An Untrollable Mathematician Illustrated
post by abramdemski · 2018-03-20T00:00:00.000Z · LW · GW · 38 commentsContents
38 comments
The following was a presentation I made for Sören Elverlin's AI Safety Reading Group. I decided to draw everything by hand because powerpoint is boring. Thanks to Ben Pace for formatting it for LW! See also the IAF post detailing the research which this presentation is based on.























38 comments
Comments sorted by top scores.
comment by Qiaochu_Yuan · 2018-03-18T03:02:06.779Z · LW(p) · GW(p)
This is great. I consistently keep wanting to read the title as "Uncontrollable Mathematician," which I'm excited about as a band name.
Replies from: ryan_bcomment by nostalgebraist · 2018-11-04T18:06:45.975Z · LW(p) · GW(p)
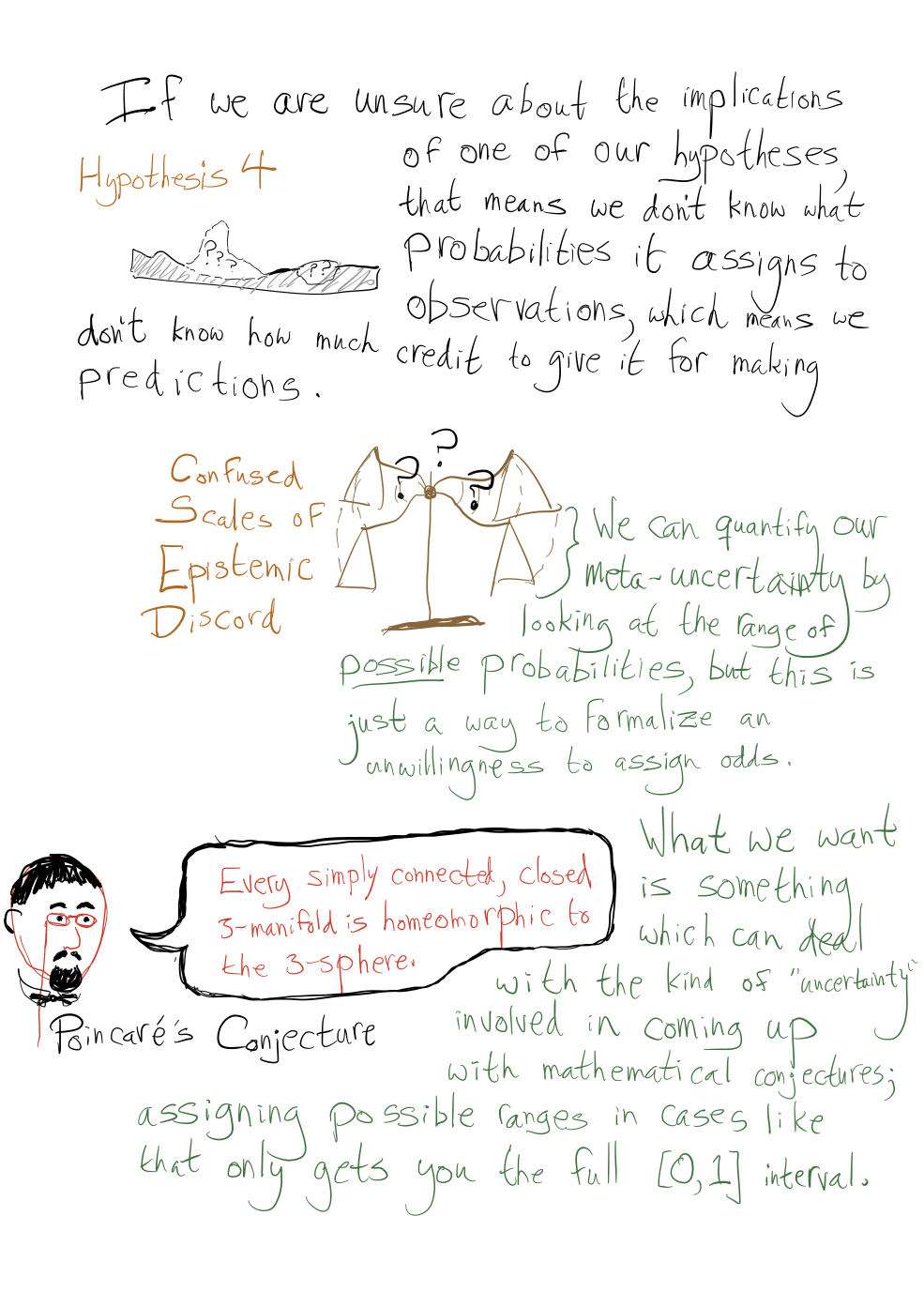
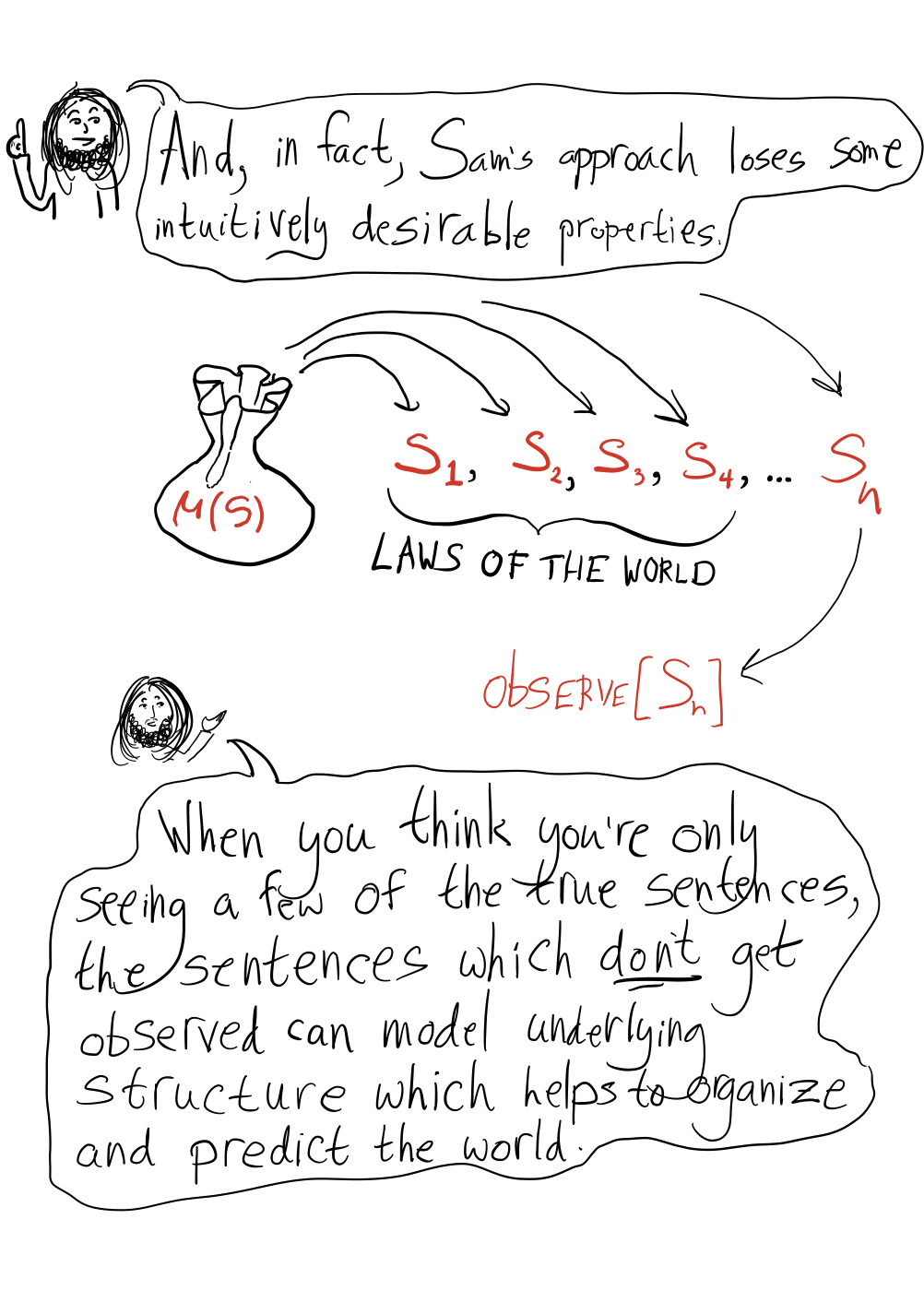
This prior isn’t trollable in the original sense, but it is trollable in a weaker sense that still strikes me as important. Since must sum to 1, only finitely many sentences can have for a given . So we can choose some finite set of “important sentences” and control their oscillations in a practical sense, but if there’s any such that we think oscillations across the range are a bad thing, all but finitely many sentences can exhibit this bad behavior.
