Never Go Full Kelly
post by SimonM · 2021-02-25T12:53:50.618Z · LW · GW · 7 commentsContents
Introduction What's wrong with Kelly? Respecting the market / your counterparty Digression on 0<α<1 Fractional Kelly as risk reduction Fractional Kelly is Mean-Variance optimal Fractional Kelly is CRRA Optimal in certain situations Fractional Kelly efficiently trades off "growth" against "security" One way to figure out your Kelly fraction Conclusion None 7 comments
Introduction
I am assuming the reader is at least somewhat familiar with the Kelly Criterion. If not, I suggest you read this first [LW · GW]. There is a sense in which I am mostly just adding meat to the bones of "Never Go Full Kelly". (Or more narrowly his two last two points):
- You can't handle the swings
- You have full knowledge of your edge
Hopefully I can give you some rules of thumb for how to handle both those issues:
- Scale down all bets "fractionally"
- Scale down by these specific fractions:
- A function of your risk-adjusted edge (1-1/(1+SR^2))
- A function of how much information is in your prediction vs your counterparty (your "information" / the "information" between you)
- You want to do both if you can't handle the swings AND don't have full knowledge. (Which is basically everyone).
For this post, is the Kelly fraction, is your estimate of the probability of an event, is the market / your counterparty's probability. In this notation:
After being introduced to the Kelly criterion the next thing people are introduced to is "fractional Kelly". Specifically the idea is rather than wagering the Kelly fraction on an event, you wager (typically with ).
What's wrong with Kelly?
Kelly is pretty aggressive compared to most people's risk tolerance. Upon seeing a Kelly bet some people will be somewhat dubious as to how aggressive it is. If someone offers you evens on something you think is 60%, Kelly would have you betting 20% of your net worth. 20% seems like an awful lot to bet on something which is only going to happen 60% of the time. You can play this game yourself here and see how comfortable you are with the drawdowns with "fake" money. (This was originally from a paper where the participants did not perform well). If you don't fancy playing, consider this thought experiment: 3 tails is a 50% draw down, and this will happen ~once every 24 flips.
To give a more recent example, before the 2020 Presidential election, the betting markets were giving Biden a 60% change. If you believed 538, and put it at ~90%, would you have been comfortable staking 50% of your net worth on Biden?
Let's have a look at what the geometric growth rate looks like for different fractions of a Kelly bet. Growth is maximised at Full Kelly:
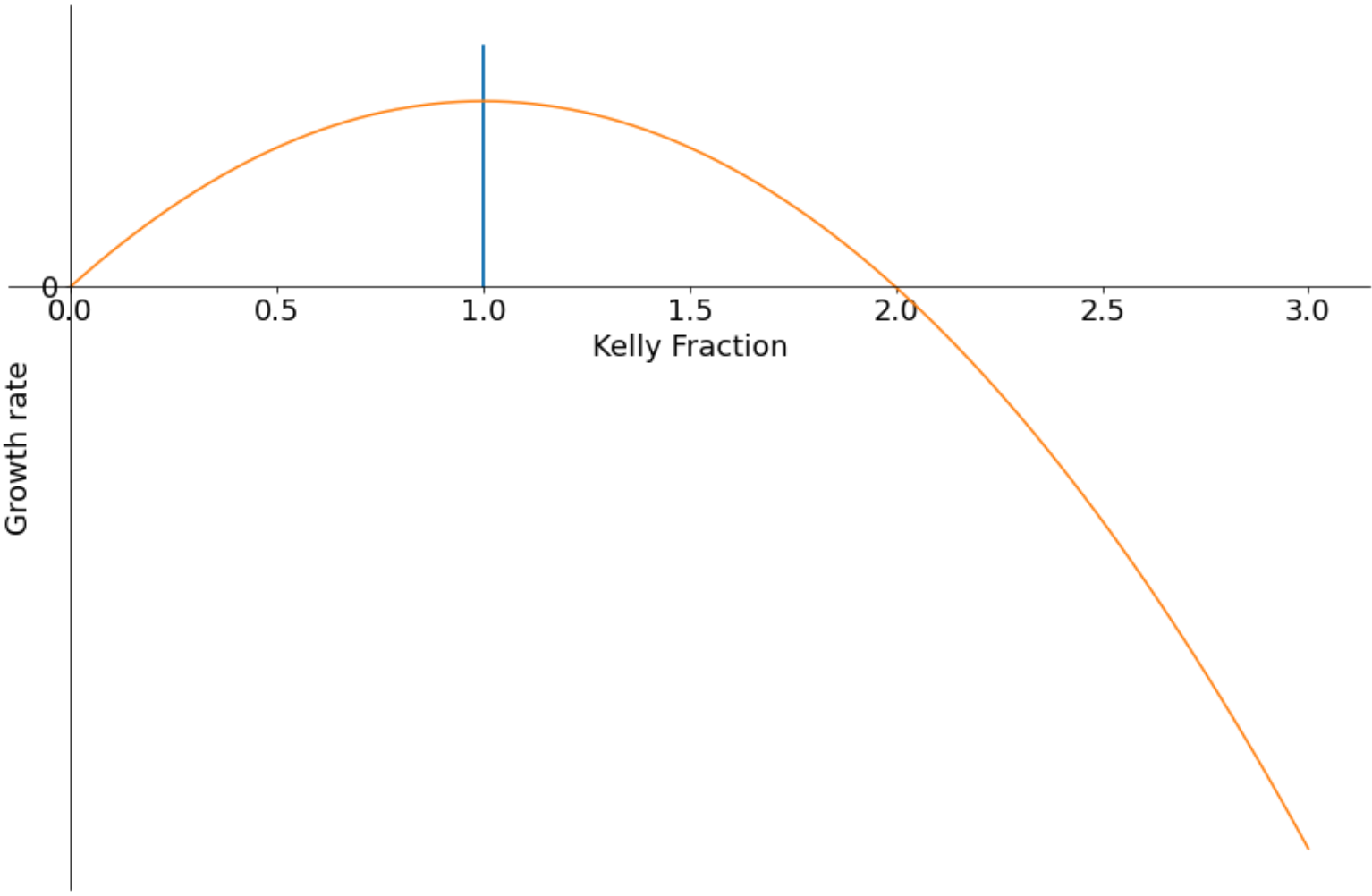
This is plotting fractional-Kelly coefficient () (1 is Full Kelly, 0.5 is half Kelly etc) vs expected growth rate (betting with a 2% edge into a 50% market).
