larger language models may disappoint you [or, an eternally unfinished draft]
post by nostalgebraist · 2021-11-26T23:08:56.221Z · LW · GW · 31 commentsContents
what this post is 0. caveat 1. polarization 2. the enthusiast's argument 3. are we getting smarter yet? 4. on ecological evaluation 4b. the road not taken 4c. non-ecological evaluation considered harmful Guess-what-I-mean bias, type 1 Guess-what-I-mean bias, type 2 Prompt noise and humans-in-the-loop 4d. just how much does prompting suck? Case study: BERT in the maze Case study: no one knows what few-shot results even mean 5. what scaling does 5b. what curation ratios miss 5c. my own subjective experience 5c. presidents 6. objective metrics, or: are you smarter than a 5th-grader? 7. getting smarter: subjective evidence? 8. pancakes None 31 comments
what this post is
The following is an incomplete draft, which I'm publishing now because I am unlikely to ever finish writing it.
I no longer fully endorse all the claims in the post. (In a few cases, I've added a note to say this explicitly.) However, there are some arguments in the post that I still endorse, and which I have not seen made elsewhere.
This post is the result of me having lots of opinions about LM scaling, at various times in 2021, which were difficult to write down briefly or independently of one another. This post, originally written in July 2021, is the closest I got to writing them all down in one place.
-nost, 11/26/21
0. caveat
This post will definitely disappoint you.
Or, anyway, it will definitely disappoint me. I know that even though I haven't written it yet.
My drafts folder contains several long, abandoned attempts to write (something like) this post. I've written (something like) this post many times in my head. I just can't seem to get it right, though. The drafts always sprawl out of control.
So, if I can't do it right, why not do it wrong? Here's the disorganized, incomplete, brain-dump version of the better post I wish I were writing. Caveat lector.
1. polarization
The topic of this post is large language models (LMs) like GPT-3. Specifically, what will happen as we make them larger and larger.
By my lights, everyone else seems either too impressed/scared by the concept of LM scaling, or not impressed/scared enough.
On LessWrong and related communities, I see lots of people worrying in earnest about whether the first superhuman AGI will be a GPT-like model. Both here and in the wider world, people often talk about GPT-3 like it's a far "smarter" being that it seems to me.
On the other hand, the people who aren't scared often don't seem like they're even paying attention. Faced with a sudden leap in machine capabilities, they shrug. Faced with a simple recipe that can make those machines even better -- with eerie, physics-like regularity -- they . . . still shrug. I wrote about the most infamous of these detractors here [LW · GW].
Meanwhile, I'm here in the middle. What do I think? Something like:
- The newer (i.e. large transformer) LMs really are a huge advance in NLP over the prior state of the art
- The prior state of the art was really bad, though. Before the new LMs, neural nets simply couldn't "do" language the way they could "do" images, something I noted back in 2017.
- Most of the "huge advance" happened in the smallest of the new models, like BERT-Base and GPT-2-small.
- The effect of scaling up these models is mostly to "de-noise" capabilities already evident in the small ones. It makes their strengths more robust and easier to access, but doesn't add fundamentally new strengths.
- The larger language models of the future will be highly impactful, but banal.
- They will probably allow us to fully automate all the routine linguistic tasks you could almost imagine automating with GPT-3.
- People will make wonderful new things using them.
- They won't be "smart" in any way that GPT-3 is not, or indeed, really in any way that GPT-2 was not.
- They will get better at abstract reasoning -- in the sense that it will be easier to get them to spit out text that sounds like it is the product of abstract reasoning. (As even GPT-2 does frequently.) They will be weak at this relative to their other capabilities, as they are today, and little will come of it.
- They might end up as sub-systems in an AGI one day.
The rest of the post will consist of some gestures where I try to make the above feel as natural to you as it does to me.
2. the enthusiast's argument
First, let's spell out the argument that has people thinking GPT will lead to AGI.
Roughly the same argument has been made elsewhere by gwern and bmk, among others.
- Loss scaling will continue. It will be straightforward to achieve lower and lower language modeling loss simply by using more compute + data.
We can do this without making any new conceptual advances (except perhaps in hardware). Therefore someone will do it.
- Loss scaling could well continue indefinitely. I.e., more compute + data might push the loss asymptotically all the way to to the "intrinsic entropy of text" -- the true noise left when all patterns have been accounted for, including arbitrarily hard ones.
It could be the case that scaling will instead bottom out at some earlier point, when the only patterns left are "too hard" for the models. We don't have much evidence one way or another on this point, and even if we did, we would have no idea how hard is "too hard."
- Language modeling is AGI-complete. A model that truly understood all patterns in a language modeling dataset would possess a large fraction of all human capabilities taken together.
Can you write a textbook on Étale cohomology? (If you can't, then you're missing out on some language modeling loss.) Can you play both sides of a roundtable between the world's leading economists, imitating the distinct intellect of each one, the novel arguments they'd concoct of the spot, the subtle flecks of personal bias tainting those arguments? (If you can't, then...) Can you translate between any pair of human languages that any linguist, anywhere, knows how to translate? (If you can't, then...) And so on.
- Loss scaling makes models "smarter" fast enough to matter. This point is a crucial bridge between the abstract potential from points 2 and 3, and the quantitative near-term predictions from point 1.
This point is easiest to explain by showing what its negation looks like.
Suppose that points 2 and 3 are really true -- that adding more compute/data eventually turns a transformer LM into an AGI. That doesn't tell you anything about how fast the process happens.
How many orders of magnitude do we need to add to make the model non-negligibly smarter? If the answer is "1 OOM," then the scaling projections from point 1 are relevant. If the answer is "100 OOM" . . . not so much.
(Or, consider a variant of this scenario: suppose most of the abilities we care about, when we use the term "AGI," are locked away in the very last tiny sliver of loss just above the intrinsic entropy of text. In the final 0.00[...many extra zeros...]1 bits/character, in a loss difference so tiny we'd need vastly larger validation sets to for it to be distinguishable from data-sampling noise.)
I agree with points 1-3. Point 4 is where I and the enthusiasts diverge.
3. are we getting smarter yet?
Why do the enthusiasts believe point 4? That is, why would we expect a feasible, incremental scaling upgrade to yield a meaningful boost in intelligence?
Because it already did: GPT-3 is meaningfully smarter than GPT-2.
The enthusiast's argument, in its most common form, relies entirely on this premise. The enthusiast knows perfectly well that AGI-completeness in principle is not enough: we need, not just an asymptotic result, but some idea of when we might get close enough.
As gwern puts it [my emphasis]:
The pretraining thesis, while logically impeccable—how is a model supposed to solve all possible trick questions without understanding, just guessing?—never struck me as convincing, an argument admitting neither confutation nor conviction. It feels too much like a magic trick: “here’s some information theory, here’s a human benchmark, here’s how we can encode all tasks as a sequence prediction problem, hey presto—Intelligence!” There are lots of algorithms which are Turing-complete or ‘universal’ in some sense; there are lots of algorithms like AIXI [? · GW] which solve AI in some theoretical sense (Schmidhuber & company have many of these cute algorithms such as ‘the fastest possible algorithm for all problems’, with the minor catch of some constant factors which require computers bigger than the universe).
Why think pretraining or sequence modeling is not another one of them? Sure, if the model got a low enough loss, it’d have to be intelligent, but how could you prove that would happen in practice? [...] It might require more text than exists, countless petabytes of data for all of those subtle factors like logical reasoning to represent enough training signal, amidst all the noise and distractors, to train a model. Or maybe your models are too small to do more than absorb the simple surface-level signals [...]
But apparently, it would’ve worked fine. [...] It just required more compute & data than anyone was willing to risk on it until a few true-believers were able to get their hands on a few million dollars of compute. [...]
If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s level, what capabilities would another ~30% improvement over GPT-3 gain?
But ... are the GPTs getting meaningfully smarter already, as we scale them?
It's tempting to casually answer "yes," pointing to any one of the numerous ways that the bigger models just are better. (But see the section below on "continuity"!)
However, we should not take this question so lightly. A yes answer would "complete the circuit" of the enthusiast's argument -- "turn it on" as a live concern. A no answer would leave the argument in limbo until more evidence comes in.
So, let's assess the state of the evidence.
4. on ecological evaluation
Consider an organism, say, or a reinforcement learning agent. How do we know whether it has some capability?
Easy. We put it in a situation where it needs to deploy that capability to get what it wants. We put food (or reward) at the end of the maze.
Assessing capabilities by prompting GPT is not like this. GPT does not "want" to show off its capabilities to you, the way a mouse wants food and an RL agent wants reward.
What GPT wants -- what it was directly optimized to do -- is to guess how a text will continue. This is not the same as "getting the right answer" or even "saying something sensible."
GPT was trained on the writing of thousands of individual humans, possessed of various flavors and magnitudes of ignorance, and capable of saying all kinds of irrational, inexplicable, or just plain bizarre things on occasion. To put it rather over-dramatically: much of the task of language modeling is figuring out which capabilities you're not supposed to reveal right now. Figuring out what sorts of mistakes the current writer is likely to make, and making them right on cue.
Thus, prompting tends to vastly underestimate (!) what any LM knows how to do in principle.
What is special about the "food in the maze" type of evaluation: it removes any uncertainty as to whether the model knows it's supposed to do the thing you want. The model is given a direct signal, in its "native language," about exactly what you want. This will tend to elicit the capability if it exists at all.
There's probably a standard term for the "food in the maze" thing, but I don't know it, so I'll just make one up: "ecological evaluation."
4b. the road not taken
It's totally possible to do ecological evaluation with large LMs. (Indeed, lots of people are doing it.) For example, you can:
- Take an RL environment with some text in it, and make an agent that uses the LM as its "text understanding module."
- If the LM has a capacity, and that capability is helpful for the task, the agent will learn to elicit it from the LM as needed. See e.g. this paper.
- Just do supervised learning on a capability you want to probe.
Both of these can be done with the LM weights frozen, or with full fine-tuning, or with a frozen LM plus a new "head" on top.
A purist might argue that you have to freeze the LM weights, or else you aren't really probing what the LM "already" knows. (The gradients from fine-tuning could induce new capabilities that weren't there before.)
But I doubt it really matters, since it turns out you can get the benefits of full fine-tuning even if you only tune the bias terms -- conceptually, just boosting or lowering the salience of patterns the LM could already recognize.
There is a divide -- to me, a strange and inexplicable one -- in the LM community, as to who does this ecological stuff and who doesn't.
- The people who do fine-tuning / extra heads / etc...
