Takeoff Speeds and Discontinuities
post by Sammy Martin (SDM), Daniel_Eth · 2021-09-30T13:50:35.046Z · LW · GW · 1 commentsContents
Early Modules (Discontinuity and Intelligence Explosion) Discontinuity around HLMI without self-improvement How many breakthroughs? Intelligence Explosion Comparing Discontinuity and Intelligence Explosion Later Modules (Takeoff Speed and HLMI is Distributed) Takeoff Speed HLMI is Distributed Conclusion Acknowledgments None 1 comment
This post is part 4 in our sequence on Modeling Transformative AI Risk [? · GW]. We are building a model to understand debates around existential risks from advanced AI. The model is made with Analytica software, and consists of nodes (representing key hypotheses and cruxes) and edges (representing the relationships between these cruxes), with final outputs corresponding to the likelihood of various potential failure scenarios. You can read more about the motivation for our project and how the model works in the Introduction post [AF · GW]. The previous post in the sequence, Paths to High-Level Machine Intelligence [AF · GW], investigated how and when HLMI will be developed.
We are interested in feedback on this post, especially in places where the model does not capture your views or fails to include an uncertainty that you think could be an important crux. Similarly, if an explanation seems confused or confusing, flagging this is useful – both to help us clarify, and to ensure it doesn’t reflect an actual disagreement.
The goal of this part of the model is to describe the different potential characteristics of a transition from (pre-)HLMI¹ to superintelligent AI (i.e., “AI takeoff”). We also aim to clarify the relationships between these characteristics, and explain what assumptions they are sensitive to.
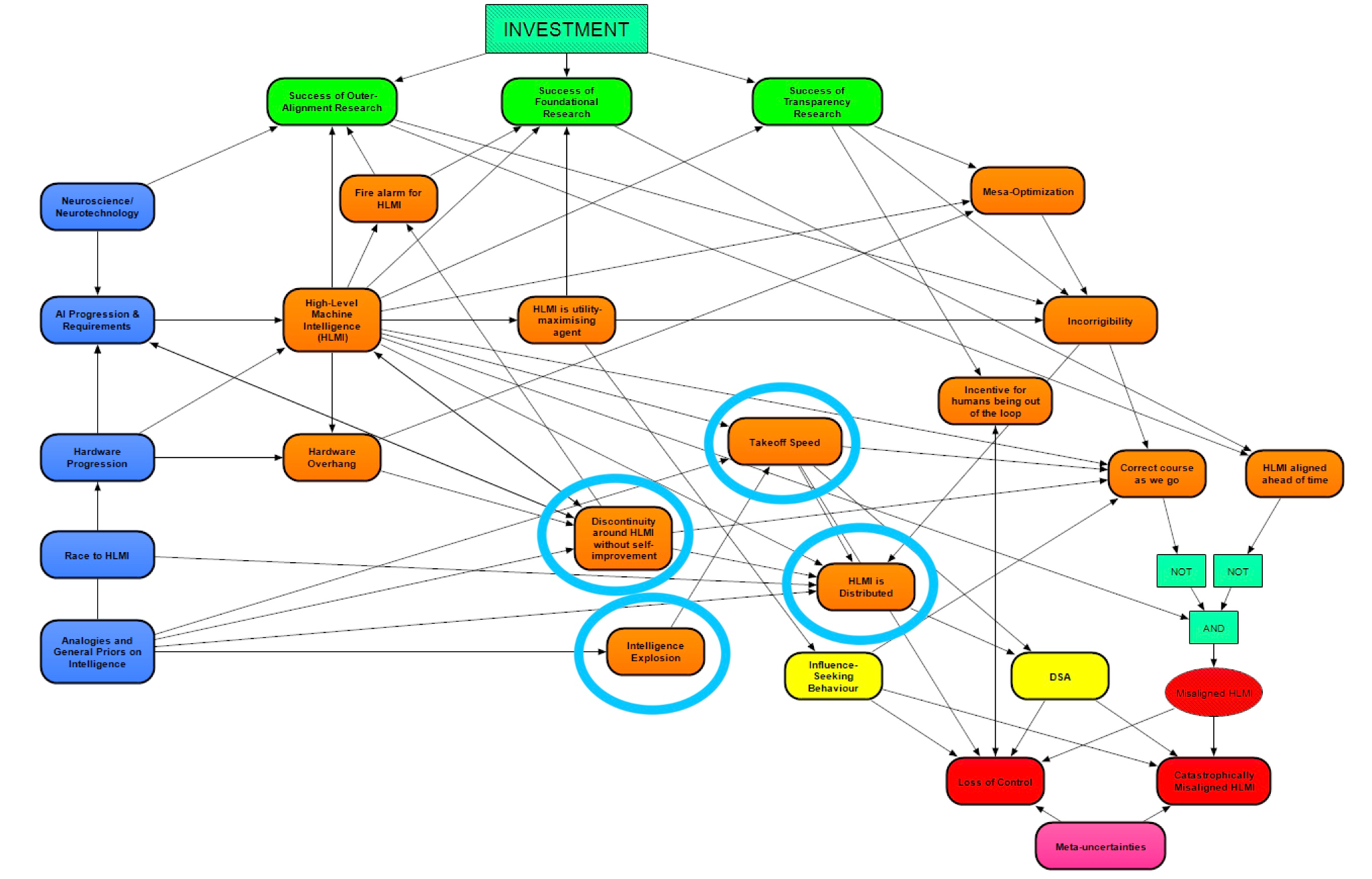
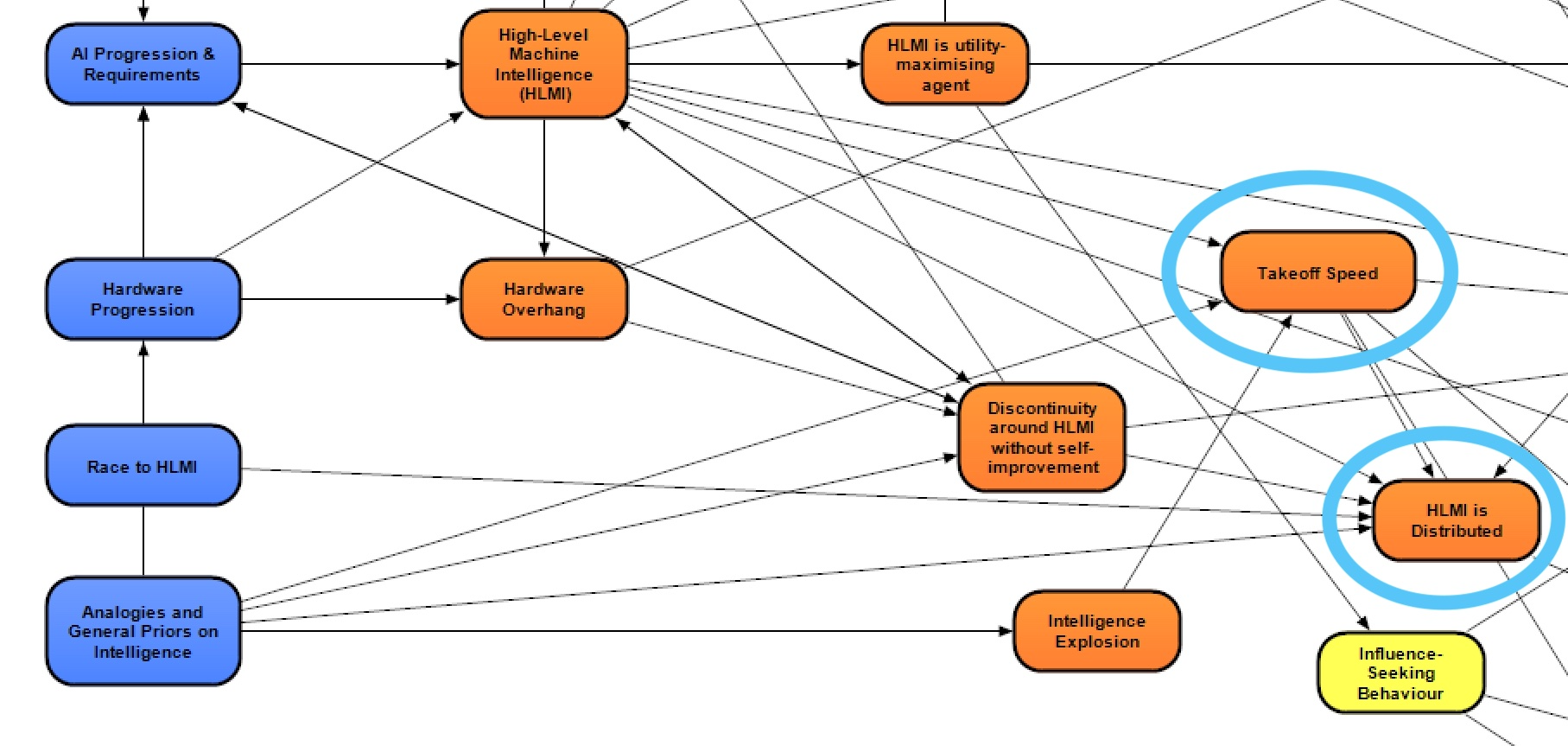
As shown in the above image, the relevant sections of the model (circled in light blue) take inputs primarily from these modules:
- Analogies and General Priors on Intelligence [? · GW] – this module concerns both arguments that compare HLMI development with other, previous developments (for example, the evolution of human intelligence, current progress in machine learning, and past historical/cultural transitions) and broad philosophical claims about the nature of intelligence
- High-Level Machine Intelligence (HLMI) [? · GW] – this module concerns whether HLMI will be developed at all, and if so, which type of HLMI and when
- Hardware Overhang – this module concerns whether, at the time HLMI is developed, the amount of hardware required to run HLMI and the availability of such hardware will lead to a situation of “hardware overhang”, where overwhelming hardware resources allow for the first HLMI(s) to be overpowered due to being cheaply duplicated, easily run at a high clock speed, or otherwise rapidly scaled up.
The outputs of the sections of concern in this post, corresponding to the above circled modules, are:
- Intelligence Explosion – will a positive feedback loop involving AI capabilities lead these capabilities to grow roughly hyperbolically [LW · GW] across a sufficient range, such that the capabilities eventually grow incredibly quickly to an incredibly high level (presumably before plateauing as they approach some fundamental limit)?