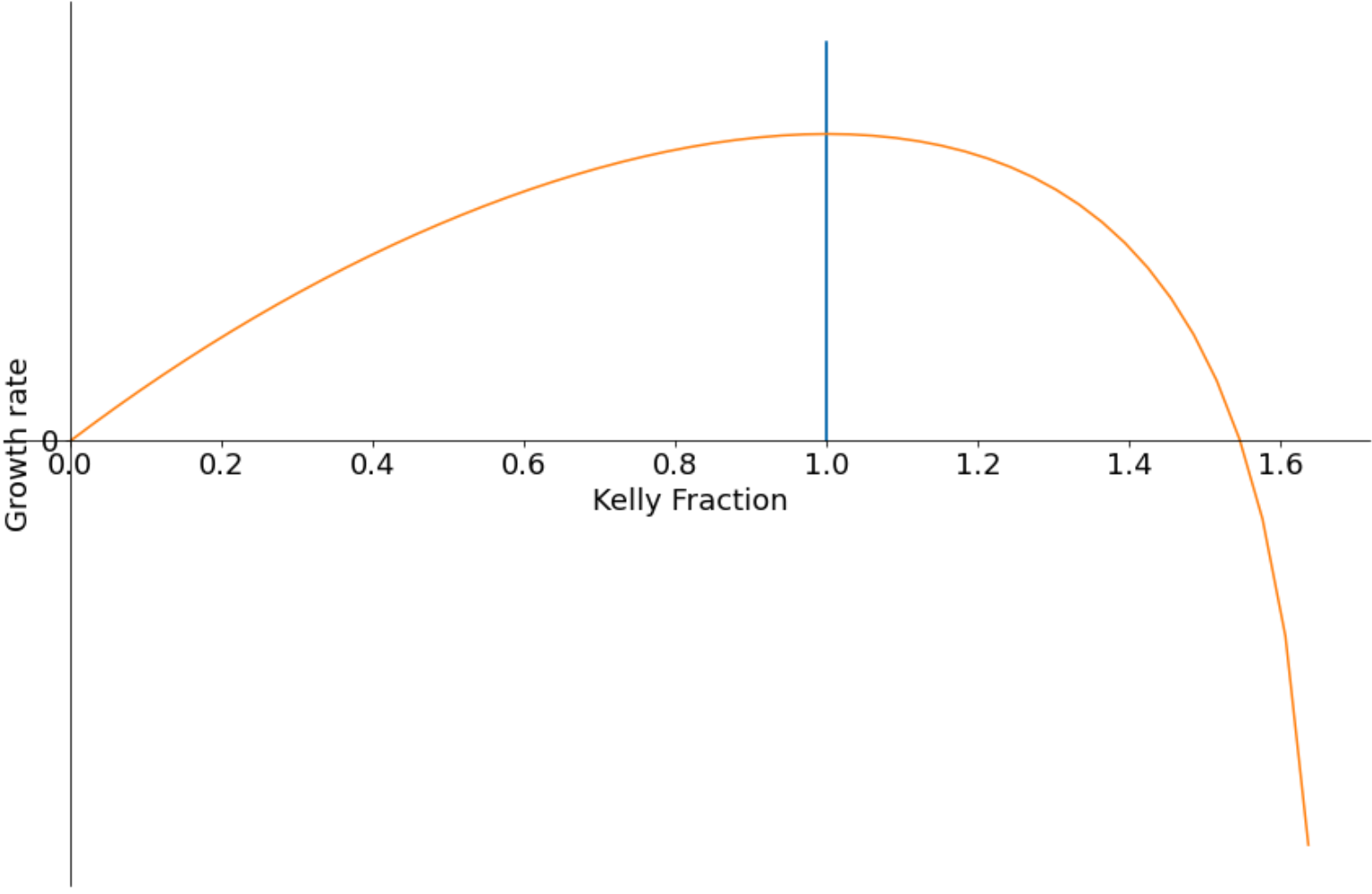
There's nothing special about "2" here. Using a different set-up (30% edge into 50% market, (f = .6) so you can't bet more than ) we have a chart that looks like:
So far, we've been assuming that we know the probability of an event occurring, so we can perfectly balance on the peak of that curve. Now lets assume there's some uncertainty in that. (Bayesians might get a little uncomfortable here - posterior distributions for discrete events are point estimates. Instead imagine you view the event as a Bernoulli random variable with parameter p, and you have a posterior distribution for p.*).
The peak of that curve looks vaguely symmetric, so you could be forgiven for thinking that you get penalised equally for being over- or under-confident. (And therefore if your posterior distribution for p is symmetric, betting Fully Kelly is optimal). Unfortunately this is not true. The heuristic argument for this takes a little but of algebra, but roughly stated, you can check that the derivative of the growth rate with respect to at plus-or-minus a small amount is negative, therefore we've already passed the "optimal" point. To use a more concrete example:
Baker and McHale model the posterior of p as a Beta-distribution. How does our growth-rate vs Kelly fraction change with increasing uncertainty?