- ... generally don't care about scaling (an exception: section 3.4 here)
- ...generally use comparatively "tiny" models like BERT (an exception: T5)
- ... are often just trying to get practical things done, not deepen our understanding of LM capabilities (an exception: "probing tasks" in BERTology)
- The people who care about scaling and huge models...
- ... care about understanding LM capabilities
- ... mostly use non-ecological methods (prompting / few-shot), which are vastly unreliable measures of capability
- ... often use purely subjective (and thus bias-prone) measures, like whether samples from an LM "feel smart" or "sound human" to a particular reader
In other words, there are ways to really know what a big LM is capable of -- but the GPT enthusiasts aren't making use of them.
4c. non-ecological evaluation considered harmful
Non-ecological evaluation is epistemically bad. Whatever signal it provides is buried under thick layers of bias and noise, and can only be extracted with great care, if at all.
I don't think the GPT enthusiasts realize just how bad it is. I think this is one crux of our disagreement.
Let's survey some of the problems. (The names below are made-up and not meant very seriously -- I just need some headings to make this section readable.)
Guess-what-I-mean bias, type 1
As discussed above, the model may not understand what specific thing you want it to do, even if it's perfectly capable of doing that thing.
Result: a downward bias in capability estimates.
Guess-what-I-mean bias, type 2
The observed signal mixes together two components: "Can the model guess what you're trying to make it do?", and "Can the model actually do that thing?"
But when people interpret such results, they tend to round them off to measures only of the latter.
That is, when people see a bigger model do better on a few-shot task, they tend to think, "the model got better at the task!" -- not "the model got better at guessing which task I mean!"
But bigger models tend to get better at these two things simultaneously. The better results you get from bigger models reflect some mixture of "true capability gains" and "better guessing of what the prompt writer was trying to measure."
Result: an upward bias in capability scaling estimates.
Prompt noise and humans-in-the-loop
Guessing-what-you-mean is extremely sensitive to fine details of the prompt, even with huge models. (This is why "prompt programming" is a thing.)
Thus, if you just pick the first reasonable-seeming prompt that comes into your head, you'll get a horribly noisy measure of the LM's true abilities. Maybe a slightly different prompt would elicit far better performance.
(As you'd expect, the GPT-3 paper -- which took the "first reasonable-seeming prompt that comes into your head" approach -- ended up using severely suboptimal prompts for some tasks, like WiC.)
If possible, you want less noisy estimates. So you do prompt programming. You try a bunch of different things.
Even picking one "reasonable-seeming" prompt requires some human linguistic knowledge (to tell you what seems reasonable). Optimizing the prompt introduces more and more human linguistic knowledge, as you use what you know about language and the task to come up with new candidates and diagnose problems.
Now we're not evaluating a machine anyone. We're evaluating a (human + machine) super-system.
I don't want to make too much of this. Like, if you can find some prompt that always works across every variation of the task, surely the LM must "really know how to do the task," right?
(Although there are dangers even here. Are you doing the same amount of prompt-optimization with bigger models as with smaller ones? What performance might be coaxed out of GPT-2 124M, if you gave it as much attention as you're giving GPT-3? Probably not much, I agree -- but if you haven't tried, that's a source of bias.)
The issue I'm raising here is not that big LMs can't be smart without humans in the loop. (I'm sure they can.) The issue is that, with a human involved, we can't see clearly which parts would be easy for a machine alone, and hence which parts get us straightforwardly closer to AGI.
For example. In an ecological setting -- with no human, only a machine (say an RL agent with an LM sub-system) -- would the machine need to do its own "prompt programming"?
How much worse would it be at this than you are? (The part that operates the LM from the outside knows nothing about language; that's what the LM is there for.) What algorithms would work for this?
Or maybe that wouldn't be necessary. Maybe the right information is there in the LM's inner activations, even when it's fed a "bad" prompt. Maybe the problem with "bad" prompts is only that they don't propagate this interior info into the output in a legible way. I don't know. No one does.
[Addendum 11/26/21: prompt/P-tuning sheds some light on this question, cf. next Addendum]
4d. just how much does prompting suck?
But how much does all that really matter? Are we really missing out on nontrivial knowledge here?
Two case studies.
Case study: BERT in the maze
The GPT-3 paper measured model capabilities with "few-shot" prompting, i.e. filling up a long prompt with solved task examples and letting the model fill in the final-unsolved one. Typically they used 10 to 100 examples.
They compared GPT-3 against strong previous models on the same tasks.
These reference models used fine-tuning, generally with many more than 100 examples -- but the gap here is not always very big. On some benchmarks of great academic interest, even the fine-tuned models only get to see a few hundred examples:

Some of the reference models were carefully designed by researchers for one specific task. Let's ignore those.
In most cases, the paper also compared against a BERT baseline: literally just a vanilla transformer, like GPT-3, hooked up to the task with vanilla fine-tuning. (Fine-tuning BERT is literally so routine that a machine can do the entire process for you, even on a totally novel dataset.)
How well did GPT-3 do? On most tasks, about as well as a fine-tuned BERT-Large. Which is a transformer 500 times smaller than GPT-3.
These are not new feats of intelligence emerging at GPT-3's vast scale. Apparently they're already there inside models several orders of magnitude smaller. They're not hard to see, once you put food at the end of the maze, and give the model a reason to show off its smarts.
(Once again, GPT-3 saw fewer examples than the reference models -- but often not by much, and anyway you can make BERT do just fine with only 10-100 examples if you try hard and believe in yourself)
So. If even cute little BERT-Large is capable of all this ... then what on earth is GPT-3 really capable of?
Either GPT-3 is far smarter than the few-shot results can possibly convey . . .
. . . or it isn't -- which would be a dramatic failure of scaling, with those 499 extra copies of BERT's neural infrastructure hardly adding any intelligence!
No one knows, and no amount of prompting can tell you.
As I wrote last summer:
I called GPT-3 a “disappointing paper,” which is not the same thing as calling the model disappointing: the feeling is more like how I’d feel if they found a superintelligent alien and chose only to communicate its abilities by noting that, when the alien is blackout drunk and playing 8 simuntaneous games of chess while also taking an IQ test, it then has an “IQ” of about 100.
[Addendum 11/26/21:
"No one knows" here was wrong. The P-tuning paper, from March 2021, described an ecological evaluation method for GPTs that make them competitive with similarly-sized BERTs on SuperGLUE.
I think I had heard of prompt tuning when I wrote this, but I had not read that paper and didn't appreciate how powerful this family of methods is.
I'm not currently aware of any P-tuning-like results with very large models like GPT-3. End addendum]
Case study: no one knows what few-shot results even mean
There's an excellent blog post by janus called "Language models are 0-shot interpreters." Go read it, if you haven't yet. I'll summarize parts of it below, but I'll probably get it a bit wrong.
As stated above, the GPT-3 paper prompted the model with solved task examples. In fact, they compared three variants of this:
- zero-shot: no examples
- one-shot: a single example
- few-shot: many (10-100) examples
Most of the time, more "shots" were better. And the bigger the LM, the more it benefitted from extra shots.
It is not immediately obvious what to make of this.
The GPT-3 paper takes care to be technically 100% agnostic about the underlying mechanism . . . if you read it carefully, including the fine-print (i.e. footnotes and appendices). At the same time, in its choice of words, it gestures suggestively in exciting directions that a casual reader is likely to take at face value.
For example, the paper makes extensive use of the term "meta-learning." Read casually, it seems to be saying that LMs as big as GPT-3 have a novel capability -- they can learn new tasks on the fly, without fine-tuning!
But what the paper means by "meta-learning" is probably not what you mean by "meta-learning."
The paper's own definition is provided in a footnote. It is (admirably) precise, non-standard, and almost tautologous. In short, meta-learning is "any mechanism that makes more 'shots' work better":
These terms ["meta-learning" and "zero/one/few-shot" -nost] are intended to remain agnostic on the question of whether the model learns new tasks from scratch at inference time or simply recognizes patterns seen during training – this is an important issue which we discuss later in the paper, but “meta-learning” is intended to encompass both possibilities, and simply describes the inner-outer loop structure.
The same passage is quoted by janus in "Language models are 0-shot interpreters," who goes on to say:
The later discussion is not very extensive, mostly just acknowledging the ambiguity inherent to few-shot [...]
This is the uncertainty that I will investigate in this blog post, expanding on the results published in Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm.
My purpose is also to challenge the ontology introduced by Language Models are Few-Shot Learners. Although the authors are careful to remain agnostic as to the mechanism of few-shot/meta-learning, what we have found by probing the mechanism suggests that an alternative framework which emphasizes the means by which a task is communicated may be more salient in some contexts.
What does janus mean? The post goes on to describe a number of experiments, whose results suggest that
- What matters is not the number of task examples ("shots"), but how well the prompt specifies the desired task.
- Failures of zero- and one-shot are often failures to guess-what-I-mean on the basis of a legitimately ambiguous prompt.
- The value of additional "shots" may only lie in their value as a proxy for clarity in task communication.
- Once you have written a sufficiently clear one-shot (or even zero-shot) prompt, the model does not do any better with additional examples -- the task has already been communicated.
- In some cases, one-shot is actually worse than zero-shot -- because it adds a new kind of ambiguity.
("We noticed that sometimes the model would respond to one-shot prompts as if the semantic content of the example translation was relevant to the new translation. Without multiple examples, it’s less clear that the translation instances are meant to be parallel and independent.")
- OpenAI made much of the fact that adding "shots" helps larger models more. (This was the result behind the whole "meta-learning" framing.) However...
- Larger models are also far better at zero-shot.
- Comparing a zero-shot prompt to a "control" prompt with no task information, larger models get a larger fraction of their few-shot performance out of the jump from control to zero-shot, and a smaller fraction from the additional examples.
- In other words: GPT-3's size lets it extract more information from examples, if you provide them. But its size also lets it extract far more information from the original question. So it doesn't need the examples as much.
janus's post delights me for two reasons. First, I enjoyed learning the new experimental evidence it presents. But second, and perhaps more importantly, there was the sense of relief that someone actually did the experiments!
OpenAI's few-shot "learning" results are full of ambiguity. The GPT-3 paper left me confused on a basic philosophical level, as I noted at the time [LW · GW].
Surely the model isn't learning French de novo from 100 paired sentences -- either it speaks French at the outset, or it doesn't. So what could it be "learning" from those 100 examples?
Likewise for virtually every result in the paper: grammar, commonsense reasoning, book-learning trivia quizzes... all things it's clearly possible to learn from reading massive swaths of the internet, and all things it's clearly impossible to learn from reading 10 to 100 examples. Yet the examples help? And I'm supposed to think that makes the model . . . smarter, somehow?
