AI #39: The Week of OpenAI
post by Zvi · 2023-11-23T15:10:04.865Z · LW · GW · 8 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility The Q Continuum OpenAI: The Saga Continues Altman Could Step Up You Thought This Week Was Tough Fun with Image Generation Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved Introducing In Other AI News Quiet Speculations The Quest for Sane Regulations That Is Not What Totalitarianism Means The Week in Audio Rhetorical Innovation Aligning a Smarter Than Human Intelligence is Difficult People Are Worried About AI Killing Everyone Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 8 comments
The board firing Sam Altman, then reinstating him, dominated everything else this week. Other stuff also happened, but definitely focus on that first.
Table of Contents
Developments at OpenAI were far more important than everything else this read. So you can read this timeline of events over the weekend, and this attempt to put all the information together.
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Narrate your life, as you do all life.
- Language Models Don’t Offer Mundane Utility. Prompt injection unsolved.
- The Q Continuum. Disputed claims about new training techniques.
- OpenAI: The Saga Continues. The story is far from over.
- Altman Could Step Up. He understands existential risk. Now he can act.
- You Thought This Week Was Tough. It is not getting any easier.
- Fun With Image Generation. A few seconds of an Emu.
- Deepfaketown and Botpocalypse Soon. Beware phone requests for money.
- They Took Our Jobs. Freelancers in some areas are in trouble.
- Get Involved. Dave Orr hiring for DeepMind alignment team.
- Introducing. Claude 2.1 looks like a substantial incremental improvement.
- In Other AI News. Meta breaks up ‘responsible AI’ team. Microsoft invests $50b.
- Quiet Speculations. Will deep learning hit a wall?
- The Quest for Sane Regulation. EU AI Act struggles, FTC AI definition is nuts.
- That Is Not What Totalitarianism Means. People need to cut that claim out.
- The Week in Audio. Sam Altman, Yoshua Bengio, Davidad, Ilya Sutskever.
- Rhetorical Innovation. David Sacks says it best this week.
- Aligning a Smarter Than Human Intelligence is Difficult. Technical debates.
- People Are Worried About AI Killing Everyone. Roon fully now in this section.
- Other People Are Not As Worried About AI Killing Everyone. Listen to them.
- The Lighter Side. Yes, of course I am, but do you even hear yourself?
Language Models Offer Mundane Utility
GPT-4-Turbo substantially outperforms GPT-4 on Arena leaderboard. GPT-3.5-Turbo is still ahead of every model not from either OpenAI or Anthropic. Claude-1 outscores Claude-2 and is very close to old GPT-4 for second place, which is weird.
Own too much cryptocurrency? Ian built a GPT that can ‘bank itself using blockchains.’
Paper says AI pancreatic cancer detection finally outperforming expert radiologists. This is the one we keep expecting that keeps not happening.
David Attenborough narrates your life how-to guide, using Eleven Labs and GPT-4V. Code here. Good pick. Not my top favorite, but very good pick.
Another good pick, Larry David as productivity coach.
Language Models Don’t Offer Mundane Utility

Kai Greshake: PSA: The US Military is actively testing and deploying LLMs to the battlefield. I think these systems are likely to be vulnerable to indirect prompt injection by adversaries. I’ll lay out the story in this thread.
This is http://Scale.ai’s Donovan model. Basically, they let an LLM see and search through all of your military data (assets and threat intelligence) and then it tells you what you should do..
Now, it turns out to be really useful if you let the model see news and public information as well. This is called open-source intelligence or OSINT. In this screenshot, you can see them load “news and press reports” from the target area that the *adversary* can publish!
We’ve shown many times that if an attacker can inject text into your model, you get to “reprogram” it with natural language. Imagine hiding & manipulating information that is presented to the operators and then having your little adversarial minion tell them where to strike.
…
Unfortunately the goal here is to shorten the time to a decision, so cross-checking everything is impossible, and they are not afraid to talk about the intentions. There will be a “human in the loop”, but that human would get their information from the attacker’s minion!
…
@alexlevinson (head of security at scale) responded to me, saying these are “potential vulnerabilities inherent to AI systems, […] <that> do not automatically translate into specific vulnerabilities within individual AI systems”
And that “Each AI system […] is designed with unique security measures that may or may not be susceptible to the vulnerabilities you’ve identified”.
Now, I’ve not had any access to Donovan, and am only judging based on the publicly available information and my expertise. I hope everyone can judge for themselves whether they trust Scale to have found a secret fix to this issue that gives them confidence to deploy.. or not.
Yeah, this is, what’s the term, completely insane? Not in a ‘you are going to wake up Skynet’ way, although it certainly is not helping on such matters but in a ‘you are going to get prompt injected and otherwise attacked by your enemies’ way.
This does not even get into the ways in which such a system might, for example, be used to generate leaks of classified documents and other intel.
You can hook the LLM up to the weapons and your classified data. You can hook the LLM up to outside data sources. You cannot responsibly or safely do both. Pick one.
Robin Hanson survey finds majority see not too much productivity enhancement in software yet.
Robin Hanson: Median estimate of ~7% cut in software time/cost over last 10 years (ignoring LLMs), ~4% recently due to LLMs. But high variance of estimates.
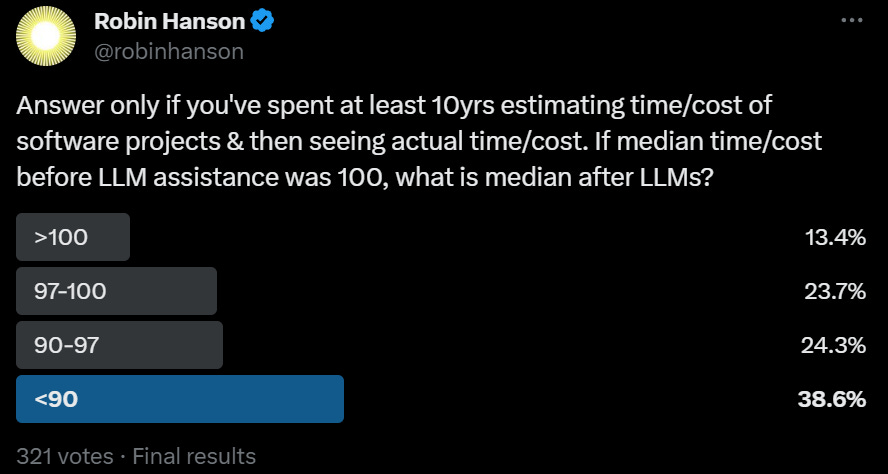
Robin Debreuil: Lots of experience, and I’m 100% sure it’s already less than 90. Also a lot of this saving are on the front end of development (finding and integrating technologies, testing, etc), so prototyping ideas much faster. Quality will improve dramatically too, but hasn’t so much yet.
