Kelly isn't (just) about logarithmic utility
post by SimonM · 2021-02-23T12:12:24.999Z · LW · GW · 41 commentsContents
Repeated bets involve variance drag People need to account for this Utilities and repeated bets are two sides of the same coin People focus too much on the "Utility" formulation and not enough on the "repeated nature" People focus too much on the formula It's not about logarithmic utility (but really it is) Conclusion Further Reading None 41 comments
Edit: The original version of this was titled without the "(just)". I also regret the first 4 lines, but I'm leaving them in for posterity's sake. I also think that johnswentworth [LW(p) · GW(p)]'s comment is a better tl;dr than what I wrote.
Deep breath.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Kelly isn't about logarithmic utility. Kelly is about repeated bets.
Perhaps one reason is that maximizing E log S suggests that the investor has a logarithmic utility for money. However, the criticism of the choice of utility functions ignores the fact that maximizing E log S is a consequence of the goals represented by properties P1 and P2, and has nothing to do with utility theory.
"Competitive Optimality of Logarithmic Investment" (Bell, Cover) (emphasis mine):
Things I am not saying:
- Kelly isn't maximising logarithmic utility
- Kelly is the optimal strategy, bow down before her in awe
- Multiperiod optimization is different to single period optimization(!)
The structure of what I am saying is roughly:
- Repeated bets involve variance drag
- People need to account for this
- Utilities and repeated bets are two sides of the same coin
- People focus too much on the "Utility" formulation and not enough on the "repeated nature"
- People focus too much on the formula
Repeated bets involve variance drag
This has been said many times, by many people. The simplest example is usually something along the lines of:
You invest in a stock which goes up 1% 50% of the time, and down 1% 50% of the time. On any given day, the expected value of the stock tomorrow is the same as the stock today:
But what happens if you invest in it? On day 1 it goes up 1%, on day 2 it goes down 1%. How much money do you have?
Another way of writing this is:
The term is "variance decay". (Or volatility dray, or any of a number of different names)
This means that over a large sequence of trials, you tend to lose money. (On average over sequences "you" break-even, a small number of your multiverse brethren are getting very lucky with their coin flips).
Let's consider a positive sum example (from "The ergodicity problem in economic" (Peters)). We have a stock which returns 50% or -40%. If we put all our money in this stock, we are going to lose it over time since but on any given day, this stock has a positive expected return.
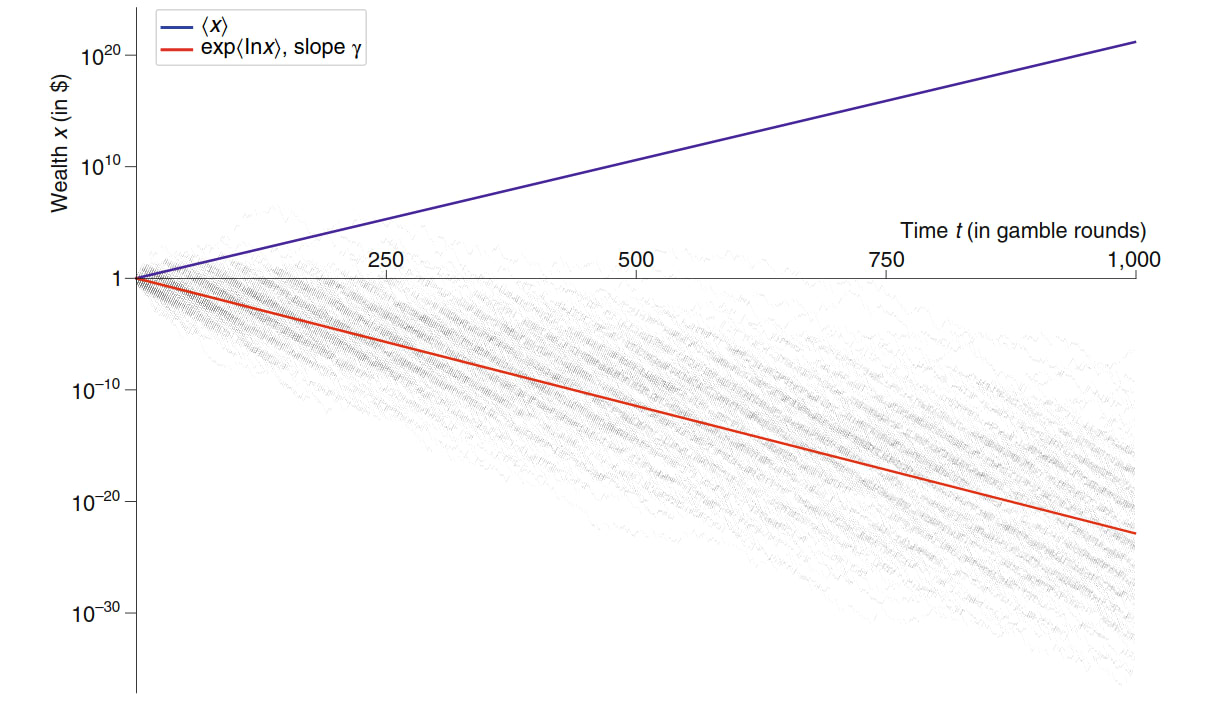
[I think there is a sense in which this is much more intuitive for gamblers than for investors. If your typical "investment opportunity" (read bet) goes to 0 some fraction of the time, investing all your "assets" (read bank roll) in it is obviously going to run a high risk of ruin after not very many trials.]
People need to account for this
In order to account for the fact that "variance is bad" people need to adjust their strategy. To take our example from earlier. That stock is fantastic! It returns 10% per day (on average). There must be some way to buy it and make money? The answer is yes. Don't invest all of your money in it. If you invest 10%. After one day you will either have or . This is winning proposition (even long term) since
Kelly is (a) way to account for this.
Utilities and repeated bets are two sides of the same coin
I think this is fairly clear - "The time interpretation of expected utility theory" (Peters, Adamou) prove this. I don't want to say too much more about this. This section is mostly to acknowledge that:
- Yes, Kelly is maximising log utility
- No, it doesn't matter which way you think about this
- Yes, I do think thinking in the repeated bets framework is more useful
People focus too much on the "Utility" formulation and not enough on the "repeated nature"
This is my personal opinion (and that of the Ergodicity Economics crowd). Both of the recent [LW · GW] threads [LW · GW] talk at length about the formula for Kelly for one bet. There seems to be little (if any) discussion of where the usefulness comes from. Kelly is useful when you can repeat and therefore compound your bets. Compounding is multiplicative, so it becomes "natural" (in some sense) to transform everything by taking logs.
