Modelling Transformative AI Risks (MTAIR) Project: Introduction
post by Davidmanheim, Aryeh Englander (alenglander) · 2021-08-16T07:12:22.277Z · LW · GW · 0 commentsContents
Conceptual Approach Model Overview How to read Analytica models The Model is (Already) Wrong Further Posts and Feedback Footnotes Acknowledgements None No comments
Numerous books, articles, and blog posts have laid out reasons to think that AI might pose catastrophic or existential risks for the future of humanity. However, these reasons often differ from each other both in details and in main conceptual arguments, and other researchers have questioned or disputed many of the key assumptions and arguments.
The disputes and associated discussions can often become quite long and complex, and they can involve many different arguments, counter-arguments, sub-arguments, implicit assumptions, and references to other discussions or debated positions. Many of the relevant debates and hypotheses are also subtly related to each other.
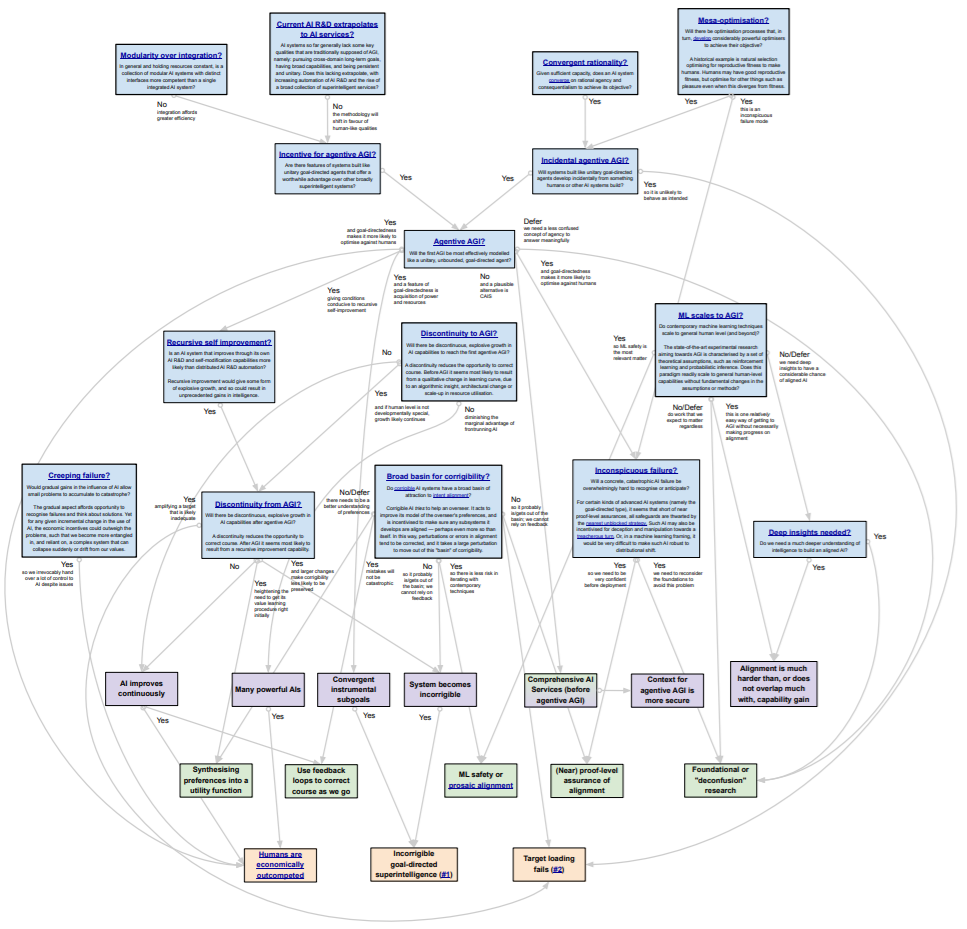
Two years ago, Ben Cottier and Rohin Shah created a hypothesis map [LW · GW], shown below, which provided a useful starting point for untangling and clarifying some of these interrelated hypotheses and disputes.
