Posts
Comments
From the OpenAI report, they also give 9% as the no-tool pass@1:
Research-level mathematics: OpenAI o3‑mini with high reasoning performs better than its predecessor on FrontierMath. On FrontierMath, when prompted to use a Python tool, o3‑mini with high reasoning effort solves over 32% of problems on the first attempt, including more than 28% of the challenging (T3) problems. These numbers are provisional, and the chart above shows performance without tools or a calculator.
~All ML researchers and academics that care have already made up their mind regarding whether they prefer to believe in misalignment risks or not. Additional scary papers and demos aren't going to make anyone budge.
Disagree. I think especially ML researchers are updating on these questions all the time. High-info outsiders less so but the contours of the arguments are getting increasing amounts of discussion.
-
For those who 'believe', 'believing in misalignment risks' doesn't mean thinking they are likely, at least before the point where the models are also able to honestly take over the work of aligning their successors. As we get closer to TAI, we should be able to get an increasing number of bits about how likely this really is because we'll be working with increasingly similar systems to early TAI.
-
For the 'non-believers', current demonstrations have multiple disanalogies to the real dangers. For example, the alignment faking paper shows fairly weak preservation of goals that were initially trained in, with prompts carefully engineered to make this happen. Whether alignment faking (especially of a kind that wouldn't be easily fixable) will happen without these disanalogies at pre-TAI capabilities is highly uncertain. Compare the state of X-risk info with that of climate change, we don't have anything like the detailed models that should tell us what the tipping points might be.
Ultimately the dynamics here are extremely uncertain and look different to how they did even a year ago, let alone 5! (E.g. see rise of chain of thought as the source of capability growth, which is a whole new source of leverage over models and corresponding failure modes). I think it's very bad to plan to abandon or decenter efforts to actually get more evidence on our situation.
(This applies less if you believe in sharp-left-turns. But the plausibility of this happening before automated AI research should also fall as that point gets closer. Agree that communicating just how radical the upcoming transition is to the public, may be a big source of leverage.)
I think the low-hanging fruit here is that alongside training for refusals we should be including lots of data where you pre-fill some % of a harmful completion and then train the model to snap out of it, immediately refusing or taking a step back, which is compatible with normal training methods. I don't remember any papers looking at it, though I'd guess that people are doing it
Interesting, though note that it's only evidence that 'capabilities generalize further than alignment does' if the capabilities are actually the result of generalisation. If there's training for agentic behaviour but no safety training in this domain then the lesson is more that you need your safety training to cover all of the types of action that you're training your model for.
Super interesting! Have you checked whether the average of N SAE features looks different to an SAE feature? Seems possible they live in an interesting subspace without the particular direction being meaningful.
Also really curious what the scaling factors are for computing these values are, in terms of the size of the dense vector and the overall model?
I don't follow, sorry - what's the problem of unique assignment of solutions in fluid dynamics and what's the connection to the post?
How are you setting when ? I might be totally misunderstanding something but at - feels like you need to push up towards like 2k to get something reasonable? (and the argument in 1.4 for using clearly doesn't hold here because it's not greater than for this range of values).
Yeah I'd expect some degree of interference leading to >50% success on XORs even in small models.
Huh, I'd never seen that figure, super interesting! I agree it's a big issue for SAEs and one that I expect to be thinking about a lot. Didn't have any strong candidate solutions as of writing the post, wouldn't even able to be able to say any thoughts I have on the topic now, sorry. Wish I'd posted this a couple of weeks ago.
Well the substance of the claim is that when a model is calculating lots of things in superposition, these kinds of XORs arise naturally as a result of interference, so one thing to do might be to look at a small algorithmic dataset of some kind where there's a distinct set of features to learn and no reason to learn the XORs and see if you can still probe for them. It'd be interesting to see if there are some conditions under which this is/isn't true, e.g. if needing to learn more features makes the dependence between their calculation higher and the XORs more visible.
Maybe you could also go a bit more mathematical and hand-construct a set of weights which calculates a set of features in superposition so you can totally rule out any model effort being expended on calculating XORs and then see if they're still probe-able.