People focus too much on the formula
Personally, I use Kelly more often for pencil-and-pap`er calculations and financial models than for making yes-or-no bets in the wild. For this purpose, far and away the most important form of Kelly to remember is "maximize expected log wealth". In particular, this is the form which generalizes beyond 2-outcome bets - e.g. it can handle allocating investments across a whole portfolio. It's also the form which most directly suggests how to derive the Kelly criterion, and therefore the situations in which it will/won't apply. - johnswentworth [LW(p) · GW(p)]
I think this comment was spot on, and I don't really want to say too much more about it than that. The really magic takeaway (which I think is underappreciated) is. "maximise log your expected wealth". "Optimal Multiperiod Portfolio Policies" (Mossin) shows that for a wide class of utilities, optimising utility of wealth at time t is equivalent to maximising utility at each time-step.
BUT HANG ON! I hear you say. Haven't you just spent the last 5 paragraphs saying that Kelly is about repeated bets? If it all reduces to one period, why all the effort? The point is this: legible utilities need to handle the multi-period nature of the world. I have no (real) sense of what my utility function is, but I do know that I want my actions to be repeatable without risking ruin!
It's not about logarithmic utility (but really it is)
There is so much more which could be said about Kelly criterion for which this is really scratching the surface. Kelly has lots of nice properties (which are independent of utility functions) which I think are worth flagging:
- Maximises asymptotic long run growth
- Given a target wealth, is the strategy which achieves that wealth fastest
- Asymptotically outperforms any other strategy (ie E[X/X_{kelly}] <= 1)
- (Related to 3) "Competitive optimality". Any other strategy can only beat Kelly at most 1/2 the time. (1/2 is optimal since the other strategy could be Kelly)
Conclusion
Never go full Kelly [LW · GW]
- Zvi (Kelly Criterion [LW · GW])
What I am trying to do is shift the conversation away from discussion of the Kelly formula, which smells a bit like guessing the teacher's password [LW · GW] to me, and get people to think more about how we should really think about and apply Kelly. The formula isn't the hard part. Logarithms aren't (that) important.
Further Reading
- The Kelly Criterion [LW · GW]
- Kelly bet on everything [LW · GW]
- The Kelly Capital Growth Investment Criterion
41 comments
Comments sorted by top scores.
comment by abramdemski · 2021-02-23T21:14:10.180Z · LW(p) · GW(p)
OK, here is my fuller response.
First of all, I want to state that Ergodicity Economics is great and I'm glad that it exists -- like I said in my other comment, it's a true frequentist alternative to Bayesian decision theory, and it does some cool things, and I would like to see it developed further.
That said, I want to defend two claims:
- From a strict Bayesian perspective, it's all nonsense, so those arguments in favor of Kelly are at best heuristic. A Bayesian should be much more interested in the question of whether their utility is log in money. (Note: I am not a strict bayesian [LW · GW], although I think strict Bayes is a pretty good starting point.)
- From a broader perspective, I think Peters' direction is interesting, but his current methodology is not very satisfying, and doesn't support his strong claims that EG Kelly naturally pops out when you take a time-averaging rather than ensemble-averaging perspective.
"It's All Nonsense"
Let's deal with the strict Bayesian perspective first.
You start your argument by discussing the "variance drag" phenomenon. You point out that the expected monetary value of an investment can be constant or even increasing, but it may be that due to variance drag, it typically (with high probability) goes down over time.
You go on to assert that "people need to account for this" and "adjust their strategy" because "variance is bad".
To a strict Bayesian, this is a non-sequitur. If it be the case that a strict Bayesian is a money-maximizer (IE, has utility linear in money), they'll see no problem with variance drag. You still put your money where it gets the highest expected value.
Furthermore, repeated bets don't make any material difference to the money-maximizer. Suppose the optimal one-step investment strategy has a tare of return R. Then the best two-step strategy is to use that strategy twice to get an expected rate of return R^2. This is because the best way they can set themselves up to succeed at stage 2 (in expectation!) is to get as much money as they can at stage 1 (in expectation!). This reasoning applies no matter how many stages we string together. So to the money-maximizer, your argument about repeated bets is totally wrong.
Where a strict Bayesian would start to agree with you is if they don't have utility linear in money, but rather, have diminishing returns.
In that case, the best strategy for single-step investing can differ from the best strategy for multi-step investing.
Say the utility function is . Treat an investment strategy as a stochastic function . We assume the random variable behaves the same as the random variable ; IE, returns are proportional to investment. So, actually, we can treat a strategy as a random variable which gets multiplied by our money; .
In a one-step scenario, the Bayesian wants to maximize where is your starting money. In a two-step scenario, the Bayesian wants to maximize . And so on. The reason the strategy was so simple when was that this allowed us to push the expectation inwards; (the last step holds because we assume the random variables are independent). So in that case, we could just choose the best individual strategy and apply it at each time-step.
In general, however, nonlinear stops us from pushing the expectations inward. So multi-step matters.
A many-step problem looks like . The product of many independent random variables will closely approximate a log-normal distribution, by the multiplicative central limit theorem. I think this somehow implies that if the Bayesian had to select the same strategy to be used on all days, the Bayesian would be pretty happy for it to be a log-wealth maximizing strategy, but I'm not connecting the dots on the argument right now.
So anyway, under some assumptions, I think a Bayesian will behave increasingly like a log-wealth maximizer as the number of steps goes up.
But this is because the Bayesian had diminishing returns in the first place. So it's still ultimately about the utility function.
Most attempts to justify Kelly by repeated-bet phenomena overtly or implicitly rely on an assumption that we care about typical outcomes. A strict Bayesian will always stop you there. "Hold on now. I care about average outcomes!"
(And Ergodicity Economics says: so much the worse for Bayes!)
Bayesians may also raise other concerns with Peters-style reasoning:
- Ensemble averaging is the natural response to decision-making under uncertainty; you're averaging over different possibilities. When you try to time-average to get rid of your uncertainty, you have to ask "time average what?" -- you don't know what specific situation you're in.