The MTAIR project is an attempt to build on this earlier work by including additional hypotheses, debates, and uncertainties, and by including more recent research. We are also attempting to convert Cottier and Shah’s informal diagram style into a quantitative model that can incorporate explicit probability estimates, measures of uncertainty, relevant data, and other quantitative factors or analysis, in a way that might be useful for planning or decision-making purposes.
This post is the first in a series which presents our preliminary outputs from this project, along with some of our plans going forward. Although the project is still a work in progress, we believe that we are now at a stage where we can productively engage the community, both to contribute to the relevant discourse and to solicit feedback, critiques, and suggestions.
This introductory post gives a brief conceptual overview of our approach and a high-level walkthrough of the hypothesis map that we have developed. Subsequent posts will go into much more detail on different parts of this model. We are primarily interested in feedback on the portions of the model that we are presenting in detail. In the final posts of this sequence we will describe some of our plans going forward.
Conceptual Approach
There are two primary parts to the MTAIR project. The first part, which is still ongoing, involves creating a qualitative map (“model”) of key hypotheses, cruxes, and relationships, as described earlier. The second part, which is still largely in the planning phase, is to convert our qualitative map into a quantitative model with elicited values from experts, in a way that can be useful for decision-making purposes.
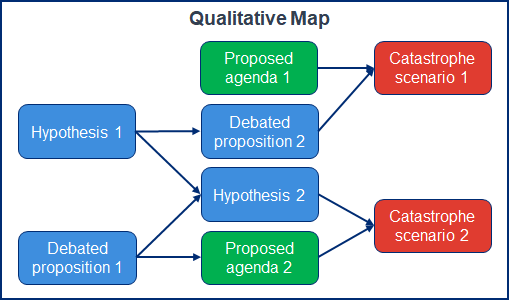
Mapping key hypotheses: As mentioned above, this part of the project involves an ongoing effort to map out the key hypotheses and debate cruxes relevant to risks from Transformative AI, in a manner comparable to and building upon the earlier diagram by Ben Cottier and Rohin Shah. As shown in the conceptual diagram below, the idea is to create a qualitative map showing how the various disagreements and hypotheses (blue nodes) are related to each other, how different proposed technical or governance agendas (green nodes) relate to different disagreements and hypotheses, and how all of those factors feed into the likelihood that different catastrophe scenarios (red nodes) might materialize.
Quantification and decision analysis: Our longer-term plan is to convert our hypothesis map into a quantitative model that can be used to calculate decision-relevant probability estimates. For example, a completed model could output a roughly estimated probability of transformative AI arriving by a given date, a given catastrophe scenario materializing, or a given approach successfully preventing a catastrophe.
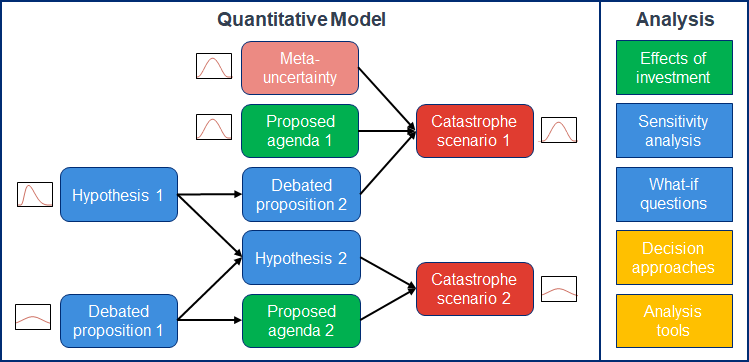
The basic idea is to take any available data, along with probability estimates or structural beliefs elicited from relevant experts (which users can modify or replace with their own estimates as desired). Once this model is fully implemented, we can then calculate probability estimates for downstream nodes of interest via Monte Carlo, based either on a subset or a weighted average of expert opinions, or using specific claims about the structure or quantities of interest, or a combination of the above. Finally, even if the outputs are not accepted, we can use the indicative values as inputs for a variety of analysis tools or formal decision-making techniques. For example, we might consider the choice to pursue a given alignment strategy, and use the model as an aid to think about how the payoff of investments changes if we believe hardware progress will accelerate or if we presume that there is relatively more existential risk from nearer-term failures.