- Discontinuity around HLMI without self-improvement – will there be a rapid jump in AI capabilities from pre-HLMI AI to HLMI (for instance, if pre-HLMI acts like a machine with missing gears) and/or from HLMI to much higher intelligence (for instance, if a hardware overhang allows for rapid capability gain soon after HLMI)?
- Takeoff Speed – how fast will the global economy (or the next closest thing, if this concept doesn’t transfer to a post-HLMI world) grow, once HLMI has matured as a technology?
- HLMI is Distributed – will AI capabilities in a post-HLMI world be dispersed among many comparably powerful systems? A negative answer to this node indicates that HLMI capabilities will be concentrated in a few powerful systems (or a single such system).
These outputs provide a rough way of characterizing AI takeoff scenarios. While they are non-exhaustive, we believe they are a simple way of characterizing the range of outcomes which those who have seriously considered AI takeoff tend to find plausible. For instance, we can summarize (our understanding of) the publicly espoused views of Eliezer Yudkowsky, Paul Christiano, and Robin Hanson (along with a sceptic position) as follows:
| Eliezer Yudkowsky | Paul Christiano | Robin Hanson | Sceptic | |
| Intelligence Explosion | Yes | Yes | No | No |
| Discontinuity around HLMI without self-improvement | Yes | No | No | No |
| Takeoff Speed | ~hyperbolically increasing
(No significant intermediate doublings) | ~hyperbolically increasing
(with complete intermediate doublings on the order of ~1 year) | Doubling time of ~weeks to months | Doubling time on the order of ~years or longer |
| HLMI is Distributed | No | Yes | Yes | Yes |
These outputs – in addition to outputs from other sections of our model, such as those covering misalignment – impact further downstream sections of our model relevant to failure modes.
In a previous post [AF · GW] we explored the Analogies and General Priors on Intelligence module, which includes very important input for the modules in this post. That module outputs answers to four key questions (which are used throughout this later module):
- The difficulty of marginal intelligence improvements at the approximate human level (i.e., around HLMI)
- Whether marginal intelligence improvements become increasingly difficult beyond HLMI at a rapidly growing rate or not
- ‘Rapidly growing rate’ is operationalized as becoming difficult exponentially or faster-than-exponentially
- Whether there is a fundamental upper limit to intelligence not significantly above the human level
- Whether, in general, further improvements in intelligence tend to be bottlenecked by previous improvements in intelligence rather than some external factor (such as the rate of physics-limited processes)
In the next section of this post, we discuss the Intelligence Explosion and Discontinuity around HLMI without self-improvement modules, which are upstream of the other modules covered in this post. After that, we explore these other modules (which are influenced by the earlier modules): HLMI is Distributed and Takeoff Speed.
Early Modules (Discontinuity and Intelligence Explosion)
We now examine the modules Discontinuity around HLMI without self-improvement and Intelligence Explosion, which affect the two later modules – HLMI is Distributed and Takeoff Speed.
