Radical Probabilism
post by abramdemski · 2020-08-18T21:14:19.946Z · LW · GW · 49 commentsContents
What Is Dogmatic Probabilism? What Is Radical Probabilism? Radical Probabilism and Dutch Books Rejecting the Dutch Book for Bayesian Updates Generalized Updates Other Rationality Properties Convergence Conservation of Expected Evidence Calibration Bayes From a Distance The Rationality of Acquaintances Wetware Bayes But Where Do Updates Come From? Virtual Evidence Integrating Expert Opinions Can Dogmatic Probabilists Use Virtual Evidence? Virtual evidence abandons the ratio formula. Virtual evidence requires probability functions to take arguments which aren't part of the event space. Representing Fluid Updates Non-Sequential Prediction Making the Meta-Bayesian Update It All Adds Up to Normality Don't Predictably Violate Bayes Exchange Virtual Evidence Don't Be So Realist About Your Own Utility Function Not So Radical After All Recommended Reading None 49 comments
This is an expanded version of my talk [LW · GW]. I assume a high degree of familiarity with Bayesian probability theory.
Toward a New Technical Explanation of Technical Explanation [LW · GW] -- an attempt to convey the practical implications of logical induction -- was one of my most-appreciated posts, but I don't really get the feeling that very many people have received the update. Granted, that post was speculative, sketching what a new technical explanation of technical explanation might look like. I think I can do a bit better now.
If the implied project of that post had really been completed, I would expect new practical probabilistic reasoning tools, explicitly violating Bayes' law. For example, we might expect:
- A new version of information theory.
- An update to the "prediction=compression [LW · GW]" maxim, either repairing it to incorporate the new cases, or explicitly denying it and providing a good intuitive account of why it was wrong.
- A new account of concepts such as mutual information, allowing for the fact that variables have behavior over thinking time; for example, variables may initially be very correlated, but lose correlation as our picture of each variable becomes more detailed.
- New ways of thinking about epistemology.
- One thing that my post did manage to do was to spell out the importance of "making advanced predictions", a facet of epistemology which Bayesian thinking does not do justice to.
- However, I left aspects of the problem of old evidence open, rather than giving a complete way to think about it.
- New probabilistic structures.
- Bayesian Networks are one really nice way to capture the structure of probability distributions, making them much easier to reason about. Is there anything similar for the new, wider space of probabilistic reasoning which has been opened up?
Unfortunately, I still don't have any of those things to offer. The aim of this post is more humble. I think what I originally wrote was too ambitious for didactic purposes. Where the previous post aimed to communicate the insights of logical induction by sketching broad implications, I here aim to communicate the insights in themselves, focusing on the detailed differences between classical Bayesian reasoning and the new space of ways to reason.
Rather than talking about logical induction directly, I'm mainly going to explain things in terms of a very similar philosophy which Richard Jeffrey invented -- apparently starting with his phd dissertation in the 50s, although I'm unable to get my hands on it or other early references to see how fleshed-out the view was at that point. He called this philosophy radical probabilism. Unlike logical induction, radical probabilism appears not to have any roots in worries about logical uncertainty or bounded rationality. Instead it appears to be motivated simply by a desire to generalize, and a refusal to accept unjustified assumptions. Nonetheless, it carries most of the same insights.
Radical Probabilism has not been very concerned with computational issues, and so constructing an actual algorithm (like the logical induction algorithm) has not been a focus. (However, there have been some developments -- see historical notes at the end.) This could be seen as a weakness. However, for the purpose of communicating the core insights, I think this is a strength -- there are fewer technical details to communicate.
A terminological note: I will use "radical probabilism" to refer to the new theory of rationality (treating logical induction as merely a specific way to flesh out Jeffrey's theory). I'm more conflicted about how to refer to the older theory. I'm tempted to just use the term "Bayesian", implying that the new theory is non-Bayesian -- this highlights its rejection of Bayesian updates. However, radical probabilism is Bayesian in the most important sense. Bayesianism is not about Bayes' Law. Bayesianism is, at core, about the subjectivist interpretation of probability. Radical probabilism is, if anything, much more subjectivist.
However, this choice of terminology makes for a confusion which readers (and myself) will have to carefully avoid: confusion between Bayesian probability theory and Bayesian updates. The way I'm using the term, a Bayesian need not endorse Bayesian updates.
In any case, I'll default to Jeffrey's term for the opposing viewpoint: dogmatic probabilism. (I will occasionally fall into calling it "classical Bayesianism" or similar.)
What Is Dogmatic Probabilism?
Dogmatic Probabilism is the doctrine that the conditional probability is also how we update probabilistic beliefs: any rational change in beliefs should be explained by a Bayesian update.
We can unpack this a little:
- (Dynamic Belief:) A rational agent is understood to have different beliefs over time -- call these
- (Static Rationality:) At any one time, a rational agent's beliefs are probabilistically coherent (obey the Kolmogorov axioms, or a similar axiomatization of probability theory).
- (Empiricism:) Reasons for changing beliefs across time are given entirely by observations -- that is, propositions which the agent learns.
- (Dogmatism of Perception:) Observations are believed with probability one, once learned.
- (Rigidity:) Upon observing a proposition , conditional probabilities are unmodified.
The assumptions minus empiricism imply that an update on observing is a Bayesian update: if we start with and update on to get , then must equal 1, and . So we must have . Then, empiricism says that this is the only kind of update we can possibly have.
What Is Radical Probabilism?
Radical probabilism accepts assumptions #1 and #2, but rejects the rest. (Logical Induction need not follow axiom #2, either, since beliefs at any given time only approximately follow the probability laws -- however, it's not necessary to discuss this complication here. Jeffrey's philosophy did not attempt to tackle such things.)
Jeffrey seemed uncomfortable with updating to 100% on anything, making dogmatism of perception untenable. A similar view is already popular on LessWrong [LW · GW], but it seems that no one here took the implication and denied Bayesian updates as a result. (Bayesian updates have been questioned for other reasons [LW · GW], of course.) This is a bit of an embarassment. But fans of Bayesian updates reading this are more likely to accept that zero and one are probabilities, rather than give up Bayes.
Fortunately, this isn't actually the crux. Radical probabilism is a pure generalization of orthodox Bayesianism; you can have zero and one as probabilities, and still be a radical probabilist. The real fun begins not with the rejection of dogmatism of perception, but with the rejection of rigidity and empiricism.
This gives us a view in which a rational update from to can be almost anything. (You still can't update from to .) Simply put, you are allowed to change your mind. This doesn't make you irrational.
Yet, there are still some rationality constraints. In fact, we can say a lot about how rational agents think in this model. In place of assumptions #3-#5, we assume rational agents cannot be Dutch Booked.
Radical Probabilism and Dutch Books
Rejecting the Dutch Book for Bayesian Updates
At this point, if you're familiar with the philosophy of probability theory, you might be thinking: wait a minute, isn't there a Dutch Book argument for Bayesian updates? If radical probabilism accepts the validity of Dutch Book arguments, shouldn't it thereby be forced into Bayesian updates?
No!
As it turns out, there is a major flaw in the Dutch Book for Bayesian updates. The argument assumes that the bookie knows how the agent will update. (I encourage the interested reader to read the SEP section on diachronic Dutch Book arguments for details.) Normally, a Dutch Book argument requires the bookie to be ignorant. It's no surprise if a bookie can take our lunch money by getting us to agree to bets when the bookie knows something we don't know. So what's actually established by these arguments is: if you know how you're going to update, then your update had better be Bayesian.
Actually, that's not quite right: the argument for Bayesian updates also still assumes dogmatism of perception. If we relax that assumption, all we can really argue for is rigidity: if you know how you are going to update, then your update had better be rigid.
This leads to a generalized update rule, called Jeffrey updating (or Jeffrey conditioning).
Generalized Updates
Jeffrey updates keep the rigidity assumption, but reject dogmatism of perception. So, we're changing the probability of some sentence to , without changing any . There's only one way to do this:
In other words, the Jeffrey update interpolates linearly between the Bayesian update on and the Bayesian update on . This generalizes Bayesian updates to allow for uncertain evidence: we're not sure we just saw someone duck behind the corner, but we're 40% sure.
If this way of updating seems a bit arbitrary to you, Jeffrey would agree. It offers only a small generalization of Bayes. Jeffrey wants to open up much broader space:

As I've already said, the rigidity assumption can only be justified if the agent knows how it will update. Philosophers like to say the agent has a plan for updating: "If I saw a UFO land in my yard and little green men come out, I would believe I was hallucinating." This is something we've worked out ahead of time.
A non-rigid update, on the other hand, means you don't know how you'd react: "If I saw a convincing proof of P=NP, I wouldn't know what to think. I'd have to consider it carefully." I'll call non-rigid updates fluid updates.
For me, fluid updates are primarily about having longer to think, and reaching better conclusions as a result. That's because my main motivation for accepting a radical-probabilist view is logical uncertainty. Without such a motivation, I can't really imagine being very interested. I boggle at the fact that Jeffrey arrived at this view without such a motivation.
Dogmatic Probabilist: All I can say is: why??
Richard Jeffrey: I've explained to you how the Dutch Book for Bayesian updates fails. What more do you want? My view is simply what you get when you remove the faulty assumptions and keep the rest.
Dogmatic Probabilist (DP): I understand that, but why should anyone be interested in this theory? OK, sure, I CAN make Jeffrey updates without getting Dutch Booked. But why ever would I? If I see a cloth in dim lighting, and update to 80% confident the cloth is red, I update in that way because of the evidence which I've seen, which is itself fully confident. How could it be any other way?
Richard Jeffrey (RJ): Tell me one peice of information you're absolutely certain of in such a situation.
DP: I'm certain I had that experience, of looking at the cloth.
RJ: Surely you aren't 100% sure you were looking at cloth. It's merely very probable.
DP: Fine then. The experience of looking at ... what I was looking at.
RJ: I'll grant you that tautologies have probability one.
DP: It's not a tautology... it's the fact that I had an experience, rather than none!
RJ: OK, but you are trying to defend the position that there is some observation, which you condition on, which explains your 80% confidence the cloth is red. Conditioning on "I had an experience, rather than none" won't do that. What proposition are you confident in, which explains your less-confident updates?
DP: The photons hitting my retinas, which I directly experience.
RJ: Surely not. You don't have any detailed knowledge of that.
DP: OK, fine, the individual rods and cones.
RJ: I doubt that. Within the retina, before any message gets sent to the brain, these get put through an opponent process which sharpens the contrast and colors. You're not perceiving rods and cones directly, but rather a probabilistic guess at light conditions based on rod and cone activation.
DP: The output of that process, then.
RJ: Again I doubt it. You're engaging in inner-outer hocus pocus.* There is no clean dividing line before which a signal is external, and after which that signal has been "observed". The optic nerve is a noisy channel, warping the signal. And the output of the optic nerve itself gets processed at V1, so the rest of your visual processing doesn't get direct access to it, but rather a processed version of the information. And all this processing is noisy. Nowhere is anything certain. Everything is a guess. If, anywhere in the brain, there were a sharp 100% observation, then the nerves carrying that signal to other parts of the brain would rapidly turn it into a 99% observation, or a 90% observation...
DP: I begin to suspect you are trying to describe human fallibility rather than ideal rationality.
RJ: Not so! I'm describing how to rationally deal with uncertain observations. The source of this uncertainty could be anything. I'm merely giving human examples to establish that the theory has practical interest for humans. The theory itself only throws out unnecessary assumptions from the usual theory of rationality -- as we've already discussed.
DP: (sigh...) OK. I'm still never going to design an artificial intelligence to have uncertain observations. It just doesn't seem like something you do on purpose. But let's grant, provisionally, that rational agents could do so and still be called rational.
RJ: Great.
DP: So what's this about giving up rigidity??
RJ: It's the same story: it's just another assumption we don't need.
DP: Right, but then how do we update?
RJ: However we want.
DP: Right, but how? I want a constructive story for where my updates come from.
RJ: Well, if you precommit to update in a predictable fashion, you'll be Dutch-Bookable unless it's a rigid fashion.
DP: So you admit it! Updates need to be rigid!
RJ: By no means!
DP: But updates need to come from somewhere. Whether you know it or not, there's some mechanism in your brain which produces the updates.
RJ: Whether you know it or not is a critical factor. Updates you can't anticipate need not be Bayesian.
DP: Right, but... the point of epistemology is to give guidance about forming rational beliefs. So you should provide some formula for updating. But any formula is predictable. So a formula has to satisfy the rigidity condition. So it's got to be a Bayesian update, or at least a Jeffrey update. Right?
RJ: I see the confusion. But epistemology does not have to reduce things to a strict formula in order to provide useful advice. Radical probabilism can still say many useful things. Indeed, I think it's more useful, since it's closer to real human experience. Humans can't always account for why they change their minds. They've updated, but they can't give any account of where it came from.
DP: OK... but... I'm sure as hell never designing an artificial intelligence that way.
I hope you see what I mean. It's all terribly uninteresting to a typical Bayesian, especially with the design of artificial agents in mind. Why consider uncertainty about evidence? Why study updates which don't obey any concrete update rules? What would it even mean for an artificial intelligence to be designed with such updates?
In the light of logical uncertainty, however, it all becomes well-motivated. Updates are unpredictable not because there's no rule behind them -- nor because we lack knowledge of what exactly that rule is -- but because we can't always anticipate the results of computations before we finish running them. There are updates without corresponding evidence because we can think longer to reach better conclusions, and doing so does not reduce to Bayesian conditioning on the output of some computation. This doesn't imply uncertain evidence in exactly Jeffrey's sense, but it does give us cases where we update specific propositions to confidence levels other than 100%, and want to know how to move other beliefs in response. For example, we might apply a heuristic to determine that some number is very very likely to be prime, and update on this information.