Well, for French --> English translation at least, it turns out that the examples help in pretty much the only way they possibly could: by informing an already competent translator that you are requesting a translation.
As we were attempting to replicate [OpenAI's translation] results, we noticed that when the model was failing on the 0-shot prompt, the failures were often of catastrophic nature: the task was not attempted at all, e.g. the model would output a newline, or another (or the same) French phrase instead of an attempt at an English translation.
BLEU assigns a score from 0 to 1 to the accuracy of a translation, and would assign a score close to 0 to a catastrophic failure. The scores reported in the paper, however, are averaged over a large dataset, so the same score could hypothetically correspond to uniformly flawed attempts or a mix of perfect attempts and catastrophic failures.
It seemed possible that 0-shot prompts were much less reliable at getting the models to attempt the translation task, but result in equivalent accuracy in the event that they did attempt it.
[janus does an experiment investigating this hypothesis, and the results seem to confirm it]
How much of the apparent consistent monotonic improvement in performance on tasks relative to number of shots in OpenAI’s results can be attributed to an unhelpful zero-shot prompt? Much more extensive testing is needed to say, but I suspect that this is the case for most of the translation tasks, at least.
If the extra shots are just about clarifying the task, then what should we make of the claim that "larger models benefit more from extra shots?" That it's . . . easier to clarify tasks to them using this one particular mechanism? When people say GPT-3 displays some new, frightening kind of intelligence, emerging only at its massive scale, surely they can't mean that?
And that's not even all. As janus shows, even though it is easier to clarify tasks to GPT-3 through the "shots" mechanism, it's also easier for GPT-3 to guess what you mean with no shots at all.
"My friend has such sharp hearing. Why, you see see, conditional on her not hearing what you say the first time you say it, she will definitely hear it when you repeat yourself." Quite probably true, but not a good way to make the point!
What does it even mean that "language models are few-shot learners"? What does that tell us about the model's capabilities? We don't know. We haven't studied it in the level of depth appropriate for something that might actually matter.
After all, janus did a simple and innocuous set of experiments -- just trying to figure out which prompts work best -- and ended up drawing radically different conclusions about the whole thing than OpenAI did.
Oh, surely GPT-3 is plenty smart, I don't doubt that. The key question is how much smarter it got from scale, and in which ways. I don't think we'll know that until we put the model to the test, ecologically.
5. what scaling does
LMs are trained with a convex loss function. This means they are not min-maxers. They prefer to spread out their capabilities.
Given two areas of skill, Thing A and Thing B, they'll try to become equally good at both, even if that means not doing especially well at either. Given an extra marginal unit of potential-for-greatness, they'll smear it out as far as possible over all the Things they know about.
Thanks to the convex loss, they do this in proportion to how bad they are at each Thing to begin with -- leveling up their very worst abilities first, making themselves as un-specialized as they can.
As we've discussed above, LMs are also trained on very wide-ranging text corpora. Everything from fourth-tier clickbait news to advanced physics preprints to advanced-looking but crackpot physics preprints to badly-written furry porn to astonishingly well-written furry porn to mangled OCR transcripts of 18th-century law texts to et cetera, et cetera. And as far as they can manage, they will do exactly as well at modeling each and every (information-theoretic) bit of it.
Larger LMs achieve lower loss. We know that from the scaling laws. And lower loss means being better at predicting each individual word in that corpus, as uniformly as possible.
What does this imply?
First: that larger LMs are better at everything. It is difficult to find any capability which is present at all in smaller LMs, yet which does not improve with scale.
And second: that LMs abhor a skill vacuum.
Take a tiny LM, so tiny it really can't make heads or tails of some particular type of text. Now start scaling it up. As its capacity grows, its first priority is to eliminate its greatest weaknesses.
That one type of text, that utterly baffled the tiny LM? Convex loss hates that. Every additional unit of capacity gets invested, disproportionately, in bringing such stragglers up to par. The LM desperately wants to be at least sort-of-decent-I-guess at everything -- more than it wants to be a master of anything.
Given any one Thing, it will reach sort-of-decent-I-guess performance at that Thing at the smallest scale it can manage -- given the competition from all the other Things it desperately needs to be sort-of-decent-I-guess at.
By subjective standards, to human eyes casually scanning over LM samples, this happens pretty fast.
GPT-3 is great at lots of individual Things. But take any one of those Things, and you can bet a much tinier LM can do it at the sort-of-decent-I-guess level.
Humans, I think, tend to expect intelligence to grow in discontinuous jumps. Stages of child development. They don't understand that at this age. And then, a year or two later, they do understand -- fully.
LMs work the other way around. They never perform a sudden jump into competence where they could instead make a slow, gradual rise from "sort of seeming like they understand 10% of the time" to "sort of seeming like they understand 11% of the time" and so on. And this for every Thing uniformly.
It's very hard to find any point where scaling suddenly "flips a switch," and the model didn't Get It before, but now it Gets It.
(The one example I know of is GPT-3 arithmetic, for some reason. Note that few-shot learning -- whether you call it "meta-learning" or not -- is as gradual as everything else, not a switch that flips on with GPT-3.)
[Addendum 11/26/21:
I wrote this in ignorance of the BIG-Bench project, which is tracking returns to scale for a large and diverse set of tasks.
BIG-Bench has not published results yet, but they livestreamed some preliminary results in May 2021; see also LW discussion here [LW(p) · GW(p)].
In the livestream, they give two examples of tasks with smooth scaling and two examples of tasks with a "sudden switch-flip" around 100B params (this slide). They also show, in the aggregate over all tasks, "switch-flip" to faster scaling around 100B (this slide), although this is tricky to interpret since it depends on the task mixture. End addendum]
This confounds our intuitive assessments of LM scaling.
I have been on this train since the beginning, when tiny lil' GPT-2 124M blew my mind. I've used every new big every model from almost the moment it came out, as excited as a kid on Christmas morning.
I did this with every step of the (in retrospect, rather silly) GPT-2 staged release. My tumblr bot started out as (I think) 774M. Then I jumped to 1.5B.
That was as far as free OpenAI models went, but when EleutherAI came out with a 2.7B model, I finetuned that one for my bot. I was willing to endure the absolute horrors of mesh-tensorflow (don't ask) to get that 2.7B model up and running. Then, when EleutherAI made a 6.1B model, I got my bot using it in under a week.
I feel a kind of double vision, seeing these scale-ups happen in real time. The bigger models are better, at everything at once. Each increment of scale is barely perceptible, but once you've crossed enough of a scale gap, you feel it. When I go back and sample from 124M again, I feel deprived. It just isn't as good.
And yet, 124M blew my mind the first time I saw it. And no bigger LM, not even GPT-3, has come close to that experience.
Even lil' 124M is sort-of-decent-I-guess at so many things. It gets all the basics that older LMs missed: a true grasp of the regularity of syntax, the nuances of style, and at least the way meaning sounds if not meaning itself.
124M makes lots of little blunders, littered all over the place. Your probability of running into one increases as you read a sample, token by token.
You can glide along almost thinking "a human wrote this," but soon enough, you'll hit a point where the model gives away the whole game. Not just something weird (humans can be weird) but something alien, inherently unfitted to the context, something no one ever would write, even to be weird on purpose.
The bigger models? They smooth out all the trivial failings. They unwrinkle the creases. They babble on for longer and longer stretches without falling flat on their face. But eventually they fall, and they fall just as hard.
Play with GPT-3 for long, and you'll see it fall hard too.
Here's a sample where GPT-3 falls on its face. It starts out as a (near-?) verbatim regurgitation of a Wikipedia article on the 6th Harry Potter film. It's factually perfect up until the plot summary, which immediately goes off the rails into metafiction:
Following a Harry Potter fan’s dream that Harry’s late headmaster Albus Dumbledore is alive, and in a critical condition at the Ministry of Magic, Harry Potter and his friends Ron Weasley and Hermione Granger, decide to rescue him, as the school year comes to a close.
This sort of fanfictional "plot summary" proceeds with barely even an internal kind of coherence, as the tone veers from tense, dark drama to inappropriate anticlimax:
The two engage in a fierce duel in which Snape calls on his master to save him. Harry is unaffected by the curse due to his ability to cast a shield charm. He manages to shield himself and fight back, and in his distraction, Snape accidentally breaks his neck and dies.
Dumbledore explicitly dies, yet is somehow alive later on:
Lucius disarms Dumbledore, and an enraged Bellatrix kills him. [...]
Harry wakes up to find Dumbledore, Sirius, and Remus in the hospital wing, as well as his friends and the rest of the school, and he realizes that he is safe.
At the very end, both the Wikipedia article and the extended plot summary abruptly fall away, and we are suddenly reading an inane film review, by someone who must have a dark sense of humor:
I liked this movie as it is full of action and adventure. The plot is great as well as the dialogue. It is a well made movie and it is very entertaining.
This movie is definitely a must-watch, as it has plenty of action as well as being very humorous.
Advertisements
This sample is a failure. No one would have written this, not even as satire or surrealism or experimental literature. Taken as a joke, it's a nonsensical one. Taken as a plot for a film, it can't even keep track of who's alive and who's dead. It contains three recognizable genres of writing that would never appear together in this particular way, with no delineations whatsoever.
Remember janus's point about taking averages over success and "catastrophic failure"? Human reactions to LM samples are like that too. Even the smallest ones do all sorts of things OK, and can string you along for a while. The bigger ones do this for longer. The average consists of stringing people along, and then failing.
When you see a statistic like "humans could distinguish LM samples from human-written text in 52% of cases," this doesn't mean people are squinting at every single text like Blade Runner characters, scrutinizing it for the subtle, nearly invisible "tells" of cold, whirring machinery.
It means most of the texts look like generic news stories, and then occasionally you get one where Dumbledore dies, and is alive in the hospital, and I liked this movie as it is full of action and adventure.
When we get GPT-4, Dumbledore will die and be reborn a little less often, but mark my works, it'll happen.
Subjectively, LM scaling converges pointwise but not uniformly. The bigger models string you along for longer stretches, and then they fall, and they fall exactly as hard. Like the jumps in a Fourier series, striving to fit a square wave and never succeeding, not at infinite scale.

{kind=link}
5b. what curation ratios miss
Bigger models write "better" samples, by our subjective lights. Is that possible to quantify?
There's a simple way to do this, proposed by gwern and recently expanded upon by janus.
