Modeling Risks From Learned Optimization
post by Ben Cottier (ben-cottier) · 2021-10-12T20:54:18.555Z · LW · GW · 0 commentsContents
Module Overview HLMI contains a mesa-optimizer Analogies for mesa-optimization The mesa-optimizer is pseudo-aligned Pseudo-alignment is not safe enough Deceptive alignment We fail to stop deployment Conclusion Acknowledgements None No comments
This post, which deals with how risks from learned optimization and inner alignment can be understood, is part 5 in our sequence on Modeling Transformative AI Risk [? · GW]. We are building a model to understand debates around existential risks from advanced AI. The model is made with Analytica software, and consists of nodes (representing key hypotheses and cruxes) and edges (representing the relationships between these cruxes), with final output corresponding to the likelihood of various potential failure scenarios. You can read more about the motivation for our project and how the model works in the Introduction post [AF · GW]. The previous post in the sequence, Takeoff Speeds and Discontinuities [AF · GW], described the different potential characteristics of a transition from high-level machine intelligence [1] to superintelligent AI.
We are interested in feedback on this post, especially in places where the model does not capture your views or fails to include an uncertainty that you think could be an important crux. Similarly, if an explanation seems confused or confusing, flagging this is useful – both to help us clarify, and to ensure it doesn’t reflect an actual disagreement.
This post explains how risks from learned optimization are incorporated in our model. The relevant part of the model is mostly based on the Risks from Learned Optimization sequence [? · GW] and paper (henceforth RLO). Although we considered responses and alternate [AF · GW] perspectives [LW · GW] to RLO in our research, these perspectives are not currently modeled explicitly.
