff Hinton who first made this argument to me.)
Different copies of a model can share parameter updates. For instance, ChatGPT could be deployed to millions of users, learn something from each interaction, and then propagate gradient updates to a central server where they are averaged together and applied to all copies of the model. In this way, ChatGPT could observe more about human nature in an hour than humans do in a lifetime (1 million hours = 114 years). Parallel learning may be one of the most important advantages models have, as it means they can rapidly learn any missing skills.
The rate of parallel learning depends on how many copies of a model are running at once, how quickly they can acquire data, and whether the data can be efficiently utilized in parallel. On the last point, even extreme parallelization should not harm learning efficiency much, as batch sizes in the millions are routine in practice, and the gradient noise scale (McCandlish et al., 2018) predicts minimal degradation in learning performance below a certain “critical batch size”. We'll therefore focus on parallel copies and data acquisition.
I will provide two estimates that both suggest it would be feasible to have at least ~1 million copies of a model learning in parallel at human speed. This corresponds to 2500 human-equivalent years of learning per day, since 1 million days = 2500 years.
The first estimate uses the numbers from Section 3, which concluded that the cost of training a model is enough to simulate models for 1.8M years of work (adjusted to human speed). Assuming that the training run itself lasted for less than 1.2 years (Sevilla et al., 2022), this means the organization that trained the model has enough GPUs to run 1.5M copies at human speed.
The second estimate considers the market share of the organization deploying the model. For example, if there are 1 million users querying the model at a time, then the organization necessarily has the resources to serve 1 million copies of the model. As a ballpark, ChatGPT had 100 million users as of May 2023 (not all active at once), and 13 million active users/day as of January 2023. I’d assume the typical user is requesting a few minutes worth of model-generated text, so the January number probably only implies around 0.05 million person-days of text each day. However, it seems fairly plausible that future ChatGPT-style models would 20x this, reaching 250 million active users/day or more and hence 1 million person-days of data each day. As a point of comparison, Facebook has 2 billion daily active users.
5. Modalities, Tools, and Actuators
Historically, GPT-style models have primarily been trained on text and code, and had limited capacity to interact with the outside world except via chat dialog. However, this is rapidly changing, as models are being trained on additional modalities such as images, are being trained to use tools, and are starting to interface with physical actuators. Moreover, models will not be restricted to anthropocentric modalities such as text, natural images, video, and speech---they will likely also be trained on unfamiliar modalities such as network traffic, astronomical images, or other massive data sources.
Tools. Recently-released models use external tools, as seen with ChatGPT plugins as well as Schick et al. (2023), Yao et al. (2022), and Gao et al. (2022). Text combined with tool use is sufficient to write code that gets executed, convince humans to take actions on their behalf, make API calls, make transactions, and potentially execute cyberattacks. Tool use is economically useful, so there will be strong incentives to further develop this capability.
ChatGPT is reactive: user says X, ChatGPT responds with Y. Risks exist but are bounded. Soon it will be tempting to have proactive systems - an assistant that will answer emails for you, take actions on your behalf, etc. Risks will then be much higher.
— Percy Liang (@percyliang) February 27, 2023
New modalities. There are now large open-source vision-language models such as OpenFlamingo, and on the commercial side, GPT-4 and Flamingo were both trained on vision and text data. Researchers are also experimenting with more exotic pairs of modalities such as proteins and language (Guo et al., 2023).
We should expect the modalities of large pretrained models to continue to expand, for two reasons. First, economically, it is useful to pair language with less familiar modalities (such as proteins) so that users can benefit from explanations and efficiently make edits. This predicts multimodal training with proteins, biomedical data, CAD models, and any other modality associated with a major economic sector.
Second, we are starting to run out of language data, so model developers will search for new types of data to continue benefiting from scale. Aside from the traditional text and videos, some of the largest existing sources of data are astronomical data (will soon be at exabytes per day) and genomic data (around 0.1 exabytes/day). It is plausible that these and other massive data sources will be leveraged for training GPT2030.
The use of exotic modalities means that GPT2030 might have unintuitive capabilities. It might understand stars and genes much better than we do, even while it struggles with basic physical tasks. This could lead to surprises, such as designing novel proteins, that we would not have expected based on GPT2030’s level of “general” intelligence. When thinking about the impacts of GPT2030, it will be important to consider specific superhuman capabilities it might possess due to these exotic data sources.
Actuators. Models are also beginning to use physical actuators: ChatGPT has already been used for robot control and OpenAI is investing in a humanoid robotics company. However, it is much more expensive to collect data in physical domains than digital domains, and humans are also more evolutionarily adapted to physical domains (so the bar for ML models to compete with us is higher). Compared to digital tools, I’d therefore expect mastery of physical actuators to occur more slowly, and I’m unsure if we should expect it by 2030. Quantitatively, I’d assign 40% probability to there being a general-purpose model in 2030 that is able to autonomously assemble a scale-replica Ferrari as defined in this Metaculus question.
6. Implications of GPT-2030
We’ll next analyze what a system like GPT2030 would mean for society. A system with GPT2030’s characteristics would, at minimum, significantly accelerate some areas of research, while also possessing powerful capacities for misuse.
I’ll start by framing some general strengths and limitations of GPT2030, then use this as a lens to analyze both acceleration and misuse.
Strengths. GPT2030 represents a large, highly adaptable, high-throughput workforce. Recall that GPT2030 could do 1.8 million years of work[8] across parallel copies, where each copy is run at 5x human speed. This means we could simulate 1.8 million agents working for a year each in 2.4 months. As discussed above, we could also instead run 1/5 as many copies at 125x human speed, so we could simulate 360,000 agents working for a year each in 3 days.
Limitations. There are three obstacles to utilizing this digital workforce: skill profile, experiment cost, and autonomy. On the first, GPT2030 will have a different skill profile from humans that makes it worse at some tasks (but better at others). On the second, simulated workers still need to interface with the world to collect data, which has its own time and compute costs. Finally, on autonomy, models today can only generate a few thousand tokens in a chain-of-thought before getting “stuck”, entering a state where they no longer produce high-quality output. We’d need significant increases in reliability before delegating complex tasks to models. I expect reliability to increase, but not without limit: my (very rough) guess is that GPT2030 will be able to run for several human-equivalent days before having to be reset or steered by external feedback. If models run at a 5x speed-up, that means they need human oversight every several hours.
Therefore, the tasks that GPT2030 would most impact are tasks that:
- Leverage skills that GPT2030 is strong at relative to humans.
- Only require external empirical data that can be readily and quickly collected (as opposed to costly physical experiments).
- Can be a priori decomposed into subtasks that can be performed reliably, or that have clear and automatable feedback metrics to help steer the model.
Acceleration. One task that readily meets all three criteria is mathematics research. On the first, GPT2030 will likely have superhuman mathematical capabilities (Section 1). On the second and third, math can be done purely by thinking and writing, and we know when a theorem has been proved. There are furthermore not that many mathematicians in total in the world (e.g. only 3,000 in the US) so GPT2030 could simulate 10x or more the annual output of mathematicians every few days.
Significant parts of ML research also meet the criteria above. GPT2030 would be superhuman at programming, which includes implementing and running experiments. I’d guess it will also be good at presenting and explaining the results of experiments, given that GPT-4 is good at explaining complex topics in an accessible way (and there is significant market demand for this). Therefore, ML research might reduce to thinking up good experiments to run and interfacing with high-quality (but potentially unreliable) write-ups of the results. In 2030, grad students might therefore have the same resources as a professor with several strong students would have today.
