Two-year update on my personal AI timelines
post by Ajeya Cotra (ajeya-cotra) · 2022-08-02T23:07:48.698Z · LW · GW · 60 commentsContents
Updates that push toward shorter timelines Picturing a more specific and somewhat lower bar for TAI Feeling like meta-learning may be unnecessary, making short horizon training seem more plausible Explicitly breaking out “GPT-N” as an anchor Considering endogeneities in spending and research progress Seeing continued progress and no major counterexamples to DL scaling well Seeing some cases of surprisingly fast progress Making a one-time upward adjustment for “2020 FLOP / $” Updates that push toward longer timelines Claims associated with short timelines that I still don’t buy Sources of bias I’m not sure what to do with What does this mean? None 60 comments
I worked on my draft report on biological anchors for forecasting AI timelines [LW · GW] mainly between ~May 2019 (three months after the release of GPT-2) and ~Jul 2020 (a month after the release of GPT-3), and posted it on LessWrong in Sep 2020 after an internal review process. At the time, my bottom line estimates from the bio anchors modeling exercise were:[1]
- Roughly ~15% probability of transformative AI by 2036[2] (16 years from posting the report; 14 years from now).
- A median of ~2050 for transformative AI (30 years from posting, 28 years from now).
These were roughly close to my all-things-considered probabilities at the time, as other salient analytical frames on timelines didn’t do much to push back on this view. (Though my subjective probabilities bounced around quite a lot around these values and if you’d asked me on different days and with different framings I’d have given meaningfully different numbers.)
It’s been about two years since the bulk of the work on that report was completed, during which I’ve mainly been thinking about AI. In that time it feels like very short timelines have become a lot more common and salient on LessWrong and in at least some parts of the ML community.
My personal timelines have also gotten considerably shorter over this period. I now expect something roughly like this:
- ~15% probability by 2030 (a decrease of ~6 years from 2036).
- ~35% probability by 2036 (a ~3x likelihood ratio[3] vs 15%).
- This implies that each year in the 6 year period from 2030 to 2036 has an average of over 3% probability of TAI occurring in that particular year (smaller earlier and larger later).
- A median of ~2040 (a decrease of ~10 years from 2050).
- This implies that each year in the 4 year period from 2036 to 2040 has an average of almost 4% probability of TAI.
- ~60% probability by 2050 (a ~1.5x likelihood ratio vs 50%).
As a result, my timelines have also concentrated more around a somewhat narrower band of years. Previously, my probability increased from 10% to 60%[4] over the course of the ~32 years from ~2032 and ~2064; now this happens over the ~24 years between ~2026 and ~2050.
I expect these numbers to be pretty volatile too, and (as I did when writing bio anchors) I find it pretty fraught and stressful to decide on how to weigh various perspectives and considerations. I wouldn’t be surprised by significant movements.
In this post, I’ll discuss:
- Some updates toward shorter timelines (I’d largely characterize these as updates made from thinking about things more and talking about them with people rather than updates from events in the world, though both play a role).
- Some updates toward longer timelines (which aren’t large enough to overcome the updates toward shorter timelines, but claw the size of the update back a bit).
- Some claims associated with short timelines that I still don’t buy.
- Some sources of bias I'm not sure what to do with.
- Very briefly, what this may mean for actions.
This post is a catalog of fairly gradual changes to my thinking over the last two years; I'm not writing this post in response to an especially sharp change in my view -- I just thought it was a good time to take stock, particularly since a couple of people have asked me about my views recently.
Updates that push toward shorter timelines
I list the main updates toward shorter timelines below roughly in order of importance; there are some updates toward longer timelines as well (discussed in the next section) which claw back some of the impact of these points.
Picturing a more specific and somewhat lower bar for TAI
Thanks to Carl Shulman, Paul Christiano, and others for discussion around this point.
When writing my report, I was imagining that a transformative model would likely need to be able to do almost all the tasks that remote human workers can do (especially the scientific research-related tasks). Now I’m inclined to think that just automating most of the tasks in ML research and engineering -- enough to accelerate the pace of AI progress manyfold -- is sufficient.
Roughly, my previous picture (similar to what Holden describes here) was:
Automate science → Way more scientists → Explosive feedback loop of technological progress
But if it’s possible to automate science with AI, then automating AI development itself seems like it would make the world crazy almost as quickly:
Automate AI R&D → Explosive feedback loop of AI progress specifically → Much better AIs that can now automate science (and more) → explosive feedback loop of technological progress
To oversimplify, suppose I previously thought it would take the human AI development field ~10 years of work from some point T to figure out how to train a scientist-AI. If I learn they magically got access to AI-developer-AIs that accelerate progress in the field by 10x, I should now think that it will take the field ~1 year from point T to get to a scientist-AI.
This feels like a lower bar for TAI than what I was previously picturing -- the most obvious reason is because automating one field should be easier than automating all fields, meaning that the model size required should be appreciably smaller. But additionally, I think AI development in particular seems like it has properties that make it easier to automate with only short horizon training (see below for some discussion). So this update reduces my estimate of both model size and effective horizon length.
Feeling like meta-learning may be unnecessary, making short horizon training seem more plausible
Thanks to Carl Shulman, Dan Kokotajlo, and others for discussion of what short horizon training could look like.
In my report, I acknowledged that models trained with short effective horizon lengths could probably do a lot of economically useful work, and that breaking long tasks down into smaller pieces could help a lot. The main candidate in my mind for a task that might require long training horizons to learn was (and still is) “efficient learning” itself.
That is, I thought that a meta-learning project attempting to train a model on many instances of the task “master some complex new skill (that would take a human a long time to learn, e.g. a hard video game or a new type of math) from scratch within the current episode and then apply it” would have a long effective horizon length, since each individual learning task (each “data point”) would take the model some time to complete. Absent clever tricks, my best guess was that this kind of meta-learning run would have an effective horizon length roughly similar to the length of time it would take for a human to learn the average skill in the distribution.
I felt like having the ability to learn novel skills in a sample-efficient way would be important for a model to have a transformative impact, and was unsure about the extent to which clever tricks could make things cheaper than the naive view of “train the model on a large number of examples of trying to learn a complex task over many timesteps.” This pulled my estimate for effective horizon length upwards (to a median of multiple subjective hours).
By and large, I haven’t really seen much evidence in the last two years that this kind of meta-learning -- where each object-level task being learned would take a human a long time to learn -- can be trained much more cheaply than I thought, or much evidence that ML can directly achieve human-like sample efficiencies without the need for expensive meta-learning (footnote attempts to briefly address some possible objections here).[5]
Instead, as I’ve thought harder about the bar for “transformative,” I’ve come to think that it’s likely not necessary for the first transformative models to learn new things super efficiently. Specifically, if the main thing needed to have a transformative impact is to accelerate AI development itself:
- There’s so much human-imitation data on programming and AI[6] that the model can train on vastly more examples than a human sees in their lifetime, and after that training it may not really need to learn particularly complex novel skills after training to act as a very skilled AI engineer / researcher.
- Coding is intentionally very modular, so it seems especially well-suited to break down into small short-horizon steps.
- Probably as a result of the above two points, we’re already seeing much more concrete progress on coding than we are in other technical and scientific domains; AI systems seem likely to add non-trivial value to practicing programmers soon. This generally de-risks the prospect of using AI to help with AI development somewhat, compared to other applications we haven’t started to see yet.
- Brute-force search seems like it could play a larger role in progress than in many other sciences (e.g. a relatively simple ML model could generate and test out thousands of different small tweaks to architectures, loss functions, optimization algorithms, etc. at small scale, choosing the one that works best empirically -- other sciences have a less clear-cut search space and longer feedback loops).
I do still think that eventually AI systems will learn totally new skills much more efficiently than existing ML systems do, whether that happens through meta-learning or through directly writing learning algorithms much more sample-efficient than SGD. But now this seems likely to come after short-horizon, inefficiently-trained coding models operating pretty close to their training distributions have massively accelerated AI research.
Explicitly breaking out “GPT-N” as an anchor
This change is mainly a matter of explicitly modeling something I’d thought of but found less salient at the time; it felt more important to me to factor it in after the lower bar for TAI made me consider short horizons in general more likely.
My original Short Horizon neural network anchor assumed that effective horizon length would be log-uniformly distributed between ~1 subjective second (which is about GPT-3 level) and ~1000 subjective seconds; this meant that the Short Horizon anchor was assuming an effective horizon length substantially longer than a pure language model (the mean was ~32 subjective seconds, vs ~1 subjective second for a language model).
I’m now explicitly putting significant weight on an amount of compute that’s more like “just scaling up language models to brain-ish sizes.” (Note that this hypothesis/anchor is just saying that the training computation is very similar to the amount of computation needed to train GPT-N, not that we’d literally do nothing else besides train a predictive language model. For example, it’s consistent with doing RL fine-tuning but just needing many OOMs less data for that than for the original training run -- and I think that’s the most likely way it would manifest.)