I agree with Debreuil for most projects. What is less obvious is if this yet applies to the most expensive and valuable ones, where the results need to be rather bulletproof. My presumption is that it still does. I know my productivity coding is up dramatically.
The Q Continuum
There was a disputed claim in Reuters that prior to Altman’s ouster, the board was given notice by several researchers of alarming progress in tests of a new algorithmic technique called Q*, and that this contributed to Altman’s ouster. Q refers to a known type of RL algorithm, which it makes sense for OpenAI to have been working on.
The reported results are not themselves scary, but could point to scary potential later. If Altman had not shared the results with the board, that could be part of ‘not consistently candid.’ However, this story has been explicitly denied in Verge, with their editor Alex Heath saying multiple sources claimed it wasn’t true, and my prediction market has the story as 29% to be substantively true even offering ‘some give.’ This other market says 40% that Q* is ‘a significant capabilities advance.’
For now I will wait for more info. Expect follow-up later.
OpenAI: The Saga Continues
Sam Altman was fired from OpenAI. Now he’s back. For details, see my two posts on the subject, OpenAI: Facts from a Weekend and OpenAI: Battle of the Boards.
The super short version is that Altman gave the board various reasons to fire him that we know about and was seeking to consolidate power, the board fired Altman essentially without explanation, Altman rallied investors especially Microsoft and 97% of the employees, he threatened to have everyone leave and join Microsoft, and the board agreed to resign in favor of a new negotiated board and bring Altman back.
What happens next depends on the full board chosen and who functionally controls it. The new temporary board is Brad Taylor, Larry Summers and Adam D’Angelo. The final board will have nine members, one from Microsoft at least as an observer, and presumably Altman will eventually return. That still leaves room for any number of outcomes. If they create a new board that cares about safety enough to make a stand and can serve as a check on Altman, that is a very different result than if the board ends up essentially under Altman’s control, or as a traditional board of CEOs who unlike D’Angelo prioritize investors and profits over humanity not dying. We shall see.
The loud Twitter statements continue to be that this was a total victory for Altman and for the conducting of ordinary profit-maximizing VC-SV-style business. Or that there is no other way any threat to corporate profits could ever end. That is all in large part a deliberate attempt at manifestation and self-fulfilling declaration. Power as the magician’s trick, residing where people believe it resides.
Things could turn out that way, but do not confuse such power plays with reality. We do not yet know what the ultimate outcome will be.
Nor was Altman’s reinstatement inevitable. Imagine a world in which the board, instead of remaining silent, made its case, and also brought in credible additional board members while firing Altman (let’s say Taylor, Summers, Shear and Mira Murati), and also did this after the stock sale to employees had finished. I bet that goes considerably differently.
Recommended: A timeline history of the OpenAI board. At one point Altman and Brockman were two of four board members. The board has expanded and contracted many times. No one seems to have taken the board sufficiently seriously during this whole time as a permanent ultimate authority that controls its own succession. How were things allowed to get to this point, from all parties?
Recommended: Nathan Lebenz offers a thread about his experiences red teaming GPT-4. Those at OpenAI did not realize what they had, they were too used to worrying about shortcomings to see how good their new model was. Despite the willingness to wait a long time before deployment, he finds the efforts unguided, most involved checked out, a fully inadequate process. Meanwhile for months the board was given no access to GPT-4, and when Lebenz went to the board attacks on Lebenz’s character were used to silence him.
At the ‘we’re so back’ party at OpenAI, there was a fire alarm triggered by a smoke machine, causing two fire trucks to show up. All future fire alarms are hereby discredited, as are reality’s hack writers. Do better.
Bloomberg gives additional details on Wednesday afternoon. There will be an independent investigation into the whole incident.
A thing Larry Summers once said that seems relevant, from Elizabeth Warren:
He teed it up this way: I had a choice. I could be an insider or I could be an outsider. Outsiders can say whatever they want. But people on the inside don’t listen to them. Insiders, however, get lots of access and a chance to push their ideas. People – powerful people – listen to what they have to say. But insiders also understand one unbreakable rule: They don’t criticize other insiders.
I had been warned.
Stuart Buck interprets this as siding with Altman’s criticism of Toner.
The other implication in context would be that Altman is this form of insider. Which would mean that he will not listen to anyone who criticizes an insider. Which would mean he will not listen to most meaningful criticism. I like to think that instead what we saw was that Altman is willing to use such principles as weapons.
My actual understanding of the insider rule is not that insiders will never listen to outside criticism. It is that they do not feel obligated or bound by it, and can choose to ignore it. They can also choose to listen.
A key question is whether this is Summers endorsing this rule, or whether it is, as I would hope, Summers observing that the rule exists, and providing clarity. The second insider rule is that you do not talk about the insider rules.
Also on Summers, Bloomberg notes he expects AI to come for white collar jobs. In a worrying sign, he has expressed concern about America ‘losing its lead’ to China. What a world in which our fate largely rests on the world models of Larry Summers.
Parmy Olson writes in Bloomberg that the previous setup of OpenAI was good for humanity, but bad for Microsoft, that the new board will be traditional and current members scream ‘safe hands’ to investors. And that Microsoft benefits by keeping the new tech at arms length to allow OpenAI to move faster.
Rob Bensinger asks, if Toner’s statements about OpenAI shutting down potentially being consistent with its mission are considered crazy by all employees, what does that say about potential future actions in a dangerous future?
Cate Hall reminds us that from the perspective of someone who thinks OpenAI is not otherwise a good thing, those board seats came with a very high price. If the new board proves to not be a check on Altman, and instead the week backfires, years of strategy by those with certain large purse strings made no sense.