- In general, the question of how to turn your current situation into a repeated sequence for the purpose of time-averaging analysis seems under-determined (even if you are certain about your present situation). Surely Peters doesn't want us to use actual time in the analysis; in actual time, you end up dead and lose all your money, so the time-average analysis is trivial. So Peters has to invent an imagined time dimension, in which the game goes on forever. In contrast, Bayesians can deal with time as it actually is, accounting for the actual number of iterations of the game, utility of money at death, etc.
- Even if you settle on a way to turn the situation into an iterated sequence, the necessary limit does not necessarily exist. This is also true of the possibility-average, of course (the St Petersburg Paradox being a classic example); but it seems easier to get failure in the time-avarage case, because you just need non-convergence; ie, you don't need any unbounded stuff to happen.
It's Not Nonsense, But It's Not Great, Either
Each of the above three objections are common fare for the Frequentist:
- Frequentist approaches start from the objective/external perspective rather than the agent's internal uncertainty. (For example, an "unbiased estimator" is one such that given a true value of the parameter, the estimator achieves that true value on average.) So they're not starting from averaging over subjective possibilities. Instead, Frequentism averages over a sequence of experiments (to get a frequency!). This is like a time-average, since we have to put it in sequence. Hence, time-averages are natural to the way Frequentists think about probability.
- Even given direct access to objective truth, frequentist probabilities are still under-defined because of the reference class problem -- what infinite sequence of experiments do you conceive of your experiment as part of? So the ambiguity about how to turn your situation into a sequence is natural.
- And, again, once you select a sequence, there's no guarantee that a limit exists. Frequentism has to solve this by postulating that limits exist for the kinds of reference classes we want to talk about.
So, actually, this way of thinking about decision theory is quite appealing from a Frequentist perspective.
Remember all that stuff about how a Bayesian money-maximizer would behave? That was crazy. The Bayesian money-maximizer would, in fact, lose all its money rather quickly (with very high probability). Its in-expectation returns come from increasingly improbable universes. Would natural selection design agents like that, if it could help it?
So, the fact that Bayesian decision theory cares only about in-expectation, rather than caring about typical outcomes, does seem like a problem -- for some utility functions, at least, it results in behavior which humans intuitively feel is insane and ineffective. (And philosophy is all about trying to take human intuitions seriously, even if sometimes we do decide human intuition is wrong and better discarded).
So I applaud Ole Peters' heroic attempt to fix this problem.
However, if you dig into Peters, there's one critical place where his method is sadly arbitrary. You say:
Compounding is multiplicative, so it becomes "natural" (in some sense) to transform everything by taking logs.
Peters makes much of this idea of what's "natural". He talks about additive problems vs multiplicative problems, as well as the more general case (when neither additive/multiplicative work).
However, as far as I can tell, this boils down to creatively choosing a function which makes the math work out.
I find this inexcusable, as-is.
For example, Peters makes much of the St Petersburg lottery:
A resolution of the St Petersburg paradox is presented. In contrast to the standard resolution, utility is not required. Instead, the time-average performance of the lottery is computed. The final result can be phrased mathematically identically to Daniel Bernoulli’s resolution, which uses logarithmic utility, but is derived using a conceptually different argument. The advantage of the time resolution is the elimination of arbitrary utility functions.
Daniel Bernoulli "solved" the St Petersburg paradox by suggesting that utility is log in money, which makes the expectations work out. (This is not very satisfying, because we can always transform the monetary payouts by an exponential function, making things problematic again! D Bernoulli could respond "take the logarithm twice" in such a case, but by this point, it's clear he's just making stuff up, so we ignore him.)
Ole Peters offers the same solution, but, he says, with an improved justification: he promises to eliminate the arbitrary choice of utility functions.
He does this by arbitrarily choosing to examine the time-average behavior in terms of growth rate, which is defined multiplicatively, rather than additively.
"Growth rate" sounds like an innocuous, objective choice of what to maximize. But really, it's sneaking in exactly the same arbitrary decision which D Bernoulli made. Taking a ratio, rather than a difference, is just a sneaky way to take the logarithm.
So, similarly, I see the Peters justification of Kelly as ultimately just a fancy way of saying that taking the logarithm makes the math nice. You're leaning on that argument to a large extent, although you also cite some other properties which I have no beef with.
Again, I think Ole Peters is pretty cool, and there's interesting stuff in this general direction, even if I find that the particular methodology he's developed doesn't justify anything and instead engages in obfuscated question-begging of existing ideas (like Kelly, and like D Bernoulli's proposed solution to St Petersburg).
Also, I could be misunderstanding something about Peters!
Replies from: johnswentworth, SimonM, Vitor↑ comment by johnswentworth · 2021-02-23T22:26:09.984Z · LW(p) · GW(p)
I have some interesting disagreements with this.
Prescriptive vs Descriptive
First and foremost: you and I have disagreed in the past on wanting descriptive vs prescriptive roles for probability/decision theory. In this case, I'd paraphrase the two perspectives as:
- Prescriptive-pure-Bayes: as long as we're maximizing an expected utility, we're "good", and it doesn't really matter which utility. But many utilities will throw away all their money with probability close to 1, so Kelly isn't prescriptively correct.
- Descriptive-pure-Bayes: as long as we're not throwing away money for nothing, we're implicitly maximizing an expected utility. Maximizing typical (i.e. modal/median/etc) long-run wealth is presumably incompatible with throwing away money for nothing, so presumably a typical-long-run-wealth-maximizer is also an expected utility maximizer. (Note that this is nontrivial, since "typical long-run wealth" is not itself an expectation.) Sure enough, the Kelly rule has the form of expected utility maximization, and the implicit utility is logarithmic.
In particular, this is relevant to:
Remember all that stuff about how a Bayesian money-maximizer would behave? That was crazy. The Bayesian money-maximizer would, in fact, lose all its money rather quickly (with very high probability). Its in-expectation returns come from increasingly improbable universes. Would natural selection design agents like that, if it could help it?
"Does Bayesian utility maximization imply good performance?" is mainly relevant to the prescriptive view. "Does good performance imply Bayesian utility maximization?" is the key descriptive question. In this case, the latter would say that natural selection would indeed design Bayesian agents, but that does not mean that every Bayesian agent is positively selected - just that those designs which are positively selected are (approximately) Bayesian agents.
"Natural" -> Symmetry
Peters makes much of this idea of what's "natural". He talks about additive problems vs multiplicative problems, as well as the more general case (when neither additive/multiplicative work).
