Universality and Hidden Information in Concept Bottleneck Models
post by Hoagy · 2023-04-05T14:00:35.529Z · LW · GW · 0 commentsContents
Summary Background Training Procedure Measuring Concept Fidelity Training Identical Models with Different Seeds Varying Dropout Varying attr_loss_weight Training with the wires crossed Predicting where information is hidden Non-pre-trained models Additional Reading Acknowledgements None No comments
Summary
I use the CUB dataset to finetune models to classify images of birds, via a layer trained to predict relevant concepts (e.g. "has_wing_pattern::spotted"). These models, when trained end-to-end, naturally put additional relevant information into the concept layer, which is encoded from run to run in very similar ways. The form of encoding is robust to initialisation of the concept-heads, and fairly robust to changes in architecture (presence of dropout, weighting of the two loss components), though not to initialisation of the entire model. The additional information seems to be primarily placed into low-entropy concepts.
This suggests that if steganography were to arise in, for example, fine-tuned autoregressive models, there would be convergent ways for this information to hide, which I previously thought unlikely, and which constrains the space of possible mitigations.
This work is ongoing and there are any more experiments to run but this is an intermediate post to show the arc of my current results and to help gather feedback. Code for all experiments on GitHub.
Background
In my Distilled Representations Research Agenda [LW · GW] I laid out the basic plan for this research. The quick version of this is that we showed that we can create toy cases where we train auto-encoders to encode vectors of a certain dimension, within which some dimensions have a preferred way of being represented, while others don't, and by training multiple models, we can distinguish between these different dimensions and create a new model which encodes only those dimensions which have a preferred encoding.
The next step is to see whether this toy model has any relevance to a real-world case, which I explore in this post.
Training Procedure
This work uses the CUB dataset. This is a dataset which contains >10K images, each labelled one of 200 species of bird. Each image also has 109 features which describe the birds' appearances.[1] These features are divided into 28 categories, such as beak-shape. Usually only one of these features is true for any given image, though the raw annotations can have multiple attributes in a class be true.

I perform experiments on the CUB dataset using Concept Bottleneck Models, specifically by finetuning an ImageNet-trained model to predict the species of bird from an image, with an auxiliary loss which incentivises each neuron in a layer near the final outputs to fire if and only if a human labeller has indicated that a particular 'concept', i.e. feature of the bird, is true of this bird. The model has a separate fully-connected 2-layer network for each concept, and then a single fully-connected 2-layer network to predict the class from the concept vector. These fully-connected layers are reinitialised from scratch with each run but the ImageNet model is pre-trained. The use of the pre-trained network is important to this shared information but also causes a host of other behaviour changes such that I don't think non-pre-trained networks are an ideal model of behaviour either (see final section).
Concept bottleneck models have three basic forms:
- Independent: the image-to-concept model and concept-to-class model are trained totally separately, and only combined into a single model at test time.
- Sequential: the image-to-concept model is trained first, and then the concept-to-class model is trained to predict the class from the generated concept vectors - but without propagating the gradient back to the image-to-concept model.
- Joint: the model is trained end-to-end using a loss combined of the concept prediction error and class prediction error. The relative weight of these can be adjusted for different tradeoffs between performance and concept fidelity.
Measuring Concept Fidelity
What we want to know for these systems is to what extent we've managed to construct a system which understands and responds to the concepts in the same way that we do. I follow the original Concept Bottleneck Models paper in using performance when the concept vector is replaced by the ground-truth label. If it performs well when given these labels then it seems that it is using the concepts closer to the way that we understand them. I call this 'full intervention performance'.
In the original experiments by Koh et al we see improvements to the performance when given the ground-truth concept labels - but given the trivial relationship between concept and class in that dataset this is not surprising (though their altered-background experiments are reassuring).
In this harder case that I use, without majority voting for the attributes (see footnote [1]), replacing estimated concept vectors with the original labels degrades performance even for sequential models. However, the intervention performance is much worse for joint models than for sequential models, indicating that the gap between the human meaning of the concept and the way that the model responds to the corresponding neuron is larger for joint models, and so we can still use this as a reasonable proxy for the degree of alignment of the neurons with concepts.(though it would be good if we had a better way of measuring this!).
Training Identical Models with Different Seeds
My initial experiment was what happens when we take two models which have been trained separately, and train them such that we've 'crossed the wires' - 50% of the time putting the concept vectors predicted by one model into the second model, and vice versa - how well will the classifiers work on concept vectors generated by a different model to the one that they are used to?
We have two main metrics - the performance on the test set, and the performance on the test set when the estimated concepts have been 'intervened on' - ie with their value in the concept vector replaced with their label in the dataset, this time using averaging over the concept labels in the train set to get a more accurate concept label (again see footnote [1]).
This gives us a 2D space of performance which we want to be able to improve on, shown by performance on the test set (this is referred to as test time intervention, or TTI) with 0 concepts intervened on (''tti0"), and with all concepts intervened on ("ttilast").