Still, I'm very impressed with Jeffrey for reaching so many of the right conclusions without this motivation.
Other Rationality Properties
So far, I've emphasized that fluid updates "can be almost anything". This makes it sound as if there are essentially no rationality constraints at all! However, this is far from true. We can establish some very important properties via Dutch Book.
Convergence
No single update can be condemned as irrational. However, if you keep changing your mind again and again without ever settling down, that is irrational. Rational beliefs are required to eventually move less and less, converging to a single value.
Proof: If there exists a point which your beliefs forever oscillate around (that is, your belief falls above infinitely often, and falls below infinitely often, for some ) then a bookie can make money off of you as follows: when your belief is below , the bookie makes a bet in favor of the proposition in question, at odds. When your belief is above , the bookie offers to cancel that bet for a small fee. The bookie earns the fee with certainty, since your beliefs are sure to swing down eventually (allowing the bet to be placed) and are sure to swing up some time after that (allowing the fee to be collected). What's more, the bookie can do this again and again and again, turning you into a money pump.
If there exists no such , then your beliefs must converge to some value.
Caveat: this is the proof in the context of logical induction. There are other ways to establish convergence in other formalizations of radical probabilism.
In any case, this is really important. This isn't just a nice rationality property. It's a nice rationality property which dogmatic probilists don't have. Lack of a convergence guarantee is one of the main criticisms Frequentists make of Bayesian updates. And it's a good critique!
Consider a simple coin-tossing scenario, in which we have two hypotheses: posits that the probability of heads is , and posits that the probability of heads is . The prior places probability on both of these hypotheses. The only problem is that the true coin probability is . What happens? The probabilities and will oscillate forever without converging.
Proof: The quantity will take a random walk as we keep flipping the fair coin. A random walk returns to zero infinitely often (a phenomenon known as gambler's ruin). At each such point, evidence is evenly balanced between the two hypotheses, so we've returned to the prior. Then, the next flip is either heads or tails. This results in a probability of for one of the hypotheses, and for the other. This sequence of events happens infinitely often, so and keep experiencing changes of size at least , never settling down.
Now, the objection to Bayesian updates here isn't just that oscillating forever looks irrational. Bayesian updates are supposed to help us predict the data well; in particular, you might think they're supposed to help us minimize log-loss. But here, we would be doing much better if beliefs would converge toward . The problem is, Bayes takes each new bit of evidence just as seriously as the last. Really, though, a rational agent in this situation should be saying: "Ugh, this again! If I send my probability up, it'll come crashing right back down some time later. I should skip all the hassle and keep my probability close to where it is."
In other words, a rational agent should be looking out for Dutch Books against itself, including the non-convergence Dutch Book. Its probabilities should be adjusted to avoid such Dutch Books.
DP: Why should I be bothered by this example? If my prior is as you describe it, I assign literally zero probability to the world you describe -- I know the coin isn't fair. I'm fine with my inference procedure displaying pathological behavior in a universe I'm absolutely confident I'm not in.
RJ: So you're fine with an inference procedure which performs abysmally in the real world?
DP: What? Of course not.
RJ: But the real world cannot possibly be in your hypothesis space. It's too big. [? · GW] You can't explicitly write it down.
DP: Physicists seem to be making good progress.
RJ: Sure, but those aren't hypotheses which you can directly use to anticipate your experiences. They require too much computation. Anything that can fit in your head, can't be the real world.
DP: You're dealing with human frailty again.
RJ: On the contrary. Even idealized agents can't fit inside a universe they can perfectly predict. To see the contradiction, just let two of them play rock-paper-scissors with each other. Anything that can anticipate what you expect, and then do something else, can't be in your hypothesis space. But let me try a different angle of attack. Bayesianism is supposed to be the philosophy of subjective probability. Here, you're arguing as if the prior represented an objective fact about how the universe is. It isn't, and can't be.
DP: I'll deal with both of those points at once. I don't really need to assume that the actual universe is within my hypothesis space. Constructing a prior over a set of hypotheses guarantees you this: if there is a best element in that class, you will converge to it. In the coin-flip example, I don't have the objective universe in my set of hypotheses unless I can perfectly predict every coin-flip. But the subjective hypothesis which treats the coin as fair is the best of its kind. In the rock-paper-scissors example, rational players would similarly converge toward treating each other's moves as random, with probability on each move.
RJ: Good. But you've set up the punchline for me: if there is no best element, you lack a convergence guarantee.
DP: But it seems as if good priors usually do have a best element. Using Laplace's rule of succession, I can predict coins of any bias without divergence.
RJ: What if the coin lands as follows: 5 heads in a row, then 25 tails, then 125 heads, and so on, each run lasting for the next power of five. Then you diverge again.
DP: Ok, sure... but if the coin flips might not be independent, then I should have hypotheses like that in my prior.
RJ: I could keep trying to give examples which break your prior, and you could keep trying to patch it. But we have agreed on the important thing: good priors should have the convergence property. At least you've agreed that this is a desirable property not always achieved by Bayes.
DP: Sure.
In the end, I'm not sure who would win the counterexample/patch game: it's quite possible that there general priors with convergence guarantees. No computable prior has convergence guarantees for "sufficiently rich" observables [LW · GW] (ie, observables including logical combinations of observables). However, that's a theorem with a lot of caveats. In particular, Solomonoff Induction isn't computable, so might be immune to the critique. And we can certainly get rid of the problem by restricting the observables, EG by conditioning on their sequential order rather than just their truth [LW · GW]. Yet, I suspect all such solutions will either be really dumb, or uncomputable [LW · GW].
So there's work to be done here.
But, in general (ie without any special prior which does guarantee convergence for restricted observation models), a Bayesian relies on a realizability (aka grain-of-truth) assumption for convergence, as it does for some other nice properties [? · GW]. Radical probabilism demands these properties without such an assumption.
So much for technical details. Another point I want to make is that convergence points at a notion of "objectivity" for the radical probabilist. Although the individual updates a radical probabilist makes can go all over the place, the beliefs must eventually settle down to something. The goal of reasoning is to settle down to that answer as quickly as possible. Updates may appear arbitrary from the outside, but internally, they are always moving toward this goal.
This point is further emphasized by the next rationality property: conservation of expected evidence.
Conservation of Expected Evidence
The law of conservation of expected evidence [LW · GW] is a dearly beloved Bayesian principle. You'll be glad to hear that it survives unscathed:
In the above, is your current belief in some proposition ; is some future belief about (so I'm assuming ); and is the expected value operator according to your current beliefs. So what the equation says is: your current beliefs equal your expected value of your future beliefs. This is just like the usual formulation of no-expected-net-update, except we no longer take the expectation with respect to evidence, since a non-Bayesian update may not be grounded in evidence.
Proof: Suppose . One of the two numbers is higher, and the other lower. Suppose is the lower number. Then a bookie can buy a certificate paying $ on day ; we will willingly sell the bookie this for $. The bookie can also sell us a certificate paying $1 if , for a price of $. At time , the bookie gains $ due to the first certificate. It can then buy the second certificate back from us for $, using the winnings. Overall, the bookie has now paid $ to us, but we have paid the bookie $, which we assumed was greater. So the bookie profits the difference.
If is the lower number instead, the same strategy works, reversing all buys and sells.
The key idea here is that both a direct bet on and a bet on will be worth later, so they'd better have the same price now, too.
I see this property as being even more important for a radical probabilist than it is for a dogmatic probabilist. For a dogmatic probabilist, it's a consequence of Bayesian conditional probability. For a radical probabilist, it's a basic condition on rational updates. With updates being so free to go in any direction, it's an important anchor-point.
Another name for this law is the martingale property. This is a property of many stochastic processes, such as Brownian motion. From wikipedia:
In probability theory, a martingale is a sequence of random variables (i.e., a stochastic process) for which, at a particular time, the conditional expectation of the next value in the sequence, given all prior values, is equal to the present value.
It's important that a sequence of rational beliefs have this property. Otherwise, future beliefs are different from current beliefs in a predictable way, and we would be better off updating ahead of time.
Actually, that's not immediately obvious, right? The bookie in the Dutch Book argument doesn't make money by updating to the future belief faster than the agent, but rather, by playing the agent's beliefs off of each other.
This leads me to a stronger property, which has the martingale property as an immediate consequence (strong self trust):
Again I'm assuming . The idea here is supposed to be: if you knew your own future belief, you would believe it already. Furthermore, you believe and are perfectly correlated: the only way you'd have high confidence in would be if it were very probably true, and the only way you'd have low confidence would be for it to be very probably false.
I won't try to prove this one. In fact, be wary: this rationality condition is a bit too strong. The condition holds true in the radical-probabilism formalization of Diachronic Coherence and Radical Probabilism by Brian Skyrms, so long as (see section 6 for statement and proof). However, Logical Induction argues persuasively that this condition is undesirable in specific cases, and replaces it with a slightly weaker condition (see section 4.12).
Nonetheless, for simplicity, I'll proceed as if strong self trust were precisely true.
At the end of the previous section, I promised that the current section would further illuminate my remark:
The goal of reasoning is to settle down to that answer as quickly as possible. Updates may appear arbitrary from the outside, but internally, they are always moving toward this goal.
The way radical probabilism allows just about any change when beliefs shift from to may make its updates seem irrational. How can the update be anything, and still be called rational? Doesn't that mean a radical probabilist is open to garbage updates?
No. A radical probabilist doesn't subjectively think all updates are equally rational. A radical probabilist trusts the progression of their own thinking, and also does not yet know the outcome of their own thinking; this is why I asserted earlier that a fluid update can be just about anything (barring the transformation of a zero into a positive probability). However, this does not mean that a radical probabilist would accept a psychedelic pill which arbitrarily modified their beliefs.
Suppose a radical probabilist has a sequence of beliefs . If they thought hard for a while, they could update to . On the other hand, if they took the psychedelic pill, their beliefs would be modified to become . The sequence would be abruptly disrupted, and go off the rails:
The radical probabilist does not trust whatever they believe next. Rather, the radical probabilist has a concept of virtuous epistemic process, and is willing to believe the next output of such a process. Disruptions to the epistemic process do not get this sort of trust without reason. (For those familiar with The Abolition of Man, this concept is very reminiscent of his "Tao".)
On the other hand, a radical probabilist could trust a different process. One person, , might trust that another person, , is better-informed about any subject:
This says that trusts on any subject if they've had the same amount of time to think. This leaves open the question of what thinks if has had longer to think. In the extreme case, it might be that thinks is better no matter how long has to think:
On the other hand, and can both be perfectly rational by the standards of radical probabilism and not trust each other at all. might not trust 's opinion no matter how long thinks.
(Note, however, that you do get eventual agreement on matters where good feedback is available -- much like in dogmatic Bayesianism, it's difficult for two Bayesians to disagree about empirical predictions for long.)
This means you can't necessarily replace one "virtuous epistemic process" with another. and might both be perfectly rational by the standards of radical probabilism, and yet the disrupted sequence would not be, because does not necessarily trust or subsequent s.
Realistically, we can be in this kind of position and not even know what constitutes a virtuous reasoning process by our standards. We generally think that we can "do philosophy" and reach better conclusions. But we don't have a clean specification of our own thinking process. We don't know exactly what counts as a virtuous continuation of our thinking vs a disruption.
This has some implications for AI alignment, but I won't try to spell them out here.
Calibration
One more rationality property before we move on.
One could be forgiven for reading Eliezer's A Technical Explanation of Technical Explanation [LW · GW] and coming to believe that Bayesian reasoners are calibrated. Eliezer goes so far as to suggest that we define probability in terms of calibration, so that what it means to say "90% probability" is that, in cases where you say 90%, the thing happens 9 out of 10 times.
However, the truth is that calibration is a neglected property in Bayesian probability theory. Bayesian updates do not help you learn to be calibrated, any more than they help your beliefs to be convergent.
We can make a sort of Dutch Book argument for calibration: if things happen 9-out-of-ten times when the agent says 80%, then a bookie can place bets with the agent at 85:15 odds and profit in the long run. (Note, however, that this is a bit different from typical Dutch Book arguments: it's a strategy in which the bookie risks some money, rather than just getting a sure gain. What I can say is that Logical Induction treats this as a valid Dutch Book, and so, we get a calibration property in that formalism. I'm not sure about other formalisations of Radical Probabilism.)
The intuition is similar to convergence: even lacking a hypothesis to explain it, a rational agent should eventually notice "hey, when I say 80%, the thing happens 90% of the time!". It can then improve its beliefs in future cases by adjusting upwards.
This illustrates "meta-probabilistic beliefs": a radical probabilist can have informed opinions about the beliefs themselves. By default, a classical Bayesian doesn't have beliefs-about-beliefs except as a result of learning about the world and reasoning about themselves as a part of the world, which is problematic in the classical Bayesian formalism [? · GW]. It is possible to add second-order probabilities, third-order, etc. But calibration is a case which collapses all those levels, illustrating how the radical probabilist can handle all of this more naturally.
I'm struck by the way calibration is something Bayesians obviously want. The set of people who advocate applying Bayes Law and the set of people who look at calibration charts for their own probabilities has a very significant overlap. Yet, Bayes' Law does not give you calibration. It makes me feel like more people should have noticed this sooner and made a bigger deal about it.
Bayes From a Distance
Before any more technical details about radical probabilism, I want to take a step back and give one intuition for what's going on here.
We can see radical probabilism as what a dogmatic Bayesian looks like if you can't see all the details.
The Rationality of Acquaintances
Imagine you have a roommate who is perfectly rational in the dogmatic sense: this roommate has low-level observations which are 100% confident, and performs a perfect Bayesian update on those observations.
However, observing your roommate, you can't track all the details of this. You talk to your roommate about some important beliefs, but you can't track every little Bayesian update -- that would mean tracking every sensory stimulus.