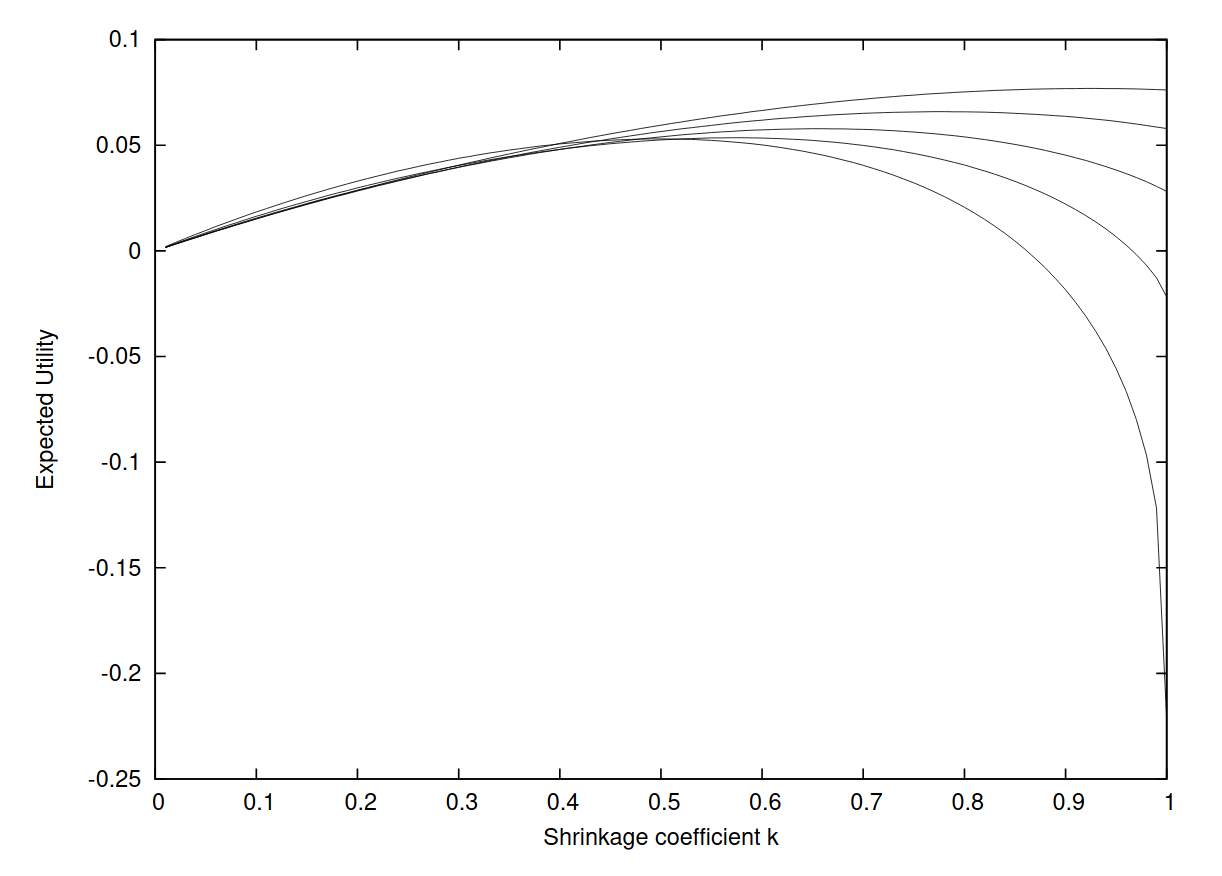
First thing to note: growth rate is always sloping down at . ie Full Kelly where there is any uncertainty is not optimal!
They then go on to describe (in their model) how to find the correct "shrinkage coefficient" (what I call ) as a function of uncertainty;
I think this is a pretty decent rule of thumb, which is worth keeping in mind. (We'll come back to another interpretation of this later). (SR = Sharpe Ratio = "Edge divided by standard deviation"). "The higher your (risk-adjusted) edge, the closer to Full Kelly you can go".
* Yes, if you had your posterior distribution and your utility you can happily go off and optimize to your hearts content. I am mostly aiming this at people who only have a vague sense for what their uncertainty and utility are.
Respecting the market / your counterparty
Moving away from thinking about our posterior in isolation, we'll consider a world in which we are now being presented with a bet. Let's start by assuming that the market (or Alice who we're betting against) has information we don't. Let's also assume that we have information the market (Alice) doesn't. (Otherwise we really shouldn't be betting).
When betting, we should update our probability upon seeing the market (or our counterparty's) odds. One way to do this update is to create a weighted average of weighted by how much "information" (I'm being pretty loose with terminology here) they contain. (, we know everything the market does (and something else); , the market knows everything we do (and something else) - we will take their probability as our own; somewhere in-between, we have some information the market is missing and they have some we don't have. I'll make this more precise with a toy model to give more intuition).
.
In this instance, our new Kelly fraction is fractional Kelly.
Some properties of : which we might expect:
- 0≤α≤1
- α depends on our relative confidence of the two forecasts [Again, not always true, but true in some model]
To give a concrete example of this, in his 2020 Presidential Market postmortem [LW · GW] Zvi says:
If I was allowed to look at both the models and markets, and also at the news for context, I would combine all sources. If the election is still far away, I would give more weight to the market, while correcting for its biases. The closer to election day, the more I would trust the model over the polls. In the final week, I expect the market mainly to indicate who the favorite is, but not to tell me much about the degree to which they are favored.
If FiveThirtyEight gives either side 90%, and the market gives that side 62%, in 2024, my fair will again be on the order of 80%, depending on how seriously we need to worry about the integrity of the process at that point.