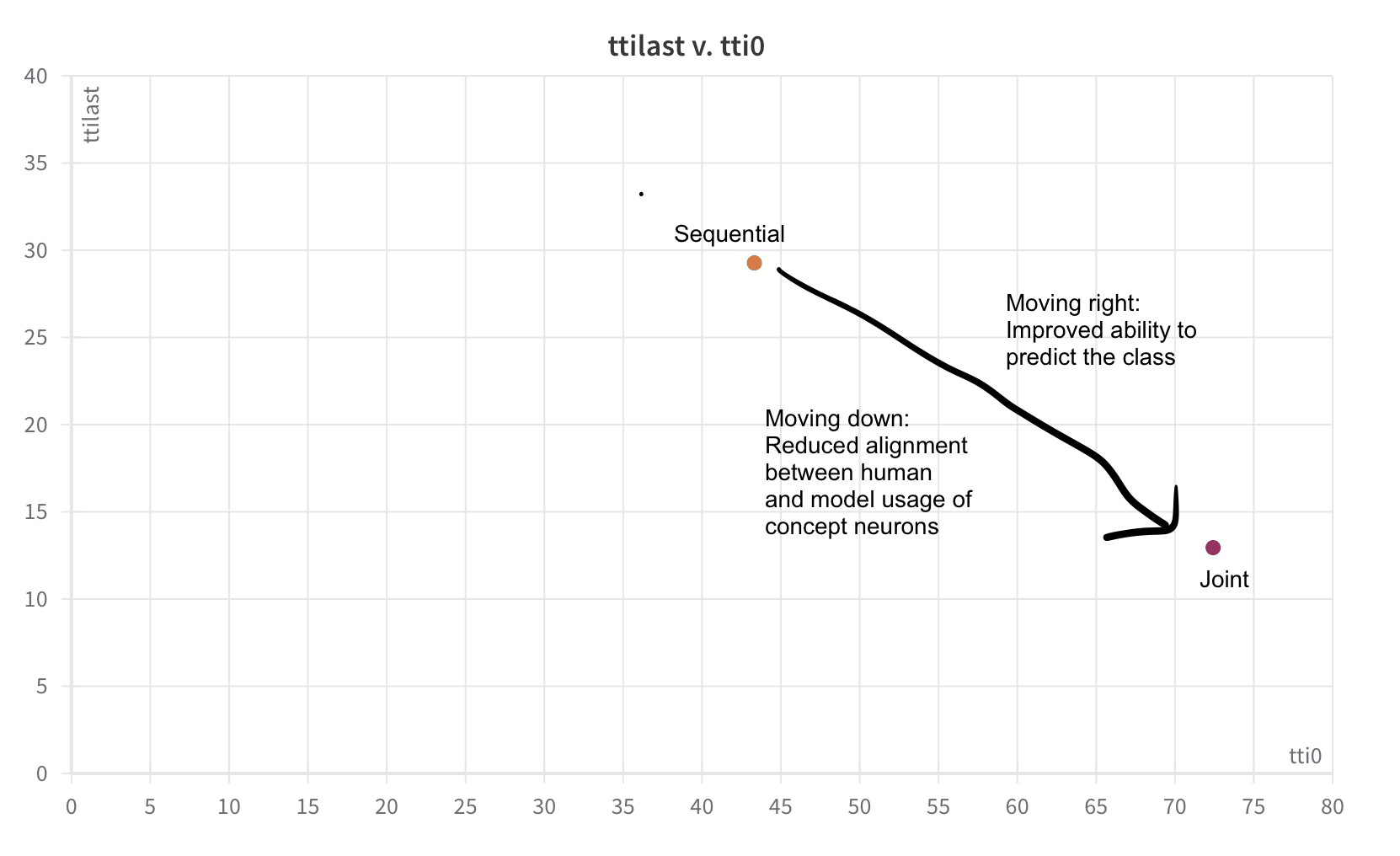
The initial configuration that I wanted to run was to train two joint models separately, and then at a certain point begin 'crossing the wires', so that the concept-to-class model was responding to a concept vector generated either by the first or second image-to-concept model.
My reasoning was that the extra information that boosts the performance of the joint model will be a load of add ons which have to sneak into the concept vector, a somewhat unnatural task that wouldn't necessarily correspond to features of any kind.