From your perspective, your roommate has constantly shifting beliefs, which can't quite be accounted for. If you are particularly puzzled by a shift in belief, you can discuss reasons. "I updated against getting a cat because I observed a hairball in our neighbor's apartment." Yet, none of the evidence discussed is itself 100% confident -- it's at least a little bit removed from low-level sense-data, and at least a little uncertain.
Yet, this is not a big obstacle to viewing your roommate's beliefs as rational. You can evaluate these beliefs on their own merits.
I've heard this model called Bayes-with-a-side-channel. You have an agent updating via Bayes, but part of the evidence is hidden. You can't give a formula for changes in belief over time, but you can still assert that they'll follow conservation of expected evidence, and some other rationality conditions.
What Jeffrey proposes is that we allow these dynamics without necessarily positing a side-channel to explain the unpredictable updates. This has an anti-reductionist flavor to it: updates do not have to reduce to observations. But why should we be reductionist in that way? Why would subjective belief updates need to reduce to observations?
(Note that Bayes-with-a-side-channel does not imply conditions such as convergence and calibration; so, Jeffrey's theory of rationality is more demanding.)
Wetware Bayes
Of course, Jeffrey would say that our relationship with ourselves is much like the roommate in my story. Our beliefs move around, and while we can often give some account of why, we can't give a full account in terms of things we've learned with 100% confidence. And it's not simply because we're a Bayesian reasoner who lacks introspective access to the low-level information. The nature of our wetware is such that there isn't really any place you can point to and say "this is a 100% known observation". Jeffrey would go on to point out that there's no clean dividing line between external and internal, so you can't really draw a boundary between external event and internal observation-of-that-event.
(I would remark that Jeffrey doesn't exactly give us a way to handle that problem; he just offers an abstraction which doesn't chafe on that aspect of reality so badly.)
Rather than imagining that there are perfect observations somewhere in the nervous system, we can instead imagine that a sensory stimulus exerts a kind of "evidential pressure" which can be less than 100%. These evidential pressures can also come from within the brain, as is the case with logical updates.
But Where Do Updates Come From?
Dogmatic probabilism raises the all-important question "where do priors come from?" -- but once you answer that, everything else is supposed to be settled. There have been many debates about what constitutes a rational prior.
Q. How can I find the priors for a problem?
A. Many commonly used priors are listed in the Handbook of Chemistry and Physics.
Q. Where do priors originally come from?
A. Never ask that question.
Q. Uh huh. Then where do scientists get their priors?
A. Priors for scientific problems are established by annual vote of the AAAS. In recent years the vote has become fractious and controversial, with widespread acrimony, factional polarization, and several outright assassinations. This may be a front for infighting within the Bayes Council, or it may be that the disputants have too much spare time. No one is really sure.
Q. I see. And where does everyone else get their priors?
A. They download their priors from Kazaa.
Q. What if the priors I want aren't available on Kazaa?
A. There's a small, cluttered antique shop in a back alley of San Francisco's Chinatown. Don't ask about the bronze rat.-- Eliezer Yudkowsky, An Intuitive Explanation of Bayes' Theorem
Radical probabilists put less emphasis on the prior, since a radical probabilist can effectively "decide to have a different prior" (updating their beliefs as if they'd swapped out one prior for another). However, they face a similarly large problem of where updates come from.
We are given a picture in which beliefs are like a small particle in a fluid, reacting to all sorts of forces (some strong and some weak). Its location gradually shifts as a result of Brownian motion. Presumably, the interesting work is being done behind the scenes, by whatever is generating these updates. Yet, Jeffrey's picture seems to mainly be about the dance of the particle, while the fluid around it remains a mystery.
A full answer to that question is beyond the scope of this post. (Logical Induction offers one fully detailed answer to that question.) However, I do want to make a few remarks on this problem.
- It might at first seem strange for beliefs to be so radically malleable to external pressures. But, actually, this is already the familiar Bayesian picture: everything happens due to externally-driven updates.
- Bayesian updates don't really answer the question of where updates come from, either. They take it as given that there are some "observations". Radical probabilism simply allows for a more general sort of feedback for learning.
- An orthodox probabilist might answer this challenge by saying something like: when we design an agent, we design sensors for it. These are connected in such a way as to feed in sensory observations. A radical probabilist can similarly say: when we design an agent, we get to decide what sort of feedback it uses to improve its beliefs.
The next section will give some practical, human examples of non-Bayesian updates.
Virtual Evidence
Bayesian updates are path-independent: it does not matter in what order you apply them. If you first learn and then learn , your updated probability distribution is . If you learn these facts the other way around, it's still .
Jeffrey updates are path-dependent. Suppose my probability distribution is as follows:
| A | ¬A | |
| B | 30% | 20% |
| ¬B | 20% | 30% |
I then apply the Jeffrey update P(B)=60%:
| A | ¬A | |
| B | 36% | 24% |
| ¬B | 16% | 24% |
Now I apply P(A)=60%:
| A | ¬A | |
| B | 41.54% | 20% |
| ¬B | 18.46% | 20% |
Since this is asymmetric, but the initial distribution was symmetric, obviously this would turn out differently if we had applied the Jeffrey updates in a different order.
Jeffrey considered this to be a bug -- although he seems fine with path-dependence under some circumstances, he used examples like the above to motivate a different way of handling uncertain evidence, which I'll call virtual evidence. (Judea Pearl strongly advocated virtual evidence over Jeffrey's rule near the beginning of Probabilistic Reasoning in Intelligent Systems (Section 2.2.2 and 2.3.3), in what can easily be read as a critique of Jeffrey's theory -- if one does not realize that Jeffrey is largely in agreement with Pearl. I thoroughly recommend Pearl's discussion of the details.)
Recall the basic anatomy of a Bayesian update:
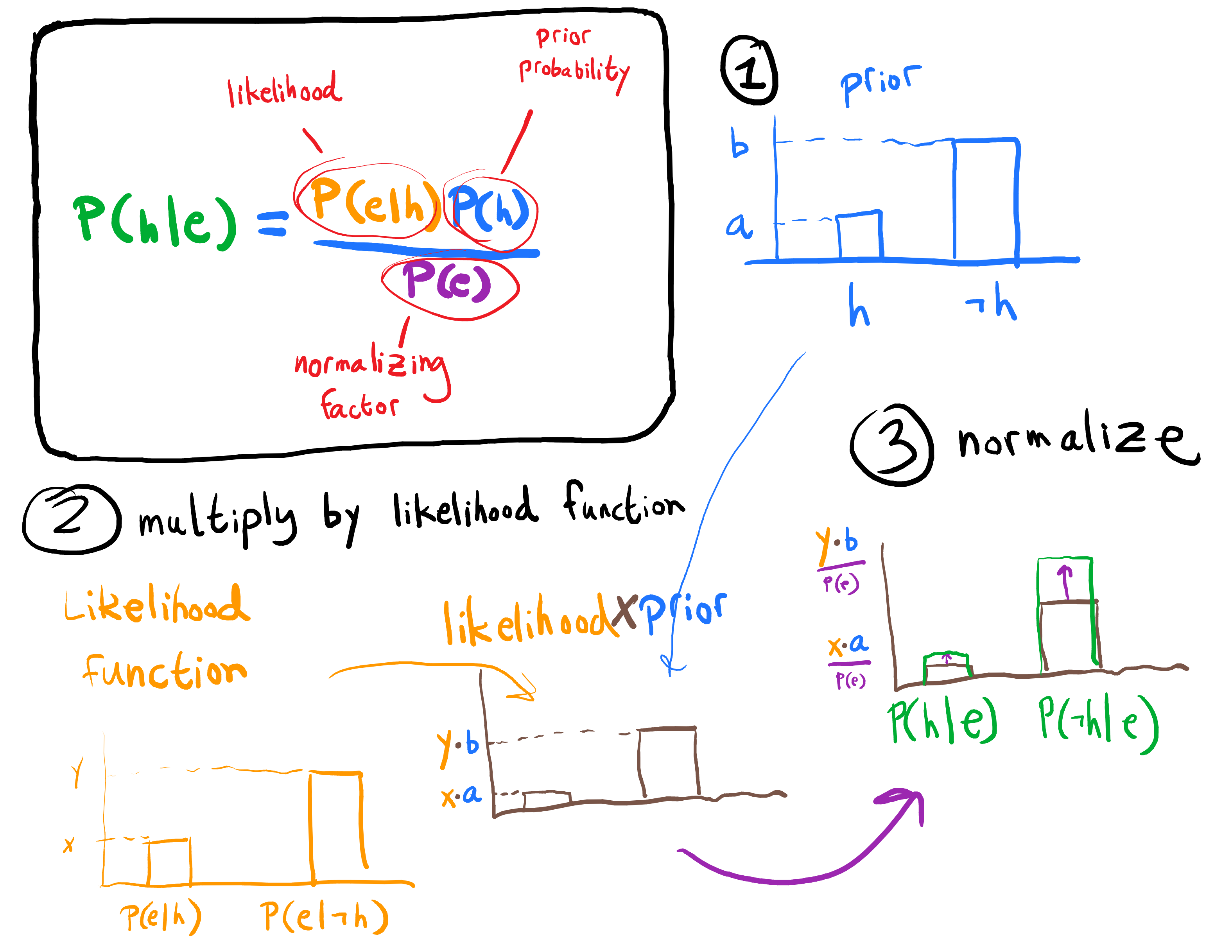
The idea of virtual evidence is to use evidence 'e' which is not an event in our event space. We're just acting as if there were evidence 'e' which justifies our update. Terms such as P(e), P(e&h), P(e|h), P(h|e), and so on are not given the usual probabilistic interpretation; they just stand as a convenient notation for the update. All we need to know is the likelihood function for the update. We then multiply our probabilities by the likelihood function as usual, and normalize. P(e) is easy to find, since it's just whatever factor makes everything sum to one at the end. This is good, since it isn't clear what P(e) would mean for a virtual event.
Actually, we can simplify even further. All we really need to know is the likelihood ratio: the ratio between the two numbers in the likelihood function. (I will illustrate this with an example soon). However, it may sometimes be easier to find the whole likelihood function in practice.
Let's look at the path-dependence example again. As before, we start with:
| A | ¬A | |
| B | 30% | 20% |
| ¬B | 20% | 30% |
I want to apply a Jeffrey update which makes P(B)=60%. However, let's represent the update via virtual evidence this time. Currently, P(B)=50%. To take it to 60%, we need to see virtual evidence with a 60:40 likelihood ratio, such as P(B|E)=60%, P(¬B|E)=40%. This gives us the same update as before:
| A | ¬A | |
| B | 36% | 24% |
| ¬B | 16% | 24% |
(Note that we would have gotten the same result with a likelihood function of P(B|E)=3%, P(¬B|E)=2%, since 60:40 is the same as 3:2. That's what I meant when I said that only the ratio matters.)
But now we want to apply the same update to A as we did to B. So now we update on virtual evidence P(A|E)=60%, P(¬A|E)=40%. This gives us the following (approximately):
| A | ¬A | |
| B | 43% | 19% |
| ¬B | 19% | 19% |
As you can see, the result is quite symmetric. In general, virtual evidence updates will be path-independent, because multiplication is commutative (and the normalization step of updating doesn't mess with this commutativity).
So, virtual evidence is a reformulation of Jeffrey updates with a lot of advantages:
- Unlike raw Jeffrey updates, virtual evidence is path-independent.
- You don't have to decide right away what you're updating to; you just have to decide the strength and direction of the update.
- I don't fully discuss this here, but Pearl argues persuasively that it's easier to tell when a virtual-evidence update is appropriate than when a Jeffrey update is appropriate.
Because of these features, virtual evidence is much more useful for integrating information from multiple sources.
Integrating Expert Opinions
Suppose you have an ancient artefact. You want to know whether this artefact was made by ancient aliens. You have some friends who are also curious about ancient aliens, so you enlist their help.
You ask one friend who is a metallurgist. After performing experiments (the details of which you don't understand), the metallurgist isn't sure, but gives 80% that the tests would turn out that way if it were of terrestrial origin, and 20% for metals of non-terrestrial origin. (Let's pretend that ancient aliens would 100% use metals of non-Earth origin, and that ancient humans would 100% use Earth metals.)
You then ask a second friend, who is an anthropologist. The anthropologist uses cultural signs, identifying the style of the art and writing. Based on that information, the anthropologist estimates that it's half as likely to be of terrestrial origin as alien.
How do we integrate this information? According to Jeffrey and Pearl, we can apply the virtual evidence formula if we think the two expert judgements are independent. What 'independence' means for virtual evidence is a bit murky, since the evidence is not part of our probability calculus, so we can't apply the usual probabilistic definition. However, Pearl argues persuasively that this condition is easier to evaluate in practice than the rigidity condition which governs the applicability of Jeffrey updates. (He also gives an example where rigidity is violated, so a naive Jeffrey update gives a nonsensical result but where virtual evidence can still be easily applied to get a correct result.)
The information provided by the anthropologist and the metallurgist seem to be quite independent types of information (at least, if we ignore the fact that both experts are biased by an interest in ancient aliens), so let's apply the virtual evidence rule. The likelihood ratio from the metallurgist was 80:20, which simplifies to 4:1. The likelihood ratio from the anthropologist was 1:2. That makes the combined likelihood vector 2:1 in favor of terrestrial origin. We would then combine this with our prior; for example, if we had a prior of 3:1 in favor of a terrestrial origin, our posterior would be 6:1 in favor.
(Note that we also have to think that the virtual evidence is independent of our prior information.)
So, virtual evidence offers a practical way to integrate information when we cannot quantify exactly what the evidence was -- a condition which is especially likely when consulting experts. This illustrates the utility of the bayes-with-a-side-channel model mentioned earlier; we are able to deal effectively with evidence, even when the exact nature of the evidence is hidden to us.
A few notes on how we gathered expert information in our hypothetical example.
