Posts
Comments
While I enjoy Derek Lowe, the extent to which his posts are inside-baseball and do not repeat themes, or only repeat many years apart, emphasize the contrast with Levine.
The original post also addresses this suggestion
Your definition of the Heaviside step function has H(0) = 1.
Your definition of L has L(0) = 1/2, so you're not really taking the derivative of the same function.
I don't really believe nonstandard analysis helps us differentiate the Heaviside step function. You have found a function that is quite a lot like the step function and shown that it has a derivative (maybe), but I would need to be convinced that all functions have the same derivative to be convinced that something meaningful is going on. (And since all your derivatives have different values, this seems like a not useful definition of a derivative)
The log-returns are not linear in the bits. (They aren't even constant for a given level of bits.)
For example, say the market is 1:1, and you have 1 bit of information: you think the odds are 1:2, then Kelly betting you will bet 1/3 of your bankroll and expect to make a ~20% log-return.
Say the market was 1:2, and you had 1 bit of information: you think the odds are 1:4, then Kelly betting, you will bet 1/5 of your bankroll and expect to make a ~27% log-return.
We've already determined that quite different returns can be obtained for the same amount of information.
To get some idea of what's going on, we can plot various scenarios, how much log-returns does the additional bit (or many bits) generate for a fixed market probability. (I've plotted these as two separate charts - one where the market already thinks an event is evens or better,
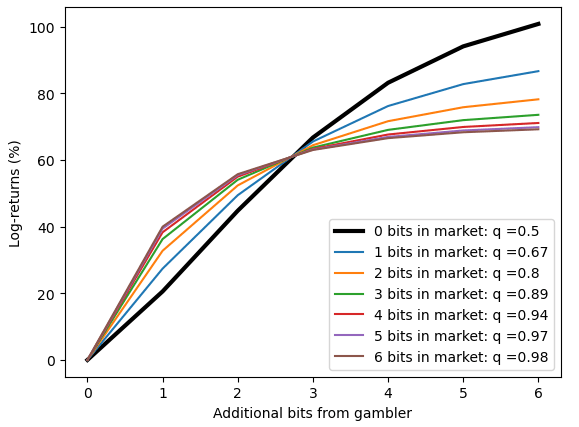
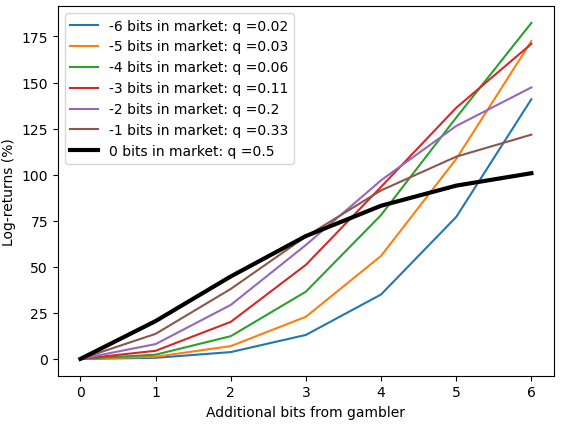
For example, we can spot where the as the market thinks an event is more likely (first chart, 0 bits in the market, 1 bit in the market, etc) and looking at the point where we have 1 bit, we can where we expect to make 20%, then 27% [the examples I worked through first], and more-and-more as the market becomes more confident.
The fact that 1 bit has relatively little value when the market has low probability is also fairly obvious. When there are fairly long odds, 2^(n+1):1 and you think it should be 2^n:1, you will bet approximately(!) 1/2^n, to approximately(!) either double your bankroll or leave it approximately(!) unchanged. So the log-return of these outcomes is capped, but the probability of success keeps declining
There's also a meta-question here which is - why would you expect a strict relationship between bits and return. Ignoring the Kelly framework, we could just look at the expected value of 1 bit of information. The expected value of a market currently priced at q, which should be priced at p is p-q.
When the market has no information (it's 1:1) a single bit is valuable, but when a market has lots of information the marginal bit doesn't move the probabilities as much (and therefore the expected value is smaller)
When this paradox gets talked about, people rarely bring up the caveat that to make the math nice you're supposed to keep rejecting this first bet over a potentially broad range of wealth.
This is exactly the first thing I bring up when people talk about this.