The more interesting scenario for 2024 is FiveThirtyEight is 62% on one side and the market is 62% on the other, and there is no obvious information outside of FiveThirtyEight’s model that caused that divergence. My gut tells me that I have that one about 50% each way.
Digression on
There are cases where two people coming to independent conclusions of a probability means the best estimate of the probability is higher. If our evidence Bob is the killer is a bloody sock we might give a probability 40%, if Alice's evidence Bob is the killer is a conversation she overheard she might have a probability of 20%. Upon hearing Alice's data, we might update to higher than 40%.
This becomes a little trickier when dealing with betting. If all we know from Alice is she is willing to bet at 20% it's hard for us to gauge what information she has that we don't. We'd need to infer it. (Perhaps 20% is much higher than the base-rate, she can't know about the sock / our evidence and so she must have some evidence we don't have). The same is also true when dealing with a faceless market. Betting markets don't announce what's priced in (and often figuring out what the market has priced into an event is the whole game).
... back to estimating our posterior.
To go back to our earlier model we're looking at a Bernoulli event and we have a posterior for P. Suppose also the market has a posterior for P and they are both normal with known variances:
(This wont be exactly true, probabilities need to be positive and less than one, but assuming the are small enough this is good enough. We could also do this in log-odds space or similar if needs be) Given then our best estimate / Bayesian posterior for P is:
This is exactly our model from before with as our fraction. How to read alpha? "How much of the uncertainty in P is being captured by our estimate vs their estimate?"
Clearly this toy model isn't perfect, I would encourage you to play around with some other examples. The general sentiment is as follows:
You probably believe that the market contains some information you missed. Use a Kelly fraction which accounts for your humility.
- Full Kelly - I know everything the market / Alice does. (And my edge is precisely what they don't know)
- 1/2 Kelly - I know as much as the market (but we know different things, otherwise our estimates would be the same)
- 1/3 Kelly - I know something the market doesn't know which is ~1/2 as important as what the market knows.
- ...
- 0 Kelly - I know nothing the market doesn't already know, and I've updated my estimate
Linking this back to the Baker-McHale formula:
"Our edge is the market error, our error is the market's edge"
Fractional Kelly as risk reduction
So far, everything I've suggested only really applies to Full Kelly. I've suggested how to reduce the Kelly fraction, but only as a means to achieving a more optimal full Kelly. I think it's worth reconsidering the more risk averse people we discussed earlier.
I mostly want to spend this section vaguely gesturing towards the literature on fractional Kelly without giving too much detail. In part this is because I think there's nothing especially persuasive here. Risk tolerance is a personal thing so saying things like "fractional Kelly is optimal in certain circumstances for a certain utility" isn't going to persuade anyone. That said, there are lots of cases in which fractional Kelly is optimal, and I think it's worth knowing that. There are also a bunch of properties similar to "Kelly maximises long-run median wealth" which aren't specifically utility related, but might encourage you to think a little bit about how you calibrate your risk taking.
Fractional Kelly is Mean-Variance optimal
(This is another way of stating the 2-fund theorem in finance)
Given a trade-off between maximising returns (equivalently (wealth)) and for a specific variance of returns, the optimal strategy is a linear combination of the Kelly-strategy and the "hold cash" strategy.
MacLean, Ziemba, Li give a proof of this in the Kelly framework.
Wikipedia give a proof using the standard Lagrangian set-up (equivalent to MacLean et al)
Hansen and Richard give a more geometric proof
[The discrete time analogy to this is sadly trivial. There's only one bet to be made, so once you choose your variance, your strategy is always going to be a multiple of the Kelly criterion.]
Fractional Kelly is CRRA Optimal in certain situations
The Constant Relative Risk Aversion utilities are popular in economics (probably because they are tractable). I think (since this post is mostly rules-of-thumb) it's not unreasonable to see what results come of them and adjust ourselves accordingly. Calculating the optimal bet using CRRA utilities is fairly straightforward in some circumstances. (Discrete bets and lognormal bets). For the later, fractional Kelly is optimal.
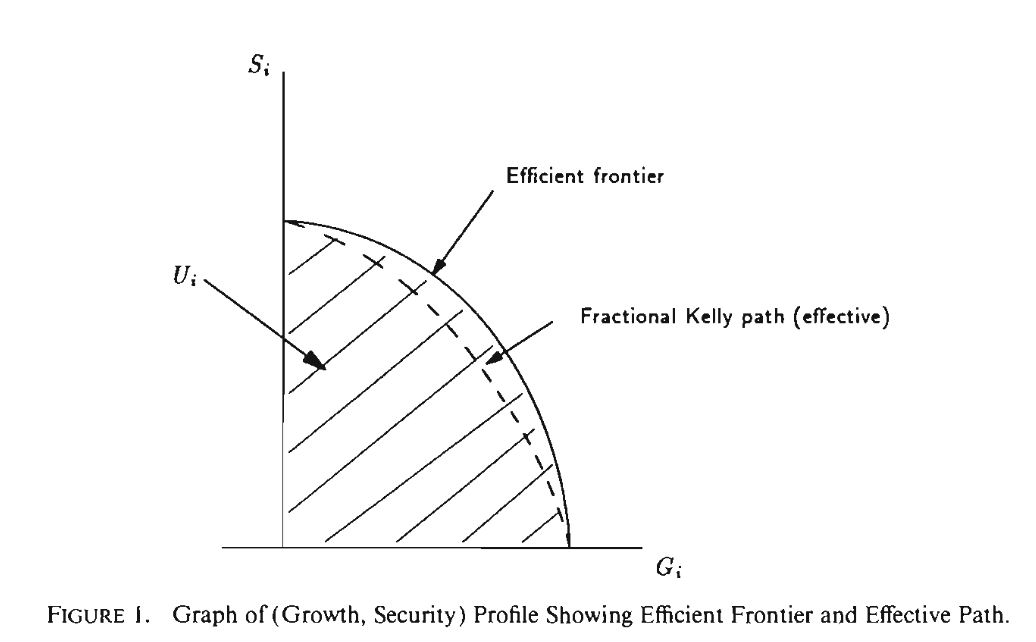
Fractional Kelly efficiently trades off "growth" against "security"
(This is mostly a summary of Growth Versus Security in Dynamic Investment Analysis and some extensions of the results in MacLean, Ziemba, Li)
Given growth goals:
- Expected wealth at a fixed time (I believe this is also true for any utility of wealth, although the algebra is pretty hairy)
- Expected growth rate
- Expected time to achieve given wealth level U
and security goals:
- Probability of having at least a given wealth at time t
- Probability wealth is above a specified path
- Probability of achieving a wealth U without drawing down to wealth W
The first paper shows that fractional Kelly is monotonic in each of these. That is for any increase in growth it is being traded off against an increase in security (and doing so in a convex way). For lognormal assets, the second paper shows that fractional Kelly is optimal. There is a fair amount of handwaving in the literature about how close to optimal fractional Kelly is when we're not in a lognormal world. It generally appears to be "quite".