Most of the posts in this series will focus on the qualitative mapping part of the project, since that has been our primary focus to date. In our last post we will discuss our plans related to the second, quantitative, part of the project.
Model Overview
The next several posts in this sequence will dive into the details of our current qualitative model. Each post will be written by team members involved in crafting that particular part of the model, as different team members or groups of team members worked on different parts of the model.
The structure of each part of the model is primarily based on a literature review and the understanding of the team members, along with considerable feedback and input from researchers outside the team. As noted above, this series of posts will hopefully continue to gather input from the community and lead to further discussions. At the same time, the various parts of the model are interrelated. Daniel Eth is leading the ongoing work of integrating the individual parts of the model, as we continue developing a better understanding of how the issues addressed in each component relate to each other.
Note on Implementation and Software: At present, we are using Analytica, a “visual software environment for building, exploring, and sharing quantitative decision models that generate prescriptive results.” The models that will be displayed in the rest of this sequence were created using this software program. Note: If you have Windows you can download the free version of Analytica and once the full sequence of posts is available, we hope to make the model files available, if not publicly, at least on request. To edit the full model you unfortunately need the expensive licensed version of Analytica, since the free version is limited to editing small models and viewing models created by others. There are some ways around this restriction if you only want to edit individual parts of the model - once the sequence has been posted, please message Daniel Eth, David Manheim, or Aryeh Englander for more information.
How to read Analytica models
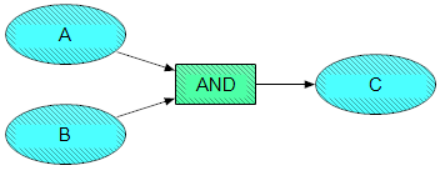
Before presenting an overview of the model, and as a reference for later posts, we present a brief explanation of how these models work, and how they should be read. Analytica models are composed of different types of nodes, with the relationships between nodes represented as directed edges (arrows). The two primary types of nodes in our model are variable nodes and modules. Variable nodes are usually oval or rounded rectangles without bolded outlines, and correspond to key hypotheses, cruxes of disagreement, or other parameters of interest. Modules, represented by rounded rectangles with bolded outlines, are “sub-models” that contain their own sets of nodes and relationships. In our model we also sometimes use small square nodes to visually represent AND, OR, or NOT relationships. In the software, a far wider set of ways to combine outputs from nodes are available, and will be used in our model - but they are difficult to represent visually.


Arrows represent directions of probabilistic influence, in the sense that information about the first node influences the probability estimate for the second node. For example, an arrow from Variable A to Variable B indicates that the probability of B depends at least in part on the probability of A. It is important to note that the model is not a causal model per se. An edge from one node to another does not necessarily imply that the first causes the second, but rather that there is some relationship between them such that information about the first informs the probability estimate for the second. Some edges do represent causal relationships, but only insofar as that relationship is important for informing probability estimates.
Different parts of the model use various color schemes to group nodes that share certain characteristics, but color does not have any formal meaning in Analytica and is not necessary to make sense of the model. The color schemes for individual parts of the model will be explained as needed, but color differences can be safely ignored if they become confusing.
Other things to note:
- In some of the diagrams there are small arrowheads leading into or out of certain nodes, but which do not point to any other node in the diagram. These arrowheads indicate that there are nodes elsewhere in the model that depend on this node or that this node depends on.