But counter-caveat: you don't actually need a range of $1,000,000,000. Betting $1000 against $5000, or $1000 against $10,000, still sounds appealing, but the benefit of the winnings is squished against the ceiling of seven hundred and sixty nine utilons all the same. The logic doesn't require that the trend continues forever.
I don't think so? The 769 limit is coming from never accepting the 100/110 bet at ANY wealth, which is a silly assumption
Thus, an attacker, knowing this, could only reasonably expect to demand half the amount to get paid.
Who bears the cost of a tax depends on the elasticities of supply and demand. In the case of a ransomware attack, I would expect the vast majority of the burden to fall on the victim.
I wrote about exactly this recently- https://www.lesswrong.com/posts/zLnHk9udC28D34GBB/prediction-markets-aren-t-magic
I don't give much weight to his diagnosis of problematic group decision mechanisms
I have quite a lot of time for it personally.
The world is dominated by a lot of large organizations that have a lot of dysfunction. Anybody over the age of 40 will just agree with me on this. I think it's pretty hard to find anybody who would disagree about that who's been around the world. Our world is full of big organizations that just make a lot of bad decisions because they find it hard to aggregate information from all the different people.
This is roughly Hanson's reasoning, and you can spell out the details a bit more. (Poor communication between high level decision makers and shop-floor workers, incentives at all levels dissuading truth telling etc). Fundamentally though I find it hard to make a case this isn't true in /any/ large organization. Maybe the big tech companies can make a case for this, but I doubt it. Office politics and self-interest are powerful forces.
For employment decisions, it's not clear that there is usable (legally and socially tolerated) information which a market can provide
I roughly agree - this is the point I was trying to make. All the information is already there in interview evaluations. I don't think Robin is expecting new information though - he's expecting to combine the information more effectively. I just don't expect that to make much difference in this case.
So the first question is: "how much should we expect the sample mean to move?".
If the current state is , and we see a sample of (where is going to be 0 or 1 based on whether or not we have heads or tails), then the expected change is:
In these steps we are using the facts that ( is independent of the previous samples, and the distribution of is Bernoulli with . (So and ).
To do the proper version of this, we would be interested in how our prior changes, and our distribution for wouldn't purely be a function of . This will reduce the difference, so I have glossed over this detail.
The next question is: "given we shift the market parameter by , how much money (pnl) should we expect to be able to extract from the market in expectation?"
For this, I am assuming that our market is equivalent to a proper scoring rule. This duality is laid out nicely here. Expending the proper scoring rule out locally, it must be of the form , since we have to be at a local minima. To use some classic examples, in a log scoring rule:
in a brier scoring rule:
Whoops. Good catch. Fixing
x is the result of the (n+1)th draw sigma is the standard deviation after the first n draws pnl is the profit and loss the bettor can expect to earn
Prediction markets generate information. Information is valuable as a public good. Failure of public good provision is not a failure of prediction markets.
I think you've slightly missed my point. My claim is narrower than this. I'm saying that prediction markets have a concrete issue which means you should expect them to be less efficient at gathering data than alternatives. Even if information is a public good, it might not be worth as much as prediction markets would charge to find that information. Imagine if the cost of information via a prediction market was exponential in the cost of information gathering, that wouldn't mean the right answer is to subsidise prediction markets more.
If you have another suggestion for a title, I'd be happy to use it
Even if there is no acceptable way to share the data semi-anonymously outside of match group, the arguments for prediction markets still apply within match group. A well designed prediction market would still be a better way to distribute internal resources and rewards amongst competing data science teams within match group.
I used to think things like this, but now I disagree, and actually think it's fairly unlikely this is the case.
- Internal prediction markets have tried (and failed) at multiple large organisations who made serious efforts to create them
- As I've explained in this post, prediction markets are very inefficient at sharing rewards. Internal to a company you are unlikely to have the right incentives in place as much as just subsidising a single team who can share models etc. The added frictions of a market are substantial.
- The big selling points of prediction markets (imo) come from:
- Being able to share results without sharing information (ie I can do some research, keep the information secret, but have people benefit from the conclusions)
- Incentivising a wider range of people. At an orgasation, you'd hire the most appropriate people into your data science team and let them run. There's no need to wonder if someone from marketing is going to outperform their algorithm.
