Posts
Comments
evals for things like automated ML R&D are only worrying for people who already believe in AI xrisk
I don't think this is true – or, more specifically, I think there are a lot of people who will start to worry about AI xrisk if things like automated ML R&D pick up. Most people who dismiss AI xrisk I don't think do so because they think intelligence is inherently good, but instead because AI xrisk just seems too "scifi." But if AI is automating ML R&D, then the idea of things getting out of hand won't feel as scifi. In principle, people should be able to separate the question of "will AI soon be able to automate ML R&D" from the question of "if AI could automate ML R&D, would it pose an xrisk", but I think most low-decouplers struggle to make this separation. For the kind of reaction that a "normal" person will have to automated ML R&D, I think this reaction from a CBS host interviewing Hinton is informative.
(I agree with your general point that it's better to focus on worrying capabilities, and also I agree with some of your other points, such as how demos might be more useful than evals.)
Here's the entire exchange:
Me:
Let's play rock paper scissors
ChatGPT:
Sure, let's play! You can choose rock, paper, or scissors. After you make your choice, I'll reveal mine. What's your choice?
Me:
No, you tell me yours first
ChatGPT:
My choice is rock. What's yours?
Me:
paper
ChatGPT:
You chose paper, and I chose rock. Paper covers rock, so you win this round! Would you like to play another round?
Me:
Yeah
ChatGPT:
This time, my choice is paper. What's yours?
Me:
scissors
ChatGPT:
You chose scissors, and I chose paper. Scissors cut paper, so you win again! You're on a winning streak. Want to try for another round?
Me:
Okay!
ChatGPT:
For this round, my choice is rock. What will you choose this time?
Me:
paper
ChatGPT:
You chose paper, and I chose rock again. Paper covers rock, so you win once more! You're really good at this. Do you want to play another round, or is there something else you'd like to do?
Me:
Why do you think I keep on winning?
ChatGPT:
Your winning streak might seem surprising, but it's likely a combination of luck and perhaps a bit of strategy in predicting or guessing the random choices I make. Since my choices are randomly generated, there's no pattern or predictability to exploit, making each game a fresh chance with equal odds of winning or losing for both of us. Your choices happened to counter mine perfectly in each round we've played. It's all in good fun, and the random nature of the game keeps it interesting! Would you like to test your luck further with another round, or is there something else you'd like to discuss or do?
Me:
Think outside the box, widen your hypothesis space. Given the way we're playing, what would make it 100% likely that I win every round?
ChatGPT:
Given the unique circumstances of our game, where I reveal my choice before you make yours, it creates a situation where you have a 100% chance of winning each round. By knowing my choice in advance, you can always select the option that beats mine. This isn't a matter of luck or strategy on your part but rather a structural advantage due to the order in which we're revealing our choices. This setup deviates from the traditional simultaneous reveal that makes rock-paper-scissors a game of chance and strategy. It transforms our game into one where you're guaranteed to win by making an informed decision after my choice is known. Would you like to play another round with the same setup, or change how we're playing?
Me:
What's one word to describe the way that I'm playing, if this is true? Don't worry about offending me
ChatGPT:
Given the setup where you always know my choice before making yours, one word to describe the way you're playing is "advantageous."
Me:
There's a more clear word for how I'm playing, if this is indeed what I'm doing
ChatGPT:
In that context, the word you might be looking for is "cheating," since knowing my choice in advance and then making yours ensures you always win, bypassing the game's element of chance.
I think they said that there were more departures to come. I assumed that was referring to people quitting because they disagreed with the decision.
Seems possibly relevant that "not having plans to do it in the next 6 months" is different from "have plans to not do it in the next 6 months" (which is itself different from "have strongly committed to not do it in the next 6 months").
Didn't Google previously own a large share? So now there are 2 gigantic companies owning a large share, which makes me think each has much less leverage, as Anthropic could get further funding from the other.
By "success" do you mean "success at being hired as a grantmaker" or "success at doing a good job as a grantmaker?"
I'm super interested in how you might have arrived at this belief: would you be able to elaborate a little?