One way to figure out your Kelly fraction
I am not one of these people who sees massive betting opportunities on a daily basis. (But if you are - let me know, I'm open to seeing any opportunities I'm missing). I think for most people, "true" Kelly betting opportunities come up fairly rarely, but they are the best opportunities to find out what Kelly fraction you are comfortable with:
- How much did you bet on Biden? What did you think the fair odds were?
- How much did you bet on Mayweather-McGregor?
Conclusion
- Never Go Full Kelly
- Adjust your posterior for information the market has
- Adjust your Kelly fraction by your posterior uncertainty
- "Our edge is is market error; market edge is our error"
- Consider how aggressive Full Kelly is, and if that's truly your risk appetite
Thanks to gjm and johnswentworth for comments on earlier versions. I'm still not fully happy with this, but it's much better than it was. (Improvements are all due to them, issues are all me).
7 comments
Comments sorted by top scores.
comment by abramdemski · 2021-02-27T01:47:38.815Z · LW(p) · GW(p)
Thanks for writing this!
Just to be pedantic, I wanted to mention: if we take Fractional Kelly as the average-with-market-beliefs thing, it's actually full Kelly in terms of our final probability estimate, having updated on the market :)
Concerning your first argument, that uncertainty leads to fractional Kelly -- is the idea:
- We have a probability estimate , which comes from estimating the true frequency ,
- Our uncertainty follows a Beta distribution,
- We have to commit to a fractional Kelly strategy based on our and never update that strategy ever again
?
So the graph shows what happens if we take our uncertainty and keep it as-is, not updating on data, as we continue to update?
Or is it that we keep updating (and hence reduce our uncertainty), but nonetheless, keep our Kelly fraction fixed (so we don't converge to full Kelly even as we become increasingly certain)?
Also, I don't understand the graph. (The third graph in your post.) You say that it shows growth rate vs Kelly fraction. Yet it's labeled "expected utility". I don't know what "expected utility" means, since the expected utility should grow unboundedly as we increase the number of iterations.
Or maybe the graph is of a single step of Kelly investment, showing expected log returns? But then wouldn't Kelly be optimal, given that Kelly maximizes log-wealth in expectation, and in this scenario the estimate is going to be right on average, when we sample from the prior?
Anyway, I'm puzzled about this one. What exactly is the take-away? Let's say a more-or-less Bayesian person (with uncertainty about their utilities and probabilities) buys the various arguments for Kelly, so they say, "In practice, my utility is more or less logarithmic in cash, at least in so far as it pertains to situations where I have repeated opportunities to invest/bet".
Then they read your argument about parameter uncertainty.
Now lets assume there's some uncertainty in that. (Bayesians might get a little uncomfortable here - posterior distributions for discrete events are point estimates. Instead imagine you view the event as a Bernoulli random variable with parameter p, and you have a posterior distribution for p.*).
BAYESIAN: Wait, what? I agree I'll have parameter uncertainty. But we've already established that my utility is roughly logarithmic in money. My point estimate (my posterior) for this gamble paying off is . The optimal bet under these assumptions is Kelly. So what are you saying? Perhaps you're arguing that my best-estimate probability isn't really .
OTHER: No, is really your best-estimate probability. I'm pointing to your model uncertainty.
BAYESIAN: Perhaps you're saying that my utility isn't really logarithmic? That I should be more risk-averse in this situation?
OTHER: No, my argument doesn't involve anything like that.
BAYESIAN: So what am I missing? Log utility, probability , therefore Kelly.
OTHER: Look, one of the ways we can argue for Kelly is by studying the iterated investment game, right? We look at the behavior of different strategies in the long term in that game. And we intuitively find that strategies which don't maximize growth (EG the expected-money-maximizer) look pretty dumb. So we conclude that our values must me closer to the growth-maximizer, ie Kelly, strategy.
BAYESIAN: Right; that's part of what convinced me that my values must be roughly logarithmic in money.
OTHER: So all I'm trying to do is examine the same game. But this time, rather than assuming we know the frequency of success from the beginning, I'm assuming we're uncertain about that frequency.
BAYESIAN: Right... look, when I accepted the original Kelly argument, I wasn't really imagining this circumstance where we face the exact same bet over and over. Rather, I was imagining I face lots of different situations. So long as my probabilities are calibrated, the long-run frequency argument works out the same way. Kelly looks optimal. So what's your beef with me going "full Kelly" on those estimates?
OTHER: In those terms, I'm examining the case where probabilities aren't calibrated.