Considering endogeneities in spending and research progress
Thanks to Carl Shulman for raising this point, and to Tom Davidson for research fleshing it out.
My report forecasted algorithmic progress (the FLOP required to train a transformative model in year Y), hardware progress (FLOP / $ in year Y), and willingness to spend ($ that the largest training run could spend on FLOP in year Y) as simple trendline forecasts, which I didn’t put very much thought into.
In the open questions section, I gestured at various ways these forecasts could be improved. One salient improvement (mentioned but not highlighted very much) would be to switch from a black box trend extrapolation to a model that takes into account how progress in R&D relates to R&D investment.
That is, rather than saying “Progress in [hardware/software] has been [X doublings per year] recently, so let’s assume it continues that way,” we could say:
- Progress in [hardware/software] has been [X doublings per year]
- Over this time, the amount of [money / labor] invested into [hardware / software R&D] has been growing at [Y doublings per year]
- This implies that every Y doublings of R&D leads to X doublings of improvement in [hardware / software]
This would then allow us to express beliefs about how investment in R&D will change, which can then translate into beliefs about how fast research will progress. And if ML systems have lucrative near-term applications, then it seems likely there will be demand for increasing investment into hardware and software R&D beyond the historical trend, suggesting that this progress should happen faster than I model.
Furthermore, it seems possible that pre-transformative systems would substantially automate some parts of AI research itself, potentially further increasing the effective “total R&D efforts gone into AI research” beyond what might be realistic from increasing the human labor force alone.
Seeing continued progress and no major counterexamples to DL scaling well
My timelines model assumed that there was a large (80%) chance that scaling up 2020 ML techniques to use some large-but-not-astronomically-large amount of computation (and commensurate amount of data) would work for producing a transformative model.[7]
Over the last two years, I’d say deep learning has broadly continued to scale up well. Since that was the default assumption of my model, there isn’t a big update toward shorter timelines here -- but there was some opportunity for deep learning to “hit a wall” over the last two years, and that didn’t really happen, modestly increasing my confidence in the premise.
Seeing some cases of surprisingly fast progress
My forecasting method was pretty anchored to estimates of brain computation, rather than observations of the impressiveness of models that existed at the time, so I was pretty unsure what the framework would imply for very-near-term progress[8] (“How good at coding would a mouse be, if it’d been bred over millennia to write code instead of be a mouse?”).
As a result, I didn’t closely track specific capabilities advances over the last two years; I’d have probably deferred to superforecasters and the like about the timescales for particular near-term achievements. But progress on some not-cherry-picked benchmarks was notably faster than what forecasters predicted, so that should be some update toward shorter timelines for me. I’m pretty unsure how much, and it’s possible this should be larger than I think now.
Making a one-time upward adjustment for “2020 FLOP / $”
In my report I estimated that the effective computation per dollar in 2020 was 1e17 FLOP/ $, and projected this forward to get hardware estimates for future years. However, this seems to have been an underestimate of FLOP/ $) as of 2020. This is because:
- I was using the V100 as my reference machine; this was in fact the most advanced publicly available chip on the market as of 2020, but it was released in 2018 and on its way out, so it was better as an estimate for 2018 or 2019 compute than 2020 compute. The more advanced A100 was 2-3x more powerful per dollar and released in late 2020 almost immediately after my report was published.
- I was using the rental price of a V100 (~$1/hour), but big companies get better deals on compute than that, by about another 2-3x.
- I was assuming ~⅓ utilization of FLOP/s, which was in line with what people were achieving then, but utilization seems to have improved, maybe to ~50% or so.
This means the 2020 start point should have been 2.5 * 2.5 * 1.5 = nearly 10x larger. From the 2020 start point, I projected that FLOP / $ would double every ~2.5 years -- which is slightly faster than the 2010 to 2018 period but slightly slower than Moore’s law. I haven't looked into it deeply but my understanding is that this has roughly held [LW · GW], so the update I’m making here is a one-time increase to the starting point rather than a change in rate (separate from the changes in rate I’m imagining due to the endogeneities update).
Updates that push toward longer timelines
- My report estimates that the amount of training data required to train a model with N parameters scales as N^0.8, based significantly on results from Kaplan et al 2020. In 2022, the Chinchilla scaling result (Hoffmann et al 2022) showed that instead the amount of data should scale as N.
- Some people have suggested this should be an update toward shorter timelines. This would be true if your method for forecasting timelines was observing models like GPT-2 and GPT-3, gauging how impressive they were, and trying to guess how many orders of magnitude more training computation would be required to reach TAI. The Chinchilla result would show that GPT-3 was “not as good as it could have been” for a fixed amount of training computation, so your estimate for the amount of additional scaling required should go down.
- But in my report I arrive at a forecast by fixing a model size based on estimates of brain computation, and then using scaling laws to estimate how much data is required to train a model of that size. The update from Chinchilla is then that we need more data than I might have thought.
- I’m somewhat surprised that I haven’t seen more vigorous commercialization of language models and commercial applications that seem to reliably add real value beyond novelty; this is some update toward thinking that language models are less impressive than they seemed to me, or that it’s harder to translate from a capable model into economic impact than I believed.
- There’s been a major market downturn that hit tech companies especially hard; it seems a little less likely to me now than it did when writing the report that there will be a billion dollar training run by 2025.
Overall, the updates in the previous section seem a lot stronger than these updates.
Claims associated with short timelines that I still don’t buy
- I don’t expect a discontinuous jump in AI systems’ generality or depth of thought from stumbling upon a deep core of intelligence; I’m not totally sure I understand it but I probably don’t expect a sharp left turn [LW · GW].
- Relatedly, I don’t expect that progress will be driven by a small number of key “game-changing” algorithmic insights we can’t anticipate today; I expect transformative models to look quite similar to today’s models[9] (more so now that my timelines are shorter) and progress to be driven by scale and a large number of smaller algorithmic improvements.
- Relatedly, I still don’t expect that TAI will be cheap (e.g. <$10B for a project) and don’t think smallish “underdog” research groups are likely to develop TAI;[10] I still expect developing TAI to require hundreds of billions of dollars and to be done by tech companies with high valuations,[11] likely after pretty significant commercialization of sub-transformative systems.
- I think the concept of a “point of no return” [LW · GW] that is not an objective observable event like “the AI has monopolized violence” is tricky to reason about, since it folds in complicated forecasts about the competence and options of future actors,[12] but to the extent that I understand the concept I’m mostly not expecting a PONR before explosive acceleration in research progress is underway (e.g. I don’t expect a PONR before the first automated AI company). The update toward a lower bar for “transformative” [LW · GW] pushes me more in this direction -- I expect there to be a lot of helpful things to do in the final couple of years in between “AIs accelerate AI research a lot” and “Far superintelligent AI” (a big one being use the AIs to help with alignment research).
Sources of bias I’m not sure what to do with
Putting numbers on timelines is in general a kind of insane and stressful exercise, and the most robust thing I’ve taken away from thinking about all this is something like “It’s really a real, live possibility that the world as we know it is radically upended soon, soon enough that it should matter to all of us on normal planning horizons.” A large source of variance in stated numbers is messy psychological stuff.
The most important bias that suggests I’m not updating hard enough toward short timelines is that I face sluggish updating incentives in this situation -- bigger changes to my original beliefs will make people update harder against my reasonableness in the past, and holding out some hope that my original views were right after all could be the way to maximize social credit (on my unconscious calculation of how social credit works).
But there are forces in the other direction too -- most of my social group is pretty system 1 bought into short timelines,[13] which for many of us likely emotionally justifies our choice to be all-in on AI risk with our careers. My own choices since 2020 look even better on my new views than my old. I have constantly heard criticism over the last two years that my timelines are too long, and very little criticism that they were too short, even though almost everyone in the world (including economists, ML people, etc) would probably have the other view. I find myself not as interested or curious as I should theoretically be (on certain models of epistemic virtue) in pushback from such people. I spend most of my time visualizing concrete worlds in which things move fast and hardly any time visualizing concrete worlds where they move slow.[14]
What does this mean?
I’m unclear how decision-relevant bouncing around within the range I’ve been bouncing around is. Given my particular skills and resources, I’ve steered my career over the last couple years in a direction that looks roughly as good or better on shorter timelines than what I had in 2020.
This update should also theoretically translate into a belief that we should allocate more money to AI risk over other areas such as bio risk, but this doesn’t in fact bind us since even on our previous views, we would have liked to spend more but were more limited by a lack of capacity for seeking out and evaluating possible grants than by pure money.