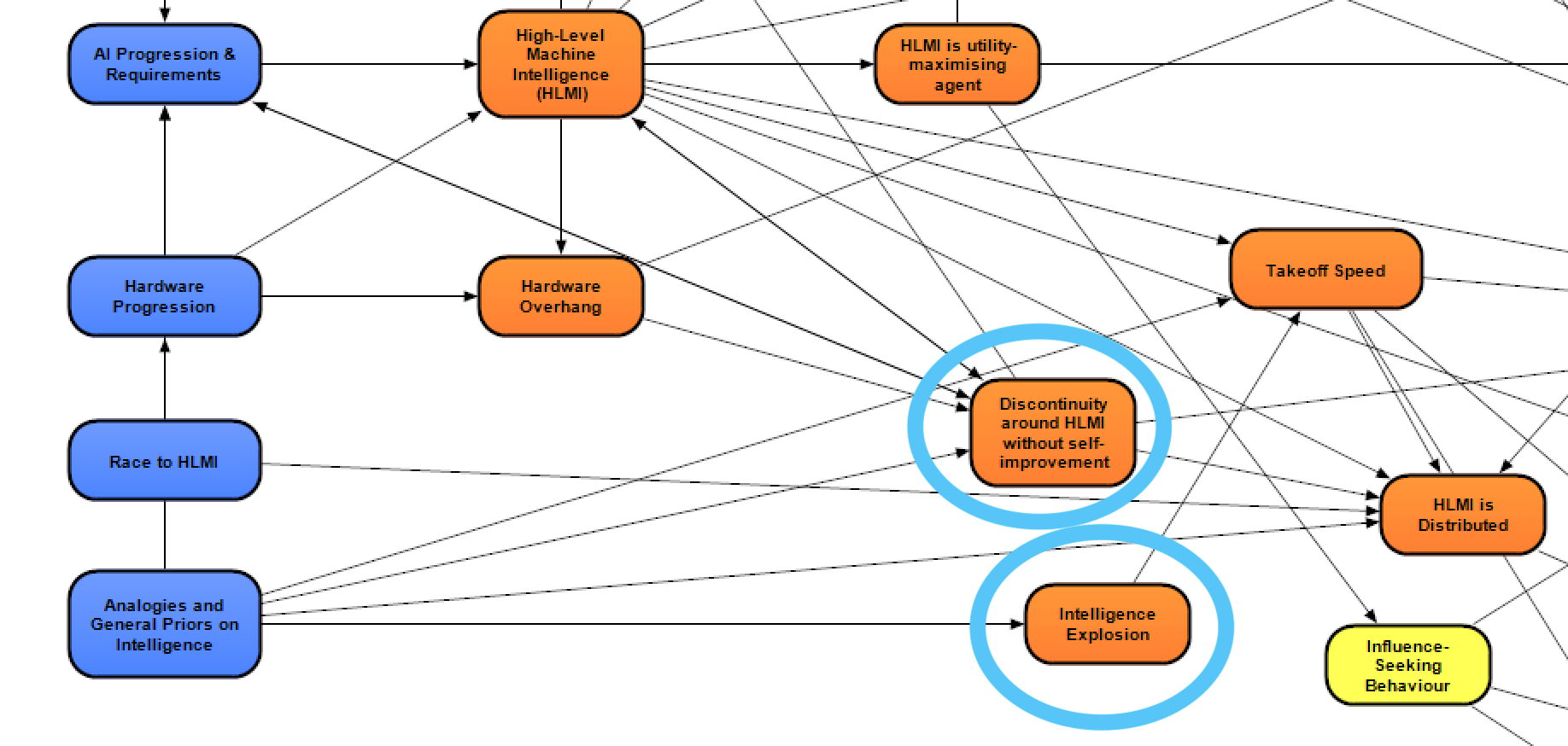
Discontinuity around HLMI without self-improvement
This module aims to answer the question: will the first HLMI (or a very early HLMI) represent a discontinuity in AI capabilities from what came before? We define a discontinuity as a very large and very sudden jump in AI capabilities, not necessarily a mathematical discontinuity, but a phase change caused by a significantly quicker rate of improvement than what projecting the previous trend would imply. Note that this module is NOT considering rapid self-improvement from quick feedback loops (that would be considered instead in the module on Intelligence Explosion), but is instead concerned with large jumps occurring around the time of the HLMI generation of AI systems.
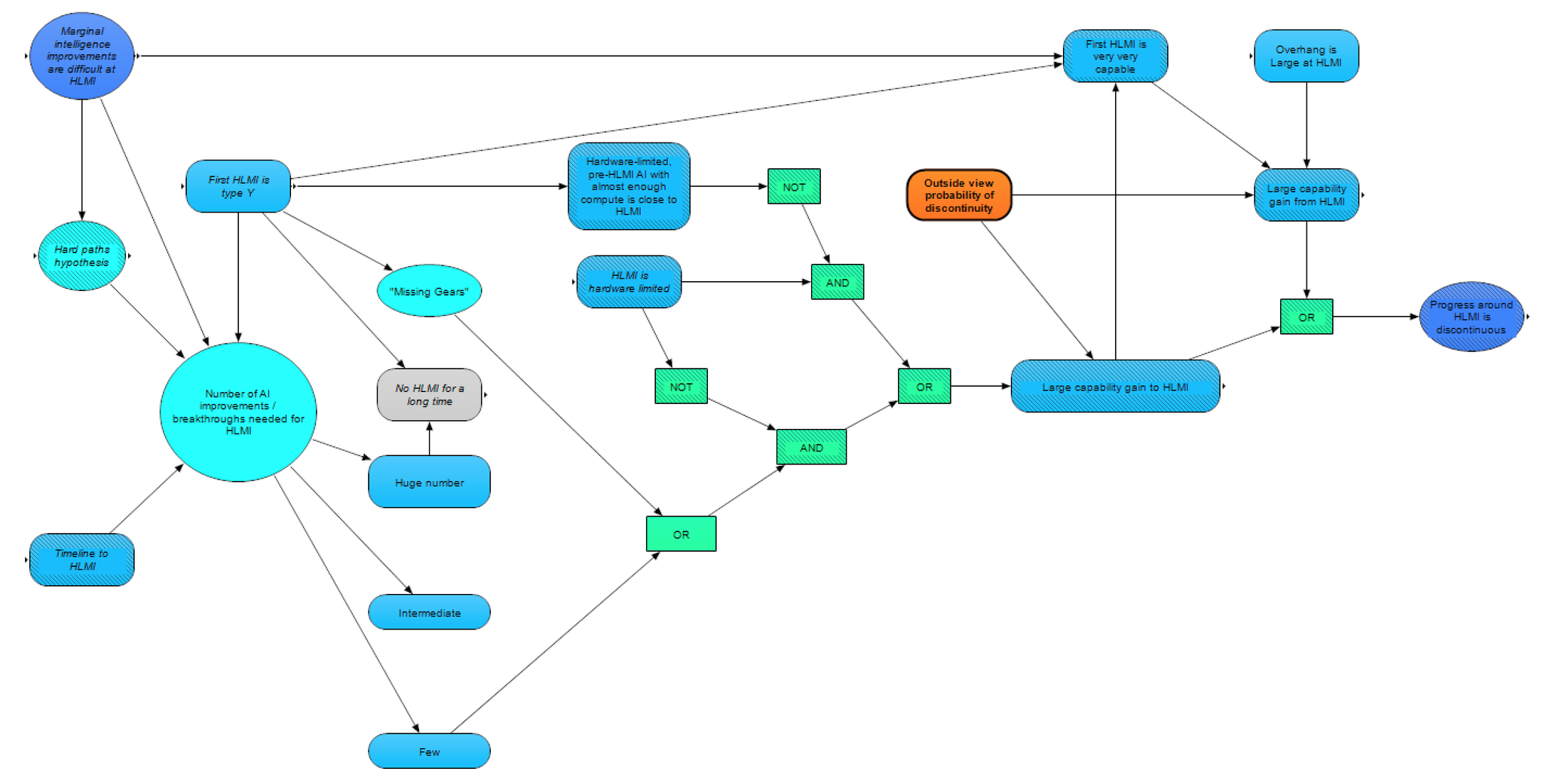
Such a discontinuity could be from a jump in capabilities to HLMI or a jump from HLMI to significantly higher capabilities (or both). A jump in capabilities from HLMI could occur, either if the first HLMI “overshoots” the HLMI-level and is very very capable (which likely depends on both the type of HLMI and whether marginal intelligence improvements are difficult around HLMI), or if a large hardware overhang allows for the first HLMI to scale (in quality or quantity) in such a way that it is far beyond the HLMI-level in capabilities.
The image below shows a zoomed-in view of the two routes (either a large capability gain from HLMI, or a large capability gain to HLMI):
Regarding capability jumps to HLMI, we see a few pathways, which can be broken down by whether HLMI will ultimately be bottlenecked on hardware or software (i.e., which of hardware or software will be last to fall into place – as determined by considerations in our post on Paths to HLMI [LW · GW]). If HLMI will be bottlenecked on hardware (circled in green on the graph below), then the question reduces to whether pre-HLMI with almost enough compute has almost as strong capabilities as HLMI. To get a discontinuity from hardware-limited HLMI, the relationship between increasing abilities and increasing compute has to diverge from an existing trend to reach HLMI (i.e., hardware-limited, pre-HLMI AI with somewhat less compute is much less capable than HLMI with the required compute). We suspect that whether this crux is true may depend on the type of HLMI in question (e.g. statistical methods might be more likely to gain capabilities if scaled up and run with more compute).