BAYESIAN: That's not so hard to fix, though. I can make a calibration graph of my long-term performance. I can try to adjust my probability estimates based on that. If my 70% probability events tend to come back true 60% of the time, I adjust for that in the future. I've done this. You've done this.
OTHER: Do you really think your estimates are calibrated, now?
BAYESIAN: Not precisely, but I could put more work into it if I wanted to. Is this your crux? Would you be happy for me to go Full Kelly if I could show you a perfect x=y line on my calibration graph? Are you saying you can calculate the value for my fractional Kelly strategy from my calibration graph?
OTHER: ... maybe? I'd have to think about how to do the calculation. But look, even if you're perfectly calibrated in terms of past data, you might be caught off guard by a sudden change in the state of affairs.
BAYESIAN: Hm. So let's grant that there's uncertainty in my calibration graph. Are you saying it's not my current point-estimate of my calibration that matters, but rather, my uncertainty about my calibration?
OTHER: I fear we're getting overly meta. I do think should be lower the more uncertain you are about your calibration you are, in addition to lower the lower your point-estimate calibration is. But let's get a bit more concrete. Look at the graph. I'm showing that you can expect better returns with lower in this scenario. Is that not compelling?
BAYESIAN (who at this point regresses to just being Abram again): See, that's my problem. I don't understand the graph. I'm kind of stuck thinking that it represents someone with their hands tied behind their back, like they can't perform a Bayes update to improve their estimate , or they can't change their after the start, or something.
Replies from: SimonM↑ comment by SimonM · 2021-02-27T09:41:20.039Z · LW(p) · GW(p)
Just to be pedantic, I wanted to mention: if we take Fractional Kelly as the average-with-market-beliefs thing, it's actually full Kelly in terms of our final probability estimate, having updated on the market :)
Yes - I absolutely should have made that clearer.
Concerning your first argument, that uncertainty leads to fractional Kelly -- is the idea:
- We have a probability estimate , which comes from estimating the true frequency ,
- Our uncertainty follows a Beta distribution,
- We have to commit to a fractional Kelly strategy based on our and never update that strategy ever again
Sort of? 1. Yes, 2. no, 3. kinda.
I don't think it's an argument which leads to fractional Kelly. It's an argument which leads to "less than Kelly with a fraction which varies with your uncertainty". This (to be clear) is not fractional Kelly, where I think we're talking about a situation where the fraction is constant.
The chart I presented (copied from the Baker-McHale paper) does assume a beta distribution, and the "rule-of-thumb" which comes from that paper also assumes a beta distribution. The result that "uncertainty => go sub-Kelly" is robust to different models of uncertainty.
The first argument doesn't really make a case for fractional Kelly. It makes a case for two things:
- Strong case: you should (unless you have really skewed uncertainty) be betting sub-Kelly
- Rule-of-thumb: you can approximate how much sub-Kelly you should go using this formula. (Which isn't a fixed
So the graph shows what happens if we take our uncertainty and keep it as-is, not updating on data, as we continue to update?
Yes. Think of it as having a series of bets on different events with the same uncertainty each time.
Also, I don't understand the graph. (The third graph in your post.) You say that it shows growth rate vs Kelly fraction. Yet it's labeled "expected utility". I don't know what "expected utility" means, since the expected utility should grow unboundedly as we increase the number of iterations.
Or maybe the graph is of a single step of Kelly investment, showing expected log returns? But then wouldn't Kelly be optimal, given that Kelly maximizes log-wealth in expectation, and in this scenario the estimate is going to be right on average, when we sample from the prior?
Yeah - the latter - I will edit this to make it clearer. This is "expected utility" for one-period. (Which is equivalent to growth rate). I just took the chart from their paper and didn't want to edit it. (Although that would have made things clearer. I think I'll just generate the graph myself).
Looking at the bit I've emphasised. No! This is the point. When is too large, this error costs you more than when it's too small.
I think our confusion is coming from the fact we're thinking about two different scenarios:
Here I am considering (notice the Kelly fraction depending on inside the utility but not outside). "What is my expected utility, if I bet according to Kelly given my estimate". (Ans: Not Full Kelly)
I think you are talking about the scenario ? (Ans: Full Kelly)
I'm struggling to extract the right quotes from your dialogue, although I think there are several things where I don't think I've managed to get my message across:
OTHER: In those terms, I'm examining the case where probabilities aren't calibrated.
I'm trying to find the right Bayesian way to express this, without saying the word "True probability". Consider a scenario where we're predicting a lot of (different) sports events. We could both be perfectly calibrated (what you say happens 20% of the time happens 20% of the time) etc, but I could be more "uncertain" with my predictions. If my prediction is always 50-50 I am calibrated, but I really shouldn't be betting. This is about adjusting your strategy for this uncertainty.
OTHER: So all I'm trying to do is examine the same game. But this time, rather than assuming we know the frequency of success from the beginning, I'm assuming we're uncertain about that frequency.
BAYESIAN: Right... look, when I accepted the original Kelly argument, I wasn't really imagining this circumstance where we face the exact same bet over and over. Rather, I was imagining I face lots of different situations. So long as my probabilities are calibrated, the long-run frequency argument works out the same way. Kelly looks optimal. So what's your beef with me going "full Kelly" on those estimates?
No, my view were always closer to BAYESIAN here. I think we're looking at a variety of different bets but where my probabilities are calibrated but uncertain. Being calibrated isn't the same as being right. I have always assumed here that you are calibrated.
BAYESIAN: Not precisely, but I could put more work into it if I wanted to. Is this your crux? Would you be happy for me to go Full Kelly if I could show you a perfect x=y line on my calibration graph? Are you saying you can calculate the value for my fractional Kelly strategy from my calibration graph?
OTHER: ... maybe? I'd have to think about how to do the calculation. But look, even if you're perfectly calibrated in terms of past data, you might be caught off guard by a sudden change in the state of affairs.