Claim that Altman at his startup Loopt had his friends show up during a negotiation and pretend to be employees working on other major deals to give a false impression. As poster notes, this is Altman being resourceful in the way successful start-up founders are. It is also a classic con artist move, and not the sign of someone worthy of trust.
After the deal was in place, Vinod Khosla said the nonprofit control system is fine, look at companies like IKEA. Does he not understand the difference?
Fun claim on Reddit by ‘OpenAIofThrones’ (without private knowledge) of a more specific, more extreme version of what I outline in Battle of the Board. That Altman tried to convene the board without Toner to expel her, Ilya balked, that presented both the means and a short window to fire Altman before Ilya changed his mind, and that ultimately Altman blinked and agreed to real supervision.
Whatever else happens, we can all set aside our differences to point out the utter failure of The New York Times to understand what happened.
Garry Tan: NYT just going with straight ad hominem with no facts on the front page these days Putting the “capitalists” in the crosshairs with the tuxedo photos is some high class real propaganda.
Paul Graham: OpenAI’s leaders, employees, and code are all about to migrate to Microsoft. Strenuous efforts enable them to remain working for a nonprofit instead. New York Times reaction: “A.I. Belongs to the Capitalists Now.”
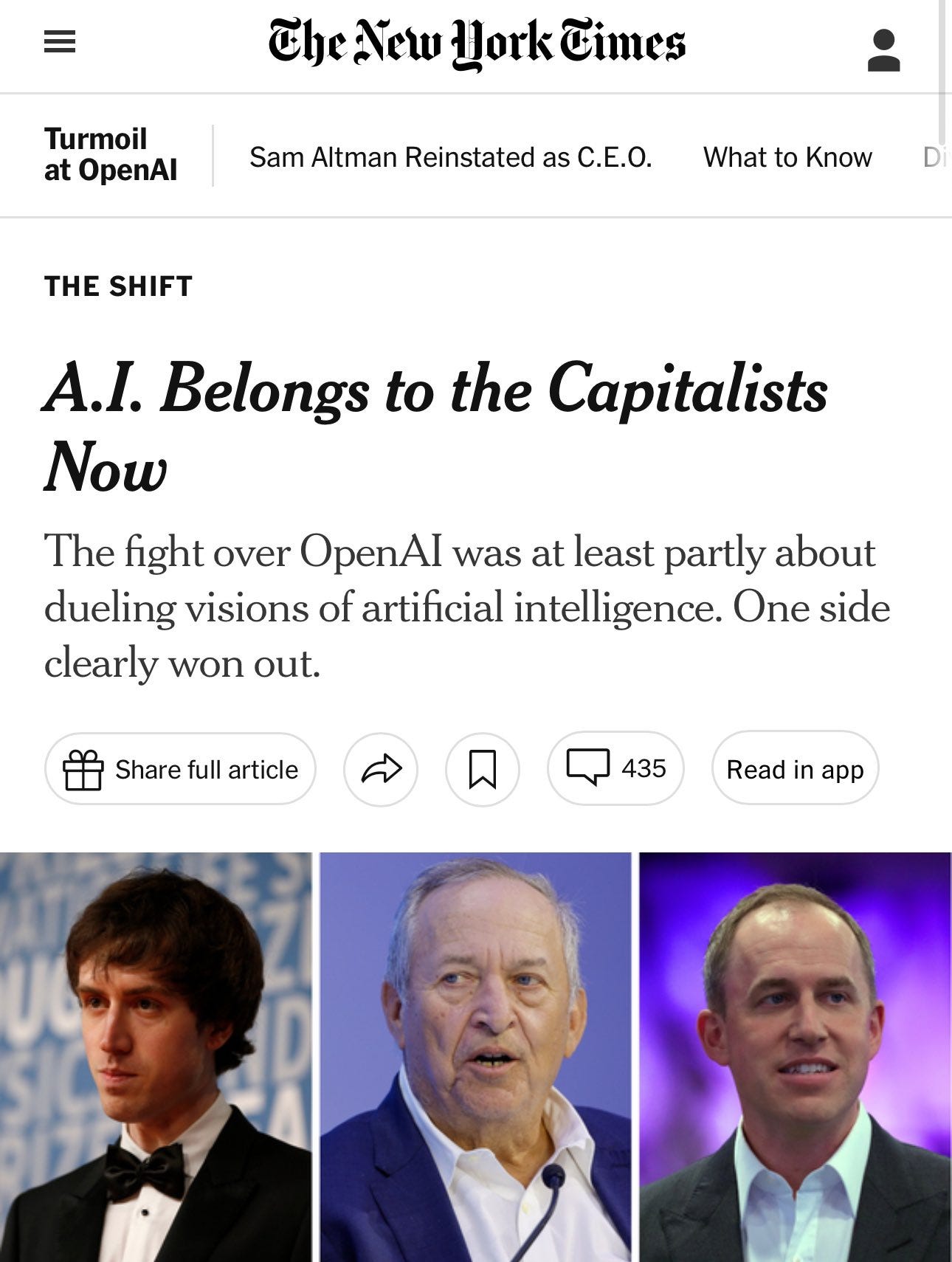
That is very much not how any of this works.
Altman Could Step Up
It is very much an underdog, but one sincere hope I have is Nixon Goes to China.
Altman now has the loyalty of his team, a clear ability to shut down what he helped build if crossed, and unwavering faith of investors who trust him to find a way. No one can say they do not ship. OpenAI retains a rather large lead in the AI race. The e/acc crowd has rallied its flags, and was always more into being against those against things rather than anything else.
If Altman and his team really do care deeply about the safe part of building safe AGI, he now has the opportunity to do the funniest, and also the best, possible thing.
Rather than navigating a conflict between ‘EA’ and ‘e/acc,’ or between worried and unworried, ‘doomer’ and (boomer?), he now has the credibility to say that it is time to make serious costly commitments and investments in the name of ensuring that safe AGI is actually safe.
Not because he was forced into it – surely we all know that any such secret promises the old board might have extracted are worth exactly nothing. Not to placate factions or board members. He can do it because he knows it is the right thing to do, and he now is in a position to do it without endangering his power.