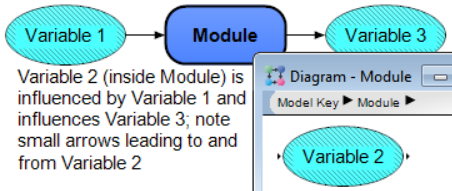
- “Alias nodes” are copies of nodes that link back to the original “real” node, and are mainly useful for display or readability purposes. We use alias nodes in many parts of our diagrams, especially when a node from one module influences or is influenced by some important node(s) elsewhere in the model. Analytica indicates that a node is an alias by displaying the node name in italics.
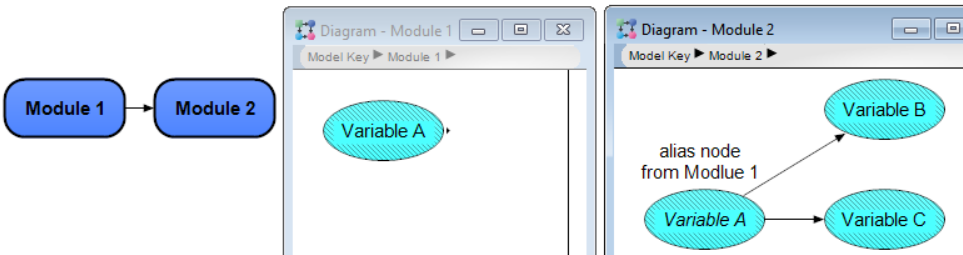
- Our model is technically a directed acyclic graph. However, there are a few places in the model diagrams where Analytica confusingly displays bidirectional arrows between modules even though the direction of influence only goes in one direction. This is because Analytica uses arrows not just to indicate direction of influence, but also to indicate that one module contains an alias node from a different model. For example, the direction of influence in the image below is from Variable A in Module 1 to Variable B in Module 2, but Analytica displays a bidirectional arrow between the modules because Module 1 also contains an alias node from Module 2.

Top-level model walkthrough
The image below represents the top-level diagram of our current model. Most of the nodes in this diagram are their own separate modules, each with their own set of nodes and relationships. Most of these modules will be discussed in much more detail in later posts.
In this overview, we highlight key potential nodes and the related questions, and discuss how they are interrelated at a high level. This overview, which in part explains the diagram below, hopes to provide a basic outline of what later posts will discuss in much more detail. (Note that the arrows represent the direction of inference in the model, rather than the underlying causal relationships. Also note that the relationship between the modules reflect dependencies between the individual nodes in the modules, rather than just notional suggestions about the relationships between the concepts represented by the modules themselves.)