However, as far as I can tell, this boils down to creatively choosing a function which makes the math work out.
I haven't read Peters, but the argument I see in this space is about symmetry/exchangeability (similar to some of de Finetti's stuff). Choosing a function which makes reward/utility additive across timesteps is not arbitrary; it's making utility have the same symmetry as our beliefs (in situations where each timestep's variables are independent, or at least exchangeable).
In general, there's a whole cluster of theorems which say, roughly, if a function is invariant under re-ordering its inputs, then it can be written as for some g, h. This includes, for instance, characterizing all finite abelian groups as modular addition, or de Finetti's Theorem, or expressing symmetric polynomials in terms of power-sum polynomials. Addition is, in some sense, a "standard form" for symmetric functions.
Suppose we have a sequence of n bets. Our knowledge is symmetric under swapping the bets around, and our terminal goals don't involve the bets themselves. So, our preferences should be symmetric under swapping the bets around. That implies we can write it in the "standard form" - i.e. we can express our preferences as a function of a sum of some summary data about each bet.
I'm not seeing the full argument yet, but it feels like there's something in roughly that space. Presumably it would derive a de Finetti-style exchangeability-based version of Bayesian reasoning.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-24T01:22:40.207Z · LW(p) · GW(p)
I agree with your prescriptive vs descriptive thing, and agree that I was basically making that mistake.
I think the correct position here is something like: expected utility maximization; and also, utility in "these cases" is going to be close to logarithmic. (IE, if you evolve trading strategies in something resembling Kelly's conditions, you'll end up with something resembling Kelly agents. And there's probably some generalization of this which plausibly abstracts aspects of the human condition.)
But note how piecemeal and fragile this sounds. One layer is the relatively firm expectation-maximization layer. On top of this we add another layer (based on maximization of mode/median/quantile, so that we can ignore things not true with probability 1 [LW(p) · GW(p)]) which argues for some utility functions in particular.
Ole Peters is trying to re-found decision theory on the basis of this second layer alone. I think this is basically a good instinct:
- It's good to try to firm up this second layer, since just Kelly alone is way too special-case, and we'd like to understand the phenomenon in as much generality as possible.
- It's good to try and make a 1-layer system rather than a 2-layer one, to try and make our principles as unified as possible. The Kelly idea is consistent with our foundation of expectation maximization, sure, but if "realistic" agents systematically avoid some utility functions, that makes expectation maximization a worse descriptive theory. Perhaps there is a better one.
This is similar to the way Solomonoff is a two-layer system: there's a lower layer of probability theory, and then on top of that, there's the layer of algorithmic information theory, which tells us to prefer particular priors. In hindsight this should have been "suspicious"; logical induction merges those two layers together, giving a unified framework which gives us (approximately) probability theory and also (approximately) algorithmic information theory, tying them together with a unified bounded-loss notion. (And also implies many new principles which neither probability theory nor algorithmic information theory gave us.)
So although I agree that your descriptive lens is the better one, I think that lens has similar implications.
As for your comments about symmetry -- I must admit that I tend to find symmetry arguments to be weak. Maybe you can come up with something cool, but I would tend to predict it'll be superseded by less symmetry-based alternatives. For one thing, it tends to be a two-layered thing, with symmetry constraints added on top of more basic ideas.
↑ comment by SimonM · 2021-02-23T22:25:27.474Z · LW(p) · GW(p)
This was fascinating. Thanks for taking the time to write it. I agree with the vast majority of what you wrote, although I don't think it actually applies to what I was trying to do in this post. I don't disagree that a full-Bayesian finds this whole thing a bit trivial, but I don't believe people are fully Bayesian (to the extent they know their utility function) and therefore I think coming up with heuristics is valuable to help them think about things.
So, similarly, I see the Peters justification of Kelly as ultimately just a fancy way of saying that taking the logarithm makes the math nice. You're leaning on that argument to a large extent, although you also cite some other properties which I have no beef with.
I don't really think of it as much as an "argument". I'm not trying to "prove" Kelly criterion. I'm trying to help people get some intuition for where it might come from and some other reasons to consider it if they aren't utility maximising.
It's interesting to me that you brought up the exponential St Petersburg paradox, since MacLean, Thorpe, Ziemba claim that Kelly criterion can also handle it although I personally haven't gone through the math.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-24T00:15:32.770Z · LW(p) · GW(p)
Yeah, in retrospect it was a bit straw of me to argue the pure bayesian perspective like I did (I think I was just interested in the pure-bayes response, not thinking hard about what I was trying to argue there).
So, similarly, I see the Peters justification of Kelly as ultimately just a fancy way of saying that taking the logarithm makes the math nice. You’re leaning on that argument to a large extent, although you also cite some other properties which I have no beef with.
I don’t really think of it as much as an “argument”. I’m not trying to “prove” Kelly criterion.
I'm surprised at that. Your post read to me as endorsing Peters' argument. (Although you did emphasize that you were not trying to say that Kelly was the one true rule.)
Hm. I guess I should work harder on articulating what position I would argue for wrt Kelly. I basically think there exist good heuristic arguments for Kelly, but people often confuse them for more objective than they are (either in an unsophisticated way, like reading standard arguments for Kelly and thinking they're stronger than they are, or in a sophisticated way, like Peters' explicit attempt to rewrite the whole foundation of decision theory). Which leads me to reflexively snipe at people who appear to be arguing for Kelly, unless they clearly distinguish themselves from the wrong arguments.
I'm very interested in your potential post on corrections to Kelly.
↑ comment by Vitor · 2021-02-24T09:51:25.833Z · LW(p) · GW(p)
Comment/question about St. Petersburg and utilities: given any utility function u which goes to infinity, it should be possible to construct a custom St. Petersburg lottery for that utility function, right? I.e. a lottery with infinite expectation but arbitrarily low probability of being in the green. If we want to model an agent as universally rejecting such lotteries, it follows that utility cannot diverge, and thus must asymptotically approach some supremum (also requiring the natural condition that u is strictly monotone). Has this shape of utility function been seriously proposed in economics? Does it have a name?
Replies from: abramdemski↑ comment by abramdemski · 2021-02-24T16:01:23.739Z · LW(p) · GW(p)
I wondered if someone would bring this up! Yes, some people take this as a strong argument that utilities simply have to be bounded in order to be well-defined at all. AFAIK this is just called a "bounded utility function". Many of the standard representation theorems also imply that utility is bounded; this simply isn't mentioned as often as other properties of utility.