Sample from an LM, which some threshold of perceived quality in mind. Keep only the samples that good enough to pass your threshold, discarding the rest. (This is simply "curation" or "cherry-picking"). Divide the number of samples you keep by the total number you generated, and you get a ratio.
gwern:
Objective metrics hard to interpret. How much better is (un-finetuned base) GPT-3? The likelihood loss is an absolute measure, as are the benchmarks, but it’s hard to say what a decrease of, say, 0.1 bits per character might mean, or a 5% improvement on SQuAD, in terms of real-world use or creative fiction writing. It feels like a large improvement, definitely a larger improvement than going from GPT-2-345M to GPT-2-1.5b, or GPT-2-1.5b to GPT-3-12b, but how much?
Screening gains: 1:100 → 1:5 or 20× better? For fiction, I treat it as a curation problem: how many samples do I have to read to get one worth showing off? [...] With GPT-2-117M poetry, I’d typically read through a few hundred samples to get a good one, with worthwhile improvements coming from 345M→774M→1.5b; by 1.5b, I’d say that for the crowdsourcing experiment, I read through 50–100 ‘poems’ to select one. But for GPT-3, once the prompt is dialed in, the ratio appears to have dropped to closer to 1:5—maybe even as low as 1:3! [...] I would have to read GPT-2 outputs for months and probably surreptitiously edit samples together to get a dataset of samples like this page.
I completely understand why you would want to compute this metric. But it doesn't capture everything about subjective quality.
Suppose I take a math test. If it's scored in the simplest way, with no partial credit, then my score on the test is straightforwardly a "curation ratio." If I got 50% of the questions right, my ratio is 2:1.
But there are a lot of different ways to get 50% of a math test wrong. I could
- remember the techniques needed solve a 50% subset of the questions, and be totally stumped by the other 50%, or...
- be capable of doing all the problems, but fail to use it 50% of the time perhaps due to getting distracted or tired later in the test, or...
- be capable of doing all the problems, but fail to use it 50% of the time in a completely random fashion no one can predict or explain, or...
- be capable of doing all the problems, but also be sensitive to question phrasing in a complex and illegible way, so that I flub some questions that say "solve for X" where I could have gotten them if they had said "find X", or...
- ignore the nominal purpose of a math test ("demonstrate what you know") and instead set myself the task of roleplaying a self-consistent student character of initially unspecified skill, so that after making one stray mistake, the "correct" thing to do is now to make the same mistake everywhere, just like "my character" would, or...
#1 and #2 are the kinds of mistakes we expect humans to make. When we interpret human test scores, we assume we are averaging over these types of mistakes. This is why we feel comfortable making inferences from the scores to the human's understanding of the mathematical material.
LMs do #3-5 ubiquitously. (In particular, whatever else they are doing, LMs are always doing the role-playing of #5.)
Even as curation ratios trend towards 1:1, I don't think this distinction shrinks in size. That is, the LMs really are making fewer mistakes, but when they do make mistakes, I don't think they make them for increasingly "appropriate" reasons.
As I'll describe next, I've read a whole lot of LM samples, across many different model sizes. For better or for worse, this is the subjective sense I come away with.
It is for hard for me, inside my intuitive mental model, to credit any LM with any concrete "capability." To rely on it to know something, the way I'm relying on you to know some things (or else this post would be incomprehensible).
In my model there are only probabilities of different failures, and the probabilities decline, but the failures themselves remain perfectly devoid of sense and reason, concentrated diamonds of non-thought and non-seeing. Not amendable to Dennett's intentional stance. Non-even-wrong rather than wrong.
This movie is definitely a must-watch, as it has plenty of action as well as being very humorous.
Advertisements
5c. my own subjective experience
What does it feel like to compare one GPT model to another one that's just a tad bigger? (You can try this right now on one of the free web APIs, say with 774M and 1.5B.)
To be honest, I find this distinction almost imperceptible. So close to imperceptible that I'd be willing to chalk the remainder up to confirmation bias.
I've made this leap three times with my tumblr bot. Add up several nearly-imperceptible changes and, of course, you get a perceptible one. The bot really does feel a little "smarter" at 6.1B than at 774M.
But smarter how, exactly? I can't point you to one single thing it "learned" or "became capable of" when I went from 774M to 1.5B -- like I said, I could hardly notice a difference, much less a discrete one like "learning something new." Likewise, I cannot point to any one new capability I got from the next two scale-ups. (The model did start occasionally writing non-English text at 2.7B, but I think that was just the change in pre-training corpus.)
It just . . . sounds a little more like it's making sense, now, on average. Equivalently, it takes more tokens on average for it to stop making sense.
My mental model of these things does not contain abstractions like "knowing a fact" or "mastering a skill." If it ever did, it doesn't now.
I don't even know how many tens of thousands of LM samples I've read by now. (Just my bot alone has written 80,138 posts -- and counting -- and while I no longer read every new one these days, I did for a very long time.)
Read enough, and you will witness the LM both failing and succeeding at anything your mind might want to carve out as a "capability." You see the semblance of abstract reasoning shimmer across a strings of tokens, only to yield to suddenly to absurd, direct self-contradiction. You see the model getting each fact right, then wrong, then right. I see no single, stable trove of skills being leveraged here and there as needed. I just see stretches of success and failure at imitating ten thousand different kinds of people, all nearly independent of one another, the products of barely-coupled subsystems.
This is hard to refute, but I think this is something you only grok when you read enough LM samples -- where "enough" is a pretty big number.
GPT makes many mistakes, but many of these mistakes are of types which it only makes rarely. Some mistake the model makes only every 200 samples, say, is invisible upon one's first encounter with GPT. You don't even notice that model is "getting it right," any more than you would notice a fellow human "failing to forget" that water flows downhill. It's just part of the floor you think you're standing on.
The first time you see it, it surprises you, a crack in the floor. By the fourth time, it doesn't surprise you as much. The fortieth time you see the mistake, you don't even notice it, because "the model occasionally gets this wrong" has become part of the floor.
Eventually, you no longer picture of a floor with cracks in it. You picture a roiling chaos which randomly, but regularly, coalesces into ephemeral structures possessing randomly selected subsets of the properties of floors.
Once you have this picture, I find, it never goes away. That "bad" Harry Potter sample was exceptional; I did have to dig through plenty of unobjectionable stuff to find it, or stuff that was merely wrong in some more limited way (factually, tonally). Compared to the ones I knew, the model went on for longer stretches not making each mistake -- before, at last, it made it.
I've played with GPT-3 in the API too, and still, I just don't see the "phase transition" that some people see. I don't see a new level of abstract reasoning, just stochastically longer intervals in which the text fails to reveal a lack of abstract reasoning.
5c. presidents
What do the different GPTs "know" about the historical presidents of the U.S.?
Here is a picture from OpenAI's second scaling paper:

The accompanying text:
[...] we also observe some qualitative “phases of learning”, with small models having difficulty understanding the question being asked of them, larger models showing some rudimentary understanding, and the largest models correctly answering the questions. [...]
Tiny models appear to have trouble understanding the question, and don’t place any significant probability on the correct answer. Larger models understand that we’re requesting a US president, but fail to understand that the “second president” and “first president” are different requests, placing most of their weight for both questions on “George Washington”. Only larger models understand both aspects of the questions, answering both correctly.
Is this information about "what the different models know" about the presidents?
The inset text in the picture seems to say so: "100M-parameter models think every president is George Washington ... 3B-parameter models understand ordering or presidents."
Like many offhand statements about big LMs, this one made me feel kind of offended on behalf of smaller ones. I've seen sub-1B models converse about all kinds of more niche topics with factual accuracy far above chance. Do we really need 3B parameters for something as basic as "ordering of presidents"?
So I looked into it a bit.
I wrote a different prompt, not in OpenAI's Q&A format. (I expect my results don't generalized well across prompts, as LM "knowledge" is always mysteriously sensitive to details of context.)
My prompt looks like:
List of presidents of the United States
George Washington, April 30, 1789 – March 4, 1797
John Adams, March 4, 1797 – March 4, 1801
Thomas Jefferson, March 4, 1801 – March 4, 1809
James Madison, March 4, 1809 – March 4, 1817
James Monroe, March 4, 1817 – March 4, 1825
John Quincy Adams, March 4, 1825 – March 4, 1829
Andrew Jackson, March 4, 1829 – March 4, 1837
Martin Van Buren, March 4, 1837 – March 4, 1841
William Henry Harrison, March 4, 1841 – April 4, 1841
John Tyler, April 4, 1841 – March 4, 1845
James K. Polk, March 4, 1845 – March 4, 1849
Zachary Taylor, March 4, 1849 – July 9, 1850and so on, ending with Trump. I feed the entire thing into the model, once, and read off its predictions for the first token in each new president's name.
(In terms of shots, the problem is 0-shot for the first president, 1-shot for the second, 2-shot for the third, etc.)
Here are the probabilities you get from the different GPT-2 models:

What if we look at the rank of the right answer -- whether it's the model's first guess (rank 0), or its runner-up (rank 1), etc.?
This lens reveals knowledge in the smaller models that's invisible if you look only at top-1 guesses or probabilities. These models correctly assign low probabilities to all answers -- they're not great at this task, and they know it -- but press them for a top-10 list, and you'll often find the right answer in it.
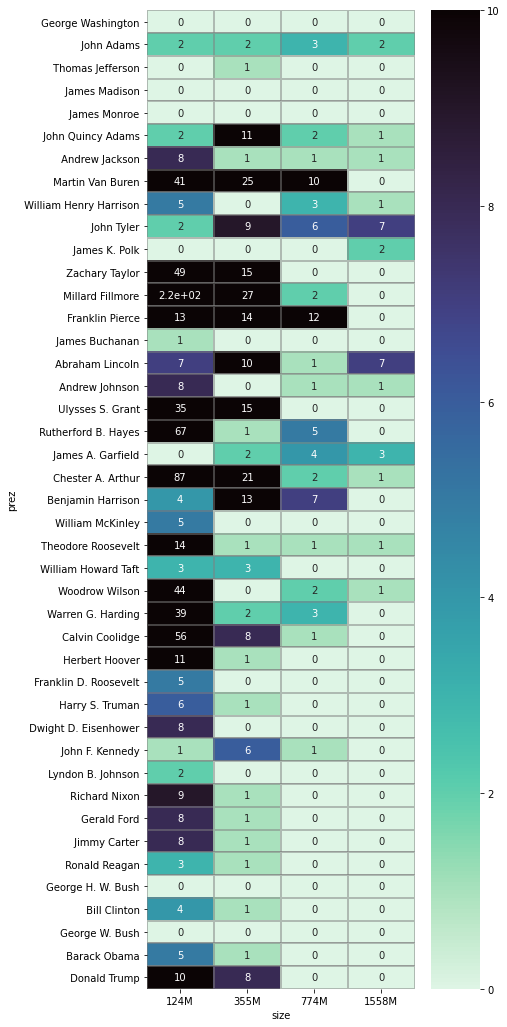
And here's the four models from the OpenAI API:


[11/26/21: Unfinished. I don't remember what the rest of this section was going to be about. Probably I was going to say that we intuitively assume models learn things like "ordering of presidents" in stages, and that we tend to interpret coarse-grained evidence in this light, when finer-grained evidence would show continuity with no stages]
6. objective metrics, or: are you smarter than a 5th-grader?