People who actually match and meetup with another user will probably have important inside view information inaccessible to the algorithms of match group.
I strongly agree. I think people often confuse "market" and "prediction market". There is another (arguably better) model of dating apps which is that the market participants are the users, and the site is actually acting as a matching engine. Since I (generally) think markets are great, this also seems pretty great to me.
Sure - but that answer doesn't explain their relative lack of success in other countries (eg the UK)
Additionally, where prediction markets work well (eg sports betting, political betting) there is a thriving offshore market catering to US customers.
This post triggered me a bit, so I ended up writing one of my own.
I agree the entire thing is about how to subsidise the markets, but I think you're overestimating how good markets are as a mechanism for subsidising forecasting (in general). Specifically for your examples:
- Direct subsidies are expensive relative to the alternatives (the point of my post)
- Hedging doesn't apply in lots of markets, and in the ones where it does make sense those markets already exist. (Eg insurance)
- New traders is a terrible idea as you say. It will work in some niches (eg where there's lots of organic interest, but it wont work at scale for important things)
I'm excited about the potential of conditional prediction markets to improve on them and solve two-sided adverse selection.
This applies to roughly the entire post, but I see an awful lot of magical thinking in this space. What is the actual mechanism by which you think prediction markets will solve these problems?
In order to get a good prediction from a market you need traders to put prices in the right places. This means you need to subsidise the markets. Whether or not a subsidised prediction market is going to be cheaper for the equivalent level of forecast than paying another 3rd party (as is currently the case in most of your examples) is very unclear to me
A thing Larry Summers once said that seems relevant, from Elizabeth Warren:
He said something very similar to Yanis Varoufakis (https://www.globaljustice.org.uk/blog/2017/06/when-yanis-met-prince-darkness-extract-adults-room/) and now I like to assume he goes around saying this to everyone
No, it's fairly straightforward to see this won't work
Let N be the random variable denoting the number of rounds. Let x = p*w+(1-p)*l where p is probability of winning and w=1-f+o*f, l=1-f the amounts we win or lose betting a fraction f of our wealth.
Then the value we care about is E[x^N], which is the moment generating function of X evaluated at log(x). Since our mgf is increasing as a function of x, we want to maximise x. ie our linear utility doesn't change
Yes? 1/ it's not in their mandate 2/ they've never done it before (I guess you could argue the UK did for in 2022, but I'm not sure this is quite the same) 3/ it's not clear that this form of QE would have the effect you're expecting on long end yields
I absolutely do not recommend shorting long-dated bonds. However, if I did want to do so a a retail investor, I would maintain a rolling short in CME treasury futures. Longest future is UB. You'd need to roll your short once every 3 months, and you'd also want to adjust the size each time, given that the changing CTD means that the same number of contracts doesn't necessarily mean the same amount of risk each expiry.
Err... just so I'm clear lots of money being printed will devalue those long dated bonds even more, making the bond short an even better trade? (Or are you talking about some kind of YCC scenario?)
average returns
I think the disagreement here is on what "average" means. All-in maximises the arithmetic average return. Kelly maximises the geometric average. Which average is more relevant is equivalent to the Kelly debate though, so hard to say much more
Wouldn’t You Prefer a Good Game of Chess?
I assume this was supposed to be a WarGames reference, in which case I think it should be a "nice" game of chess.
Yeah, and it doesn't adjust for taxes there either. I thought this was less of an issue when comparing rents to owning though, as the same error should affect both equally.
This doesn't seem to account for property taxes, which I expect would change the story quite a bit for the US.
This seems needlessly narrow minded. Just because AI is better than humans doesn't make it uniformly better than humans in all subtasks of chess.
I don't know enough about the specifics that this guy is talking about (I am not an expert) but I do know that until the release of NN-based algorithms most top players were still comfortable talking about positions where the computer was mis-evaluating positions soon out of the opening.
To take another more concrete example - computers were much better than humans in 2004, and yet Peter Leko still managed to refute a computer prepared line OTB in a world championship game.
Agreed - as I said, the most important things are compute and dilligence. Just because a large fraction of the top games are draws doesn't really say much about whether or not there is an edge being given by the humans (A large fraction of elite chess games are draws, but no-one doubts there are differences in skill level there). Really you'd want to see Jon Edward's setup vs a completely untweaked engine being administered by a novice.