However, I am not one of the people who takes this view. It's perfectly consistent to define preferences which must be treated as unbounded utility. In doing so, we also have to specify our preferences about infinite lotteries. The divergent sum doesn't make this impossible; instead, what it does is allow us to take many different possible values (within some consistency constraints). So for example, a lottery with 50% probability of +1 util, 25% of -3, 1/8th chance of +9, 1/16 -27, etc can be assigned any expected value whatsoever. Its evaluation is subjective! So in this framework, preferences encode more information than just a utility for each possible world; we can't calculate all the expected values just from that. We also have to know how the agent subjectively values infinite lotteries. But this is fine!
How that works is a bit technical and I don't want to get into it atm. From a mathematical perspective, it's pretty "standard/obvious" stuff (for a graduate-level mathematician, anyway). But I don't think many professional philosophers have picked up on this? The literature on Infinite Ethics seems mostly ignorant of it?
Replies from: MSRayne↑ comment by MSRayne · 2023-03-10T22:30:27.707Z · LW(p) · GW(p)
Sorry to comment on a two year old post but: I'm actually quite intrigued by the arbitrary valuation of infinite lotteries thing here. Can you explain this a bit further or point me to somewhere I can learn about it? (P-adic numbers come to mind, but probably have nothing to do with it.)
Replies from: Yoav Ravid↑ comment by Yoav Ravid · 2023-03-11T05:01:02.213Z · LW(p) · GW(p)
Commenting on old posts is encouraged :)
comment by johnswentworth · 2021-02-23T16:04:55.724Z · LW(p) · GW(p)
I almost like what this post is trying to do, except that Kelly isn't just about repeated bets. It's about multiplicative returns and independent bets. If the returns from your bets add (rather than multiply), then Kelly isn't optimal. This is the case, for instance, for many high-frequency traders - the opportunities they exploit have limited capacity, so if they had twice as much money, they would not actually be able to bet twice as much.
The logarithm in the "maximize expected log wealth" formulation is a reminder of that. If returns are multiplicative and bets are independent, then the long run return will be the product of individual returns, and the log of long-run return will be the sum of individual log returns. That's a sum of independent random variables, so we apply the central limit theorem, and find that long-run return is roughly e^((number of periods)*(average expected log return)). To maximize that, we maximize expected log return each timestep, which is the Kelly rule.
Replies from: abramdemski, SimonM↑ comment by abramdemski · 2021-02-23T21:35:34.740Z · LW(p) · GW(p)
The logarithm in the "maximize expected log wealth" formulation is a reminder of that. If returns are multiplicative and bets are independent, then the long run return will be the product of individual returns, and the log of long-run return will be the sum of individual log returns. That's a sum of independent random variables, so we apply the central limit theorem, and find that long-run return is roughly e^((number of periods)*(average expected log return)). To maximize that, we maximize expected log return each timestep, which is the Kelly rule.
Wait, so, what's actually the argument?
It looks to me like the argument is "returns are multiplicative, so the long-run behavior is log-normal. But we like normals better than log-normals, so we take a log. Now, since we took a log, when we maximize we'll find that we're maximizing log-wealth instead of wealth."
But what if I like log-normals fine, so I don't transform things to get a regular normal distribution? Then when I maximize, I'm maximizing raw money rather than log money.
I don't see a justification of the Kelly formula here.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-02-23T22:36:34.324Z · LW(p) · GW(p)
The central limit theorem is used here to say "our long-run wealth will converge to e^((number of periods)*(average expected log return)), modulo error bars, with probability 1". So, with probability 1, that's the wealth we get (within error), and maximizing modal/median/any-fixed-quantile wealth will all result in the Kelly rule.
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2021-02-24T00:32:25.102Z · LW(p) · GW(p)
Under ordinary conditions, it's pretty safe to argue "such and such with probability 1, therefore, it's safe to pretend such-and-such". But this happens to be a case where doing so makes us greatly diverge from the Bayesian analysis -- ignoring the "most important" worlds from a pure expectation-maximization perspective (IE the ones where we repeatedly win bets, amassing huge sums).
So I'm very against sweeping that particular part of the reasoning under the rug. It's a reasonable argument, it's just one that imho should come equipped with big warning lights saying "NOTE: THIS IS A SEVERELY NON-BAYESIAN STEP IN THE REASONING. DO NOT CONFUSE THIS WITH EXPECTATION MAXIMIZATION."
Instead, you simply said:
To maximize that, we maximize expected log return each timestep, which is the Kelly rule.
which, to my eye, doesn't provide any warning to the reader. I just really think this kind of argument should be explicit about maximizing modal/median/any-fixed-quantile rather than the more common expectation maximization. Because people should be aware if one of their ideas about rational agency is based on mode/median/quantile maximization rather than expectation maximization.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-02-24T00:53:11.465Z · LW(p) · GW(p)
Ok, I buy that.
↑ comment by abramdemski · 2021-03-08T21:24:20.931Z · LW(p) · GW(p)
So, with probability 1, that's the wealth we get (within error), and maximizing modal/median/any-fixed-quantile wealth will all result in the Kelly rule.
Sorry, but I'm pulling out my "wait, what's actually the claim here?" guns again.
Kelly maximizes a kind of pseudo-mode. For example, for a sequence of two bets on coin flips, Kelly optimizes the world where you win one and lose one, which is the mode. However, for three such bets, Kelly optimizes the world where you win 1.5 and lose 1.5, which isn't even physically possible.
At first I thought there would be an obvious sense in which this is approximately mode-optimizing, getting closer and closer to mode-optimal in the limit. And maybe so. But it's not obvious.
The pseudo-mode is never more than 1 outcome away from the true mode. However, one bet can make a lot of difference, and can make more difference if we have more rounds to accumulate money. So certainly we can't say that Kelly's maximization problem (I mean the maximization of wealth in the pseudo-mode world) becomes epsilon close to true mode-optimization, in terms of numerical measurement of the quality of a given strategy.