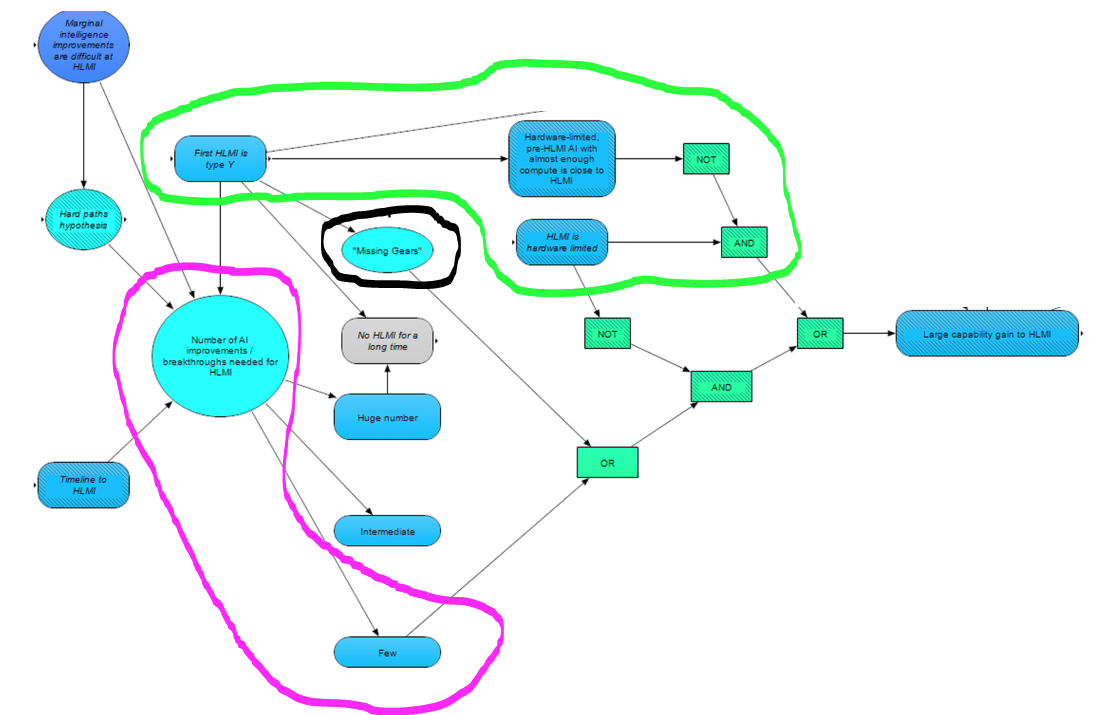
If HLMI is software limited, on the other hand, then instead of hardware, we want to know whether the last software step(s) will result in a large jump in capabilities. This could happen either if there are very few remaining breakthroughs needed for HLMI (circled in magenta above) such that the last step(s) correspond to a large portion of the problem, or if the last step(s) act as “missing gears” putting the rest of the system in place (circled in black above).
We suspect that whether the last step(s) present a “missing gears” situation is likely to depend on the type of HLMI realized. A (likely) example of “missing gears” would be whole brain emulation [? · GW] (WBE), where 99% of the way towards WBE presumably doesn’t get you anything like 99% of the capabilities of WBE. (See here for an extended discussion of the relationship between "fundamental breakthroughs” and "missing gears”.) If the “missing gears” crux resolves negatively, however, then determining whether there will be a large capability gain to HLMI is modeled as depending on the number of remaining breakthroughs needed for HLMI.
We make the simplifying assumption that the remaining fundamental breakthroughs are all of roughly comparable size, such that the more breakthroughs needed, the less of a step any individual breakthrough represents. This means that the last breakthrough – the one that gives us HLMI – might either take us from AI greatly inferior to HLMI all the way to HLMI (if there are ‘few’ key breakthroughs needed), or just be an incremental improvement on pre-HLMI AI that is already almost as useful as HLMI (if there are an ‘intermediate’ or ‘huge number’ of key breakthroughs needed).
We consider several lines of evidence to estimate whether HLMI requires few or many key breakthroughs.
To start, the type of HLMI being developed influences the number of breakthroughs we expect will be needed. For instance, if HLMI is achieved with current deep learning methods plus business-as-usual advancements [AF · GW], then, ceteris paribus, we’d expect fewer breakthroughs needed to reach HLMI than if HLMI is achieved via WBE [AF · GW].
As well as depending on the type of HLMI developed, our model assumes the expected number of breakthroughs needed for HLMI is influenced significantly by the Difficulty of Marginal Intelligence Improvements at HLMI (in the Analogies and General Priors on Intelligence [? · GW] module). If marginal intelligence improvements are difficult at HLMI, then more separate breakthroughs are probably required for HLMI.
Lastly, the hard paths hypothesis and timeline to HLMI (as determined in the Paths to HLMI [AF · GW] modules) each influence our estimate of how many breakthroughs are needed to reach HLMI. The hard paths hypothesis [AF · GW] claims that it’s rare for environments to straightforwardly select for general intelligence – if this hypothesis is true, then we’d expect more steps to be necessary (e.g., for crafting the key features of such environments). Additionally, short timelines would imply that there are very few breakthroughs remaining, while longer timelines may imply more breakthroughs needing to be found (remember [AF · GW], it’s fine if this logic feels “backwards”, as our model is not a causal model per se, and instead arrows represent probabilistic influence).
How many breakthroughs?
We don’t place exact values on the number of breakthroughs needed for HLMI in either the ‘few’, ‘intermediate’ or ‘huge number’ cases. This is because we have not yet settled on a way of defining “fundamental breakthroughs”, nor of estimating how many would be needed to shift the balance on whether there would be a large capability gain to HLMI.
Our current plan for characterizing the number of breakthroughs is to anchor the ‘intermediate’ answer to ‘number of remaining breakthroughs’ as similar to the number of breakthroughs that have so far occurred in the history of AI [LW · GW]. If we identify that there have been 3 major paradigms in AI so far (knowledge engineering, deep search, and deep learning), and maybe ten times as many decently-sized breakthroughs (within deep learning, this means things like CNNs, the transformer architecture, DQNs) to get to our current level of AI capability, then an ‘intermediate’ case would imply similar numbers to come. From this, we have:
- Few Breakthroughs: 0-2 major paradigms and 0-9 new breakthroughs
- Intermediate: Similar number of breakthroughs as so far, or somewhat more: 3-9 new paradigms and 10-100 breakthroughs
- Huge number: More than 10 paradigms, 100 breakthroughs
Another way to estimate the number of remaining breakthroughs is to use expert opinion. For example, Stuart Russell identifies 4 remaining fundamental breakthroughs needed for HLMI (although these ‘breakthroughs’ seem more fundamental than those listed above, and might correspond to a series of breakthroughs as defined above):
"We will need several conceptual breakthroughs, for example in language or common sense understanding, cumulative learning (the analog of cultural accumulation for humans), discovering hierarchy, and managing mental activity (that is, the metacognition needed to prioritize what to think about next)"
Note that the ‘Few Breakthroughs’ case includes situations where 0 breakthroughs are needed (and we actually don't make any new breakthroughs before HLMI) - i.e. cases where current deep learning with only minor algorithmic improvements and somewhat increased compute gives us HLMI [LW · GW].