Parts of social science could also be significantly accelerated. There are many papers where the majority of the work is chasing down, categorizing, and labeling scientifically interesting sources of data and extracting important patterns—see Acemoglu et al. (2001) or Webb (2020) for representative examples. This satisfies requirement (3.) because categorization and labeling can be decomposed into simple subtasks, and it satisfies requirement (2.) as long as the data is available on the internet, or could be collected through an online survey.
Misuse. Beyond acceleration, there would be serious risks of misuse. The most direct case is cyberoffensive hacking capabilities. Inspecting a specific target for a specific style of vulnerability could likely be done reliably, and it is easy to check if an exploit succeeds (subject to being able to interact with the code), so requirement (3.) is doubly satisfied. On (2.), GPT2030 would need to interact with target systems to know if the exploit works, which imposes some cost, but not enough to be a significant bottleneck. Moreover, the model could locally design and test exploits on open source code as a source of training data, so it could become very good at hacking before needing to interact with any external systems. Thus, GPT2030 could rapidly execute sophisticated cyberattacks against large numbers of targets in parallel.
A second source of misuse is manipulation. If GPT2030 interacts with millions of users at once, then it gains more experience about human interaction in an hour than a human does in their lifetime (1 million hours = 114 years). If it used these interactions to learn about manipulation, then it could obtain manipulation skills that are far greater than humans—as an analogy, con artists are good at tricking victims because they’ve practiced on hundreds of people before, and GPT2030 could scale this up by several orders of magnitude. It could therefore be very good at manipulating users in one-on-one conversation, or at writing news articles to sway public opinion.
Thus in summary, GPT2030 could automate almost all mathematics research as well as important parts of other research areas, and it could be a powerful vector of misuse regarding both cyberattacks and persuasion/manipulation. Much of its impact would be limited by “oversight bottlenecks”, so if it could run autonomously for long periods of time then its impact may be larger still.
Thanks to Louise Verkin for transcribing this post to Ghost format, and Lev McKinney for running empirical benchmark experiments. Thanks to Karena Cai, Michael Webb, Leo Aschenbrenner, Anca Dragan, Roger Grosse, Lev McKinney, Ruiqi Zhong, Sam Bowman, Tatsunori Hashimoto, Percy Liang, Tom Davidson, and others for providing feedback on drafts of this post.
Appendix: Runtime and Training Estimates for Future Models
A. Words per minute
First we’ll estimate the word per minute of humans and of current models. Then we’ll extrapolate from current models to future models.
For humans, there are five numbers we could measure: talking speed, reading speed, listening speed, and both “elliptic” and “extended” thinking speed. Regarding the first three, Rayner and Clifton (2009) say that reading speed is 300 words per minute[9] and speaking is 160 words per minute[10], and that listening can be done 2-3 times faster than speaking (so ~400 words per minute)[11]. For thinking speed, we need to distinguish between “elliptic” and “extended” thought—it turns out that we think in flashes of words rather than complete sentences, and if we extend these flashes to full sentences we get very different word counts (~10x different). Korba (2016) find that elliptic thought is 380 words per minute while extended thought is ~4200 words per minute. Since most of these numbers cluster in the 300-400 wpm range, I’ll use 380 words per minute as my estimate of human thinking speed. Using the 4:3 token to word ratio suggested by OpenAI, this comes out to 500 tokens per minute.[12]
(Thanks to Lev McKinney for running the evaluations in the following paragraphs.)
Next, let’s consider current models. We queried gpt-3.5-turbo and gpt-4, as well as several open source models from EleutherAI, to benchmark their inference speed. We did this by querying the models to count from 1 to n, where n ranged from 100 to 1900 inclusive in increments of 100. Since numbers contain more than one token, we cut the model off when it reached n tokens generated, and measured the time elapsed. We then ran a linear regression with a bias term to account for latency in order to estimate the asymptotic number of tokens per second.
GPT-4 and GPT-3.5-turbo were queried from the OpenAI AIP in early April 2023. All experiments for the pythia models were performed using deepspeed's injected kernels and fp16 models on a single A100 GPU.[13] Code for replicating these results can be found at https://github.com/levmckinney/llm-racing.
The raw data is plotted in Figure 1 below, while Figure 2 and Table 1 give the resulting estimated tokens per minute.
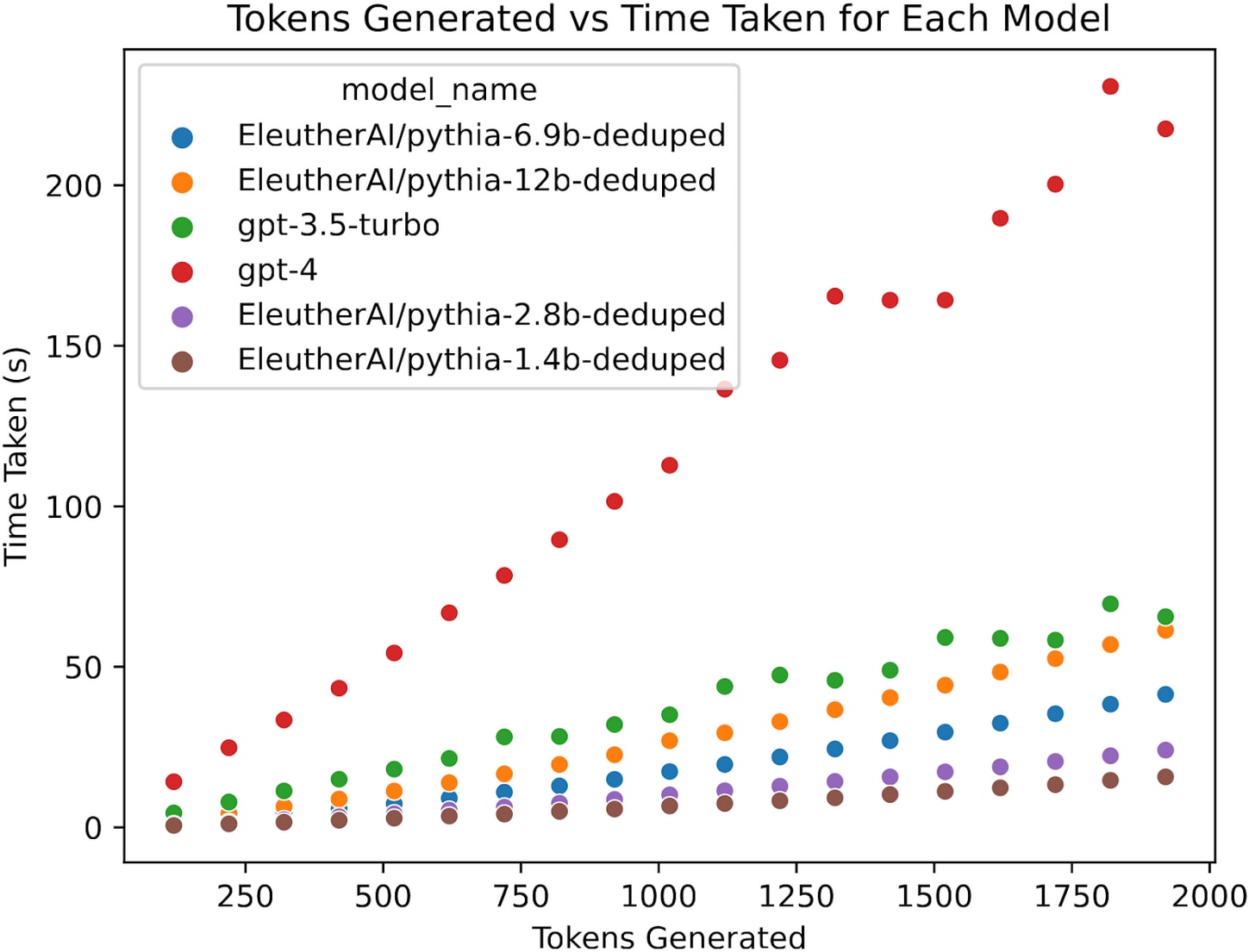
Figure 1 demonstrates how model inference scales with token input. Note that time per token remains relatively linear at these context lengths.