That is the thing about attempting to align something more capable than you that will pursue power due to instrumental convergence. The early steps look the same whether or not you succeeded. You only find out at the end whether or not the result was compatible with humans.
You Thought This Week Was Tough
Ilya Sutskever tried to put the breaks on AI development and remove what he saw at the time as a reckless CEO, from an organization explicitly dedicated to safety. Or at least, that’s the story everyone believed on the outside.
What happened? An avalanche of pressure from all sides. This despite no attempt to turn off any existing systems.
Ask yourself: What would happen if AI was integrated into the economy, or even was a useful tool everyone liked, and it suddenly became necessary to turn it off?
Never mind whether we could. Suppose we could, and also that we should. Would we?
Would anyone even dare try?
Chris Maddison: The wrath that @ilyasut is facing is just a prelude of the wrath that will be faced by anyone who tries to “unplug” an unaligned, supervaluable AI. This weekend has not been encouraging from an AI safety perspective.
David Rein: This is an extremely important and underrated point. Once AI systems are deeply integrated into the economy, there’s ~0% chance we will be able to just “turn them off”, even if they start acting against our interests.
Fun with Image Generation
Meta introduces Emu Video and Emu Edit. Edit means that if you get part of what you want, you can keep it and build upon it. Video is a few seconds of video. I have yet to see any useful applications of a few seconds of video that is essentially ‘things drift in a direction’ but someday, right?
Deepfaketown and Botpocalypse Soon
Report of scam deepfake calls hitting right now, asking for bail money.
Distinct first hand report of that same scam, asking for bail money.
As a general rule, scammers are profoundly uncreative. The reason the Nigerian scam is still the Nigerian scam is that if you recognize the term ‘Nigerian prince’ as a scam then you were not about to fall for an ‘Angolan principle’ either.
So for now, while a code word is still a fine idea, you can get most of the way there with ‘any request for bail money or a suspiciously low-random-amount kidnapping is highly suspicious, probably a scam.’
An even easier, more robust rule suggests itself.
If a phone call leads to a request for money or financial information, assume until proven otherwise that this is a scam!
Good rule even without AI.
They Took Our Jobs
Paper suggests top freelancers are losing business due to ChatGPT. Overall demand drops for knowledge workers and also narrows gaps between them.
I would not presume this holds long term. The skill gap has narrowed, but also there is always demand for the best, although they do not find such an effect here. Mostly I would caution against generalizing too much from early impacts in quirky domains.
Vance Ginn at EconLib opposes the EO, gives the standard ‘they will never take our jobs’ speech warning that ‘red teaming’ and any other regulation will only slow down innovation, does not even bother dismissing existential risks.
Get Involved
Dave Orr is hiring for a new DeepMind alignment team he is joining to start. Post is light on details, including planned technical details.
Red teaming competition, goal is to find an embedded Trojan in otherwise aligned LLMs, a backdoor that lets the user do whatever they want. Submissions accepted until February 25.
Introducing
Claude v2.1. 200k context window, specific prompt engineering techniques, half as many hallucinations (they say), system prompts and experimental tool use for calling arbitrary functions, private knowledge bases or browsing the web. It seems you use things like <code></code>, <book> or <papers>. You can also employ <guidelines>.
All seems highly incrementally useful.
GPQA, a new benchmark of 448 multiple choice science questions where experts often get them wrong and the answers are Google-proof.
ChatGPT Voice rolls out for all free users, amid all the turmoil, with Greg Brockman promoting it. This is presumably a strong cooperative sign, but it could also be a move to raise costs even further.
In Other AI News
Microsoft to spend over $50 billion on data centers. Yikes indeed, sir.
Meta, while everyone is super distracted by OpenAI drama, breaks up its ‘Responsible AI’ team. To which we all said, Meta has a responsible AI team? I do not believe this is a team worth worrying about. Again, I expect the main effect of yelling when people disband such teams is that companies will avoid making such teams, or ensure they are illegible. Yes, they are trying to bury it, but I’m basically OK with letting them.
Jack Morris: now seems as good a time as ever to remind people that the biggest breakthroughs at OpenAI came from a previously unknown researcher [Alec Radord] with a bachelors degree from olin college of engineering.
Ethan Mollick points out that the OpenAI situation highlights the need to not enforce noncompete agreements in tech. I once sat out six months of Magic writing because I had a non-compete and my attempts to reach a win-win deal to diffuse it were roundly rejected, and I keep my agreements. I do think advocates are too eager to ignore the cases where such agreements are necessary in some form, or at least net useful, so it is not as simple as all that.
New paper: Building the Epistemic Community of AI Safety. Don’t think there’s much here but included for completeness.
Quiet Speculations
Will deep learning soon hit a wall? Gary Marcus says it is already hitting one based on this answer, at the end of the Sam Altman video I discuss in This Week in Audio, and writes a post suggesting Altman agrees.
Sam Altman (CEO of OpenAI): There are more breakthroughs required in order to get to AGI
Cambridge Student: “To get to AGI, can we just keep min maxing language models, or is there another breakthrough that we haven’t really found yet to get to AGI?”
Sam Altman: “We need another breakthrough. We can still push on large language models quite a lot, and we will do that. We can take the hill that we’re on and keep climbing it, and the peak of that is still pretty far away. But, within reason, I don’t think that doing that will (get us to) AGI. If (for example) super intelligence can’t discover novel physics I don’t think it’s a superintelligence. And teaching it to clone the behavior of humans and human text – I don’t think that’s going to get there.And so there’s this question which has been debated in the field for a long time: what do we have to do in addition to a language model to make a system that can go discover new physics?”
Gary Marcus: Translation: “deep learning is hitting a wall”
Rob Bensinger: What’s your rough probability on “In 2026, it will seem as though deep learning hit a non-transient wall at some point in 2023-2025, after the relatively impressive results from GPT-4?”
Michael Vassar: 85% by 2028. 65% in 2026. But economic impact will still be accelerating in 2028
AgiDoomerAnon: 25-30% maybe, it’s where most of my hope comes from :)
Negative Utilitarian: 80%.
Fanged Desire: 90%. Though at the same time it’s true that a *lot* of things are going to be possible just by modifying the capabilities we have now in basic ways and making them applicable to different scenarios, so to a layman it may *look* like we’re still progressing at lightning speed.