It seems especially bad that we can only prevent “up-to- trolling” for finite sets of sentences, since in PA (or whatever) there are plenty of countable sets of sentences that seem “essentially the same” (like the ones you get from an induction argument), and it feels very unnatural to choose finite subsets of these and distinguish them from the others, even (or especially?) if we pretend we have no prior knowledge beyond the axioms.
comment by Hazard · 2018-03-16T22:38:13.933Z · LW(p) · GW(p)
This was incredibly enjoyable to read! I think you did a very good job of making it easy to read without dumbing it down. Though I'm not well versed in the core math of this post, I still feel like I managed to get some useful gist from it, and I also don't feel like I've been tricked into thinking I understand more than I do.
comment by habryka (habryka4) · 2019-11-29T20:53:02.046Z · LW(p) · GW(p)
I think this post, together with Abram's other post "Towards a new technical explanation" actually convinced me that a bayesian approach to epistemology can't work in an embedded context, which was a really big shift for me.
comment by TurnTrout · 2019-11-22T17:01:15.930Z · LW(p) · GW(p)
Abram's writing and illustrations often distill technical insights into accessible, fun adventures. I've come to appreciate the importance and value of this expository style more and more over the last year, and this post is what first put me on this track. While more rigorous communication certainly has its place, clearly communicating the key conceptual insights behind a piece of work makes those insights available to the entire community.
comment by Ben Pace (Benito) · 2018-03-16T21:38:04.253Z · LW(p) · GW(p)
(this is so awesome and it helps give me intuitions about Gödel's theorem and how mathematics happens and stuff)
I didn't parse the final sentence?
Logical induction (which is untrollable but not exactly a Bayesian probability distribution) is still the gold standard for logical uncertainty, but perhaps the number of desirable properties we can get by specifying simple sampling processes.
It feels like it should say 'but perhaps the number of desirable properties we can get by specifying simple sampling processes is X' but is missing the final clause, or something.
Edit: This has been fixed now :-)
Replies from: abramdemski↑ comment by abramdemski · 2018-03-16T21:42:46.307Z · LW(p) · GW(p)
Right, whoops.
It should have said "... by specifying simple sampling processes will increase as we push further in the direction Sam has opened up."
Replies from: DanielFilan↑ comment by DanielFilan · 2018-03-16T22:44:59.548Z · LW(p) · GW(p)