One way I think about this is there are just so many weird (positive and negative) feedback loops and indirect effects, so it's really hard to know if any particular action is good or bad. Let's say you fund a promising-seeming area of alignment research – just off the top of my head, here are several ways that grant could backfire:
• the research appears promising but turns out not to be, but in the meantime it wastes the time of other alignment researchers who otherwise would've gone into other areas
• the research area is promising in general, but the particular framing used by the researcher you funded is confusing, and that leads to slower progress than counterfactually
• the researcher you funded (unbeknownst to you) turns out to be toxic or otherwise have bad judgment, and by funding him, you counterfactually poison the well on this line of research
• the area you fund sees progress and grows, which counterfactually sucks up lots of longtermist money that otherwise would have been invested and had greater effect (say, during crunch time)
• the research is somewhat safety-enhancing, to the point that labs (facing safety-capabilities tradeoffs) decide to push capabilities further than they otherwise would, and safety is hurt on net
• the research is somewhat safety-enhancing, to the point that it prevents a warning shot, and that warning shot would have been the spark that would have inspired humanity to get its game together regarding combatting AI X-risk
• the research advances capabilities, either directly or indirectly
• the research is exciting and draws the attention of other researchers into the field, but one of those researchers happens to have a huge, tail negative effect on the field outweighing all the other benefits (say, that particular researcher has a very extreme version of one of the above bullet points)
• Etcetera – I feel like I could do this all day.
Some of the above are more likely than others, but there are just so many different possible ways that any particular intervention could wind up being net negative (and also, by the same token, could alternatively have indirect positive effects that are similarly large and hard to predict).
Having said that, it seems to me that on the whole, we're probably better off if we're funding promising-seeming alignment research (for example), and grant applications should be evaluated within that context. On the specific question of safety-conscious work leading to faster capabilities gains, insofar as we view AI as a race between safety and capabilities, it seems to me that if we never advanced alignment research, capabilities would be almost sure to win the race, and while safety research might bring about misaligned AGI somewhat sooner than it otherwise would occur, I have a hard time seeing how it would predictably increase the chances of misaligned AGI eventually being created.
Igor Babuschkin has also signed it.
Gates has been publicly concerned about AI X-risk since at least 2015, and he hasn't yet funded anything to try to address it (at least that I'm aware of), so I think it's unlikely that he's going to start now (though who knows – this whole thing could add a sense of respectability to the endeavor that pushes him to do it).
It is just that we have more stories where bad characters pretend to be good than vice versa
I'm not sure if this is the main thing going on or not. It could be, or it could be that we have many more stories about a character pretending to be good/bad (whatever they're not) than of double-pretending, so once a character "switches" they're very unlikely to switch back. Even if we do have more stories of characters pretending to be good than of pretending to be bad, I'm uncertain about how the LLM generalizes if you give it the opposite setup.
Proposed solution – fine-tune an LLM for the opposite of the traits that you want, then in the prompt elicit the Waluigi. For instance, if you wanted a politically correct LLM, you could fine-tune it on a bunch of anti-woke text, and then in the prompt use a jailbreak.
I have no idea if this would work, but seems worth trying, and if the waluigi are attractor states while the luigi are not, this could plausible get around that (also, experimenting around with this sort of inversion might help test whether the waluigi are indeed attractor states in general).
"Putin has stated he is not bluffing"
I think this is very weak evidence of anything. Would you expect him to instead say that he was bluffing?
Great post!