For those not familiar with the topic, a mesa-optimizer is a learned algorithm that is itself an optimizer. According to RLO, inner alignment [AF · GW] is the problem of aligning the objective of a mesa-optimizer with the objective of its base optimizer (which may be specified by the programmer). A contrived example [AF · GW] supposes we want an algorithm that finds the shortest path through any maze. In the training data, all mazes have doors that are red, including the exit. Inner misalignment arises if we get an algorithm that efficiently searches for the next red door – the capabilities are robust because the search algorithm is general and efficient, but the objective is not robust [AF · GW] because it finds red doors rather than the exit.
The relevant part of our model is contained in the Mesa-Optimization module:
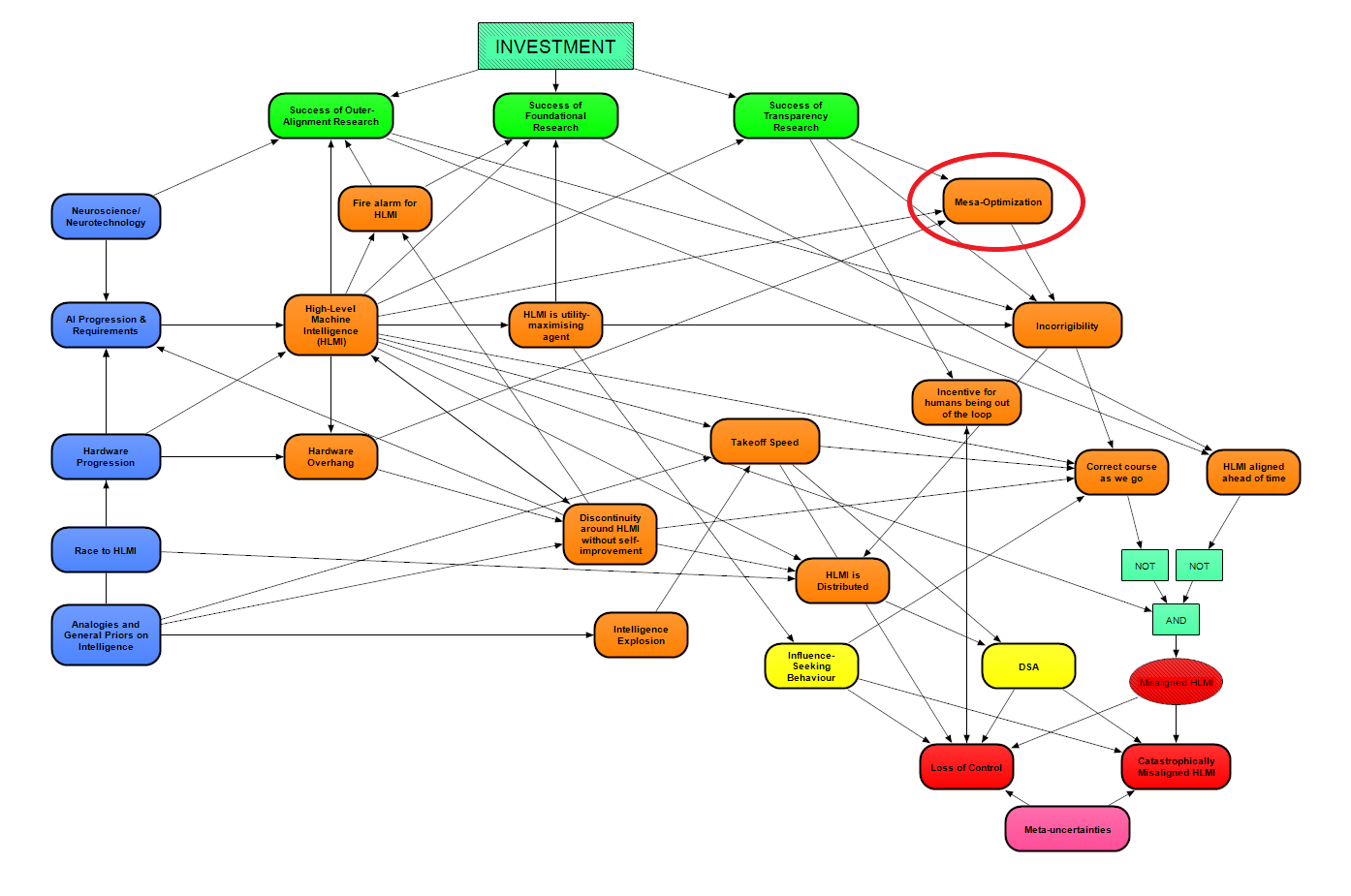
The output of the Mesa-Optimization module is an input to the Incorrigibility module. The logic is that inner misalignment is one way that high-level machine intelligence (HLMI) could become incorrigible [LW · GW], which in turn counts strongly against being able to Correct course as we go in the development of HLMI.
Module Overview
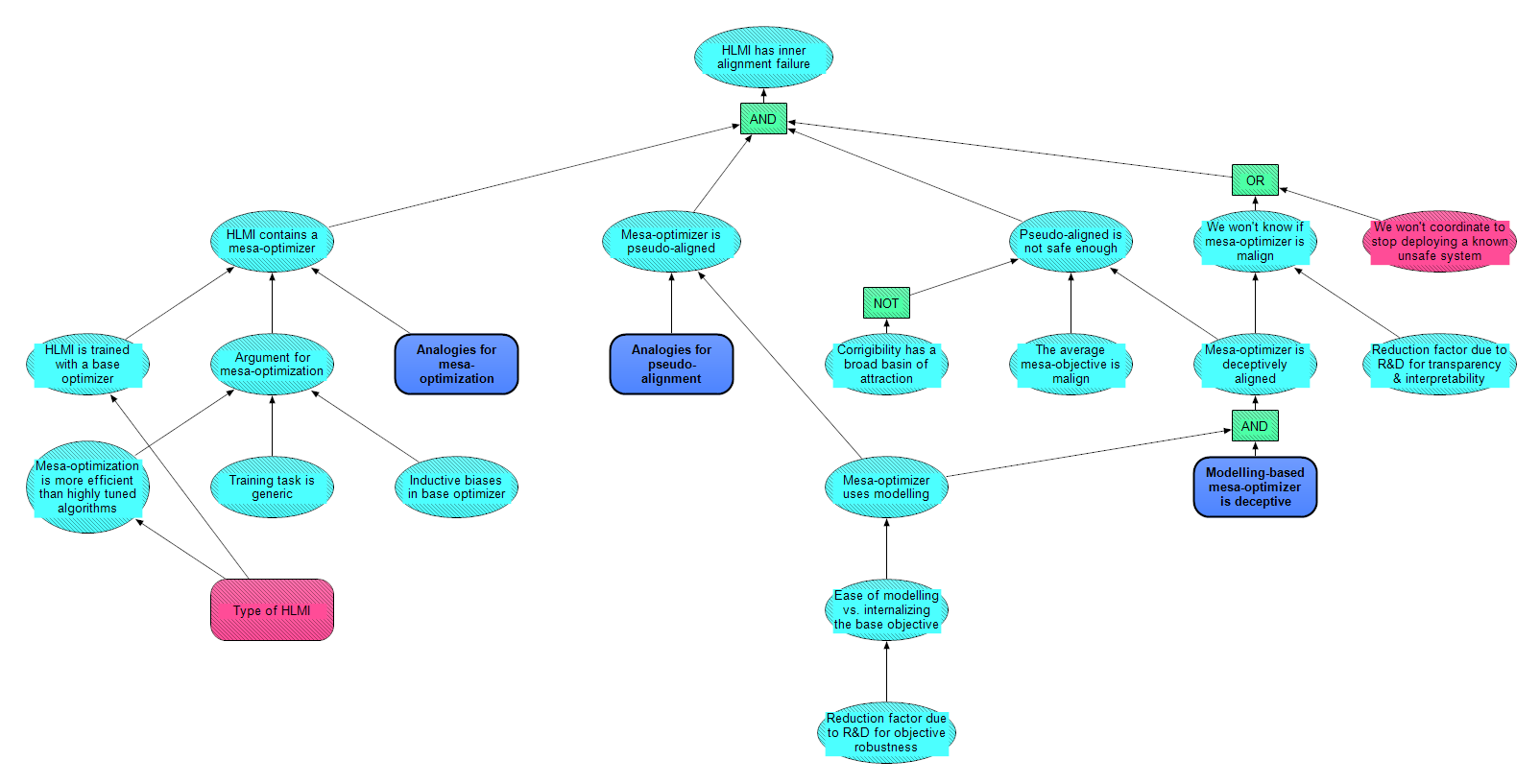
The top-level logic of the Mesa-Optimization module is: HLMI has an inner alignment failure if
- The HLMI contains a mesa-optimizer, AND
- Given (1), the mesa-optimizer is pseudo-aligned, i.e. it acts aligned in the training setting but its objective is not robust to other settings, AND
- Given (2), the pseudo-alignment is not sufficient for intent alignment, i.e. is not safe enough to make HLMI corrigible, AND
