GPT-3: a disappointing paper
post by nostalgebraist · 2020-05-29T19:06:27.589Z · LW · GW · 43 commentsContents
Part 1 1.1: On GPT-3's mundanity 1.2: On "few-shot learning" 1.3: On benchmarks 1.4: On annoyance Part 2 2.1: On "few-shot learning," again 2.2: On novel words 2.3: On abstract reasoning None 43 comments
[Note: I wrote this post in late May 2020, immediately after the GPT-3 paper was released.]
This post is a compilation of two posts I recently made on tumblr.
For context: I have been an enthusiastic user of GPT-2, and have written a lot about it and transformer models more generally. My other writing on this topic includes human psycholinguists: a critical appraisal [LW · GW] and "the transformer ... "explained?" See also my tumblr bot, which uses GPT-2 as a core component.
Part 1
argumate said:
@nostalgebraist, give us the goss on how GPT-3 compares with GPT-2!
I haven’t read the paper super carefully yet, but I am pretty sure of the following:
1.1: On GPT-3's mundanity
“GPT-3″ is just a bigger GPT-2. In other words, it’s a straightforward generalization of the “just make the transformers bigger” approach that has been popular across multiple research groups since GPT-2.
This excerpt captures this pretty clearly:
Several lines of work have focused on increasing parameter count and/or computation in language models as a means to improve generative or task performance. […] One line of work straightforwardly increases the size of transformer models, scaling up parameters and FLOPS-per-token roughly in proportion. Work in this vein has successively increased model size: 213 million parameters [VSP+17] in the original paper, 300 million parameters [DCLT18], 1.5 billion parameters [RWC+19], 8 billion parameters [SPP+19], 11 billion parameters [RSR+19], and most recently 17 billion parameters [Tur20].
The first two papers mentioned here are the original transformer for machine translation (VSP+17) and BERT (DCLT18). The parameter count doesn’t actually increase that much between those two.
The third one (RWC+19) is GPT-2. The parameter counts jumps up 5x there. Arguably the point of the GPT-2 paper was “it sounds dumb and too easy, but amazing things happen if you just make a transformer bigger” – and this “GPT-3″ paper is making the same point with bigger numbers.
"GPT-3" is a transformer with 175 billion parameters. It's another big jump in the number, but the underlying architecture hasn't changed much.
In one way this is a fair thing to call “GPT-3″: it’s another step in the new biggening tradition which GPT-2 initiated.
But in another way it’s pretty annoying and misleading to call it “GPT-3.” GPT-2 was (arguably) a fundamental advance, because it demonstrated the power of way bigger transformers when people didn’t know about that power. Now everyone knows, so it’s the furthest thing from a fundamental advance. (As an illustration, consider that their new big model deserves the title “GPT-3″ just as much, and just as little, as any of the last 3 big models they mention in that paragraph.)
1.2: On "few-shot learning"
The paper seems very targeted at the NLP community, which I mean in almost a wholly negative way. (Despite being part of the NLP community, I guess.)
The GPT-2 paper argued that language models (text predictors) could do well, or in some cases “at least not terribly,” at the specialized tasks used as NLP benchmarks – even without being told anything about those tasks. This was sort of neat, but mostly as a demonstration of the language model’s power.
The “zero-shot” learning they demonstrated in the paper – stuff like “adding tl;dr after a text and treating GPT-2′s continuation thereafter as a ‘summary’” – were weird and goofy and not the way anyone would want to do these things in practice. It was more cool as a demonstration that sufficiently good language models could “do it all,” even things they weren’t intended for; the point wasn’t that they were world-class great at these tasks, the point was the gap between their performance and their low level of preparation. Kinda like a child prodigy.
In the GPT-3 paper, they’ve introduced a new (…ish? maybe?) way for language models to be good at the standard benchmarks. Now it’s about how they can “figure out” what they’re supposed to be doing across the course of a text, i.e. instead of prompting the model with one thing like
Q: What is the capital of France?
A:
they instead prompt it with several, like
Q: What is the capital of France?
A: Paris
Q: What is the capital of Spain?
A: Madrid
Q: What is the capital of Lithuania?
A: Vilnius
Q: What is the capital of Brazil?
A:
The NLP-community-relevant point of “GPT-3″ is that language models can do much better on the standard benchmarks than we thought, via this kind of multi-prompting and also via even more biggening. Putting those two changes together, you can even even beat the state of the art on a few tasks (of many).
I can imagine someone viewing this as very important, if they thought it showed an ability in transformer LMs to “pick things up on the fly” in an extremely data-efficient, human-like way. That would be relevant to some of Gary Marcus’ concerns [LW · GW].
But the paper seems totally, weirdly uninterested in the “learning on the fly” angle. Their paper has many, many figures graphing performance against papemeter count – bigger is better yet again – but I can only find one figure graphing performance against their parameter K, the number of distinct task examples in the prompt (K is 1 and 4 in the two capitals examples).
[It turns out there’s another one I missed on my first read – Fig. 1.2 on page 4. I discuss this in Part 2 below.]
And that figure is, uh, not encouraging:
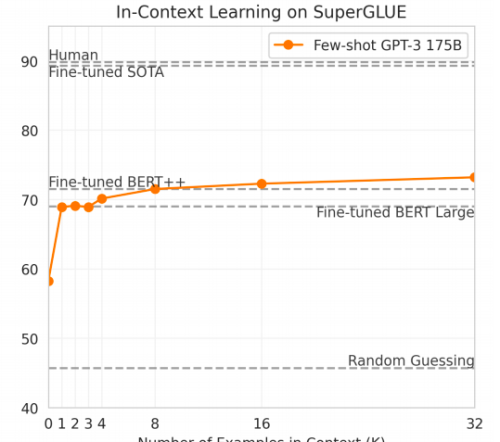
They do better with one task example than zero (the GPT-2 paper used zero), but otherwise it’s a pretty flat line; evidently there is not too much progressive “learning as you go” here.
(Oddly, the caption for this figure explains these are dev set results so not directly comparable to the test set results given as horizontal lines – which doesn’t stop them from plotting them! Elsewhere, they do report test set results for SuperGLUE, but only for K=32. Also, I’m not a fan of this plot’s lack of error bars.)
1.3: On benchmarks
Instead, their interest is almost completely in how good they can get on the benchmarks in absolute terms.
This is why I say it’s aimed at the NLP community: these are the metrics that whole community measures itself against, so in a trivial sense the community “has to” find these results interesting. But by now, this starts to feel like Goodhart’s Law.
The reason GPT-2 was so cool wasn’t that it did so well on these tasks. It was that it was a really good language model that demonstrated a new overall understanding of language. Coercing it to do well on standard benchmarks was valuable (to me) only as a flamboyant, semi-comedic way of pointing this out, kind of like showing off one’s artistic talent by painting (but not painting especially well) with just one’s non-dominant hand.
GPT-2 isn’t cool because it’s good at “question answering,” it’s cool because it’s so good at everything that it makes caring about “question answering” per se feel tiny, irrelevant.