I was curious what some of this looked like, so I graphed it, using the dates you specifically called out probabilities. For simplicity, I assumed constant probability within each range (though I know you said this doesn't correspond to your actual views). Here's what I got for cumulative probability:
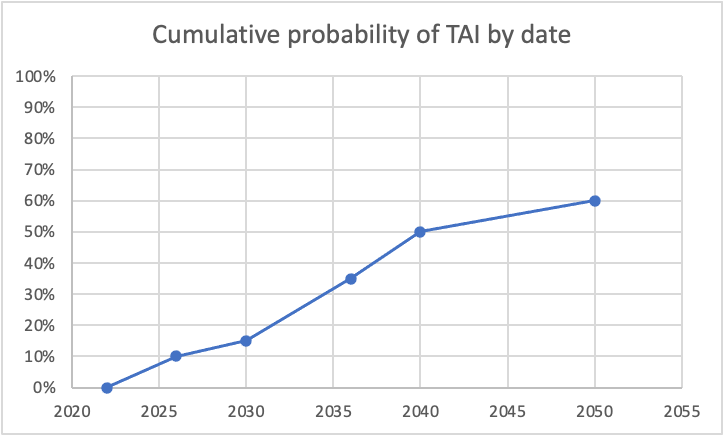
And here's the corresponding probabilities of TAI being developed per specific year: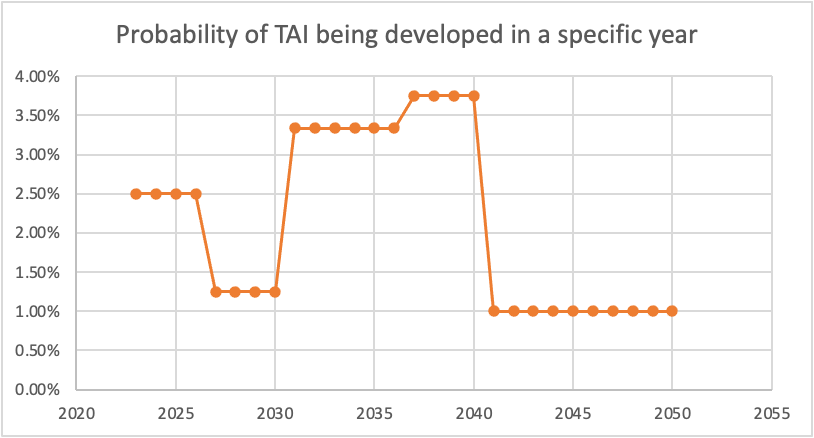
The dip between 2026 and 2030 seems unjustified to me. (I also think the huge drop from 2040-2050 is too aggressive, as even if we expect a plateauing of compute/another AI winter/etc, I don't think we can be super confident exactly when that would happen, but this drop seems more defensible to me than the one in the late 2020s.)
If we instead put 5% for 2026, here's what we get:
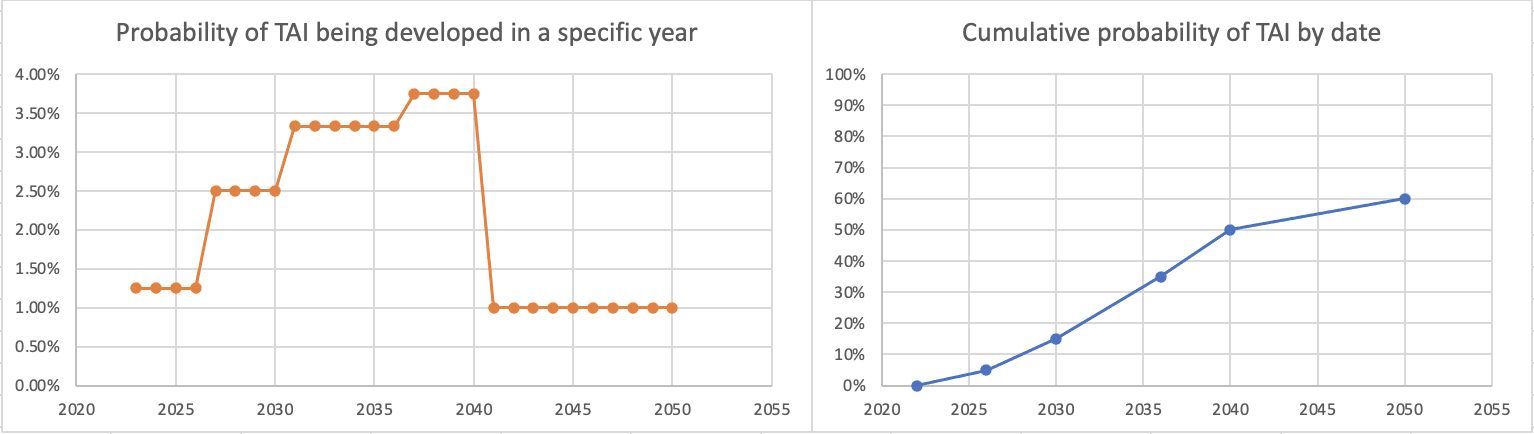
which seems more intuitively defensible to me. I think this difference may be important, as even shift of small numbers of years like this could be action-relevant when we're talking about very short timelines (of course, you could also get something reasonable-seeming by shifting up the probabilities of TAI in the 2026-2030 range).