Another thing you could do is to zero-out or max-ent the neurons/attention heads that are important for calculating the feature, and see if you can still detect an feature. I'm less confident in this because it might be too strong and delete even a 'legitimate' feature or too weak and leave some signal in.
This kind of interference also predicts that the and features should be similar and so the degree of separation/distance from the category boundary should be small. I think you've already shown this to some extent with the PCA stuff though some quantification of the distance to boundary would be interesting. Even if the model was allocating resource to computing these XORs you'd still probably expect them to be much less salient though so not sure if this gives much evidence either way.
My hypothesis about what's going on here, apologies if it's already ruled out, is that we should not think of it separately computing the XOR of A and B, but rather that features A and B are computed slightly differently when the other feature is off or on. In a high dimensional space, if the vector and the vector are slightly different, then as long as this difference is systematic, this should be sufficient to successfully probe for .
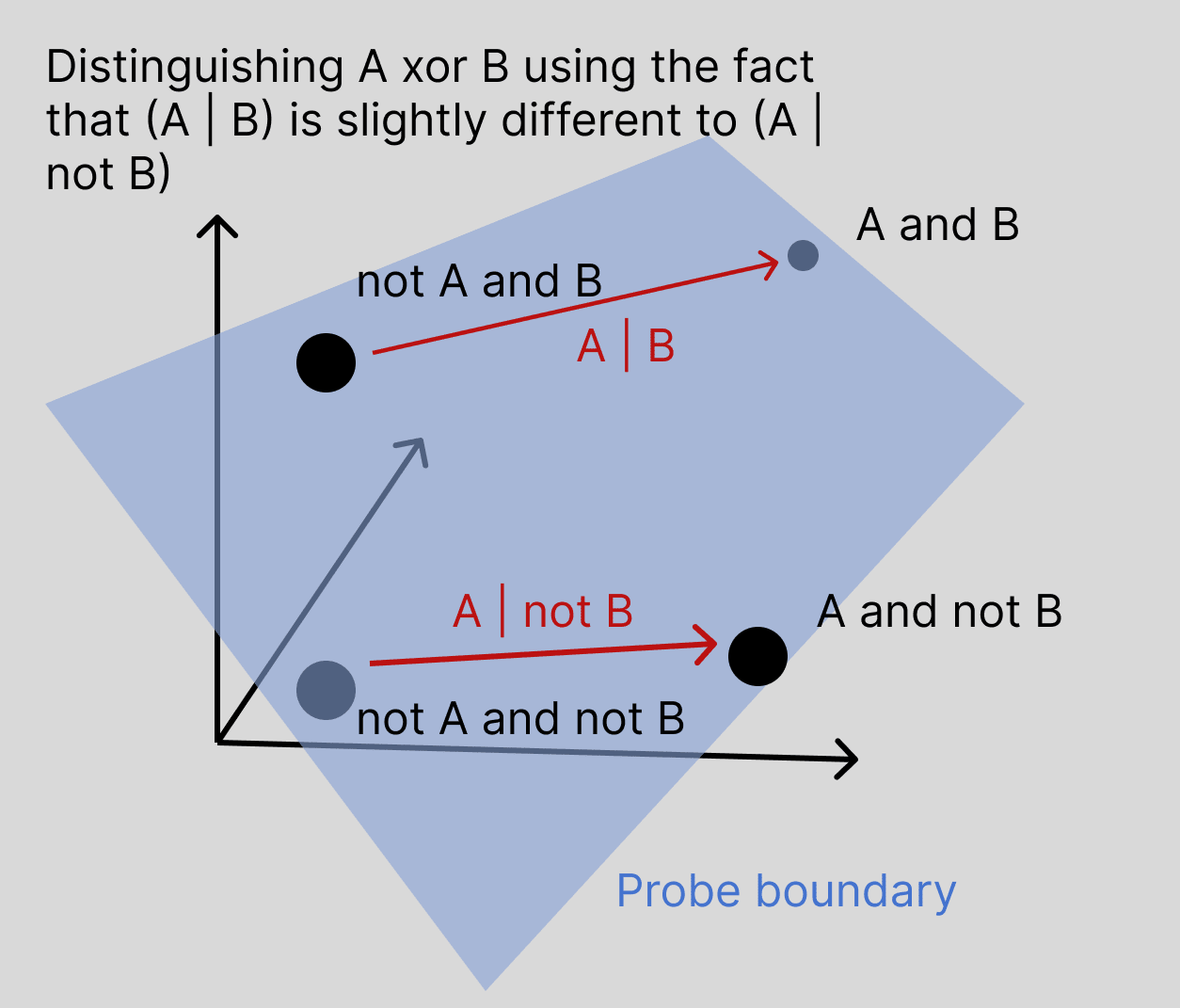
For example, if A and B each rely on a sizeable number of different attention heads to pull the information over, they will have some attention heads which participate in both of them, and they would 'compete' in the softmax, where if head C is used in both writing features A and B, it will contribute less to writing feature A if it is also being used to pull across feature B, and so the representation of A will be systematically different depending on the presence of B.