The transformer was such an advance that it made the community create a new benchmark, “SuperGLUE,” because the previous gold standard benchmark (GLUE) was now too easy.
GPT-3 is so little of an advance, it doesn’t even do that well at SuperGLUE. It just does okay with its dominant hand tied behind its back.
“No, my 10-year-old math prodigy hasn’t proven any new theorems, but she can get a perfect score on the math SAT in under 10 minutes. Isn’t that groundbreaking?”
Sort of? Not especially?
1.4: On annoyance
The more I think about this paper, the more annoying it is. Transformers are extremely interesting. And this is about the least interesting transformer paper one can imagine in 2020.
Part 2
2.1: On "few-shot learning," again
On my first read, I thought there was only one plot showing how performance varies with K (number of few-shot samples), but I missed the one very early in the paper, Fig 1.2 on p. 4.
That plot is more impressive than the other one, but doesn’t change my impression that the authors are not very interested in showing off “progressive learning” over the course of a text.
The argument they’re trying to make with Fig 1.2 is that more progressive learning happens with bigger models, and hence that their overall strategy – “use big models + few-shot learning to get good scores on benchmarks” – benefits from an interaction effect above and beyond the independent effects of its two parts (big models, few-shot learning).
Again, this is interesting if you care about scores on NLP benchmarks, but I have trouble seeing much qualitative significance for overall language understanding.
2.2: On novel words
One of their experiments, “Learning and Using Novel Words,“ strikes me as more remarkable than most of the others and the paper’s lack of focus on it confuses me. (This is section 3.9.5 and table 3.16.) The task is closely related to the Wug test – it’s the kind of thing Gary Marcus focused on in his critique of GPT-2 – and looks like this:
[Human prompt] To do a “farduddle” means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
[GPT-3 continuation] One day when I was playing tag with my little sister, she got really excited and she started doing these crazy farduddles.
This is the sort of task that developmental linguists study in human children, and which past NLP models have had trouble with. You’d think a success on it would deserve top billing. The authors apparently report a success here, but treat it as an unimportant sideshow: they say they tried it 6 times and got 6 successes (100% accuracy?!), but they apparently didn’t consider this important enough to try the same thing on a larger sample, compute a real metric, show variance w/r/t parameters, etc. Meanwhile, they did those things on something like 40 other tasks, mostly far less interesting (to me). Confusing!
2.3: On abstract reasoning
In addition to the usual NLP benchmarks, they tried some “synthetic or qualitative” tasks (section 3.9). Their stated goal with these is to clarify the role the actual learning in “few-shot learning,” separating it from mere familiarity with similar-looking text:
One way to probe GPT-3’s range of abilities in the few-shot (or zero- and one-shot) setting is to give it tasks which require it to perform simple on-the-fly computational reasoning, recognize a novel pattern that is unlikely to have occurred in training, or adapt quickly to an unusual task.
The “synthetic or qualitative” tasks are:
- various forms of simple arithmetic (like “add two 2-digit numbers”)
- various anagram/reversal/etc tasks operating on the individual letters of words
- SAT analogies
This line of work feels insufficiently theorized, and thus hard to interpret.
Consider the arithmetic tasks. Let’s grant the authors’ premise that the model has not just memorized some lookup table for arithmetic problems – it’s really “doing the problems” on the fly. Then, there are 2 things the model could be doing here (probably some of each simultaneously):
- It might have developed a real internal model of arithmetic from seeing many related numbers in training texts, and is applying this model to do the problems like you or I would
- It might have developed some generic reasoning capability for arbitrary abstract tasks, which can handle arithmetic as a particular case of a much more generic class of problems (e.g. it could also pick up various “fake arithmetics” where +, -, etc have non-standing meanings, if appropriately prompted)
Insofar as #1 is happening, the multiple prompts of few-shot learning shouldn’t matter: if the model knows how real (not fake) arithmetic works because it’s seen it in text, then additional examples don’t help “locate the task.” That is, if it has only learned to do real arithmetic, it shouldn’t need to be told “in this task the + symbol has the standard meaning,” because its ability depends on that assumption anyway.
So, if we’re mostly seeing #1 here, this is not a good demo of few-shot learning the way the authors think it is.
Insofar as #2 is happening, the few-shot prompts do matter: they “locate the meanings” of the symbols in the large space of possible formal systems. But #2 is wild: it would represent a kind of non-linguistic general intelligence ability which would be remarkable to find in a language model.
I really doubt this is what the authors are thinking. If they think language models are fully general reasoners, why not highlight that? The abstract reasoning capacity of transformers has already been more clearly probed without the confounding aspects of natural language, and a priori there are few reasons to think a very large language-specific model should develop strong abilities here (while there are a priori reasons to think the abilities are subtle forms of text recognition/memorization the authors’ methodology was not able to detect).
My best guess is that the authors imagine a factorization of the task into “knowing how to do it” and “knowing we are doing it right now.” Training on text teaches you how to do (real) arithmetic, and the few-shot prompts tell you “right now we are doing (real) arithmetic, not some other thing you know how to do.”
But arithmetic is a really bad choice if you want to probe this! The authors use K=50 here, meaning they give the model 50 correct examples of simple math problems to let it “locate the task.” But no one who can do this task should need 50 examples of it.
What information is conveyed by example #50 that wasn’t already known by example #49? What are we ruling out here? Trollish formal systems that look like addition 98% of the time? “Addition, except ‘52′ actually means ‘37′ but everything else is the same?” Do we have to rule this out when you should have (and the model must have) a strong prior towards real addition?
I don’t know what the authors are trying to do here, and I think they may not know, either.
43 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-05-29T20:24:01.206Z · LW(p) · GW(p)
Much of your criticism is of the form "This is just a rehash of the GPT-2 paper; it doesn't teach us anything new." My reaction to this paper was: "In the GPT-2 paper, they made a prediction: that scaling up the same architecture would lead to more and more impressive and general capabilities. Now they've confirmed that prediction."
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-05-31T12:36:07.867Z · LW(p) · GW(p)
I feel the need at this point to add that I upvoted this post, even though I disagree with much of it, because this sort of discussion is exactly the sort of thing I like to see on LW, and I thought the OP was a nice detailed criticism of an important paper (and more importantly, criticism of the hype that many people including myself may be feeling after reading it). Again, I ultimately am still hyped, but my hype would be hollow if I didn't welcome criticisms of it!
comment by Past Account (zachary-robertson) · 2020-05-29T19:32:06.851Z · LW(p) · GW(p)
[Deleted]
Replies from: gwern, nostalgebraist↑ comment by gwern · 2020-05-29T19:53:40.573Z · LW(p) · GW(p)
Yeah, this post seems mostly focused on complaints like, they didn't include enough variants of k (despite half the graphs in the paper being about zero/one/few shot which are all different k and him missing graphs in the first place from skimming) and that they didn't dig enough into the handful of tasks Nostalgebraist is interested in because he finds oh so tedious all the usual benchmarks. (Truly devastating criticisms. "What have the Romans ever given us?"...) When you boil it all down, Nostalgebraist is basically Reviewer #3.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-05-29T21:01:55.886Z · LW(p) · GW(p)
It sounds like you think I'm nitpicking relatively minor points while ignoring the main significance of the paper. What do you think that main significance is?