Intelligence Explosion
This module aims to answer the question: will there eventually be an intelligence explosion? We define an “intelligence explosion” as a process by which HLMI successfully accelerates the rate at which HLMI hardware or software advances, to such a degree that the rate of progress approaches vertical over a large range.
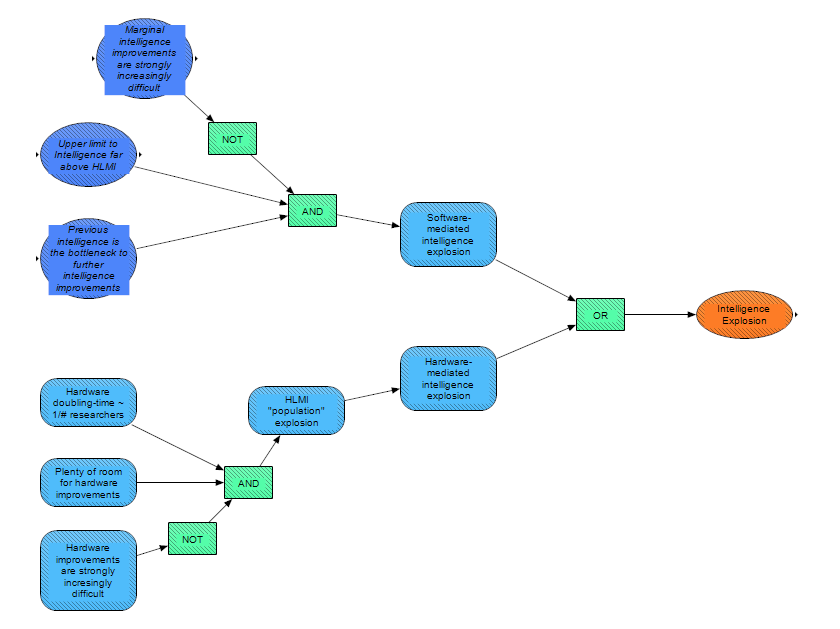
In our model, whether an intelligence explosion eventually occurs does not directly depend on what type of HLMI is first developed (as we assume that if one type of HLMI could not achieve an intelligence explosion while another could, even if the first type of HLMI is achieved first, the latter type – if possible to build – will eventually be built and cause an intelligence explosion then). Our model considers two paths to an intelligence explosion – a software-mediated path and a hardware-mediated path.
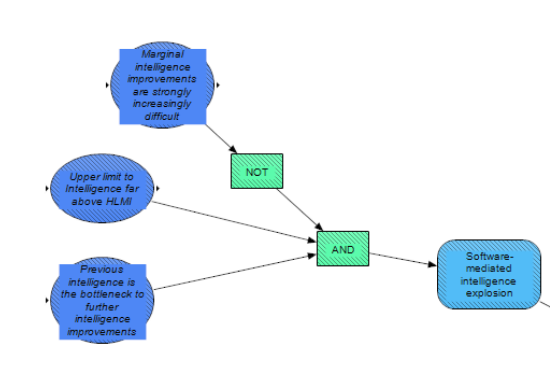
Under the software-mediated path, our model assumes there will be explosive growth in intelligence, due to AI accelerating the rate of AI progress, if HLMI is developed and:
- marginal intelligence improvements are not strongly increasingly difficult,
- there are no other theoretical limits to increasing general intelligence or the practical capabilities of a general intelligence (at least none barely above the human level), and
- further intelligence improvements are bottlenecked by previous intelligence (as opposed to, say, physical processes that cannot be sped up).
In such a scenario, the positive feedback loop from “more intelligent AI” to “better AI research (performed by the more intelligent AI)” to “even more intelligent AI still” would be explosive – in effect, HLMI could achieve sustained returns on cognitive reinvestment, at least over a sufficiently large range.
In addition to the software-mediated path, an intelligence explosion could occur due to a hardware-mediated path.
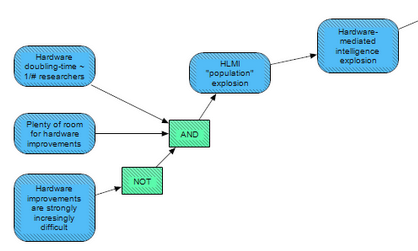
In this scenario, HLMI (doing hardware R&D) would cause an explosion in the amount of hardware, and thus an explosion in the “population” of HLMI (implying more HLMIs to perform hardware research, faster hardware gains, and so on). This phenomenon would require hardware improvements to scale with the number of hardware researchers (with this work being performed by HLMIs), for hardware improvements not to become strongly-increasingly difficult, and for there to be plenty of room for more hardware improvements. Such a pathway would allow, at least in principle, the capabilities of AI to explode even if the capability of any given AI (with a fixed amount of hardware) did not explode.
Note that Intelligence Explosion as defined in this model does not necessarily refer to an instantaneous switch to an intelligence explosion immediately upon reaching HLMI – an intelligence explosion could occur after a period of slower post-HLMI growth with intermediate doubling times. Questions about immediate jumps in capabilities upon reaching HLMI are handled by the Discontinuity module.
Comparing Discontinuity and Intelligence Explosion
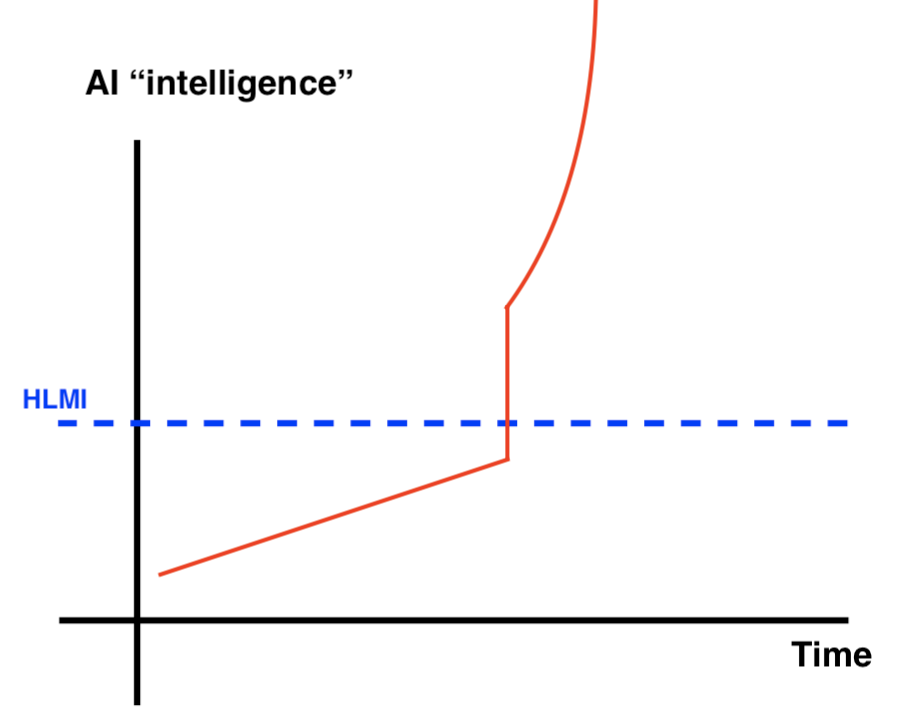
The distinction between a discontinuity and an intelligence explosion in our model can be understood from the following graphs, which show rough features of how AI capabilities might advance over time given different resolutions of these cruxes. Note that, while these graphs show the main range of views our model can express, they are not exhaustive of these views (e.g., the graphs show the discontinuity going through HLMI, while it’s possible that a discontinuity would instead simply go to or from HLMI).