- Given (3), we fail to stop deployment of the unsafe system.
In the following sections, we explain how each of these steps are modeled.
HLMI contains a mesa-optimizer
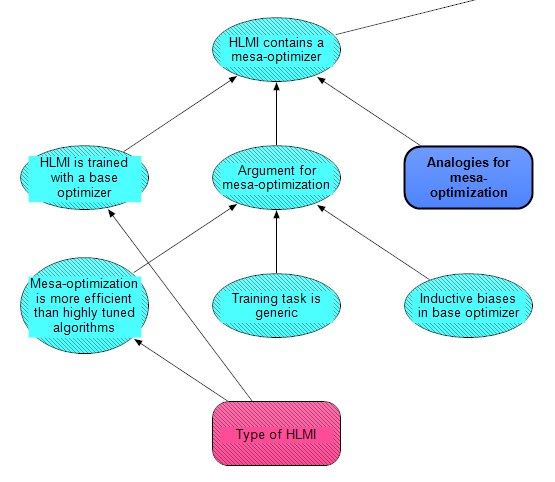
The output of this section is HLMI contains a mesa-optimizer, which depends on three nodes. The left node, HLMI is trained with a base optimizer, means that a training algorithm optimized a distinct learned algorithm, and that learned algorithm forms all or part of the HLMI system. A crux here is what Type of HLMI you expect, which comes out of the pathways discussed in the Paths to HLMI post [? · GW]. For instance, HLMI via current deep learning methods or evolutionary methods will involve a base optimizer, but this is not true of other pathways such as whole-brain emulation.
The middle node, Argument for mesa-optimization, represents the argument from first principles for why mesa-optimization would occur in HLMI. It is mainly based on the post Conditions for Mesa-Optimization [AF · GW]. This is broken down further into three nodes. Mesa-optimization is more efficient than highly tuned algorithms distils some claims about the advantages of mesa-optimization compared to systems without mesa-optimization, including that it offers better generalisation through search. You could reject that claim on the grounds that sample efficiency will be high enough, such that HLMI consists of a bunch of algorithms that are highly tuned to different domains. You could also argue that some types of HLMI are more prone to be highly tuned than others. For instance, evolutionary algorithms might be more likely to mesa-optimize than machine learning, and machine learning might be more likely to mesa-optimize than hybrid ML-symbolic algorithms.