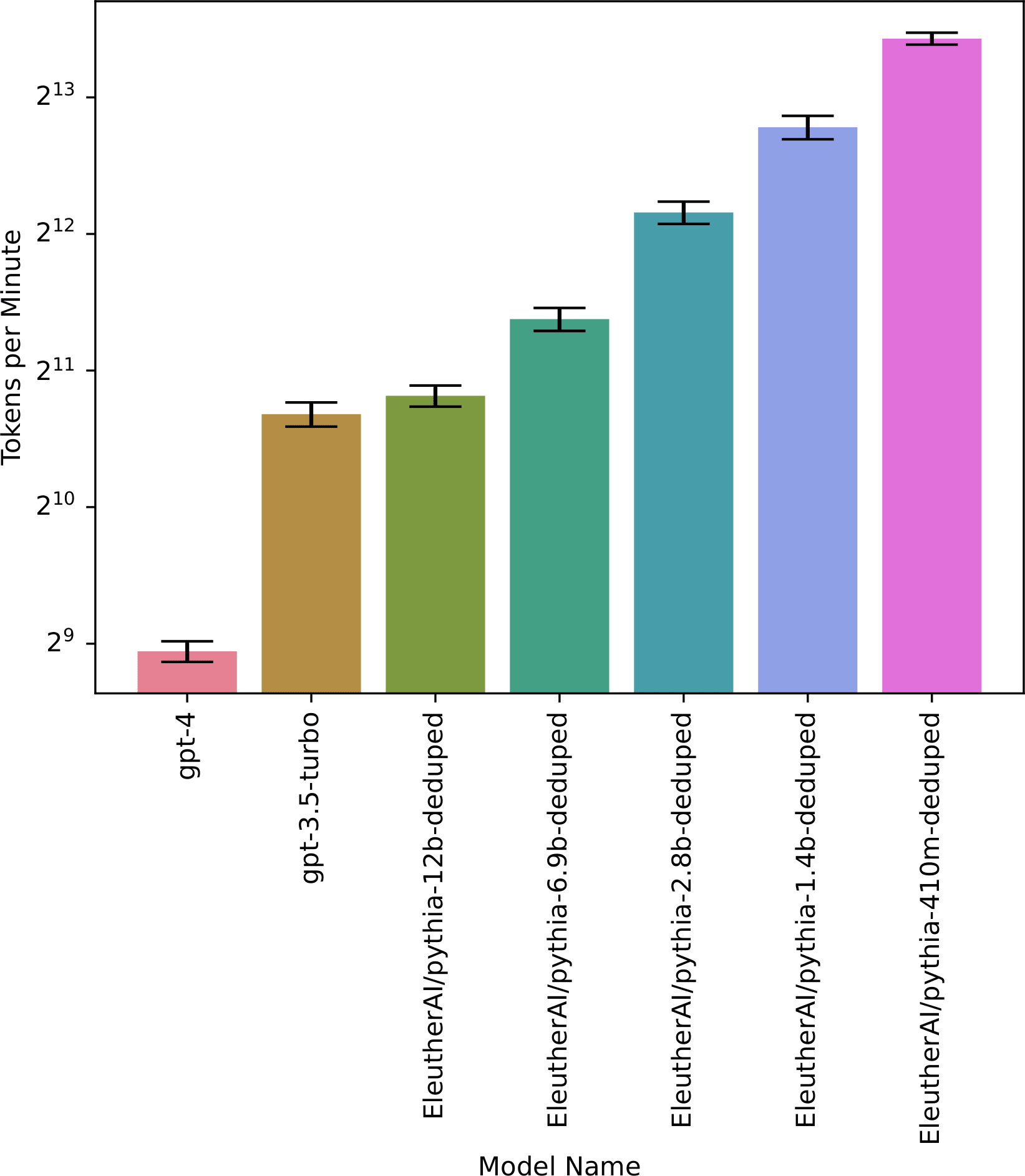
Figure 2 and the table below demonstrates how model inference speed scales with size. Error bars are 95% confidence intervals.
| Model name | Tokens per minute |
|---|---|
| gpt-4 | 493 |
| gpt-3.5-turbo | 1641 |
| EleutherAI/pythia-12b-deduped | 1801 |
| EleutherAI/pythia-6.9b-deduped | 2659 |
| EleutherAI/pythia-2.8b-deduped | 4568 |
| EleutherAI/pythia-1.4b-deduped | 7040 |
| EleutherAI/pythia-410m-deduped | 11039 |
| EleutherAI/pythia-160m-deduped | 21580 |
| EleutherAI/pythia-70m-deduped | 31809 |
Thus, GPT-4 is close to the human benchmark of 500 tokens/minute, while GPT-3.5-turbo is about 3x faster. Smaller models are an order of magnitude faster still, which indicates that even faster inference is possible, although it also suggests that future larger models may be slower (not accounting for better hardware and other optimizations). Inference speed in practice seems to slow down sublinearly with model size–in the pythia models, increasing size by a factor of k decreases inference speed by approximately k0.6.
How will models’ words per minute change in the future? There are factors pushing towards both faster and slower speeds:
- Larger models are more expensive to run, especially if they have more layers (larger widths can be parallelized, but larger depths cannot be).
- Inference will generally be optimized more, e.g. via early exiting, sparse attention, cross-GPU parallelization, or better hardware. There is quite a bit of headroom here, especially from parallelization and hardware (see discussion below).
- In particular, there will be quite a bit of incentive to make models fast enough to be easily usable (e.g. faster than human reading speed).
- After staring at lots of data about trends in model size, GPU architecture, etc. for 10+ hours, I mostly concluded that I am very uncertain about how the competing trends of larger models vs. better hardware and software will play out. My median guess would be that we get models that are noticeably faster than humans (5x), but I wouldn’t be surprised by anything from 2x slower to 20x faster.
- Importantly, these speeds are only if we demand maximum throughput from the GPUs. If we are willing to sacrifice throughput by a factor of k, we can speed up inference by a factor of k^2, up to fairly large values of k. So if models are only 5x faster than humans by default, they could instead be 125x faster in exchange for a 5x reduction in throughput, and this could be pushed further still if necessary.
Finally, aside from raw speed, words/minute isn’t apples-to-apples across humans and language models. For one, the language models aren’t just thinking but also writing, and in some cases they are writing content that would be much slower for humans to produce (e.g. code, or arguments with references). In the other direction, language models are currently quite verbose, so one word from a language model does less “work” than one word from a human. This verbosity could be fine-tuned away, but it’s not clear we could match the efficiency of elliptic thought in humans. Finally, tokenization and word complexity will change over time, and so the 1.333x conversation ratio from words to tokens won’t stay constant (indeed, I’d guess it’s already an underestimate for today’s models since they now tend to use complex words with prefixes and suffixes).