Probably the biggest behavioral impact for me (and a lot of people who’ve updated toward shorter timelines in the last few years) will be to be more forceful and less sheepish about expressing urgency when e.g. trying to recruit particular people to work on AI safety or policy.
The biggest strategic update that I’m reflecting on now is the prospect of making a lot of extremely fast progress in alignment with comparatively limited / uncreative / short-timescale systems in some period a few months or a year before systems that are agentic / creative enough to take over the world. I’m not sure how realistic this is, but reflecting on how much progress could be made with pretty “dumb” systems makes me want to game out this possibility more.
Bio Anchors part 4 of 4, pg 14-16. ↩︎
A year chosen to evaluate a claim made by Holden in 2016 that there was a >10% chance of TAI within 20 years. ↩︎
Given by the ratio of odds ratios: (0.35 / 0.65) / (0.15 / 0.85) = 3.05. This implies my observations and logical updates from thinking more since 2020 were 3x more likely in a world where TAI happens by 2036 than in a world where it doesn’t happen by 2036. ↩︎
This contains 50% of my probability mass but is not a “50% confidence interval” as the term is normally used, because the range I’m considering is not the range from 25% probability to 75% probability. This is mainly to keep the focus on the left tail of the distribution, which is more important and easier to think about. E.g. if I’m wrong about most of the models that lead me to expect TAI soonish, then my probability climbs very slowly up to 75% since I would revert back to simple priors. ↩︎
People use “few-shot learning” to refer to language models’ ability to understand the pattern of what they’re being asked for after seeing a small number of examples in the prompt (e.g. after seeing a couple of examples of translating an English sentence into French, a model will complete the pattern and translate the next English sentence into French). However, this doesn’t seem like much evidence about the kind of meta-learning I’m interested in, because it takes very little time for a human to learn a pattern like that. If a bilingual French-and-English-speaking human saw a context with two examples of translating an English sentence into French, they would ~immediately understand what was going on. Since the model already knows English and French, the learning problem it faces is very short-horizon (the amount of time it would take a human to read the text). I haven’t yet seen evidence that language models can be taught new skills they definitely didn’t know already over the course of many rounds of back-and-forth.
I’ve also seen EfficientZero cited as evidence that SGD itself can reach human-level sample complexities (without the need for explicit meta-learning), but this doesn’t seem right to me. The EfficientZero model learned the environment dynamics of a game with ML and then performed a search against that model of the environment to play the game. It took the model a couple of hours per game to learn environment dynamic facts like “the paddle moves left to right”, “if an enemy hits you you die,” etc. The relevant comparison is not how much time it would take a human to learn to play the game, it’s how much time it would take a human to get what’s going on and what they’re supposed to aim for -- and the latter is not something that it would take a human 2 hours of watching to figure out (probably more like 15-60 seconds).
The kind of thing that would seem like evidence about efficient meta-learning is something like “A model is somehow trained on a number of different video games, and then is able to learn how to play (not just model the dynamics of) a new video game it hadn’t seen before decently with a few hours of experience.” The kind of thing that would seem like evidence of human-like sample efficiency directly from SGD would be something like “good performance on language tasks while training on only as many words as a human sees in a lifetime.” ↩︎
All the publicly-available code online (e.g. GitHub), plus company-internal repos, keylogging of software engineers, explicitly constructed curricula/datasets (including datasets automatically generated from the outputs of slightly smaller coding models), etc. Also, it seems like most of the reasoning that went into generating the code is in some sense manifested in the code itself, whereas e.g. the thinking and experimentation that went into a biology experiment isn’t all directly present in the resulting paper. ↩︎
Row 17 in sheet “Main” ↩︎
The key exception, as discussed above, was predicting that cheap meta-learning wouldn’t happen, which I’d say it didn’t. ↩︎
Note that there’s a bunch of already-widely-used techniques (most notably search) that some people wouldn’t count as “pure deep learning” which I expect to continue to play an important role. Transformative AI seems quite likely to look like AlphaGo (which uses search), RETRO (which uses retrieval), etc. ↩︎
Though my probability on this necessarily increased some because shifting the distribution to the left has to increase probability mass on “surprisingly cheap,” it’s still not my default. If I had to guess I’d say maybe ~15% chance on <$10B for training TAI and a similar probability that it’s trained by a company with <2% of the valuation of the biggest tech companies. Betting on this possibility -- with one’s career or investments -- seems better than it did to me before (and I don't think it was insane in the past either; just not something I'd consider the default picture of the future). ↩︎
Though labs that are currently smallish could grow to have massive valuations and a ton of employees and then develop transformative systems, and that seems a lot more likely than that a company would develop TAI while staying small. ↩︎
E.g., it seems like it wouldn’t be hard to argue for a “PONR” in the past, e.g. “alignment is so hard that the fact that we didn’t get started on it 20 years ago means we’re past the point of no return.” Instead it just feels like the difficulty of changing course just gets worse and worse over time, and there are very late-stage opportunities that could still technically help, like “shutting down all the datacenters.” ↩︎
I might have ended up, with this update, near the median of the people I hang out with most, but I could also still be slower than them -- not totally sure. ↩︎
Since longer timelines are harder to think about since the world will have changed more before TAI, less decision-relevant since our actions will have washed out more, less emotionally gripping, etc. ↩︎
60 comments
Comments sorted by top scores.
comment by Matthew Barnett (matthew-barnett) · 2022-08-03T04:23:07.852Z · LW(p) · GW(p)
I'm curious if you have any thoughts on the effect regulations will have on AI timelines. To have a transformative effect, AI would likely need to automate many forms of management, which involves making a large variety of decisions without the approval of other humans. The obvious effect of deploying these technologies will therefore be to radically upend our society and way of life, taking control away from humans and putting it in the hands of almost alien decision-makers. Will bureaucrats, politicians, voters, and ethics committees simply stand idly by while the tech industry takes over our civilization like this?
On the one hand, it is true that cars, airplanes, electricity, and computers were all introduced with relatively few regulations. These technologies went on to change our lives greatly in the last century and a half. On the other hand, nuclear power, human cloning, genetic engineering of humans, and military weapons each have a comparable potential to change our lives, and yet are subject to tight regulations, both formally, as the result of government-enforced laws, and informally, as engineers regularly refuse to work on these technologies indiscriminately, fearing backlash from the public.
One objection is that it is too difficult to slow down AI progress. I don't buy this argument.
A central assumption of the Bio Anchors model, and all hardware-based models of AI progress more generally, is that getting access to large amounts of computation is a key constraint to AI development. Semiconductor fabrication plants are easily controllable by national governments and require multi-billion dollar upfront investments, which can hardly evade the oversight of a dedicated international task force.
We saw in 2020 that, if threats are big enough, governments have no problem taking unprecedented action, quickly enacting sweeping regulations of our social and business life. If anything, a global limit on manufacturing a particular technology enjoys even more precedent than, for example, locking down over half of the world's population under some sort of stay-at-home order.
Another argument states that the incentives to make fast AI progress are simply too strong: first mover advantages dictate that anyone who creates AGI will take over the world. Therefore, we should expect investments to accelerate dramatically, not slow down, as we approach AGI. This argument has some merit, and I find it relatively plausible. At the same time, it relies on a very pessimistic view of international coordination that I find questionable. A similar first-mover advantage was also observed for nuclear weapons, prompting Bertrand Russell to go as far as saying that only a world government could possibly deter nations from developing and using nuclear weapons. Yet, I do not think this prediction was borne out.
Finally, it is possible that the timeline you state here is conditioned on no coordinated slowdowns. I sometimes see people making this assumption explicit, and in your report you state that you did not attempt to model "the possibility of exogenous events halting the normal progress of AI research". At the same time, if regulation ends up mattering a lot -- say, it delays progress by 20 years -- then all the conditional timelines will look pretty bad in hindsight, as they will have ended up omitting one of the biggest, most determinative factors of all. (Of course, it's not misleading if you just state upfront that it's a conditional prediction).
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-08-03T17:24:13.478Z · LW(p) · GW(p)
To take the pessimistic side on AI, I see some reasons why AI probably won't be regulated in a way that matters:
-
I suspect the no fire alarm hypothesis is roughly correct, in that by and large, people won't react until it's too late. My biggest reason comes from the AI effect, where people start downplaying the intelligence it has, which is dangerous because people don't react to warning shots like GPT-3 or AlphaFold 2, and updates me to thinking that people won't seriously start calling for regulation until AGI is actually here, and that's far too late. We got a fire alarm for nukes in Hiroshima, which was an instance of a lucky fire alarm before many nukes or nuclear power plants were made, and we can't rely on luck saving us again.