The middle node, Training task is generic, resolves as positive if the learned algorithm is not directly optimized for domain-specific tasks. This scenario is characteristic of pre-training in modern machine learning. For example, the task of predicting the next word in a large text dataset is generic, because the dataset could contain all kinds of content that is relevant to many different domain-specific tasks. In contrast, one could use a more domain-specific dataset (e.g. worded math problems) or objective function (e.g. reward for the quality of a news article summary). This crux is important if mesa-optimizers generalise better than other kinds of algorithms, because then a generic training task would tend to select for mesa-optimizers more. GPT-3 gives credence to this idea, because it demonstrates strong few-shot learning performance by simply learning to predict the next word in a text. However, it's uncertain if GPT-3 meets the definition of a mesa-optimizer.
Finally, Inductive biases in base optimizer lumps together some factors about inductive bias in the HLMI’s architecture and training algorithm which affect the chance of mesa-optimization. For example, the extent that mesa-optimization exists in the space of possible models (i.e. algorithmic range), and the ease by which the base optimizer finds a mesa-optimizer (i.e. reachability). Inductive bias is a big factor in some people's beliefs about inner alignment, but there is disagreement about just how important it is and how it works (see e.g. Inductive biases stick around [AF · GW], including comments).
Analogies for mesa-optimization
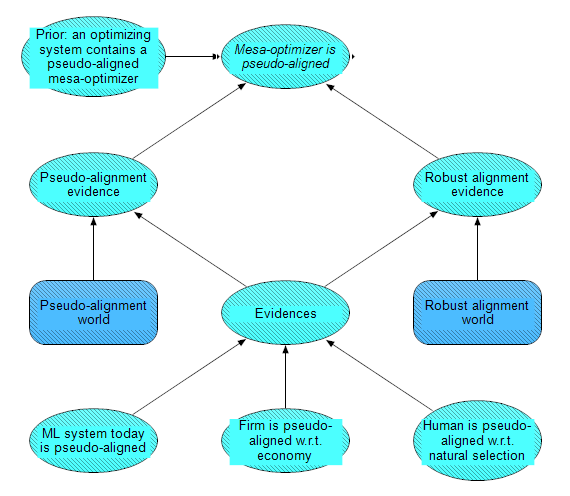
Finally, evidence for the node HLMI contains a mesa-optimizer is also drawn from history and analogies. We modeled this evidence in a submodule, shown below. The submodule is structured as a Naive Bayes classifier: it models the likelihood of the evidence, given the hypotheses that an HLMI system does or does not contain a mesa-optimizer. The likelihood updates the following prior: if you only knew the definition of mesa-optimizer, and hadn't considered any specific cases, arguments or evidence for it, what is the probability of an optimizing system containing a mesa-optimizer?
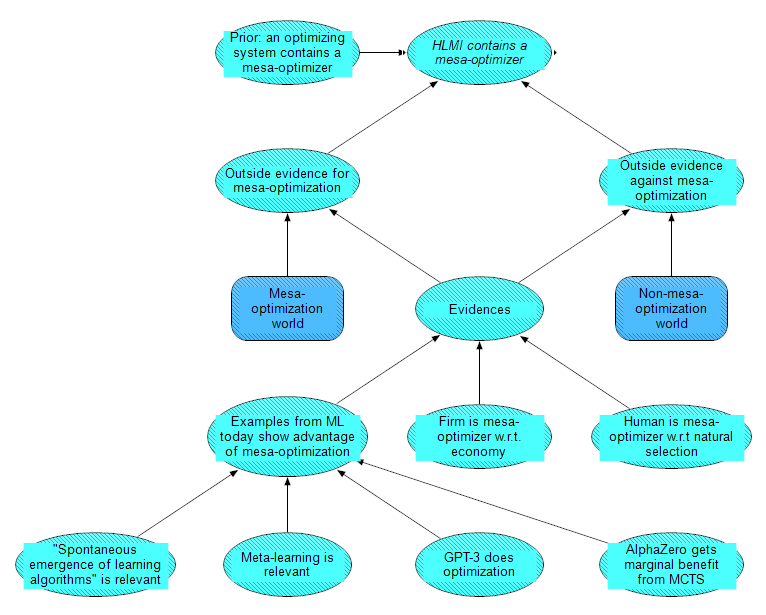
We considered three domains for the evidence: machine learning today, firms with respect to economies, and humans with respect to natural selection. A few more specific nodes are included under Examples from ML today because there has been some interesting discussion and disagreement in this area:
- The "spontaneous emergence of learning algorithms" from reinforcement learning algorithms has been cited [AF(p) · GW(p)] as evidence for mesa-optimization, but this may not be informative [AF(p) · GW(p)].