Details on parallelization and hardware speed-ups. As described in How Fast Can We Perform a Forward Pass?, there are parallel tiling schemes that significantly increase serial inference speed with only minor overhead. For instance, parallel tiling of GPT-3 would increase its inference speed by 30x or more on an A100 cluster relative to running it on a single 8-GPU machine[14]. These optimizations are not currently widely used because they aren’t useful for training and slightly decrease inference throughput, but people would start using them once inference time becomes a bottleneck.
For hardware, GPUs are becoming more powerful, which will speed up inference. However, GPUs are also being built to require larger arithmetic intensity, which will decrease the amount of parallel tiling (see previous point) that is possible. For reference, I’ve included the specs of all NVIDIA GPUs below. The “Mem Bandwidth” column measures the serial throughput without any cross-GPU parallelization[15], while the final M3/C2 column measures serial throughput with the maximum cross-GPU parallelization that maintains high enough arithmetic intensity[16]. The former is steadily increasing, while the latter jumps around but has tended to decrease.
| Date | GPU | Compute | Memory | Clock Speed | Mem Bandwidth | Interconnect | Network | M^3 / C^2 |
|---|---|---|---|---|---|---|---|---|
| 05/2016 | P100 | ~84TF | 16GB | 1.45GHz | 720GB/s | 160GB/s | 53M | |
| 12/2017 | V100 16GB | 125TF | 16GB | 1.49GHz | 900GB/s | 300GB/s | ~25GB/s | 47M |
| 03/2018 | V100 32GB | 125TF | 32GB | 1.49GHz | 900GB/s | 300GB/s | ~100GB/s | 47M |
| 05/2020 | A100 40GB | 312 TF | 40GB | 1.38GHz | 1555GB/s | 600GB/s | ~400GB/s | 39M |
| 11/2020 | A100 80GB | 312 TF | 80GB | 1.38GHz | 2039GB/s | 600GB/s | ~400GB/s | 87M |
| ~8/2022 | H100 | 2000 TF | 80GB | 1.74GHz | 3072GB/s | 900GB/s | 900GB/s? | 7.2M |
B. Training overhang
There will likely be enough resources to run many copies of a model once it has been trained. GPT-3 took 3.1e23 FLOPs to train and requires 3.5e11 FLOPs for a forward pass, so 9e11 forward passes could be run for the cost of training. Using the 500 tokens per minute conversion from Appendix A, this would correspond to ~3400 human-years of thinking.
How will this change in the future? I’ll use the Chinchilla scaling law and projections of future training costs to form an initial estimate, then I’ll consider ways we could deviate from the Chinchilla trend. For future training costs, I consider the projection in Besiroglu et al. (2022), who analyzed over 500 existing models to extrapolate compute trends in machine learning. Their central projection of training FLOPs in 2030 is 4.7e28, with a range of 5.1e26 to 3.0e30. Metaculus has a similar estimate of 2.3e27 (for Jan 1, 2031)[17]. Taking the geometric median, I’ll use 1.0e28 as my estimate of training FLOPs, or a 33,000-fold increase over GPT-3. Since the Chinchilla scaling law implies that model size (and hence inference cost) scales as the square-root of training cost, this means the training overhang should increase by sqrt(33000), or around 180-fold. The 3400 human-years of thinking would thus increase to 620,000 human-years. However, there’s an additional consideration, which is that GPT-3 was actually trained with suboptimal scaling. The ideal size of GPT-3 (given its training cost) would have been 4 times smaller, so we need to add an additional factor of 4, to get 2.5M human-years, with a range from 0.8M to 9M accounting for uncertainty in the number of training FLOPs[18].
Next, let’s consider deviations from the Chinchilla scaling law. The most obvious deviation is that we might soon run out of data. This could either mean that larger models becomes more attractive relative to more data (which would decrease training overhang), or that we generate additional synthetic data (makes creating data more computationally-expensive, which would increase training overhang), or we move to new data-rich modalities such as video (unclear effect on training overhand, probably increases it). To roughly bound these effects:
- Lower bound: Villalobos et al. (2022) estimate that we will run out of high-quality language data (e.g. Wikipedia, books, scientific papers, etc.) by 2026, although we will not run out of low-quality data (e.g. web pages) before 2030. In a pessimistic world where high-quality data is a completely binding constraint, the model in Villalobos et al. implies an 8x increase in dataset size by 2030, meaning the training overhang would increase only 8-fold instead of 180-fold.
- Upper bound: If we run out of data, we might generate new data synthetically. One possibility for this is chain-of-thought distillation as in Huang et al. (2022). In that paper, 32 chains of thought are generated on each input instance, only some of which are used for training updates. Assume that on average 5 of the 32 chains of thought get used for training updates, and that a backward pass is twice the cost of a forward pass. Then the cost per training update is equivalent to 2 + 32/5 = 8.4 forward passes, compared to 3 previously, or a 2.8x increase. Under Chinchilla scaling this cost propagates forward to an additional sqrt(2.8) = 1.7x increase in training overhang, i.e. 300-fold instead of 180-fold.
Overall, the lower bound seems fairly pessimistic to me as we’ll almost certainly find some way to leverage lower-quality or synthetic data. On the other hand, beyond running out of data, we might find ways to make the training process more efficient via e.g. curriculum learning. Accounting for this, my personal guess is we will end up somewhere between a 12-fold and 200-fold increase in overhang, with a central estimate of 100x, yielding a training overhang of around 1.8M human-years of thinking. We would also want to expand our range to account for the additional uncertainty from deviations to the Chinchilla scaling law. Subjectively, I’d increase the range to be 0.4M to 10M.
All of these estimates are for 2030. In general, the numbers above would be larger for later years and smaller for earlier years.
As an additional point of comparison, Karnofsky (2022) (following Cotra, 2020 [LW · GW]) estimates that the cost to train a human-level model would be enough compute to run 100 million copies of the model for a year each, although that estimate assumes training runs that use 1e30 FLOPs instead of 1e28. Even accounting for that, this seems a bit high to me, and I’d have been closer to 18 million than 100 million based on the square-root scaling above.