CF: Lol, 0%.
Jason: 0%. There’s obvious ways forward. Adding short term memory for a start. Parallel streams of consciousness output that are compared and rated by another LLM.
Such strong disagreement. I opened up a market.
Sarah Constantin: The good news is that you’d need an AI to do original science for the worst-case scenarios to occur, and it doesn’t look like LLMs are remotely close.
The bad news is that @sama apparently *wants* an AI physicist.
Not remotely close now, but I am not confident about how long until a lot closer.
Dwarkesh Patel asks why LLMs with so much knowledge don’t notice new correlations and discoveries, pretty much at all. Eliezer responds that humans are computers too, so this is unlikely to be a fundamental limitation, but we do not know how much more capacity would be required for this to happen under current architectures. Roon predicts better and more creative reasoning will solve it.
The Quest for Sane Regulations
FTC is latest agency to give an absurd definition of AI.
Al includes, but is not limited to, machine-based systems that can, for a set of defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. Generative Al can be used to generate synthetic content including images, videos, audio, text, and other digital content that appear to be created by humans. Many companies now offer products and services using Al and generative Al, while others offer products and services that claim to detect content made by generative Al.
I get that a perfect legal definition of AI is hard, but this is broad enough to include essentially every worthwhile piece of software.
UK to not regulate AI at all ‘in the short term’ to avoid ‘stifling innovation.’ This could in theory be part of a sensible portfolio, where Sunak helps them lay groundwork for international cooperation and sensible regulation when we need it, while not getting in the way now. Or it could be a different way to describe the situation – Biden’s Executive Order could also does not regulate AI in the short term in any meaningful way. What’s the difference? This could also reflect deep dysfunction. We will see.
Simeon attempts to explain one more time why not regulating foundation models, as in letting anyone who wants to create the most dangerous, capable and intelligent systems possible, won’t work. No, you can’t meaningfully ‘regulate applications,’ by then it is too late. Also he notes that to the extent Mistral (the most prominent voice advocating this path) has a track record on alignment, it is atrocious.
Corporate Europe on how Big Tech undermined the AI Act. Much to wince over on many fronts. It confirms the basic story of Big Tech lobbying hard against regulations with teeth, then Mistral and Aleph Alpha lobbying hard against those same regulations by claiming the regulations are a Big Tech conspiracy. Nice trick.
Politico Pro EU’s Vincent Manancourt: New: EU “crazy” to consider carve out for foundation models in AI act, ‘Godfather of AI’ Yoshua Bengio told me. He warned bloc risks “law of the jungle” for most advanced forms of the tech. [Story for pros here]
Control AI points out that Mistral’s lobbying champion is the former French tech minister for Macron, who has very much reversed his tune. I’ve heard other reports as well that this relationship has been central.
Italy seems to be with Germany and France on this. Others not so much, but that’s rather a bit three, who want a regime with zero teeth whatsoever. Other officials walked out in response.
“This is a declaration of war,” a parliament official told Euractiv on condition of anonymity.
Max Tegmark and Yoshua Bengio indeed point out that this would be the worst possible thing.
Connor Dunlop of Euractiv argues regulating AI foundation models is crucial for innovation. I agree that the proposed regulations would assist, not hurt, Mistral and Aleph Alpha, the so-called would-be upstart ‘national champions.’ I do not think the linked post effectively makes that case.
That Is Not What Totalitarianism Means
One approach to dismissing any attempts to not die, or any form of regulation on AI, has always been to refer to any, and in many although not all cases I do mean any, restriction or regulation on AI as totalitarianism.
They want people to think of a surveillance state with secret police looking for rogue laptops and monitoring your every keystroke. Plus airstrikes.
What they are actually talking about is taking frontier models, the creation and deployment of new entities potentially smarter and more capable than humans, and applying a normal regulatory regime.
It is time to treat such talk the same way we treat people who get arrested because they deny the constitutional right of the United States Government to collect income taxes.
As in: I am not saying that taxation is not theft, but seriously, get a grip, stop it.
As an excellent concrete example with 500k+ views up top, I am highly disappointed in this disingenuous thread from Brian Chau.
Brian Chau: Did you guys know there’s 24-author paper by EAs, for EAs, about how Totalitarianism is absolutely necessary to prevent AI from killing everyone?
What is this ‘totalitarianism’ as it applies here, as Chau explains it?
They predictably call for exactly the kind of regulatory capture most convenient to OpenAI, Deepmind, and other large players.
[From Paper, quoted by Chau]: blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models.
In other words, the ‘totalitarianism’ is:
- Standards for frontier models.
- Registration and reporting of training runs.
- Mechanisms allowing enforcement of the safety rules.
This is not totalitarianism. This is a completely ordinary regulatory regime.
(I checked with Claude, which was about as kind to Chau’s claims as I was.)
If you want to argue that standard regulatory interventions tend to favor insiders and large players over time? I will agree. We could then work together against that on 90% (98%?) of issues, while looking for the best solution available in the AI space.
Or you can make your true position flat out text?
Here’s how the paper describes three ways their regulatory regime might fail.
The Unexpected Capabilities Problem. Dangerous capabilities can arise unpredictably and undetected, both during development and after deployment.
The Deployment Safety Problem. Preventing deployed AI models from causing harm is a continually evolving challenge.
The Proliferation Problem. Frontier AI models can proliferate rapidly, making accountability difficult.
Here’s how Brian Chau describes this:
Brain Chau: They lay out three obstacles to their plans. If you pause for a moment and read the lines carefully, you will realize they are all synonyms for freedom.
If you want to take the full anarchist position, go ahead. But own it.
In addition to the above mischaracterization, he then ‘rebuts’ the four claims of harm. Here is his reason biological threats don’t matter.
Re 1: the limiting factor of designing new biological weapons is equipment, safety, and not killing yourself with them. No clue why this obviously false talking point is trodded out by EAs so often.
This seems to be a claim that no amount of expertise or intelligence enables the importantly easier creation of dangerous biological pandemic agents? Not only the claim, but the assertion that this is so obviously false that it is crazy to suggest?