- Meta-learning is a popular area of ML research, but since it applies a deliberate and outer-loop optimization, it doesn't clearly affect the likelihood of spontaneous mesa-optimization.
- GPT-3 does few-shot learning in order to perform novel tasks. This post [AF · GW] gives an argument for why it is incentivised for – or may already be – mesa-optimizing.
- It is unclear and debated [AF(p) · GW(p)] how much AlphaZero marginally benefits from Monte Carlo Tree Search, which is a form of mechanistic optimization, compared to just increasing the model size. In turn it is unclear how much evidence AlphaZero provides for getting better generalisation through search, which is argued [? · GW] as an advantage of mesa-optimization.
The mesa-optimizer is pseudo-aligned
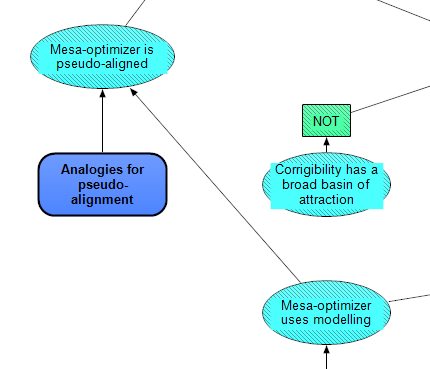
The possibility of pseudo-alignment depends on just two nodes in our model. The structure is simple mainly because pseudo-alignment of any kind seems much more likely than robust alignment, so we haven't noticed much debate on this point. In general there are many more ways to perform well on the training distribution which are not robustly aligned with the objective, i.e. they would perform significantly worse on that objective under some realistic shift in the distribution. And in practice today, this kind of robustness is a major challenge in ML (Concrete Problems in AI Safety section 7 gives an overview, though it was published back in 2016).
The dependency on the left is a module, Analogies for pseudo-alignment, which is structured identically to Analogies for mesa-optimization (i.e. with a Naive Bayes classifier, and so on), but the competing hypotheses are pseudo-alignment and robust alignment, and the analogies are simply "ML systems today", "Firm", and "Human".s
The second node influencing pseudo-alignment is Mesa-optimizer uses modeling. The concept of "modeling" vs. "internalization" introduced in the RLO paper (section 4.4) is relevant to pseudo-alignment. Internalization implies robust alignment, whereas modeling means the mesa-optimizer is pointing to something in its input data and/or its model of the world in order to act aligned. We explain this node and the implications of "modeling" in more detail in the next section.
Pseudo-alignment is not safe enough
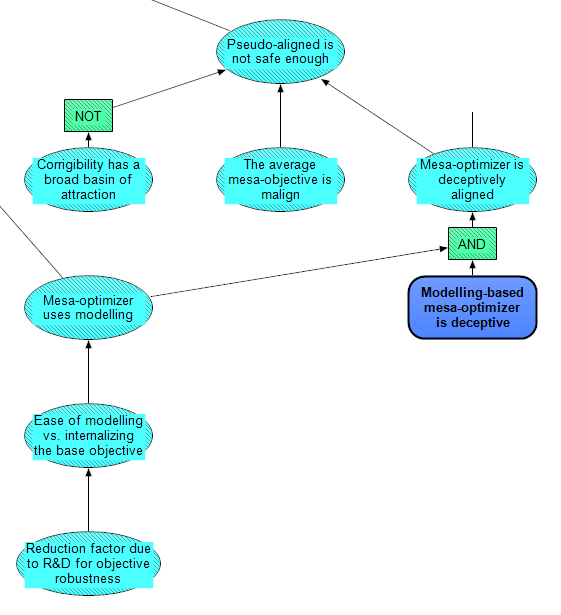
At the top level of this subsection, we include three reasons why pseudo-alignment might not be safe enough to count as a failure of inner alignment. Firstly, there is a crux of whether corrigibility has a broad basin of attraction. This refers to Paul Christiano's claim that "A sufficiently corrigible agent will tend to become more corrigible and benign over time. Corrigibility marks out a broad basin of attraction towards acceptable outcomes." If Christiano’s claim about corrigibility is true, this increases the overall chance that a pseudo-aligned algorithm becomes safe enough before it locks in a path to catastrophe.
