Modeling Failure Modes of High-Level Machine Intelligence
post by Ben Cottier (ben-cottier), Daniel_Eth, Sammy Martin (SDM) · 2021-12-06T13:54:38.147Z · LW · GW · 1 commentsContents
Outcomes of HLMI Development Correct Course as we Go Alignment ahead of time Misaligned HLMI Decisive Strategic Advantage (DSA) Influence-Seeking Behaviour Catastrophically Misaligned HLMI Loss of Control Conclusion None 1 comment
This post, which deals with some widely discussed failure modes of transformative AI, is part 7 in our sequence on Modeling Transformative AI Risk [? · GW]. In this series of posts, we are presenting a preliminary model of the relationships between key hypotheses in debates about catastrophic risks from AI. Previous posts in this sequence explained how different subtopics of this project, such as mesa-optimization [? · GW] and safety research agendas [AF · GW], are incorporated into our model.
We now come to the potential failure modes caused by High-Level Machine Intelligence (HLMI). These failure modes are the principal outputs of our model. Ultimately, we need to look at these outputs to analyze the effect that upstream parts of our model have on the risks, and in turn to guide decision-making. This post will first explain the relevant high-level components of our model before going through each component in detail. In the figure below, failure modes are represented by red-colored nodes.
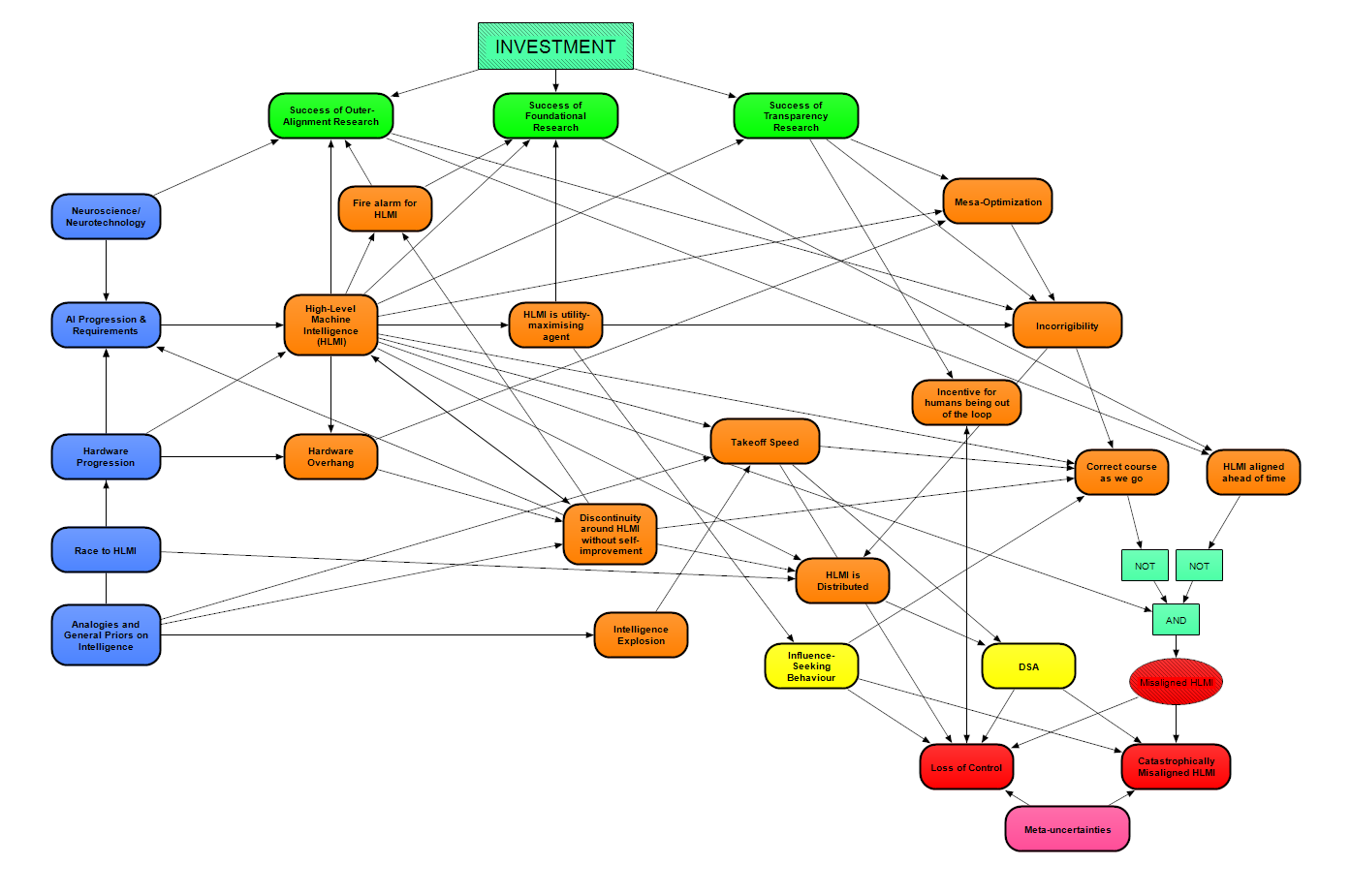
We do not model catastrophe itself in detail, because there seem to be a very wide range of ways it could play out. Rather, the outcomes are states from which existential catastrophe is very likely, or "points of no return" for a range of catastrophes. Catastrophically Misaligned HLMI covers scenarios where one HLMI, or a coalition of HLMIs and possibly humans, achieves a Decisive Strategic Advantage (DSA), and the DSA enables an existential catastrophe to occur. Loss of Control covers existential scenarios where a DSA does not occur; instead HLMI systems gain influence on the world in an incremental and distributed fashion, and either humanity's control over the future gradually fades away, or a sudden change in the world causes a sufficiently large and irreversibly damaging automation failure (see What failure looks like [AF · GW]); alternatively, the use of HLMI leads to an extreme "Moloch" scenario where most of what we value is burned down through competition.
