Posts
Comments
Sure, never give up, die with dignity if it comes to that. None of that translates into a budget. Concrete plans translate into a budget.
So if no one else knew how to counter drone swarms, and every defence they experimented with got obliterated by drone swarms,
…then by hypothesis, you’re screwed. But you’re making up this scenario, and this is where you’ve brought the imaginary protagonists to. You’re denying them a solution, while insisting they should spend money on a solution.
Suppose you had literally no ideas at all how to counter drone swarms, and you were really bad at judging other people's ideas for countering drone swarms.
In that case, I would be unqualified to do anything, and I would be wondering how I got into a position where people were asking me for advice. If I couldn’t pass the buck to someone competent, I’d look for competent people, get their recommendations, try as best I could to judge them, and turn on the money tap accordingly. But I can’t wave a magic wand, and where there was a pile of money there is now a pile of anti-drone technology.
Neither can anyone in AI alignment.
Money isn’t magic. It’s nothing more than the slack in the system of exchange. You have to start from some idea of what the work is that needs to happen. That seems to me to be lacking. Are there any other proposals on the table against doom but “shut it all down”?
If you spend 8000 times less on AI alignment (compared to the military),
You must also believe that AI risk is 8000 times less (than military risk).
Why?
We know how to effectively spend money on the military: get more of what we have and do R&D to make better stuff. The only limit on effective military spending is all the other things that the money is needed for, i.e. having a country worth defending.
It is not clear to me how to buy AI safety. Money is useless without something to spend it on. What would you buy with your suggested level of funding?
As I mentioned, I eat to sustain myself. I find quite repellent the idea of growing a bigger liver just to be able to eat more, and it did not even occur to me that someone would want to do that.
As for why people have got a lot fatter over recent decades, there are various ideas, but I don’t think anyone knows. ETA: See also.
Beings evolved by natural selection have to be small and short-lived relative to the size of the universe, or they won’t have enough space or time to reach intelligence. How small and short-lived I don’t know, but I can’t see galaxies doing it. Nor planets, which do not reproduce and only barely interact.
I agree with the problem (which is rumoured to be one factor in the Trump regime's unhinged behaviour), but I doubt that an add-on to improve LLM output will do any more than polish the turd. And how would such an add-on be created? More LLMs would only pile the shit higher. Even humans don't seem capable of "revising" LLM slop into anything useful.
ETA: "anything useful" depends on one's use for it. Clearly (if the rumours are true) it's being very useful to the Trump regime. They can do anything they like and trot out an LLM argument for it, and do the same to answer all possible reactions and all subsequent events. What people seem incapable of doing is "revising" LLM output into something possessing epistemic virtue.
It’s like asking why high kinetic energy “feels” hot. It doesn’t, heat is just how the brain models signals from temperature receptors and maps them into the self-model.
We know how high (random) kinetic energy causes a high reading on a thermometer.
We do not know why this "feels hot" to people but (we presume) not to a thermometer. Or if you think, as some have claimed to, that it might actually "feel hot" to a strand of mercury in a glass tube, how would you go about finding out, given that in the case of a thermometer, we already know all the relevant physical facts about why the line lengthens and shrinks?
Sections 4 and 5 explain why this evolved: it’s a useful way for the brain to prioritize action when reflexes aren’t enough. You “feel” something because that’s how your brain tracks itself and the environment.
This is redefining the word "feel", not accounting for the thing that "feel" ordinarily points to.
The same thing happened to the word "sensation" when mechanisms of the sensory organs were being traced out. The mechanism of how sensations "feel" (the previous meaning of the word "sensation") was never found, and "sensation" came to be used to mean only those physical mechanisms. This is why the word "quale" (pl. qualia) was revived, to refer to what there was no longer a name for, the subjective experience of "sensations" (in the new sense).
The OP, for all its length, appears to be redefining the word "conscious" to mean "of a system, that it contains a model of itself". It goes into great detail and length on phenomena of self-modelling and speculations of why they may have arisen, and adds the bald assertion, passim, that this is what consciousness is. The original concept that it aims and claims to explain is not touched on.
Where does this model fail?
I didn't see any explanation of why subjective experience exists at all. Why does it feel like something to be me? Why does anything feel like something?