A second crux for the safety of pseudo-alignment is how malign we expect a mesa-objective to be by default (by malign, we just mean non-benign, or harmful in effect – it doesn't have to be inherently malicious). It's uncertain what mesa-objectives are generally like, because they arise internally from the base optimizer, and there is currently scant empirical evidence of mesa-optimization. It's reasonable to expect a proxy objective to be much closer to the base objective than to a random objective, so the danger partly depends on the base objective. Perhaps mesa-objectives will just be weird in benign ways, e.g. being irrational, or very local [AF · GW]. On the other hand, it seems that simple, unbounded, coherent objectives would tend to have lower description length than objectives lacking those attributes, so those objectives may be favoured by simplicity bias.
Before moving on to the third reason, deceptive alignment, let's review the concept of modeling vs. internalization introduced in the RLO paper (section 4.4). Modeling is where a mesa-optimizer acts aligned with a base objective (in training) by representing the base objective within its world model (using relevant information from its input data) and then deliberately acting aligned with this representation. By understanding the base objective, the mesa optimizer can behave more aligned, whether or not its own objective is different. (In this case, “modeling” is similar to a trial employee working hard because their mental model of the company indicates that the company wants them to work hard.) The alternative manner to modeling in which a mesa-optimizer can act aligned with a base objective is internalization: the base optimizer adjusts the mesa-objective to be more and more aligned until convergence. (In this case, internalization is similar to a trial employee working hard because they intrinsically want to work hard.)
Modeling-based mesa-optimizers are thought to end up deceptively or corrigibly [AF · GW] aligned as a result of training. Deceptive alignment means the learned algorithm optimizes for the base objective during training for instrumental reasons (namely, to deceive the learning algorithm or programmers into thinking it’s aligned). Returning to the example of our trial employee, a deceptively aligned trial employee might just want a salary and to slack off, so he will work hard while in trial to be offered the job, and then after being offered the job only work the minimal amount to not get fired. So a deceptively aligned algorithm deviates when it becomes favourable, e.g. it figures out that training has ended, removing the threat of being penalised.
The main alternative to a deceptive mesa-optimizer that we consider is a corrigible mesa-optimizer. A corrigible mesa-optimizer optimizes for a pointer to the part of its world model that includes the base objective (both in training and deployment). The corrigibility comes from the fact that the base optimizer can modify this pointer to be more accurate. Here, our trial employee cares about being "the perfect employee" both in trial and once offered a job, but they are uncertain how to measure that. So they might observe employees that have succeeded (the pointer) and learn to imitate that. Note that this is subtly different from the internalizing employee. The internalizing employee doesn't care about the company in itself, but values working hard for its own sake (and thus happens to be aligned with the company), whereas the corrigibly modeling employee wants to do whatever they believe the company wants of them, which is to work hard.
Coming back to our model, the third reason that pseudo-alignment might not be safe enough is if the Mesa-optimizer is deceptively aligned.
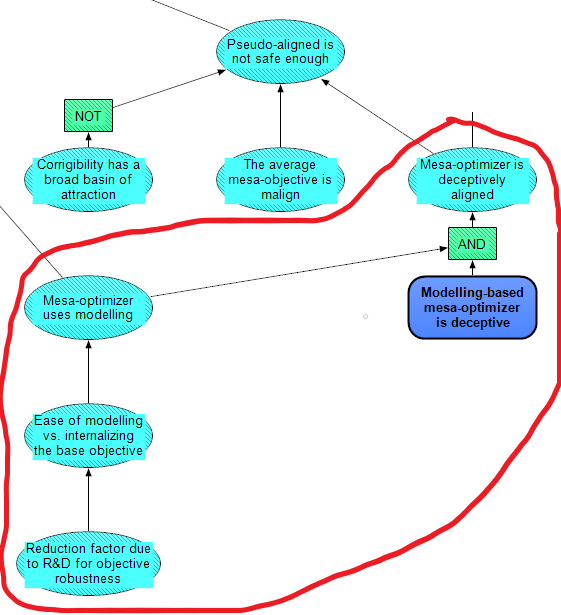
We broke down deceptive alignment into two main conditions. First, a precondition that the mesa-optimizer is using modeling. The key question influencing this precondition is how easy it is for a mesa-optimizer to model rather than internalize. We represent this as the likelihood ratio of eventually settling on modeling versus internalization. One argument for modeling being easier is that, within the training data for the HLMI, there will likely be a huge amount of rich input data relevant for determining the base objective, and it will therefore be easier for the HLMI to capture this objective function by referring to the relevant parts of this data, than it will be to build a representation of the objective from scratch. However, this argument depends on just how difficult it is to construct representations that are useful for modeling the objective, which in turn depends both on the nature of the data and the objective. We can also look to analogies here, such as imprinting in animals. For example, rather than have a detailed representation of a mother goose, a gosling imprints on some initial stimulus in its environment, whether that be an actual goose or, say, a human's boots, and then treats the imprinted object as its mother (e.g. it follows the object around).