Additionally, the model is a simplification, and we do not mean to imply that progress will be quite as smooth as the graphs imply – we’re simply modeling what we expect to be the most important and crux-y features. Take these graphs as qualitative descriptions of possible scenarios as opposed to quantitative predictions – note that the y-axis (AI “intelligence”) is an inherently fuzzy concept (which perhaps is better thought of as increasing on a log scale) and that the dotted blue line for “HLMI” might not occupy a specific point as implied here but instead a rough range. Further remember that we’re not talking about economic growth, but AI capabilities (which feed into economic growth).
| No Intelligence Explosion, No Discontinuity | No Intelligence Explosion, Discontinuity |
 |  |
| Intelligence Explosion, No Discontinuity | Intelligence Explosion, Discontinuity |
 |  |
Later Modules (Takeoff Speed and HLMI is Distributed)
The earlier modules from the previous section act as inputs to the modules in this section: Takeoff Speed and HLMI is Distributed.
Takeoff Speed
We have seen how the model estimates the factors which are important for assessing the takeoff speed:
- Will there be an intelligence explosion?
- From Analogies and General Priors:
- How difficult are marginal intelligence improvements at and beyond HLMI?
- What is the upper limit to intelligence?
This module aims to combine these results to answer the question – what will happen to economic growth post-HLMI? Will there be a new, faster economic doubling time (or equivalent) and if so, how fast will it be? Alternatively, will growth be roughly hyperbolic (before running into physical limits)? To clarify, while previously we were considering changes in AI capabilities, here we are examining the resultant effects for economic growth (or similar). This discussion is not per se premised on considerations of GDP [LW · GW] measurement.
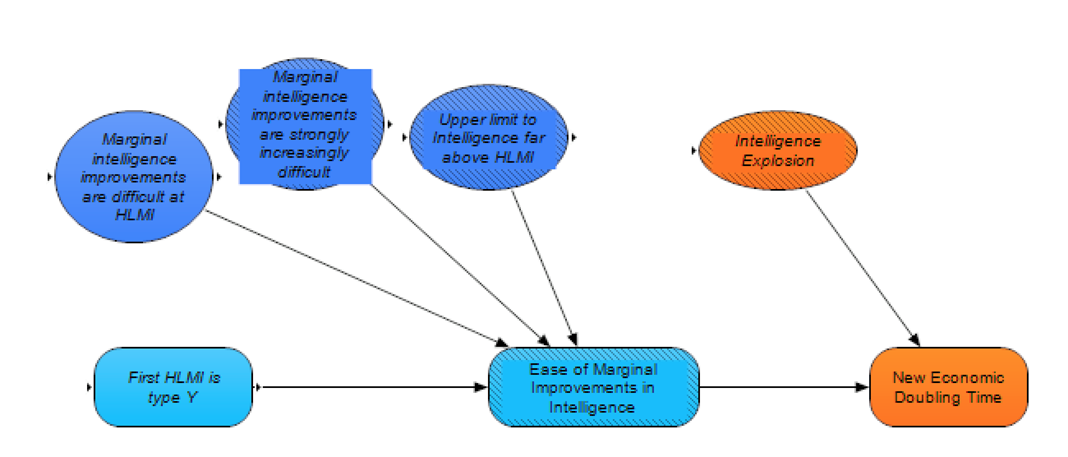
If the Intelligence Explosion module indicates an intelligence explosion, then we assume economic growth becomes roughly hyperbolic, along with AI capabilities (i.e., increasingly short economic doubling times).
If there is not an intelligence explosion, however, then we assume that there will be a switch to a new mode of exponential economic growth, and we estimate the speed-up factor for this new growth rate compared to the current growth rate based largely on outside-view estimates of previous transitions in growth rates (the Agricultural Revolution and the Industrial Revolution – on this outside view alone, we would expect the next transition to bring us an economic doubling time of perhaps days to weeks). This estimate is then updated based on an assessment of the overall ease of marginal improvements post-HLMI.
If
- marginal intelligence improvements are not strongly increasingly difficult,
- there is no significant upper limit to HLMI capability, and
- marginal intelligence improvements are not difficult at HLMI,
then we conclude that the transition to more-powerful HLMI looks faster, all else equal, and update our outside-view estimate regarding the economic impact accordingly (and similarly we update towards slower growth if these conditions do not apply). We plan to use these considerations to create a lognormally-distributed estimate of the final growth rate, given that we are uncertain over multiple orders of magnitude regarding the post-HLMI growth rate, even in a world without an intelligence explosion.
The connection between economic doubling time and the overall intelligence/capability of HLMI is not precise. We think our fuzzy assessment is appropriate, however, since we’re only looking for a ballpark estimate here (and due to the lognormal uncertainty, the results of our model should be robust to small differences in these parameters).
HLMI is Distributed
This module aims to answer the question, is HLMI ‘distributed by default’? That is, do we expect (ignoring the possibility of a Manhattan Project-style endeavour that concentrates most of the world’s initial research effort) to see HLMI capability distributed throughout the world, or highly localized into one or a few leading projects?
Later in this sequence of posts we will synthesise predictions about the two routes to highly localised HLMI: the route explored in this post i.e., HLMI not being distributed by default; and an alternative route, explored in a later module, where most of the world's research effort is concentrated into one project. We expect that if HLMI is distributed by default and research effort is not strongly concentrated into a few projects, many powerful HLMIs will be around at the same time.
Several considerations in this section are taken from Intelligence Explosion Microeconomics (in section 3.9 “Local versus Distributed Intelligence Explosions”).
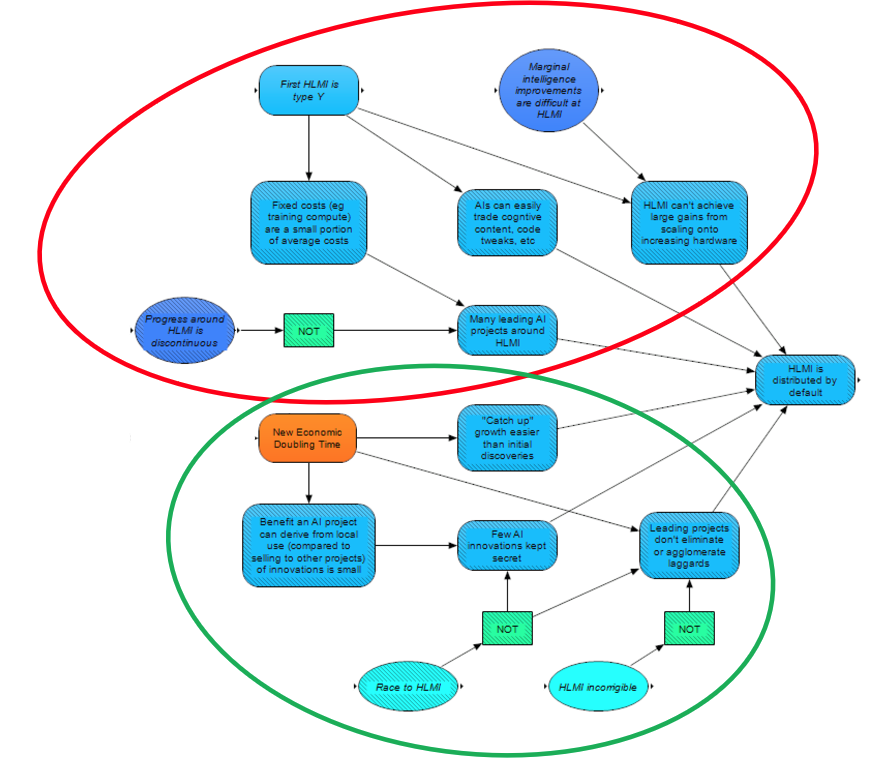
Arguments about the degree to which HLMI will be distributed by default can be further broken up into two main categories: those heavily influenced by the economic takeoff speed/possibility of an intelligence explosion (mostly social factors, circled in green); and those not heavily influenced by the economic takeoff speed (mostly technical factors, circled in red). We should note that, while takeoff speed indirectly affects the likelihood of HLMI distribution through intermediate factors, it does not directly affect whether HLMI will be distributed; even in the case of an intelligence (and therefore economic) explosion, it’s still possible that progress could accelerate uniformly [LW · GW], such that no single project has a chance to pull ahead.