Further bug: I can now see both the old final image and the new final image.
Replies from: abramdemski↑ comment by abramdemski · 2018-03-16T22:47:07.789Z · LW(p) · GW(p)
Wow, that's weird, I **don't** see both when I try to edit the draft. Only in the non-editing view.
Replies from: habryka4, Benito↑ comment by habryka (habryka4) · 2018-03-16T23:19:31.820Z · LW(p) · GW(p)
Sorry for that, fixed it!
↑ comment by Ben Pace (Benito) · 2018-03-16T23:13:48.190Z · LW(p) · GW(p)
Wow. Oli's on it.
comment by Ben Pace (Benito) · 2018-03-31T23:59:59.993Z · LW(p) · GW(p)
I curated this post because:
- The explanation itself was very clear - a serious effort had been made to explain this work and related ideas.
- In the course of explaining a single result, it helps give strong intuitions about a wide variety of related areas in math and logic, which are very important for alignment research.
- It was really fun to read; the drawings are very beautiful.
Biggest hesitations I had with curating:
- It wasn't clear to me that the main argument the post makes regarding the untrollable mathematicians is itself a huge result in agent foundations research.
This wasn't a big factor for me though, as just making transparent all of the mental moves in achieving this result helps the reader with seeing / learning the mental models used throughout this research area.
comment by Jameson Quinn (jameson-quinn) · 2020-01-10T23:23:35.466Z · LW(p) · GW(p)
This is truly one of the best posts I've read. It guides the reader through a complex argument in a way that's engaging and inspiring. Great job.
comment by hwold · 2018-04-13T07:49:51.076Z · LW(p) · GW(p)
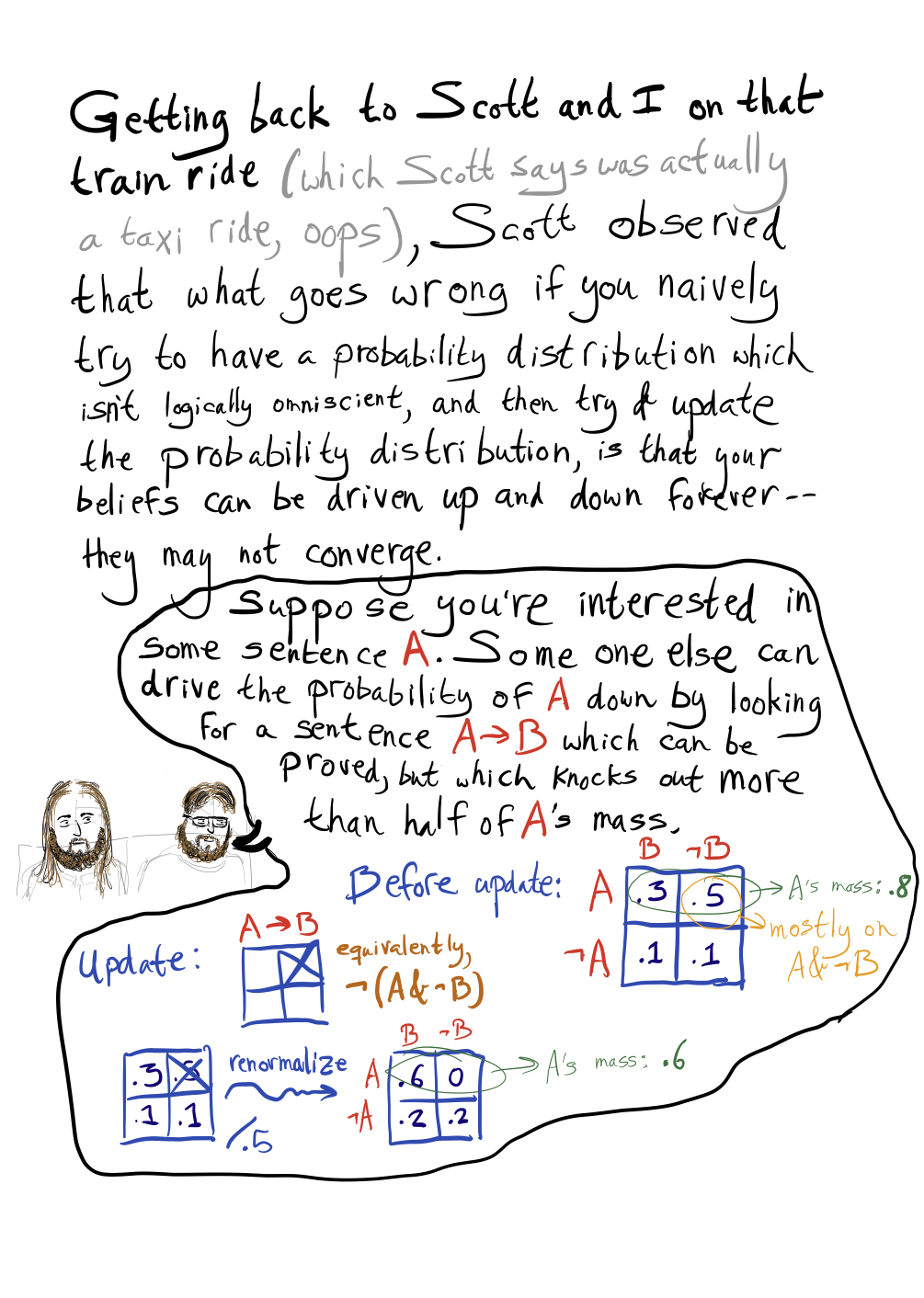
I don’t understand where that 1/2 comes from. Unless I have made a gross mistake P(A|A => B) < P(A) even if P(A&B) > P(A¬(B)). In your first example, if I swap P(AB) and P(A¬(B)) so that P(AB) = .5 and P(A¬(B))=.3 then P(A|A=>B) = .5/.7 ~ 0.71 < 0.8 = P(A).
Replies from: Chris_Leong↑ comment by Chris_Leong · 2018-12-14T22:50:55.649Z · LW(p) · GW(p)
This confused me as well. This being true ensures that the ratio P(A):P(not A) doubles at each step. But part of this comic seems to imply that being less than a half stops the trolling, when it should only stop the trolling from proceeding at such a fast-paced rate.
comment by rk · 2018-03-29T12:45:31.901Z · LW(p) · GW(p)
I want to echo the other comments thanking you for making this lay-approachable and for the fun format!
I do find myself confused by some of the statements though. It may be that I have a root misunderstanding or that I am misreading some of the more quickly stated sentences.