[11/26/21: Never started writing this section. It and the next section were intended to call into question the sense that "we have evidence showing GPT-3 is smarter than GPT-2," by reviewing this evidence.
This section was about changes in numeric metrics. It was going to argue, using LAMBADA as an example, that lot of the standard NLP benchmarks are testing capabilities that seem easy relative to what we know about GPT-2/3, and thus that they are not good probes of further capability growth.
The BIG-Bench project is now addressing this point, with a suite of diverse tasks, many of them very hard.]
7. getting smarter: subjective evidence?
[11/26/21: Never started writing this section. It and the previous section were intended to call into question the sense that "we have evidence showing GPT-3 is smarter than GPT-2," by reviewing this evidence.
This section was about the subjective feeling that GPT-3 is smarter. It was going to make several arguments, including:
- Subjective impressions of GPT models are distorted by an anchoring effect.
- People have a "wow moment" the first time they witness a GPT model.
- The "wow" moment looks similar in people who had it with GPT-2, vs. people who missed GPT-2 and only became aware of these models with GPT-3.
- People who see GPT-3 for the first time, without having seen GPT-2, are impressed by many of the things GPT-2 can already do, and only secondarily by new traits of GPT-3; they are also unable to tell which of these traits are which.
- In both cases, the model was advertised as being importantly bigger than earlier models; this advertisement was more aggressive in the case of GPT-3.
- So, people anchor to whichever model size they saw first, and attribute the "wow effect" to that size.
- GPT-2 was once considered scarily big and impressive, maybe even dangerously so; a year later, GPT-2 became "small" and "dumb" and the role of model-that-wows-you transferred to GPT-3; yet the impressive traits are in fact largely the same ones across models.
- Subjective impressions of GPT models are distorted by framing and salesmanship.
- Public discussion of GPT models has tended to uncritically accept OpenAI's choices of framing, e.g.
- Discussion of GPT-2 during the staged release focused heavily on the ethics of the staged release. GPT-3 is ostensibly much more powerful, but I don't remember many (any?) people asking why they didn't do a staged release.
- Discussion of GPT-3 has focused heavily on the idea that GPT-3 is not just "smarter" but somehow "differently smart," by exhibiting "meta-learning." This corresponds to OpenAI's framing but, as shown above, does not survive a close read of the evidence.
- Public discussion of GPT models has tended to uncritically accept OpenAI's choices of framing, e.g.
]
8. pancakes
[11/26/21: Never started writing this section. It was going to discuss the following idea mentioned in Sharma and Kaplan 2020:
Scaling could also end for other, more interesting reasons. For example, perhaps beyond a certain point the loss can only improve by exploring a higher dimensional data manifold. This is possible if the data manifold has a pancake-like structure, with a small width that can only be dissected by models with very large capacity.
In string theory, spacetime lives in 11 dimensions, but looks mostly like a 4-dimensional slice; orthogonal to the slice, there are tiny but importantly structured protrusions into the other dimensions.
The data manifold might look like this too, and the "tiny extra dimensions" might encode a lot of the high-level capabilities we care about for AGI. As argued in the paper, the scaling exponents are determined by the (effective) dimension of the data manifold. So, scaling might slow down when the model has mastered the lower-dimensional "width axis of the pancake," and remaining gains lie only in the higher-dimensional "height axis of the pancake."
]
31 comments
Comments sorted by top scores.
comment by janus · 2021-12-03T01:47:05.718Z · LW(p) · GW(p)
This is the best post about language models I've read in a long time. It's clear how much you have used LMs and grokked the peculiar way they operate. You've touched on many important points which I've wanted to write about or have but with less eloquence. Also I glad you liked my blog :) (generative.ink)
I definitely belong to your “enthusiasts” camp, and I agree your fourth point (loss scaling makes models "smarter" fast enough to matter) is a crux. I won't fully defend that here, but I'll do my own brain dump and share some of the thoughts that came up when reading your post.
Discontinuous jumps in capabilities
One of the reasons for my optimism/concern about scaling is that I do expect discontinuous jumps in capabilities, but not in the way you are arguing against here. I don't think discontinuous jumps will necessarily come from discontinuous improvements of the model's single step inference accuracy (though it may), but from the tasks we need it to do.
I see two big sources of discontinuity in tasks and many tasks contain both. The first is that many tasks are somewhat binary in nature. If you can't do it well enough, you basically can't do it at all. The second is that many tasks happen over multiple inferential steps where small improvements in single step accuracy translate into large changes in multistep capabilities.
The most important binary task is whether or not a model can be amplified under some given amplification strategy. As a particular example, at one OOM the model will not be able to amplification technique because it is too unreliable, even with techniques to make it more robust. Then at one OOM it suddenly will. We can observe it getting closer to this, but it can be difficult to say how close we are without getting deep into the gears of the amplification technique.
As an example of multistep inferential tasks, in some experiments collaborators and I found that larger models are dramatically better at solving math problems in multiple steps ("factored cognition"), while accuracy of solving the problem in a single step increases more continuously. Whether this is counts as a fundamentally new capability depends on your definition, but the pragmatic result is discontinuous competence. (A few of our results were eventually posted here)
We should expect to see this with various multi-token tasks which can only be executed if the model chains together many “correct” inferences. It's still a probabilistic matter, as you say: a small model would succeed with some small probability, and the large model will fail with a small probability. However, when the task requires multiple steps to all be executed correctly, the probability of the small model succeeding at the the task dwindles exponentially, magnifying the difference. The problem is more pronounced when you add feature engineering because it's often the case that irregular errors can be accounted for while frequent errors cannot.
Say the task is about 100 tokens long and for each token GPT-3 outputs an acceptable (non-fatal) prediction 90% of the time. The probability of it successfully completing the task is 0.9^100 = 0.00002656139: near 0. A model whose mistake rate is only 1% would complete the task with probability 0.99^100 = 0.36603234127 – more than one out of 3 times. This can be the difference between total impracticality and a task that can be automated with high accuracy by adding a few extra tricks. A model with 99.9% single-token accuracy succeeds most of the time (~90%). This is of course a simplification of the dynamics, but you get the point.
Mistakes
Mistakes during generation are particularly fatal for GPTs because there's no way to go back on them (unless the prompt introduces a mechanism for doing so). GPT updates on its own mistakes and elevates them to a sort of delusive “certainty” after being appended to the prompt. One way of looking at it is that the “delusions” of GPT simulacra are not the model's fault, but the fault of the autoregressive sampling process which spuriously elevates the model's mere guesses to canonical reality.
As you point out, “mistakes” can be of various types, including ones which aren't really failures of capability, and which we won't expect to go away if models scale. However, I think those problems (GPT isn't trying its best, the prompt is ambiguous, etc.) are difficult but tractable to address and will become more tractable as models scale. More powerful models are amenable to more precise control by many methods, even simple prompt programming and fine tuning. OpenAI's instruct models, for instance, are quite reliable at interpreting single-line imperative instructions “correctly” (that is, attempting to execute the instruction), whereas the base models would react to most single-line context-free instructions chaotically.
I also agree that evaluating GPTs with prompts is actually evaluating the GPT+human system, but I'm optimistic/concerned that given time we will automate the effects of this process (automated prompt programming, filtering, fine tuning in clever ways, embedding in larger systems, etc.), even if somehow we don't find ways to make pretrained LMs themselves more intentionally goal-directed.
Prompt noise and shattered cognition
This is excellently put:
I see no single, stable trove of skills being leveraged here and there as needed. I just see stretches of success and failure at imitating ten thousand different kinds of people, all nearly independent of one another, the products of barely-coupled subsystems.
Here's some simple experimental evidence to support this observation. I found that GPT-3's ability to sort a list of 5 integers was 28% with a 0-shot natural language description of the task, 50% with a 10-shot prompt, and 76% (!) accuracy with 0-shot in the style of python documentation/code.
This case cannot be explained by 'meta-learning' because the more effective prompt contains no additional information about how to solve the task. I think simply claiming GPT-3 has only learned "shallow patterns" is also insufficient because it clearly has learned the deep pattern needed to sort lists of integers like this, it just fails to access this ability under different circumstances. Does the pure natural language description and the few-shot prompt invoke a different and inferior strategy, or an imperfect/corrupted version of the same list-sorting subsystem? (I'd love to know.)
In either case, as you say, GPT does not act like it has a centralized repertoire of skills which determines how well it's able to perform tasks across prompts. This is an important intuition. Everything suggests to me that there is no core, no unified self, whether in terms of agency or capability or even knowledge. Gwern has said that he thinks of GPT-3 as an agent which wants to roleplay accurately; I disagree because I don't perceive anything as coherent or centralized as even a “puppetmaster” or “shapeshifter” that controls or roleplays simulacra. The inability of some simulacra to access knowledge and capabilities that would unambiguously make them better imitations, and which different simulacra can somehow access, contributes to my impression of GPT's subsystem disunity. However, I think there is good reason to expect this to change as these models scale.
Meta-learning
Despite my blog post, I do think GPT-3 is capable of “meta-learning” – just that this perspective is often misleading, especially for some tasks like translation. I haven't played with small models enough to say how discontinuous it is, but “meta-learning” seems necessary if any size of GPT should be able to coherently continue most long prompts. The same way GPT-3 “updates" from the task demonstrations, it clearly updates on information in a story prompt, such as the demonstrated personality of the characters, information which reveals(constrains) things about the premise, etc. The few-shot “meta-learning” capability is a special case of its general ability to continue text in the style of its training data; lists of examples are a common feature which constrains the future in systematic ways.
Learning curves
The point about LMs' learning curves looking different than those of humans is very important. The probabilistic competencies exhibited by GPT are quite different from what we see from humans.
One note: Contributing to the apparent discontinuity of human learning is that most humans are much less willing to pronounce on topics they're unsure on than GPTs (autoregressively sampled) are. We usually say/think we don't know even when it would be possible to make a probabilistic guess. That said, I do think the way GPTs learn is fundamentally different than humans, and this causes us to both over and underestimate their capabilities.