Moving one step back, there are three major drivers of those outcomes. Firstly, Misaligned HLMI is the technical failure to align an HLMI. Second, the DSA module considers different ways DSA could be achieved by a leading HLMI project or coalition. Third, Influence-seeking Behavior considers whether an HLMI would pursue accumulation of power (e.g. political, financial) and/or manipulation of humans as an instrumental goal. This third consideration is based on whether HLMI will be agent-like and to what extent the Instrumental Convergence [? · GW] thesis applies.
Outcomes of HLMI Development
As discussed in the "impact of safety agendas [AF · GW]" post, we are still in the process of understanding the theory of change behind many of the safety agendas, and similarly our attempts at translating the success/failure of these safety agendas into models of HLMI development are still only approximate. With that said, for each of the green modules shown below on the Success of [agenda] Research, we model their affect on the likelihood of an incorrigible HLMI - in particular, if the research fails to produce its intended effect. Meanwhile, the Mesa-optimisation module [? · GW] evaluates the likelihood of dangers from learned optimization which would tend to make HLMI incorrigible [? · GW].
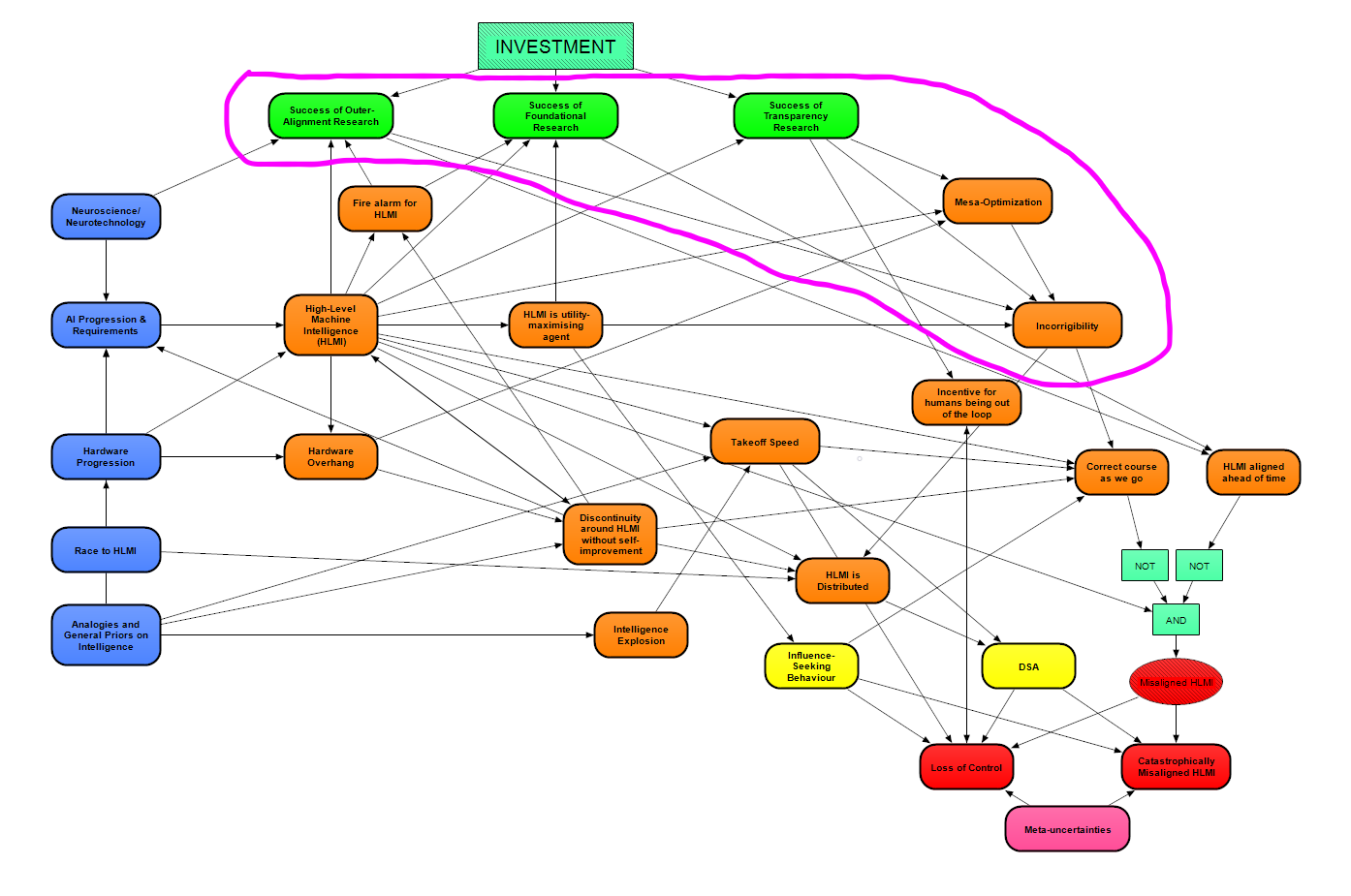
Besides Incorrigibility, the question of HLMI being aligned may be influenced by the expected speed and level of discontinuity during takeoff (represented by the modules Takeoff Speed and Discontinuity around HLMI without self-improvement, covered in Takeoff Speeds and Discontinuities [? · GW]). The expectation is that misalignment is more likely the faster progress becomes, because attempts at control will be harder if less time is available. Those factors - incorrigibility and takeoff - are more relevant if alignment will be attempted in an iterated manner post-HLMI, so they connect to the Correct course as we go module. On the other hand, if we have HLMI aligned ahead of time (another module), then we assume that the Success of [agenda] Research is the key influence, so those are connected up. We explain these two downstream modules about alignment in the following sections.
Correct Course as we Go
The Correct course as we go module is shown below. We consider two possibilities that would allow us to correct course as we go. One is that we can intervene to fix misbehaving HLMI, circled in black in the image.