I can see an argument that the value of few-shot LM prediction is its potential flexibility as a generic tool -- it can presumably do many tasks that are not standard benchmarks, weren't in the paper, etc.
Given my past ML experience, this just doesn't sound that promising to me, which may be our disconnect. In practical work I tend to find that a few days' work preparing a supervised dataset on my exact problem domain beats anything I can produce without that dataset. Few-shot learning apparently trades that few days of work for another non-zero time investment (finding the right prompt and output-reading methodology), generally worse performance, and (pending distillation successes) vastly larger compute requirements.
Replies from: dxu, gwern↑ comment by dxu · 2020-05-30T19:31:37.868Z · LW(p) · GW(p)
What do you think that main significance is?
I can’t claim to speak for gwern, but as far as significance goes, Daniel Kokotajlo has already advanced a plausible takeaway [LW(p) · GW(p)]. Given that his comment is currently the most highly upvoted comment on this post, I imagine that a substantial fraction of people here share his viewpoint.
Given my past ML experience, this just doesn't sound that promising to me, which may be our disconnect.
I strongly suspect the true disconnect comes a step before this conclusion: namely, that “[your] past ML experience” is all that strongly predictive of performance using new techniques. A smell test: what do you think your past experience would have predicted about the performance of a 175B-parameter model in advance? (And if the answer is that you don’t think you would have had clear predictions, then I don’t see how you can justify this “review” of the paper as anything other than hindsight bias.)
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-05-30T20:50:31.785Z · LW(p) · GW(p)
Perhaps I wasn't clear -- when I cited my experience as an ML practitioner, I did so in support of a claim about whether the stated capabilities of GPT-3 sound useful, not as a point about what those capabilities are.
I don't think the practical value of very new techniques is impossible to estimate. For example, the value of BERT was very clear in the paper that introduced it: it was obvious that this was a strictly better way to do supervised NLP, and it was quickly and widely adopted.
(I suppose it's conceivable that few-shot learning with a large model is "secretly useful" in some way not conveyed in the paper, but that's true of any paper, so if this proves anything then it proves too much.)
A smell test: what do you think your past experience would have predicted about the performance of a 175B-parameter model in advance?
Above I argued this question was orthogonal to my point, but to answer it anyway: I'd certainly predict better performance on LM tasks, as a simple extrapolation of the existing "biggening" research (GPT-2 at 1.5B parameters, Megatron-LM at 8.3B, T5 at 11B, T-NLG at 17B).
For downstream tasks, I'd expect similar scaling: certainly with fine-tuning (given T5's success on SuperGLUE) though GPT-3 was not fine-tuned, and also with unsupervised approaches (zero-shot, few-shot) given the reported scaling of GPT-2 zero-shot with model size (GPT-2 Fig 1).
I also would have predicted that fine-tuning still out-performs unsupervised approaches by a large margin on most tasks, a gap we observe with unsupervised GPT-3 vs. fine-tuned smaller models (presumably comparing to fine-tuned 175B models would yield an even larger gap).
I alluded to all this in the post, as did the GPT-3 authors in their paper: the results demonstrate that existing trends continue up to 175B. As Daniel Kokotajlo says, the new observation confirms an already familiar, though previously untested, prediction.
Replies from: dxu↑ comment by dxu · 2020-05-31T02:12:32.804Z · LW(p) · GW(p)
I don't think the practical value of very new techniques is impossible to estimate. For example, the value of BERT was very clear in the paper that introduced it: it was obvious that this was a strictly better way to do supervised NLP, and it was quickly and widely adopted.
This comparison seems disingenuous. The goal of the BERT paper was to introduce a novel training method for Transformer-based models that measurably outperformed previous training methods. Conversely, the goal of the GPT-3 paper seems to be to investigate the performance of an existing training method when scaled up to previously unreached (and unreachable) model sizes. I would expect you to agree that these are two very different things, surely?
More generally, it seems to me that you've been consistently conflating the practical usefulness of a result with how informative said result is. Earlier, you wrote that "few-shot LM prediction" (not GPT-3 specifically, few-shot prediction in general!) doesn't sound that promising to you because the specific model discussed in the paper doesn't outperform SOTA on all benchmarks, and also requires currently impractical levels of hardware/compute. Setting aside the question of whether this original claim resembles the one you just made in your latest response to me (it doesn't), neither claim addresses what, in my view, are the primary implications of the GPT-3 paper--namely, what it says about the viability of few-shot prediction as model capacity continues to increase.
This, incidentally, is why I issued the "smell test" described in the grandparent, and your answer more or less confirms what I initially suspected: the paper comes across as unsurprising to you because you largely had no concrete predictions to begin with, beyond the trivial prediction that existing trends will persist to some (unknown) degree. (In particular, I didn't see anything in what you wrote that indicates an overall view of how far the capabilities current language models are from human reasoning ability, and what that might imply about where model performance might start flattening with increased scaling.)
Since it doesn't appear that you had any intuitions to begin with about what GPT-3's results might indicate about the scalability of language models in general, it makes sense that your reading of the paper would be framed in terms of practical applications, of which (quite obviously) there are currently none.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-05-31T04:25:36.775Z · LW(p) · GW(p)
what, in my view, are the primary implications of the GPT-3 paper--namely, what it says about the viability of few-shot prediction as model capacity continues to increase
This seems like one crux of our disagreement. If I thought the paper shows a clear trend, with room to grow, toward much greater performance few-shot learning with even bigger models, I would be more impressed with "few-shot + large LM" as an approach.
I don't think it shows that. The clearest evidence on this subject, IMO, is the many plots in their Appendix H. On a large fraction of the individual downstream tasks, few-shot learning has either
- a scaling trend with a clearly defined shape that is mostly flat by the 175B point, with a remaining gap vs. fine-tuning that seems unlike to be closed (examples: WiC, MultiRC, ReCoRD, PhysicaQA, OpenBookQA, at least 5 of the 6 reading comprehension tasks, ANLI)
- a very noisy trend where, due to noise, returns to scale might be large but might just as well be near zero (examples: BoolQ, CB, WSC)
The scaling trend is more encouraging on certain downstream tasks (COPA, ARC, Winogrande, many the MT tasks), on "less downstream" tasks that essentially probe language modeling skill in a different way (cloze/completion), and on synthetic tasks.
On average, there is a trend toward slow but steady growth with scale (Fig 1.3), but this masks the great across-task variance catalogued above. The scaling picture for few-shot is very different from the scaling picture for LM loss itself, which as catalogued in another OpenAI paper is remarkably smooth and predictable, and which (as GPT-3 shows) continues smoothly to 175B.