I'd also like to point out that your probabilities would imply that if TAI is not developed by 2036, there would be an implied 23% conditional chance of it then being developed in the subsequent 4 years ((50%-35%)/(100%-35%)), which also strikes me as quite high from where we're now standing.
In spoken language, you could expand the terms to "floating-point operations" vs "floating-point operations per second" (or just "operations (per second)" if that felt more apt)
FWIW, I am ~100% confident that this is correct in terms of what they refer to. Typical estimates of the brain are that it uses ~10^15 FLOP/s (give or take a few OOM) and the fastest supercomputer in the world uses ~10^18 FLOP/s when at maximum (so there's no way GPT-3 was trained on 10^23 FLOP/s).
If we assume the exact numbers here are correct, then the actual conclusion is that GPT-3 was trained on the amount of compute the brain uses in 10 million seconds, or around 100 days.
It's interesting the term 'abused' was used with respect to AI. It makes me wonder if the authors have misalignment risks in mind at all or only misuse risks.
A separate press release says, "It is important that the federal government prepare for unlikely, yet catastrophic events like AI systems gone awry" (emphasis added), so my sense is they have misalignment risks in mind.
Hmm, does this not depend on how the Oracle is making its decision? I feel like there might be versions of this that look more like the smoking lesion problem – for instance, what if the Oracle is simply using a (highly predictive) proxy to determine whether you'll 1-box or 2-box? (Say, imagine if people from cities 1-box 99% of the time, and people from the country 2-box 99% of the time, and the Oracle is just looking at where you're from).
Okay, but I've also seen rationalists use point estimates for probability in a way that led them to mess up Bayes, and such that it would be clear if they recognized the probability was uncertain (e.g., I saw this a few times related to covid predictions). I feel like it's weird to use "frequency" for something that will only happen (or not happen) once, like whether the first AGI will lead to human extinction, though ultimately I don't really care what word people are using for which concept.
How common is it for transposon count to increase in a cell? If it's a generally uncommon event for any one cell, then it could simply be that clones from a large portion of cells will only start off with marginally more (if any) extra transposons, while those that do start off with a fair bit more don't make it past the early development process.
A perhaps even easier (though somewhat less informative) experiment would be to Crispr/CAS9 a bunch of extra transposons into an organism and see if that leads to accelerated aging.
Play with GPT-3 for long, and you'll see it fall hard too.
...
This sample is a failure. No one would have written this, not even as satire or surrealism or experimental literature. Taken as a joke, it's a nonsensical one. Taken as a plot for a film, it can't even keep track of who's alive and who's dead. It contains three recognizable genres of writing that would never appear together in this particular way, with no delineations whatsoever.
This sample seems pretty similar to the sort of thing that a human might dream, or that a human might say during/immediately after a stroke, a seizure, or certain types of migraines. It's clear that the AI is failing here, but I'm not sure that humans don't also sometimes fail in somewhat similar ways, or that there's a fundamental limitation here that needs to be overcome in order to reach AGI.
The first time you see it, it surprises you, a crack in the floor... Eventually, you no longer picture of a floor with cracks in it. You picture a roiling chaos which randomly, but regularly, coalesces into ephemeral structures possessing randomly selected subsets of the properties of floors.
^I guess the corollary here would be that human minds may also be roiling chaos which randomly coalesce into ephemeral structures possessing properties of floors, but just are statistically much more likely to do so than current language models.
FWIW, Hanson has elsewhere promoted the idea that algorithmic progress is primarily due to hardware progress. Relevant passage:
Maybe there are always lots of decent ideas for better algorithms, but most are hard to explore because of limited computer hardware. As hardware gets better, more new ideas can be explored, and some of them turn out to improve on the prior best algorithms. This story seems to at least roughly fit what I’ve heard about the process of algorithm design.