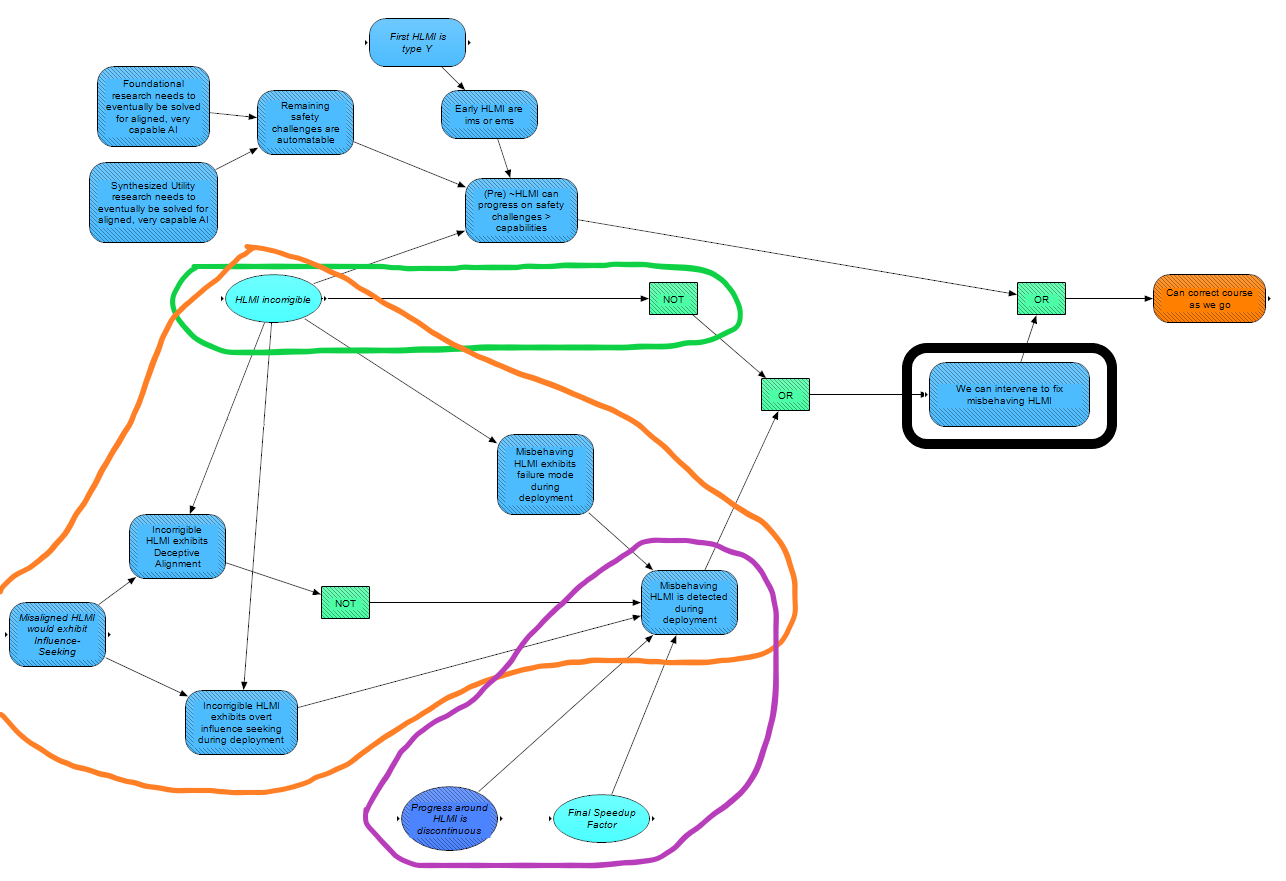
In general, if HLMI is corrigible - either due to getting alignment "by default", or due to the success of safety research agendas aimed at corrigibility - then we can expect that it will be possible to deal with potentially dangerous behaviours as they arise. This is modeled by the green-circled nodes. If HLMI is incorrigible, then the risk of not catching and stopping any dangerous behaviors depends on two factors. First, it depends on the nature of these behaviors; if the HLMI is deceptively aligned [AF · GW], or otherwise exhibits influence-seeking behaviour (discussed in a later section), then it is less likely we will notice misbehavior - this is modeled by the orange-circled nodes. Second, the risk depends on how fast progress in AI is when we develop HLMI: the less time that we have to catch and correct misbehavior, and the more rapidly HLMI increases in capability, the more likely we are to fail to course correct as we go - this is modeled by the purple-circled nodes.
The other way we could course correct as we go is if [AI systems that are (close to) HLMI] can progress on safety challenges [more than] capabilities, modeled in the top left of the figure. This seems more likely if early HLMI takes the form of [? · GW] imitation learners (ims) or emulations of humans (ems). It also seems more likely if we reach a point in AI safety research where the remaining safety challenges are automatable. Reaching that point in turn depends on the progress of specific safety agendas - currently we just include foundational research and synthesising a utility function [AF · GW]. As the model is further developed, it will additionally depend on the success of other safety agendas, as we clarify their routes to impact.
Alignment ahead of time
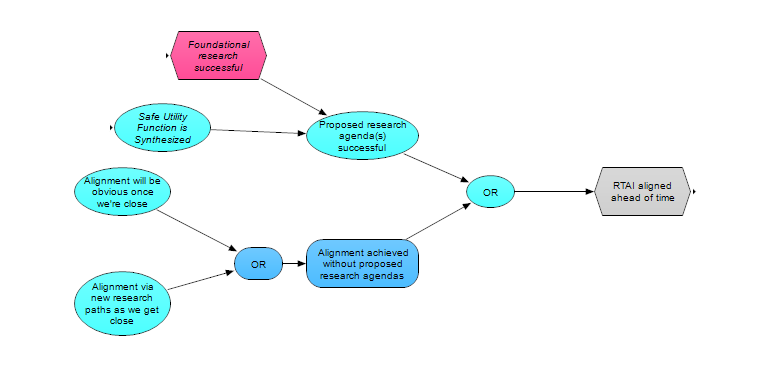
Some safety agendas - principally those based around ambitious value learning [AF · GW] - don’t seem to depend on ensuring corrigibility, and instead of trying to catch misalignment issues that arise, they focus on ensuring that HLMI is successfully aligned on the first try. We model this effect of safety agendas separately in the HLMI aligned ahead of time module, as the agendas do not depend on catching dangerous behaviors post-HLMI, and therefore if they are successful, are less affected by the speed of progress post-HLMI. The module (shown below) is a simplistic version of this idea, and once again, other agendas besides the ones shown may fit into its logic. We discussed this module from a slightly different perspective in the previous post on safety agendas [? · GW].