I'm not even sure that the mode-optimizing strategy is a fixed-fraction strategy like Kelly. Maybe a mode-optimizing strategy does some clever things in worlds where it starts winning unusually much, to cluster those worlds together and make their winnings into a mode that's much better than the mode of Kelly.
our long-run wealth will converge to e^((number of periods)*(average expected log return)), modulo error bars
If the error bars became epsilon-close, then the argument would obviously work fine: the mode/median/quantile would all be very close to the same number, and this number would itself be very close to the pseudo-mode Kelly optimizes. So then Kelly would clearly come very close to optimizing all these numbers.
If the error bars became epsilon-close in ratio instead of in absolute difference, we could get a weaker but still nice guarantee: Kelly might fall short of mode-optimal by millions of dollars, but only in situations where "millions" is negligible compared to total wealth. This is comforting if we have diminishing returns in money.
But because any one bet can change wealth by a non-vanishing fraction (in general, and in particular when following Kelly), we know neither of those bounds can hold.
So in what sense, if any, does Kelly maximize mode/median/quantile wealth?
I'm suspecting that it may only maximize approximate mode/median/quantile, rather than approximately maximizing mode/median/quantile.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-03-08T23:14:03.955Z · LW(p) · GW(p)
Just think of the whole thing on a log scale. The error bars become epsilon close in ratio on a log scale. There's some terms and conditions to that approximation - average expected log return must be nonzero, for instance. But it shouldn't be terribly restrictive.
If your immediate thought is "but why consider things on a log scale in the first place?", then remember that we're talking about mode/order statistics, so monotonic transformations are totally fine.
(Really, though, if we want to be precise... the exact property which makes Kelly interesting is that if you take the Kelly strategy and any other strategy, and compare them to each other, then Kelly wins with probability 1 in the long run. That's the property which tells us that Kelly should show up in evolved systems. We can get that conclusion directly from the central limit theorem argument: as long as the "average expected log return" term grows like O(n), and the error term grows like O(sqrt(n)) or slower, we get the result. In order for a non-Kelly strategy to beat Kelly in the long run with greater-than-0 probability, it would somehow have to grow the error term by O(n).)
Replies from: abramdemski↑ comment by abramdemski · 2021-03-09T01:32:32.551Z · LW(p) · GW(p)
If your immediate thought is "but why consider things on a log scale in the first place?", then remember that we're talking about mode/order statistics, so monotonic transformations are totally fine.
Riiight, but, "totally fine" doesn't here mean "Kelly approximately maximizes the mode as opposed to maximizing an approximate mode", does it?
I have approximately two problems with this:
- Bounding the ratio of log wealth compared to a true mode-maximizer would be reassuring if my utility was doubly logarithmic. But if it's approximately logarithmic, this is little comfort.
- But are we even bounding the ratio of log wealth to a true mode-maximizer? As I mentioned, I'm not sure a mode-maximizer is even a constant-fraction strategy.
Sorry if I'm being dense, here.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-03-09T18:27:19.772Z · LW(p) · GW(p)
Actually, you're right, I goofed. Monotonic increasing transformation respects median or order statistics, so e.g. max median F(u) = F(max median u) (since F commutes with both max and median), but mode will have an additional term contributed by any nonlinear transformation of a continuous distribution. (It will still work for discrete distributions - i.e. max mode F(u) = F(max mode u) for u discrete, and in that case F doesn't even have to be monotonic.)
So I guess the argument for median is roughly: we have some true optimum policy and Kelly policy , and , which implies as long as F is continuous and strictly increasing.
↑ comment by SimonM · 2021-02-23T17:20:43.887Z · LW(p) · GW(p)
Yeah - I agree, that was what I was trying to get at. I tried to address (the narrower point) here:
Compounding is multiplicative, so it becomes "natural" (in some sense) to transform everything by taking logs.
But I agree giving some examples of where it doesn't apply would probably have been helpful to demonstrate when it is useful
comment by SimonM · 2021-02-23T12:19:21.878Z · LW(p) · GW(p)
This is my first post, so I would appreciate any feedback. This started out as a comment on one of the other threads but kept on expanding from there.
I'm also tempted to write "Contra Kelly Criterion" or "Kelly is just the start" where I write a rebuttal to using Kelly. (Rough sketch - Kelly is not enough you need to understand your edge, Kelly is too volatile). Or "Fractional Kelly is the true Kelly" (either a piece about how fractional Kelly accounts for your uncertainty vs market uncertainty OR a piece about how fractional Kelly is about power utilities OR a piece about fractional Kelly is optimal in some risk-return sense)
↑ comment by johnswentworth · 2021-02-23T18:21:34.107Z · LW(p) · GW(p)
This was a pretty solid post, and outstanding for a first post. Well done. A few commenters said the tone seemed too strong or something along those lines, but I personally think that's a good thing. "Strong opinions, weakly held" is a great standard to adhere to; at least some pushback in the comments is a good thing. I think your writing fits that standard well.
↑ comment by gjm · 2021-02-23T16:34:02.553Z · LW(p) · GW(p)
Of those, I think I would vote for one of the fractional-Kelly ones -- providing arguments for something (fractional Kelly) rather than merely against naive Kelly. (Suppose I think one should "Kelly bet on everything", and you write an article saying that Kelly is too volatile, and I read it and am convinced. Now I know that what I've been doing is wrong, but I don't know what I should be doing instead. On the other hand, if instead I read an article saying that fractional Kelly is better in specific circumstances for specific reasons, then it probably also gives some indication of how to choose the fraction one uses, and now I have not merely an awareness that my existing strategy is bad but a concrete better strategy to use in future.)
↑ comment by abramdemski · 2021-02-23T21:42:29.974Z · LW(p) · GW(p)
I appreciated that you posted this, and I think your further proposed post(s) sound good, too!
To my personal taste, my main disappointment when reading the post was that you didn't expand this section more:
Utilities and repeated bets are two sides of the same coin
I think this is fairly clear - "The time interpretation of expected utility theory" (Peters, Adamou) prove this. I don't want to say too much more about this. This section is mostly to acknowledge that:
- Yes, Kelly is maximising log utility
- No, it doesn't matter which way you think about this
- Yes, I do think thinking in the repeated bets framework is more useful
But that's a perfectly reasonable choice given (a) writing time constraints, (b) time constraints of readers. You probably shouldn't feel pressured to expand arguments out more as opposed to writing up rough thoughts with pointers to the info.
Speaking of which, I appreciated all the references you included!
Replies from: SimonM↑ comment by SimonM · 2021-02-23T21:51:46.643Z · LW(p) · GW(p)
Yeah, I think I'm about to write a reply to your massive comment, but I think I'm getting closer to understanding. I think what I really need to do is write my "Kelly is Black-Scholes for utility" post.