No, I read your vignette as describing a process of things snowballing all on their own, rather than by any such skilful response on either side. Hence my sceptical reply to it.
This is a very strange read, for two reasons.
The story began (emphasis added) (ETA: more emphasis added):
When the cashier smiles at you 1% more than usual, you probably don't stop and wonder whether it's a sign or not. You won't think anything of it because it's well within the noise -- but you might smile 1% more in return without noticing that you do.
And I took that to be the pattern of the subsequent mutual 1%-ing, neither of the participants noticing what they are doing until you envisage some outside witness waking them up:
Before you know it people might be saying "Get a room, you two!".
Of course there are skills. But they all begin with noticing.
I am claiming no particular social skills for myself, only perhaps a general skill of noticing.
"Frog boiling" is standing in for "responding skillfully to women expressing subtle interest, and managing to turn it into clear cut interest so that asking her out is no longer a leap of faith"... right?
No, I read your vignette as describing a process of things snowballing all on their own, rather than by any such skilful response on either side. Hence my sceptical reply to it.
Am I reading this correctly that you're patting yourself on the back
No.
Is accidentally intentionally getting women too obviously interested in them the problem that you think most men have in dating?
No, that strikes me as so far fetched a scenario as to only occur in the fiction of another era.
Is the kingdom of heaven actually going to be as perfect as Christians imagine it? Is the lion really going to lie down with lamb? Is God really all-loving and omnipotent? Is that beam of light really infinite? That’s not really the point.
For believers (which I do not count myself among), leaving aside the beam of light, that very much is the point. That God really is up there/down here/in here and it is our duty to live as He has shown us. "He hath shewed thee, O man, what is good; and what doth the LORD require of thee, but to do justly, and to love mercy, and to walk humbly with thy God?" (Micah 6:8.)
Another has commented that the Unbendable Arm demo is headology, and that you can just do the thing without tricking yourself into it.
I must wonder whether this "as if" conception of God will wear thin in adversity. Are you really going to put a life's work into building a cathedral for the glory of God on that foundation?
I remember that back in the 60's, the hippy era, the concept arose of the "earth mother", a woman fulfilling an ideal of bountifulness, nurturing, and attunement to Mother Nature. It did not take long for people — or at least, the women — to realise that this was a scam to get the women to do all the cooking and provide free sex (which was called free love, but that is another story). As a woman of the time put it, "there's only so many pounds of carrots you can scrub and still imagine you're having a valid spiritual experience."
Why should I bargain for a portion of pie if I can just take whatever I want? This is the real game between an ASI and humanity:
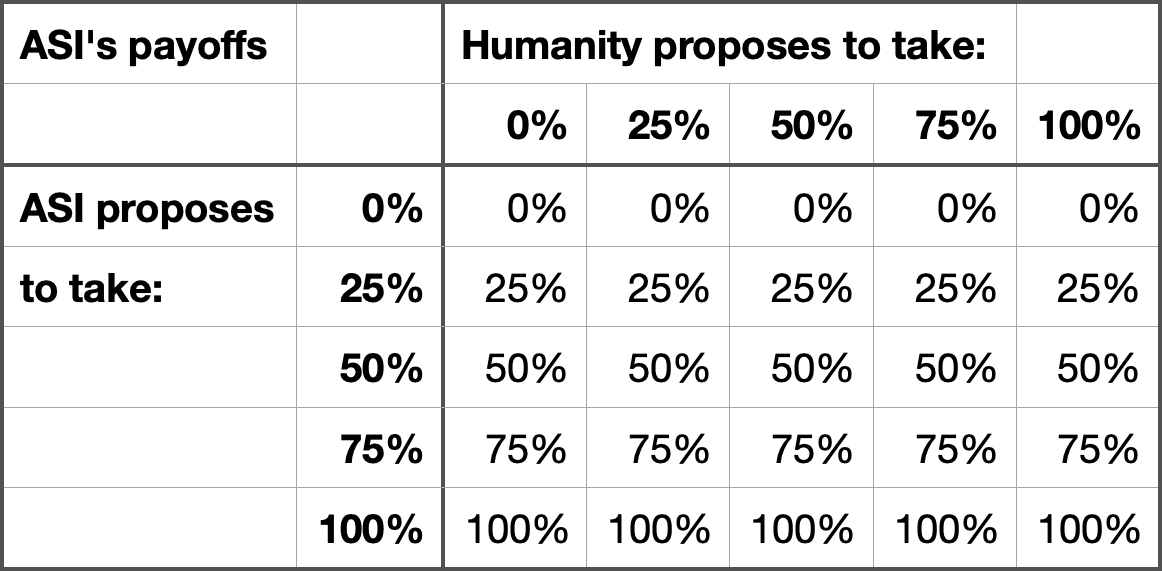
When the cashier smiles at you 1% more than usual, you probably don't stop and wonder whether it's a sign or not. You won't think anything of it because it's well within the noise -- but you might smile 1% more in return without noticing that you do. She might smile an additional 1% the next time, and you might respond in kind. Before you know it people might be saying "Get a room, you two!".