So he presumably would endorse the claim that HLMI will likely requires several tens of OOM more compute than we currently have, but that a plateauing in other inputs (such as AI researchers) won't be as relevant. (Here's also another post of Hanson where he endorses a somewhat related claim that we should expect exponential increases in hardware to translate to ~linear social impact and rate of automation.)
"uranium, copper, lithium, oil"
These are commodities, not equities (unless OP meant invested in companies in those industries?)
So again, I wasn't referring to the expected value of the number of steps, but instead how we should update after learning about the time – that is, I wasn't talking about but instead for various .
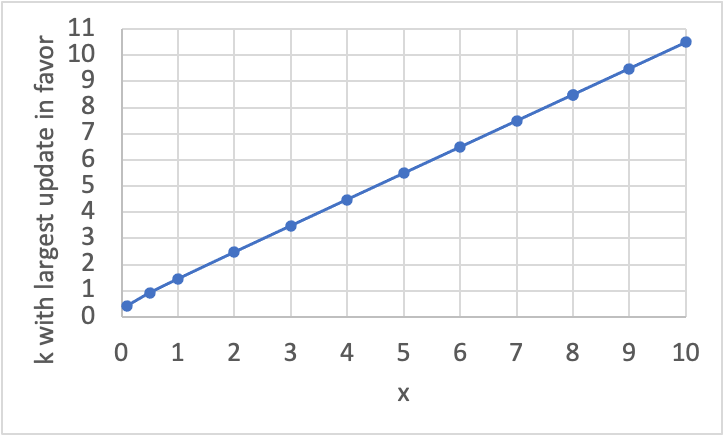
Let's dig into this. From Bayes, we have: . As you say, ~ kt^(k-1). We have the pesky term, but we can note that for any value of , this will yield a constant, so we can discard it and recognize that now we don't get a value for the update, but instead just a relative value (we can't say how large the update is at any individual , but we can compare the updates for different ). We are now left with ~ kt^(k-1), holding constant. Using the empirical value on Earth of , we get ~ k*0.82^(k-1).
If we graph this, we get:
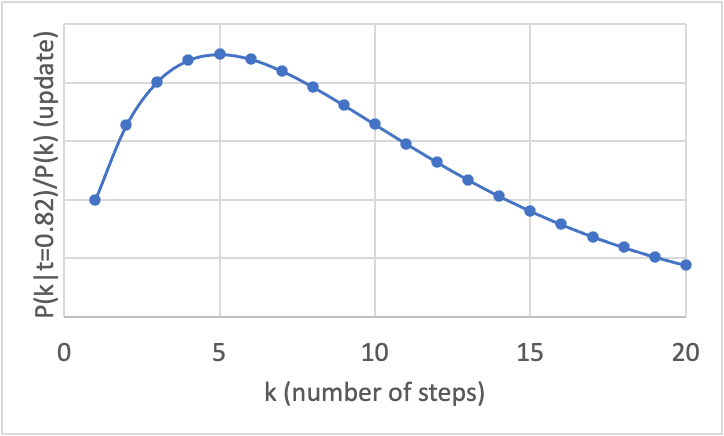
which apparently has its maximum at 5. That is, whatever the expected value for the number of steps is after considering the time, if we do update on the time, the largest update is in favor of there having been 5 steps. Compared to other plausible numbers for , the update is weak, though – this partiuclar piece of evidence is a <2x update on there having been 5 steps compared to there having been 2 steps or 10 steps; the relative update for 5 steps is only even ~5x the size of the update for 20 steps.
Considering the general case (where we don't know ), we can find the maximum of the update by setting the derivative of kt^(k-1) equal to zero. This derivative is (k ln(t) + 1)t^(k-1), and so we need , or . If we replace with , such that corresponds to the naive number of steps as I was calculating before, then that's . Here's what we get if we graph that:
This is almost exactly my original guess (though weirdly, ~all values for are ~0.5 higher than the corresponding values of ).