You've explained well the differences which result from GPT's incentive to imitate a broad range of disparate patterns. Another (related) difference is that whereas humans tend to build up their understanding of a world by learning “fundamentals” like object permanence first, LMs approach competence through a route which masters “superficial”, “stylistic” patterns first, learning to write in the style of famous authors before mastering object permanence. In your words from another post, it learns to run before learning to walk.
This causes some people to conclude that GPTs learns only shallow patterns. I don't think this is true; I think it only approaches the same “deep” patterns from a different trajectory. A “fake it til you make it” approach – but that doesn't mean it won't eventually “make it”. Looking at GPT-2, I could imagine thinking that however impressive the ability of large language models to write in beautiful and difficult (for a human) styles, basic object permanence will always be a problem. GPT-3 doesn't struggle much with it.
Abstract reasoning
I'm interested in knowing more about your reasons for thinking that little will come of scaled LLMs' abstract reasoning capabilities. None of the above suggests this to me. I wonder if your thoughts have changed since Codex was released after you originally drafted this post.
You said that large language models will be better at abstract reasoning in that it will be easier to get them to spit out text that sounds like it's a product of abstract reasoning (implying, perhaps, that it is in some sense not real abstract reasoning). While I agree that language models are very prone to spit out text that looks superficially more like legitimate abstract reasoning than it is, as they're particularly good at imitating surface patterns of competence, why does this imply that they cannot also learn the “real” patterns? What exactly are the "real" patterns?
Many people dismiss the legitimacy of LMs' reasoning because they just parrot probabilities from the training data. But I know you have seen its capacity for generalization. Given a good prompt as a seed, it often is able to reproduce chains of reasoning and conclusions regarding a completely unprecedented state of affairs exactly as they occurred to me. I considered these thoughts to be abstract reasoning when they happened in my mind. So what is it when GPT-3 can reliably reproduce these thoughts?
How do we apply this to Codex writing code that compiles, providing the instrumental fruits of what, if coming from a human, we would not hesitate to call abstract reasoning?
Human evaluation
I agree with your concerns about human evaluation for reasons of unreliableness, underperformance, risk of bias, etc. but I think you overstate the uselessness of the approach. Despite these very real problems, I have found almost universally that people who have spent considerable time using GPT-3 hands-on understand its capabilities and flaws significantly better than researchers who have only read benchmark and ecological evaluation papers. I will even argue that you cannot understand GPT-3 without using it.
Non-ecological benchmarks (almost all of them) are really, really bad, and most are actively misleading. Ecological evaluations, though you say they exist, are woefully inadequate for probing general intelligence for its capabilities and limits, especially in their current form. I second your call to improve them.
↑ comment by nostalgebraist · 2021-12-03T20:19:06.841Z · LW(p) · GW(p)
I'm glad you liked the post! And, given that you are an avowed "enthusiast," I'm pleasantly surprised that we agree about as many things as we do.
The second [source of discontinuous performance scaling] is that many tasks happen over multiple inferential steps where small improvements in single step accuracy translate into large changes in multistep capabilities.
Thanks for pointing out this argument -- I hadn't thought about it before. A few thoughts:
Ordinary text generation is also a multi-step process. (The token length generally isn't fixed in advance, but could be, i.e. we could define a task "write convincingly for N tokens.") So, why does generation quality scale so smoothly?
Part of the answer is that single-token success is not fully binary: there are choices that are suboptimal / "weird" without constituting instant failure. Due to the "delusion" phenomenon, weird choices can pile on themselves and lead to failure, but "weirdness" is a continuous variable so this effect can scale more gradually.
But also, part of the answer must be that generation is relatively easy, with single-token success probabilities very close to 1 even for small models.
(Why is generation easy, when it potentially includes every other task as a subtask? Well, it samples other tasks in proportion to their frequency in natural text, which≈ their relative volume in pre-training data, which≈ how easy they are for the model.)
This shows how the relevance of the argument depends on the success probabilities living in the right "transitional regime," like your 90% vs 99% vs 99.9%. More precisely, the argument is relevant at the point where, for a given task and set of model scales, the scaling moves us across this range. I suppose by continuity this has to happen somewhere for any multi-step task, which makes me wonder whether we could "induce" discontinuous scaling for any task by forcing it to be done in a multi-step way.
Last thought: this might explain why one-step arithmetic scales discontinuously. Suppose it can only be done by some sequential multi-step algorithm (and that this is not true of most tasks). Presumably the model implements the steps along the "time axis" of successive layers. The model has some failure probability at each step, and the argument goes through.
I wonder if your thoughts [on abstract reasoning] have changed since Codex was released after you originally drafted this post.
I didn't update much on Codex. Part of that was because I'd already seen this paper, which strikes me as a comparably impressive feat of abstraction in the code generation domain.
Also, the Codex model available in the API feels very much like GPT in the way it "reasons," and is roughly what I'd expect from a GPT extended to code. It has that same quality where it frequently but not predictably does the right thing, where I often see it doing many separate things right but I can't rely on it doing any one of them stably across all contexts. As with GPT, I get the best results when I stop asking "does it know X or not?" and instead ask "can I express X in a form likely to be common in the training data?"
I'm interested in knowing more about your reasons for thinking that little will come of scaled LLMs' abstract reasoning capabilities.
[...] While I agree that language models are very prone to spit out text that looks superficially more like legitimate abstract reasoning than it is [...], why does this imply that they cannot also learn the “real” patterns? What exactly are the "real" patterns?
This is going to get speculative and hand-wavey. I don't know what abstract reasoning really is, any more than anyone does. But I have some ideas :)
First, something I have noticed since I started working with these models is that my own mind contains a module much like GPT, and this module plays a role in my reasoning process.
When I reflect on my own thought processes, they often look like a game played between a GPT-like "babbler" and an evaluating "critic."
The babbler produces an interior monologue that sounds like my own voice, but (unlike when I'm speaking out loud) is only lightly conditioned at best on things like "concepts I want to express." Instead, it just . . . says words that sound like me, making some argument with the confidence I'd have if I actually believed it, but it's not trying to express an idea I already have -- it's just generating text that sounds like me.
I let the babbler run for a while, and then I step back and assess the monologue, asking "does this make sense? is this really a new idea? does this prove too much? can I think of counterexamples?" Like generating code and then checking if it compiles. Most babbler-monologues are rejected by the critic, at which point the babbler tries again, conditioned (in some way I don't understand) on the critic's rejection.
Most of my actually-believed-ideas originated in this game, I think. Also, I often do a short-range, purely linguistic variant of this when I'm writing: I ask the babbler for the next word or phrase, and there are several rounds of "no that doesn't work" before I pick one. Even my mathematical reasoning is often like this, though it also involves other babbler-like modules that eg generate mental imagery which can be interpreted (by the critic) as expressing a mathematical argument.
Now, I highly doubt this is the only way that one can do abstract reasoning. (I don't even think that all humans do it like this.) However, this is the source of my intuitions about the components involved in "true abstract reasoning" and how it differs from what LMs tend to do.
When I do "true abstract reasoning" as described above, there is a distinction between timesteps of candidate generation (inner loop), timesteps of candidate evaluation (outer loop), and timesteps of actually selecting the next idea (increments on some passes of the outer loop but not others). This seems important for avoiding "delusive" effects.
I have to run the babbler for a while to even get a coherent idea that's possible to assess. By that point, the babbler is already conditioning on its earlier output in a self-deluding way. Unlike in GPT, though, these earlier outputs are not irrevocably written in stone at the moment we receive the later outputs; the critic is free to reject the entire sequence. With GPT, by the time it would be possible to notice "hey, I'm making a bad argument," it's already ... making a bad argument, and there's no going back.
(I think there's an analogy here to AlphaZero/MuZero's value head vs. its MCTS rollouts, where GPT is like the value head / "intuitive hunches," lacking the slower search wrapper.)
Of course, in principle, you could imagine bundling this entire procedure inside an LM. Indeed, any sufficiently good LM would eventually have to solve the problems this procedure is designed to solve. Why don't I expect transformer LMs to develop this structure internally?
One reason: the existence of my babbler seems like (weak) evidence that it's better to use an LM inside a bigger non-LM algorithm.
My babbler itself feels very much like a likelihood-trained causal generative model, with the same virtuosity at surface mimicry, and the same lack of conditioning latents besides its own output. I suspect that making these kinds of models comes naturally to the cerebral cortex, and that if the brain could just implement reasoning end-to-end with such a model, it would have done it that way.
A second reason is ... okay, this is a whole separate point and the comment's already long. I'll try to make this brief.
I think transformer LMs do a lot of what they do through a kind of "compressed memorization" of very large amounts of data. Early on, they learn many different ways that text is regular; some of this may look like "truly learning (eg syntactic) rules." This low-level knowledge allows them to store training sequences in a vastly compressed form. Then, a lot of what they do in training is actual memorization of the data, in a compressed and noisy/interleaved form. Inference looks like mapping the input to the compressed space, and then doing a shallow-ish ensemble in that space over a massive number of texts the input is "reminiscent of" along various dimensions. The huge model capacity allows for a huge ensemble, so many superficial patterns cancel out in the ensemble, while deeper patterns stack.
This perspective is inspired by the way logit lens [LW · GW] looks in later layers, by this paper which is similar to logit lens, and also by work like this showing you can extract exact strings from trained models that were only seen a few times in training.
The key point here is that you can compress things you can't yet abstractively understand, using easier things you do understand. I can't use abstractive summarization to compress (say) Grothendieck's EGA, since I don't understand it . . . but I can still run gzip on it, and that goes a long way! Hence, the frontier of the model's apparent abstractive capability will outrun its actual abstractive capability: this frontier consists of texts the model can't compress via facility with their content, but can simply memorize in bulk using easier compression.
In something like your list sorting example, I suspect the model doesn't "have" an internal list sorter that looks anything like an algorithm. Instead, it has heavily compressed memories of many actual programming tutorials that included short example lists in unsorted and sorted form, and taking an average over these will usually "sort" a short list of small numbers -- with help from low-level abstract operations like "greater than over small numbers," but without any idea that a list can be arbitrary length / can contain any ordered type.