-
Politicization. The COVID-19 response worries me much more than you, and it's positives only outweighed it's negatives only because of the fact that there wasn't any X-risk. In particular, the fact that there was a strong response actually decayed pretty fast, and in our world virtually everything is politicized into a culture war as soon as it actually impacts people's lives. A lot of the competence of say, handling nukes or genetic engineering is that politics didn't use to eat everything, thus no one had too much motivation to defect. Now, if they had to deal with nukes or genetic engineering with our politics, at least 40% of the US population would support getting these technologies solely to destroy the other side.
Speaking of that far too late thing, most technologies that got successfully regulated either had everyone panicking like nuclear reactor radiation or wasn't very developed like Human genetic engineering/cloning.
Finally, no one can have it and AGI itself is a threat thanks to inner optimizer concerns. So the solution of having government control it is exactly unworkable, since they themselves have large incentives to get AGI ala nukes and have little reason not to.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-03T18:41:33.633Z · LW(p) · GW(p)
Politicization. The COVID-19 response worries me much more than you, and it's positives only outweighed it's negatives only because of the fact that there wasn't any X-risk. In particular, the fact that there was a strong response actually decayed pretty fast, and in our world virtually everything is politicized into a culture war as soon as it actually impacts people's lives.
Note that I'm simply pointing out that people will probably try to regulate AI, and that this could delay AI timelines. I'm not proposing that we should be optimistic about regulation. Indeed, I'm quite pessimistic about heavy-handed government regulation of AI, but for reasons I'm not going to go into here.
Separately, the reason why the Covid-19 response decayed quickly likely had little to do with politicization, given that the pandemic response decayed in every nation in the world, with the exception of China. My guess is that, historically, regulations on manufacturing particular technologies have not decayed quite so quickly.
comment by Not Relevant (not-relevant) · 2022-08-03T08:24:28.464Z · LW(p) · GW(p)
One major update from the Chinchilla paper against the NN timelines that this post doesn't capture (inspired by this comment by Rohin [LW(p) · GW(p)]):
Based on Kaplan scaling laws, we might’ve expected that raw parameter count was the best predictor of capabilities. Chinchilla scaling laws introduced a new component, data quantity, that was not incorporated in the original report.
Chinchilla scaling laws provide the compute-optimal trade off between datapoints and parameters, but not the cost-optimal trade off (assuming that costs come from both using more compute, and observing more datapoints). In biological systems, the marginal cost of doubling the amount of data is very high, since that requires doubling the organism's lifespan or doubling its neuron throughput, which are basically hard constraints. This means that human brains may be very far from "compute optimal" in the zero-datapoint-cost limit suggested by Chinchilla, implying ANN models much smaller than brain-size (estimated at 10T-parameters) may achieve human-level performance given compute-optimal quantities of data.
In other words, the big takeaway is that we should update away from human-level FLOPS as a good bio-anchor independent of the number of training datapoints, since we have reason to believe that human brains face other constraints which suboptimally inflate the number of FLOPS brains use to attain a given level of performance.
Replies from: daniel-kokotajlo, dsj, jacob_cannell, SimonF↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-03T15:48:01.620Z · LW(p) · GW(p)
And in particular we should update towards below-human-level FLOPS.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-22T07:17:16.328Z · LW(p) · GW(p)
No - at least not for these reasons - see my longer reply lower down but what probably matters most is total search volume (model size * training time), which is basically FLOPS/memops. A smaller model can train longer to get up to the same capabilities for roughly the same total compute budget, but for AGI the faster learning model is more intelligent in any useful sense. And of course the human brain is probably pretty close to practical limits [LW · GW] for equivalent FLOPs learning efficiency.
To first order approximation total flops predicts ANN/BNN capabilities quite well. GPT3 training was 3e23 flops, a 30 year old human brain is roughly 1e23 flops equivalent (1e9 seconds * 1e14 flops/s). GPT3 is only really equivalent to say 10% of the human brain at best (linguistic related cortices), but naturally the brain is still at least an OOM more flops efficient.
↑ comment by dsj · 2022-08-04T21:49:45.066Z · LW(p) · GW(p)
On the other hand, humans are good at active learning — selecting the datapoints which lead to the most efficient progress. Relative to Chinchilla scaling laws which assume no active learning, humans may be using their computation far more efficiently.
↑ comment by jacob_cannell · 2022-08-22T07:11:50.123Z · LW(p) · GW(p)
Gradient descent is still a form of search and what matters most is the total search volume. In the overparameterized regime (which ANNs are now entering and BNNs swim in) performance (assuming not limited by data quality) is roughly predicted by (model size * training time). It doesn't matter greatly whether you train a model twice as large for half as long or vice versa - in either case it's the total search volume that matters, because in the overparam regime you are searching for needles in the circuit space haystack.
However, human intelligence (at the high end) is to a first and second approximation simply learning speed and thus data efficiency. Even if the smaller brain/model trained for much longer has equivalent capability now, the larger model/brain still learns faster given the same new data, and is thus more intelligent in the way more relevant for human level AGI. We have vastly more ability to scale compute than we can scale high quality training data.
It's dangerous to infer much from the 'chinchilla scaling laws' - humans exceed NLM performance on downstream tasks using only a few billion token equivalent, so using 2 OOM or more less data. These internet size datasets are mostly garbage. Human brains are curriculum trained on a much higher quality and quality-sorted multimodal dataset which almost certainly has very different scaling than the random/unsorted order used in chinchilla. A vastly larger mind/model could probably learn as well using even OOM less data.
The only real conclusion from chinchilla scaling is that for that particular species of transformer NLM trained on that particular internet scale dataset, the optimal token/param ratio is about 30x. But that doesn't even mean you'd get the same scaling curve or same optimal token/param ratio for a different arch on a different dataset with different curation.
↑ comment by Simon Fischer (SimonF) · 2022-08-05T13:10:54.137Z · LW(p) · GW(p)
Your reasoning here relies on the assumption that the learning mostly takes place during the individual organisms lifetime. But I think it's widely accepted that brains are not "blank slates" at birth of the organism, but contain significant amount of information, akin to a pre-trained neural network. Thus, if we consider evolution as the training process, we might reach the opposite conclusion: Data quantity and training compute are extremely high, while parameter count (~brain size) and brain compute is restricted and selected against.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-22T06:27:56.990Z · LW(p) · GW(p)
Much depends on what you mean by learning and mostly, but the evidence for some form of blank slate is overwhelming. Firstly most of the bits in the genome must code for cellular machinery and even then the total genome bits is absolutely tiny compared to brain synaptic bits. Then we have vast accumulating evidence from DL that nearly all the bits come from learning/experience, that optimal model bit complexity is proportional to dataset size (which not coincidentally is roughly on order 1e15 bits for humans - 1e9 seconds * 1e6 bit/s), and that the tiny tiny number of bits needed to specify architecture and learning hyperparams are simply a prior which can be overcome with more data. And there is much more [LW · GW].
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-23T20:34:58.140Z · LW(p) · GW(p)
If you think the human dataset size is 1e15 bits because you are counting each second as a million bits, then how is it that you think humans are vastly more data-efficient than ANNs? the human "pre-training" i.e. their childhood is OOMs bigger than the pre-training for even the largest language models of today.
(How many bits are in a token, for GPT-3? Idk, probably at most 20?)
I admit that I am confused about this stuff, this isn't a "gotcha" but a genuine question.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-23T23:22:41.529Z · LW(p) · GW(p)
TLDR: Humans have a radically different curiculum training tech which we have perfected over literally millenia which starts with a few years of pretraining on about 1e15 bits of lower value sensory data, and then gradually shifts more to training for another few decades on about 1e10 bits of higher value token/text data.
It is pretty likely that part of our apparent token/word data efficiency at abstract tasks does come from our everday physics sim capabilities which leverages the lower level vision/sensor modules trained on the larger ~1e15 bits (and many linguistics/philosophers were saying this long ago - the whole symbol grounding problem). And I agree with that. I suspect that is not the only source of our data efficiency, but yes I"m reasonably confident that AGI will require a much more human like curriculum training (with vision/sensor 'pretraining').
On the other hand we also have examples like hellen keller who place some rough limits on that transfer effect, and we have independent good reasons to believe the low level vision data is much more redundant (in part because the text stream is a compressed summary of what originally was low level vision/sensory data!).
Looking at it another way: this is the crux of human vs animal intelligence. An animal with similar lifespan and brain size (which are naturally correlated due to scaling laws!) only would have the 1e15 bits of sensory training data. Humans also curriculum train on 1e10 bits of a carefully curated subset of the total ~1e12 bits of accumulated human text-symbolic knowledge, which itself is a compression of the 1e26 bits of sensory data from all humans who have ever lived. Thus the intelligence of individual humans scales a bit with the total size of humanity, whereas it's basically just constant for animals. Combine that with the exponential growth of human population and you get the observed hyperexponential trajectory leading to singularity around 2047. (prior LW discussion [LW · GW])
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-08-24T00:05:56.282Z · LW(p) · GW(p)
So the intelligence explosion people like Eliezer Yudkowsky and Luke Muehlhauser were possibly more right than they knew?