I think that (roughly) this post isn't aimed at someone who has already decided what their utility is. Most of the examples you didn't like / saw as non-sequitor were explicitly given to help people think about their utility.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-23T22:09:56.230Z · LW(p) · GW(p)
I think that (roughly) this post isn't aimed at someone who has already decided what their utility is. Most of the examples you didn't like / saw as non-sequitor were explicitly given to help people think about their utility.
Ah, I suspect this is a mis-reading of my intention. For a good portion of my long response, I was speaking from the perspective of a standard Bayesian. Standard Bayesians have already decided what their utility is. I didn't intend that part as my "real response". Indeed, I intended some of it to sound a bit absurd. However, a lotta folks round here are real fond of Bayes, so articulating "the bayesian response" seems relevant.
If you'd wanted to forestall that particular response, in writing the piece, I suppose you could have been more explicit about which arguments are Bayesian, and which are explicitly anti-Bayesian (IE Peters), and where you fall wrt accepting Bayesian / anti-Bayesian assumptions. Partly I thought you might be pretty Bayesian and would take "Bayesians wouldn't accept this argument" pretty seriously. (Although I also had probability on you being pretty anti-Bayesian.)
↑ comment by Oscar_Cunningham · 2021-02-23T13:29:20.879Z · LW(p) · GW(p)
Why teach about these concepts in terms of the Kelly criterion, if the Kelly criterion isn't optimal? You could just teach about repeated bets directly.
Replies from: SimonM↑ comment by SimonM · 2021-02-23T14:21:39.834Z · LW(p) · GW(p)
A couple of reasons:
- For whatever reason, people seem to really like Kelly criterion related posts at the moment.
- I think Kelly is a good framework for thinking about things
- "Kelly is about repeated bets" could easily be "Kelly is about bet sizing"
- "Kelly is Black-Scholes for utility"
- Kelly is optimal (in some very concrete senses) and fractional-Kelly is optional in some other senses which I think people don't discuss enough
comment by abramdemski · 2021-02-23T18:30:57.915Z · LW(p) · GW(p)
I've only skimmed this post so far, so, I'll need to read it in greater detail. However, I think this is quite related to Nassim Taleb and Ole Peters' critique of Bayesian decision theory [LW · GW]. I've left fairly extensive comments there, although I'm afraid I changed my mind a couple of times as I read deeper into the material, and there's not a nice summary of my final assessment.
I would currently defend the following statements:
- From a Bayesian standpoint, Kelly is all about logarithmic utility, and the arguments about repeated bets don't make very much sense.
- From a frequentist standpoint, the arguments about repeated bets make way more sense. Ole Peters is developing a true frequentist decision theory: it used to be that Bayesianism was the only game in town if you wanted your philosophy of statistics to also give you decision theory, but no longer!
- I ultimately find Peters' decision theory unsatisfying. It promises to justify different strategies for different situations (EG logarithmic utility for Kelly-type scenarios), but really, pulls the quantity to be maximized out of thin air (IE the creativity of the practitioner). It's slight of hand.
Anyway, I'll read the post more closely, and go further into my critique of Peters if it seems relevant.
Replies from: johnswentworth, SimonM↑ comment by johnswentworth · 2021-02-23T19:09:08.425Z · LW(p) · GW(p)
From a Bayesian standpoint, Kelly is all about logarithmic utility, and the arguments about repeated bets don't make very much sense.
This disagrees with my current understanding, so I'd be interested to hear the reasoning.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-23T21:28:11.513Z · LW(p) · GW(p)
Well, here's my longer response [LW(p) · GW(p)]!
↑ comment by SimonM · 2021-02-23T19:58:59.719Z · LW(p) · GW(p)
Yes - I cited Peters in the post (and stole one of their images). Personally I don't actually think what they are doing has as much value as they seem to think, although that's a whole other conversation. I basically think something akin to your third bullet point.
Having read your comments on the other post, I think I understand your critique, and I don't think there's much more to be said if you take the utility as axiomatic. However, I guess the larger point I'm trying to make is there are other reasons to care about Kelly other than if you're a log-utility maximiser. (Several of which you mention in your post)
comment by gjm · 2021-02-23T16:27:09.227Z · LW(p) · GW(p)
There's something odd about the tone of this piece. It begins by saying three times (three times!) "Kelly isn't about logarithmic utility. Kelly is about repeated bets." Then, later, it says "Yes, Kelly is maximising log utility. No, it doesn't matter which way you think about this".
I think you have to choose between "You can think about Kelly in terms of maximizing utility = log(wealth), and that's OK" and "Thinking about it that way is sufficiently not-OK that I wrote an article that says not to do it in the title and then reiterates three times in a row that you shouldn't do it".
I do agree that there are excellent arguments for Kelly-betting that assume very little about your utility function. (E.g., if you are going to make a long series of identical bets at given odds then almost certainly the Kelly bet leaves you better off at the end than any different bet.) And I do agree that there's something a bit odd about focusing on details of the formula rather than the underlying principles. (Though I don't think "odd" is the same as "wrong"; if you ever expect to be making Kelly bets, or non-Kelly bets informed by the Kelly criterion, it's not a bad idea to have a memorable form of the formula in your head, as well as the higher-level concept that maximizing expected log wealth is a good idea.) But none of that seems to explain how cross you seem to be about it at the start of the article.
Replies from: SimonM↑ comment by SimonM · 2021-02-23T17:16:23.939Z · LW(p) · GW(p)
Thanks! That's helpful. I definitely wrote this rather stream of consciousness and I definitely was more amped up about what I was going to say at the start than I was by the time I'd gotten halfway through. EDIT: I've changed the title an added a note at the top
I think the section where I say "it doesn't matter how you think about this" I mean it something in the sense of: "Prices and vols are equivalent in a Black-Scholes world, it doesn't matter if you think in terms of prices of vols, but thinking in terms of vols is usually much more helpful".
I also agree that having a handy version of the formula is useful. I basically think of Kelly in the format you do in your comment I highlighted and I think I would never have written this if someone else hadn't taken that comment butchered it a little but and it became a (somewhat) popular post. (Roughly I started writing a long fairly negative comment on that post, and tried to turn it into something more positive. I see I didn't quite manage to avoid all the anger issues that entails).
comment by lsusr · 2021-02-23T20:56:41.026Z · LW(p) · GW(p)
We have a stock which returns 50% or -40%. If we put all our money in this stock, we are going to lose it over time since but on any given day, this stock has a positive expected return.