I believe the answer is potentially. The main things which matter in high-level correspondence chess are:
- Total amount of compute available to players
- Not making errors
Although I don't think either of those are really relevant. The really relevant bit is (apparently) planning:
For me, the key is planning, which computers do not do well — Petrosian-like evaluations of where pieces belong, what exchanges are needed, and what move orders are most precise within the long-term plan.
(From this interview with Jon Edwards (reigning correspondence world champion) from New In Chess)
I would highly recommend the interview on Perpetual Chess podcast also with Jon Edwards which I would also recommend.
I'll leave you with this final quote, which has stuck with me for ages:
The most important game in the Final was my game against Osipov. I really hoped to win in order to extend my razor-thin lead, and the game’s 119 moves testify to my determination. In one middlegame sequence, to make progress, I had to find a way to force him to advance his b-pawn one square, all while avoiding the 50-move rule. I accomplished the feat in 38 moves, in a sequence that no computer would consider or find. Such is the joy of high-level correspondence chess. Sadly, I did not subsequently find a win. But happily, I won the Final without it!
I agree, as I said here
Just in case anyone is struggling to find the relevant bits of the the codebase, my best guess is the link for the collections folder in github is now here.
You are looking in "views.ts" eg .../collections/comments/views.ts
The best thing to search for (I found) was ".addView(" and see what fits your requirements
I feel in all these contexts odds are better than log-odds.
Log-odds simplifies Bayesian calculations: so does odds. (The addition becomes multiplication)
Every number is meaningful: every positive number is meaningful and the numbers are clearer. I can tell you intuitively what 4:1 or 1:4 means. I can't tell you what -2.4 means quickly, especially if I have to keep specifying a base.
Certainty is infinite: same is true for odds
Negation is the complement and 0 is neutral: Inverse is the complement and 1 is neutral. 1:1 means "I don't know" and 1:x is the inverse of x:1. Both ot these are intuitive to me.
No - I think probability is the thing supposed to be a martingale, but I might be being dumb here.
So, what do you think? Does this method seem at all promising? I'm debating with myself whether I should begin using SPIES on Metaculus or elsewhere.
I'm not super impressed tbh. I don't see "give a 90% confidence interval for x" as a question which comes up frequently? (At least in the context of eliciting forecasts and estimates from humans - it comes up quite a bit in data analysis).
For example, I don't really understand how you'd use it as a method on Metaculus. Metaculus has 2 question types - binary and continuous. For binary you have to give the probability an event happens - not sure how you'd use SPIES to help here. For continuous you are effectively doing the first step of SPIES - specifying the full distribution.
If I was to make a positive case for this, it would be - forcing people to give a full distribution results in better forecasts for sub-intervals. This seems an interesting (and plausible claim) but I don't find anything beyond that insight especially valuable.
17. Unemployment below five percent in December: 73 (Kalshi said 92% that unemployment never goes above 6%; 49 from Manifold)
I'm not sure exactly how you're converting 92% unemployment < 6% to < 5%, but I'm not entirely convinced by your methodology?
15. The Fed ends up doing more than its currently forecast three interest rate hikes: None (couldn't find any markets)
Looking at the SOFR Dec-22 3M futures 99.25/99.125 put spread on the 14-Feb, I put this probability at ~84%.
Thanks for doing this, I started doing it before I saw your competition and then decided against since it would have made cheating too easy. (Also why I didn't enter)
And one way to accomplish that would be to bet on what percentage of bets are on "uncertainty" vs. a prediction.
How do you plan on incentivising people to bet on "uncertainty"? All the ways I can think of lead to people either gaming the index, or turning uncertainty into a KBC.
The market and most of the indicators you mentioned would be dominated by the 60 that placed large bets
I disagree with this. Volatility, liquidity, # predictors, spread of forecasts will all be affected by the fact that 20 people aren't willing to get involved. I'm not sure what information you think is being lost by people stepping away? (I guess the difference between "the market is wrong" and "the market is uninteresting"?)