I find it difficult to express just what I find unimpressive here without further knowledge of your position. (There is an asymmetry: "there is value in this paper" is a there-exists-an-x claim, while "there is no value in this paper" is a for-all-x claim. I'm not arguing for-all-x, only that I have not seen any x yet.)
All I can do is enumerate and strike out all the "x"s I can think of. Does few-shot learning look promising in the scaling limit?
- As a tool for humans: no, I expect fine-tuning will always be preferred.
- As a demonstration that transformers are very generic reasoners: no, we still see a wide spread of task performance despite smooth gains in LM loss, with some of the most distinctive deficits persisting at all scales (common sense physics, cf section 5), and some very basic capabilities only emerging at very large scale and noisily even there (arithmetic).
- As an AGI component: no. Because few-shot learning on most tasks shows no clear scaling trend toward human level, any role of transformers in AGI will require more effective ways of querying them (such as fine-tuning controlled by another module), or non-transformer models.
↑ comment by dxu · 2020-06-02T20:06:38.721Z · LW(p) · GW(p)
I'm not seeing how you distinguish between the following two hypotheses:
- GPT-3 exhibits mostly flat scaling at the tasks you mention underneath your first bullet point (WiC, MultiRC, etc.) because its architecture is fundamentally unsuited to those tasks, such that increasing the model capacity will lead to little further improvement.
- Even 175B parameters isn't sufficient to perform well on certain tasks (given a fixed architecture), but increasing the number of parameters will eventually cause performance on said tasks to undergo a large increase (akin to something like a phase change in physics).
It sounds like you're implicitly taking the first hypothesis as a given (e.g. when you assert that there is a "remaining gap vs. fine-tuning that seems [unlikely] to be closed"), but I see no reason to give this hypothesis preferential treatment!
In fact, it seems to be precisely the assertion of the paper's authors that the first hypothesis should not be taken as a given; and the evidence they give to support this assertion is... the multiple downstream tasks for which an apparent "phase change" did in fact occur. Let's list them out:
- BoolQ (apparent flatline between 2.6B and 13B, then a sudden jump in performance at 175B)
- CB (essentially noise between 0.4B and 13B, then a sudden jump in performance at 175B)
- RTE (essentially noise until 2.6B, then a sudden shift to very regular improvement until 175B)
- WSC (essentially noise until 2.6B, then a sudden shift to very regular improvement until 175B)
- basic arithmetic (mostly flat until 6.7B, followed by rapid improvement until 175B)
- SquadV2 (apparent flatline at 0.8B, sudden jump at 1.3B followed by approximately constant rate of improvement until 175B)
- ANLI round 3 (noise until 13B, sudden jump at 175B)
- word-scramble with random insertion (sudden increase in rate of improvement after 6.7B)
Several of the above examples exhibit a substantial amount of noise in their performance graphs, but nonetheless, I feel my point stands. Given this, it seems rather odd for you to be claiming that the "great across-task variance" indicates a lack of general reasoning capability when said across-task variance is (if anything) evidence for the opposite, with many tasks that previously stumped smaller models being overcome by GPT-3.
It's especially interesting to me that you would write the following, seemingly without realizing the obvious implication (emphasis mine):
we still see a wide spread of task performance despite smooth gains in LM loss, with some of the most distinctive deficits persisting at all scales (common sense physics, cf section 5), and some very basic capabilities only emerging at very large scale and noisily even there (arithmetic)
The takeaway here is, at least in my mind, quite clear: it's a mistake to evaluate model performance on human terms. Without getting into an extended discussion on whether arithmetic ought to count as a "simple" or "natural" task, empirically transformers do not exhibit a strong affinity for the task. Therefore, the fact that this "basic capability" emerges at all is, or at least should be, strong evidence for generalization capability. As such, the way you use this fact to argue otherwise (both in the section I just quoted and in your original post) seems to me to be exactly backwards.
Elsewhere, you write:
The ability to get better downstream results is utterly unsurprising: it would be very surprising if language prediction grew steadily toward perfection without a corresponding trend toward good performance on NLP benchmarks
It's surprising to me that you would write this while also claiming that few-shot prediction seems unlikely to close the gap to fine-tuned models on certain tasks. I can't think of a coherent model where both of these claims are simultaneously true; if you have one, I'd certainly be interested in hearing what it is.
More generally, this is (again) why I stress the importance of concrete predictions. You call it "utterly unsurprising" that a 175B-param model would outperform smaller ones on NLP benchmarks, and yet neither you nor anyone else could have predicted what the scaling curves for those benchmarks would look like. (Indeed, your entire original post can be read as an expression of surprise at the lack of impressiveness of GPT-3's performance on certain benchmarks.)
When you only ever look at things in hindsight, without ever setting forth concrete predictions that can be overturned by evidence, you run the risk of never forming a model concrete enough to be engaged with. I don't believe it's a coincidence that you called it "difficult" to explain why you found the paper unimpressive: it's because your standards of impressiveness are opaque enough that they don't, in and of themselves, constitute a model of how transformers might/might not possess general reasoning ability.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-06-03T03:24:24.245Z · LW(p) · GW(p)
On the reading of the graphs:
All I can say is "I read them differently and I don't think further discussion of the 'right' way to read them would be productive."
Something that might make my perspective clear:
- when I first read this comment, I thought "whoa, that 'phase change' point seems fair and important, maybe I just wasn't looking for that in the graphs"
- and then I went back and looked at the graphs and thought "oh, no, that's obviously not distinguishable from noise; that's the kind of non-monotonic bouncing around that I expect when you need more data per plotted point to get a reasonable estimate; that Squad V2 graph looks like the other 5 reading comp graphs except with more noise," etc. etc.
I don't expect this will convince you I'm right, but the distance here seems more about generic "how to interpret plots in papers" stuff than anything interesting about GPT-3.
On this:
I can't think of a coherent model where both of these claims are simultaneously true; if you have one, I'd certainly be interested in hearing what it is.
Roughly, my position is that transformer LMs are very impressive and know all sorts of things, even at small scale, although they know them "less noisily" as the scale grows.
The intended connotation of my stance that "fine-tuning will outperform few-shot" is not "haha, transformers are limited, they will never stand on their own without supervised training, boo transformers!" If anything, it's the opposite:
- I think transformers have some limits (e.g. physical / spatial stuff). But, already at the 1.5B scale if not before, they display a very-real-if-noisy understanding of the linguistic phenomena probed by most NLP benchmarks.
- I think fine-tuning has shown itself to be a remarkably effective way to "get at" this knowledge for downstream tasks -- even with small data sets, not far in scale from the "data sets" used in few-shot.
- So, I don't understand what few-shot gets us in terms of ways to probe transformer understanding (we already had a great one) or as a demo of language understanding (what I see in my own generation experiments, at two orders of magnitude lower, impresses me far more than the few-shot results).
Again, I engage with this stuff foremost as someone who is very impressed transformer LMs as text generators and has interacted with them a lot in that modality.