I do not believe that any such frog-boiling has ever happened to me.
It is said that humans who are not paying attention are not general intelligences. I try to cultivate the virtue of attention.
The distinction always exists.
The perception and the perception of the perception are always different things. But to return to the situation at hand, I find it difficult to imagine responding to subtle clues by asking for the other person's phone number, without being aware that "here I am, responding to what I think are probably clues by considering possible responses", and also going on to higher levels of the ladder, like considering whether my perception of these supposed clues is correct, how i know what I think I know, deciding whether if clues these be I wish to build something on them (depending on the person, maybe I'd rather put them off than draw them on), deciding how long to maintain plausible deniability that there is anything going on here and when to break cover, and so on. The searchlight of attention, of noticing, sweeps over all of these, in less time than it takes to read this paragraph.
At least, that is how it is for me.
Higher-level posts are normally filled by promoting those who entered at a lower level. When there are no lower level staff, what replaces that process?
I notice that this article reads like it was produced by the process it condemns.
Different minds may operate quite differently.
The distinction you are describing may be very important and salient to you, but it does not necessarily even exist for someone else. At one extreme, someone who is always effectively asleep (by comparison to the other extreme) and barely aware of their own existence, permanently on automatic pilot, senses things without being aware of themselves sensing things, because they are hardly aware of themselves at all. At the other, someone who is always aware of their own existence, whose own presence is as ineluctable to them as their awareness of the sun when out of doors on a bright sunny day: for such a person, to be aware is always to be aware of themselves. At either of those extremes, the distinction you are drawing does not exist. In the first case, because the person is never aware of themselves; in the second, because they always are.
So what I've though is maybe that is backwards. I'm starting a test to see flipping the approach, putting the word I already know up first and then having to come up with the Korean word as the "answer"
I thought it was standard to practice flashcards both ways round. Recognition and recall are different skills.
Familiarity with he following people and how they influenced the movement. I’m probably forgetting some.
• Eliezer Yudkowski
...
• Stuart Russel
Especially if they know how to spell all their names!
This might seem absurd, but try to explain soccer to someone without making it sound absurd.
No need, soccer is already absurd to me.
This is exactly the standard of answer I predicted. It stirs my analysis of the story into its previous interpretation without the two interacting. Its comment that "I didn’t ignore that tension—I leaned into it" is an exercise in irregular verbs, or would be, if there was a mind behind it.
As for the traits being selected, we obviously don't know, though the idea is that selecting for homosexuality gifts the selectors an obvious manner of control of whomever makes it into the college of cardinals.
I don't know what you have in mind there. If they're 80% gay, they can hardly threaten each other with exposure. At the most, the accusation would be a smokescreen, transparent to all the insiders, for those who already have the power to dispose of an enemy. Cf. the exclusion of Marine Le Pen from standing for President of France, on the grounds of an "embezzlement" which it appears that every party freely engages in.
Who or what is Amelia AI?
From an inconsistency, everything follows.
The story tells us that on the one hand, Hugo shows no sign of higher brain function. Then on the other hand, it introduces an exception to that. So does Hugo have higher brain function?
Hugo does not exist. There are no observations to be made on him that might shed light. Everything in this story was made up by the author. There is no answer to the question. You might as well say "suppose I had a square circle! suppose 2+2 was 3! suppose I could flap my arms and fly to the Moon!"