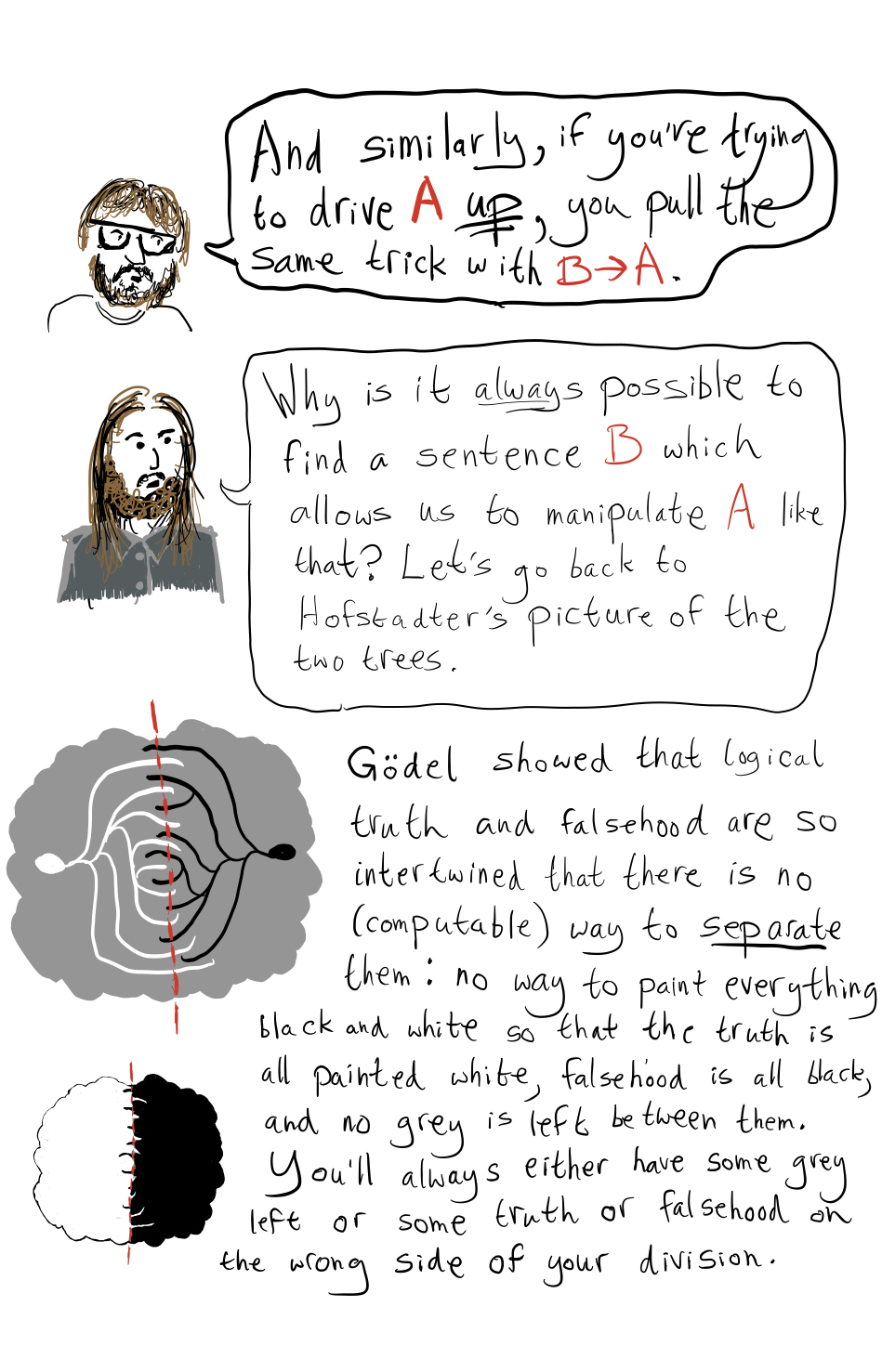
For example, when you talk about the trees of truth & falsehood and the gap in the middle: am I right in thinking of these trees as provability and non-provability? Rather than perhaps truth & falsehood
Also, in the existence proof for Bs such that and we can prove , you say that if B is a logical truth, A -> B must be provable, because anything implies a logical truth. It seems right to me that anything logically implies a logical truth. But surely we can't prove all logical truths from anything -- what if it's a truth in the grey area such that it can't be proved at all?
If someone can put me right, that would be great
Replies from: Dacyn↑ comment by Dacyn · 2018-04-02T15:18:07.429Z · LW(p) · GW(p)
Yes you are right that the first tree is provability, but I think the second tree is meant to be disprovability rather than non-provability. Similarly, when the OP later talks about "logical truths" and "logical falsehoods" it seems he really means "provable statements" and "disprovable statements" -- this should resolve the issue in your last paragraph, since if B is provable then so is A->B.
Replies from: rk↑ comment by rk · 2018-04-02T16:40:13.040Z · LW(p) · GW(p)
disprovability rather than non-provability
Yeah, you're definitely right there. Oops, me.
Similarly, when the OP later talks about "logical truths" and "logical falsehoods" it seems he really means "provable statements" and "disprovable statements" -- this should resolve the issue in your last paragraph, since if B is provable then so is A->B
If that's the case, then how does Goedel kick in? He then says, nothing can separate logical truth from logical falsehood. But if he means provability and disprovability, then trivially they can be separated
Replies from: Dacyn↑ comment by Dacyn · 2018-04-02T21:23:42.997Z · LW(p) · GW(p)
Here "separation" would mean that there is an algorithm which inputs any statement and outputs either "yes" or "no", such that the algorithm returns "yes" on all inputs that are provable statements and "no" on all inputs that are disprovable statements. But the algorithm also has to halt on all possible inputs, not just the ones that are provable or disprovable. Such a separation algorithm cannot exist (I am not sure if this follows from Gödel's theorem or requires a separate diagonalization argument). This is the result needed in that step of the argument.