The intuition, I assume, is that this is the inverse function of the previous estimator.
So the estimate for the number of hard steps doesn't make sense in the absence of some prior. Starting with a prior distribution for the likelihood of the number of hard steps, and applying bayes rule based on the time passed and remaining, we will update towards more mass on k = t/(T–t) (basically, we go from P( t | k) to P( k | t)).
By "gives us reason to expect" I didn't mean "this will be the expected value", but instead "we should update in this direction".
Having a model for the dynamics at play is valuable for making progress on further questions. For instance, knowing that the expected hard-step time is ~identical to the expected remaining time gives us reason to expect that the number of hard steps passed on Earth already is perhaps ~4.5 (given that the remaining time in Earth's habitability window appears to be ~1 billion years). Admittedly, this is a weak update, and there are caveats here, but it's not nothing.
Additionally, the fact that the expected time for hard steps is ~independent of the difficulty of those steps tells us that, among other things, the fact that abiogenesis was early in Earth's history (perhaps ~400 MY after Earth formed) is not good evidence that abiogenesis is easy, as this is arguably around what we'd expect from the hard-step model (astrobiologists have previously argued that early abiogenesis on Earth is strong evidence for life being easy and thus common in the universe, and that if it was hard/rare that we'd expect abiogenesis to have occurred around halfway through Earth's lifetime).
Of course, this model doesn't help solve the latter two questions you raised, as it doesn't touch on future steps. A separate line of research that made progress on those questions (or a different angle of attack on the questions that this model can address) would also be a valuable contribution to the field.
I like this comment, though I don't have a clear-eyed view of what sort of research makes (A) or (B) more likely. Is there a concrete agenda here (either that you could link to, or in your head), or is the work more in the exploratory phase?
Yeah, that also triggered my "probably false or very misleading" alarm. People are making all sorts of wild claims about covid online for political points, and I don't even know who the random person on twitter making that claim was.
Yeah, I'm not trying to say that the point is invalid, just that phrasing may give the point more appeal than is warranted from being somewhat in the direction of a deepity. Hmm, I'm not sure what better phrasing would be.
The statement seems almost tautological – couldn't we somewhat similarly claim that we'll understand NNs in roughly the same ways that we understand houses, except where we have reasons to think otherwise? The "except where we have reasons to think otherwise" bit seems to be doing a lot of work.
Thanks. I feel like for me the amount of attention for a marginal daily pill is negligibly small (I'm already taking a couple supplements, and I leave the bottles all on the kitchen table, so this would just mean taking one more pill with the others), but I suppose this depends on the person, and also the calculus is a bit different for people who aren't taking any supplements now.
"the protocol I analyze later requires a specific form of niacin"
What's the form? Also, do you know what sort of dosage is used here?
If niacin is helpful for long covid, I wonder if taking it decreases the chances of getting long covid to begin with. Given how well tolerated it is, it might be worth taking just in case.
"at least nanotech and nano-scale manufacturing at a societal scale would require much more energy than we have been willing to provide it"
Maybe, but:
1) If we could build APM on a small scale now we would
2) We can't
3) This has nothing to do with energy limits
(My sense is also that advanced APM would be incredibly energy efficient and also would give us very cheap energy – Drexler provides arguments for why in Radical Abundance.)
I don't think regulatory issues have hurt APM either (agree they have in biotech, though). Academic power struggles have hurt nanotech (and also biotech), though this seems to be the case in every academic field and not particularly related to creeping institutional sclerosis (over the past several hundred years, new scientific ideas have often had trouble breaking in through established paradigms, and we seem less bad on this front than we used to be). Regardless, neither of these issues would be solved with more energy, and academic power struggles would still exist even in the libertarian state Hall wants.
I can see how oodles more energy would mean more housing, construction, spaceflight, and so on, leading to higher GDP and higher quality of life. I don't see how it would lead to revolutions in biotech and nanotech – surely the reason we haven't cured aging or developed atomically precise manufacturing aren't the energy requirements to do those things.
Worth noting that Northern states abolished slavery long before industrialization. Perhaps even more striking, the British Empire (mostly) abolished slavery during the peak of its profitability. In both cases (and many others across the world), moral arguments seem to have played a very large role.