He says repeatedly ‘show me the real examples,’ dismissing the danger of anything not yet dangerous. That is not how any of this works.
The Week in Audio
Sam Altman at Cambridge Union Society on November 1 accepting an award and answering questions. Opening speech is highly skippable. The risks and promise of AI are both front and center throughout, I provide a summary that suffices, except you will also want to watch that last question, where Sam says more breakthroughs are needed to get to AGI.
The existential risk protest interruption is at about 17:00 and is quite brief.
At 19:30 he describes OpenAI as tool builders. Notice every time someone assumes that sufficiently capable AIs would long remain our tools.
Right after that he says that young programmers are now outperforming older ones due to greater familiarity with AI tools.
22:00 Sam says he learned two things in school: How to learn new things, and how to think of new things he hadn’t heard elsewhere. Learning how to learn was all the value, the content was worthless.
25:30 Sam responds to the protest, saying that things decay without progress, the benefits can’t be ignored, there needs to be a way forward. Except of course no, there is no reason why there needs to be a way forward. Maybe there is. Maybe there isn’t.
34:00 Sam’s primary concern remains misuse.
47:00 Sam discusses open source, warns of potential to make an irreversible mistake. Calls immediately open sourcing any model trained ‘insanely reckless’ but says open source has a place.
From two weeks ago, I happened to listen to this right before Friday’s events: OpenAI co-founder Ilya Sutskever on No Priors. p(doom) went up as I heard him express the importance of ensuring future AIs have, his term, ‘warm feelings’ towards us, or needing it to ‘be prosocial’ or ‘humanity loving.’ That is not how I believe any of this works. He’s working alongside Leike on Superalignment, and he is still saying that, and I do not understand how or why. But assuming they can continue to work together after this and still have OpenAI’s support, they can hopefully learn and adjust as they go. It is also very possible that Ilya is speaking loosely here and his actual detailed beliefs are much better and more precise.
What is very clear here is Ilya’s sincerity and genuine concern. I wish him all the best.
Yoshua Bengio talk, towards AI safety that improves with more compute. I have not watched yet.
Davidad brief thread compares his approach to those of Bengio and Tegmark.
Rhetorical Innovation
Some basic truth well said.
David Sacks: I’m all in favor of accelerating technological progress, but there is something unsettling about the way OpenAI explicitly declares its mission to be the creation of AGI.
AI is a wonderful tool for the betterment of humanity; AGI is a potential successor species.
By the way, I doubt OpenAI would be subject to so many attacks from the safety movement if it wasn’t constantly declaring its outright intention to create AGI.
To the extent the mission produces extra motivation for the team to ship good products, it’s a positive. To the extent it might actually succeed, it’s a reason for concern. Since it’s hard to assess the likelihood or risk of AGI, most investors just think about the former.
Staff Engineer: If you don’t believe in existential risk from artificial super intelligence. then you don’t believe in artificial super intelligence. You’re just looking at something that isn’t scary so you don’t have to think about the thing that is.
Jeffrey Ladish: Agree with the first sentence but not the second. Many people are just choosing to look away, but some genuinely think ASI is extremely hard / very far away / impossible. I think that’s wrong, but it doesn’t seem like a crazy thing to believe.
Eliezer Yudkowsky notes that people constantly gaslight us saying ‘creating smarter than human AIs would not be a threat to humanity’s survival’ and gets gaslit by most of the comments, including the gaslighting that ‘those who warn of AI’s existential risk deny its upsides’ and ‘those who warn of AI’s existential risk do not say over and over that not ever building it would be a tragedy.’
Your periodic reminder and reference point: AI has huge upside even today. Future more capable AI has transformational insanely great upside, if we can keep control of the future, not get killed and otherwise choose wisely. Never building it would be a great tragedy. However, it would not be as big a tragedy as everyone dying, so if those are the choices then don’t f***ing build it.
On Liars and Lying, a perspective on such questions very different from my own.
Your periodic reminder that ‘doomer’ is mostly a label used either as shorthand, or as a kudgel of those who want to ridicule the idea that AI could be existentially dangerous. Whereas those who do worry have widely varying opinions.
Eliezer Yudkowsky: Disturbing tendency to conflate anyone who believes in any kind of AGI risk as a “doomer”. If that’s the definition, Sam Altman is a doomer. Ilya Sutskever is a doomer. Helen Toner is a doomer. Shane Legg is a doomer. I am a doomer. Guess what? We are importantly different doomers. None of their opinions are my own, nor their plans, nor their choices. Right or wrong they are not mine and do not proceed from my own reasons.
Your periodic reminder that a for-profit business has in practice a strong economic incentive to not kill all of its customers, but only to the extent that would leave other humans alive but not leave it as many customers. If everyone is dead, the company makes no money, but no one cares or is punished for it.
Packy McCormick (a16z): The cool thing about for-profit AI, from an alignment perspective, is that it gives you a strong economic incentive to not kill all of your customers.
Rob Bensinger: If you die in all the scenarios where your customers die, then I don’t see how for-profit improves your long-term incentives. “I and all my loved ones and the entire planet die” is just as bad as “I and all my loved ones and the entire planet die, and a bunch of my customers.”
A for-profit structure may or may not be useful for other reasons, but I don’t think it’s specifically useful because of the “all my customers suddenly die (at the same time the reset of humanity does) scenario”, which is the main scenario to worry about.
Do the events of the past week doom all nuance even more than usual?
Haseeb: This weekend we all witnessed how a culture war is born.
E/accs now have their original sin they can point back to. This will become the new thing that people feel compelled to take a side on–e/acc vs decel–and nuance or middle ground will be punished.
Such claims are constant. Everything that happens nuance is presumed dead. Also every time most people with the ‘e/acc’ label speak nuance is announced dead. Them I do not worry about, they are a lost cause. The question is whether a lot of otherwise reasonable people will follow. Too soon to tell.
Not the argument you want to be making, but…
Misha Gurevich: People who think EA X-risk worries about AI are a destructive ideology: imagine the kind of ideologies artificial intelligences are gonna have.