So, this all feels a bit like being a dog owner who reads a new paper "demonstrating dogs' capacity for empathy with humans," is unimpressed w/ it's methodology, and finds themselves arguing over what concrete model of "dog empathy" they hold and what it predicts for the currently popular "dog empathy" proxy metrics, with a background assumption that they're some sort of dog-empathy-skeptic.
When in fact -- they believe that of course their dog empathizes with them, and they find the methodology of the paper awkwardly under-equipped to explore this complex, and very clearly real, phenomenon.
I've already seen GPT-2 display vast declarative knowledge and use words in subtle context-dependent ways, and pick up the many-faceted nuances implied in a prompt, and all those things. When I see it again, but with ~100x parameters, and in a contrived experimental setting where ~1.5B models technically fare poorly even if I've seen them do that kind of thing in real life . . . should I be impressed?
↑ comment by gwern · 2020-07-31T01:37:40.011Z · LW(p) · GW(p)
a scaling trend with a clearly defined shape that is mostly flat by the 175B point, with a remaining gap vs. fine-tuning that seems unlike to be closed (examples: WiC
Matt Brockman has closed half the gap for WiC by prompt programming, without any finetuning: http://gptprompts.wikidot.com/linguistics:word-in-context
↑ comment by gwern · 2020-05-30T23:52:38.491Z · LW(p) · GW(p)
It sounds like you think I’m nitpicking relatively minor points while ignoring the main significance of the paper. What do you think that main significance is?
The paper has an abstract and clearly-written discussions, which you presumably read. I know that you know perfectly well what the implications of the scaling curves and meta-learning are for AI risk and OA's AGI research programme. That your response is to feign Socratic ignorance and sealion me here, disgenuously asking, 'gosh, I just don't know, gwern, what does this paper show other than a mix of SOTA and non-SOTA performance, I am but a humble ML practitioner plying my usual craft of training and finetuning', shows what extreme bad faith you are arguing in, and it is, sir, bullshit and I will have none of it.
If you think that this does not show what it shows about DL scaling and meta-learning, have the guts to say so, don't meander around complaining about which of dozens of benchmarks you thought a nearly 100-page paper should've talked more about and then retreating to feigned ignorance when challenged.
Replies from: FactorialCode, nostalgebraist↑ comment by FactorialCode · 2020-05-31T07:19:08.632Z · LW(p) · GW(p)
When you boil it all down, Nostalgebraist is basically Reviewer #3.
That your response is to feign Socratic ignorance and sealion me here, disgenuously asking, 'gosh, I just don't know, gwern, what does this paper show other than a mix of SOTA and non-SOTA performance, I am but a humble ML practitioner plying my usual craft of training and finetuning', shows what extreme bad faith you are arguing in, and it is, sir, bullshit and I will have none of it.
Unless I'm missing some context in previous discussions, this strikes me as extremely antagonistic, uncharitable, and uncalled for. This pattern matches to the kind of shit I would expect to see on the political side of reddit, not LW.
Strongly downvoted.
↑ comment by nostalgebraist · 2020-05-31T01:57:20.820Z · LW(p) · GW(p)
Since I'm not feigning ignorance -- I was genuinely curious to hear your view of the paper -- there's little I can do to productively continue this conversation.
Responding mainly to register (in case there's any doubt) that I don't agree with your account of my beliefs and motivations, and also to register my surprise at the confidence with which you assert things I know to be false.
↑ comment by nostalgebraist · 2020-05-29T19:57:18.240Z · LW(p) · GW(p)
If one ignores the "GPT-3" terminology, then yeah, it's a perfectly decent scaling-up-transformers paper similar to the others that have come out in the last few years. (A paper with some flaws, but that's not surprising.)
But, I would be very surprised if there isn't a lot of hype about this paper -- hype largely due to the "GPT-3" term, and the inappropriate expectations it sets. People are naturally going to think "GPT-3" is as much of a step forward as "GPT-2" was, and it isn't. I take a critical tone here in an effort to cut that hype off at the pass.
Replies from: Vaniver, daniel-kokotajlo↑ comment by Vaniver · 2020-06-01T18:54:24.756Z · LW(p) · GW(p)
I take a critical tone here in an effort to cut that hype off at the pass.
Maybe this is just my AI safety focus, or something, but I find myself annoyed by 'hype management' more often than not; I think the underlying root cause of the frustration is that it's easier to reach agreement on object-level details than interpretations, which are themselves easier than interpretations of interpretations.
Like, when I heard "GPT-3", I thought "like GPT-2, except one more," and from what I can tell that expectation is roughly accurate. The post agrees, and notes that since "one" doesn't correspond to anything here, the main thing this tells you is that this transformer paper came from people who feel like they own the GPT name instead of people who don't feel that. It sounds like you expected "GPT" to mean something more like "paradigm-breaker" and so you were disappointed, but this feels like a ding on your expectations more than a ding on the paper.
But under the hype management goal, the question of whether we should celebrate it as "as predicted, larger models continue to perform better, and astoundingly 175B parameters for the amount of training we did still hasn't converged" or criticize it as "oh, it is a mere confirmation of a prediction widely suspected" isn't a question of what's in the paper (as neither disagree), or even your personal take, but what you expect the social distribution of takes is, so that your statement is the right pull on the group beliefs.
---
Maybe putting this another way, when I view this as "nostalgebraist the NLP expert who is following and sharing his own research taste", I like the post, as expert taste is useful even if you the reader disagree; and when I view it as "nostalgebraist the person who has goals for social epistemology around NLP" I like it less.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-06-01T19:53:18.684Z · LW(p) · GW(p)
I agree with you about hype management in general, I think. The following does seem like a point of concrete disagreement:
It sounds like you expected "GPT" to mean something more like "paradigm-breaker" and so you were disappointed, but this feels like a ding on your expectations more than a ding on the paper.
If the paper had not done few-shot learning, and had just reviewed LM task performance / generation quality / zero-shot (note that zero-shot scales up well too!), I would agree with you.
However, as I read the paper, it touts few-shot as this new, exciting capability that only properly emerges at the new scale. I expected that, if any given person found the paper impressive, it would be for this purported newness and not only "LM scaling continues," and this does seem to be the case (e.g. gwern, dxu [LW(p) · GW(p)]). So there is a real, object-level dispute over the extent to which this is a qualitative jump.