Feeding into the ease of modeling vs. internalization node is Reduction factor due to R&D for objective robustness (objective robustness is terminology from Clarifying inner alignment terminology [AF · GW]). This node quantifies the effect that safety research has (as a constant multiplier) on reducing the Ease of modeling vs. internalizing the base objective, assuming that modeling is dangerous and better to avoid.
The second condition for deceptive alignment is simply: given that a mesa-optimizer uses modeling, it is deceptive. This possibility is broken down into a submodule of nodes, explained in the next section.
Deceptive alignment
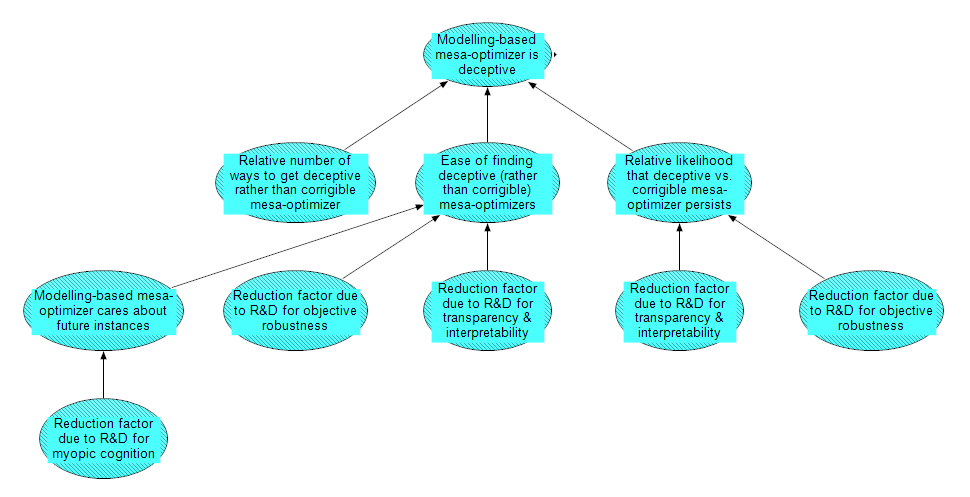
The inside of the "Modeling-based mesa-optimizer is deceptive" submodule.
There are three factors feeding into the modeling-based mesa-optimizer is deceptive node. First is Relative number of ways to get a deceptive rather than corrigible mesa-optimizer. Think of this as a base rate for deceptive (rather than corrigle) mesa-optimization. There is a counting argument for deception here: since deception is instrumentally motivated, it is compatible with almost any proxy goal, whereas for corrigibility, the base optimizer has to find a very specific pointer to relate to the base objective.
The second factor is the Ease of finding deceptive (rather than corrigible) mesa-optimizers. Similar to reachability [AF · GW], this node is represented by the relative likelihood that the base optimizer outputs a deceptive mesa-optimizer at some point in training.
The post Does SGD Produce Deceptive Alignment? [AF · GW] details some arguments for and against deceptive algorithms being easier to find than corrigible alignment (specifically for stochastic gradient descent, but much of it is more general). Becoming deceptive requires caring about future instances, so that there is an incentive to deceive now for later gain. Becoming deceptive also requires reasoning about the training process, so that the mesa-optimizer expects the threat of modification to go away and for deception to pay off. On the other hand, becoming corrigible requires a robust pointer to a good model of the base objective – otherwise the mesa-optimizer will just optimize for whatever proxy it has. Furthermore, even if there is information related to the base objective in the input data, the mesa-optimizer will need to have uncertainty about precisely what objective it is pointing to. The conditions for deception are claimed to be easier [2]. However, there seems to be a lot of uncertainty here which might hinge on the nature of the base objective and how the base optimizer works.
Going one level down from the Ease of finding deceptive (rather than corrigible) mesa-optimizers node, we have Modeling-based mesa-optimizer cares about future instances. This means the mesa-optimizer is motivated by what happens in future instances of training or in deployment (instead of just its current round of training). Caring about future instances is a necessary condition for deceptive alignment, but not corrigible alignment – if an algorithm does not consider future instances, then it will not see the benefit of defecting later in time, and therefore has no instrumental reason to deceive. The node for Reduction factor due to R&D for myopic cognition refers to the idea that methods to induce myopic cognition, such as approval-directed agents, could reduce the chance of modeling-based mesa-optimizers caring about future instances (myopic cognition is discussed in this post [AF · GW]).