I like this example as a way of thinking about the problem.
comment by SarahNibs (GuySrinivasan) · 2021-02-23T17:33:55.350Z · LW(p) · GW(p)
This post makes some good points, too strongly. I will now proceed to make some good points, too rambly.
F=ma is a fantastically useful concept, even if in practice the scenario is always more complicated than just "apply this formula and you win". It's short and intuitive and ports the right ideas about energy and mass and stuff into your brain.
Maximizing expected value is a fantastically useful concept.
Maximizing expected value at a time t after many repeated choices is a fantastically useful concept.
(Edit: see comments, there are false statements incoming. Leaving it all up for posterity.) It turns out that maximizing expected magnitude of value at every choice is very close to the optimal way to maximize your expected value at a time t after many repeated choices. Kelly is a nice, intuitive, easy heuristic for doing so.
So yes, what you really want to do is maximize something like "your total wealth at times t0 and t1 and t2 and t3 and... weighted by how much you care about having wealth at those times, or something" and the way to do that is to implement a function which knows there will be choices in the future and remembers to take into account now, on this choice having the power to maximally exploit those future choices, aka think about repeated bets. But also the simple general way to do something very close to that maximization is just "maximize magnitude of wealth", and the intuitions you get from thinking "maximize magnitude of wealth" are more easily ported than the intuitions you get from thinking "I have a universe of future decisions with some distribution and I will think about all of them and determine the slightly-different-from-maximize-log-wealth way to maximize my finnicky weighted average over future selves' wealth".
Do you need to think about whether you should use your naive estimate of the probability you win this bet, when plugging into Kelly to get an idea of what to do? Absolutely. If you're not sure of the ball's starting location, substituting a point estimate with wide variance into the calculation which eventually feeds into F=ma will do bad things and you should figure out what those things are. But starting from F=ma is still the nice, simple concept which will be super helpful to your brain.
Kelly is about one frictionless sphere approximation to [the frictionless sphere approximation which is maximizing magnitude of wealth]. Bits that were rubbed off to form the spheres involve repeated bets, for sure.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-23T22:24:12.966Z · LW(p) · GW(p)
Maximizing expected value is a fantastically useful concept.
Maximizing expected value at a time t after many repeated choices is a fantastically useful concept.
It turns out that maximizing expected magnitude of value at every choice is very close to the optimal way to maximize your expected value at a time t after many repeated choices. Kelly is a nice, intuitive, easy heuristic for doing so.
I'm not 100% sure what mathematical fact you are trying to refer to here, but I am worried that you are stating a falsehood.
Slightly editing stuff from another comment of mine:
In a one-step scenario, the Bayesian wants to maximize where is your starting money and is a random variable for the payoff-per-dollar of your strategy. In a two-step scenario, the Bayesian wants to maximize . And so on. If , this allows us to push the expectation inwards; (the last step holds because we assume the random variables are independent). So in that case, we could just choose the best one-step strategy and apply it at each time-step.
In other words, starting with the idea of raw expectation maximization (maximizing money, so , where is our bankroll) and adding the idea of iteration, we don't get any closer to Kelly. Kelly isn't an approximately good strategy for the version of the game with a lot of iterations. The very same greedy one-step strategy remains optimal forever.
But I could be misunderstanding the point you were trying to communicate.
Replies from: GuySrinivasan↑ comment by SarahNibs (GuySrinivasan) · 2021-02-25T16:24:25.166Z · LW(p) · GW(p)
You're absolutely right! I think I have a true intuition I'm trying to communicate, and will continue to think about it and see, but it might turn out that the entirety of the intuition can be summarized as "actually the utility is nonlinear in money".
comment by pilord · 2021-02-23T13:54:17.507Z · LW(p) · GW(p)
I’m not sure what prompted all of this effort, and I’ve rarely heard Kelly described as corresponding to log utility, only ever as an aside about mean-variance optimization. There, log utility corresponds to A=1, which is also the Kelly portfolio. That is the maximally aggressive portfolio, and most people are much, much more risk averse.
If anything, I’d say that the Kelly - log utility connection obviously suggests one point, which is that most people are far too risk-averse (less normatively, most people don’t have log utility functions). The exception is Buffett - empirically he does, subject to leverage constraints.
Replies from: abramdemski, abramdemski, SimonM↑ comment by abramdemski · 2021-02-23T22:11:42.055Z · LW(p) · GW(p)
I’m not sure what prompted all of this effort, and I’ve rarely heard Kelly described as corresponding to log utility, only ever as an aside about mean-variance optimization. There, log utility corresponds to A=1, which is also the Kelly portfolio. That is the maximally aggressive portfolio, and most people are much, much more risk averse.
Where can I read more about this?
↑ comment by abramdemski · 2021-02-23T18:13:43.855Z · LW(p) · GW(p)
I would defend the idea that Kelly is more genuinely about log utility when approached from a strict Bayesian perspective, ie, a Bayesian has little reason to buy the other arguments in favor of Kelly.
↑ comment by SimonM · 2021-02-23T14:32:09.241Z · LW(p) · GW(p)
I’m not sure what prompted all of this effort,
The comments section here [LW · GW] and the post and comments section here [LW · GW]. To be completely frank, my post started out as a comment similar to yours in those threads. "I'm not sure what led you to post this". (Especially the Calculating Kelly post which seemed to mostly copy and make worse this comment [LW(p) · GW(p)]).
I’ve rarely heard Kelly described as corresponding to log utility,
I actually agree with you that aside from LW I haven't really seen Kelly discussed in the context of log-utilities, which is why I wanted to address this here rather than anywhere else.
only ever as an aside about mean-variance optimization
Okay, here our experiences differ. I see Kelly coming up in all sorts of contexts, not just relating to mean-variance portfolio optimization for a CRRA-utility or whatever.
If anything, I’d say that the Kelly - log utility connection obviously suggests one point, which is that most people are far too risk-averse (less normatively, most people don’t have log utility functions). The exception is Buffett - empirically he does, subject to leverage constraints.
So I agree with this. I'd quite happily write the "you are too risk averse" post, but I think Putanumonit [LW · GW] already did a better job than I could hope to do on that