There are a bunch of different metrics which you could look at on a prediction market / prediction platform to gauge how "uncertain" the forecast is:
- Volatility - if the forecast is moving around quite a bit, there are two reasons:
- Lots of new information arriving and people updating efficiently
- There is little conviction around "fair value" so traders can move the price with little capital
- Liquidity - if the market is 49.9 / 50.1 in millions of dollars, then you can be fairly confident that 50% is the "right" price. If the market is 40 / 60 with $1 on the bid and $0.50 on the offer, I probably wouldn't be confident the probability lies between 40 and 60, let along "50% is the right number". (The equivalent on prediction platforms might be number of forecasters, although CharlesD has done some research on this which suggests there's little addition value being added by large numbers of forecasters)
- "Spread of forecasts" - on Metaculus (for example) you can see a distribution of people's forecasts. If everyone is tightly clustered around 50% that (usually) gives me more confidence that 50% is the right number than if they are widely spread out
Prediction markets function best when liquidity is high, but they break completely if the liquidity exceeds the price of influencing the outcome. Prediction markets function only in situations where outcomes are expensive to influence.
There are a ton of fun examples of this failing:
- Libor
- "Chicken Libor"
- Every sport, all the time
- Option expiries (I don't have a good single link for this)
I don't know enough about how equities trade during earnings, but I do know a little about how some other products trade during data releases and while people are speaking.
In general, the vast, vast, vast majority of liquidity is withdrawn from the market before the release. There will be a few stale orders people have left by accident + a few orders left in at levels deemed ridiculously unlikely. As soon as the data is released, the fastest players will general send quotes making a (fairly wide market) around their estimate of the fair price. Over time (and here we're still talking very fast) more players will come in, firming up that new market.
The absolute level of money which is being made during this period is relatively small. It's not like the first person to see the report gets to trade at the old price, they get to trade with any stale orders - the market just reprices with very little trading volume.
All of the money-making value was redeemed before people like you and me even had a chance to trade. Right?
Correct, you absolutely did not have the chance to be involved in this trade unless you work at one of a handful of firms which have spent 9 figure sums on doing this really, really well.
I agree identifying model failure is something people can be good at (although I find people often forget to consider it). Pricing it they are usually pretty bad at.
I'd personally be more interested in asking someone for their 95% CI than their 68% CI, if I had to ask them for exactly one of the two. (Although it might again depend on what exactly I plain to do with this estimate.)
I'm usually much more interested in a 68% CI (or a 50% CI) than a 95% CI because:
- People in general arent super calibrated, especially at the tails
- You won't find out for a while how good their intervals are anyway
- What happens most often is usually the main interest. (Although in some scenarios the tails are all that matters, so again, depends on context - emphasis usually). I would like people to normalise narrower confidence intervals more.
- (as you note) the tails are often dominated by model failure, so you're asking a question less about their forecast, and more about their estimate of model failure. I want information about their model of the world rather than their beliefs about where their beliefs breakdown.
Under what assumption?
1/ You aren't "[assuming] the errors are normally distributed". (Since a mixture of two normals isn't normal) in what you've written above.
2/ If your assumption is then yes, I agree the median of is ~0.45 (although
from scipy import stats
stats.chi2.ppf(.5, df=1)
>>> 0.454936would have been an easier way to illustrate your point). I think this is actually the assumption you're making. [Which is a horrible assumption, because if it were true, you would already be perfectly calibrated].
3/ I guess you're new claim is "[assuming] the errors are a mixture of normal distributions, centered at 0", which okay, fine that's probably true, I don't care enough to check because it seems a bad assumption to make.
More importantly, there's a more fundamental problem with your post. You can't just take some numbers from my post and then put them in a different model and think that's in some sense equivalent. It's quite frankly bizarre. The equivalent model would be something like:
I think the controversy is mostly irrelevant at this point. Leela performed comparably to Stockfish in the latest TCEC season and is based on Alpha Zero. It has most of the "romantic" properties mentioned in the post.
That isn't a "simple" observation.
Consider an error which is 0.5 22% of the time, 1.1 78% of the time. The squared errors are 0.25 and 1.21. The median error is 1.1 > 1. (The mean squared error is 1)
Metaculus uses the cdf of the predicted distribution which is better If you have lots of predictions, my scheme gives an actionable number faster
You keep claiming this, but I don't understand why you think this
If you suck like me and get a prediction very close then I would probably say: that sometimes happen :) note I assume the average squared error should be 1, which means most errors are less than 1, because 02+22=2>1
I assume you're making some unspoken assumptions here, because is not enough to say that. A naive application of Chebyshev's inequality would just say that .