I'm not sure I have concrete social epistemology goals except "fewer false beliefs" -- that is, I am concerned with group beliefs, but only because they point to which truths will be most impactful to voice. I predicted people would be overly impressed with few-shot, and I wanted to counter that. Arguably I should have concentrated less on "does this deserve the title GPT-3?" and more heavily on few-shot, as I've done more recently.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-05-31T12:46:45.978Z · LW(p) · GW(p)
I think if I were you, then, I would have focused more on how we already knew you could scale up transformers and get more and more impressive results. I had heard of (and maybe skimmed) some of those other papers, so I was already somewhat confident that you could scale up transformers and get more impressive results... but I didn't quite believe it, deep down. Deep down I thought that probably there was going to be some catch or limitation I didn't know of yet that would prevent this easy scaling from going on much farther, or leading to anything interestingly new. After all, speculation is easy; making predictions and then later confirming them is hard. Well, now it's confirmed. This doesn't change my credences that much (maybe they go from 60% to 90% for the "can we scale up langauge models" and from like 20% to 30% for "are within 5 years of some sort of transformative AI") but it's changed my gut.
comment by lsusr · 2020-05-31T09:47:27.659Z · LW(p) · GW(p)
Your previous posts have been well-received, with averages of > karma per vote. This post GPT-3: a disappointing paper has received < karma per vote, due to a large quantity of downvotes. Your post is well-written, well-reasoned and civil. I don't think GPT-3: a disappointing paper deserves downvotes.
I wouldn't have noticed the downvotes if my own most heavily downvoted post [LW · GW] hadn't also cruxed around bottom-up few-shot learning [LW · GW].
I hope the feedback you received on this article doesn't discourage you from continuing to write about the limits of today's AI. Merely scaling up existing architectures won't get us from AI to AGI. The world needs people on the lookout for the next paradigm shift.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-05-31T12:48:31.955Z · LW(p) · GW(p)
Agreed! (Well, actually I do have like 10% credence that merely scaling up existing architectures will get us to AGI. But everything else I agree with.)
Replies from: lsusr↑ comment by lsusr · 2020-05-31T18:14:16.482Z · LW(p) · GW(p)
What existing architectures you would bet on, if you had to?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-06-01T10:29:43.453Z · LW(p) · GW(p)
I don't have a fleshed-out inside view on this; my credence is 10% for outside-view reasons. If somehow my job was to build AGI now (mind, I'm not an AI scientist) I'd try to combine GPT-3 with some sort of population-based reinforcement learning. Maybe the reward signal would come from chat interactions with human users (I'm assuming I work for Facebook or something and have access to millions of users willing to talk to my chatbot for free, plus huge amounts of data to get started). Idk, what would your answer be?
Replies from: lsusr↑ comment by lsusr · 2020-06-01T16:42:43.300Z · LW(p) · GW(p)
It's hard to go much lower than 10% uncertainty on anything like this without specialized domain knowledge. I'm in a different position. I'm CTO of an AI startup I founded so I get a little bit of an advantage from our private technologies.
If I had to restrict myself to public knowledge then I'd look for a good predictive processing algorithm and then plug it into the harmonic wave theory of neuroscience. Admittedly, this stretches the meaning of "existing architectures".
comment by nostalgebraist · 2021-12-17T22:14:12.285Z · LW(p) · GW(p)
This post holds up well in hindsight. I still endorse most of the critiques here, and the ones I don't endorse are relatively unimportant. Insofar as we have new evidence, I think it tends to support the claims here.
In particular:
- Framing few-shot learning as "meta-learning" has caused a lot of confusion. This framing made little sense to begin with, for the reasons I note in this post, and there is now some additional evidence against it.
- The paper does very little to push the envelope of what is possible in NLP, even though GPT-3 is probable capable of pushing the envelope. The paper spends very little time getting GPT-3 to do new things that were not previously possible. Instead it spends most of its time reproducing BERT results.
"Our 175B model can do as well as BERT" is an underwhelming punchline, and if anything an inadvertent argument against prompting as a technique.
Both these points are still not appreciated as broadly as I think they ought to be.
I'm not sure how much lasting value this post has. My recent post here [LW · GW] covers the same ground more carefully.
I'm not sure if this is relevant, but this post received some very critical comments, leading me to seriously question the value of continuing to write posts like this on LW. See here for a discussion about this with a reader of my blog. I did continue to write posts like this, and they have been well received, even when they reiterated my arguments here. I am curious what explains this difference, and have no good hypotheses.
Some points here I no longer endorse:
- I no longer care whether the new model "deserves" the name GPT-3, and I shouldn't have mixed this inane gripe with serious critiques. (I had forgotten at the time, but when GPT-2 was first announced, I made a similar objection to its name.)
- "this is about the least interesting transformer paper one can imagine in 2020" is just wrong, even as hyperbole.
- The paper crosses a larger scale gulf than earlier ones, and it's valuable to know what happens as you scale that much, even if what happens is "nothing especially novel."
- Related: I had a vague impression from other work that "scaled-up transformers are fundamentally like smaller ones." Here, I acted more confident of that claim than I had reason to be, and also assumed it was an established consensus, which it (clearly!) wasn't. I still think [LW · GW] this claim is true, but it's a point of contention even today.
- I didn't understand that OpenAI "really meant it" about few-shot results.
- That is, I assumed that "obviously" no one would use few-shot as a practical technique, and thought OpenAI was exhibiting these results to illuminate the model's properties, where in fact OpenAI really believes in a future where we interact with LMs entirely through natural language prompting.
- The release of the API (some time after this post) blindsided me.
- I had the same "obviously this isn't practical" response to GPT-2 zero-shot results, though when I go back and read the GPT-2 paper, it's clear the authors "really mean it" there too.
↑ comment by Kaj_Sotala · 2021-12-23T16:29:23.426Z · LW(p) · GW(p)
I'm not sure how much lasting value this post has. My recent post here covers the same ground more carefully.
I'm not sure if this is relevant, but this post received some very critical comments, leading me to seriously question the value of continuing to write posts like this on LW. See here for a discussion about this with a reader of my blog. I did continue to write posts like this, and they have been well received, even when they reiterated my arguments here. I am curious what explains this difference, and have no good hypotheses.
If you feel like "larger language models may disappoint you" was one of the posts that reiterated your arguments here, they seem to be saying pretty different things to me? It feels like this article is fundamentally focused on talking about the GPT-3 paper whereas your later post is focused on talking about GPT-3 itself.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-12-24T19:45:45.190Z · LW(p) · GW(p)
The later post still reiterates the main claims from this post, though.
- This post: "Few-shot learning results are philosophically confusing and numerically unimpressive; the GPT-3 paper was largely a collection of few-shot learning results, therefore the paper was disappointing"
- The later post: "Few-shot learning results are philosophically confusing and numerically unimpressive; therefore we don't understand GPT-3's capabilities well and should use more 'ecological' methods instead"
Many commenters on this post disagreed with the part that both posts share ("Few-shot learning results are philosophically confusing and numerically unimpressive").
comment by dmtea · 2020-05-31T13:37:11.442Z · LW(p) · GW(p)
I feel the few shot arithmetic results were some of the most revolutionary results we've received this decade. Learning math from nothing but verbal examples shows that we have an agent that can reason like us. The progression to complex algebra seems inevitable, with nothing but more parameters.
Assumption #2 is entirely correct, which is why few shot examples matter. The system is literally smart enough to figure out what addition is with those 50 examples. I bet most of us took longer than 50 examples.
" But #2 is wild: it would represent a kind of non-linguistic general intelligence ability which would be remarkable to find in a language model."