No, definitely not. Your calibration graph really isn't relevant to me here.
BAYESIAN (who at this point regresses to just being Abram again): See, that's my problem. I don't understand the graph. I'm kind of stuck thinking that it represents someone with their hands tied behind their back, like they can't perform a Bayes update to improve their estimate , or they can't change their after the start, or something.
This is almost certainly "on me". I really don't think I'm talking about a person who can't update their estimate and I advocate people adjusting their fraction. I think there's something which I've not made clear but I'm not 100% I know we've found what it is yet.
The strawman of your argument (which I'm struggling to understand where you differ) is. "A Bayesian with log-utility is repeatedly offered bets (mechanism for choosing bets unclear) against an unfair coin. His prior is that the coin comes up heads is uniform [0,1]. He should bet Full Kelly with p = 1/2 (or slightly less than Full Kelly once he's updated for the odds he's offered)". I don't think he should take any bets. (I'm guessing you would say that he would update his strategy each time to the point where he no longer takes any bets - but what would he do the first time? Would he take the bet?)
Replies from: abramdemski↑ comment by abramdemski · 2021-02-28T21:32:23.949Z · LW(p) · GW(p)
This (to be clear) is not fractional Kelly, where I think we're talking about a situation where the fraction is constant.
In the same way that "the Kelly strategy" in practice refers to betting a variable fraction of your wealth (even if the simple scenarios used to illustrate/derive the formula involve the same bet repeatedly, so the Kelly strategy is one which implies betting a fixed fraction of wealth), I think it's perfectly sensible to use "fractional Kelly" to describe a strategy which takes a variable fraction of the Kelly bet, using some formula to determine the fraction (even if the argument we use to establish the formula is one where a constant Kelly fraction is optimal).
What I would take issue with would be an argument for fractional Kelly which assumed we should use a constant Kelly fraction (as I said, "tying the agent's hands" by only looking at strategies where some constant Kelly fraction is chosen). Because then it's not clear whether some fractional-Kelly is the best strategy for the described scenario; it's only clear that you've found some formula for which fractional-Kelly is best in a scenario, given that you're using some fractional Kelly.
Which was one of my concerns about what might be going on with the first argument.
The result that "uncertainty => go sub-Kelly" is robust to different models of uncertainty.
I find myself really wishing that you'd use slightly more Bayesian terminology. Kelly betting is already a rule for betting under uncertainty. You're specifically saying that meta-uncertainty implies sub-kelly. (Or parameter uncertainty, or whatever you want to call it.)
I’m trying to find the right Bayesian way to express this, without saying the word “True probability”.
I appreciate the effort :)
So the graph shows what happens if we take our uncertainty and keep it as-is, not updating on data, as we continue to update?
Yes. Think of it as having a series of bets on different events with the same uncertainty each time.
Right... so in this case, it pretty strongly seems to me like the usual argument for Kelly applies. If you have a series of different bets in which you have the same meta-uncertainty, either your meta-uncertainty is calibrated, in which case your probability estimates will be calibrated, so the Kelly argument works as usual, or your meta-uncertainty is uncalibrated, in which case I just go meta on my earlier objections: why aren't we updating our meta-uncertainty? I'm fine with assuming repeated different bets (from different reference classes) with the same parameter uncertainty being applied to all of them so long as it's apparently sensible to apply the same meta-uncertainty to all of them. But systematic errors in your parameter uncertainty (such that you can look at a calibration graph and see the problem) should trigger an update in the general priors you're using.
Here I am considering ∫ (notice the Kelly fraction depending on inside the utility but not outside). "What is my expected utility, if I bet according to Kelly given my estimate". (Ans: Not Full Kelly)
I think you are talking about the scenario ∫? (Ans: Full Kelly)
(Sorry, had trouble copying the formulae on greaterwrong)
I think what you're pointing to here is very much like the difference between unbiased estimators and bayes-optimal estimators, right? Frequentists argue that unbiased estimators are better, because given any value of the true parameter, an unbiased estimator is in some sense doing a better job of approximating the right answer. Bayesians argue that Bayesian estimators are better, because of the bias-variance trade-off, and because you expect the Bayesian estimator to be more accurate in expectation (the whole point of accounting for the prior is to be more accurate in more typical situations).
I think the Bayesians pretty decisively win that particular argument; as an agent with a subjective perspective, you're better off doing what's best from within that subjective perspective. The Frequentist concept is optimizing based on a God's-eye view, where we already know . In this case, it leads us astray. The God's-eye view just isn't the perspective from which a situated agent should optimize.
Similarly, I think it's just not right to optimize the formula you give, rather than the one you attribute to me. If I have parameter uncertainty, then my notion of the expected value of using fractional Kelly is going to come from sampling from my parameter uncertainty, and checking what the expected payoffs are for each sample.
But then, as you know, that would just select a Kelly fraction of 1.
So if that formula describes your reasoning, I think you really are making the "true probability" mistake, and that's why you're struggling to put it in terms that are less objectionable from the Bayesian perspective. (Which, again, I don't think is always right, but which I think is right in this case.)
(FYI, I'm not really arguing against fractional Kelly; full Kelly really does seem too high in some sense. I just don't think this particular argument for fractional Kelly makes sense.)
Consider a scenario where we’re predicting a lot of (different) sports events. We could both be perfectly calibrated (what you say happens 20% of the time happens 20% of the time) etc, but I could be more “uncertain” with my predictions. If my prediction is always 50-50 I am calibrated, but I really shouldn’t be betting. This is about adjusting your strategy for this uncertainty.
I think what's going on in this example is that you're setting it up so that I know strictly more about sports than you. You aren't willing to bet, because anything you know about the situation, I know better. In terms of your post, this is your second argument in favor of Kelly. And I think it's the explanation here. I don't think your meta-uncertainty has much to do with it.