Replies from: rkcomment by cousin_it · 2018-03-19T08:29:41.694Z · LW(p) · GW(p)
Great explanation! I read your earlier post on IAFF where the whole thing was explained in one sentence, and it was quite clear, but seeing it in pictures is much more fun. Maybe this is also why the Sequences were fun to read - they explained simple ideas but in a very fancy cursive font :-)
comment by Connor_Flexman · 2018-03-21T00:50:22.342Z · LW(p) · GW(p)
I am confused as to how the propositional consistency and function work together to prevent the trolling in the final step. Suppose I do try to find pairs of sentences such that I can show and also to drive down. Does this fail because you are postulating non-adversarial sampling, as ESRogs mentions? Or is there some other reason why propositional consistency is important here?
Replies from: Diffractor↑ comment by Diffractor · 2018-03-22T01:03:12.216Z · LW(p) · GW(p)
There's a misconception, it isn't about finding sentences of the form and , because if you do that, it immediately disproves . It's actually about merely finding many instances of where has probability, and this lowers the probability of . This is kind of like how finding out about the Banach-Tarski paradox (something you assign low probability to) may lower your degree of belief in the axiom of choice.
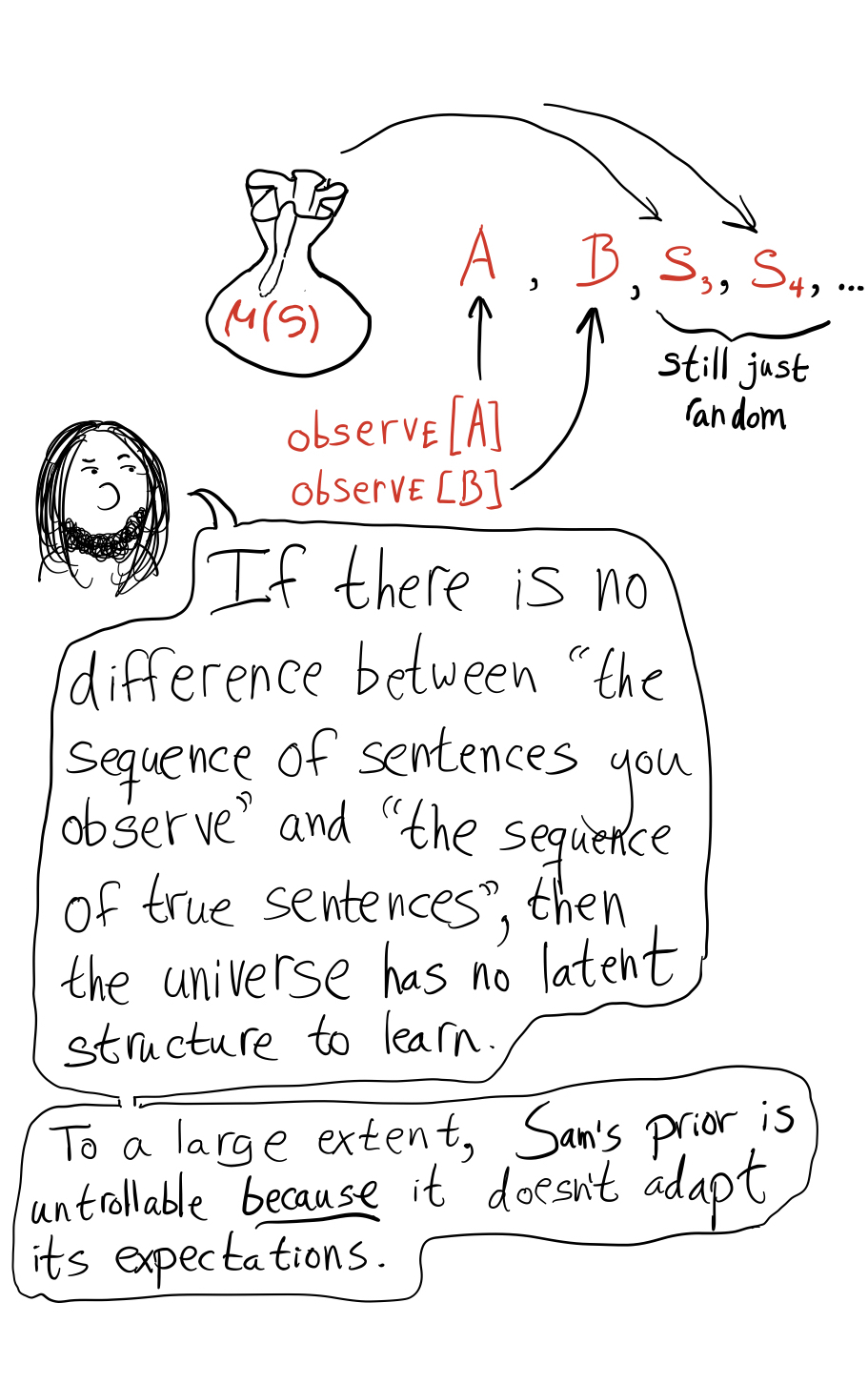
The particular thing that prevents trolling is that in this distribution, there's a fixed probability of drawing on the next round no matter how many implications and 's you've found so far. So the way it evades trolling is a bit cheaty, in a certain sense, because it believes that the sequence of truth or falsity of math sentences that it sees is drawn from a certain fixed distribution, and doesn't do anything like believing that it's more likely to see a certain class of sentences come up soon.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2018-03-22T01:10:11.349Z · LW(p) · GW(p)
(I fixed your LaTex. FYI whatever your comment looks like before you post, is what it will look like after. Use ctrl-4 or cmd-4 for LaTex, depending on whether you're using a PC or a Mac.)