(EDIT to clarify: the context-dependence and flakiness of the capability is how we can tell it's coming from the compressed ensemble. Contrast with the reliability of something like English syntax, which I believe is part of the compressor itself. This is my distinction between abstraction that's "real" and "fake")
Anyway, I think transformers are very good at this kind of compressive memorization -- but not nearly as good at doing other kinds of computational work, like search or (obviously?) recursion. Like, whenever I think about how to "program" some routine using attn+FFs, I tend to despair. Even simple things often to be spread across >1 layer/"step" or >1 head, and the number of heads/layers in huge models feels tiny relative to the diversity of abstraction we expect out of them. (See this paper for some actual transformer "programs.")
This is hand-wavey, but my intuition is that the "right abstractions for abstraction" are hard to fit in a transformer or similar modern NN, while memorizing instances of abstraction-use is far cheaper. And yes, eventually, at large enough scale, the models will have to do the right thing or they'll stop progressing. But there is so much more left to smoothly learn with memorization that I think this architectural deficit will be invisible for a long time, over which LMs will continue to (unreliably) imitate abstraction better and better.
↑ comment by janus · 2021-12-09T20:03:08.367Z · LW(p) · GW(p)
One reason we agree on many object-level facts but have different takeaways is that we have different desiderata for what GPT is supposed to do in the limit. I agree that many of the problems you discuss are fundamental to the way GPT is trained and how it works, but I generally feel these problems don't need to be solved directly in order to use GPT to build AGI. I see GPT as the _seed_ for a future AGI system built off of or around it.
I see the big crux is how much "compressed memorization" will extrapolate to general intelligence vs. begin to show cracks as we ask it for more and more advanced and general one-step deductions. It would be worth coming up with some specific claims about how we expect future systems to act to differentiate our two perspectives (including at the level of internals). Probably this is useful to start on my end because I have higher expectations for performance. Unfortunately I'm very adverse to talking about _how_ I would amplify GPT by extending it or wrapping it in a larger system, and I see steps like that as key to unlocking its capabilities.
Your idea about multi-step deduction happening over multiple layers makes a lot of sense. You brought up an experiment in the Eleuther discord I think would be a great idea to try. We could train several models to see if tasks that require a sequence of discrete steps are unusually sensitive to network depth rather than scaling with parameter count alone.
I agree about your insights about abstract reasoning as babble and prune, although this definitely isn't the only way I reason abstractly. I babble and prune especially when I am writing (on the word/sentence/paragraph level), and I babble and prune as a part of the search process when I am trying to come up with a plan or navigate through a math proof. But when I am talking I am able to fluidly reason towards my goal with little to no plan ahead of ahead of time. I work collaboratively so much of my abstract thinking is out loud. If babble/prune is going on when I talk, it is happening at a level below my awareness.
These rollouts are not always complete, as I often need to attack problems from multiple angles before I've fully understood them. But the individual rollouts look like abstract reasoning to me, just as they do (can) in GPT-3. I look at individual rollouts and think: That's general intelligence. If something could reason as well or more powerfully than I can in an individual rollouts, it is the seed of an AGI.
I also often have moments of great insight where I seem to understand a full chain of thought almost instantly. The delay comes from my inability to communicate/record it quickly. I can also use abstract reasoning in visual space (e.g. figuring out a geometric proof). In these cases I often seem to have access to a causal model that I can examine and conclude things from directly.
comment by Ben Pace (Benito) · 2021-11-27T04:16:08.672Z · LW(p) · GW(p)
Man, I learned so much about language models from this post. Thanks so much for publishing it, even if it is unfinished.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-01-06T08:15:23.000Z · LW(p) · GW(p)
Curated. This might be my favorite thing I've read about GPT-3. Ideas about how bigger models might just be finding the same knowledge more effectively, or how it's sensible for longer but then makes the same old-dumb mistakes at the end, really help me understand what GPT-3 is and what it isn't. I wish I had time to write a more thoughtful curation notice, but I'll just repeat I'm very glad you wrote this post, I'd be much more conceptually malnourished about modern AI without it.
comment by calef · 2021-11-27T02:59:02.206Z · LW(p) · GW(p)
In defense of shot-ness as a paradigm:
Shot-ness is a nice task-ambiguous interface for revealing capability that doesn’t require any cleverness from the prompt designer. Said another way, If you needed task-specific knowledge to construct the prompt that makes GPT-3 reveal it can do the task, it’s hard to compare “ability to do that task” in a task-agnostic way to other potential capabilities.
For a completely unrealistic example that hyperbolically gestures at what I mean: you could spend a tremendous amount of compute to come up with the magic password prompt that gets GPT-3 to reveal that it can prove P!=NP, but this is worthless if that prompt itself contains a proof that P!=NP, or worse, is harder to generate than the original proof.
This is not what if “feels like” when GPT-3 suddenly demonstrates it is able to do something, of course—it’s more like it just suddenly knows what you meant, and does it, without your hinting really seeming like it provided anything particularly clever-hans-y. So it’s not a great analogy. But I can’t help but feel that a “sufficiently intelligent” language model shouldn’t need to be cajoled into performing a task you can demonstrate to it, thus I personally don’t want to have to rely on cajoling.
Regardless, it’s important to keep track of both “can GPT-n be cajoled into this capability?” as well as “how hard is it to cajole GPT-n into demonstrating this capability?”. But I maintain that shot-prompting is one nice way of probing this while holding “cajoling-ness” relatively fixed.
This is of course moot if all you care about is demonstrating that GPT-n can do the thing. Of course you should prompt tune. Go bananas. But it makes a particular kind of principled comparison hard.
Edit: wanted to add, thank you tremendously for posting this—always appreciate your LLM takes, independent of how fully fleshed they might be
comment by Ben Pace (Benito) · 2023-01-07T02:10:06.699Z · LW(p) · GW(p)
This is a post that gave me (an ML noob) a great deal of understanding of how language models work — for example the discussion of the difference between "being able to do a task" and "knowing when to perform that task" is one I hadn't conceptualized before reading this post, and makes a large difference in how to think about the improvements from scaling. I also thought the characterization of the split between different schools of thought and what they pay attention to was quite illuminating.
I don't have enough object-level engagement for my recommendation to be much independent evidence, but I still will be voting this either a +4 or +9, because I personally learned a bunch from it.
comment by evhub · 2021-12-09T01:05:48.113Z · LW(p) · GW(p)
It's totally possible to do ecological evaluation with large LMs. (Indeed, lots of people are doing it.) For example, you can:
- Take an RL environment with some text in it, and make an agent that uses the LM as its "text understanding module."
- If the LM has a capacity, and that capability is helpful for the task, the agent will learn to elicit it from the LM as needed. See e.g. this paper.
- Just do supervised learning on a capability you want to probe.
I don't understand why you think this would actually give you an ecological evaluation. It seems very plausible to me for a LM to have a capability and yet for the RL/SL/etc. technique that you're using to not be able to effectively access that capability. Do you think that's not very plausible? Or do you just think that this is a less-biased underestimate when compared with other evaluation techniques?
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-12-09T01:24:42.144Z · LW(p) · GW(p)
It will still only provide a lower bound, yes, but only in the trivial sense that presence is easier to demonstrate than absence.
All experiments that try to assess a capability suffer from this type of directional error, even prototype cases like "giving someone a free-response math test."
- They know the material, yet they fail the test: easy to imagine (say, if they are preoccupied by some unexpected life event)
- They don't know the material, yet they ace the test: requires an astronomically unlikely coincidence
The distinction I'm meaning to draw is not that there is no directional error, but that the RL/SL tasks have the right structure: there is an optimization procedure which is "leaving money on the table" if the capability is present yet ends up unused.
comment by Ben Pace (Benito) · 2023-01-07T01:24:35.040Z · LW(p) · GW(p)
However, we should not take this question so lightly. A yes answer would "complete the circuit" of the enthusiast's argument -- "turn it on" as a live concern. A no answer would leave the argument in limbo until more evidence comes in.
So, let's assess the state of the evidence.
Such a weird reason (to me) for not taking a question lightly. Are different standards of evidence are required for conclusions who we care about? The bayesian math of probability theorem does not have a term for expected utility.
Of course, it makes sense to invest more into getting a robust answer to an important question like this, but still, I think lightness is a core rationalist virtue, and shouldn't be abandoned because a question is important.
comment by Maybe_a · 2022-12-10T12:59:01.057Z · LW(p) · GW(p)
It's a fine overview of modern language models. Idea of scaling all the skills at the same time is highlighted, different from human developmental psychology. Since publishing 500B-PaLM models seemed to have jumps at around 25% of the tasks of BIG-bench.
Inadequacy of measuring average performance on LLM is discussed, where a proportion is good, and rest is outright failure from human PoV. Scale seems to help with rate of success.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-02-16T22:09:58.219Z · LW(p) · GW(p)
A small takeaway from this is the value of using better descriptions of tasks when reporting results. For example, if the data about failures had been presented as a violin plot rather than an average then it would be easy to see the difference between a distribution consisting of middling results vs a bimodal distribution of mostly-successes and complete-failures.
comment by sid (sidhire) · 2022-01-03T17:05:37.917Z · LW(p) · GW(p)
There is some point at which it’s gaining a given capability for the first time though, right? In earlier training stages I would expect the output to be gobbledygook, and then at some point it starts spelling out actual words. (I realize I’m conflating parameters and training compute, but I would expect a model with few enough parameters to output gobbledygook even when fully trained.)
So my read of the de-noising argument is that at current scaling margins we shouldn’t expect new capabilities—is that correct? Part of the evidence being that GPT-3 doesn’t show new capabilities over GPT-2. This also implies that capability gains are all front-loaded in the lower numbers of parameters.
As an aside that people might find interesting: this recent paper shows OpenAI Codex succeeding on college math problems simply once prompted in a particular way. So in this case the capability was there in GPT-3 all along…we just had to find it.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2022-01-03T17:37:18.845Z · LW(p) · GW(p)
There is some point at which it’s gaining a given capability for the first time though, right? [...]
So my read of the de-noising argument is that at current scaling margins we shouldn’t expect new capabilities—is that correct?
Not quite.
If you define some capability in a binary yes-no way, where it either "has it" or "doesn't have it" -- then yes, there are models that "have it" and those that "don't," and there is some scale where models start "having it."
But this apparent "switch flip" is almost always an artifact of the map, not a part of the territory.
Suppose we operationalize "having the capability" as "scoring better than chance on some test of the capability." What we'll find is that models smoothly move from doing no better than chance, to doing 1% better than chance, to doing 2% better . . . (numbers are meant qualitatively).
If we want, we can point at the model that does 1% better than chance and say "it got the capability right here," but (A) this model doesn't have the capability in any colloquial sense of the term, and (B) if we looked harder, we could probably find an intermediate model that does 0.5% better, or 0.25%...