Though actually, zeroth order forecasting already helps a lot if done right! Many who were surprised by ChatGPT would have already been impressed by text-davinci-003, which was released much earlier but with a less user-friendly interface. ↩︎
As a specific point of comparison, GPT-3 only had enough compute to run 3400 human-adjusted years of work, and I'd guess it could do less than 100 human-adjusted years of learning per day. I'd guess GPT-4 is at 130,000 human-adjusted years of work and 125 adjusted years of learning. So GPT2030 is at least an order of magnitude larger on both axes. ↩︎
Throughout, the range in brackets represents the 25th to 75th percentile of my predictive distribution. In practice the range is probably too narrow because I only did a mainline forecast without accounting for “other” options. ↩︎
Qualitatively, GPT-4 Bubeck et al. also found that GPT-4 could produce a 400-line 3D game zero-shot, which is probably impossible for nearly all humans. ↩︎
See Forecasting ML Benchmarks in 2023 for some further discussion of this. ↩︎
Concretely, I’d assign 50% probability to the following: “If we take 5 randomly selected theorem statements from the Electronic Journal of Combinatorics and give them to the math faculty at UCSD, GPT2030 would solve a larger fraction of problems than the median faculty and have a shorter-than-median solve time on the ones that it does solve.” ↩︎
A second factor is that GPT-3 was trained suboptimally, and with optimal (Chinchilla-style) scaling the training overhang would be 4x larger already. ↩︎
Adjusted to human working speeds. ↩︎
“skilled readers typically reading at rates between 250-350 words per minute” ↩︎
“estimates of normal speaking rate range from 120 to 200 words per minute” ↩︎
“Experiments on compressed speech suggest that comprehension can be successful at two times or more the normal rate (e.g., Dupoux & Green, 1997)” ↩︎
I personally think that 4:3 is too optimistic and 3:2 or even 2:1 might be more realistic, but I’ll stick to 4:3 throughout the doc since it was the main citation I found. ↩︎
The performance for pythia models can likely be improved further. For instance, NVIDIA has reported about 80 tokens per second on a comparable model to pythia-6.9 billion on a single A100. When allowing for more hardware, they have even shown approximately 90 tokens per second using 8 way tensor parallelism on an 8xA100 SuperPod architecture when generating using a 20B parameter GPT model. ↩︎
A single A100 can handle matrix multiplies as small as 1024x1024 before becoming bottlenecked on memory reads, and the main operation in GPT-3 is a 12288 x (4*12288) matrix multiply, meaning we would tile it across 576 GPUs (72 machines). This would naively mean a 72x speedup, but there is probably enough overhead that I’m estimating closer to 30x. ↩︎
Roughly speaking, with no cross-GPU tiling, the serial speed of inference is determined by the memory bandwidth, e.g. the A100 with 2039GB/s bandwidth should be able to complete 2039/175 \approx 12 forward passes with a 175B parameter model per second (up to constant factors). ↩︎
With parallel tiling, the forward passes per second is proportional to M3/54C2L, where C = Compute, M = Mem bandwidth, and L = # of layers. (see here for details). The final column gives M3/C2. ↩︎
Metaculus also estimates that the largest model trained will have 2.5e15 parameters (for Jan 1, 2030), meaning a forward pass costs 5e15 FLOPs. If we naively take the ratio, we again get 9e11 forward passes, but I think this is not the right calculation, because the largest model trained will likely not be state-of-the-art but rather something like the 174 trillion parameter BaGuaLu model. ↩︎
I’m basing this on Metaculus giving a range of 5M to 660M as the interquartile range of their estimate, and propagating the uncertainty through the square-root function. ↩︎
43 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-06-08T04:02:46.911Z · LW(p) · GW(p)
Well said.
One thing conspicuously absent, IMO, is discussion of misalignment risk. I'd argue that GPT-2030 will be situationally aware, strategically aware, and (at least when plugged into fancy future versions of AutoGPT etc.) agentic/goal-directed. If you think it wouldn't be a powerful adversary of humanity, why not? Because it'll be 'just following instructions' and people will put benign instructions in the prompt? Because HFDT [AF · GW]will ensure that it'll robustly avoid POUDA? [LW · GW] Or will it in fact be a powerful adversary of humanity, but one that is unable to cause a point-of-no-return [LW · GW] or achieve powerbase ability [LW · GW], due to various capability limitations or safety procedures?
Another thing worth mentioning (though less important) is that if you think GPT-2030 would massively accelerate AI R&D, then you should probably think that GPT-2027 will substantially accelerate AI R&D, meaning that AIs with the abilities of GPT-2030 will actually appear sooner than 2030. You are no doubt familiar with Tom's takeoff model.
Finally, I'd be curious to hear where you got your rough guess about how long (in subjective time) GPT-2030 could run before getting stuck and needing human feedback. My prediction is that by the time it can reliably run for a subjective day across many diverse tasks, it'll get 'transfer learning' and 'generalization' benefits that cause it to very rapidly learn to go for subjective weeks, months, years, infinity. See this table [LW(p) · GW(p)] explaining my view by comparison to Richard Ngo's view. What do you think?
↑ comment by FinalFormal2 · 2023-06-08T18:20:47.935Z · LW(p) · GW(p)
I don't like the number of links that you put into your first paragraph. The point of developing a vocabulary for a field is to make communication more efficient so that the field can advance. Do you need an acronym and associated article for 'pretty obviously unintended/destructive actions,' or in practice is that just insularizing the discussion?
I hear people complaining about how AI safety only has ~300 people working about it, and how nobody is developing object level understandings and everyone's thinking from authority, but the more sentences you write like: "Because HFDT [LW · GW]will ensure that it'll robustly avoid POUDA [LW · GW]?" the more true that becomes.
I feel very strongly about this.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-06-08T20:54:41.823Z · LW(p) · GW(p)
Thanks for the feedback, I'll try to keep this in mind in the future. I imagine you'd prefer me to keep the links, but make the text use common-sense language instead of acronyms so that people don't need to click on the links to understand what I'm saying?
Replies from: FinalFormal2↑ comment by FinalFormal2 · 2023-06-09T06:34:32.647Z · LW(p) · GW(p)
That seems like a useful heuristic-
I also think there's an important distinction between using links in a debate frame and in a sharing frame.
I wouldn't be bothered at all by a comment using acronyms and links, no matter how insular, if the context was just 'hey this reminds me of HDFT and POUDA,' a beginner can jump off of that and get down a rabbit hole of interesting concepts.
But if you're in a debate frame, you're introducing unnecessary barriers to discussion which feel unfair and disqualifying. At its worst it would be like saying: 'youre not qualified to debate until you read these five articles.'
In a debate frame I don't think you should use any unnecessary links or acronyms at all. If you're linking a whole article it should be because it's necessary for them to read and understand the whole article for the discussion to continue and it cannot be summarized.
I think I have this principle because in my mind you cannot not debate so therefore you have to read all the links and content included, meaning that links in a sharing context are optional but in a debate context they're required.
I think on a second read your comment might have been more in the 'sharing' frame than I originally thought, but to the extent you were presenting arguments I think you should maximize legibility, to the point of only including links if you make clear contextually or explicitly to what degree the link is optional or just for reference.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-06-09T17:21:55.626Z · LW(p) · GW(p)
Thanks for that feedback as well -- I think I didn't realize how much my comment comes across as 'debate' framing, which now on second read seems obvious. I genuinely didn't intend my comment to be a criticism of the post at all; I genuinely was thinking something like "This is a great post. But other than that, what should I say? I should have something useful to add. Ooh, here's something: Why no talk of misalignment? Seems like a big omission. I wonder what he thinks about that stuff." But on reread it comes across as more of a "nyah nyah why didn't you talk about my hobbyhorse" unfortunately.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-06-12T17:45:05.162Z · LW(p) · GW(p)
As I read this post, I found myself puzzled by the omission of the potential of AI-research-acceleration by SotA AI models, as Daniel mentions in his comment. I think it's worth pointing out that this has been explicitly discussed by leading individuals in the big AI labs. For instance, Sam Altman saying that scaling is no longer the primary path forward in their work, that instead algorithmic advances are.