- We asked for likelihood ratios, rather than posterior probabilities. This allows us to combine the information as virtual evidence.
- In the case of the metallurgist, it makes sense to ask for likelihood ratios, since the metallurgist is unlikely to have good prior information about the artefact. Asking only for likelihoods allows us to factor out any effect from this poor prior (and instead use our own prior, which may still be poor, but has the advantage of being ours).
- In the case of the anthropologist, however, it doesn't make as much sense -- if we trust their expertise, we're likely to think the anthropologist has a good prior about artefacts. It might have made more sense to ask for the anthropologist's posterior, take it as our own, and then apply a virtual-evidence update to integrate the metallurgist's report. (However, if we weren't able to properly communicate our own prior information to the anthropologist, it would be ignored in such an approach.)
- In the case of the metallurgist, it felt more natural to give a full likelihood function, rather than a likelihood ratio. It makes sense to know the probability of test result given a particular substance. It would have made even more sense if the likelihood function were a function of each metal the artefact could be made of, rather than just "terrestrial" or "extraterrestrial" -- using broad categories allows the metallurgist's prior about specific substances to creep in, which might be unfortunate.
- In the case of the anthropologist, however, it didn't make sense to give a full likelihood function. "The probability that the artefact would look exactly the way it looks assuming that it's made by humans" is very very low, and seems quite difficult and unnatural to evaluate. It seems much easier to come up with a likelihood ratio, comparing the probability of terrestrial and extraterrestrial origin.
Why did Pearl devote several sections to virtual evidence, in a book which is otherwise a bible for dogmatic probabilists? I think the main reason is the close analogy to the mathematics of Bayesian networks. The message-passing algorithm which makes Bayesian networks efficient is almost exactly the virtual evidence procedure I've described. If we think of each node as an expert trying to integrate information from its neighbors, then the efficiency of Bayes nets comes from the fact that they can use virtual evidence to update on likelihood functions rather than needing to know about the evidence in detail. This may have even been one source of inspiration for Pearl's belief propagation algorithm?
Can Dogmatic Probabilists Use Virtual Evidence?
OK, so we've put Jeffrey's radical updates into a more palatable form -- one which borrows the structure and notation of classical Bayesian updates.
Does this mean orthodox Bayesians can join the party, and use virtual evidence to accomplish everything a radical probabilist can do?
No.
Virtual evidence abandons the ratio formula.
One of the longstanding axioms of classical Bayesian thought is the ratio formula for conditional probability that Bayes himself introduced:
Virtual evidence, as an updating practice, holds that can be usefully defined in cases where the ratio cannot be usefully defined. Indeed, virtual evidence treats Bayes' Law (which is usually a derived theorem) as more fundamental than the ratio formula (which is usually taken as a definition).
Granted, dogmatic probabilism as I defined it at the beginning of this post does not explicitly assume the ratio formula. But the assumption is so ingrained that I assume most readers took to mean the ratio.
Still, even so, we can consider a version of dogmatic probabilism which rejects the ratio formula. Couldn't they use virtual evidence?
Virtual evidence requires probability functions to take arguments which aren't part of the event space.
Even abandoning the ratio formula, still, it's hard to see how a dogmatic probabilist could use virtual evidence without abandoning the Kolmogorov axioms as the foundation of probability theory. The Kolmogorov axioms make probabilities a function of events; and events are taken from a pre-defined event space. Virtual evidence constructs new events at will, and does not include them in an overarching event space (so that, for example, virtual evidence can be defined -- so that is meaningful for all from the event space --without events like being meaningful, as would be required for a sigma-algebra).
I left some wiggle room in my definition, saying that a dogmatic probabilist might endorse the Kolmogorov axioms "or a similar axiomatization of probability theory". But even the Jeffrey-Bolker axioms, which are pretty liberal, don't allow enough flexibility for this!
Representing Fluid Updates
A final point about virtual evidence and Jeffrey updates.
Near the beginning of this essay, I gave a picture in which Jeffrey updates generalize Bayesian updates, but fluid updates generalize things even further, opening up the space of possibilities when rigidity does not hold.
However, I should point out that any update is a Jeffrey update on a sufficiently fine partition.
So far, for simplicity, I've focused on binary partitions: we're judging between H and ¬H, rather than a larger set such as . However, we can generalize everything to arbitrarily sized partitions, and will often want to do so. I noted that a larger set might have been better when asking the metallurgist about the artefact, since it's easier to judge the probability of test results given specific metals rather than broad categories.
If we make a partition large enough to cover every possible combination of events, then a Jeffrey update is now just a completely arbitrary shift in probability. Or, alternatively, we can represent arbitrary shifts via virtual evidence, by converting to likelihood-ratio format.
So, these updates are completely general after all.
Granted, there might not be any point to seeing things that way.
Non-Sequential Prediction
One advantage of radical probabilism is that it offers a more general framework for statistical learning theory. I already mentioned, briefly, that it allows one to do away with the realizability/grain-of-truth assumption. This is very important, but not what I'm going to dwell on here. Instead I'm going to talk about non-sequential prediction, which is a benefit of logical induction which I think has been under-emphasized so far.
Information theory -- in particular, algorithmic information theory -- in particular, Solomonoff induction -- is restricted to a sequential prediction frame. This means there's a very rigid observation model: observations are a sequence of tokens and you always observe the nth token after observing tokens one through n-1.
Granted, you can fit lots of things into a sequential prediction model. However, it is a flaw the otherwise close relationship between Bayesian probability and information theory. You'll run into this if you try to relate information theory and logic. Can you give an information-theoretic intuition for the laws of probability that deal with logical combinations, such as P(A or B) + P(A and B) = P(A) + P(B)?
I've complained about this before [AF · GW], offering a theorem which (somewhat) problematizes the situation, and suggesting that people should notice whether or not they're making sequential-prediction style assumptions. I almost included related assumptions in my definition of dogmatic probabilism at the beginning of this post, but ultimately it makes more sense to contrast radical probabilism to the more general doctrine of Bayesian updates.
Sequential prediction cares only about the accuracy of beliefs at the moment of observation; the accuracy of the full distribution over the future is reduced to the accuracy about each next bit as it is observed.
If information is coming in "in any old way" rather than according to the assumptions of sequential prediction, then we can construct problematic cases for Solomonoff induction. For example, if we condition the nth bit to be 1 (or 0) when a theorem prover proves (or refutes) the nth sentence of Peano arithmetic, then Solomonoff induction will never assign positive probability to hypotheses consistent with Peano arithmetic, and will therefore do poorly on this prediction task. This is despite the fact that there are computable programs which do better at this prediction task; for example, the same theorem prover running just a little bit faster can have highly accurate beliefs at the moment of observation.
In non-sequential prediction, however, we care about accuracy at every moment, rather than just at the moment of observation. Running the same theorem prover, just one step faster, doesn't do very well on that metric. It allows you to get things right just in time, but you won't have any clue about what probabilities to assign before that. We don't just want the right conclusion; we want to get there as fast as possible, and (in a subtle sense) via a rational path
Part of the difficulty of non-sequential prediction is how to score it. Bayes loss applied to your predictions at the moment of observation, in a sequential prediction setting, seems quite useful. Bayes loss applied to all your beliefs, at every moment does not seem very useful.
Radical probabilism gives us a way to evaluate the rationality of non-sequential predictions -- namely, how vulnerable the sequence of belief distributions was to losing money via some sequence of bets.
Sadly, I'm not yet aware of any appropriate generalization of information theory -- at least not one that's very interesting. (You can index information by time, to account for the way probabilities stift over time... but that does not come with a nice theory of communication or compression, which are fundamental to classical information theory.) This is why I objected to prediction=compression in the discussion section of Alkjash's talk [LW · GW].
To summarize, sequential prediction makes three critical assumptions which may not be true in general:
- It assumes observations will always inform us about one of a set of observable variables. In general, Bayesian updates can instead inform us about any event, including complex logical combinations (such as "either the first bit is 1, or the second bit is 0").
- It assumes these observations will be made in a specific sequence, whereas in general updates could come in in any order.
- It assumes that what we care about is the accuracy of belief at the time of observation; in general, we may care about the accuracy of beliefs at other times.
The only way I currently know how to get theoretical benefits similar to those of Solomonoff induction while avoiding all three of these assumptions is radical probabilism (in particular, as formalized by logical induction).
(The connection between this section and radical probabilism is notably weaker than the other parts of this essay. I think there is a lot of low-hanging fruit here, fleshing out the space of possible properties, the relationship between various problems and various assumptions, trying to generalize information theory, clarifying our concept of observation models, et cetera.)
Making the Meta-Bayesian Update
In Pascal's Muggle (long version [LW · GW], short version [LW · GW]) Eliezer discusses situations in which he would be forced to make a non-Bayesian update:
But if I actually see strong evidence for something I previously thought was super-improbable, I don't just do a Bayesian update, I should also question whether I was right to assign such a tiny probability in the first place - whether the scenario was really as complex, or unnatural, as I thought. In real life, you are not ever supposed to have a prior improbability of 10-100 for some fact distinguished enough to be written down, and yet encounter strong evidence, say 1010 to 1, that the thing has actually happened. If something like that happens, you don't do a Bayesian update to a posterior of 10-90. Instead you question both whether the evidence might be weaker than it seems, and whether your estimate of prior improbability might have been poorly calibrated, because rational agents who actually have well-calibrated priors should not encounter situations like that until they are ten billion days old. Now, this may mean that I end up doing some non-Bayesian updates: I say some hypothesis has a prior probability of a quadrillion to one, you show me evidence with a likelihood ratio of a billion to one, and I say 'Guess I was wrong about that quadrillion to one thing' rather than being a Muggle about it.
At the risk of being too cutesy, I want to make two related points:
- At the object level, radical probabilism offers a framework in which we can make these sorts of non-Bayesian updates. We can encounter something which makes us question our whole way of thinking. It also allows us to significantly revise that way of thinking, without modeling the situation as something extreme like self-modification (or even something very out of the ordinary).
- At the meta level, updating to radical probabilism is itself one of these non-Bayesian updates. Of course, if you were really a hard-wired dogmatic probabilist at core, you would be unable to make such an update (except perhaps if we model it as self-modification). But, since you are already using reasoning which is actually closer in spirit to radical probabilism, you can start to model yourself in this way and using radical-probabilist ideas to guide future updates.
So, I wanted to use this penultimate section for some advice about making the leap.
It All Adds Up to Normality
Radical Probabilism is not a license to update however you want, nor even an invitation to massively change the way you update. It is primarily a new way to understand what you are already doing. Yes, it's possible that viewing things through this lense (rather than the more narrow lense of dogmatic probabilism) will change the way you see things, and as a consequence, change the way you do things. However, you are not (usually) making some sort of mistake by engaging in the sort of Bayesian reasoning you are familiar with -- there is no need to abandon large portions of your thinking.
Instead, try to notice ordinary updates you make which are not perfectly understood as Bayesian updates.
- Calibration corrections are not well-modeled as Bayesian updates. If you say to yourself "I've been overconfident in similar situations", and lower your probability, your shift is better-understood as a fluid update.
- Many instances of "outside view" are not well-modeled in a Bayesian update framework. You've probably seen outside view explained as prior probability. However, you often take the outside view on one of your own arguments, e.g. "I've often made arguments like this and been wrong". This kind of reflection doesn't fit well in the framework of Bayesian updates, but fits fine in a radical-probabilist picture.
- It is often warranted to downgrade the probability of a hypothesis without having an alternative in mind to upgrade. You can start to find a hypothesis suspicious without having any better way of predicting observations. For example, a sequence of surprising events might stick out to you as evidence that your hypothesis is wrong, even though your hypothesis is still the best way that you know to try and predict the data. This is hard to formalize as a Bayesian update. Changes in probability between hypotheses always remain balanced. It's true that you move the probability to a "not the hypotheses I know" category which balances the probability loss, but it's not true that this category earned the increased probability by predicting the data better. Instead, you used a set of heuristics which have worked well in the past to decide when to move probabilities around.
Don't Predictably Violate Bayes
Again, this is not a license to violate Bayes' Rule whenever you feel like it.
A radical probabilist should obey Bayes' Law in expectation, in the following sense:
If some evidence E or ¬E is bound to be observed by time m>n, then the following should hold:
And the same for ¬E. In other words, you should not expect your updated beliefs to differ from your conditional probabilities on average.
(You should suspect from the fact that I'm not proving this one that I'm playing a bit fast and loose -- whether this law holds may depend on the formalization of radical probabilism, and it probably needs some extra conditions I haven't stated, such as P(E)>0.)
And remember, every update is a Bayesian update, with the right virtual evidence.
Exchange Virtual Evidence
Play around with the epistemic practice Jeffrey suggests. I suspect some of you already do something similar, just not necessarily calling it by this name or looking so closely at what you're doing.
Don't Be So Realist About Your Own Utility Function
Note that the picture here is quite compatible with what I said in An Orthodox Case Against Utility Functions [AF · GW]. Your utility function need not be computable, and there need not be something in your ontology which you can think of your utility as a function of. All you need are utility expectations, and the ability to update those expectations. Radical Probabilism adds a further twist: you don't need to be able to predict those updates ahead of time; indeed, you probably can't. Your values aren't tied to a function, but rather, are tied to your trust in the ongoing process of reasoning which refines and extends those values (very much like the self-trust discussed in the section on conservation of expected evidence).
Not So Radical After All
And remember, every update is a Bayesian update, with the right virtual evidence.
Recommended Reading
Diachronic Coherence and Radical Probabilism, Brian Skyrms
- This paper is really nice in that it constructs Radical Probabilism from the ground up, rather than starting with regular probability theory and relaxing it. It provides a view in which diachronic coherence is foundational, and regular one-time-slice probabilistic coherence is derived. Like logical induction, it rests on a market metaphor. It also briefly covers the argument that radical-probabilism beliefs must have a convergence property.