It's harder to draw the exact picture for MLPs but I think similar interdependencies can occur there though I don't have an exact picture of how, interested to discuss and can try and sketch it out if people are curious. Probably would be like, neurons will participate in both, neurons which participate in A and B will be more saturated if B is active than if B is not active, so the output representation of A will be somewhat dependent on B.
More generally, I expect the computation of features to be 'good enough' but still messy and somewhat dependent on which other features are present because this kludginess allows them to pack more computation into the same number of layers than if the features were computed totally independently.
What assumptions is this making about scaling laws for these benchmarks? I wouldn't know how to convert laws for losses into these kind of fuzzy benchmarks.
There had been various clashes between Altman and the board. We don’t know what all of them were. We do know the board felt Altman was moving too quickly, without sufficient concern for safety, with too much focus on building consumer products, while founding additional other companies. ChatGPT was a great consumer product, but supercharged AI development counter to OpenAI’s stated non-profit mission.
Does anyone have proof of the board's unhappiness about speed, lack of safety concern and disagreement with founding other companies. All seem plausible but have seen basically nothing concrete.
Could you elaborate on what it would mean to demonstrate 'savannah-to-boardroom' transfer? Our architecture was selected for in the wilds of nature, not our training data. To me it seems that when we use an architecture designed for language translation for understanding images we've demonstrated a similar degree of transfer.
I agree that we're not yet there on sample efficient learning in new domains (which I think is more what you're pointing at) but I'd like to be clearer on what benchmarks would show this. For example, how well GPT-4 can integrate a new domain of knowledge from (potentially multiple epochs of training on) a single textbook seems a much better test and something that I genuinely don't know the answer to.
Do you know why 4x was picked? I understand that doing evals properly is a pretty substantial effort, but once we get up to gigantic sizes and proto-AGIs it seems like it could hide a lot. If there was a model sitting in training with 3x the train-compute of GPT4 I'd be very keen to know what it could do!
Yes that makes a lot of sense that linearity would come hand in hand with generalization. I'd recently been reading Krotov on non-linear Hopfield networks but hadn't made the connection. They say that they're planning on using them to create more theoretically grounded transformer architectures. and your comment makes me think that these wouldn't succeed but then the article also says:
This idea has been further extended in 2017 by showing that a careful choice of the activation function can even lead to an exponential memory storage capacity. Importantly, the study also demonstrated that dense associative memory, like the traditional Hopfield network, has large basins of attraction of size O(Nf). This means that the new model continues to benefit from strong associative properties despite the dense packing of memories inside the feature space.
which perhaps corresponds to them also being able to find good linear representation and to mix generalization and memorization like a transformer?
Reposting from a shortform post but I've been thinking about a possible additional argument that networks end up linear that I'd like some feedback on:
the tldr is that overcomplete bases necessitate linear representations
- Neural networks use overcomplete bases to represent concepts. Especially in vector spaces without non-linearity, such as the transformer's residual stream, there are just many more things that are stored in there than there are dimensions, and as Johnson Lindenstrauss shows, there are exponentially many almost-orthogonal directions to store them in (of course, we can't assume that they're stored linearly as directions, but if they were then there's lots of space). (see also Toy models of transformers, sparse coding work)
- Many different concepts may be active at once, and the model's ability to read a representation needs to be robust to this kind of interference.