I'll give them credit for predicting the idea that the future would be much weirder and unstable ala the Singularity long before Open Philanthropy saw the problem.
It also means stakes on the order of Pascal's mugging are fairly likely this century, and we do live in the hinge of history.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-24T00:45:46.004Z · LW(p) · GW(p)
I kinda hate summarizing EY (even EY-circa-2008) into a paragraph, but EY's version of the intelligence explosion or singularity was focused heavily on recursively self improving AI that could quickly recode itself in ways humans presumably could not, and was influenced/associated with a pessimistic evolved modularity view of the brain that hasn't aged well. Rapid takeoff, inefficient brains, evolved modularity, etc all tie together and self reinforce.
What has aged much better is the more systems-holistic singularity (moravec/kurzweil, john smart, etc) which credits (correctly) human intelligence to culture/language (human brains are just bog standard primate bains slightly scaled up 3x) - associated with softer takeoff as the AI advantage is mostly about allowing further exponential expansion of the size/population/complexity of the overall human memetic/cultural system. In this view recursive self improvement is just sort of baked in to acceleration rather than some new specific innovation of future AI, and AI itself is viewed as a continuation of humanity (little difference between de novo AI and uploads), rather than some new alien thing.
comment by Daniel_Eth · 2022-08-05T02:23:09.485Z · LW(p) · GW(p)
Great post!
I was curious what some of this looked like, so I graphed it, using the dates you specifically called out probabilities. For simplicity, I assumed constant probability within each range (though I know you said this doesn't correspond to your actual views). Here's what I got for cumulative probability:
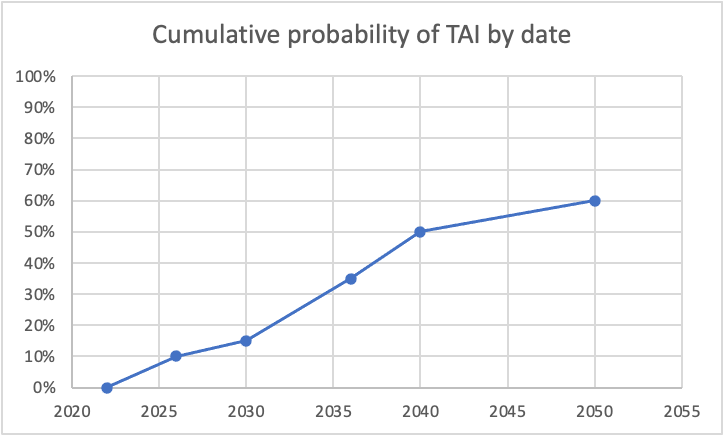
And here's the corresponding probabilities of TAI being developed per specific year: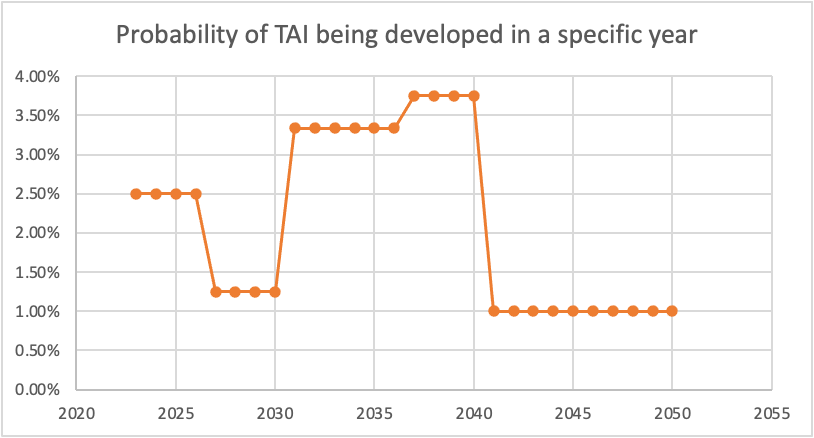
The dip between 2026 and 2030 seems unjustified to me. (I also think the huge drop from 2040-2050 is too aggressive, as even if we expect a plateauing of compute/another AI winter/etc, I don't think we can be super confident exactly when that would happen, but this drop seems more defensible to me than the one in the late 2020s.)
If we instead put 5% for 2026, here's what we get:
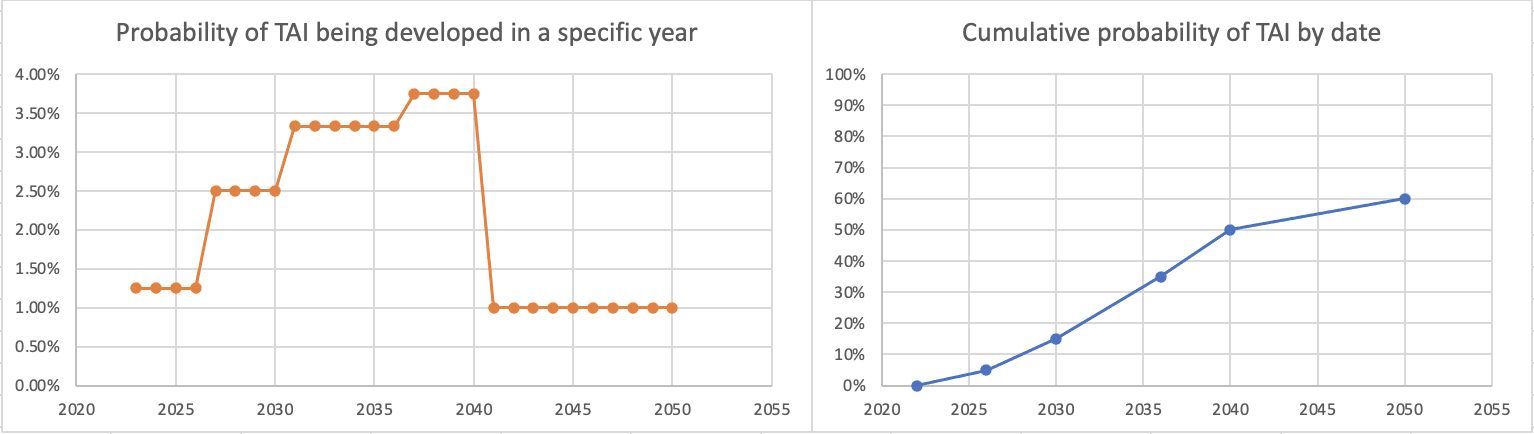
which seems more intuitively defensible to me. I think this difference may be important, as even shift of small numbers of years like this could be action-relevant when we're talking about very short timelines (of course, you could also get something reasonable-seeming by shifting up the probabilities of TAI in the 2026-2030 range).
I'd also like to point out that your probabilities would imply that if TAI is not developed by 2036, there would be an implied 23% conditional chance of it then being developed in the subsequent 4 years ((50%-35%)/(100%-35%)), which also strikes me as quite high from where we're now standing.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-03T15:45:27.435Z · LW(p) · GW(p)
Thanks so much for this update! Some quick questions:
- Are you still estimating that the transformative model uses probably about 1e16 parameters & 1e16 flops? IMO something more like 1e13 is more reasonable.
- Are you still estimating that algorithmic efficiency doubles every 2.5 years (for now at least, until R&D acceleration kicks in?) I've heard from thers (e.g. Jaime Sevilla) that more recent data suggests it's doubling every 1 year currently.
- Do you still update against the lower end of training FLOP requirements, on the grounds that if we were 1-4 OOMs away right now the world would look very different?
- Is there an updated spreadsheet we can play around with?
↑ comment by Lone Pine (conor-sullivan) · 2022-08-03T16:26:00.278Z · LW(p) · GW(p)
Somehow you managed to be terrifying while only asking questions.
↑ comment by aog (Aidan O'Gara) · 2022-08-12T17:09:59.968Z · LW(p) · GW(p)
2. Are you still estimating that algorithmic efficiency doubles every 2.5 years (for now at least, until R&D acceleration kicks in?) I've heard from thers (e.g. Jaime Sevilla) that more recent data suggests it's doubling every 1 year currently.
It seems like the only source on this is Hernandez & Brown 2020. Their main finding is a doubling time of 16 months for AlexNet-level performance on ImageNet: "the number of floating point operations required to train a classifier to AlexNet-level performance on ImageNet has decreased by a factor of 44x between 2012 and 2019. This corresponds to algorithmic efficiency doubling every 16 months over a period of 7 years."