Radical Probabilism and Bayesian Conditioning, Richard Bradley
- This is a more thorough comparison of radical probabilism to standard bayesian probabilism, which breaks down the departure carefully, while covering the fundamentals of radical probabilism. In addition to Bayesian conditioning and Jeffrey conditioning, it introduces Adams conditioning, a new type of conditioning which will be valid in many cases (for the same sort of reason as why Jeffrey conditioning or Bayesian conditioning can be valid). He contends that there are, nonetheless, many more ways to update beyond these; and, he illustrates this with a purported example where none of those updates seems to be the correct one.
Epistemology Probabilized, Richard Jeffrey
- The man himself. This essay focuses mainly on how to update on likelihood ratios rather than directly performing Jeffrey updates (what I called virtual evidence). The motivations are rather practical -- updating on expert advice when you don't know precisely what observations lead to that advice.
I was a Teenage Logical Positivist (Now a Septuagenarian Radical Probabilist), Richard Jeffrey.
- Richard Jeffrey reflects on his life and philosophy.
Probabilistic Reasoning in Intelligent Systems, Judea Pearl.
- See especially chapter 2, especially 2.2.2 and 2.3.3.
Logical Induction, Garrabrant et al.
*: Jeffrey actually used this phrase. See I was a Teenage Logical Positivist, linked above.
49 comments
Comments sorted by top scores.
comment by gwern · 2020-08-20T14:42:49.011Z · LW(p) · GW(p)
Jeffrey's thesis is at https://digital.library.pitt.edu/islandora/object/pitt%3A31735062223304/viewer
comment by orthonormal · 2020-12-20T18:34:19.650Z · LW(p) · GW(p)
Remind me which bookies count and which don't, in the context of the proofs of properties?
If any computable bookie is allowed, a non-Bayesian is in trouble against a much larger bookie who can just (maybe through its own logical induction) discover who the bettor is and how to exploit them.
[EDIT: First version of this comment included "why do convergence bettors count if they don't know the bettor will oscillate", but then I realized the answer while Abram was composing his response, so I edited that part out. Editing it back in so that Abram's reply has context.]
Replies from: abramdemski↑ comment by abramdemski · 2020-12-20T20:43:03.064Z · LW(p) · GW(p)
It's a good question!
For me, the most general answer is the framework of logical induction, where the bookies are allowed so long as they have poly-time computable strategies. In this case, a bookie doesn't have to be guaranteed to make money in order to count; rather, if it makes arbitrarily much money, then there's a problem. So convergence traders are at risk of being stuck with a losing ticket, but, their existence forces convergence anyway.
If we don't care about logical uncertainty, the right condition is instead that the bookie knows the agent's beliefs, but doesn't know what the outcome in the world will be, or what the agent's future beliefs will be. In this case, it's traditional to requite that bookies are guaranteed to make money.
(Puzzles of logical uncertainty can easily point out how this condition doesn't really make sense, given EG that future events and beliefs might be computable from the past, which is why the condition doesn't work if we care about logical uncertainty.)
In that case, I believe you're right, we can't use convergence traders as I described them.
Yet, it turns out we can prove convergence a different way.
To be honest, I haven't tried to understand the details of those proofs yet, but you can read about it in the paper "It All Adds Up: Dynamic Coherence of Radical Probabilism" by Sandy Zabell.
comment by Richard_Ngo (ricraz) · 2021-01-14T12:55:24.665Z · LW(p) · GW(p)
DP: (sigh...) OK. I'm still never going to design an artificial intelligence to have uncertain observations. It just doesn't seem like something you do on purpose.
What makes you think that having certain observations is possible for an AI?
Replies from: abramdemski↑ comment by abramdemski · 2021-01-14T17:05:55.860Z · LW(p) · GW(p)
DP: I'm not saying that hardware is infinitely reliable, or confusing a camera for direct access to reality, or anything like that. But, at some point, in practice, we get what we get, and we have to take it for granted. Maybe you consider the camera unreliable, but you still directly observe what the camera tells you. Then you would make probabilistic inferences about what light hit the camera, based on definite observations of what the camera tells you. Or maybe it's one level more indirect from that, because your communication channel with the camera is itself imperfect. Nonetheless, at some point, you know what you saw -- the bits make it through the peripheral systems, and enter the main AI system as direct observations, of which we can be certain. Hardware failures inside the core system can happen, but you shouldn't be trying to plan for that in the reasoning of the core system itself -- reasoning about that would be intractable. Instead, to address that concern, you use high-reliability computational methods at a lower level, such as redundant computations on separate hardware to check the integrity of each computation.
RJ: Then the error-checking at the lower level must be seen as part of the rational machinery.
DP: True, but all the error-checking procedures I know of can also be dealt with in a classical bayesian framework.
RJ: Can they? I wonder. But, I must admit, to me, this is a theory of rationality for human beings. It's possible that the massively parallel hardware of the brain performs error-correction at a separated, lower level. However, it is also quite possible that it does not. An abstract theory of rationality should capture both possibilities. And is this flexibility really useless for AI? You mention running computations on different hardware in order to check everything. But this requires a rigid setup, where all computations are re-run a set number of times. We could also have a more flexible setup, where computations have confidence attached, and running on different machines creates increased confidence. This would allow for finer-grained control, re-running computations when the confidence is really important. And need I remind you that belief prop in Bayesian networks can be understood in radical probabilist terms? In this view, a belief network can be seen as a network of experts communicating with one another. This perspective has been, as I understand it, fruitful.
DP: Sure, but we can also see belief prop as just an efficient way of computing the regular Bayesian math. The efficiency can come from nowhere special, rather than coming from a core insight about rationality. Algorithms are like that all the time -- I don't see the fast fourier transform as coming from some basic insight about rationality.
RJ: The "factor graph" community says that belief prop and fast fourier actually come from the same insight! But I concede the point; we don't actually need to be radical probabilists to understand and use belief prop. But why are you so resistant? Why are you so eager to posit a well-defined boundary between the "core system" and the environment?
DP: It just seems like good engineering. We want to deal with a cleanly defined boundary if possible, and it seems possible. And this way we can reason explicitly about the meaning of sensory observations, rather than implicitly being given the meaning by way of uncertain updates which stipulate a given likelihood ratio with no model. And it doesn't seem like you've given me a full alternative -- how do you propose to, really truly, specify a system without a boundary? At some point, messages have to be interpreted as uncertain evidence. It's not like you have a camera automatically feeding you virtual evidence, unless you've designed the hardware to do that. In which case, the boundary would be the camera -- the light waves don't give you virtual evidence in the format the system accepts, even if light is "fundamentally uncertain" in some quantum sense or whatever. So you have this boundary, where the system translates input into evidence (be it uncertain or not) -- you haven't eliminated it.
RJ: That's true, but you're supposing the boundary is represented in the AI itself as a special class of "sensory" propositions. Part of my argument is that, due to logical uncertainty, we can't really make this distinction between sensory observations and internal propositions. And, once we make that concession, we might as well allow the programmer/teacher to introduce virtual evidence about whatever they want; this allows direct feedback on abstract matters such as "how to think about this", which can't be modeled easily in classic Bayesian settings such as Solomonoff induction, and may be important for AI safety.
DP: Very well, I concede that while I still hold out hope for a fully Bayesian treatment of logical uncertainty, I can't provide you with one. And, sure, providing virtual evidence about arbitrary propositions does seem like a useful way to train a system. I'm just suspicious that there's a fully Bayesian way to do everything you might want to do...
comment by magfrump · 2020-08-26T02:40:56.517Z · LW(p) · GW(p)
So one of the first thoughts I had when reading this was whether you can model any Radical Probabilist as a Bayesian agent that has some probability mass on "my assumptions are wrong" and will have that probability mass increase so that it questions its assumptions over a "reasonable timeframe" for whatever definition.
For the case of coin flips, there is a clear assumption in the naive model that the coin flips are independent of each other, which can be fairly simply expressed as $P(flip_i = H | flip_{j} = H) = P(flip_i = H | flip_{j} = T) \forall j < i$. In the case of the coin that flips 1 heads, 5 tails, 25 heads, 125 tails, just evaluating j=i-1 through the 31st flip gives P(H|last flip heads) = 24/25, P(H|last flip tails) = 1/5, which is unlikely at p=~1e-4, which is approximately the difference in bayesian weight between the hypothesis H1: the coin flips heads 26/31 times (P(E|H1)=~1e-6) and H0: the coin flips heads unpredictably (1/2 the time, P(E|H0)=~4e-10) which is a better hypothesis in the long run until you expand your hypothesis space.
So in this case, the "I don't have the hypothesis in my space" hypothesis actually wins out right around the 30th-32nd flip, possibly about the same time a human would be identifying the alternate hypothesis. That seems helpful!
However this relies on the fact that this specific hypothesis has a single very clear assumption and there is a single very clear calculation that can be done to test that assumption. Even in this case though, the "independence of all coin flips" assumption makes a bunch more predictions, like that coin flips two apart are independent, etc. calculating all of these may be theoretically possible but it's arduous in practice, and would give rise to far too much false evidence--for example, in real life there are often distributions that look a lot like normal distributions in the general sense that over half the data is within one standard deviation of the mean and 90% of the data is within two standard deviations, but where if you apply an actual hypothesis test of whether the data is normally distributed it will point out some ways that it isn't exactly normal (only 62% of the data is in this region, not 68%! etc.).
It seems like the idea of having a specific hypothesis in your space labeled "I don't have the right hypothesis in my space" can work okay under the conditions
1. You have a clearly stated assumption which defines your current hypothesis space
2. You have a clear statistical test which shows when data doesn't match your hypothesis space
3. You know how much data needs to be present for that test to be valid--both in terms of the minimum for it to distinguish itself so you don't follow conspiracy theories, and something like a maximum (maybe this will naturally emerge from tracking the probability of the data given the null hypothesis, maybe not).
I have no idea whether these conditions are reasonable "in practice" whatever that means, so I'm not really clear whether this framework is useful, but it's what I thought of and I want to share even negative results in case other people had the same thoughts.
Replies from: abramdemski, capybaralet↑ comment by abramdemski · 2020-08-30T13:43:38.860Z · LW(p) · GW(p)
Yeah, I don't think this can be generalized to model a radical probabilist in general, but it does seem like a relevant example of "extra-bayesian" (but not totally non-bayesian) calculations which can be performed to supplement Bayesian updates in practice.
↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2020-09-02T08:19:05.397Z · LW(p) · GW(p)
It seems like you don't need statistical tests, and can instead include a special "Socratic" hypothesis (which just says "I don't know") in your hypothesis space. This hypothesis can assign some fixed or time-varying probability to any observation (e.g. yielding an unnormalized probability distribution by saying P(X=r) = epsilon for any real number r, assuming all observations X are real-valued). I wonder if that has been explored.
Replies from: magfrump, capybaralet↑ comment by magfrump · 2020-09-03T04:59:31.737Z · LW(p) · GW(p)
If you don't have statistical tests then I don't see how you have a principled way to update away from your structured hypotheses, since the structured space will always give strictly better predictions than the socratic hypothesis.
Replies from: capybaralet↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2020-09-03T05:43:36.544Z · LW(p) · GW(p)
the structured space will always give strictly better predictions than the socratic hypothesis.
I don't think so.... suppose in the H/T example, the Socratic hypothesis says that P(H) = P(T) = 3. Then it will always do better than any hypothesis that has to be normalized.
I'm not sure what you mean by "structured hypotheses" here though...
Replies from: magfrump↑ comment by magfrump · 2020-09-03T07:06:55.346Z · LW(p) · GW(p)
In the case where you get 1 heads, 5 tails, 25 heads, etc., then at every point in time, and you are working with the assumption that the flips are independent, then the Bayesian hypothesis will never converge, but it will actually give better predictions than the Socratic hypothesis most of the time. In particular when it's halfway through one of the powers of five, it will assign P>.5 to the correct prediction every time. And if you expand that to assuming the flip can depend on the previous flip, it will get to a hypothesis (the next flip will be the same as the last one) that actually performs VERY well, and does converge.
By "structured" I mean that I have a principled way of determining P(Evidence|Hypothesis); with the Socratic hypothesis I only have unprincipled ways of determining it.
I'm not sure what you mean by normalized, unless you mean that the Socratic hypothesis always gives probability 1 to the observed evidence, in which case it will dominate even the correct hypothesis if there is uncertainty.
↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2020-09-02T08:20:49.661Z · LW(p) · GW(p)
It seems like you could get pretty far with this approach, and it starts to look pretty Bayesian to me if I update epsilon based on how predictable the world seems to have been, in general, so far.
comment by habryka (habryka4) · 2020-08-29T18:57:03.314Z · LW(p) · GW(p)
Promoted to curated: This post is answering (of course not fully, but in parts) what seems to me one of the most important open questions in theoretical rationality, and I think does so in a really thorough and engaging way. It also draws connections to a substantial number of other parts of your and Scott's work in a way that has helped me understand those much more thoroughly.
I am really excited about this post. I kind of wish I could curate it two or three times because I do really want a lot of people to have read this, and expect that it will change how I think about a substantial number of topics.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-30T11:20:21.960Z · LW(p) · GW(p)
I'll try to write some good follow-up posts for you to also curate ;3
comment by Pattern · 2020-08-20T17:31:30.018Z · LW(p) · GW(p)
This link doesn't seem to work:
I was a Teenage Logical Positivist (Now a Septuagenarian Radical Probabilist) [LW · GW], Richard Jeffrey.
I haven't checked the others.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-20T19:49:03.060Z · LW(p) · GW(p)
Thanks, fixed!
comment by johnswentworth · 2020-08-19T21:05:12.662Z · LW(p) · GW(p)
(Note that Bayes-with-a-side-channel does not imply conditions such as convergence and calibration; so, Jeffrey's theory of rationality is more demanding.)