Misaligned HLMI
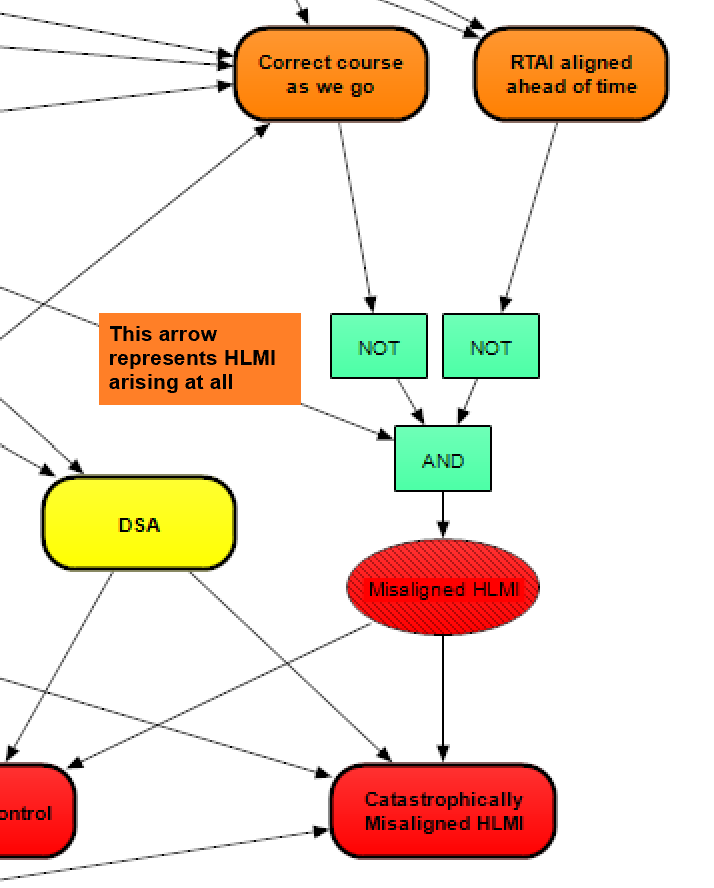
We decomposed the risk factor of Misaligned HLMI into three conditions. The first condition is that HLMI arises at all. The second condition is that it's not feasible to correct course as we go - this would depend on HLMI not being benign by default, and humanity not developing and implementing technical solutions that iteratively align HLMI in a post-HLMI world. The third condition is that we do not find a way to align HLMI before it appears, or before some other pre-HLMI point of no return. This third condition is a big uncertainty for most people concerned about AI risk, and we have discussed how it is particularly difficult to model in the previous post on the impact of safety research agendas [? · GW].
Keeping this part of the model leading up to Misaligned HLMI in mind, we now move to another major driver of risk in our model, Decisive Strategic Advantage.
Decisive Strategic Advantage (DSA)
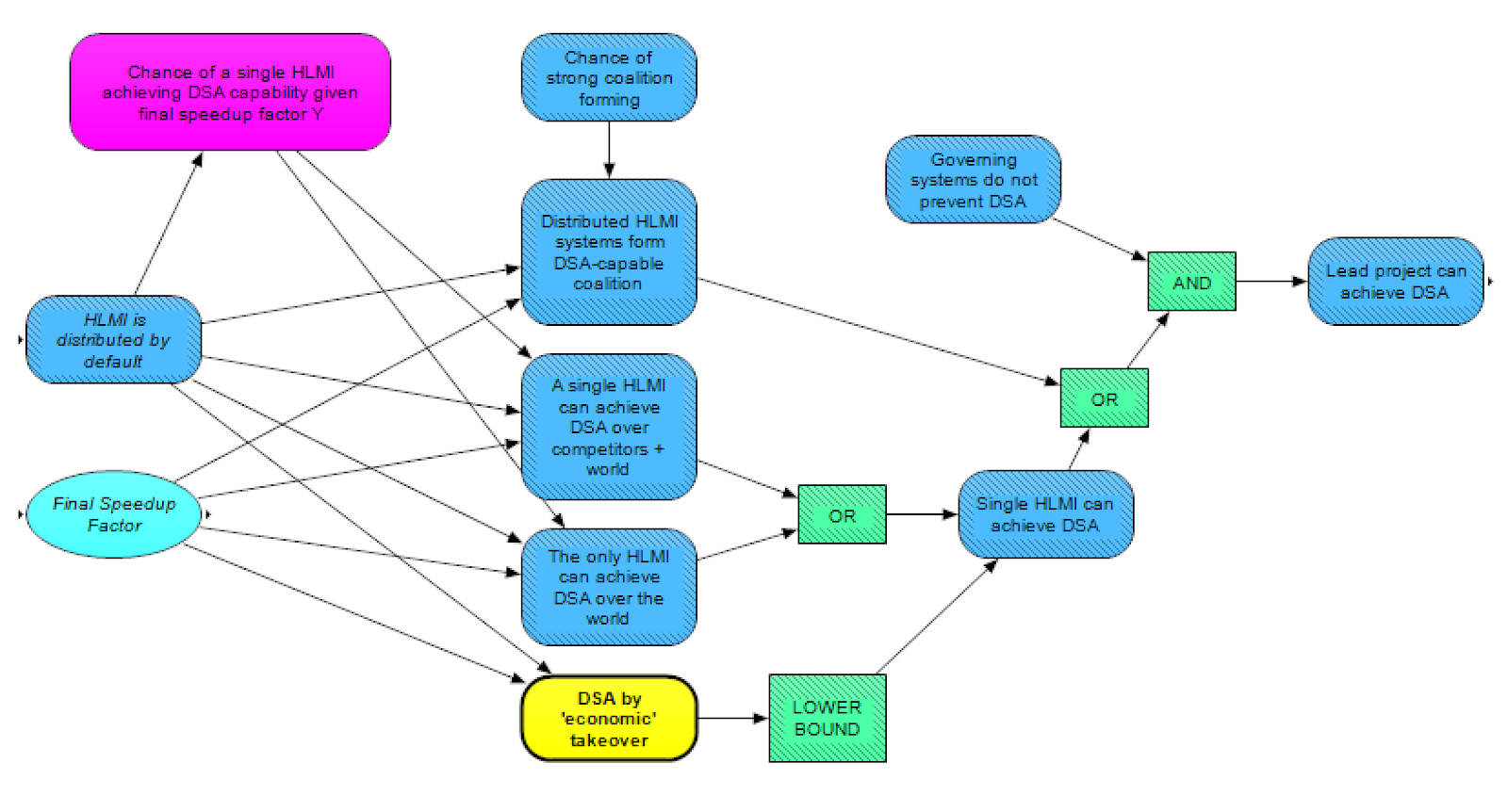
Attaining a DSA through HLMI is a key factor in many risk scenarios. We assume that if DSA is attained, it is attained by a "project" or a coalition of different projects. A project could be a team within a tech company, a state-owned lab, a military, a rogue actor, etc. Working from right to left in the figure pictured above, the leading project to develop HLMI can only achieve DSA if governing systems do not prevent it from independently amassing such power. Governing systems include state governments, institutions, laws and norms. AI systems, including other HLMI projects, can also count as governing systems. Failing the intervention of governing systems, there are three main ways to gain the potential for DSA. First, multiple HLMI systems could form a coalition that achieves a DSA. Second, the first HLMI may achieve a DSA over the rest of the world before competitors arise. Third, in a world with multiple HLMIs, a single HLMI may achieve a DSA over the rest of the world (including over its competitors).