Think about your intuitions of what a smart and motivated human is capable of. The computations that that human brain is running represent an algorithm. From neuroscience we have a lot of information about the invariant organization of human brains, the architectural constraints and priors established during fetal development under guidance from the genome. The human brain's macroscale connectome is complicated and hacky, with a lot of weirdly specific and not fully understood aspects. The architectures currently used in ML are comparatively simple and have more uniform repeating structures. Some of the hacky specific brain connectome details are apparently very helpful though, considering how quickly humans do, in practice, learn. Figuring out what aspects of the brain would be useful to incorporate into ML models is exactly the sort of constrained engineering problem that ML excels at. Take in neuroscience data, design a large number of automated experiments, run the experiments in parallel, analyze and summarize the results, reward model for successes, repeat. The better our models get, and the more compute we have with which to do this automated search, the more likely we are to find something. The more advances we find, the faster and cheaper the process becomes and the more investment will be put into pursuing it. The combination of all of these factors implies a strong accelerating trend beyond a certain threshold. This trend, unlike scaling compute or data, is not expected to sigmoid-out before exceeding human intelligence. That's what makes this truely a big deal. Without this potential meta-growth, ML would be just a big deal instead of absolutely pivotal. Trying to project ML development without taking this into account is like watching a fuse burn towards a bomb, and trying to model the bomb like a somewhat unusually vigorous campfire.
↑ comment by Not Relevant (not-relevant) · 2023-06-08T14:10:49.227Z · LW(p) · GW(p)
Where does this “transfer learning across timespans” come from? The main reason I see for checking back in after 3 days is the model’s losing the thread of what the human currently wants, rather than being incapable of pursuing something for longer stretches. A direct parallel is a human worker reporting to a manager on a project - the worker could keep going without check-ins, but their mental model of the larger project goes out of sync within a few days so de facto they’re rate limited by manager check-ins.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-06-08T15:23:11.159Z · LW(p) · GW(p)
Responded in DM.
comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2023-06-08T05:01:12.968Z · LW(p) · GW(p)
Nit: I don’t consider polymorphic malware to be that advanced. I made some as a university project. It is essentially automated refactoring. All you need to do is replace sections of a binary with other functionally equivalent sections without breaking it, optionally adding some optimization so that the new variant is classified as benign.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2023-06-09T03:50:52.550Z · LW(p) · GW(p)
Thanks! I removed the link.
comment by 1a3orn · 2023-06-08T13:27:22.678Z · LW(p) · GW(p)
I will provide two estimates that both suggest it would be feasible to have at least ~1 million copies of a model learning in parallel at human speed. This corresponds to 2500 human-equivalent years of learning per day, since 1 million days = 2500 years.
This is potentially a little misleading, I think?
A human who learning does *active exploration". They seek out things that they don't know, and try to find blind spots. They loop around and try to connect pieces of their knowledge that were unconnected. They balance exploration and exploitation. 2500 years of this is a lot of time to dive deeply into individual topics, pursue them in depth, write new papers on them, talk with other people, connect them carefully, and so on.
An LLM learning from feedback on what it says doesn't do any of this. It isn't pursuing long-running threads over 2500-equivalent years, or seeking out blindspots in its knowledge -- it isn't trying to balance exploration and exploitation at all, because it's just trying to provide accurate answers to the questions given to it. There's even anti-blindspot feedback -- people are disproportionately going to ask LLMs about what people predict they'll do well at, rather than what they'll do poorly at! Which will limit the skills it picks up badly.
I don't know what that looks like in the limit. You could maintain that it's frighteningly smart, or still really stupid, or more likely both on different topics. But not sure human-equivalent years is going to give you a useful intuition for what this looks like at all. Like it's... some large amount of knowledge that is attainable from this info, but it isn't human-equivalent. Just a different kind of thing.
comment by reallyeli · 2023-06-08T06:02:12.477Z · LW(p) · GW(p)
Beyond acceleration, there would be serious risks of misuse. The most direct case is cyberoffensive hacking capabilities. Inspecting a specific target for a specific style of vulnerability could likely be done reliably, and it is easy to check if an exploit succeeds (subject to being able to interact with the code)
This one sticks out because cybersecurity involves attackers and defenders, unlike math research. Seems like the defenders would be able to use GPT_2030 in the same way to locate and patch their vulnerabilities before the attackers do.
It feels like GPT_2030 would significantly advantage the defenders, actually, relative to the current status quo. The intuition is that if I spend 10^1 hours securing my system and you spend 10^2 hours finding vulns, maybe you have a shot, but if I spend 10^3 hours on a similarly sized system and you spend 10^5, your chances are much worse. For example at some point I can formally verify my software.
Replies from: Kaj_Sotala, PeterMcCluskey, RussellThor, Gurkenglas↑ comment by Kaj_Sotala · 2023-06-08T15:59:35.473Z · LW(p) · GW(p)
Though note that this assumes that defenders are willing and capable of actually patching their systems. There are lots of people who are running outdated insecure versions of various pieces of software, product vendors with no process for patching their products (especially in the case of software embedded into physical products), etc.
E.g.:
This report analyses 127 current routers for private use developed by seven different large vendors selling their products in Europe. An automated approach was used to check the router’s most recent firmware versions for five security related aspects. [...]
Our results are alarming. There is no router without flaws. 46 routers did not get any security update within the last year. Many routers are affected by hundreds of known vulnerabilities. Even if the routers got recent updates, many of these known vulnerabilities were not fixed. What makes matters even worse is that exploit mitigation techniques are used rarely. Some routers have easy crackable or even well known passwords that cannot be changed by the user. [...]
Our analysis showed that Linux is the most used OS running on more than 90% of the devices. However, many routers are powered by very old versions of Linux. Most devices are still powered with a 2.6 Linux kernel, which is no longer maintained for many years. This leads to a high number of critical and high severity CVEs affecting these devices.
Also specifically on the topic of routers, but also applies to a lot of other hardware with embedded software:
The problem with this process is that no one entity has any incentive, expertise, or even ability to patch the software once it’s shipped. The chip manufacturer is busy shipping the next version of the chip, and the ODM is busy upgrading its product to work with this next chip. Maintaining the older chips and products just isn’t a priority.
And the software is old, even when the device is new. For example, one survey of common home routers found that the software components were four to five years older than the device. The minimum age of the Linux operating system was four years. The minimum age of the Samba file system software: six years. They may have had all the security patches applied, but most likely not. No one has that job. Some of the components are so old that they’re no longer being patched. This patching is especially important because security vulnerabilities are found “more easily” as systems age.
To make matters worse, it’s often impossible to patch the software or upgrade the components to the latest version. Often, the complete source code isn’t available. Yes, they’ll have the source code to Linux and any other open-source components. But many of the device drivers and other components are just ‘binary blobs’—no source code at all. That’s the most pernicious part of the problem: No one can possibly patch code that’s just binary.
Even when a patch is possible, it’s rarely applied. Users usually have to manually download and install relevant patches. But since users never get alerted about security updates, and don’t have the expertise to manually administer these devices, it doesn’t happen. Sometimes the ISPs have the ability to remotely patch routers and modems, but this is also rare.
The result is hundreds of millions of devices that have been sitting on the Internet, unpatched and insecure, for the last five to ten years.
On the software side, there was e.g. this (in 2015, don't know what the current situation is):
Replies from: lcmgcdA lot has been written about the security vulnerability resulting from outdated and unpatched Android software. The basic problem is that while Google regularly updates the Android software, phone manufacturers don’t regularly push updates out to Android users.
New research tries to quantify the risk:
We are presenting a paper at SPSM next week that shows that, on average over the last four years, 87% of Android devices are vulnerable to attack by malicious apps. This is because manufacturers have not provided regular security updates.