What about the converse? Is a radical probabilist always behaviorally equivalent to a Bayesian with a side-channel? Or to some sequence of virtual evidence updates?
You seem to say so later on - "And remember, every update is a Bayesian update, with the right virtual evidence" - but I don't think this was proven?
Replies from: abramdemski↑ comment by abramdemski · 2020-08-20T19:51:22.623Z · LW(p) · GW(p)
Ah, this was supposed to have been established in the section "Representing Fluid Updates" -- the idea being that any change in probabilities can be represented as virtual evidence on a sufficiently fine partition (barring an update from zero to a positive number).
Replies from: johnswentworth↑ comment by johnswentworth · 2020-08-20T23:57:57.534Z · LW(p) · GW(p)
Ah, I see. Made sense on a second read. Thanks.
comment by Rohin Shah (rohinmshah) · 2020-08-19T19:08:37.043Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
The traditional Bayesian treatment of rational agents assumes that the only way an agent can get new information is by getting some new observation that is known with probability 1. However, we would like a theory of rationality that can allow for agents that also get more information by thinking longer. In such a situation, some of the constraints imposed by traditional Bayesian reasoning no longer apply. This detailed post explores what constraints remain, and what types of updating are allowable under this more permissive definition of rationality.
Planned opinion:
I particularly enjoyed this post; it felt like the best explanation in relatively simple terms of a theory of rationality that is more suited to bounded agents that cannot perfectly reason about an environment larger than they are. (Note “simple” really is relative; the post still assumes a lot of technical knowledge about traditional Bayesianism.)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-08-19T15:08:05.211Z · LW(p) · GW(p)
Thanks for this, I found it quite clear and helpful.
The radical probabilist does not trust whatever they believe next. Rather, the radical probabilist has a concept of virtuous epistemic process, and is willing to believe the next output of such a process. Disruptions to the epistemic process do not get this sort of trust without reason. (For those familiar with The Abolition of Man, this concept is very reminiscent of his "Tao".)
I had some uncertainty/confusion when reading this part: How does it follow from the axioms? Or is it merely permitted by the axioms? What constraints are there, if any, on what a radical probabilist's subjective notion of virtuous process can be? Can there be a radical probabilist who has an extremely loose notion of virtue such that they do trust whatever they believe next?
Replies from: abramdemski, dranorter↑ comment by abramdemski · 2020-08-19T15:45:14.223Z · LW(p) · GW(p)
I'm pulling some slight of hand here: it doesn't follow from the axioms. I'm talking about what I see as the sensible interpretation of the axioms.
Good job noticing that confusion.
I think that section is pretty important; I stand by what I said, but it definitely needs to be developed more.
↑ comment by dranorter · 2020-08-19T20:26:15.837Z · LW(p) · GW(p)
It's worth noting that in the case of logical induction, there's a more fleshed-out story where the LI eventually has self-trust and can also come to believe probabilities produced by other LI processes. And, logical induction can come to trust outputs of other processes too. For LI, a "virtuous process" is basically one that satisfies the LI criterion, though of course it wouldn't switch to the new set of beliefs unless they were known products of a longer amount of thought, or had proven themselves superior in some other way.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-19T20:39:01.450Z · LW(p) · GW(p)
For LI, a "virtuous process" is basically one that satisfies the LI criterion,
I don't think this is true. Two different logical inductors need not trust each other in general, even if one has had vastly longer to think, and so has developed "better" beliefs. They do have reason to trust each other eventually on empirical matters, IE, matters for which they get sufficient feedback. (I'm unfortunately relying an an unpublished theorem to assert that.) However, for undecidable sentences, I think there is no reason why one logical inductor should consider another to have "virtuous reasoning", even if the other has thought for much longer.
What we can say is that a logical inductor eventually sees itself as reasoning virtuously. And, furthermore, that "itself" means as mathematically defined -- it does not similarly trust "whatever the computer I'm running on happens to believe tomorrow", since the computational process could be corrupted by e.g. a cosmic ray.
But for both a human and for a logical inductor, the epistemic process involves an interaction with the environment. Humans engage in discussion, read literature, observe nature. Logical inductors get information from the deductive process, which it trusts to be a source of truth. What distinguishes corrupt environmental influences from non-corrupt ones?
comment by Ben Pace (Benito) · 2020-08-30T07:30:52.910Z · LW(p) · GW(p)
Sh*t. Wow. This is really impressive.
Speaking for myself, this (combined with your orthodox case against utility functions) feels like the next biggest step for me since Embedded Agency in understanding what's wrong with our models of agency and how to improve them.
If I were to put it into words, I'm getting a strong vibe of "No really, you're starting the game inside the universe, stop assuming you've got all the hypotheses in your head and that you've got clean input-output, you need far fewer assumptions if you're going to get around this space at all." Plus a sense that this isn't 'weird' or 'impossibly confusing', and that actually these things will be able to make good sense.
All the details though are in the things you say about convergence and not knowing your updates and so on, which I don't have anything to add to.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-08-30T07:31:03.217Z · LW(p) · GW(p)
I made notes while reading about things that I was confused about or that stood out to me. Here they are:
- The post says that radical probabilism rejects #3-#5, but also that Jeffrey's updates is derived from having rigidity (#5), which sounds like a contradiction. (I feel most dumb about this bullet, it's probably obvious.)
- The convergence section blew me away. The dialogue here correctly understood my confusion (why would I only believe either h(1/3) or h(2/3)) and then hit me with the 'embedded world models' point, and that was so persuasive. This felt really powerful, tying together some key arguments in this space.
- I don’t get why the proof of conservation of expected evidence is relevant. It seems to assume that not only do I know how I will update, but that the bookie does too, which seems like an odd and overpowered assumption, and feels in contrast with all the things you said about rigidity – why does the bookie get to know how I’ll update?
- "This has some implications for AI alignment, but I won't try to spell them out here." Such temptation! :)
- I didn’t follow the argument that classical bayesians don’t have calibration. I think it's just saying that classical bayesianism doesn't have any part for self-reference, and that's a big deal? I don't think this means bayesians aren't calibrated, just that they don't have calibration as an explicit part of their model.
- I do not understand how Jeffrey updates lead to path dependence. Is the trick that my probabilities can change without evidence, therefore I can just update B without observing anything that also updates A, and then use that for hocus pocus? Writing that out, I think that's probably it, but as I was reading the essay I wasn't sure which bit was where the key step was happening.
- Okay, I got tired and skipped most of the virtual evidence section (it got tough for me). You say "Exchange Virtual Evidence" and I would be interested in a concrete example of what that kind of conversation would look like. I'm imagining it's something like "I thought for ages and changed my mind, let me tell you why".
- Thanks for the the stuff at the end, about making the meta-bayesian update. I wanted to read you say your thoughts on that, would've been sad if it hadn't been there.
- The examples of non-bayesian updates I've been making are really valuable. I'll be noticing these more often.
↑ comment by abramdemski · 2020-08-30T12:53:58.769Z · LW(p) · GW(p)
The post says that radical probabilism rejects #3-#5, but also that Jeffrey's updates is derived from having rigidity (#5), which sounds like a contradiction.
Jeffrey doesn't see Jeffrey updates as normative! Like Bayesian updates, they're merely one possible way to update.
This is also part of why Pearl sounds like a critic of Jeffrey when in fact the two largely agree -- you have to realize that Jeffrey isn't advocating Jeffrey updating in a strong way, only using it as a kind of gateway drug to the more general fluid updates.
I don’t get why the proof of conservation of expected evidence is relevant. It seems to assume that not only do I know how I will update, but that the bookie does too, which seems like an odd and overpowered assumption, and feels in contrast with all the things you said about rigidity – why does the bookie get to know how I’ll update?
Hmm. It seems like a proper reply to this would be to step through the argument more carefully -- maybe later? But no, the argument doesn't require either of those. It requires only that you have some expectation about your update, and the bookie knows what that is (which is pretty standard, because in dutch book arguments the bookies generally have access to your beliefs). You might have a very broad distribution over your possible updates, but there will still be an expected value, which is what's used in the argument.
I didn’t follow the argument that classical bayesians don’t have calibration. I think it's just saying that classical bayesianism doesn't have any part for self-reference, and that's a big deal? I don't think this means bayesians aren't calibrated, just that they don't have calibration as an explicit part of their model.
Like convergence, this is dependent on the prior, so I can't say that classical Bayesians are never calibrated (although one could potentially prove some pretty strong negative results, as is the case with convergence?). I didn't really include any argument, I just stated it as a fact.
What I can say is that classical Bayesianism doesn't give you tools for getting calibrated. How do you construct a prior so that it'll have a calibration property wrt learning? Classical Bayesianism doesn't, to my knowledge, talk about this. Hence, by default, I expect most priors to be miscalibrated in practice when grain-of-truth (realizability) doesn't hold.
For example, I'm not sure whether Solomonoff induction has a calibration property -- nor whether it has a convergence property. These strike me as mathematically complex questions. What I do know is that the usual path to prove nice properties for Solomonoff induction doesn't let you prove either of these things. (IE, we can't just say "there's a program in the mixture that's calibrated/convergent, so...." ... whereas logical induction lets you argue calibration and convergence via the relatively simple "there are traders which enforce these properties")
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-08-30T17:56:35.985Z · LW(p) · GW(p)
Thank you, those points all helped a bunch.
(I feel most resolved on the calibration one. If I think more about the other two and have more questions, I'll come back and write them.)
↑ comment by abramdemski · 2020-08-30T13:37:30.698Z · LW(p) · GW(p)
I do not understand how Jeffrey updates lead to path dependence. Is the trick that my probabilities can change without evidence, therefore I can just update B without observing anything that also updates A, and then use that for hocus pocus? Writing that out, I think that's probably it, but as I was reading the essay I wasn't sure which bit was where the key step was happening.
hmmmm. My attempt at an English translation of my example:
A and B are correlated, so moving B to 60% (up from 50%) makes A more probable as well. But then moving A up to 60% is less of a move for A. This means that (A&¬B) ends up smaller than (B&¬A): both get dragged up and then down, but (B&¬A) was dragged up by the larger update and down by the smaller.
Okay, I got tired and skipped most of the virtual evidence section (it got tough for me). You say "Exchange Virtual Evidence" and I would be interested in a concrete example of what that kind of conversation would look like.
It would be nice to write a whole post on this, but the first thing you need to do is distinguish between likelihoods and probabilities.
The notation may look pointless at first. The main usage has to do with the way we usually regard the first argument as variable an the second as fixed. IE, "a probability function sums to one" can be understood as P(A|B)+P(¬A|B)=1; we more readily think of A as variable here. In a Bayesian update, we vary the hypothesis, not the evidence, so it's more natural to think in terms of a likelihood function, L(H|E).
In a Bayesian network, you propagate probability functions down links, and likelihood functions up links. Hence Pearl distinguished between the two strongly.
Likelihood functions don't sum to 1. Think of them as fragments of belief which aren't meaningful on their own until they're combined with a probability.
Base-rate neglect can be thought of as confusion of likelihood for probability. The conjunction fallacy could also be explained in this way.
I wish it were feasible to get people to use "likely" vs "probable" in this way. Sadly, that's unprobable to work.
I'm imagining it's something like "I thought for ages and changed my mind, let me tell you why".
What I'm pointing at is really much more outside-view than that. Standard warnings about outside view apply. ;p
An example of exchanging probabilities is: I assert X, and another person agrees. I now know that they assign a high probability to X. But that does not tell me very much about how to update.
Exchanging likelihoods instead: I assert X, and the other person tells me they already thought that for unrelated reasons. This tells me that their agreement is further evidence for X, and I should update up.
Or, a different possibility: I assert X, and the other person updates to X, and tells me so. This doesn't provide me with further evidence in favor of X, except insofar as they acted as a proof-checker for my argument.
"Exchange virtual evidence" just means "communicate likelihoods" (or just likelihood ratios!)
Exchanging likelihoods is better than exchanging probabilities, because likelihoods are much easier to update on.
Granted, exchanging models [? · GW] is much better than either of those two ;3 However, it's not always feasible. There's the quick conversational examples like I gave, where someone may just want to express their epistemic state wrt what you just said in a way which doesn't interrupt the flow of conversation significantly. But we could also be in a position where we're trying to integrate many expert opinions in a forecasting-like setting. If we can't build a coherent model to fit all the information together, virtual evidence is probable to be one of the more practical and effective ways to go.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2020-08-30T17:59:57.404Z · LW(p) · GW(p)
Thank you, they were all helpful. I'll write more if I have more questions.
("sadly that's unprobable to work" lol)
↑ comment by Pattern · 2020-09-11T17:23:53.634Z · LW(p) · GW(p)
- I do not understand how Jeffrey updates lead to path dependence. Is the trick that my probabilities can change without evidence, therefore I can just update B without observing anything that also updates A, and then use that for hocus pocus? Writing that out, I think that's probably it, but as I was reading the essay I wasn't sure which bit was where the key step was happening.
TL:DR;
Based on Radical Probabilism and Bayesian Conditioning (page 4 and page 5), the path depends on the order evidence is received in, but the destination does not.