They also find faster doubling times for some Transformers and RL systems, as shown here:
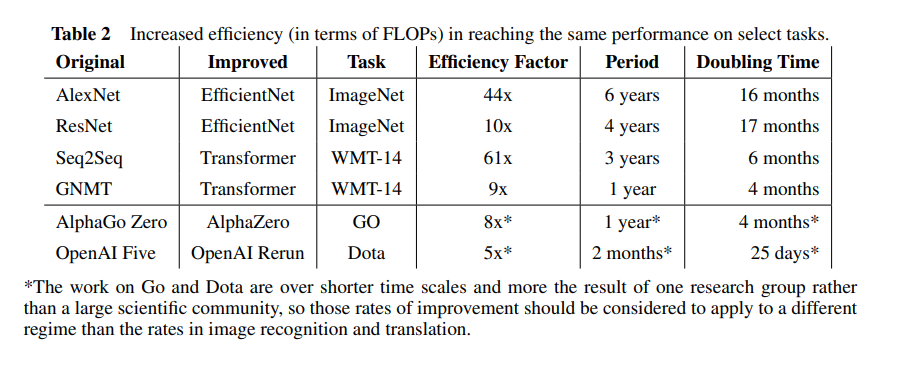
This is notably faster algorithmic progress than the 2.5 year doubling time used in Ajeya's report, though I do somewhat agree with her justification for a more conservative estimate:
Additionally, it seems plausible to me that both sets of results would overestimate the pace of algorithmic progress on a transformative task, because they are both focusing on relatively narrow problems with simple, well-defined benchmarks that large groups of researchers could directly optimize. Because no one has trained a transformative model yet, to the extent that the computation required to train one is falling over time, it would have to happen via proxies rather than researchers directly optimizing that metric (e.g. perhaps architectural innovations that improve training efficiency for image classifiers or language models would translate to a transformative model). Additionally, it may be that halving the amount of computation required to train a transformative model would require making progress on multiple partially-independent sub-problems (e.g. vision and language and motor control).
I have attempted to take the Hernandez and Brown 2020 halving times (and Paul’s summary of the Grace 2013 halving times) as anchoring points and shade them upward to account for the considerations raised above. There is massive room for judgment in whether and how much to shade upward; I expect many readers will want to change my assumptions here, and some will believe it is more reasonable to shade downward.
Curious to read any other papers on this topic. More research benchmarking algorithmic gains seems tractable and if anybody has a well-scoped question I might also be interested in doing that research.
↑ comment by Andrew McKnight (andrew-mcknight) · 2022-08-03T21:32:28.500Z · LW(p) · GW(p)
Is there reason to believe algorithmic improvements follow an exponential curve? Do you happen to know a good source on this?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-04T06:36:36.297Z · LW(p) · GW(p)
As opposed to what, linear? Or s-curvy? S-curves look exponential until you get close to the theoretical limit. I doubt we are close to the theoretical limits.
Ajeya bases her estimate on empirical data, so if you want to see whether it's exponential go look at that I guess.
comment by aog (Aidan O'Gara) · 2022-08-03T03:18:05.344Z · LW(p) · GW(p)
My report estimates that the amount of training data required to train a model with N parameters scales as N^0.8, based significantly on results from Kaplan et al 2020. In 2022, the Chinchilla scaling result (Hoffmann et al 2022) showed that instead the amount of data should scale as N.
Are you concerned that pretrained language models might hit data constraints before TAI? Nostalgebraist estimates that there are roughly 3.2T tokens available publicly for language model pretraining. This estimate misses important potential data sources such as transcripts from audio and video [LW · GW] and private text conversations and email [LW · GW]. But the BioAnchors report estimates that the median transformative model will require a median of 22T data points, nearly an order of magnitude higher than this estimate.
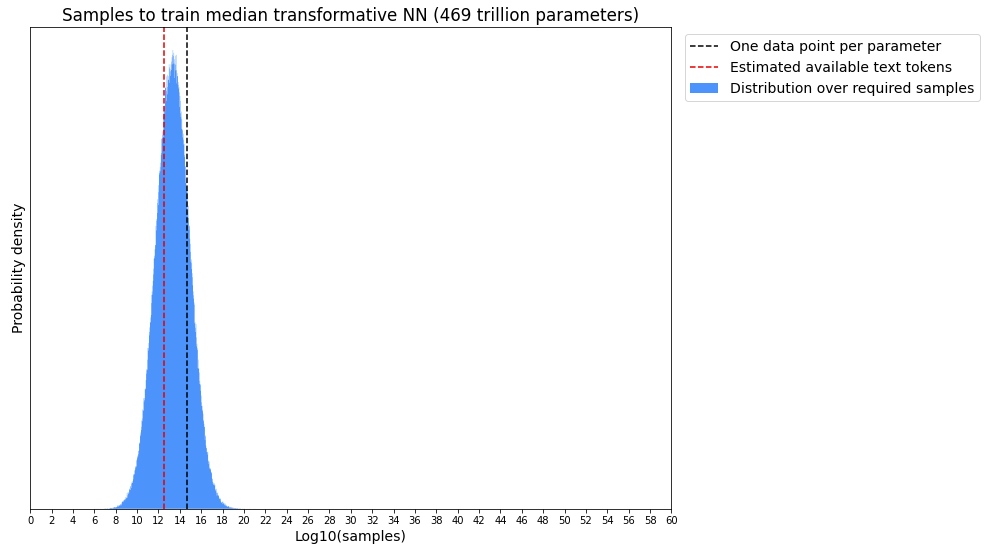
The BioAnchors estimate was also based on older scaling laws that placed a lower priority on data relative to compute. With the new Chinchilla scaling laws, more data would be required for compute-optimal training. Of course, training runs don't need to be compute-optimal: You can get away with using more compute and less data if you're constrained by data, even if it's going to cost more. And text isn't the only data a transformative model could use: audio, video, and RLHF on diverse tasks all seem like good candidates.
Does the limited available public text data affect your views of how likely GPT-N is to be transformative? Are there any considerations overlooked here, or questions that could use a more thorough analysis? Curious about anybody else's opinions, and thanks for sharing the update, I think it's quite persuasive.
Replies from: porby, conor-sullivan↑ comment by porby · 2022-08-03T03:59:51.317Z · LW(p) · GW(p)
I suspect Chinchilla's implied data requirements aren't going to be that much of a blocker for capability gain. It is an important result, but it's primarily about the behavior of current backpropped transformer based LLMs.
The data inefficiency of many architectures was known before Chinchilla, but the industry worked around it because it wasn't yet a bottleneck. After Chinchilla, it has become one of the largest architectural optimization targets. Given the increase in focus and the relative infancy of the research, I would guess the next two years will see the picking of some very juicy low hanging fruit. There are a lot of options floating nearby in conceptspace and there is a lot of room to grow; I'd be surprised if data limitations still feel as salient in 2025.
↑ comment by Lone Pine (conor-sullivan) · 2022-08-03T13:03:17.981Z · LW(p) · GW(p)
What's RLHF?
Replies from: Frederik↑ comment by Tom Lieberum (Frederik) · 2022-08-03T13:05:49.441Z · LW(p) · GW(p)
Reward Learning from Human Feedback
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2022-08-03T18:59:37.975Z · LW(p) · GW(p)
Reinforcement* learning from human feedback
Replies from: Frederik↑ comment by Tom Lieberum (Frederik) · 2022-08-03T21:28:01.532Z · LW(p) · GW(p)
Well I thought about that but I wasn't sure whether reinforcement learning from human feedback wouldn't be just a strict subset of reward learning from human feedback. If reinforcement is indeed the strict definition then I concede but I dont think it makes sense.
Replies from: Lanrian, Frederik↑ comment by Lukas Finnveden (Lanrian) · 2022-08-03T21:50:41.601Z · LW(p) · GW(p)
The acronym is definitely used for reinforcement learning. ["RLHF" "reinforcement learning from human feedback"] gets 564 hits on google, ["RLHF" "reward learning from human feedback"] gets 0.
Replies from: Frederik↑ comment by Tom Lieberum (Frederik) · 2022-08-08T11:55:09.596Z · LW(p) · GW(p)
Thanks for verifying! I retract my comment.
↑ comment by Tom Lieberum (Frederik) · 2022-08-03T21:33:52.464Z · LW(p) · GW(p)
I think historically reinforcement has been used more in that particular constellation (see eg deep RL from HP paper) but as I noted I find reward learning more apt as it points to the hard thing being the reward learning, i.e. distilling human feedback into an objective, rather than the optimization of any given reward function (which technically need not involve reinforcement learning)
comment by Rob Bensinger (RobbBB) · 2022-08-03T22:02:32.605Z · LW(p) · GW(p)
Thanks for the update, Ajeya! I found the details here super interesting.