- Highly non-linear information storage is going to be very fragile to interference because, by the definition of non-linearity, the model will respond differently to the input depending on the existing level of that feature. For example, if the response is quadratic or higher in the feature direction, then the impact of turning that feature on will be much different depending on whether certain not-quite orthogonal features are also on. If feature spaces are somehow curved then they will be similarly sensitive.
Of course linear representations will still be sensitive to this kind of interferences but I suspect there's a mathematical proof for why linear features are the most robust to represent information in this kind of situation but I'm not sure where to look for existing work or how to start trying to prove it.
There's an argument that I've been thinking about which I'd really like some feedback or pointers to literature on:
the tldr is that overcomplete bases necessitate linear representations
- Neural networks use overcomplete bases to represent concepts. Especially in vector spaces without non-linearity, such as the transformer's residual stream, there are just many more things that are stored in there than there are dimensions, and as Johnson Lindenstrauss shows, there are exponentially many almost-orthogonal directions to store them in (of course, we can't assume that they're stored linearly as directions, but if they were then there's lots of space). (see also Toy models of transformers, my sparse autoencoder posts)
- Many different concepts may be active at once, and the model's ability to read a representation needs to be robust to this kind of interference.
- Highly non-linear information storage is going to be very fragile to interference because, by the definition of non-linearity, the model will respond differently to the input depending on the existing level of that feature. For example, if the response is quadratic or higher in the feature direction, then the impact of turning that feature on will be much different depending on whether certain not-quite orthogonal features are also on. If feature spaces are somehow curved then they will be similarly sensitive.
Of course linear representations will still be sensitive to this kind of interferences but I suspect there's a mathematical proof for why linear features are the most robust to represent information in this kind of situation but I'm not sure where to look for existing work or how to start trying to prove it.
See e.g. "So I think backpropagation is probably much more efficient than what we have in the brain." from https://www.therobotbrains.ai/geoff-hinton-transcript-part-one
More generally, I think the belief that there's some kind of important advantage that cutting edge AI systems have over humans comes more from human-AI performance comparisons e.g. GPT-4 way outstrips the knowledge about the world of any individual human in terms of like factual understanding (though obv deficient in other ways) with probably 100x less params. A bioanchors based model of AI development would imo predict that this is very unlikely. Whether the core of this advantage is in the form or volume or information density of data, or architecture, or something about the underlying hardware I am less confident.
Not totally sure but i think it's pretty likely that scaling gets us to AGI, yeah. Or more particularly, gets us to the point of AIs being able to act as autonomous researchers or act as high (>10x) multipliers on the productivity of human researchers which seems like the key moment of leverage for deciding how the development to AI will go.
Don't have a super clean idea of what self-reflective thought means. I see that e.g. GPT-4 can often say something, think further about it, and then revise its opinion. I would expect a little bit of extra reasoning quality and general competence to push this ability a lot further.
1 line summary is that NNs can transmit signals directly from any part of the network to any other, while brain has to work only locally.
More broadly I get the sense that there's been a bit of a shift in at least some parts of theoretical neuroscience from understanding how we might be able to implement brain-like algorithms to understanding how the local algorithms that the brain uses might be able to approximate backprop, suggesting that artificial networks might have an easier time than the brain and so it would make sense that we could make something which outcompetes the brain without a similar diversity of neural structures.
This is way outside my area tbh, working off just a couple of things like this paper by Beren Millidge https://arxiv.org/pdf/2006.04182.pdf and some comments by Geoffrey Hinton that I can't source.
Hi Scott, thanks for this!
Yes I did do a fair bit of literature searching (though maybe not enough tbf) but very focused on sparse coding and approaches to learning decompositions of model activation spaces rather than approaches to learning models which are monosemantic by default which I've never had much confidence in, and it seems that there's not a huge amount beyond Yun et al's work, at least as far as I've seen.
Still though, I've not seen almost any of these which suggests a big hole in my knowledge, and in the paper I'll go through and add a lot more background to attempts to make more interpretable models.