From the text itself:
The "issue" is mentioned:
An attractive feature of Jeffrey’s kinematics is that it allows one to be a fallibilist about evidence and yet still make use of it. An apparent sighting of one’s friend across the street, for instance, can be revised subsequently when you are told that he is out of the country. A closely related feature is the order-dependence of Jeffrey conditioning: conditioning on a particular redistribution of probability over a partition {Ai} and then on a redistribution of probability over another partition {Bi} will not in general yield the same posterior probability as conditioning first on the redistribution over {Bi} and 4 See Howson [8] for a full development of this point. A Bayesian might however take this as an argument against full belief in any contingent proposition. 4 then on that over {Ai}. This property, in contrast to the first, has been a matter of concern rather than admiration; a concern for the most part based on a confusion between the experience or evidence and its effect on the mind of the agent.5
And explained:
Suppose, for instance, that I expect an essay from a student. I arrive at work to find an unnamed essay in my pigeonhole with familiar writing. I am 90% sure that it is from the student in question. But then I find that he left me a message the day before saying that he thinks that he may well not be able to bring me the essay in the next couple of days. In the light of all that I have learnt, I now lower to 30% my probability that the essay was from him. Suppose now I got the message before the essay. The final outcome should be the same, but I will get there a different way: perhaps by my probabilities for the essay coming from him initially going to 10% and then rising to 30% on finding the essay. The important thing is this reversal of the order of experience does not produce a reversal of the order of the probabilities: I do not think it 30% likely that I will get the essay after hearing the message and then revise it to 90% after checking my pigeonhole. The same experiences have different effects on my probabilities depending on the order in which they occur. (This is, of course, just a particular application of the rule that my posteriors depend both on the priors and the inputs).
comment by samshap · 2020-08-21T04:18:31.796Z · LW(p) · GW(p)
Why is a dogmatic Bayesian not allowed to update on virtual evidence? It seems like you (and Jeffries?) have overly constrained the types of observations that a classical Bayesian is allowed to use, to essentially sensory stimuli. It seems like you are attacking a strawman, given that by your definition, Pearl isn't a classical Bayesian.
I also want to push back on this particular bit:
Richard Jeffrey (RJ): Tell me one peice of information you're absolutely certain of in such a situation.
DP: I'm certain I had that experience, of looking at the cloth.
RJ: Surely you aren't 100% sure you were looking at cloth. It's merely very probable.
DP: Fine then. The experience of looking at ... what I was looking at.
I'm pretty sure we can do better. How about:
DP: Fine then. I'm certain I remember believing that I had seen that cloth.
For an artificial dogmatic probabilist, the equivalent might be:
ADP: Fine then. I'm certain of evidence A* : that my probability inference algorithm received a message with information about an observation A.
Essentially, we update on A* instead of A. When we compute the likelihood P(A*|X), we can attempt to account for all the problems with our senses, neurons, memory, etc. that result in P(A*|~A) > 0.
RJ still has a counterpoint here:
RJ: Again I doubt it. You're engaging in inner-outer hocus pocus.* There is no clean dividing line before which a signal is external, and after which that signal has been "observed". The optic nerve is a noisy channel, warping the signal. And the output of the optic nerve itself gets processed at V1, so the rest of your visual processing doesn't get direct access to it, but rather a processed version of the information. And all this processing is noisy. Nowhere is anything certain. Everything is a guess. If, anywhere in the brain, there were a sharp 100% observation, then the nerves carrying that signal to other parts of the brain would rapidly turn it into a 99% observation, or a 90% observation...
But I don't find this compelling. At some point there is a boundary to the machinery that's performing the Bayesian update itself. If the message is being degraded after this point, then that means we're no longer talking about a Bayesian updater.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-21T17:38:22.939Z · LW(p) · GW(p)
It seems like you're not engaging with the core argument, though -- sure, we can understand everything as Bayesian updates, but why must we do so? Surely you agree that a classical, non-straw Bayesian understands Bayesian updates to be normative. The central argument here is just: why? The argument in favor of Bayesian updates is insufficient.
Why is a dogmatic Bayesian not allowed to update on virtual evidence? It seems like you (and Jeffries?)
Because P(A|B) is understood by the ratio formula, P(A&B)/P(B), and the terms P(A&B) and P(B) are understood in terms of the Kolmogorov probability axioms, which means that B is required to be an event (that is, a pre-existing event in the sigma algebra which underlies the probability distribution).
Straw man or no, the assumptions that P(A|B) is to be understood by the ratio formula is incredibly common, and the assumption that P(B) is to be understood as an event in a sigma algebra is incredibly common. Virtual evidence has to at least throw out one or the other; the most straightforward way of doing it throws out both.
Even if these were just common oversimplifications in textbooks, it would be worth pointing out. But I don't think that's the case -- I think lots of Bayesians would assert these things. Even if they've read Pearl at some point. (I think classical Bayesians read Pearl's section on virtual evidence and see it as a neat technical trick, but not a reason to really abandon fundamental assumptions about how updates work.)
It seems like you (and Jeffries?) have overly constrained the types of observations that a classical Bayesian is allowed to use, to essentially sensory stimuli.
I neglected to copy the thing where Jeffrey quotes prominent Bayesians to establish that they really believe these things, before ripping them to shreds.
It seems to me, talking to people, that the common Bayesian world-view includes stuff like: "any uncertain update like Jeffrey is talking about has to eventually ground out in evidence which is viewed with 100% certainty"; "formally, we have to adjust for observation bias by updating on the fact that we observed X rather than X alone; but ideal Bayesian agents never have to deal with this problem at the low level, because an agent is only ever updating on its observations -- and an observation X is precisely the sort of thing which is equal to the-observation-of-X"; "what would you update on, if not your observations?"
This stuff isn't necessarily explicitly written down or explicitly listed as part of the world-view, but (in my limited experience) it comes out when talking about tricky issues around the boundary. (And also there are some historical examples of Bayesians writing down such thoughts.)
The formal mathematics seems a little conflicted on this, since formal probability theory gives one the impression that one can update on any proposition, but information theory and some other important devices assume a stream of observations with a more restricted form.
I find your comment interesting because you seem to be suggesting a less radical interpretation of all this:
- Radical Probabilism throws out dogmatism of perception, rigidity, and empiricism (but can keep the ratio formula and the kolmogorov axioms -- although I think Jeffrey would throw out both of those too). This opens up the space of possible updates to "almost anything". I then offer virtual evidence as a reformulation which makes things feel more familiar, without really changing the fundamental conclusion that Bayesian updates are being abandoned.
- Your steelman Bayesianism instead takes the formalism of virtual evidence seriously, and so abandons the ratio formula and the Kolmogorov axioms, but keeps a version of dogmatism of perception, rigidity, and empiricism -- with the consequence of keeping Bayesian updates as the fundamental update rule.
I'm fine with either of these approaches. The second seems more practical for the working Bayesian. The first seems more fundamental/foundational, since it rests simply on scratching out unjustified rationality assumptions (IE, Bayesian updates).
It seems like you are attacking a strawman, given that by your definition, Pearl isn't a classical Bayesian.
I think Pearl has thought deeply about these things largely because Pearl has read Jeffrey.
Essentially, we update on A* instead of A. When we compute the likelihood P(A*|X), we can attempt to account for all the problems with our senses, neurons, memory, etc. that result in P(A*|~A) > 0.
The practical problem with this, in contrast to a more radical-probabilism approach, is that the probability distribution then has to explicitly model all of that stuff. As Scott and I discussed in Embedded World-Models [LW · GW], classical Bayesian models require the world to be in the hypothesis space (AKA realizability AKA grain of truth) in order to have good learning guarantees; so, in a sense, they require that the world is smaller than the probability distribution. Radical probabilism does not rest on this assumption for good learning properties.
But I don't find this compelling. At some point there is a boundary to the machinery that's performing the Bayesian update itself. If the message is being degraded after this point, then that means we're no longer talking about a Bayesian updater.
I'm not sure what Jeffrey would say to this. I like his idea of doing away with this boundary. But I have not seen that he follows through, actually providing a way to do without drawing such a boundary.
Replies from: samshap↑ comment by samshap · 2020-08-22T05:58:26.619Z · LW(p) · GW(p)
I definitely missed a few things on the first read through - thanks for repeating the ratio argument in your response.
I'm still confused about this statement:
Virtual evidence requires probability functions to take arguments which aren't part of the event space.
Why can't virtual evidence messages be part of the event space? Is it because they are continuously valued?
As to why one would want to have Bayesian updates be normative: one answer is that they maximize our predictive power, given sufficient compute. Given the name of this website, that seems a sufficient reason.
A second answer you hint at here:
The second seems more practical for the working Bayesian.
As a working Bayesian myself, having a practical update rule is quite useful! As far as I can tell, I don't see a good alternative in what you have provided.
Then we have to ask why not (steelmanned) classical Bayesianism? I think you've two arguments, one of which I buy, the other I don't.
The practical problem with this, in contrast to a more radical-probabilism approach, is that the probability distribution then has to explicitly model all of that stuff.
This is the weak argument. Computing P(A*|X) "the likelihood I recall seeing A given X" is not a fundamentally different thing than modeling P(A|X) "the likelihood signal A happened given X". You have to model an extra channel effect or two, but that's just a difference of degree.
Immediately after, though, you have the better argument:
As Scott and I discussed in Embedded World-Models [LW · GW], classical Bayesian models require the world to be in the hypothesis space (AKA realizability AKA grain of truth) in order to have good learning guarantees; so, in a sense, they require that the world is smaller than the probability distribution. Radical probabilism does not rest on this assumption for good learning properties.
if I were to paraphrase - Classical Bayesianism can fail entirely when the world state does not fit into one of its nonzero probability hypotheses, which must be of necessity limited in any realizable implementation.
I find this pretty convincing. In my experience this is a problem that crops up quite frequently, and requires meta-Bayesian methods you mentioned like calibration (to notice you are confused) and generation of novel hypotheses.
(Although Bayesianism is not completely dead here. If you reformulate your estimation problem to be over the hypothesis space and model space jointly, then Bayesian updates can get you the sort of probability shifts discussed in Pascal's Muggle [LW · GW]. Of course, you still run into the 'limited compute' problem, but in many cases it might be easier than attempting to cover the entire hypothesis space. Probably worth a whole other post by itself.)
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2020-08-24T14:50:17.257Z · LW(p) · GW(p)
I definitely missed a few things on the first read through - thanks for repeating the ratio argument in your response.
Oh, just FYI, I inserted that into the main post after writing about it in my response to you!
Replies from: samshap↑ comment by abramdemski · 2020-08-24T15:46:46.676Z · LW(p) · GW(p)
Why can't virtual evidence messages be part of the event space? Is it because they are continuously valued?
Ah, now there's a good question.
You're right, you could have an event in the event space which is just "the virtua-evidence update [such-and-such]". I'm actually going to pull out this trick in a future follow-up post.
I note that that's not how Pearl or Jeffrey understand these updates. And it's a peculiar thing to do -- something happens to make you update a particular amount, but you're just representing the event by the amount you update. Virtual evidence as-usually-understood at least coins a new symbol to represent the hard-to-articulate thing you're updating on.
But that's not much of an argument against the idea, especially when virtual evidence is already a peculiar practice.
Note that re-framing virtual evidence updates as Bayesian updates doesn't change the fact that you're now allowing essentially arbitrary updates rather than using Bayes' Law to compute your update. You're adjusting the formalism around an update to make Bayes' Law true of it, not using Bayes' Law to compute the update. So Bayes' Law is still de-throned in the sense that it's no longer the formula used to compute updates.
As to why one would want to have Bayesian updates be normative: one answer is that they maximize our predictive power, given sufficient compute. Given the name of this website, that seems a sufficient reason.
I'm going to focus on this even though you more or less concede the point later on in your reply. (By the way, I really appreciate your in-depth engagement with my position.)
In what sense? What technical claim about Bayesian updates are you trying to refer to?
One candidate is the dominance of Solomonoff induction over any computable machine learning technique. This has several problems:
- Solomonoff induction only gets you this guarantee in the sequential prediction setting, whereas logical induction gets a qualitatively similar guarantee in a broader setting.
- "sufficiently much computational power" is infinite, whereas the "sufficiently much computational power" for logical induction is finite. So logical induction would seem to get closer to offering real advice for bounded agents, rather than idealized decision theory whose application to bounded agents requires further insights [LW · GW].
- Thus, logical induction is more suited to handling logical uncertainty, which is critical for handling bounded agents. Logical uncertainty becomes less confusing when non-Bayesian updates are allowed.
- It can display irrational behaviors such as miscalibration, if grain-of-truth does not apply. These failures of rationality can be independently concerning, even given a nice guarantee about Bayes loss.
Note that I did not put the point "Solomonoff's dominance property requires grain-of-truth" in this list, because it doesn't -- in a Bayes Loss sense, Solomonoff still does almost as well as any computable machine learning technique even in non-realizable settings where it may not converge to any one computable hypothesis. (Even though better calibration does tend to improve Bayes loss, we know it isn't losing too much to this.)
Another candidate is that Bayes' law is the optimal update policy when starting with a particular prior and trying to minimize Bayes loss. But again this has several problems.
- This is only true if the only information we have coming in is a sequence of propositions which we are updating 100% on. Realistically, we can revise the prior to be better just by thinking about it (due to our logical uncertainty), making non-Bayesian updates relevant.
- This optimality property only makes sense if we believe something like grain-of-truth. "I've listed all the possibilities in my prior, and I'm hedging against them according to my degree of belief in them. What more do you want from me?"
- Rationality isn't just about minimizing Bayes loss. Bayes loss is a compelling property in part because it gets us other intuitively compelling properties (such as Bayes' Law). But properties such as calibration and convergence also have intuitive appeal, and we can back this appeal up with Dutch Book and Dutch-Book-like arguments.
A second answer you hint at here:
>The second seems more practical for the working Bayesian.
As a working Bayesian myself, having a practical update rule is quite useful! As far as I can tell, I don't see a good alternative in what you have provided.
Sadly, the actual machinery of logical induction was beyond the scope of this post, but there are answers. I just don't yet know a good way to present it all as a nice, practical, intuitively appealing package.
Replies from: samshap↑ comment by samshap · 2020-08-25T03:51:32.599Z · LW(p) · GW(p)
You're right, you could have an event in the event space which is just "the virtua-evidence update [such-and-such]". I'm actually going to pull out this trick in a future follow-up post.