Here, we will first examine the factors not tied to takeoff speed, before turning to the ones that are.
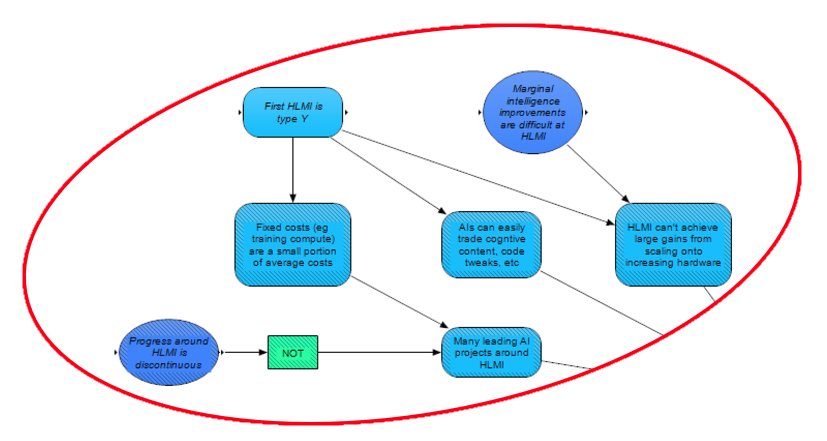
A significant consideration is whether there will be a discontinuity in AI capabilities around HLMI. If there is a discontinuity, then it is highly likely that HLMI will not initially be distributed by default, because one project will presumably reach the discontinuity first. We model this as there being only one leading AI project to begin with. Even if progress around HLMI is continuous, however, there could still be only a few leading projects going into HLMI, especially if fixed costs are a large portion of the total costs for HLMI (presumably affected by the kind of HLMI), since high fixed costs may present a barrier from many competitor projects.
HLMI is also more likely to be distributed if AIs can easily trade cognitive content, code tweaks, and so on (this likelihood is also presumably influenced by the type of HLMI), as if so, the advantages that leading projects hold may be more likely to be distributed to other projects.
Finally, if HLMI can achieve large gains from scaling onto increasing hardware, then we might expect leading projects to increase their leads over competitors, as profits could be reinvested in more hardware (or compute may be seized by other means), and thus HLMI may be expected to be less distributed. We consider that the likelihood of large gains from further hardware is dependent on both the type of HLMI, and the difficulty of marginal improvements in intelligence around HLMI (with lower difficulty implying a greater chance of large gains from increasing hardware).
Then, there are the aforementioned factors which are heavily influenced by the takeoff speed (which is influenced by whether there will be an intelligence explosion):
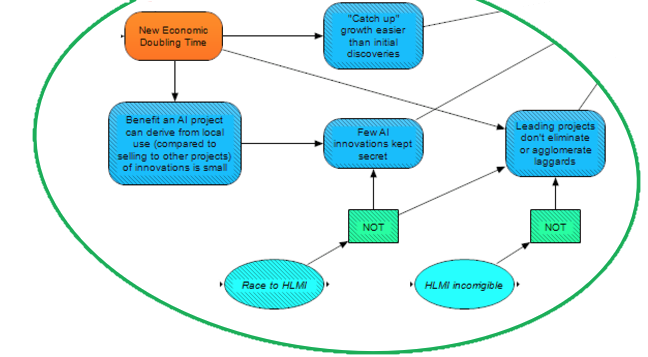
If catch-up innovation based on imitating successful HLMI projects is easier than discovering methods of improving AI in the first place, then we would expect more distribution of HLMI, as laggards may successfully play catch-up. A faster doubling time – and in particular an intelligence explosion – may push against this, as projects that begin to gather a lead may “pull ahead” more easily than others can play catch-up (we expect a faster takeoff to accelerate cutting-edge AI development by more than it accelerates the rest of the economy).
If major AI innovations tend to be kept secret, then this also pushes against HLMI being distributed. We may consider that a race to HLMI may encourage more secrecy between competitors. Additionally, secrecy may be more likely if AI projects can derive larger benefits from using its innovations locally than from selling its innovations to other projects. Local use may be more likely larger if there are shorter economic doubling times/an intelligence explosion, as such scenarios imply large returns from cognitive reinvestment.
Finally, we consider that distributed HLMI is less likely if leading projects eliminate or agglomerate laggards. Again, a race dynamic probably makes this scenario more likely. Additionally, if HLMI is incorrigible, it might be more likely to “psychopathically” eliminate laggards via actions that projects with corrigible HLMI might opt to avoid.
Conclusion
To summarize, we have examined key questions related to AI takeoff: whether there will be a discontinuity in AI capabilities to and/or from HLMI, whether there will be an intelligence explosion due to feedback loops post-HLMI, the growth rate of the global economy post-AI takeoff, and whether HLMI will be distributed by default. These estimates use a mixture of inside-view and outside-view considerations.
In building our model, we have made several assumptions and simplifications, as we’re only attempting to model the main cruxes. Naturally, this does not leave space for every possible iteration on how the future of AI might play out.
In the next post in this series, we will discuss risks from mesa-optimization.
- We define HLMI as machines that are capable, either individually or collectively, of performing almost all economically-relevant information-processing tasks that are performed by humans, or quickly (relative to humans) learning to perform such tasks. We are using the term “high-level machine intelligence” here instead of the related terms “human-level machine intelligence”, “artificial general intelligence”, or “transformative AI”, since these other terms are often seen as baking in assumptions about either the nature of intelligence or advanced AI that are not universally accepted.
Acknowledgments
This post was edited by Issa Rice [LW · GW]. We would like to thank both the rest of the MTAIR project team [? · GW], as well as the following individuals, for valuable feedback on this post: Ozzie Gooen, Daniel Kokotaljo and Rohin Shah
1 comments
Comments sorted by top scores.
comment by Sammy Martin (SDM) · 2021-09-30T15:17:10.412Z · LW(p) · GW(p)
Some comments on the model
General
- In defining the rate of AI progress and other related variables, we’ve assumed the practical impact of AI on the economy and society scales up roughly with AI ‘intelligence’, and in general used these terms (intelligence and capability) interchangeably. We have then asked if the growth of intelligence might involve sudden jumps or accelerate hyperbolically. However, as Karnofsky points out, the assumption that generality of intelligence = capability is probably false.
- There isn’t a single variable that captures all the concepts covered by e.g. impressiveness, capability, general intelligence and economic usefulness, but we have made the simplifying assumption that most of these properties are at least somewhat correlated (e.g. that more generally intelligent AIs are more economically useful). It’s not clear how to deal with this definitional uncertainty. From that post:
Overall, it's quite unclear how we should think about the spectrum from "not impressive/capable" to "very impressive/capable" for AI. And indeed, in my experience, different AI researchers have radically different intuitions about which systems are impressive or capable, and how progress is going.