These three paths to potential DSA depend on whether HLMI is distributed by default, from the module HLMI is distributed covered in a previous post on takeoff speeds and discontinuities [? · GW]. Potential for DSA is also linked to the rate of post-HLMI economic growth, represented by Final Speedup Factor. Faster growth will tend to widen the gap between the leading HLMI project and others, giving the project a greater advantage. The greater advantage makes it more likely that other projects are either abandoned, or taken over by the leading project. Therefore, faster growth seems to make a single-HLMI DSA more likely, all else equal.
The level of advantage needed for DSA is difficult to anticipate or even measure. It might be argued that an overwhelming economic or technical advantage is required for a DSA, but various arguments have been put forward for why this is incorrect [LW · GW]. Many times in history, groups of humans have used manipulation to take control of countries or empires via political manipulation. For instance, Hitler’s initial takeover of Germany was mostly via manipulating the political system (as opposed to investing his personal savings so well that he was responsible for >50% of Germany’s GDP), and Napoleon's Grande Armée was built during his takeover of Europe, not beforehand. In a more modern context, individuals have gained control over corporations via leverage and debt, without themselves having resources needed to assert such control.
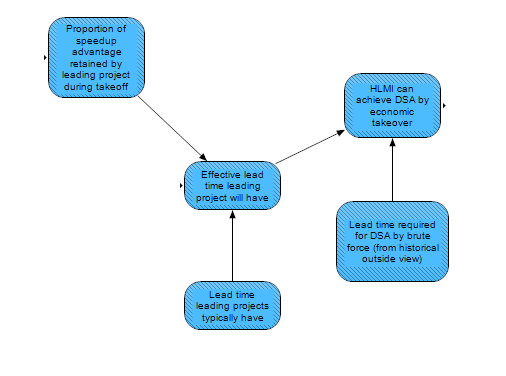
On the other hand, if these analogies don’t hold and an HLMI project is unable to exert significant manipulative pressure on the rest of the world, it might require actual control over a significant fraction of all the world's resources before DSA occurs. Therefore, we must have a very wide range of uncertainty over the degree of advantage required to achieve a DSA. There are a couple of nodes intended to capture this uncertainty. The yellow DSA by "economic takeover" module (pictured below) provides an upper bound on the degree of advantage needed (or equivalently, as stated in the diagram, a lower bound on the likelihood) based on the assumption that such an upper bound would be 50% of the world’s GDP. The purple Chance of a single HLMI achieving DSA node attempts to estimate the likelihood of DSA given different takeoff scenarios, taking into account, among other things, the possibility of HLMI-assisted manipulation of human society, or gaining control of resources or new technologies.
The Economic takeover route assumes that the HLMI takes no steps to seize resources, influence people or attack its potential opponents and just outgrows the rest of the world until it is overwhelmingly powerful. The logic here is that if the lead project increased its economic position to be responsible for >50% of the world GDP, then we would assume it would already have “taken over” (most of) the world without firing a shot. If we know how large the project is when it’s on the cusp of HLMI compared to the size of the world economy (both modeled in the Paths to HLMI [AF · GW] post), and if we know how fast the project will grow economically once it reaches HLMI (which we can naively assume is similarly quickly to the economic growth rate after HLMI, as determined in our post on Takeoff Speeds and Discontinuities [? · GW]), then we can determine how long it would have to outgrow the rest of the world to represent >50% of GDP. We then might assume that if the leading project has a lead time larger than this time, it will achieve economic takeover (the lead time can itself be estimated based on the typical lead time of large engineering projects and what portion of the lead time we might expect the leading project to keep during AI takeoff). See this sequence for further discussion [? · GW].