Yes, it does represent exactly that. The few-shot results on wordscramble further bear this out. I would go so far as to say gpt-3 is the first ever proto-AGI. For all the things people say it can't do, it's on track to becoming superintelligent in everything that matters: reasoning , math, and pattern recognition.
Gpt-2 was a toddler with decent english. GPT-3 just reached primary school.
Replies from: ESRogs↑ comment by ESRogs · 2020-05-31T20:59:51.304Z · LW(p) · GW(p)
Assumption #2 is entirely correct
What makes you conclude this?
Replies from: daniel-kokotajlo, dmtea↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-06-01T13:25:05.362Z · LW(p) · GW(p)
I'm very interested in this particular issue, so I would love to see the two of you say more about this. For my part, (1) as abergal said elsewhere in these comments, maybe there is some mundane explanation for the mathematical success (and math errors) besides assumption #2.
Assumption #2 does seem like a fairly parsimonious explanation of the data, no? It would explain the math success, the SAT question success, the "wug test" success, etc. (Whereas "it's just regurgitating the memorized dataset" does not, and "OK so it's learned some basic math and some basic word-smithing, but still doesn't have a general reasoning ability" is unparsimonious.)
I think this comes down to priors: How hard do you think it is to develop general reasoning ability?
I think we tend to think of it as the hardest thing ever because that's what you need to get AGI and AGI is far away. But this is a bias; Nature didn't sit down and make a tech tree with increasingly useful stuff being increasingly difficult to get, and general reasoning therefore being the hardest to get because it is so useful. I think our prior for the difficulty of general reasoning ability should be similar to our prior for the difficulty of image recognition, or fine motor control, or chess playing, or lord of the rings fanfiction writing. Given that the evidence shows GPT-3 architecture succeeds at two of the four examples above and hasn't been applied to the other two, well, it shouldn't be that crazy to think it might succeed at general reasoning too.
Are there bits of evidence against general reasoning ability in GPT-3? Any answers it gives that it would obviously not give if it had a shred of general reasoning ability?
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-06-01T15:48:59.151Z · LW(p) · GW(p)
Are there bits of evidence against general reasoning ability in GPT-3? Any answers it gives that it would obviously not give if it had a shred of general reasoning ability?
In the post I gestured towards the first test I would want to do here -- compare its performance on arithmetic to its performance on various "fake arithmetics." If #2 is the mechanism for its arithmetic performance, then I'd expect fake arithmetic performance which
- is roughy comparable to real arithmetic performance (perhaps a bit worse but not vastly so)
- is at least far above random guessing
- more closely correlates with the compressibility / complexity of the formal system than with its closeness to real arithmetic
BTW, I want to reiterate that #2 is about non-linguistic general reasoning, the ability to few-shot learn generic formal systems with no relation to English. So the analogies and novel words results seem irrelevant here, although word scramble results may be relevant, as dmtea says.
----
There's something else I keep wanting to say, because it's had a large influence on my beliefs, but is hard to phrase in an objective-sounding way . . . I've had a lot of experience with GPT-2:
- I was playing around with fine-tuning soon after 117M was released, and jumped to each of the three larger versions shortly after its release. I have done fine-tuning with at least 11 different text corpora I prepared myself.
- All this energy for GPT-2 hobby work eventually convergent into my tumblr bot, which uses a fine-tuned 1.5B with domain-specific encoding choices and a custom sampling strategy ("middle-p"), and generates 10-20 candidate samples per post which are then scored by a separate BERT model optimizing for user engagement and a sentiment model to constrain tone. It's made over 5000 posts so far and continues to make 15+ / day.
So, I think have a certain intimate familiarity with GPT-2 -- what it "feels like" across the 4 released sizes and across numerous fine-tuning / sampling / etc strategies on many corpora -- that can't be acquired just by reading papers. And I think this makes me less impressed with arithmetic and other synthetic results than some people.
I regularly see my own GPT-2s do all sorts of cool tricks somewhat similar to these (in fact the biggest surprise here is how far you have to scale to get few-shot arithmetic!), and yet there are also difficult-to-summarize patterns of failure and ignorance which are remarkably resistant to scaling across the 117M-to-1.5B range. (Indeed, the qualitative difference across that range is far smaller than I had expected when only 117M was out.) GPT-2 feels like a very familiar "character" to me by now, and I saw that "character" persist across the staged release without qualitative jumps. I still wait for evidence that convinces me 175B is a new "character" and not my old, goofy friend with another lovely makeover.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-06-02T13:12:45.152Z · LW(p) · GW(p)
Thanks for the thoughtful reply. I definitely acknowledge and appreciate your experience. I agree the test you proposed would be worth doing and would provide some evidence. I think it would have to be designed carefully so that the model knows it is doing fake arithmetic rather than ordinary arithmetic. Maybe the prompt could be something like "Consider the following made-up mathematical operation "@. " 3@7=8, 4@4 = 3, ... [more examples], What does 2@7 equal? Answer: 2@7 equals " I also think that we shouldn't expect GPT-3 to be able to do general formal reasoning at a level higher than, say, a fifth grade human. After all, it's been trained on a similar dataset (english, mostly non-math, but a bit of normal arithmetic math).
Are you saying that GPT-3 has learned linguistic general reasoning but not non-linguistic general reasoning? I'm not sure there's an important distinction there.
It doesn't surprise me that you need to scale up a bunch to get this sort of stuff. After all, we are still well below the size of the human brain.
Side question about experience: Surveys seem to show that older AI scientists, who have been working in the field for longer, tend to think AGI is farther in the future -- median 100+ years for scientists with 20+ years of experience, if I recall correctly. Do you think that this phenomenon represents a bias on the part of older scientists, younger scientists, both, or neither?
Replies from: dxu↑ comment by dxu · 2020-06-02T17:49:33.971Z · LW(p) · GW(p)
Also note that a significant number of humans would fail the kind of test you described (inducing the behavior of a novel mathematical operation from a relatively small number of examples), which is why similar tests of inductive reasoning ability show up quite often on IQ tests and the like. It's not the case that failing at that kind of test shows a lack of general reasoning skills, unless we permit that a substantial fraction of humans lack general reasoning skills to at least some extent.
↑ comment by dmtea · 2020-06-04T09:21:42.617Z · LW(p) · GW(p)
The big jump in performance between the zero shot and few shot setting in arithmetic and other non-linguistic reasoning tasks[esp. 3D- & 3D+] is why I think it is almost certain #2 is true. Few shot inference relies on no further training [unlike fine tuning], so the improvement in 'pattern recognition' so to speak is happening entirely at inference. It follows that the underlying model has general reasoning abilities, i.e. the ability to detect and repeat arbitrary patterns of ever increasing complexity, that occur in its input (conditioning) data.
Interestingly, the model fails to completely learn 4D and 5D arithmetic, where its zero-shot scores were really low. However few shot inference does show improvement. I wonder if problems of increasing complexity can also be solved using increasing numbers of examples in few shot (say k=500 for 4D+). Though of course this will run into the roadblock of context size very soon.