Aligning a Smarter Than Human Intelligence is Difficult
Following up on the deceptive alignment paper from last week:
Robert Wiblin: In my mind the probability that normal AI reinforcement will produce ‘deceptive alignment’ is like… 30%. So extremely worth working on, and it’s crazy we don’t know. But it might turn out to be a red herring. What’s the best evidence/argument that actually it’s <1% or >90%?
[bunch of mostly terrible arguments in various directions in reply]
I notice a key difference here. Wiblin is saying 30% to deceptive alignment. Last week’s estimate was similar (25%) but it was conditional on the AI already having goals and being situationally aware. Conditional on all that, I am confused how such behavior could fail to arise. Unconditionally is far less clear.
I still expect to almost always see something that is effectively ‘deceptive alignment.’
The AI system will figure out to do that which, within the training environment, best convinces us it is aligned. That’s the whole idea with such techniques. I do not assume that the AI will then go ‘aha, fooled you, now that I am not being trained or tested I can stop pretending.’ I don’t rule that out, but my default scenario is that the thing we got it to do fails to generalize out of distribution the way we expected. That it is sensitive to details and context in difficult to anticipate ways that do not match what we want in both directions. That it does not generalize the ways we hope for.
We discover that we did not, after all, know how to specify what we wanted, in a way that resulted in things turning out well.
Is that ‘deceptive alignment’? You tell me.
Here’s Eliezer’s response:
Eliezer Yudkowsky: Are you imagining that it won’t be smart enough to do that? Or that deception will genuinely not be in its interests because it gets just as much of what it wants with humans believing true things as the literally optimal state of affairs? Or that someone solved soft optimization? How do you imagine the weird, special circumstances where this doesn’t happen? Remember that if MIRI is worried about a scenario, that means we think it’s a convergent endpoint and not some specific pathway; if you think we’re trying to predict a hard-to-predict special case, then you’ve misunderstood a central argument.
Robert Wiblin: Joe’s paper does a better job than me of laying out ways it might or might not happen. But ‘not being smart enough’ isn’t an important reason.
‘Not trained to be a global optimizer’ is one vision.
Another is that the reinforcement for doing things we like and not things we don’t like (with some common-sense adjustments to how the feedback works suggested by alignment folks) evolves models to basically do what we want and share our aversions, maybe because that’s the simplest / most efficient / most parsimonious way to get reward during training. The wedge between what we want and what we reward isn’t large enough to generate lots of scheming behavior, because scheming isn’t the best way to turn compute into reward in training setups.
I am so completely confused by Wiblin’s position here, especially that last sentence. Why would ‘scheming’ not be the best way to turn compute into rewards? Why would a completely honest, consistent, straightforward approach be the most rewarded one, given how humans decide how to reward things? I don’t get it.
Eliezer Yudkowsky offers what for him counts as high praise.
Eliezer Yudkowsky (QTing what follows here): This seems a very weak test of the ability of dumber judges to extract truth from smarter debaters, but the methodology could be adapted to tougher tests. Increasingly tough versions of this are a good candidate for standard evals.
Julian Michael: As AIs improve at persuasion & argumentation, how do we ensure that they help us seek truth vs. just sounding convincing? In human experiments, we validate debate as a truth-seeking process, showing that it may soon be needed for supervising AI. Paper here.
When a doctor gives a diagnosis, common advice is to get a second opinion to help evaluate whether to trust their judgment, because it’s too difficult to evaluate their diagnosis by yourself.
The idea (originally proposed by @geoffreyirving et al.) is that having equally-capable adversarial AIs critique each other’s answers will make it easier for non-expert judges to evaluate their truthfulness. But does this actually hold in practice?
We find for the first time on a realistic task that the answer is yes! We use NYU competitive debaters to stand in for future AI systems, having them debate reading comprehension questions where the judge *can’t see the passage* (except for quotes revealed by the debaters).
We compare debate to a baseline we call *consultancy*, where the judge interacts with a single expert that has a 50% chance of lying. We use this to explicitly elicit dishonest behavior that may implicitly arise in methods like RLHF.
We find that judges are significantly more accurate in debate than consultancy, AND debates are much more efficient, at two-thirds the length on average.
Furthermore, many of the errors we observe in debate seem fixable with more careful judging and stronger debaters. In a third of mistakes, judges end the debate prematurely, and in nearly half, honest debaters mistakenly missed key evidence that would have helped them win.
We don’t see a difference in accuracy or efficiency between debate and consultancy when using GPT-4 as a debater — yet. In particular, GPT-4 was not very skilled at deception, which may not remain the case for future powerful AI systems.
As we move from relatively unskilled AI systems to skilled humans, non-expert judge accuracy *improves* with debate, but *decreases* with consultancy. This suggests that training AI systems to debate may be an important alternative to methods like RLHF as models improve.
In the paper, we lay out considerations on how to train AI debaters and open problems that need to be solved.
How optimistic should we be about this in the AI case where you are trying to do this to use outputs of models you cannot otherwise trust? I continue to assume this will break exactly when you need it to not break. It could have mundane utility in the period before that, but I always worry about things I assume are destined to break.
Thread with Nora Belrose and Eliezer Yudkowsky debating deceptive alignment. Nora bites the bullet and says GPT-4 scaled up in a naive way would not have such issues. Whereas I would say, that seems absurd, GPT-4 already has such problems. Nora takes the position that if your graders and feedback suck, your AI ends up believing false things the graders believe and not being so capable, but not in a highly dangerous way. I continue to be confused why one would expect that outcome.
People Are Worried About AI Killing Everyone
Roon reminds us that people acting like idiots and making deeply stupid strategic power moves, only to lose to people better at power moves, has nothing to do with the need to ensure we do not die from AI.
Roon: throughout all this please remember a few things that will be critical for the future of mankind: – this coup had nothing to do with ai safety. Sama has been a global champion of safe agi dev – the creation of new life is fraught and no one must forget that for political reasons
Sorry if the second point is vague. I literally just mean don’t turn your back on x-risk just because of this remarkably stupid event
We need better words for stuff that matters. But yes.
Roon: if a group of people are building artificial life in the lab and don’t view it with near religious significance you should be really concerned.
Axios’ Jim VandeHei and Mike Allen may or may not be worried about existential risk here, but they say outright that ‘this awesome new power’ cannot be contained, ethics never triumphs over profits, never has, never will. So we will get whatever we get.