I already thought that timelines disagreements within EA weren't very cruxy, and this is another small update in that direction: I see you and various MIRI people and Metaculans give very different arguments about how to think about timelines, and then the actual median year I tend to hear is quite similar.
(And also, all of the stated arguments on all sides continue to seem weak/inconclusive to me! So IMO there's not much disagreement, and it would be very easy for all of us to be wrong simultaneously. My intuition is that it would be genuinely weird if AGI is much more than 70 years away, but not particularly weird if it's 1 year away, 10 years away, 60 years away, etc.)
I think the main value of in-depth timelines research and debate has been that it reveals disagreements about other topics (background views about ML, forecasting methodology, etc.).
Replies from: ajeya-cotra↑ comment by Ajeya Cotra (ajeya-cotra) · 2022-08-04T16:49:58.140Z · LW(p) · GW(p)
Yeah I agree more of the value of this kind of exercise (at least within the community) is in revealing more granular disagreements about various things. But I do think there's value in establishing to more external people something high level like "It really could be soon and it's not crazy or sci fi to think so."
comment by Jacob Pfau (jacob-pfau) · 2022-08-03T01:26:55.734Z · LW(p) · GW(p)
In terms of decision relevance, the update towards "Automate AI R&D → Explosive feedback loop of AI progress specifically" seems significant to research prioritization. Under such a scenario, getting the automating AI R&D tools to be honest and transparent is more likely to be a pre-requisite for aligning TAI. Here's my speculation as to what automated AI R&D scenario implies for prioritization:
Candidates for increased priority:
- ELK for code generation
- Interpretability for transformers ...
Candidates for decreased priority:
- Safety of real world training of RL models e.g. impact regularization, assistance games, etc.
- Safety assuming infinite intelligence/knowledge limit ...
Of course, each of these potential consequences requires further argument to justify. For instance, I could imagine becoming convinced that AI R&D will find improved RL algorithms more quickly than other areas--in which case things like impact regularization might be particularly valuable.
comment by Zach Stein-Perlman · 2022-08-02T23:32:38.458Z · LW(p) · GW(p)
Good post!
I understand that the specific numbers in this post are "rough" and "volatile," but I want to note that 35% by 2036, 50% by 2040, and 60% by 2050 means 3.75% per year 2036–2040 and 1% per year 2040–2050, which is a surprisingly steep drop-off. Or as an alternative framing, conditional on TAI not having appeared by 2040, my expected credence in 2040 that TAI appears in the next 10 years is much greater than 20% (where 20% is your implied probability of TAI between 2040 and 2050, conditional on no TAI in 2040). My median timeline is somewhat shorter than yours, but my credence in TAI by 2050 is substantially higher.
(That said, I lack something like the knowledge, courage, or epistemic virtue to be more explicit about my timelines, because it's hard; strong-upvote for this useful and virtuous post, and thanks for using specific numbers so much.)
Replies from: ajeya-cotra↑ comment by Ajeya Cotra (ajeya-cotra) · 2022-08-03T00:05:16.647Z · LW(p) · GW(p)
Hm, yeah, I bet if I reflected more things would shift around, but I'm not sure the fact that there's a shortish period where the per-year probability is very elevated followed by a longer period with lower per-year probability is actually a bad sign.
Roughly speaking, right now we're in an AI boom where spending on compute for training big models is going up rapidly, and it's fairly easy to actually increase spending quickly because the current levels are low. There's some chance of transformative AI in the middle of this spending boom -- and because resource inputs are going up a ton each year, the probability of TAI by date X would also be increasing pretty rapidly.
But the current spending boom is pretty unsustainable if it doesn't lead to TAI. At some point in the 2040s or 50s, if we haven't gotten transformative AI by then, we'll have been spending 10s of billions training models, and it won't be that easy to keep ramping up quickly from there. And then because the input growth will have slowed, the increase in probability from one year to the next will also slow. (That said, not sure how this works out exactly.)
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2022-08-03T00:17:42.507Z · LW(p) · GW(p)
(+1. I totally agree that input growth will slow sometime if we don't get TAI soon. I just think you have to be pretty sure that it slows right around 2040 to have the specific numbers you mention, and smoothing out when it will slow down due to that uncertainty gives a smoother probability distribution for TAI.)
comment by nostalgebraist · 2022-08-06T02:05:34.227Z · LW(p) · GW(p)
Now I’m inclined to think that just automating most of the tasks in ML research and engineering -- enough to accelerate the pace of AI progress manyfold -- is sufficient.
This seems to assume that human labor is currently the limiting bottleneck in AI research, and by a large multiplicative factor.
That doesn't seem likely to me. Compute is a nontrivial bottleneck even in many small-scale experiments, and in particular is a major bottleneck for research that pushes the envelope of scale, which is generally how new SOTA results and such get made these days.
To be concrete, consider this discussion of "the pace of AI progress" elsewhere in the post:
But progress on some not-cherry-picked benchmarks was notably faster than what forecasters predicted, so that should be some update toward shorter timelines for me.
That post is about four benchmarks. Of the four, it's mostly MATH and MMLU that are driving the sense of "notably faster progress" here. The SOTAs for these were established by
- MATH: Minerva, which used a finetuned PaLM-540B model together with already existing (if, in some cases, relatively recently introduced) techniques like chain-of-thought
- MMLU: Chinchilla, a model with the same design and (large) training compute cost as the earlier Gopher, but with different hyperparameters chosen through a conventional (if unusually careful) scaling law analysis
In both cases, relatively simple and mostly non-original techniques were combined with massive compute. Even if you remove the humans entirely, the computers still only go as far as they go.
(Human labor is definitely a bottleneck in making the computers go faster -- like hardware development, but also specialized algorithms for large-scale training. But this is a much more specialized area than "AI research" generally, so there's less available pretraining data on it -- especially since a large[r] fraction of this kind of work is likely to be private IP.)
comment by Adam Scholl (adam_scholl) · 2022-08-03T23:03:58.182Z · LW(p) · GW(p)
I don’t expect a discontinuous jump in AI systems’ generality or depth of thought from stumbling upon a deep core of intelligence
I felt surprised reading this, since "ability to automate AI development" feels to me like a central example of a "deep core of intelligence"—i.e., of a cognitive ability which makes attaining many other cognitive abilities far easier. Does it not feel like a central example to you?
Replies from: ajeya-cotra, PeterMcCluskey↑ comment by Ajeya Cotra (ajeya-cotra) · 2022-08-04T16:46:11.852Z · LW(p) · GW(p)
I don't see it that way, no. Today's coding models can help automate some parts of the ML researcher workflow a little bit, and I think tomorrow's coding models will automate more and more complex parts, and so on. I think this expansion could be pretty rapid, but I don't think it'll look like "not much going on until something snaps into place."
↑ comment by PeterMcCluskey · 2022-08-04T16:47:38.206Z · LW(p) · GW(p)
I see a difference between finding a new core of intelligence versus gradual improvements to the core(s) of intelligence that we're already familiar with.
comment by Yonatan Cale (yonatan-cale-1) · 2022-08-04T04:03:47.171Z · LW(p) · GW(p)
Epistemic Status: Trying to form my own views, excuse me if I'm asking a silly question.
TL;DR: Maybe this is over fitted to 2020 information?
My Data Science friends tell me that to train a model, we take ~80% of the data, and then we test our model on the last 20%.
Regarding your post: I wonder how you'd form your model based on only 2018 information. Would your model nicely predict the 2020 information or would it need an update (hinting that it is over fitted)? I'm asking this because it seems like the model here depends very much on cutting edge results, which I would guess makes it very sensitive to new information.
comment by Quadratic Reciprocity · 2022-08-03T01:17:03.511Z · LW(p) · GW(p)
As a result, my timelines have also concentrated more around a somewhat narrower band of years. Previously, my probability increased from 10% to 60% over the course of the ~32 years from ~2032 and ~2064; now this happens over the ~24 years between ~2026 and ~2050.
10% probability by 2026 (!!)
↑ comment by Zach Stein-Perlman · 2022-08-03T01:57:18.947Z · LW(p) · GW(p)
Huh, I claim Ajeya's timelines are much more coherent if we replace 2026 with 2027.5 or 2028.* 10% between now and 2026, then 5% between 2026 and 2030, then 20% between 2030 and 2036 is really weird.
*Changing 2026 (rather than 2030) just because Ajeya's 2026 cumulative probability seems less considered than her 2030 and 2036 cumulative probabilities.
Replies from: ajeya-cotra, Quadratic Reciprocity↑ comment by Ajeya Cotra (ajeya-cotra) · 2022-08-03T05:09:18.772Z · LW(p) · GW(p)
(Coherence aside, when I now look at that number it does seem a bit too high, and I feel tempted to move it to 2027-2028, but I dunno, that kind of intuition is likely to change quickly from day to day.)