If increasing number of few-shot examples allows it to correctly solve ever-harder problems, there is a strong case for scaling the reformer, with a context window of 1 million tokens, to a GPT-3 like size.
It would be fascinating to probe how much of the general reasoning capabilities arise from the size of transformer itself, and how much they arise from training on a large volume of language data. Does language training implicitly impart it with the tools for all human symbolic reasoning?
A test anybody with 1024 GPUs for even a few minutes can perform, is to load an untrained GPT-3 size model, train it for a few steps on a few hundred 3D, 4D, and 5D calculations, and then test its inference. It will help show if these skills can be learnt absent a basis in language. It parallels a question in humans - can a human learn math without first learning language?
A success would indicate the existence of general reasoning as an innate attribute of large transformers themselves; failure would not however falsify general reasoning: it would imply that any general reasoning originates in language learning - which could justify why pre-trained models can perform arithmetic but untrained models can't.
[Note: my use of "trained" and "untrained" refers to pre-training on CommonCrawl.]
GPT-3 made me update my prior for "scaling current techniques will get us to Superintelligence", from probably not (<30%) to likely (>60%). The phase shifts in many tasks mentioned by dxu, and its ability to perform non-lingustic reasoning at inference, are the reasons for this shift. I tried a number of ways to make gpt-2 perform basic arithmetic but always failed, which was responsible for my earlier prior.
My updated models predict that a model between 1-2 orders of magnitude bigger will almost certainly be able to utilise calculus, trigonometry, and derivations in a human-like way to reach conclusions, given a few examples.
Essentially, I see no evidence against the proposition that language, math, and abstract reasoning are points along the same continuum - and this paper provides strong evidence that these abilities lie on the same continuum, the difference is only one of complexity.
comment by Douglas Summers-Stay (douglas-summers-stay) · 2020-05-30T17:24:53.837Z · LW(p) · GW(p)
I'm sure there will be many papers to come about GPT-3. This one is already 70 pages long, and must have come not long after the training of the model was finished, so a lot of your questions probably haven't been figured out yet. I'd love to read some speculation on how, exactly, the few-shot-learning works. Take the word scrambles, for instance. The unscrambled word will be represented by one or two tokens. The scrambled word will be represented by maybe five or six much less frequent tokens composed of a letter or two each. Neither set of tokens contains any information about what letters make up the word. Did it see enough word scrambles on the web to pick up the association between every set of tokens and all tokenizations of rearranged letters? that seems unlikely. So how is it doing it? Also, what is going on inside when it solves a math problem?
comment by abramdemski · 2020-07-23T17:29:45.445Z · LW(p) · GW(p)
GPT-3 is so little of an advance, it doesn’t even do that well at SuperGLUE. It just does okay with its dominant hand tied behind its back.
This was my biggest take-away. Not having read the GPT-3 paper, and not having heard of superGLUE (but having read Gwern's glowing review of GPT-3), I fully expected that GPT-3 few-shot learning would beat state-of-the-art on a benchmark like this!
Replies from: nostalgebraist↑ comment by nostalgebraist · 2020-08-01T22:27:38.348Z · LW(p) · GW(p)
To be fair, it's not an apples-to-apples comparison.
GPT-3 few-shot learning gets to use less data. (Although much of superGLUE has tiny train sets, so this gap isn't as big as it sounds.) And with GPT-3 you don't have the storage overhead of a separate trained model for every task.
Back when I wrote this post, I really did not realize that OpenAI was serious about few-shot learning as a practical, competitive approach. I had assumed it was meant as a conceptual demonstration of meta-learning, or a new way to probe what LMs "know."
In other words, I implicitly assumed "oh, of course they aren't planning [something like the OpenAI API], it'd be uncharitable to assume they actually think this is a practical approach." Now it's clear that they do think that, which makes for a different conversation than the one I had expected here. (I'm still bearish on the approach, though.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-20T22:29:34.377Z · LW(p) · GW(p)
Update: It seems that GPT-3 can actually do quite well (maybe SOTA? Human-level-ish it seems) at SuperGLUE with the right prompt (which I suppose you can say is a kind of fine-tuning, but it's importantly different from what everyone meant by fine-tuning at the time this article was written!) What do you think of this?
This is also a reply to your passage in the OP:
The transformer was such an advance that it made the community create a new benchmark, “SuperGLUE,” because the previous gold standard benchmark (GLUE) was now too easy.
GPT-3 is so little of an advance, it doesn’t even do that well at SuperGLUE. It just does okay with its dominant hand tied behind its back.Replies from: nostalgebraist
↑ comment by nostalgebraist · 2021-04-26T21:37:51.589Z · LW(p) · GW(p)
I'm confused -- the paper you link is not about better prompts for GPT-3. It's about a novel fine-tuning methodology for T5. GPT-3 only appears in the paper as a reference/baseline to which the new method is compared.
The use of a BERT / T5-style model (denoising loss + unmasked attn) is noteworthy because these models reliably outperform GPT-style models (LM loss + causally masked attn) in supervised settings.
Because of this, I sometimes refer to GPT-3 as "quantifying the cost (in additional scale) imposed by choosing a GPT-style model." That is, the following should be roughly competitive w/ each other:
- BERT/T5 at param count N
- GPT at param count ~100 * N
See my comments near the bottom here.
Separately, I am aware that people have gotten much better performance out of GPT-3 by putting some effort into prompt design, vs. the original paper which put basically no effort into prompt design.
Your comment claims that the "SOTA" within that line of work is close to the overall SOTA on SuperGLUE -- which I would readily believe, since GPT-3 was already pretty competitive in the paper and dramatic effects have been reported for prompt design on specific tasks. However, I'd need to see a reference that actually establishes this.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-27T06:10:50.995Z · LW(p) · GW(p)
Ah! You are right, I misread the graph. *embarrassed* Thanks for the correction!
comment by bonna · 2020-05-31T12:07:22.962Z · LW(p) · GW(p)
Regarding simple arithmetic, it would be interesting to see the how the performance of the model differs for different types of stings, e.g.
- "52 + 37 = _"
- "52 plus 37 equals _"
- "fifty-two + thirty-seven = _"
- "fifty-two plus thirty-seven equals _"
comment by Pattern · 2021-12-15T18:15:55.117Z · LW(p) · GW(p)
[Human prompt] To do a “farduddle” means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
[GPT-3 continuation] One day when I was playing tag with my little sister, she got really excited and she started doing these crazy farduddles.
The human prompt sounded clunkier than the continuation.
comment by dulleh · 2020-07-24T22:13:35.848Z · LW(p) · GW(p)
I would like to see it be given a list of the natural numbers (in order) as a prompt and then asked to do basic arithmetic. I wonder if the scores would improve over what's been reported. In particular, would be interesting to see if '1 2 3 4 ... N, what is 14 + 15?' type prompts improve on the zero shot performance?