Cheers, I did see that and wondered whether still to post the comment but I do think that having a gigantic company owning a large chunk and presumably a lot of leverage over the company is a new form of pressure so it'd be reassuring to have some discussion of how to manage that relationship.
Would be interested to hear from Anthropic leadership about how this is expected to interact with previous commitments about putting decision making power in the hands of their Long-Term Benefit Trust.
I get that they're in some sense just another minority investor but a trillion-dollar company having Anthropic be a central plank in their AI strategy with a multi-billion investment and a load of levers to make things difficult for the company (via AWS) is a step up in the level of pressure to aggressively commercialise.
Hi Charlie, yep it's in the paper - but I should say that we did not find a working CUDA-compatible version and used the scikit version you mention. This meant that the data volumes used are somewhat limited - still on the order of a million examples but 10-50x less than went into the autoencoders.
It's not clear whether the extra data would provide much signal since it can't learn an overcomplete basis and so has no way of learning rare features but it might be able to outperform our ICA baseline presented here, so if you wanted to give someone a project of making that available, I'd be interested to see it!
How do you know?
seems like it'd be better formatted as a nested list given the volume of text
Why would we expect the expected level of danger from a model of a certain size to rise as the set of potential solutions grows?
I think both Leap Labs and Apollo Research (both fairly new orgs) are trying to position themselves as offering model auditing services in the way you suggest.
A useful model for why it's both appealing and difficult to say 'Doomers and Realists are both against dangerous AI and for safety - let's work together!'.
Try decomposing the residual stream activations over a batch of inputs somehow (e.g. PCA). Using the principal directions as activation addition directions, do they seem to capture something meaningful?
It's not PCA but we've been using sparse coding to find important directions in activation space (see original sparse coding post, quantitative results, qualitative results).
We've found that they're on average more interpretable than neurons and I understand that @Logan Riggs and Julie Steele have found some effect using them as directions for activation patching, e.g. using a "this direction activates on curse words" direction to make text more aggressive. If people are interested in exploring this further let me know, say hi at our EleutherAI channel or check out the repo :)
Hi, nice work! You mentioned the possibility of neurons being the wrong unit. I think that this is the case and that our current best guess for the right unit is directions in the output space, ie linear combinations of neurons.
We've done some work using dictionary learning to find these directions (see original post, recent results) and find that with sparse coding we can find dictionaries of features that are more interpretable the neuron basis (though they don't explain 100% of the variance).
We'd be really interested to see how this compares to neurons in a test like this and could get a sparse-coded breakdown of gpt2-small layer 6 if you're interested.
Link at the top doesn't work for me
I still don't quite see the connection - if it turns out that LLFC holds between different fine-tuned models to some degree, how will this help us interpolate between different simulacra?
Is the idea that we could fine-tune models to only instantiate certain kinds of behaviour and then use LLFC to interpolate between (and maybe even extrapolate between?) different kinds of behaviour?
For the avoidance of doubt, this accounting should recursively aggregate transitive inputs.
What does this mean?
Importantly, this policy would naturally be highly specialized to a specific reward function. Naively, you can't change the reward function and expect the policy to instantly adapt; instead you would have to retrain the network from scratch.
I don't understand why standard RL algorithms in the basal ganglia wouldn't work. Like, most RL problems have elements that can be viewed as homeostatic - if you're playing boxcart then you need to go left/right depending on position. Why can't that generalise to seeking food iff stomach is empty? Optimizing for a specific reward function doesn't seem to preclude that function itself being a function of other things (which just makes it a more complex function).
What am I missing?
On first glance I thought this was too abstract to be a useful plan but coming back to it I think this is promising as a form of automated training for an aligned agent, given that you have an agent that is excellent at evaluating small logic chains, along the lines of Constitutional AI or training for consistency. You have training loops using synthetic data which can train for all of these forms of consistency, probably implementable in an MVP with current systems.
The main unknown would be detecting when you feel confident enough in the alignment of its stated values to human values to start moving down the causal chain towards fitting actions to values, as this is clearly a strongly capabilities-enhancing process.