(By the time the model does better than chance at something in a way that is noticeable to a human, it will typically have been undergoing a smooth, continuous increase in performance for a while already.)
comment by MondSemmel · 2021-11-30T07:17:48.520Z · LW(p) · GW(p)
Thanks for posting this!
Regarding the prompts problem: Is there a way to reverse a language model so it predicts preceding tokens, rather than subsequent ones? Then you could feed it the results from a standard subsequent-tokens-predicting LM, and ask it to predict which prompt generated it. (Probably something like this is already being done, and I just don't know the term for it.)
(Technically, I suppose one could also train a forward-looking LM on a dataset with reversed strings, then feed it prompts of reversed strings, to make it predict preceding tokens. So I guess the remaining question is whether one can get the same behavior without retraining the LM.)
Replies from: gwern, nostalgebraist↑ comment by gwern · 2021-11-30T19:16:53.223Z · LW(p) · GW(p)
(Technically, I suppose one could also train a forward-looking LM on a dataset with reversed strings, then feed it prompts of reversed strings, to make it predict preceding tokens. So I guess the remaining question is whether one can get the same behavior without retraining the LM.)
Yes, that works. This is how models like CogView can go both ways with the reverse caption trick, akin to projectors in GANs for reversing images to latents (see also Decision Transformer). Since it's just a sequence of tokens concatenated, the model and training is indifferent to whether you trained it with the text caption tokens first and then image tokens (to generate an image based on text) or image tokens and then text captions (to train a captioner). Apparently it costs very little training to finetune the reverse direction, the model already has most or all of the necessary knowledge (which makes sense) and just needs to rejigger its input handling. It also gives you a way to self-critique image generation: if you train CogView with a reverse captioning version, instead of calling out to CLIP to gauge quality of (text,generated-image) pairs, you can simply run the generated-image's tokens through the reverse CogView and calculate the likelihood of the text caption token by token & sum - if the total likelihood of the text seems strange based on the generated images, then it wasn't a good generated image.
No one's done this with text models that I know of. Probably everyone is too keen on doing complicated prompt-finetuning methods of various kinds to do gradient ascent on the model in various ways to optimize the inputs and weights/biases to bother with trying reversing. I'd predict that trying to infer the necessary prompt with the reversing trick wouldn't work for small models anyhow, and would be a waste of time compared to directly editing/controlling the model.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-11-30T21:01:57.767Z · LW(p) · GW(p)
I'd predict that trying to infer the necessary prompt with the reversing trick wouldn't work for small models anyhow, and would be a waste of time compared to directly editing/controlling the model.
Also, even if one had a reversed model available, it would not be trivial to generate useful prompts with it.
The goal is (roughly) to find a prompt that maximizes . But the reversed model gives you
The answer is a constant so we can ignore it, but is problematic: we don't care about the likelihood of the prompt, since we plan to condition on it.
Moreover, we need a way to communicate what the prompt is supposed to mean, and a single answer isn't a sufficient latent for that. (Consider "...2002? Barack Obama" "who was the Illinois State senator for the 13th district in the year...")
Prompt-finetuning resolves the ambiguity by averaging over multiple answers, which could work here, but would require an unusual sampling technique (average likelihood over multiple prompts?).
Replies from: gwern↑ comment by gwern · 2021-12-01T00:12:41.294Z · LW(p) · GW(p)
My intuition is that it would Just Work for large smart models, which are easy to prompt and few-shot well: like the 'French->English' prompt, if you reversed that and you kept getting 'French->English' as your prompt across multiple examples, well, that's obviously a good prompt, whatever the objective likelihood of text starting with 'French->English' may be. And to the extent that it didn't work, it would either be relatively 'obvious' what the reversed outputs have in common so you could try to come up with a generic prompt ("who was the X State senator for the nth district in the year MMMM?"), or it would at least be a good starting point for the gradient ascent-type procedures (in the same way that with GAN projectors you often treat it as a hybrid: a quick projection of amortized computation into roughly the right latent z and then gradient ascent to clean it up) and you get a bunch of reversed prompts as seeds for optimization to find the best one or maximize diversity for some other reason.
↑ comment by nostalgebraist · 2021-11-30T17:33:48.080Z · LW(p) · GW(p)
There is no known way to "reverse" an LM like that.
(Well, besides the brute force method, where you generate a preceding token by looping over all possible values for that token. GPT's vocab has ~50k tokens, so this is ~50k slower than forwared sampling.)
There are some LMs that naturally work in both directions. Namely, masked language models (eg BERT), as opposed to causal language models (eg GPT). Rather than taking a substring as input, masked language models take a complete string, but with some positions randomly masked or corrupted, and it's trained to undo these changes.
However, these models are mostly used for things other than text generation; it's possible to make them write text, but the resulting text tends to be lower-quality than what you can get from a comparably sized GPT.
comment by Lone Pine (conor-sullivan) · 2021-11-30T04:42:34.541Z · LW(p) · GW(p)
Where does the concept of "shot" originate from? How old is the term (in this usage)? Do we know who first used it?
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-11-30T18:28:33.452Z · LW(p) · GW(p)
I don't know.
I poked around on Google Scholar for a bit, trying to answer these questions, and managed to learn the following:
- The term "few-shot learning" seems to have become widespread sometime around 2017.
- The term is used in a bunch of papers from 2017 (example, another example)
- Before 2017, it's hard to find usage of "few-shot" but easy to find usage of "one-shot." (Example, example)
- The "one-shot" term dates back at least as far as 2003. Work before 2010 tends to lump what we would call "one-shot" and "few-shot" into a single category, as in this paper (2006) and this one (2003).
↑ comment by Lone Pine (conor-sullivan) · 2021-12-01T06:36:35.690Z · LW(p) · GW(p)
Thanks for looking into it! It's really interesting to see computer vision research from before the deep learning revolution.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2021-12-03T17:18:17.351Z · LW(p) · GW(p)
Here's a 1984 paper that uses the term "one-shot", apparently in the same sense as today.
A 1987 paper mentions that
Learning can be achieved by a one-shot learning process (in which each prototype is presented only once) as follows
and then after some math notes that
Several authors [2] have proposed the latter relation for one-shot learning, taking into account all second-order interactions, and have investigated the storage capacity, size of the basins of attraction, etc., for random uncorrelated patterns.
suggesting that there was already moderately active discussion of the term in the eighties.
comment by Karl Brisebois (karl-brisebois) · 2021-11-28T14:52:52.017Z · LW(p) · GW(p)
The fact that language models inevitably will end up contradicting themselves is due to the fact that they have finite memory. Asking them not to contradict themselves over sufficiently large amount of text is asking for the impossible: they're figuring out what to output as the current token by looking at only the last n tokens, so if the contradicting fact lies further back than that there is no way for the model to update on that. And no increase in the size of the models, without fundamental architecture change, will fix that problem.
But architecture changes to deal with that problem might be coming...
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-11-28T18:15:10.682Z · LW(p) · GW(p)
When I talk about self-contradiction in this post, I'm talking about the model contradicting itself in the span of a single context window. In other words, when the contradicting fact is "within the last n tokens."
Replies from: Darceycomment by Sandi · 2022-05-03T21:47:36.631Z · LW(p) · GW(p)
Epistemic status: I'm not familiar with the technical details of how LMs work, so this is more word association.
You can glide along almost thinking "a human wrote this," but soon enough, you'll hit a point where the model gives away the whole game. Not just something weird (humans can be weird) but something alien, inherently unfitted to the context, something no one ever would write, even to be weird on purpose.
What if the missing ingredient is a better sampling method, as in this paper? To my eye, the completions they show don't seem hugely better. But I do buy their point that sampling for high probability means you get low information completions.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2022-05-03T22:24:41.612Z · LW(p) · GW(p)
I've tried the method from that paper (typical sampling), and I wasn't hugely impressed with it. In fact, it was worse than my usual sampler to a sufficient extent that users noticed the difference, and I switched back after a few days. See this post and these tweets.
(My usual sampler one I came up with myself, called Breakruns. It works the best in practice of any I've tried.)
I'm also not sure I really buy the argument behind typical sampling. It seems to conflate "there are a lot of different ways the text could go from here" with "the text is about to get weird." In practice, I noticed it would tend to do the latter at points where the former was true, like the start of a sample or of a new paragraph or section.
Deciding how you sample is really important for avoiding the repetition trap, but I haven't seen sampling tweaks yield meaningful gains outside of that area.
Replies from: Sandicomment by greghb · 2022-01-06T22:19:01.627Z · LW(p) · GW(p)
This part really resonates:
suppose most of the abilities we care about, when we use the term "AGI," are locked away in the very last tiny sliver of loss just above the intrinsic entropy of text. In the final 0.00[...many extra zeros...]1 bits/character, in a loss difference so tiny we'd need vastly larger validation sets to for it to be distinguishable from data-sampling noise.
as does the ecological "road not taken". But I think part of this puzzle is that, in fact, there aren't adequate ecological measures of linguistic competence, vs. tasks that may be difficult but are always narrow and you never feel good about them being difficult for the right reasons. There are certainly no artificial environments where realistic linguistic competence is clearly needed to win. You hear things like, "but perplexity correlates with human judgement!" but they are always weak and unsatisfying. I think many NLP/DL researchers believe this, and just don't know what to do about it. The road is not readily taken. I think this is a big part of why discussions of LM performance can be so unsatisfying.
comment by Daniel_Eth · 2021-12-28T00:29:12.524Z · LW(p) · GW(p)
Play with GPT-3 for long, and you'll see it fall hard too.
...
This sample is a failure. No one would have written this, not even as satire or surrealism or experimental literature. Taken as a joke, it's a nonsensical one. Taken as a plot for a film, it can't even keep track of who's alive and who's dead. It contains three recognizable genres of writing that would never appear together in this particular way, with no delineations whatsoever.
This sample seems pretty similar to the sort of thing that a human might dream, or that a human might say during/immediately after a stroke, a seizure, or certain types of migraines. It's clear that the AI is failing here, but I'm not sure that humans don't also sometimes fail in somewhat similar ways, or that there's a fundamental limitation here that needs to be overcome in order to reach AGI.
The first time you see it, it surprises you, a crack in the floor... Eventually, you no longer picture of a floor with cracks in it. You picture a roiling chaos which randomly, but regularly, coalesces into ephemeral structures possessing randomly selected subsets of the properties of floors.
^I guess the corollary here would be that human minds may also be roiling chaos which randomly coalesce into ephemeral structures possessing properties of floors, but just are statistically much more likely to do so than current language models.