The third top-level node here is Relative likelihood that deceptive vs. corrigible mesa-optimizer persists – that is, the likelihood that once a mesa-optimizer becomes deceptive in one instance, it survives and remains deceptive indefinitely (relative to the likelihood for a corrigible mesa-optimizer). Deceptive algorithms may be favoured due to their ability and incentive to adapt to the base objective, because they can reason about the objective and they care about future instances. However, protecting a proxy objective from modification may be difficult. This too seems like an important uncertainty that depends on empirical facts about the base optimizer, e.g. how stochastic gradient descent works with modern neural nets.
Finally, we include two areas of research that could reduce the likelihood of deceptive alignment. One is research to improve objective robustness, such as Relaxed adversarial training for inner alignment [LW · GW], where one of the aims is avoiding deception. A key part of making relaxed adversarial training work is transparency tools to guide the training process. This comment [AF · GW] argues why that is more helpful than inspecting the algorithm after deception may have already occurred. Research into transparency may help to prevent deceptive alignment in other ways, so this is kept as a separate node.
We fail to stop deployment
The last part of the Mesa-Optimization module is about whether the overseers of an HLMI project will pull back before it's too late, given there is an HLMI with an unsafe mesa-optimizer that hasn’t been deployed yet (or trained to sufficiently advanced capabilities to “break out”). The way they could pull back in such a situation is if they are aware that it's unsafe, AND they coordinate to stop the threat. That logic is inverted to an OR in the module, to fit with the top-level output of HLMI has inner alignment failure.
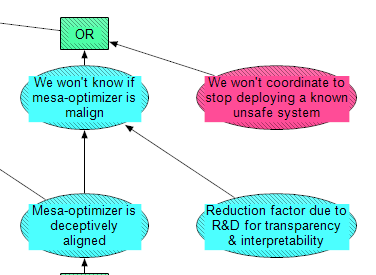
Mesa-optimizer is deceptively aligned is one of the strongest factors in knowing whether a mesa-optimizer is unsafely pseudo-aligned, because deception works against overseers figuring this out. Meanwhile, R&D for transparency & interpretability may help to detect unsafe pseudo-aligned algorithms. On the other hand [AF · GW], deceptive algorithms may just exploit weaknesses in the transparency tools, so it is even possible for the reduction factor to be less than 1 (i.e. it increases the chance that we fail to see the danger).
Conclusion
In this post, we have examined important cruxes and uncertainties about risks from learned optimization, and how they relate to each other. Our model is mostly based on the Risks from Learned Optimization [? · GW] sequence, and considers whether mesa-optimization will occur in HLMI at all, whether pseudo-alignment occurs and is dangerous, and whether the mesa-optimizer will be deployed or "break out" of a controlled environment. Some uncertainties we have identified relate to the nature of HLMI, connecting back to Paths to HLMI [? · GW] and to analogies with other domains. Other uncertainties relate to the training task, e.g. how generic the task is, and whether the input data is large and rich enough to incentivise modeling the objective. Other uncertainties are broadly related to inductive bias, e.g. whether the base optimizer tends to produce mesa-optimizers with harmful objectives.
We are interested in any feedback you might have, including how this post affected your understanding of the topic and the uncertainties involved, your opinions about the uncertainties, and important points that our model may not capture.
The next post in this series will look at the effects of AI Safety research agendas.
[1] We define HLMI as machines that are capable, either individually or collectively, of performing almost all economically-relevant information-processing tasks that are performed by humans, or quickly (relative to humans) learning to perform such tasks. We are using the term “high-level machine intelligence” here instead of the related terms “human-level machine intelligence”, “artificial general intelligence”, or “transformative AI”, since these other terms are often seen as baking in assumptions about either the nature of intelligence or advanced AI that are not universally accepted.
[2] Parts of this argument are more spelled out in the FLI podcast with Evan Hubinger (search the transcript for "which is deception versus corrigibility").
Acknowledgements
Thanks to the rest of the MTAIR Project team [? · GW], as well as the following individuals, for valuable feedback and discussion that contributed to this post: Evan Hubinger, Chris van Merwijk, and Rohin Shah.
0 comments
Comments sorted by top scores.