comment by ESRogs · 2018-03-18T21:36:55.742Z · LW(p) · GW(p)
Propositional consistency lets us express constraints between sentences (such as " and cannot both be true") as sentences (such as "") in a way the prior understands and correctly enforces.
Any branch contradicting an already-stated constraint is clipped off the tree of possible sequences of sentences.
The probability of any sentence which is consistent with everything seen so far can't go below or above , since or can be drawn next. So, no trolling.
How do I know whether is consistent with everything seen so far. Doesn't that presuppose logical omniscience?
Or does consistency here only mean that it doesn't violate any explicitly stated constraints (such that I don't have to know all the implications of all the sentences I've seen so far and whether they contradict )?
Replies from: Diffractor↑ comment by Diffractor · 2018-03-22T00:52:39.221Z · LW(p) · GW(p)
There's a difference between "consistency" (it is impossible to derive X and notX for any sentence X, this requires a halting oracle to test, because there's always more proof paths), and "propositional consistency", which merely requires that there are no contradictions discoverable by boolean algebra only. So A^B is propositionally inconsistent with notA, and propositionally consistent with A. If there's some clever way to prove that B implies notA, it wouldn't affect the propositional consistency of them at all. Propositional consistency of a set of sentences can be verified in exponential time.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2018-12-14T22:55:27.726Z · LW(p) · GW(p)
Since propositional consistency is weaker than consistency our prior may distribute some probability to cases that are contradictory. I guess that's considered acceptable because the aim is to make the prior non-trollable, rather than good.
comment by cata · 2018-03-20T21:14:57.846Z · LW(p) · GW(p)
Thank you for making this! The format held my attention well, so I understood a lot whereas I might have zoned out and left if the same material had been presented more traditionally. I'm going to print it out and distribute it at work -- people like zines there.
comment by Dacyn · 2018-04-02T15:24:01.790Z · LW(p) · GW(p)
Maybe I am not sure why this mathematician is considered to be untrollable? It seems the same or a similar algorithm could drive his probabilities up and down arbitrarily within the interval . If this is true, then his beliefs at any stage are essentially arbitrary with respect to this restriction. But isn't that basically the same as saying that if the statement hasn't been proven or disproven yet, then his beliefs don't give any meaningful (non-trollable) further information as to whether the statement is true?
Replies from: Diffractor↑ comment by Diffractor · 2018-04-02T17:46:27.954Z · LW(p) · GW(p)
The beliefs aren't arbitrary, they're still reasoning according to a probability distribution over propositionally consistent "worlds". Furthermore, the beliefs converge to a single number in the limit of updating on theorems, even if the sentence of interest is unprovable. Consider some large but finite set S of sentences that haven't been proved yet, such that the probability of sampling a sentence in that set before sampling the sentence of interest "x", is very close to 1. Then pick a time N, that is large enough that by that time, all the logical relations between the sentences in S will have been found. Then, with probability very close to 1, either "x" or "notx" will be sampled without going outside of S.
So, if there's some cool new theorem that shows up relating "x" and some sentence outside of S, like "y->x", well, you're almost certain to hit either "x" or "notx" before hitting "y", because "y" is outside S, so this hot new theorem won't affect the probabilities by more than a negligible amount.
Also I figured out how to generalize the prior a bit to take into account arbitrary constraints other than propositional consistency, though there's still kinks to iron out in that one. Check this.