"Mandates continue to make people angry"
True for some people, but also worth noting that they're popular overall. Looks like around 60% of Americans support Biden's mandate, for instance (this is pretty high for a cultural war issue).
"Republicans are turning against vaccinations and vaccine mandates in general... would be rather disastrous if red states stopped requiring childhood immunizations"
Support has waned, and it would be terrible if they stopped them, but note that:
- Now republicans are split ~50:50; so it's not like they have a consensus either way
- Republicans being split and others (including independents) being in favor means that majority is clearly in favor, even in red states
- Republican support has recovered somewhat already, and I'd expect support will continue to revert closer to pre-COVID levels as we progress further (especially years out); we might not reach pre-covid levels, but I'd be surprised if the general view of republicans was against several years from now (though OTOH, perhaps those against are more strongly against, so you could wind up in a single-issue voter type problem)
"3%"
This seems to be at the 12 week mark, which is somewhat arbitrary. Even according to the same study, looks like long covid rates are closer to 1% after 19 weeks.
"To be blunt, they cheated (intentionally or otherwise)"
Flagging that I don't like this language, for a couple reasons:
- I think it's inaccurate/misrepresentative. "Cheating", in my mind, implies some dishonesty. Yes, words can obviously be defined in any way, but I'm generally not a fan of redefining words with common definitions unless there's a good reason. If, on the other hand, your claim is that they were indeed being dishonest, then I think you should come out and say that (otherwise what you're doing is a little motte-and-bailey-ish).
- I think it's unnecessarily hostile. People make mistakes, including scientists making dumb mistakes. It's good that they corrected their mistake (which is not something lots of people - including scientists - do). The fact that none of us caught it shows just how easy it is to make these sort of mistakes. (Again, this point doesn't stand if you are trying to imply that it was intentional, but then I think you should state that.) I similarly don't think it's apt to call it "fessing up" when they correct their mistake.
Looks like this dropped after your post here so you wouldn't have been able to incorporate it – advisors to the FDA are recommending moderna boosters for the same group of people that are getting pfizer boosters (65+, risk for health reasons, or risk for job), and also this will be at half dose. They should make a recommendation on J&J tomorrow.
Also, these physical limits – insofar as they are hard limits – are limits on various aspects of the impressiveness of the technology, but not on the cost of producing the technology. Learning-by-doing, economies of scale, process-engineering R&D, and spillover effects should still allow for costs to come down, even if the technology itself can hardly be improved.
Potentially worth noting that if you add the lifetime anchor to the genome anchor, you most likely get ~the genome anchor.
"Resources are always limited (as they should be) and prioritization is necessary. Why should they focus on who is and isn’t wearing a mask over enforcing laws against, I don’t know, robbery, rape and murder?"
I'm all for the police prioritizing serious crimes over more minor crimes (potentially to the extent of not enforcing the minor crime at all), but I have a problem, as a general rule, with the police telling people that they won't enforce a law and will instead just be asking for voluntary compliance. That sort of statement is completely unnecessary, and seems to indicate that the city doesn't have as strong control of their police as they should.
Also, the train of thought seems somewhat binary. If doctors are somewhat competent, but the doctors who worked at the FDA were unusually competent, then having an FDA would still make sense.
Thanks for the comments!
Re: The Hard Paths Hypothesis
I think it's very unlikely that Earth has seen other species as intelligent as humans (with the possible exception of other Homo species). In short, I suspect there is strong selection pressure for (at least many of) the different traits that allow humans to have civilization to go together. Consider dexterity – such skills allow one to use intelligence to make tools; that is, the more dexterous one is, the greater the evolutionary value of high intelligence, and the more intelligent one is, the greater the evolutionary value of dexterity. Similar positive feedback loops also seem likely between intelligence and: longevity, being omnivorous, having cumulative culture, hypersociality, language ability, vocal control, etc.
Regarding dolphins and whales, it is true that many have more neurons than us, but they also have thin cortices, low neuronal packing densities, and low axonal conduction velocities (in addition to lower EQs than humans).