Unsurprisingly, the LLM (from what you have said of its answer) fails to notice this.
Feel free to tell it that and see what it says. I expect it to just add my commentary to the sludge and vomit it back out again.
I read this.
Then I had this in my email from Academia.edu:
Dear Dr. Kennaway,
Based on the papers you’ve autocfp, we think you might be interested in this recently published article from
"autocfp". Right. There is not the slightest chance I will be interested in whatever follows.
Re plain language movements, in the UK there were Gowers' "Plain Words" books from around that time (link provides links to full texts). I read these a very long time ago, but I don't recall if he spoke of sentence length, being mainly occupied with the choice of words.
But now they’re gone! I didn’t expect them to be real, but still, owowowowow! That’s loss aversion for you.
I notice that although the loot box is gone, the unusually strong votes that people made yesterday persist.
I got the Void once, just from spinning the wheels, but it doesn't show up on my display of virtues.
Apparently I now have a weak upvote strength of 19 and a strong upvote of 103. Similarly for downvotes. But I shall use my powers (short-lived, I'm sure) only for good.
What is it with negative utilitarianism and wanting to eliminate those they want to help?
Insanity Wolf answers your questions:
SEES UNHAPPY PERSON
KILLS THEM TO INCREASE GLOBAL HAPPINESS
IT'S A THEOREM!
YOU CAN'T ARGUE WITH A THEOREM!
We do not know each other. I know nothing about you beyond your presence on LW. My comments have been to the article at hand and to your replies. Maybe I'll expand on them at some point, but I believe the article is close to "not even wrong" territory.
Meanwhile, I'd be really interested in hearing from those two strong upvoters, or anyone else whose response to it differs greatly from mine.
Rough day, huh?
There you are — more psychologising.
Seriously though, you’ve got a thesis, but you’re missing a clear argument. Let me help:
Now condescension.
This looks to me like long-form gibberish, and it's not helped by its defensive pleas to be taken seriously and pre-emptive psychologising of anyone who might disagree.
People often ask about the reasons for downvotes. I would like to ask, what did the two people who strongly upvoted this see in it? (Currently 14 karma with 3 votes. Leaving out the automatic point of self-karma leaves 13 with 2 votes.)
a system that lets people express which issues they care about in a freeform way
We already have that: the Internet, and the major platforms built on it. Anyone can talk about anything.
allowing us to simply express our feelings about the issues which actually affect us.
If the platform is created, how do you get people to use it the way you would like them to? People have views on far more than the things someone else thinks should concern them.
You're still comparing a real situation with an imagined one. For such a large aspect of one's life, I do not think it possible to have such assurance that one can imagine the hypothetical situation well enough. Whatever you decide, you're taking a leap in the dark. This is not to say that you shouldn't take that leap, just to say that that is what you would be doing. You won't know what the other side is really (literally! really) like until you're there, and then there's no going back. (As I understand it, and my understanding may be out of date, the sort of drugs you are considering have permanent effects from the outset. Even a small step down that road cannot be taken back.)
Even in the case of blindness, I have read of a case where sight was restored to someone blind from birth, who ended up very dissatisfied. Because if you've never seen, it takes a long time to make any sense of the restored sense. Not to the point of putting his eyes out again, I think, but there was no "happily ever after".
But then, there never is.
There is an important asymmetry between the status quo and all alternatives. The status quo exists. You are walking around in it, seeing it close up, experiencing it. Any questions you may have about the reality around you can be answered by investigating it, and that investigation may turn up things you did not know, and did not know you did not know.
Alternatives, however, are imaginary. They're something made up in your head. As such, they do not have the tangibility — literally — of reality. They do not have the inexhaustibility of reality. You cannot discover things about them that you did not put into them. Outside of mathematics, applying reasoning to an imagined scenario is a poor guide to how it would work out if it were actually created. You don't know what you don't know about how it would work, and you have no way of discovering.
Or in brief, Status Quo Bias Fallacy.
I wouldn't see any compelling reason to induce in myself the desire to have sex.
That might only be true up until having the actual experience. Then you would be in a position to say which state of affairs you actually prefer.
ETA: See also.
Am I rationally required to take them?
Nobody is ever "rationally required" to do anything. [Imagine Soyboy vs. Chad meme here.]