I note that that's not how Pearl or Jeffrey understand these updates. And it's a peculiar thing to do -- something happens to make you update a particular amount, but you're just representing the event by the amount you update. Virtual evidence as-usually-understood at least coins a new symbol to represent the hard-to-articulate thing you're updating on.
That's not quite what I had in mind, but I can see how my 'continuously valued' comment might have thrown you off. A more concrete example might help: consider Example 2 in this paper. It posits three events:
b - my house was burgled
a - my alarm went off
z - my neighbor calls to tell me the alarm went off
Pearl's method is to take what would be uncertain information about a (via my model of my neighbor and the fact she called me) and transform it into virtual evidence (which includes the likelihood ratio). What I'm saying is that you can just treat z as being an event itself, and do a Bayesian update from the likelihood P(z|b)=P(z|a)P(a|b)+P(z|~a)P(~a|b), etc. This will give you the exact same posterior as Pearl. Really, the only difference in these formulations is that Pearl only needs to know the ratio P(z|a):P(z|~a), whereas traditional Bayesian update requires actual values. Of course, any set of values consistent with the ratio will produce the right answer.
The slightly more complex case (and why I mentioned continuous values) is in section 5 where the message includes probability data, such as a likelihood ratio. Note that the continuous value is not the amount you update (at least not generally), because its not generated from your own models, but rather by the messenger. Consider event z99, where my neighbor calls to say she's 99% sure the alarm went off. This doesn't mean I have to treat P(z99|b):P(z99|~b) as 99:1 - I might model my neighbor as being poorly calibrated (or as not being independent of other information I already have), and use some other ratio.
In what sense? What technical claim about Bayesian updates are you trying to refer to?
Definitely the second one, as optimal update policy. Responding to your specific objections:
This is only true if the only information we have coming in is a sequence of propositions which we are updating 100% on.
As you'll hopefully agree with at this point, we can always manufacture the 100% condition by turning it into virtual evidence.
This optimality property only makes sense if we believe something like grain-of-truth.
I believe I previously conceded this point - the true hypothesis (or at least a 'good enough' one) must have a nonzero probability, which we can't guarantee.
But properties such as calibration and convergence also have intuitive appeal
Re: calibration - I still believe that this can be included if you are jointly estimating your model and your hypothesis.
Re: convergence - how real of a problem is this? In your example you had two hypotheses that were precisely equally wrong. Does convergence still fail if the true probability is 0.500001 ?
(By the way, I really appreciate your in-depth engagement with my position.)
Likewise! This has certainly been educational, especially in light of this:
Sadly, the actual machinery of logical induction was beyond the scope of this post, but there are answers. I just don't yet know a good way to present it all as a nice, practical, intuitively appealing package.
The solution is too large to fit in the margins, eh? j/k, I know there's a real paper. Should I go break my brain trying to read it, or wait for your explanation?
Replies from: abramdemski↑ comment by abramdemski · 2020-08-30T12:10:00.758Z · LW(p) · GW(p)
The solution is too large to fit in the margins, eh? j/k, I know there's a real paper. Should I go break my brain trying to read it, or wait for your explanation?
Oh, I definitely don't have a better explanation of that in the works at this point.
Re: convergence - how real of a problem is this? In your example you had two hypotheses that were precisely equally wrong. Does convergence still fail if the true probability is 0.500001 ?
My main concern here is if there's an adversarial process taking advantage of a system, as in the trolling mathematicians [LW · GW] work.
In the case of mathematical reasoning, though, the problem is quite severe -- as is hopefully clear from what I've linked above, although an adversary can greatly exacerbate the problem, even a normal non-adversarial stream of evidence is going to keep flipping the probability up and down by non-negligible amounts. (And although the post offers a solution, it's a pretty dumb prior, and I argue all priors which avoid this problem will be similarly dumb [LW · GW].)
Re: calibration - I still believe that this can be included if you are jointly estimating your model and your hypothesis.
I don't get this at all! What do you mean?
As you'll hopefully agree with at this point, we can always manufacture the 100% condition by turning it into virtual evidence.
As I discussed earlier, I agree, but with the major caveat that the likelihoods from the update aren't found by first determining what you're updating on, and then looking up the likelihoods for that; instead, we have to determine the likelihoods and then update on the virtual-evidence proposition with those likelihoods.
That's not quite what I had in mind, but I can see how my 'continuously valued' comment might have thrown you off. A more concrete example might help: consider Example 2 in this paper. It posits three events:
[...]
What I'm saying is that you can just treat z as being an event itself, and do a Bayesian update from the likelihood [...]
Hmmmm. Unfortunately I'm not sure what to say to this one except that in logical induction, there's not generally a pre-existing z we can update on like that.
Take the example of calibration traders. These guys can be described as moving probabilities up and down to account for the calibration curves so far. But that doesn't really mean that you "update on the calibration trader" and e.g. move your 90% probabilities down to 89% in response. Instead, what happens is that the system takes a fixed-point, accounting for the calibration traders and also everything else, finding a point where all the various influences balance out. This point becomes the next overall belief distribution.
So the actual update is a fixed-point calculation, which isn't at all a nice formula such as multiplying all the forces pushing probabilities in different directions (finding the fixed point isn't even a continuous function).
We can make it into a Bayesian update on 100%-confident evidence by modeling it as virtual evidence, but the virtual evidence is sorta pulled from nowhere, just an arbitrary thing that gets us from the old belief state to the new one. The actual calculation of the new belief state is, as I said, the big fixed point operation.
You can't even say that we're updating on all those forces pulling the distribution in different directions, because there are more than one fixed points of those forces. We don't want to have uncertainty about which of those fixed points we end up in; that would give the wrong thing. So we really have to update on the fixed-point itself, which is already the answer to what to update to; not some information which we have pre-existing beliefs about and can figure out likelihood ratios for to figure out what to update to.
So that's my real crux, and any examples with telephone calls and earthquakes etc are merely illustrative for me. (Like I said, I don't know how to actually motivate any of this stuff except with actual logical uncertainty, and I'm surprised that any philosophers would have become convinced just from other sorts of examples.)
Replies from: samshap↑ comment by samshap · 2020-09-06T06:35:51.319Z · LW(p) · GW(p)
Hmmmm. Unfortunately I'm not sure what to say to this one except that in logical induction, there's not generally a pre-existing z we can update on like that.
So that's my real crux, and any examples with telephone calls and earthquakes etc are merely illustrative for me. (Like I said, I don't know how to actually motivate any of this stuff except with actual logical uncertainty, and I'm surprised that any philosophers would have become convinced just from other sorts of examples.)
I agree that the logical induction case is different, since it's hard to conceive of likelihoods to begin with. Basically, logical induction doesn't even include what I would call virtual evidence. But many of the examples you gave do have such a z. I think I agree with your crux, and my main critique here is just in the examples of overly dogmatic Bayesian who refuses to acknowledge the difference between a and z. I won't belabor the point further.
I've thought of another motivating example, BTW. In wartime, your enemy deliberately sends you some verifiably true information about their force dispositions. How should you update on that? You can't use a Bayesian update, since you don't actually have a likelihood model available. We can't even attempt to learn a model from the information, since we can't be sure its representative.
I don't get this at all! What do you mean?
By model M, I mean an algorithm that generates likelihood functions, so M(H,Z) = P(Z|H).
So any time we talk about a likelihood P(Z|H), it should really read P(Z|H,M). We'll posit that P(H,M) = P(H)P(M) (i.e. that the model says nothing about our priors), but this isn't strictly necessary.
E(P(Z|H,M)) will be higher for a well calibrated model than a poorly calibrated model, which means that we expect P(H,M|Z) to also be higher. When we then marginalize over the models to get a final posterior on the hypothesis P(H|Z), it will be dominated by the well-calibrated models: P(H|Z) = SUM_i P(H|M_i,Z)P(M_i|Z).
BTW, I had a chance to read part of the ILA paper. It barely broke my brain at all! I wonder if the trick of enumerating traders and incorporating them over time could be repurposed to a more Bayesianish context, by instead enumerating models M. Like the trading firm in ILA, a meta-Bayesian algorithm could keep introducing new models M_k over time, with some intuition that the calibration of the best model in the set would improve over time, perhaps giving it all those nice anti-dutch book properties. Basically this is a computable Solomonoff induction, that slowly approaches completeness in the limit. (I'm pretty sure this is not an original idea. I wouldn't be surprised if something like this contributed to the ILA itself).
Of course, its pretty unclear how this would work in the logical induction case. This might all be better explained in its own post.
comment by Richard_Kennaway · 2020-08-24T20:11:38.585Z · LW(p) · GW(p)
Virtual evidence requires probability functions to take arguments which aren't part of the event space
Not necessarily. Typically, the events would be all the Lebesgue measurable subsets of the state space. That's large enough to furnish a suitable event to play the role of the virtual evidence. In the example involving A, B, and the virtual event E, one would also have to somehow specify that the dependencies of A and B on E are in some sense independent of each other, but you already need that. That assumption is what gives sequence-independence.
The sequential dependence of the Jeffrey update results from violating that assumption. Updating P(B) to 60% already increases P(A), so updating from that new value of P(A) to 60% is a different update from the one you would have made by updating on P(A)=60% first.
virtual evidence treats Bayes' Law (which is usually a derived theorem) as more fundamental than the ratio formula (which is usually taken as a definition).
That is the view taken by Jaynes, a dogmatic Bayesian if ever there was one. For Jaynes, all probabilities are conditional probabilities, and when one writes baldly P(A), this is really P(A|X), the probability of A given background information X. X may be unstated but is never absent: there is always background information. This also resolves Eliezer's Pascal's Muggle conundrum over how he should react to 10^10-to-1 evidence in favour of something for which he has a probability of 10^100-to-1 against. The background information X that went into the latter figure is called into question.
I notice that this suggests an approach to allowing one to update away from probabilities of 0 or 1, conventionally thought impossible.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-30T11:31:13.744Z · LW(p) · GW(p)
Not necessarily. Typically, the events would be all the Lebesgue measurable subsets of the state space. That's large enough to furnish a suitable event to play the role of the virtual evidence.
True, although I'm not sure this would be "virtual evidence" anymore by Pearl's definition. But maybe this is the way it should be handled.
A different way of spelling out what's unique about virtual evidence is that, while compatible with Bayes, the update itself is calculated via some other means (IE, we get the likelihoods from somewhere else than looking at pre-defined likelihoods for the proposition we're updating on).
This also resolves Eliezer's Pascal's Muggle conundrum over how he should react to 10^10-to-1 evidence in favour of something for which he has a probability of 10^100-to-1 against. The background information X that went into the latter figure is called into question.
Does it, though? If you were going to call that background evidence into question for a mere 10^10-to-1 evidence, should the probability have been 10^100-to-1 against in the first place?
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2020-08-30T12:02:32.056Z · LW(p) · GW(p)
Does it, though? If you were going to call that background evidence into question for a mere 10^10-to-1 evidence, should the probability have been 10^100-to-1 against in the first place?
This is verging on the question, what do you do when the truth is not in the support of your model? That may be the main way you reach 10^100-to-1 odds in practice. Non-Bayesians like to pose this question as a knock-down of Bayesianism. I don't agree with them, but I'm not qualified to argue the case.
Once you've accepted some X as evidence, i.e. conditioned all your probabilities on X, how do you recover from that when meeting new evidence Y that is extraordinarily unlikely (e.g. 10 to -100) given X? Pulling X out from behind the vertical bar may be a first step, but that still leaves you contemplating the extraordinarily unlikely proposition X&Y that you have nevertheless observed.
comment by Ben Pace (Benito) · 2021-12-27T18:36:25.662Z · LW(p) · GW(p)
Radical Probabilism [LW · GW] is an extensions of the Embedded Agency philosophical position. I remember reading is and feeling a strong sense that I really got to see a well pinned-down argument using that philosophy. Radical Probabilism might be a +9, will have to re-read, but for now I give it +4.
(This review is taken from my post Ben Pace's Controversial Picks for the 2020 Review [LW · GW].)
comment by Cole Wyeth (Amyr) · 2024-11-11T19:36:16.609Z · LW(p) · GW(p)
What would you have to see proven about Solomonoff induction to conclude it does not have convergence/calibration problems? My friend Aram Ebtekar has worked on showing it converges to 50% on adversarial sequences.
Replies from: abramdemski↑ comment by abramdemski · 2024-11-11T20:20:40.409Z · LW(p) · GW(p)
The thing to prove is precisely convergence and calibration!
Convergence: Given arbitrary observed sequences, the probabilities of the latent bits (program tape and working tape) converge.
(Obviously the non-latent bits converge, if we assume they eventually get observed; hence the focus on the latent bits here.)
Calibration: Considering the sequence of probabilistic predictions has the property that, considering the subsequence of only predictions between 79% and 81% (for example), the empirical frequency of those predictions coming true will eventually be in that range and stay within that range forever. (This should be true for all such ranges.
Of course, there will also be a number of interesting formal variations on these properties, either weakening them (EG giving conditions where we do get a guarantee) or strengthening them (EG giving explicit bounds on how badly these properties can be violated, rather than only proving that they are obeyed in the limit). For example, converging to predict 50% on adversarial sequences is a much weaker form of a calibration guarantee.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2020-09-20T23:57:32.509Z · LW(p) · GW(p)
This blog post seems superficially similar, but I can't say ATM if there are any interesting/meaningful connections:
https://www.inference.vc/the-secular-bayesian-using-belief-distributions-without-really-believing/
comment by TAG · 2020-08-20T16:07:11.094Z · LW(p) · GW(p)
Blimey! This could be the Two Dogmas of rationalism.
Replies from: abramdemski↑ comment by abramdemski · 2020-08-21T16:58:08.197Z · LW(p) · GW(p)
I have very mixed feelings about this comment!