Influence-Seeking Behaviour
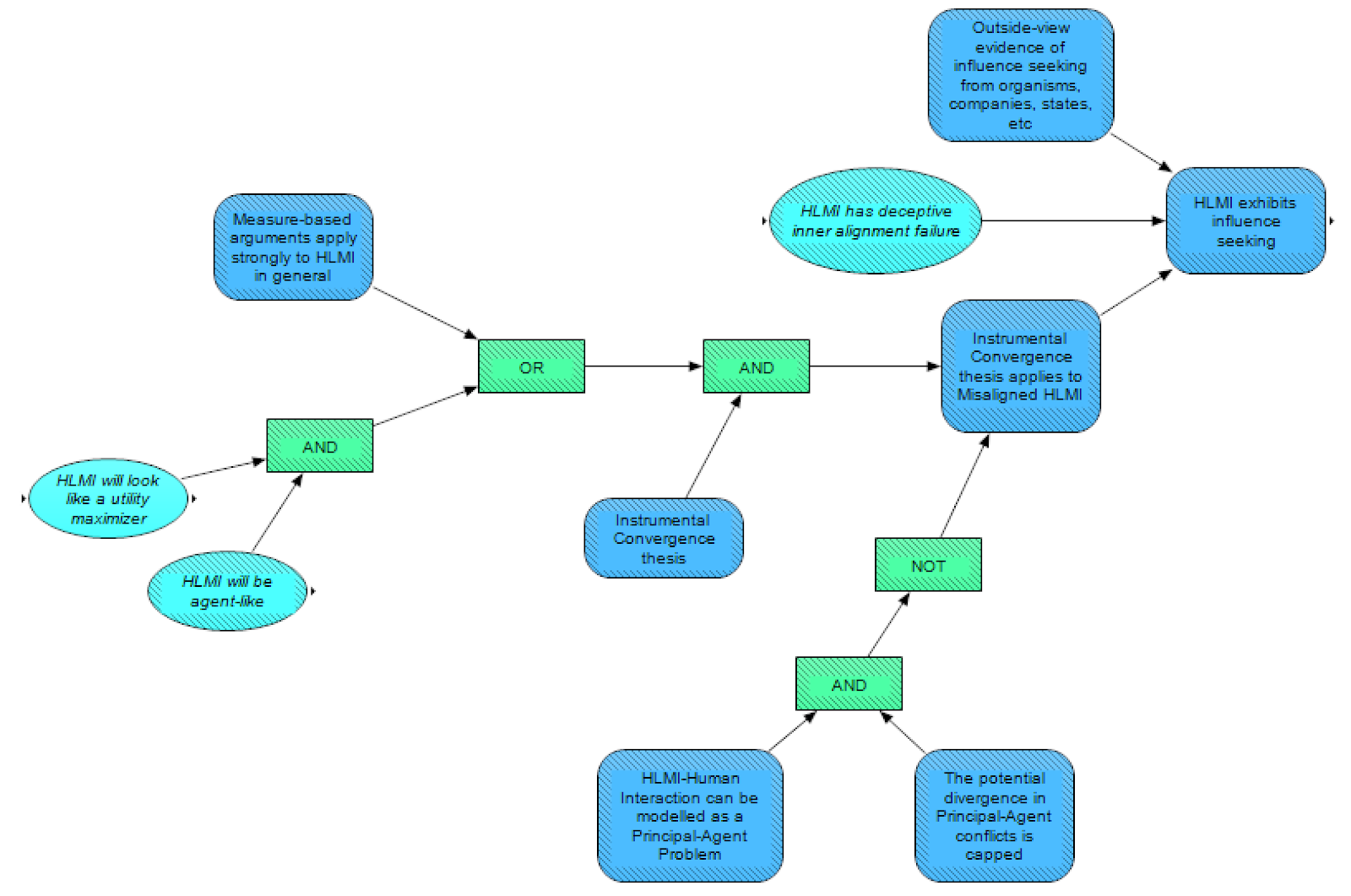
Another key factor to many risk scenarios is influence-seeking behaviour. We use this term to mean that an AI tends to increase its ability to manipulate people for instrumental reasons, either through improved manipulation skills, or acquiring of resources for the purposes of manipulation. This doesn't require that the AI system have an explicit objective of control, but having effective control may still be the goal, at least when viewing the system’s behaviour with an intentional stance.
As with many things, we can use analogies as one input to the likelihood of HLMI having influence-seeking behavior. Some plausible analogies for AI in the category of influence-seeking behaviour include organisms, companies, and states. In each of these classes there are varying degrees of influence seeking, so it would make sense to study the conditions for this behavior. For now we have kept this reasoning by analogy very simplified as a single node.
Part of the Instrumental Convergence thesis [? · GW] is that a sufficiently capable and rational agent will pursue instrumental goals that increase the likelihood of achieving its terminal goal(s). In general, these instrumental goals will include some commonalities, such as resource acquisition, self-preservation, and influence-seeking abilities. For this reason, whether the Instrumental Convergence thesis applies to Misaligned HLMI is an important factor in whether it exhibits influence seeking. We separated this question into (a) how strong the Instrumental Convergence thesis is in general, and (b) how much HLMI meets the conditions of the thesis. For (b), one could argue that Measure-based arguments [EA · GW] (e.g. "a large fraction of possible agents with certain properties will have this behaviour") apply strongly to HLMI in general. Alternatively, there is the more direct question of whether HLMI will look like a utility maximizer and be agent-like. The latter is a point of disagreement that has received a lot of attention in the discourse on AI risk, and is handled by the HLMI is utility-maximising agent module (this module is still a work in progress and is not covered by this sequence of posts).
Another important factor in whether HLMI exhibits influence-seeking is HLMI has deceptive inner alignment failure. This node is derived from the node Mesa-optimizer is deceptively aligned in the Mesa-optimization [AF · GW] module. Deceptive alignment entails some degree of influence-seeking, because the AI will perform well on its training objective for instrumental reasons - namely, so it gets deployed and can pursue some "true" objective. Deceptive alignment and influence seeking are not the same thing, because a deceptively aligned AI may not continue to seek influence once it is deployed. However, influence seeking algorithms might be favoured among all deceptively aligned algorithms, if they are more generally effective and/or simpler to represent.