comment by ESRogs · 2018-03-18T21:24:50.907Z · LW(p) · GW(p)
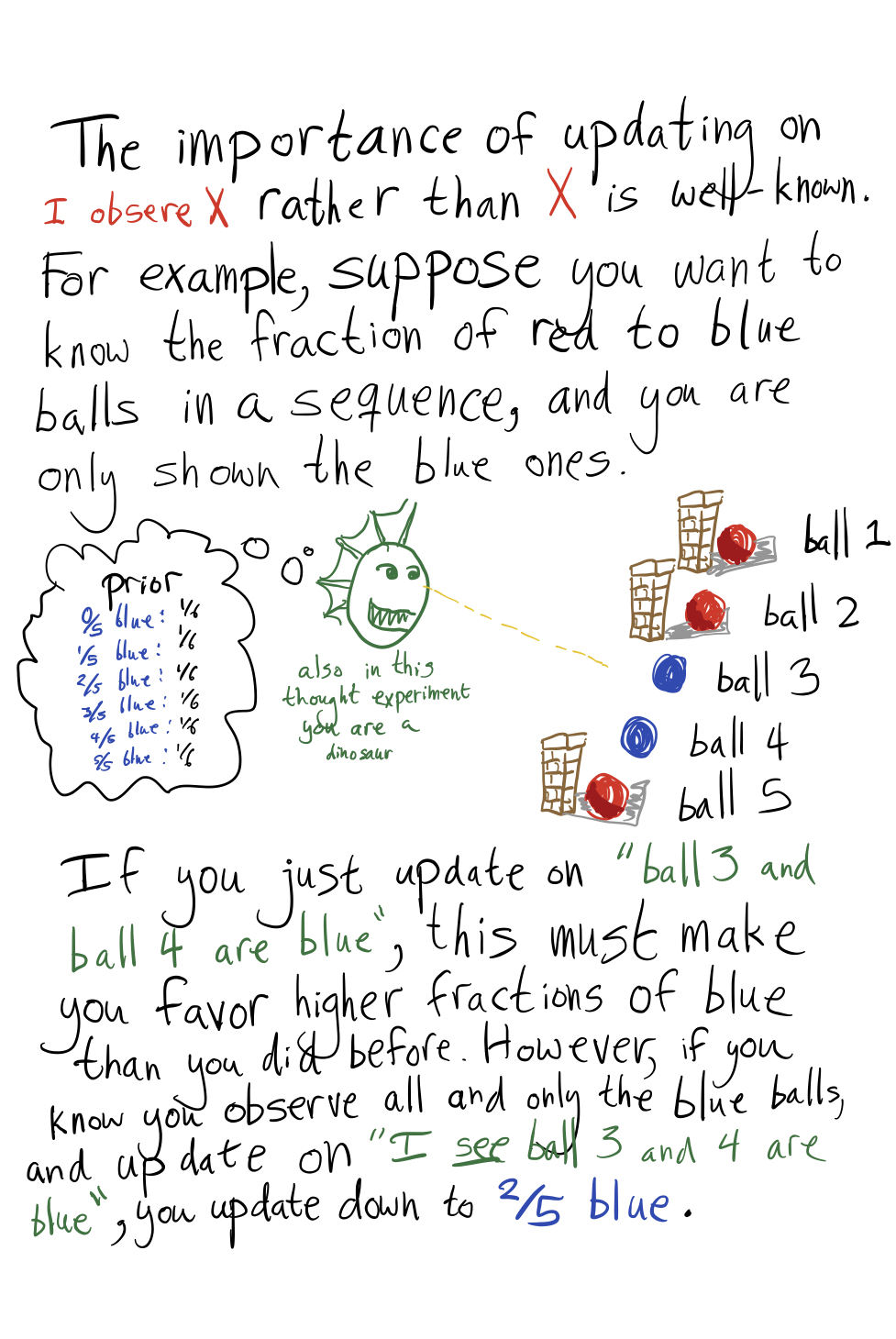
Suppose nature is showing you true sentences one at a time. Model them as drawn randomly from a fixed distribution , but enforcing propositional consistency.
Does this mean nature has to in fact be showing me sentences sampled from this fixed distribution, or am I just pretending that that's what it's doing when I update my prior?
Does this work when sentences are shown to me in an adversarial order?
Replies from: Diffractor↑ comment by Diffractor · 2018-03-22T01:06:55.414Z · LW(p) · GW(p)
You're pretending that it's what nature is doing what you update your prior. It works when sentences are shown to you in an adversarial order, but there's the weird aspect that this prior expects the sentences to go back to being drawn from some fixed distribution afterwards. It doesn't do a thing where it goes "ah, I'm seeing a bunch of blue blocks selectively revealed, even though I think there's a bunch of red blocks, the next block I'll have revealed will probably be blue". Instead, it just sticks with its prior on red and blue blocks.
comment by jimrandomh · 2018-05-09T19:33:25.378Z · LW(p) · GW(p)
Many (though not all) of the images are broken links right now. Could we get them re-uploaded somewhere else?
Replies from: Benito↑ comment by Ben Pace (Benito) · 2018-05-10T13:02:15.605Z · LW(p) · GW(p)
I just tried to fix that, and also the spacing issues. Let me know if it's still broken.
comment by romeostevensit · 2018-04-01T17:17:30.513Z · LW(p) · GW(p)
Has trolling people into providing untrollable models been reused? Seems worth trying.