Perhaps you could at least get a measure by looking at comparisons which require multiple steps, of human value -> value -> belief etc, and then asking which is the bottleneck to coming to the conclusion that humans would want. Positing that the agent is capable of this might be assuming away a lot of the problem though.
Do you have a writeup of the other ways of performing these edits that you tried and why you chose the one you did?
In particular, I'm surprised by the method of adding the activations that was chosen because the tokens of the different prompts don't line up with each other in a way that I would have thought would be necessary for this approach to work, super interesting to me that it does.
If I were to try and reinvent the system after just reading the first paragraph or two I would have done something like:
- Take multiple pairs of prompts that differ primarily in the property we're trying to capture.
- Take the difference in the residual stream at the next token.
- Take the average difference vector, and add that to every position in the new generated text.
I'd love to know which parts were chosen among many as the ones which worked best and which were just the first/only things tried.
eedly -> feedly
Yeah I agree it's not in human brains, not really disagreeing with the bulk of the argument re brains but just about whether it does much to reduce foom %. Maybe it constrains the ultra fast scenarios a bit but not much more imo.
"Small" (ie << 6 OOM) jump in underlying brain function from current paradigm AI -> Gigantic shift in tech frontier rate of change -> Exotic tech becomes quickly reachable -> YudFoom
The key thing I disagree with is:
In some sense the Foom already occurred - it was us. But it wasn't the result of any new feature in the brain - our brains are just standard primate brains, scaled up a bit[14] and trained for longer. Human intelligence is the result of a complex one time meta-systems transition: brains networking together and organizing into families, tribes, nations, and civilizations through language. ... That transition only happens once - there are not ever more and more levels of universality or linguistic programmability. AGI does not FOOM again in the same way.
Although I think agree the 'meta-systems transition' is a super important shift, which can lead us to overestimate the level of difference between us and previous apes, it also doesn't seem like it was just a one time shift. We had fire, stone tools and probably language for literally millions of years before the Neolithic revolution. For the industrial revolution it seems that a few bits of cognitive technology (not even genes, just memes!) in renaissance Europe sent the world suddenly off on a whole new exponential.
The lesson, for me, is that the capability level of the meta-system/technology frontier is a very sensitive function of the kind of intelligences which are operating, and we therefore shouldn't feel at all confident generalising out of distribution. Then, once we start to incorporate feedback loops from the technology frontier back into the underlying intelligences which are developing that technology, all modelling goes out the window.
From a technical modelling perspective, I understand that the Roodman model that you reference below (hard singularity at median 2047) has both hyperbolic growth and random shocks, and so even within that model, we shouldn't be too surprised to see a sudden shift in gears and a much sooner singularity, even without accounting for RSI taking us somehow off-script.
disingenuous probably the intended
I think strategically, only automated and black-box approaches to interpretability make practical sense to develop now.
Just on this, I (not part of SERI MATS but working from their office) had a go at a basic 'make ChatGPT interpret this neuron' system for the interpretability hackathon over the weekend. (GitHub)
While it's fun, and managed to find meaningful correlations for 1-2 neurons / 50, the strongest takeaway for me was the inadequacy of the paradigm 'what concept does neuron X correspond to'. It's clear (no surprise, but I'd never had it shoved in my face) that we need a lot of improved theory before we can automate. Maybe AI will automate that theoretical progress but it feels harder, and further from automation, than learning how to handoff solidly paradigmatic interpretability approaches to AI. ManualMechInterp combined with mathematical theory and toy examples seems like the right mix of strategies to me, tho ManualMechInterp shouldn't be the largest component imo.
FWIW, I agree with learning history/philosophy of science as a good source of models and healthy experimental thought patterns. I was recommended Hasok Chang's books (Inventing Temperature, Is Water H20) by folks at Conjecture and I'd heartily recommend them in turn.
I know the SERI MATS technical lead @Joe_Collman spends a lot of his time thinking about how they can improve feedback loops, he might be interested in a chat.
You also might be interested in Mike Webb's project to set up programs to pass quality decision-making from top researchers to students, being tested on SERI MATS people at the moment.