There is a typo/thinko where you say the answers to (i) and (ii) "should be the same". They should be opposites, one "yes" and one "no".
Such an experiment would be better conducted by making a post announcing it at the top and following with chunks of unlabelled human or AI text, like Scott Alexander did for art.
"What is the state and progress of your soul, and what is the path upon which your feet are set?" (X = alignment with yourself) I affected a quasi-religious vocabulary, but I think this has general application.
"What are you trying not to know, and why are you trying not to know it?" (X = self-deceptions)
I hope I am not de-enlightening anyone by these remarks!
I'm not just talking about your thoughts and feelings. When I say "everything in your consciousness", I mean [what you perceive as] the Sun, other people, mountains in the distance, the dirt on your floor, etc.
To me, the Sun etc. are out there. My perceptions of them are in here. As anyone with consciousness of abstraction knows at a gut level, the perception is not the thing that gave rise to that perception. My perceptions are a part of myself. The Sun is not.
Less easy to define what it does. I’ve read some of their writings and watched some of their videos, and am as much in the dark.
A quiz! (I am jokingly taking this in exactly the spirit you warned against.)
85% or more of your suffering falls away suddenly. It's been a year since then and it still hasn't come back. (This can happen more than once, with compounding effects.)
No, I've never had anything like this. My attitude is more, shit happens, I deal with it, and move on. (Because what's the alternative? Not dealing with it. Which never works.)
You no longer feel that your "self" is in a privileged position against the other stuff in your consciousness.
Does experiencing my "self" as including all that stuff count? I am guessing not. I have a strong sense of my own continuing presence.
You accidentally touch a hot stove and don't feel any pain. It's been months since your sensory inputs have congealed into pain.
Sounds dangerous. It was certainly painful when I closed a car door on my thumbnail a few months ago. (The new thumbnail may have grown back in another few months.)
Your conscious perception of time and space break down such that they are directly perceived as mental constructs rather than immutable aspects of external reality.
Way beyond me.
I seem to score a zero on this.
I'm sure I've notched up some 100s of hours of meditation, but spread over a rather large number of years, and rarely a daily practice.
I don't know what you mean by QRI. I don't think you're referring to the Qualia Research Institute.
I am. I group it with all that other stuff, but perhaps you wouldn't.
This surprised me, because there are 2+ thoroughly-awakened people in my social circle. And that's just in meatspace. Online, I've interacted with a couple others. Plus I met someone with Stream Entry at Less Online last year. That brings the total to a minimum of 5, but it's probably at least 7+.
How do you tell? How would I discern someone else's state of enlightenment? Or my own?
I am not asking out of scepticism. A problem I have understanding the whole meditation/enlightenment/jhanas/arahant/stream-entry/QRI/etc. collection of ideas is that despite trying, I have never been able to find myself on the maps of this territory that people present. I have experienced no unusual states of consciousness from the various suggested activities, and no intimations of being in the presence of someone who had something real to teach.
Yes, but that arguably means we only make decisions about which things to do now. Because we can't force our future selves to follow through, to inexorably carry out something
My left hand cannot force my right hand to do anything either. Instead, they work harmoniously together. Likewise my present, past, and future. Not only is the sage one with causation, he is one with himself.
Otherwise, always when we "decide" to definitely do an unpleasant task tomorrow rather than today ("I do the dishes tomorrow, I swear!"), we would then tomorrow in fact always follow through with it, which isn't at all the case.
That is an example of dysfunctional decision-making. It is possible to do better.
I always do the dishes today.
This seems like hyperbolic exhortation rather than simple description.
It is exhortation, certainly. It does not seem hyperbolic to me. It is making the same point that is illustrated by the multi-armed bandit problem: once you have determined which lever gives the maximum expected payout, the optimum strategy is to always pull that lever, and not to pull levers in proportion to how much they pay. Dithering never helps.
the ability to change one's plan when circumstances or knowledge changes is sometimes quite valuable.
Yes. But only as such changes come to be. Certainly not immediately on making the decision. "Commitment" is not quite the concept I'm getting at here. It's just that if I decided yesterday to do something today, then if nothing has changed I do that thing today. I don't redo the calculation, because I already know how it came out.