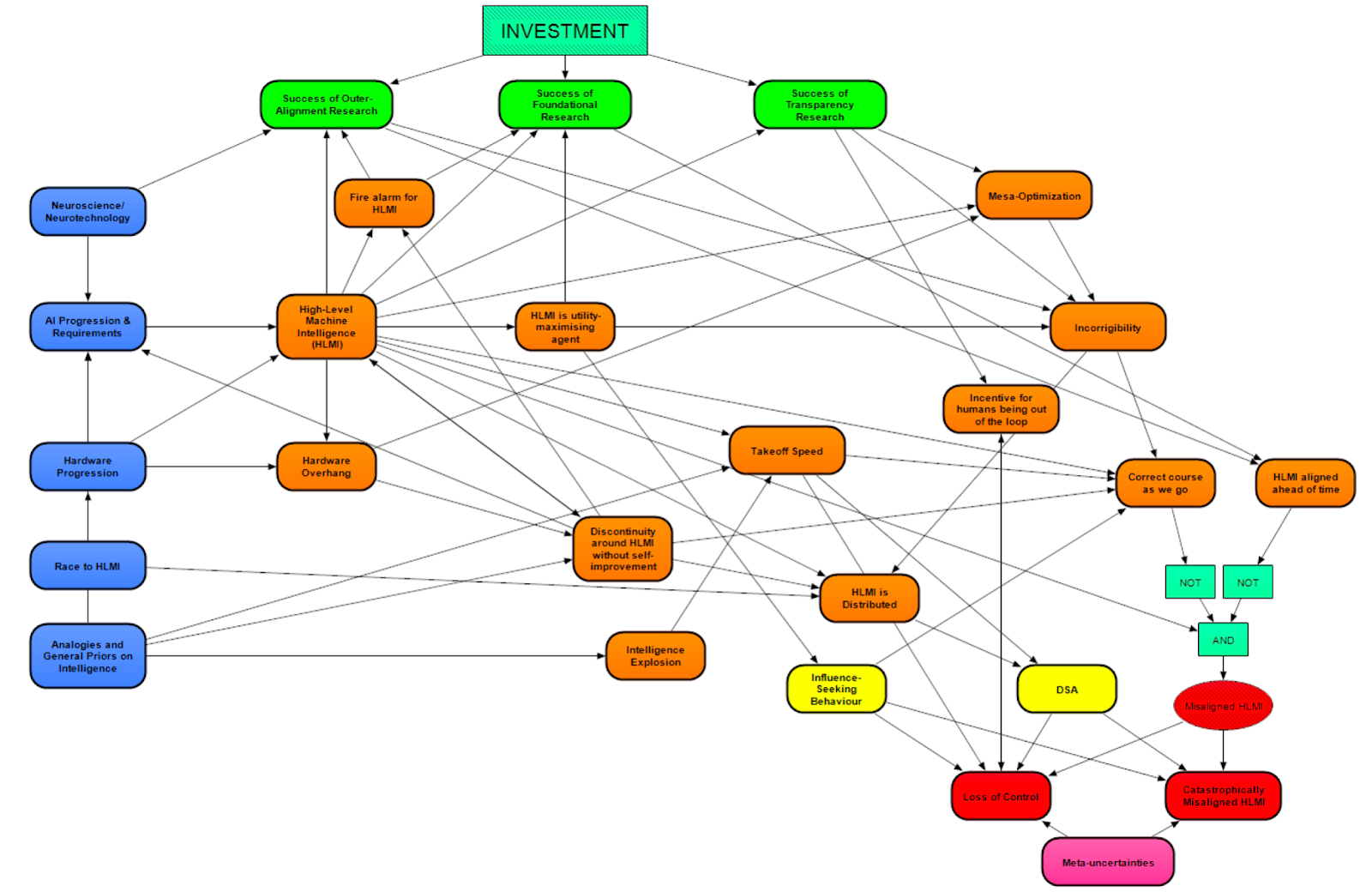
The blue nodes on the left represent technical or other developments or future progress areas that are potentially relevant inputs to the rest of the model. They are: Neuroscience / Neurotechnology, AI Progression & Requirements, Hardware Progression, and Race to HLMI. Finally, Analogies and General Priors on Intelligence, which address many assumptions and arguments by analogy from domains like human evolution, are used to ground debates about AI takeoff or timelines. These are the key inputs for understanding progress towards HLMI(1).
The main internal portions of the model (largely in orange), represent the relationships between different hypotheses and potential medium-term outcomes. Several key parts of this, which will be discussed in future posts, include paths to High-Level Machine Intelligence (HLMI) (and the inputs to it, in the blue modules), Takeoff/discontinuities, and Mesa-optimization. Impacting these are different safety agendas (along the top in green), which will be reviewed in another post.
Finally, the nodes on the bottom right represent conditions leading to failure (yellow) and failure modes (red). For instance, the possibility of Misaligned HLMI (bottom right in red) motivates the critical question of how the misalignment can be prevented. Two possibilities are modelled (orange nodes, right): The first possibility is that HLMI is aligned ahead of time (using Outer Alignment, Inner Alignment [AF · GW] and, if necessary, Foundational Research). The second possibility is that we can ‘correct course as we go’, for instance, by using an alignment method that ensures the HLMI is corrigible [? · GW].