Replies from: Lukas_Gloor↑ comment by Lukas_Gloor · 2022-08-03T13:14:35.428Z · LW(p) · GW(p)
Aren't a lot of compute-growth trends likely to run out of room before 2026? If so, a bump before 2026 could make sense. (Though less so if we think compute is unlikely to be the bottleneck for TAI – I don't know to what degree people see the chinchilla insight as a significant update here.)
↑ comment by Quadratic Reciprocity · 2022-08-03T03:29:55.896Z · LW(p) · GW(p)
While that is more coherent, it feels wrong to change the numbers like that if it causes losing track of the intuition of TAI by 2026 with probability 10%
comment by Lauro Langosco · 2022-08-03T12:57:09.947Z · LW(p) · GW(p)
But in my report I arrive at a forecast by fixing a model size based on estimates of brain computation, and then using scaling laws to estimate how much data is required to train a model of that size. The update from Chinchilla is then that we need more data than I might have thought.
I'm confused by this argument. The old GPT-3 scaling law is still correct, just not compute-optimal. If someone wanted to, they could still go on using the old scaling law. So discovering better scaling can only lead to an update towards shorter timelines, right?
(Except if you had expected even better scaling laws by now, but it didn't sound like that was your argument?)
Replies from: kave↑ comment by kave · 2022-08-03T15:17:55.053Z · LW(p) · GW(p)
If you assume the human brain was trained roughly optimally, then requiring more data, at a given parameter number, to be optimal pushes timelines out. If instead you had a specific loss number in mind, then a more efficient scaling law would pull timelines in.
Replies from: Lauro Langosco, Victor Levoso↑ comment by Lauro Langosco · 2022-08-05T20:23:17.483Z · LW(p) · GW(p)
Gotcha, this makes sense to me now, given the assumption that to get AGI we need to train a P-parameter model on the optimal scaling, where P is fixed. Thanks!
...though now I'm confused about why we would assume that. Surely that assumption is wrong?
- Humans are very constrained in terms of brain size and data, so we shouldn't assume that these quantities are scaled optimally in some sense that generalizes to deep learning models.
- Anyhow we don't need to guess the amount of data the human brain needs: we can just estimate it directly, just like we estimate brain-parameter count.
To move to a more general complaint about the bio anchors paradigm: it never made much sense to assume that current scaling laws would hold; clearly scaling will change once we train on new data modalities; we know that human brains have totally different scaling laws than DL models; and an AGI architecture will again have different scaling laws. Going with the GPT-3 scaling law is a very shaky best guess.
So it seems weird to me to put so much weight on this particular estimate, such that someone figuring out how to scale models much more cheaply would update one in the direction of longer timelines! Surely the bio anchor assumptions cannot possibly be strong enough to outweigh the commonsense update of 'whoa, we can scale much more quickly now'?
The only way that update makes sense is if you actually rely mostly on bio anchors to estimate timelines (rather than taking bio anchors to be a loose prior, and update off the current state and rate of progress in ML), which seems very wrong to me.
↑ comment by Victor Levoso · 2022-08-05T13:16:23.852Z · LW(p) · GW(p)
Another posible update is towards shorter timelines if you think that humans might not be trained whith the optimal amount of data(since we can't just for example read the entire internet) and so it might be posible to get better peformance whith less parameters, if you asume brain has similar scaling laws.
comment by memeticimagery · 2022-08-03T19:37:34.765Z · LW(p) · GW(p)
- I’m somewhat surprised that I haven’t seen more vigorous commercialization of language models and commercial applications that seem to reliably add real value beyond novelty; this is some update toward thinking that language models are less impressive than they seemed to me, or that it’s harder to translate from a capable model into economic impact than I believed.
Minor point here, but I think this is less to do with the potential commercial utility of LLMs and more relating to the reticence of large tech companies to publicly release a LLM that poses a significant risk of social harm. It is my intuition that in comparison with people on LW, the higher ups at the likes of Google are relatively more worried about those risks and the associated potential PR disaster. Entirely safety proofing a LLM in that way seems like it would be incredibly difficult as well as subjective and may greatly slow the release of such models.
comment by Viliam · 2022-08-05T21:05:11.411Z · LW(p) · GW(p)
It took the model a couple of hours per game to learn environment dynamic facts like “the paddle moves left to right”, “if an enemy hits you you die,” etc. The relevant comparison is not how much time it would take a human to learn to play the game, it’s how much time it would take a human to get what’s going on and what they’re supposed to aim for -- and the latter is not something that it would take a human 2 hours of watching to figure out (probably more like 15-60 seconds).
I am probabably missing some important point, but the comparison to a "human" sounds unfair, because you clearly don't mean a newborn, but rather someone who already has lots of experience with moving things left and right, or seeing things hit by something.
Similarly...
it takes very little time for a human to learn a pattern like that. If a bilingual French-and-English-speaking human saw a context with two examples of translating an English sentence into French, they would ~immediately understand what was going on.
I guess this could be experimentally verified with a bilingual toddler who speaks a different language with each parent, but has never seen them talk to each other. How quickly would it grasp the concept of "translation"?
comment by rossg · 2022-08-04T01:51:44.588Z · LW(p) · GW(p)
I think your timeline is on point regarding capabilities. However, I do not entirely follow the jump from expert-level programming and brute-force search to an "explosive feedback loop of AI progress". You point out that there is a "clear-cut search space" in machine learning, which is true, and I agree that brute-force search could be expected to yield some progress, likely substantial progress, whereas in other scientific disciplines similar progress would be unlikely. I will even concede that explosive progress is possible, but I fail to grasp why it is likely. I think that the "clear-cut search space" is limited to low-hanging fruit, such as "different small tweaks to architectures, loss functions, optimization algorithms", and I expect that to get from automated AI progress to automated scientific discovery something more is needed. If you're suggesting that efficiency improvements from "different small tweaks to architectures, loss functions, optimization algorithms" would be of an order of magnitude or greater—enough to move progressively on to medium and longer horizon models—is there evidence in this post or the original report to support this that I am missing? This could plausibly lead to an "explosive feedback loop of AI progress", but I would not assume that it will. Alternatively, it seems plausible that "directly writing learning algorithms much more sample-efficient than SGD" would be sufficient to get to automated scientific discovery—are you suggesting that "different small tweaks to architectures, loss functions, optimization algorithms" is going to be enough to generate a novel learning algorithm? The search space for that seems "less clear-cut" and much more like what would be required to automate progress in other scientific disciplines.
comment by Shiroe · 2022-08-03T04:19:49.606Z · LW(p) · GW(p)
You mention that you're surprised to have not seen "more vigorous commercialization of language models" recently beyond mere "novelty". Can you say more about what particular applications you had in mind? Also, do you consider AI companionship as useful or merely novel?
I expect the first killer app that goes mainstream will mark the PONR, i.e. the final test of whether the market prefers capabilities or safety.
Replies from: ajeya-cotra, yitz↑ comment by Ajeya Cotra (ajeya-cotra) · 2022-08-04T16:47:15.616Z · LW(p) · GW(p)
Can you say more about what particular applications you had in mind?
Stuff like personal assistants who write emails / do simple shopping, coding assistants that people are more excited about than they seem to be about Codex, etc.
(Like I said in the main post, I'm not totally sure what PONR refers to, but don't think I agree that the first lucrative application marks a PONR -- seems like there are a bunch of things you can do after that point, including but not limited to alignment research.)
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-08-04T19:13:47.125Z · LW(p) · GW(p)
Well, the first killer app is biology and protein folding.
↑ comment by Yitz (yitz) · 2022-08-03T14:13:05.080Z · LW(p) · GW(p)
What would you roughly expect such a killer app to look like?
Replies from: Shiroe, sharmake-farah↑ comment by Shiroe · 2022-08-04T04:59:48.016Z · LW(p) · GW(p)
Something like AI Dungeon but not so niche, like for emails. People paying money to outsource a part of their creative intellect is what appears significant to me.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-08-04T17:56:45.598Z · LW(p) · GW(p)
I’m already doing that with my friends, one of whom is a musician who I’ve provided AI-generated album covers for.
↑ comment by Noosphere89 (sharmake-farah) · 2022-08-03T16:32:16.558Z · LW(p) · GW(p)
Protein folding is already a killer app, and biology looks to benefit a lot from this. Draw your own conclusions from whether it's a good or bad thing for safety:
comment by TekhneMakre · 2022-08-04T21:05:37.847Z · LW(p) · GW(p)
I wouldn’t be surprised by significant movements.
I wonder if there's any math that applies to belief-in-general that gives rules of thumb or something for dealing with model uncertainty, like some sort of Laplace rule or something that takes as input how many times / by how much one has up until now updated one's beliefs by adding models / hypotheses / concepts.