Particularly if, as you posit, you're quite confident that 50-50 is calibrated. You have no parameter uncertainty: your model is that of a fair coin, and you're confident it's the best model in the coin-flip model class.
BAYESIAN: Right… look, when I accepted the original Kelly argument, I wasn’t really imagining this circumstance where we face the exact same bet over and over. Rather, I was imagining I face lots of different situations. So long as my probabilities are calibrated, the long-run frequency argument works out the same way. Kelly looks optimal. So what’s your beef with me going “full Kelly” on those estimates?
No, my view were always closer to BAYESIAN here. I think we’re looking at a variety of different bets but where my probabilities are calibrated but uncertain. Being calibrated isn’t the same as being right. I have always assumed here that you are calibrated.
Then you concede the major assumption of BAYESIAN's argument here! Under the calibration assumption, we can show that the long-run performance of Kelly is optimal (in the peculiar sense of optimality usually applied to Kelly, that is).
I'm curious how you would try and apply something like your formula to the mixed-bet case (ie, a case where you don't have the same meta-uncertainty each time).
The strawman of your argument (which I’m struggling to understand where you differ) is. “A Bayesian with log-utility is repeatedly offered bets (mechanism for choosing bets unclear) against an unfair coin. His prior is that the coin comes up heads is uniform [0,1]. He should bet Full Kelly with p = 1⁄2 (or slightly less than Full Kelly once he’s updated for the odds he’s offered)”. I don’t think he should take any bets. (I’m guessing you would say that he would update his strategy each time to the point where he no longer takes any bets—but what would he do the first time? Would he take the bet?)
Here's how I would fix this strawman. Note that the fixed strawman is still straw in the sense that I'm not actually arguing for full Kelly, I'm just trying to figure out your argument against it.
"A Bayesian with log-utility is repeatedly offered bets (coming from a rich, complex environment which I'm making no assumptions about, not even computability). His probabilities are, however, calibrated. Then full Kelly will be optimal."
Probably there are a few different ways to mathify what I mean by "optimal" in this argument. Here are some observations/conjectures:
- Full Kelly optimizes the expected utility of this agent, obviously. So if the agent really has log utility, and really is a Bayesian, clearly it'll go full Kelly.
- After enough bets, since we're calibrated, we can assume that the frequency of success for bets will closely match . So we can make the usual argument that full Kelly will be very close to optimal: ** Fractional Kelly, or other modified Kelly formulas, will make less money. ** In general, any other strategy will make less money in the long run, under the assumption that long-run frequencies match probabilities -- so long as that strategy does not contain further information about the world.
(For example, in your example where you have an ignorant but calibrated 50-50 model, maybe the true world is "yes on even-numbered dates, no on odd". A strategy based on this even-odd info could outperform full Kelly, obviously. The claim is that so long as you're not doing something like that, full Kelly will be approximately best.)
I think there’s something which I’ve not made clear but I’m not 100% I know we’ve found what it is yet.
My current estimate is that this is 100% about the frequentist Gods-eye-view way of arguing, where you evaluate the optimality of something by supposing a "true probability" and thinking about how well different strategies do as a function of that.
If so, I'll be curious to hear your defense of the gods-eye perspective in this case.
One thing I want to make clear is that I think there's something wrong with your argument on consequentialist grounds.
Or maybe the graph is of a single step of Kelly investment, showing expected log returns? But then wouldn’t Kelly be optimal, given that Kelly maximizes log-wealth in expectation, and in this scenario the estimate is going to be right on average, when we sample from the prior?
Yeah—the latter—I will edit this to make it clearer. This is “expected utility” for one-period. (Which is equivalent to growth rate). I just took the chart from their paper and didn’t want to edit it. (Although that would have made things clearer. I think I’ll just generate the graph myself).
Looking at the bit I’ve emphasised. No! This is the point.
I want to emphasize that I also think there's something consequentialistly weird about your position. As non-Bayesian as some arguments for Kelly are, we can fit the Kelly criterion with Bayes, by supposing logarithmic utility. So a consequentialist can see those arguments as just indirect ways of arguing for logarithmic utility.
Not so with your argument here. If we asses a gamble as having probability , then what could our model uncertainty have to do with anything? Model uncertainty can decrease our confidence that expected events will happen, but already prices that in. Model uncertainty also changes how we'll reason later, since we'll update on the results here (and wouldn't otherwise do so). But, that doesn't matter until later.
We're saying: "Event might happen, with probability ; event might happen, with probability ." Our model uncertainty grants more nuance to this model by allowing us to update it on receiving more information; but in the absence of such an update, it cannot possibly be relevant to the consequences of our strategies in events and . Unless there's some funny updateless stuff going on, which you're clearly not supposing.
From a consequentialist perspective, then, it seems we're forced to evaluate the expected utility in the same way whether we have meta-uncertainty or not.
comment by abramdemski · 2021-03-01T19:39:21.017Z · LW(p) · GW(p)
I would be interested if you could say more about the CRRA-optimality point. Does this give us the class of utility functions which prefer fractional Kelly to full Kelly? What do those functions look like?
Replies from: amaury-lorin↑ comment by momom2 (amaury-lorin) · 2023-05-12T18:08:44.814Z · LW(p) · GW(p)
I also would be interested in learning more, even just a link would be nice.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2021-02-26T18:59:21.258Z · LW(p) · GW(p)
I initially gave this post a double upvote after a skim-read. The topic is of clear interest, and these ideas are new to me. Unfortunately, after taking a closer look I found the details difficult to follow. I decided to look at the linked paper. It seems you are trying to summarize this paper, perhaps this could be stated clearly at the top of the post.
Replies from: SimonM