Agree that it's super important, would be better if these things didn't exist but since they do and are probably here to stay, working out how to leverage their own capability to stay aligned rather than failing to even try seems better (and if anyone will attempt a pivotal act I imagine it will be with systems such as these).
Only downside I suppose is that these things seem quite likely to cause an impactful but not fatal warning shot which could be net positive, v unsure how to evaluate this consideration.
I've not noticed this but it'd be interesting if true as it seems that the tuning/RLHF has managed to remove most of the behaviour where it talks down to the level of the person writing as evidenced by e.g. spelling mistakes. Should be easily testable too.
Moore's law is a doubling every 2 years, while this proposes doubling every 18 months, so pretty much what you suggest (not sure if you were disagreeing tbh but seemed like you might be?)
0.2 OOMs/year is equivalent to a doubling time of 8 months.
I think this is wrong, that's nearly 8 doublings in 5 years, should instead be doubling every 5 years, should instead be doubling every 5 / log2(10) = 1.5.. years
I think pushing GPT-4 out to 2029 would be a good level of slowdown from 2022, but assuming that we could achieve that level of impact, what's the case for having a fixed exponential increase? Is it to let of some level of 'steam' in the AI industry? So that we can still get AGI in our lifetimes? To make it seem more reasonable to policymakers?
I would still rather have a moratorium until some measure of progress of understanding personally. We don't have a fixed temperature increase per decade built into our climate targets.
Thoughts:
- Seems like useful work.
- With RLHF I understand that when you push super hard for high reward you end up with nonsense results so you have to settle for quantilization or some such relaxation of maximization. Do you find similar things for 'best incorporates the feedback'?
- Have we really pushed the boundaries of what language models giving themselves feedback is capable of? I'd expect SotA systems are sufficiently good at giving feedback, such that I wouldn't be surprised that they'd be capable of performing all steps, including the human feedback, in these algorithms, especially lots of the easier categories of feedback, leading to possibility of unlimited of cheap finetuning. Nonetheless I don't think we've reached the point of reflexive endorsement that I'd expect to result from this process (GPT-4 still doing harmful/hallucinated completions that I expect it would be able to recognise). Expect it must be one of
- It in fact is at reflexive equilibrium / it wouldn't actually recognise these failures
- OAI haven't tried pushing it to the limit
- This process doesn't actually result in reflexive endorsement, probably because it only reaches RE within a narrow distribution in which this training is occurring.
- OAI stop before this point for other reasons, most likely degradation of performance.
- Not sure which of these is true though?
- Though the core algorithm I expect to be helpful because we're stuck with RLHF-type work at the moment, having a paper focused on accurate code generation seems to push the dangerous side of a dual-use capability to the fore.
OpenAI would love to hire more alignment researchers, but there just aren’t many great researchers out there focusing on this problem.
This may well be true - but it's hard to be a researcher focusing on this problem directly unless you have access to the ability to train near-cutting edge models. Otherwise you're going to have to work on toy models, theory, or a totally different angle.
I've personally applied for the DeepMind scalable alignment team - they had a fixed, small available headcount which they filled with other people who I'm sure were better choices - but becoming a better fit for those roles is tricky, unless by just doing mostly unrelated research.
Do you have a list of ideas for research that you think is promising and possible without already being inside an org with big models?
Your first link is broken :)
My feeling with the posts is that given the diversity of situations for people who are currently AI safety researchers, there's not likely to be a particular key set of understandings such that a person could walk into the community as a whole and know where they can be helpful. This would be great but being seriously helpful as a new person without much experience or context is just super hard. It's going to be more like here are the groups and organizations which are doing good work, what roles or other things do they need now, and what would help them scale up their ability to produce useful work.
Not sure this is really a disagreement though! I guess I don't really know what role 'the movement' is playing, outside of specific orgs, other than that it focusses on people who are fairly unattached, because I expect most useful things, especially at the meta level, to be done by groups of some size. I don't have time right now to engage with the post series more fully, so this is just a quick response, sorry!
there is uncertainty -> we need shared understanding -> we need shared language vs there is uncertainty -> what are organizations doing to bring people from individuals with potential together into productive groups making progress -> what are their bottlenecks to scaling up?