Catastrophically Misaligned HLMI
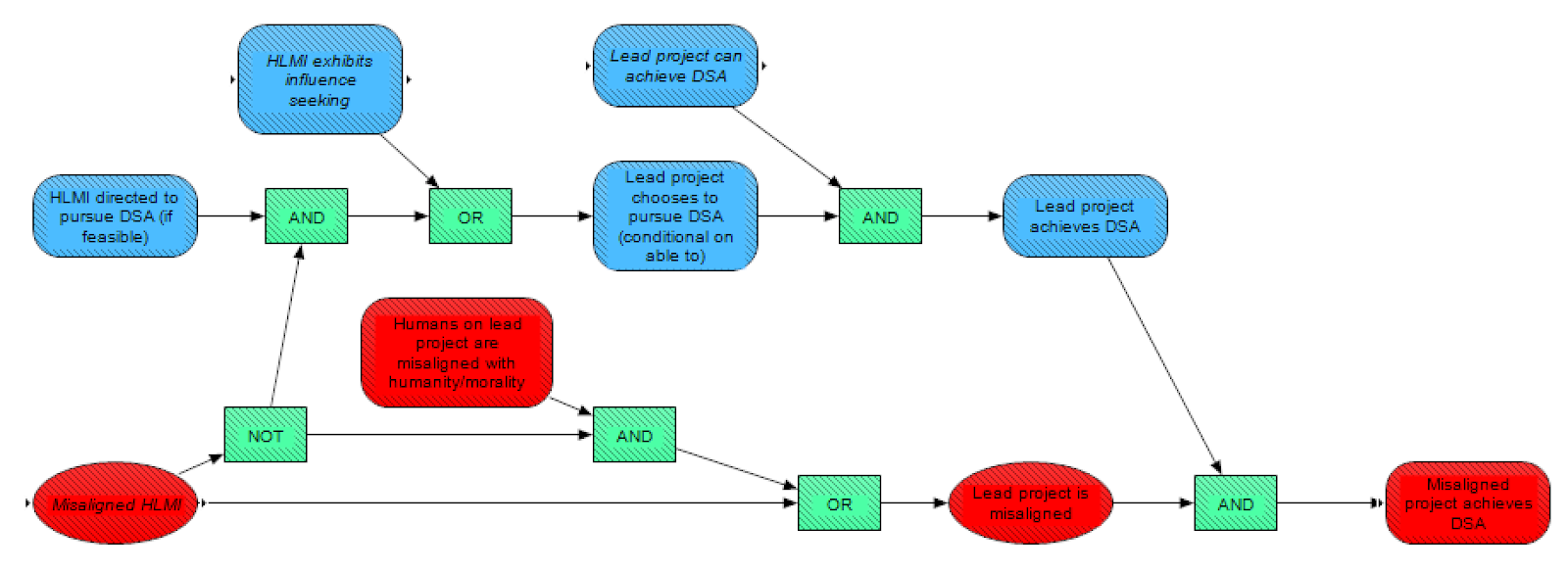
Returning to the scenario of Catastrophically Misaligned HLMI, we need to consider that misalignment can happen in many possible ways and to many degrees. So when should we consider it catastrophic? We operationalize catastrophe as when a Misaligned project achieves DSA, the node shown in red all the way on the right. The "project" includes HLMI(s) and any humans that are able to direct the HLMI(s), as well as coalitions of projects. If a project is capable of neutralizing any potential opposition due to holding a DSA, and its interests are misaligned such that after doing so it would cause an existential catastrophe, then we assume that it will cause an existential catastrophe. Naturally, this final outcome is the conjunction of Lead project achieves DSA and this Lead project is misaligned.
We decomposed the question of whether the Lead project achieves DSA into whether it can achieve DSA (from the DSA module), and whether it chooses to pursue DSA (conditional on being able to). Then we further break the latter of these down into two ways the HLMI project could choose to pursue DSA: either the HLMI exhibits influence seeking, or the HLMI is aligned with members of the project (i.e., it would NOT be misaligned) and [is] directed to pursue DSA.
Regarding whether the lead project is misaligned, this can either occur if we wind up with Misaligned HLMI, or if we do not get misaligned HLMI (from a technical perspective) but the Humans on [the] lead project are [sufficiently] misaligned with humanity [or] morality that they nevertheless cause an existential catastrophe (i.e., existential misuse).
Loss of Control
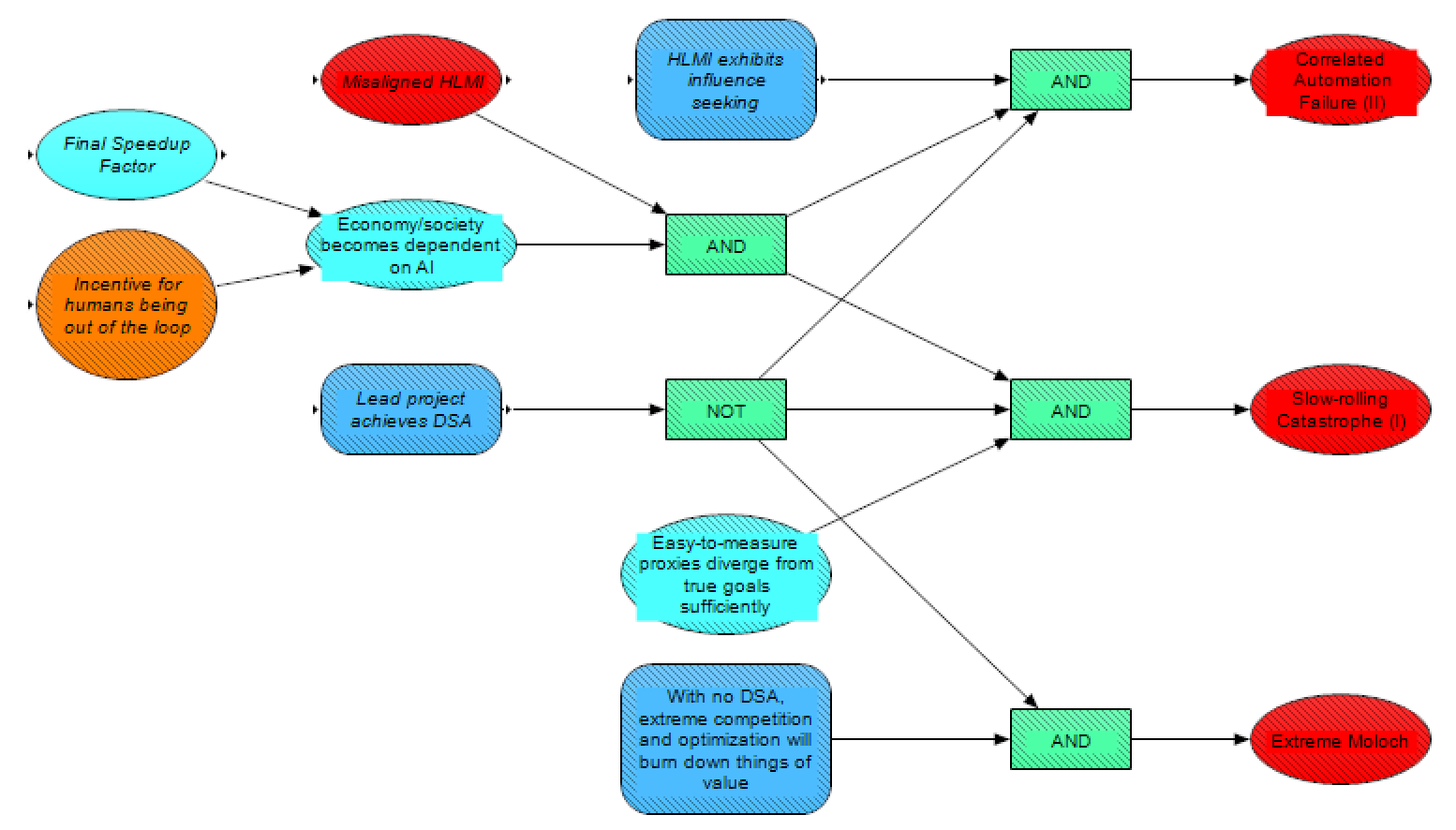
Here, we consider the possibility of humanity suffering existential harm from Loss of Control – not to a single HLMI or a coalition that has achieved a DSA, but instead to a broader HLMI ecosystem. Such an outcome could involve human extinction (e.g. if the HLMI ecosystem depleted aspects of the environment that humans need to survive, such as the oxygen in the atmosphere) but wouldn’t necessarily (e.g. it could involve humans being stuck in a sufficiently suboptimal state with no method to course correct).