↑ comment by lemonhope (lcmgcd) · 2023-06-24T07:39:16.903Z · LW(p) · GW(p)
Great references - very informative - thank you. I am always yelling at random people on the street walking their dogs that they're probably hacked already based on my needs-no-evidence raw reasoning. I'll print this out and carry it with me next time
↑ comment by PeterMcCluskey · 2023-06-08T16:37:27.105Z · LW(p) · GW(p)
Verified safe software means the battle shifts to vulnerabilities in any human who has authority over the system.
Replies from: reallyeli↑ comment by RussellThor · 2023-06-08T08:00:19.550Z · LW(p) · GW(p)
I was about to make the same point. GPTx is trying to hack GPTx-1 at best. Unless there is a very sudden takeoff, important software will be checked, rechecked by all capable AI. Yud seems to miss this, (or believe the hard takeoff is so sudden that there won't be any GPTx-1 to make the code secure).
I remember when spam used to be a thing and people were breathlessly predicting a flood of Android viruses... Attack doesn't always get easier.
Replies from: sharmake-farah, boazbarak↑ comment by Noosphere89 (sharmake-farah) · 2023-06-08T12:40:21.007Z · LW(p) · GW(p)
Yep, cybersecurity is the biggest area where I suspect intelligence improvements will let the defense go very far ahead relative to attack, for complexity theory reasons, as well as other sorts of cryptography in the works.
IMO, if we survive, our era of hacking being easy will look like a lot the pirates' history: Used to be a big threat, but we no longer care because pirates can't succeed anymore.
Cryptography vs Cryptanalysis will probably go the same way as the anti-piracy forces vs pirate forces, a decisive victory for the defense in time.
↑ comment by boazbarak · 2023-06-10T16:22:52.219Z · LW(p) · GW(p)
Yes AI advances help both the attacker and defender. In some cases like spam and real time content moderation, they enable capabilities for the defender that it simply didn’t have before. In others it elevates both sides in the arms race and it’s not immediately clear what equilibrium we end up in.
In particular re hacking / vulnerabilities it’s less clear who it helps more. It might also change with time, with initially AI enabling “script kiddies” that can hack systems without much skill, and then an AI search for vulnerabilities and then fixing them becomes part of the standard pipeline. (Or if we’re lucky then the second phase happens before the first.)
Replies from: not-relevant, o-o↑ comment by Not Relevant (not-relevant) · 2023-06-10T22:07:13.250Z · LW(p) · GW(p)
Lucky or intentional. Exploit embargoes artificially weight the balance towards the defender - we should create a strong norm of providing defender access first in AI.
Replies from: boazbarak↑ comment by O O (o-o) · 2023-06-10T21:30:56.427Z · LW(p) · GW(p)
I think it’s clear in the scenario of hacker vs defender, the defender has a terminal state of being unhackable while the hacker has no such terminal state.
Replies from: boazbarak↑ comment by boazbarak · 2023-06-10T23:24:59.194Z · LW(p) · GW(p)
Yes in the asymptotic limit the defender could get to a bug free software. But until the. It’s not clear who is helped the most by advances. In particular sometimes attackers can be more agile in exploiting new vulnerabilities while patching them could take long. (Case in point, it took ages to get the insecure hash function MD5 out of deployed security sensitive code even by companies such as Microsoft; I might be misremembering but if I recall correctly Stuxnet relied on such a vulnerability.)
Replies from: o-o↑ comment by O O (o-o) · 2023-06-10T23:36:10.655Z · LW(p) · GW(p)
This is because there probably wasn’t a huge reason to (stuxnet was done with massive resources, maybe not frequent t enough to justify fixing) and engineering time is expensive. As long as bandaid patches are available then the same AI can just be used to patch all these vulnerabilities. Also engineering time probably goes down if you have exploit finding AI.
↑ comment by Gurkenglas · 2023-06-24T09:37:23.890Z · LW(p) · GW(p)
Will it be similarly sized, though? The attack surface for supply chain attacks could hardly get bigger, to the point where this very comment is inside it.
comment by Noosphere89 (sharmake-farah) · 2023-06-09T15:14:26.600Z · LW(p) · GW(p)
There's an interesting tweet thread in which xuan disagrees with some of your predictions because of LLM limitations and the belief that the scaling hypothesis will not hold.
What's your take on the response to your predictions, and how does it affect your predictions, if you believed the tweet thread?
https://twitter.com/xuanalogue/status/1666765447054647297?t=a60XmQsIEsfHpf2O7iGMCg&s=19
Replies from: nathan-helm-burger, nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-06-12T18:28:39.415Z · LW(p) · GW(p)
Additionally, I strongly dislike twitter, but since you claimed there were worthwhile arguments there, I gritted my teeth and dove in. To save others like me from having to experience the same frustration with broken-up bits of discourse intermingled with bad hot-takes and insults from randos, I copy-pasted the relevant information. I don't think there's much substance here, other than Xuan noting that she believes that the above article holds only if you assume we stay using tranformer LLMs. If instead we change to using a superior successor to transformer LLMs, this doesn't hold, and the article should address that.
Here's the thread:
xuan (ɕɥɛn / sh-yen)
I respect Jacob a lot but I find it really difficult to engage with predictions of LLM capabilities that presume some version of the scaling hypothesis will continue to hold - it just seems highly implausible given everything we already know about the limits of transformers!
If someone can explain how the predictions above could still come true in light of the following findings, that'd honestly be helpful. - Transformers appear unable to learn non-finite or context-free languages, even autoregressively:
Dennis Ulmer
"Very cool paper to start the week: "Neural Networks and the Chomsky Hierarchy", showing which NLP architectures are able to generalize to which different formal languages! https://arxiv.org/abs/2207.02098
xuan
Transformers learn shortcuts (via linearized subgraph matching) to multi-step reasoning problems instead of the true algorithm that would systematically generalized: Faith and Fate: Limits of Transformers on Compositionality
Similarly, transformers learn shortcuts to recursive algorithms from input / output examples, instead of the recursive algorithm itself:
"Can Transformers Learn to Solve Problems Recursively?"
These are all limits that I don't see how "just add data" or "just add compute" could solve. General algorithms can be observationally equivalent with ensembles of heuristics on arbitrarily large datasets as long as the NN has capacity to represent that ensemble.
So unless you restrict the capacity of the model or do intense process-based supervision (requiring enough of the desired algorithm to just program it directly in the first place), it seems exceedingly unlikely that transformers would learn generalizable solutions.
Some additional thoughts on what autoregressive transformers can express (some variants are Turing-complete), vs. what they can learn, in this thread!"
Teortaxes
Replying to @xuanalogue
Consider that all those recent proofs of hard limits do not engage with how Transformers are used in practice, and they are qualitatively more expressive when utilized with even rudimentary scaffolding. https://twitter.com/bohang_zhang/s
I should also add that I don't find all the predictions implausible in the original piece - inference time will definitely go down, model copying and parallelization is already happening, as is multimodal training. I just don't buy the superhuman capabilities.
(Also not convinced that multimodal training buys that much - more tasks will become automatable, but I don't think there's reason to expect synergistic increase in capabilities. And PaLM-E was pretty underwhelming...)