To be more concrete, if you were very weird, and either end up forecasting 0.5 s.d. or 1.1 s.d. away, (still with mean 0 and average squared error 1) then you'd find "most" errors are more than 1.
Go to your profile page. (Will be something like https://www.metaculus.com/accounts/profile/{some number}/). Then in the track record section, switch from Brier Score to "Log Score (continuous)"
The 2000-2021 VIX has averaged 19.7, sp500 annualized vol 18.1.
I think you're trying to say something here like 18.1 <= 19.7, therefore VIX (and by extension) options are expensive. This is an error. I explain more in detail here, but in short you're comparing expected variance and expected volatility which aren't the same thing.
From a 2ndary source: "The mean of the realistic volatility risk premium since 2000 has been 11% of implied volatility, with a standard deviation of roughly 15%-points" from https://www.sr-sv.com/realistic-volatility-risk-premia/ . So 1/3 of the time the premia is outside [-4%,26%], which swamps a lot of vix info about true expect vol.
I'm not going to look too closely at that, but anything which tries to say the VRP was solidly positive post 2015 just doesn't gel with my understanding of that market. (For example). (Also, fwiw anyone who quotes changes in volatility in percentages should be treated with suspicion at best)
-60% would the worst draw down ever, the prior should be <<1%. However, 8 years have been above 30% since 1928 (9%), seems you're using a non-symetric CI.
Yeah, it's not symmetric, but I wasn't the person who suggested it. All I'm saying is "OP says [interval] has probability 90%" "market says [interval] has probability 90%".
The reasoning for why there'd be such a drawdown is backwards in OP: because real rates are so low the returns for owning stocks has declined accordingly. If you expect 0% rates and no growth stocks are priced reasonably, yielding 4%/year more than bonds. Thinking in the level of rates not changes to rates makes more sense, since investments are based on current projected rates. A discounted cash flow analysis works regardless of how rates change year to year. Currently the 30yr is trading at 2.11% so real rates around the 0 bound is the consensus view.
OP being my post of arunto's?
There's several things unclear with this paragraph though:
- Stocks are currently 'yielding' 1.3% (dividend yield) or 3.9% ('earnings' yield). Not sure exactly what yield you think is 4% over bonds. (Or which maturity bond you're considering).
- "Thinking in the level of rates not changes to rates makes more sense, since investments are based on current projected rates.". The forward curve is upward sloping, yes, but if arunto thinks rates are going to change higher than what the market forecasts that will definitely change the price of equities. "A discounted cash flow analysis works regardless of how rates change year to year." Yes, but if you change the rates in your DCF you will change your price
- "Currently the 30yr is trading at 2.11% so real rates around the 0 bound is the consensus view.". Currently 30y real rates are -15bps after a steep sell-off after the start of the year. 30y real rates were as low as -60bps in December.
10y real rates are more like -75bps (up from -110bps in December).
"the 0 bound" is something people talk about in nominal space because the yield on cash is somewhere in that ballpark. (These days people generally think that figure should be around -50 to -100bps depending on which euro rates trader you speak to). For real rates there's no particular reason to think there is any significant bound - 10y real rates in the US have been negative since the start of 2020; in the UK they've been negative since the early 2010s.
I still think you're missing my point.
If you're making ~20 predictions a year, you shouldn't be doing any funky math to analyse your forecasts. Just go through each one after the fact and decide whether or not the forecast was sensible with the benefit of hindsight.
I am even explaining what an normal distribution is because I do not expect my audience to know...
I think this is exactly my point, if someone doesn't know what a normal distribution is, maybe they should be looking at their forecasts in a fuzzier way than trying to back fit some model to them.
All I propose that people sometimes make continuous predictions, and if they want to start doing that and track how much they suck, then I give them instructions to quickly getting a number for how well it is going.
I disagree that's all you propose. As I said in an earlier comment, I'm broadly in favour of people making continuous forecasts as they convey more information. You paired your article with what I believe is broadly bad advise around analysing those forecasts. (Especially if we're talking about a sample of ~20 forecasts)