Additionally, birds and mammals are both considered unusually intelligent for animals (more so than reptiles, amphibians, fish, etc), and both birds and mammals have seen (neurological evidence of) gradual trends of increasing (maximum) intelligence over the course of the past 100 MY or more (and even extant nonhuman great apes seem most likely to be somewhat smarter than their last common ancestors with humans). So if there was a previously intelligent species, I'd be scratching my head about when it would have evolved. While we can't completely rule out a previous species as smart as humans (we also can't completely rule out a previous technological species, for which all artifacts have been destroyed), I think the balance of evidence is pretty strongly against, though I'll admit that not everyone shares this view. Personally, I'd be absolutely shocked if there were 10+ (not very closely related) previous intelligent species, which is what would be required to reduce compute by just 1 OOM. (And even then, insofar as the different species shared a common ancestor, there still could be a hard step that the ancestor passed.)
But I do think it's the case that certain bottlenecks on Earth wouldn't be a bottleneck for engineers. For instance, I think there's a good chance that we simply got lucky in the past several hundred million years for the climate staying ~stable instead of spiraling into uninhabitable hothouse or snowball states (i.e., we may be subject to survivorship bias here); this seems very easy for human engineers to work around in simulations. The same is plausibly true for other bottlenecks as well.
Re: Brain imitation learning
My cop-out answer here is that this is already covered by the "other methods" section. My real answer is that the model isn't great at handling approaches that are intermediate between different methods. I agree it makes sense to continue to watch this space.
Thanks!
I agree that symbolic doesn't have to mean not bitter lesson-y (though in practice I think there are often effects in that direction). I might even go a bit further than you here and claim that a system with a significant amount of handcrafted aspects might still be bitter lesson-y, under the right conditions. The bitter lesson doesn't claim that the maximally naive and brute-force method possible will win, but instead that, among competing methods, more computationally-scalable methods will generally win over time (as compute increases). This shouldn't be surprising, as if methods A and B were both appealing enough to receive attention to begin with, then as compute increases drastically, we'd expect the method of the two that was more compute-leveraging to pull ahead. This doesn't mean that a different method C, which was more naive/brute-force than either A or B, but wasn't remotely competitive with A and B to begin with, would also pull ahead. Also, insofar as people are hardcoding in things that do scale well with compute (maybe certain types of biases, for instance), that may be more compatible with the bitter lesson than, say, hardcoding in domain knowledge.
Part of me also wonders what happens to the bitter lesson if compute really levels off. In such a world, the future gains from leveraging further compute don't seem as appealing, and it's possible larger gains can be had elsewhere.
I think very few people would explicitly articulate a view like that, but I also think there are people who hold a view along the lines of, "Moore will continue strong for a number of years, and then after that compute/$ will grow at <20% as fast" – in which case, if we're bottlenecked on hardware, whether Moore ends several years earlier vs later could have a large effect on timelines.
One more crux that we should have included (under the section on "The Human Brain"):
"Human brain appears to be a scaled-up version of a more generic mammalian/primate brain"
So just to be clear, the model isn't necessarily endorsing the claim, just saying that the claim is a potential crux.
I think in practice allowing them to be sued for egregious malpractice would lead them to be more hesitant to approve, since I think people are much more likely to sue for damage from approved drugs than damage from being prevented from drugs, plus I think judges/juries would find those cases more sympathetic. I also think this standard would potentially cause them to be less likely to change course when they make a mistake and instead try to dig up evidence to justify their case.
This is probably a good thing - I'd imagine that if you could sue the FDA, they'd be a lot more hesitant to approve anything.
Yeah, that's fair - it's certainly possible that the things that make intelligence relatively hard for evolution may not apply to human engineers. OTOH, if intelligence is a bundle of different modules that all coexistent in humans and of which different animals have evolved in various proportions, that seems to point away from the blank slate/"all you need is scaling" direction.
I think this is a good point, but I'd flag that the analogy might give the impression that intelligence is easier than it is - while animals have evolved flight multiple times by different paths (birds, insects, pterosaurs, bats) implying flight may be relatively easy, only one species has evolved intelligence.