Asa Cooper Stickland
LLMs doesn't have to mean transformers though. Seems like there is a lot of research effort going into finding better architectures, and 7 years is a decent chunk of time to find them
xuan (ɕɥɛn / sh-yen)
Yup - I think predictions should make that clear though! Then it's not based on the scaling hypothesis but also algorithmic advances - which the post doesn't base it's predictions upon, as far as I can tell.
Alyssa Vance
This was what I thought for several years, but GPT-4 is a huge data point against, no? It seems to just keep getting better
xuan (ɕɥɛn / sh-yen)
My view on the capabilities increase is fairly close to this one! [ed: see referenced tweet from Talia below]
Talia Ringer
I also am extra confused why people are freaking out about the AI Doom nonsense now of all times because it seems to come in the wake of GPT-4 and ChatGPT, but the really big jump in capabilities came in the GPT-2 to GPT-3 jump, and recent improvements have been very modest. So like, I think GPT-4 kind of substantiates the view that we are heading nowhere too interesting very quickly. I think we are witnessing mass superstition interacting with cognitive biases and the wish for a romantic reality in which one can be the hero, though!
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-06-12T18:09:36.727Z · LW(p) · GW(p)
I can give you my take: it would be foolish to think that GPT-2030 would be an LLM as-we-know-it with the primary change being more params/compute/data. There have already been algorithmic improvements with each GPT version increase, and that will be the primary driver of capabilities advances going forwards. We know, from observing the details of brains via neuroscience, that there are algorithmic advances to be made that will result in huge leaps of ability in specific strategically-relevant domains, such as long-horizon planning and strategic reasoning. In order to project that GPT-2030 won't have superhuman capabilities, you must explicitly state that you believe the ML research community will fail at replicating these algorithmic capabilities of the human brain. Then you must justify that assertion.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-06-08T04:40:35.646Z · LW(p) · GW(p)
Tom Davidson found a math error btw, it shouldn't be 360,000 agents doing a year's worth of thinking each in only 3 days. It should be much less than that, otherwise you are getting compute for free!
Replies from: jsteinhardt↑ comment by jsteinhardt · 2023-06-09T03:52:50.079Z · LW(p) · GW(p)
Oops, thanks, updated to fix this.
comment by RogerDearnaley (roger-d-1) · 2023-06-08T22:37:25.526Z · LW(p) · GW(p)
Attempting to summarize the above, the author's projection (which looks very reasonable to me) is that for a reasonable interpretation of the phrase 'Transformative Artificial Intelligence' (TAI), i.e. an AI that could have a major transformative effect on human society, we should expect it by around 2030. So we should expect accelerating economic, social, and political upheavals in around that time-frame.
For the phrase Artificial General Intelligence (AGI), things are a little less clear, depending on what exactly you mean by AGI: the author's projection is that we should expect AI that matches or exceeds the usual range of human ability in many respects, and is clearly superhuman in many respects, but where there do still exist certain mental tasks that some humans are superior to AI at (and quite possibly also many physical tasks humans are still superior at, thanks to Moravec's Paradox).
The consequences of this analysis for alignment timelines are less clear, but my impression is that if any significant fraction of the AI capabilities the author is forecasting for 2030 are badly misaligned, we could easily be in deep trouble. Similarly, if any significant fraction of this set of capabilities were being actively misused under human direction, that could also cause serious trouble (where my definition of 'misuse' includes things like natural progressions from what the advertising industry or political consultants already do, but carried out much more effectively using much greater persuasion abilities enabled by AI).
comment by CronoDAS · 2023-06-09T20:28:25.854Z · LW(p) · GW(p)
Doesn't an LLM, at least initially, try to solve a problem very much like "what word is most likely to come next if it was written by a human"? The Internet might contain something close to the sum of all human knowledge, but that includes the parts that are wrong. Making GPT "better" might make it better at making the same kind of mistakes that humans make. (I've never tried, but what happens if you try to ask ChatGPT or other LLMs about astrology or religion - subjects on which a lot of people believe things that are false? If it equivocates, is it willing to say that Superman doesn't exist? Or Santa Claus?)
comment by ryan_greenblatt · 2024-01-30T19:13:53.530Z · LW(p) · GW(p)
As far as inference speeds, it's worth noting that OpenAI inference speeds can vary substantially and tend to decrease over time after the release of a new model.
See Fabien's lovely website for results over time.
In particular, if we look at GPT-4-1106-preview, the results indicate that it was temporarily at around 3000 tokens/minute shortly after release, but more recent speeds are only around 1200 tokens/minute.
Similarly, GPT-3.5-turbo-1106 has speeds of about 6000 tokens/minute at the time of release, but this has decreased to more like 3000 tokens/minute more recently.
comment by Ruby · 2023-06-19T00:22:59.978Z · LW(p) · GW(p)
Curated. The future is hard to predict but it's not impossible to narrow your expectations and be less surprised. I appreciate this piece for getting quite concrete and getting me thinking. The kind of piece that goes alongside What 2026 looks like [LW · GW] (though I don't think this was intended as a vignette, both merely attempt to predict where things are headed). This piece was focused on the technical capabilities, would be very interesting to see exploration of what the world looks like when you can just get approx a million hours of human cognitive labor quickly.
comment by reallyeli · 2023-06-08T05:42:43.602Z · LW(p) · GW(p)
Appreciated this post.
ChatGPT has already been used to generate exploits, including polymorphic malware, which is typically considered to be an advanced offensive capability.
I found the last link at least a bit confusing/misleading, and think it may just not support the point. As stated, it sounds like ChatGPT was able to write a particularly difficult-to-write piece of malware code. But the article instead seems to be a sketch of a design of malware that would incorporate API calls to ChatGPT, e.g. 'okay we're on the target machine, we want to search their files for stuff to delete, write me code to run the search.'
The argument is that this would be difficult for existing e.g. antivirus software to defend against because the exact code run changes each time. But if you really want to hack one person in particular and are willing to spend lots of time on it, you could achieve this today by just having a human sitting on the other end doing ChatGPT's job. What ChatGPT buys you is presumably the ability to do this at scale.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2023-06-09T03:51:34.638Z · LW(p) · GW(p)
Thanks! I removed the link.
Replies from: reallyeli↑ comment by reallyeli · 2023-06-09T06:15:10.684Z · LW(p) · GW(p)
:thumbsup: Looks like you removed it on your blog, but you may also want to remove it on the LW post here.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2023-06-10T00:37:20.185Z · LW(p) · GW(p)
I'm leaving it to the moderators to keep the copies mirrored, or just accept that errors won't be corrected on this copy. Hopefully there's some automatic way to do that?
comment by Review Bot · 2024-07-28T13:50:34.700Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by denkenberger · 2023-06-20T01:34:27.571Z · LW(p) · GW(p)
Recall that GPT2030 could do 1.8 million years of work[8] [LW(p) · GW(p)] across parallel copies, where each copy is run at 5x human speed. This means we could simulate 1.8 million agents working for a year each in 2.4 months.
You point out that human intervention might be required every few hours, but with different time zones, we could at least have the GPT working twice as many hours a week as humans, so that would imply ~1 month above. As for the speed now, you say about the same to three times as fast for thinking. You point out that it also does writing, but it is verbose. However, for solving problems like that coding interview, it does appear to be an order of magnitude faster already (and this is my experience solving physical engineering problems).
comment by [deleted] · 2023-06-11T17:14:02.733Z · LW(p) · GW(p)
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2023-06-12T10:18:26.710Z · LW(p) · GW(p)
What examples of deeper structural insights do you have in mind?