The three outcomes we model are named after popular descriptions of multi-polar catastrophes. Two of these come from What failure looks like [AF · GW]: Slow-rolling Catastrophe (I) and Correlated Automation Failure (II), and the third (Extreme Moloch) comes from Meditations on Moloch. For each of these, we’re considering a broader set of possibilities than is given in the narrow description, and we use the description just as one example of the failure mode (for a more granular breakdown of some subtypes of these scenarios, see this post [LW · GW]). Specifically, here’s what we’re envisioning for each:
- Slow-rolling Catastrophe – any failure mode where an ecosystem of HLMI systems irreversibly sends civilization off the rails, due to technical misalignment causing HLMIs to pursue proxies of what we really want (the Production Web [AF · GW] provides another example of this type of failure)
- Correlated Automation Failure – any failure mode where various misaligned HLMIs within a broader ecosystem develop influence-seeking behaviour, and then (through whatever means) collectively take power from humans (such HLMIs may or may not subsequently continue to compete for power among themselves, but either way human interests would not be prioritized)
- Extreme Moloch – a failure mode where HLMI allows humans to optimize more for what we do want (as individuals or groups), but competition between individuals/groups burns down most of the potential value
Looking at our model (and starting in the middle row), we see that all three of these failure modes depend on there not being a project or coalition that achieves DSA (since otherwise we would presumably get a Catastrophically Misaligned HLMI scenario). Other than that, Slow-rolling Catastrophe (I) and Correlated Automation Failure (II) share a couple of prerequisites not shared by the Extreme Moloch outcome. Both (I) and (II) depend on misaligned HLMI (for (I) the HLMIs will be optimizing sufficiently imperfect proxies, while for (II) they will be undesirably influence seeking). Extreme Moloch, meanwhile, does not depend on technical misalignment, as the bad outcome would instead come from conflicting human interests (or human irrationality). Additionally, (I) and (II) would likely depend on the economy/society [becoming] dependent on AI (otherwise humans may be able to “pull the plug” and/or recover after a collapse); Extreme Moloch, meanwhile, does not require dependency, as even if civilization wasn’t dependent on AI, humans could still compete using AI and burn down the cosmic endowment in the process. Societal dependence on AI is presumably more likely if there is a larger Incentive for humans being out of the loop and a faster Final Speedup Factor to the global economy from HLMI. This post discusses [LW · GW] in more depth how the various AI takeover scenarios assume different economic incentives and societal responses to HLMI.
Additionally, each of these failure modes has its own requirements not shared with the others. Correlated Automation Failure would require HLMI that was influence seeking. Slow-rolling Catastrophe would require relevant proxies [to] diverge from what we actually want HLMI to do, to a sufficient degree that their pursuit represents an X-risk. And Extreme Moloch requires that in a multi-polar world, extreme competition and optimization will burn down things of value.
Note that existential HLMI risks other than the classic “misaligned AI singleton causes existential catastrophe” is a fast-changing [AF · GW] area [EA · GW] of [EA · GW] research [AF · GW] in AI Alignment, and there is very little consensus about how to distinguish potential failure modes from each other - see for example this recent survey [AF · GW]. Resultantly, our model in this section is limited in several ways: the logic is more binary than we think is justified (the outcomes shouldn’t be as discrete as indicated here, and the logic from cause to effects shouldn’t be as absolute either), we ignore the possibility of recovering from a temporary loss of control, we don’t consider the possibility of being in a world with some aligned HLMI systems and other misaligned systems, and so on. We intend to develop this section further in response to feedback and deeper research into loss of control-like scenarios.
Conclusion
To summarise, we have presented our model of some widely discussed ways that HLMI could bring about existential catastrophe, examining some of the key mechanisms and uncertainties involved. One set of paths to catastrophe involves a misaligned HLMI or HLMI-equipped group achieving Decisive Strategic Advantage. Another set of paths involves loss of control due to HLMI systems gaining influence on the world in an incremental and distributed fashion, without anyone necessarily achieving DSA. We traced these paths back to the outcomes of HMLI development (whether and how HLMI systems are aligned), and the nature of HLMI systems (e.g. whether they exhibit influence-seeking behaviour). The post Distinguishing AI Takeover Scenarios [AF · GW] and its follow-up [AF · GW] provide a more up-to-date and detailed understanding of AI takeover scenarios compared to our current concrete model.
In the next post, we will discuss approaches to elicit expert views that can inform the concrete model we have presented so far, and our tentative plans to carry out elicitation.
Thanks to the rest of the MTAIR project team as well as Edo Arad for feedback on drafts.
1 comments
Comments sorted by top scores.
comment by supposedlyfun · 2021-12-08T23:21:31.503Z · LW(p) · GW(p)
Seeing all of this synthesized and laid out helped me to synthesize my own thinking and reading on these topics. Not coincidentally, it also gave me an anxiety attack. So very many ways for us to fail.