- See this from Ajeya Cotra - our model essentially does use such a one-dimensional scale for most of its estimates of whether there will be a discontinuity/intelligence explosion, despite there being no such metric:

- Consider this often-discussed idea of AI moving ‘continuously’ up a scale of intelligence that lets it blow past human intelligence very quickly, just because human intelligence occurs over a very narrow range:

- This scenario is one where we assume the rate of increase in ‘intelligence’ is constant, but AI capability has a massive discontinuity with respect to ‘intelligence’ (i.e. AIs become supremely capable after a small 'objective' increase in intelligence that takes them beyond humans). We don’t model a meaningful distinction between this scenario and a scenario where intelligence and capability increase in tandem, but intelligence itself has a massive discontinuity at HLMI. Instead, we treat the two as basically identical.
Discontinuity around HLMI without self-improvement
- One example of a case where this issue of considering ‘capability, intelligence, economic usefulness’ as a single variable comes up: our node for ‘hardware-limited, pre-HLMI AI with somewhat less compute is much less capable than HLMI with the required compute’ might resolve differently for different meanings of capability.
- To take a cartoonish example, scaling up the compute for some future GPT-like language model might take it from 99% predictive accuracy to 99.9% predictive accuracy on some language test, which we could consider a negative answer to the ‘hardware-limited, pre-HLMI AI with somewhat less compute is much less capable than HLMI with the required compute’ node (since 10xing the compute 10xes the capability without any off-trend jump)
- But in this scenario, the economic usefulness of the 99.9% accurate model is vastly greater (let's say it can do long-term planning over a time horizon of a year instead of a day, so it can do things like run companies and governments, while the smaller model can’t do much more than write news articles). So the bigger model, while not having a discontinuity in capability by the first definition, does have a discontinuity on the second definition.
- For this hypothetical, we would want to take ‘capability’ to mean economically useful capabilities and how those scale with compute, not just our current measures of accuracy and how those scale with compute.
- But all of our evidence about whether we expect to see sudden off-trend jumps in compute/capability comes from current ML models, where we use some particular test of capability (like accuracy on next-word prediction) and see how it scales. It is possible that until we are much closer to HLMI we won’t get any evidence about how direct economic usefulness or generality scale with compute, and instead will have to apply analogies to how other more easily measurable capabilities scale with compute, and hope that these two definitions are at least somewhat related
- One issue which we believe requires further consideration is evidence of how AI scales with hardware (e.g. if capabilities tend to be learned suddenly or gradually), and potentially how this relates to whether marginal intelligence improvements are difficult at HLMI. In particular, the node that covers whether ‘hardware limited, pre-HLMI AI is almost as capable as HLMI’ probably requires much more internal detail addressing under what conditions this is true. Currently, we just assume it has a fixed likelihood for each type of HLMI.
- Our model doesn’t treat overhang by itself as sufficient for a discontinuity. That is because overhang could still get ‘used up’ continuously if we slowly approach the HLMI level and become able to use more and more of the available compute over time. Overhang becomes relevant to a discontinuity if there is some off-trend jump in capability for another reason - if there is, then overhang greatly enlarges the effect of this discontinuity, because the systems suddenly become able to use the available overhang, rather than gradually using it up.
- There aren’t necessarily one set of breakthroughs needed, even for one type of HLMI; there may be many paths. “Many/few fundamental breakthroughs" is measuring total breakthroughs that occur along any path.
- Further to this - we consider whether HLMI is ultimately hardware or software-limited in the model. While HLMI development will be limited by one or other of these things, hardware and software barriers to progress interact complicatedly. For example, for AI development using statistical methods researchers can probably trade off making new breakthroughs against increasing compute, and additional breakthroughs reduce how much needs to be done with ‘brute force’.
- For example, this post makes the case [AF · GW] that greatly scaling up current DL would give us HLMI, but supposing the conditional claims of that post are correct, that still probably isn’t how we’ll develop HLMI in practice. So we should not treat the claims in that post as implying that there are no key breakthroughs still to come.
Intelligence Explosion
- There is an alternative source to that given in IEM (Intelligence Explosion Microeconomics) for why, absent the three defeaters we list, we should expect to see an intelligence explosion upon developing HLMI. As we define it, HLMI should enable full automation of the process by which technological improvements are discovered, since it can do all economically useful tasks (it is similar to Karnofsky’s PASTA (Process for Automating Scientific and Technological Advancement) in this respect). If the particular technological problem of discovering improvements to AI systems is not a special case (i.e. if none of the three potential defeaters mentioned above hold) then HLMI will accelerate the development of HLMI like it will everything else, producing extremely rapid progress.
- Note that the ‘improvements in intelligence tend to be bottlenecked by previous intelligence, not physical processes’ is a significant crux that probably needs more internal detail in a future version of the model - there are lots of potential candidates for physical processes that cannot be sped up, and it appears to be a significant point of disagreement.
- While not captured in the current model, a hardware-and-software mediated intelligence explosion cannot be ruled out. Conceptually, this could still happen even if neither the hardware- nor software- mediated pathway is in itself feasible. That would require returns on cognitive reinvestment along either the hardware or software pathway to not be sustainable without also considering the other.
- Suppose HLMI of generation X software and generation Y hardware could produce both generation X+1 software and generation Y+1 hardware, and then thanks to faster hardware and software, it could even quicker produce generation X+2 and Y+2 software and hardware, and so on until growth becomes vertical. Further, suppose that if software were held constant at X, hardware growth would instead not explode, and similarly for software growth if hardware were held constant at Y.
- If these two conditions held then only hardware+software together, not either one, would be sufficient for an intelligence explosion
Takeoff Speeds
- The takeoff speeds model assumes some approximate translation from AI progress to economic progress (i.e. we will see a new growth mode if AI progress is very fast), although it incorporates a lot of uncertainty to account for slow adoption of AI technologies in the wider economy and various retarding factors. However, this part of the model could do with a lot more detail. In particular, slow political processes, cost disease and regulation might significantly lengthen the new doubling times or introduce periods of stagnation, even given accelerating AI progress.
- There is a difficulty in defining the ‘new’ economic doubling time - this is once again a simplification. This is because the ‘new’ doubling time is not the first complete, new, faster doubling time (e.g. a ‘slow’ takeoff as predicted by Christiano would still have a hyperbolically increasing new doubling time). It also isn’t the final doubling time (since the ultimate ‘final’ doubling time in all scenarios must be very long, due to physical limitations like the speed of light). Rather, the ‘new’ economic doubling time is the doubling time after HLMI has matured as a technology, but before we hit physical limits. Perhaps it is the fastest doubling time we ever attain.
HLMI is Distributed
- If progress in general is faster [LW(p) · GW(p)], then social dynamics will tend to make HLMI more concentrated in a few projects. We would expect a faster takeoff to accelerate AI development by more than it accelerates the rest of the economy, especially human society. If the new economic doubling time is very short, then the (greatly accelerated) rate of HLMI progress will be disproportionately faster [LW · GW] than the (only somewhat accelerated) pace of change in the human economy and society. This suggests that the human world will have a harder time reacting to and dealing with the faster rate of innovation, increasing the likelihood that leading projects will be able to keep hold of their leads over rivals. Therefore, faster takeoff does tend to reduce the chance that HLMI is distributed by default (although by a highly uncertain amount that depends on how closely we can model the new doubling time as a uniform acceleration vs changing the speed of AI progress while the rest of the world remains the same).