While our model has intermediate outputs (which when complete will include estimates of HLMI timelines and takeoff speed), its principal outputs are the predictions for the modules marked in red. Catastrophically Misaligned HLMI covers scenarios involving a single HLMI or a coalition achieving a Decisive Strategic Advantage (DSA) over the rest of the world and causing an existential catastrophe. Loss of Control covers ‘creeping failure’ scenarios, including those that don’t require a coalition or individual to seize a DSA.
The Model is (Already) Wrong
We expect that readers will disagree with us, and with one another, about various points - we hope you flag these issues. At the same time, the above is only a high level overview, and we already know that many items in the above overview are contentious or unclear - which is exactly why we are trying to map it more clearly.
Throughout this work, we attempt to model disagreements and how they relate to each other, as shown in the earlier notional outline for mapping key hypotheses. As a concrete example, whether HLMI will be agentive, itself a debate, influences whether it is plausible that the HLMI will attempt to self-modify or design successors. The feasibility of either modification or successor design is another debate, and this partly determines the potential for very fast takeoff, influencing the probability of a catastrophic outcome. As the example illustrates, the values and the connections between the nodes are all therefore subject to potential disagreement, which must be represented in order to model the risk. Further and more detailed examples are provided in upcoming posts.
Further Posts and Feedback
The further posts in this sequence will cover the internals of these modules, which are only outlined at a very high level here. This is intended to be a sequence that will be posted over the coming weeks, starting with the post on Analogies and General Priors on Intelligence later this week, followed by Paths to HLMI.
If you think any of this is potentially useful, or if you already disagree with some of our claims, we are very interested in feedback and disagreements and hope to have a productive discussion in the comments. We are especially interested in places where the model does not capture your views or fails to include an uncertainty that you think could be an important crux. Similarly, if the explanation seems confused or confusing, flagging this is useful - both to help us clarify, and to ensure it doesn’t reflect an actual disagreement. It may also be useful to flag things that you think are not cruxes, or are obvious, since others may disagree.
Also, if this seems interesting or related to any other work you are doing to map or predict the risks, please be in touch - we would be happy to have more people to consult with or who wish to participate directly.
Footnotes
- Note that HLMI is viewed as a precursor to, and a likely cause of, transformative AI. For this reason, in the model, we discuss HLMI, which is defined more precisely in later posts.
Acknowledgements
The MTAIR project (formerly titled, “AI Forecasting: What Could Possibly Go Wrong?”) was originally funded through the Johns Hopkins University Applied Physics Laboratory (APL), with team members outside of APL working as volunteers. While APL funding was only for one year, the non-APL members of the team have continued work on the project, with additional support from the EA Long-Term Future Fund (except for Daniel Eth, whose funding comes from FHI). Aryeh Englander has also continued working with the project under a grant from the Johns Hopkins Institute for Assured Autonomy (IAA).
The project is led by Daniel Eth (FHI), David Manheim, and Aryeh Englander (APL). The original APL team included Aryeh Englander, Randy Saunders, Joe Bernstein, Lauren Ice, Sam Barham, Julie Marble, and Seth Weiner. Non-APL team members include Daniel Eth (FHI), David Manheim, Ben Cottier, Sammy Martin, Jérémy Perret, Issa Rice, Ross Gruetzemacher (Wichita State University), Alexis Carlier (FHI), and Jaime Sevilla.
We would like to thank a number of people who have graciously provided feedback and discussion on the project. These include (apologies to anybody who may have accidentally been left off this list): Ashley Llorens (formerly APL, currently at Microsoft), I-Jeng Wang (APL), Jim Scouras (APL), Helen Toner, Rohin Shah, Ben Garfinkel, Daniel Kokotajlo, and Danny Hernandez, as well as several others who prefer not to be mentioned. We are also indebted to several people who have provided feedback on this series of posts, including Rohin Shah, Neel Nanda, Adam Shimi, Edo Arad, and Ozzie Gooen.
0 comments
Comments sorted by top scores.