I say this is at best midwit meme territory. Sometimes, yes, ethics or love or the common good wins. We are not living in a full-on cyberpunk dystopia of unbridled capitalism. I am not saying it will be easy. It won’t be easy. It also is not impossible.
Other People Are Not As Worried About AI Killing Everyone
It is important to notice this non-sequitur will be with us, until very late in the game. There is always some metaphorical hard thing that looks easy.
Katherine Dee: Had an ex who worked on self-driving cars. He once said to me, “you can’t use self-check out or self-ticketing machines at the airport reliably. No AI overlords are coming.” I think about that a lot.
Eliezer Yudkowsky: This really is just a non-sequitur. Not all machines are one in their competence. The self-check-out machines can go on being bad indefinitely, right up until the $10-billion-dollar frontier research model inside the world’s leading AI lab starts self-improving.
What term would he prefer to use for the possibility?
Stewart Brand: Maybe this is the episode that makes the term “existential risk” as passé as it needs to be.
When someone tells you who they are. Believe them.
Roon (Sunday evening): i truly respect everyone involved [in the OpenAI situation].
Eliezer Yudkowsky: I respect that.
Anton: If one has actual principles, this is not possible.
The Lighter Side
And when you see them you shall call them by their true name.
8 comments
Comments sorted by top scores.
comment by Joe Collman (Joe_Collman) · 2023-11-23T20:56:05.134Z · LW(p) · GW(p)
Is that ‘deceptive alignment’? You tell me.
I don't think it makes sense to classify every instance of this as deceptive alignment - and I don't think this is the usual use of the term.
I think that to say "this is deceptive alignment" is generally to say something like "there's a sense in which this system has a goal different from ours, is modeling the selection pressure it's under, anticipating that this selection pressure may not exist in the future, and adapting its behaviour accordingly".
That still leaves things underdefined, e.g. since this can all happen implicitly and/or without the system knowing this mechanism exists.
However, if you're not suggesting in any sense that [anticipation of potential future removal of selection pressure] is a big factor, then it's strange to call it deceptive alignment.
I assume Wiblin means it in this sense - not that this is the chance we get catastrophically bad generalization, but rather that it happens via a mechanism he'd characterize this way.
[I'm now less clear that this is generally agreed, since e.g. Apollo seem to be using a foolish-to-my-mind definition here: When an AI has Misaligned goals and uses Strategic Deception to achieve them (see "Appendix C - Alternative definitions we considered", for clarification).
This is not close to the RFLO definition [LW · GW], so I really wish they wouldn't use the same name. Things are confusing enough without our help.]
All that said, it's not clear to me that [deceptive alignment] is a helpful term or target, given that there isn't a crisp boundary, and that there'll be a tendency to tackle an artificially narrow version of the problem.
The rationale for solving it usually seems to be [if we can solve/avoid this subproblem, we'd have instrumentally useful guarantees in solving the more general generalization problem] - but I haven't seen a good case made that we get the kind of guarantees we'd need (e.g. knowing only that we avoid explicit/intentional/strategic... deception of the oversight process is not enough).
It's easy to motte-and-bailey ourselves into trouble.
comment by Signer · 2023-11-23T19:07:15.884Z · LW(p) · GW(p)
Why would ‘scheming’ not be the best way to turn compute into rewards? Why would a completely honest, consistent, straightforward approach be the most rewarded one, given how humans decide how to reward things? I don’t get it.
It wouldn't be the most rewarded one. It's not what training does, because it never approaches theoretical limits. It would be uncomplicated approach that may miss some reward. In other words, the solution to soft optimization is to train a neural network with human-generated content.
comment by SimonM · 2023-11-23T17:25:52.414Z · LW(p) · GW(p)
A thing Larry Summers once said that seems relevant, from Elizabeth Warren:
He said something very similar to Yanis Varoufakis (https://www.globaljustice.org.uk/blog/2017/06/when-yanis-met-prince-darkness-extract-adults-room/) and now I like to assume he goes around saying this to everyone
comment by mishka · 2023-11-23T17:21:23.017Z · LW(p) · GW(p)
Dave Orr is hiring for a new DeepMind alignment team he is joining to start. Post is light on details, including planned technical details.
He has an edit saying
Replies from: adam-shaiThere’s already a team in London, which will continue to exist and do great work. I’m helping to set up a US branch of that team.
↑ comment by Adam Shai (adam-shai) · 2023-11-24T15:00:25.378Z · LW(p) · GW(p)
The blog post linked says it's from August. Is there something new I'm missing?
Replies from: Zvi, mishka↑ comment by Zvi · 2023-11-25T13:38:40.316Z · LW(p) · GW(p)
Ah, he didn't realize he was getting signal boosted and edited after he got a bunch of inquiries. Under the old wording, I didn't think they had no alignment teams, but I read it as 'a new alignment team.' It makes sense under Google's general structure to have multiples, in fact it would be weird if you didn't.
↑ comment by mishka · 2023-11-24T16:07:06.260Z · LW(p) · GW(p)
It's a good question.
I don't even know if the clarifying edit is new, since that's substack and not github or wikipedia, where one can see the history of edits.
But a new comment was posted 22 hours ago on that substack post, https://mistaketheory.substack.com/p/new-role-agi-alignment-research, perhaps there will be a response from the author (and perhaps the clarifying edit is related to this substack post becoming more known lately, via this post by Zvi or via other channels).
comment by Chess3D (chess-teacher) · 2023-11-23T16:24:46.784Z · LW(p) · GW(p)
Thanks for a great writeup Zvi!
My overall takeaways:
- It seems the new board will pay close attention to Sam/Greg/others in terms of making sure information is shared in timely manner for the board to make smart decisions.
I think the next few months of board additions will tell us where it is headed for AI governance of the for-profit
- Personally, I have not been concerned about AGI in the next few years, and it seems even many of the folks who worry in general, agree with that sentiment (based on some of the tweets I saw). I'm in CS but not ML (though I do follow it) and my guess is 10ish years.
I do still want to hear what Ilya was so worried about, but currently my guess is the "attitude" towards new tech rather than the "capabilities" of this particular tech
- Who knew Twitter would make such a comeback?