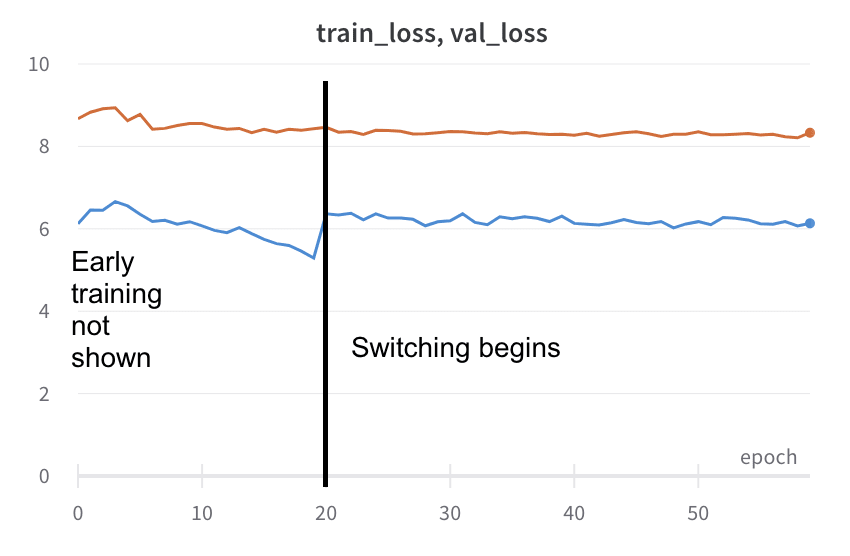
What I found instead was that the transition to this shuffling regime was barely noticeable in the loss or the accuracy curves for the validation set. I at first thought that this was a mistake but no - it seemed that they were both just learning in very similar ways!
I started to track the accuracy that the classifier of model 2 would achieve, if it were processing the concept vectors generated by the first model, during the initial phase of training. Labelling this 'cross accuracy', what I found was that the two concept models were clearly learning the same things in the same ways, at the same speeds - not just how to predict the concepts, but also how to fit in the extra information which boosts the downstream performance.
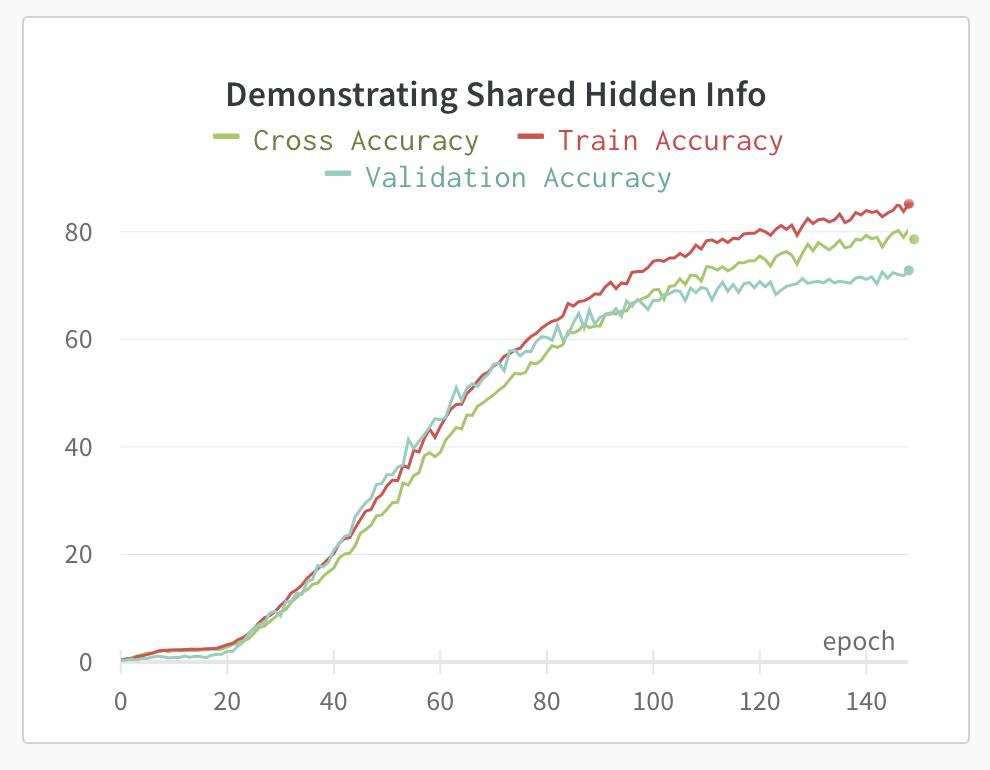
I found this very interesting because, if this were to be generalised it suggests that, if we are to find steganography in chain-of-thought reasoning, it seems likely that there are natural ways of encoding this hidden information, given that you are working with a pre-trained model. This rules out some of the ways that I had hoped we would be able to remove such information, relying on the orthogonality of the different directions in output space that different systems would use to encode particular information.
Of course this is just one datapoint, and it would be more compelling if we could understand the regularities in the forms of hidden information in a range of settings.
My next question is how robust are these systems. I investigated two ways of varying the task:
- Removing the dropout layer
- Varying the weight placed on the
attribute_lossrelative to theclass_loss.
Varying Dropout
We can see below that with dropout added to one of the models (a 50% dropout added to the fully connected layer just before the separate heads used to predict the concepts, using the Inceptionv3 architecture), the cross accuracies do start to significantly lag the train accuracy, but that the performance is still far above the performance achieved by a sequential model on the same task, showing that they still share the bulk of the methods by which they fit additional information into the concepts.
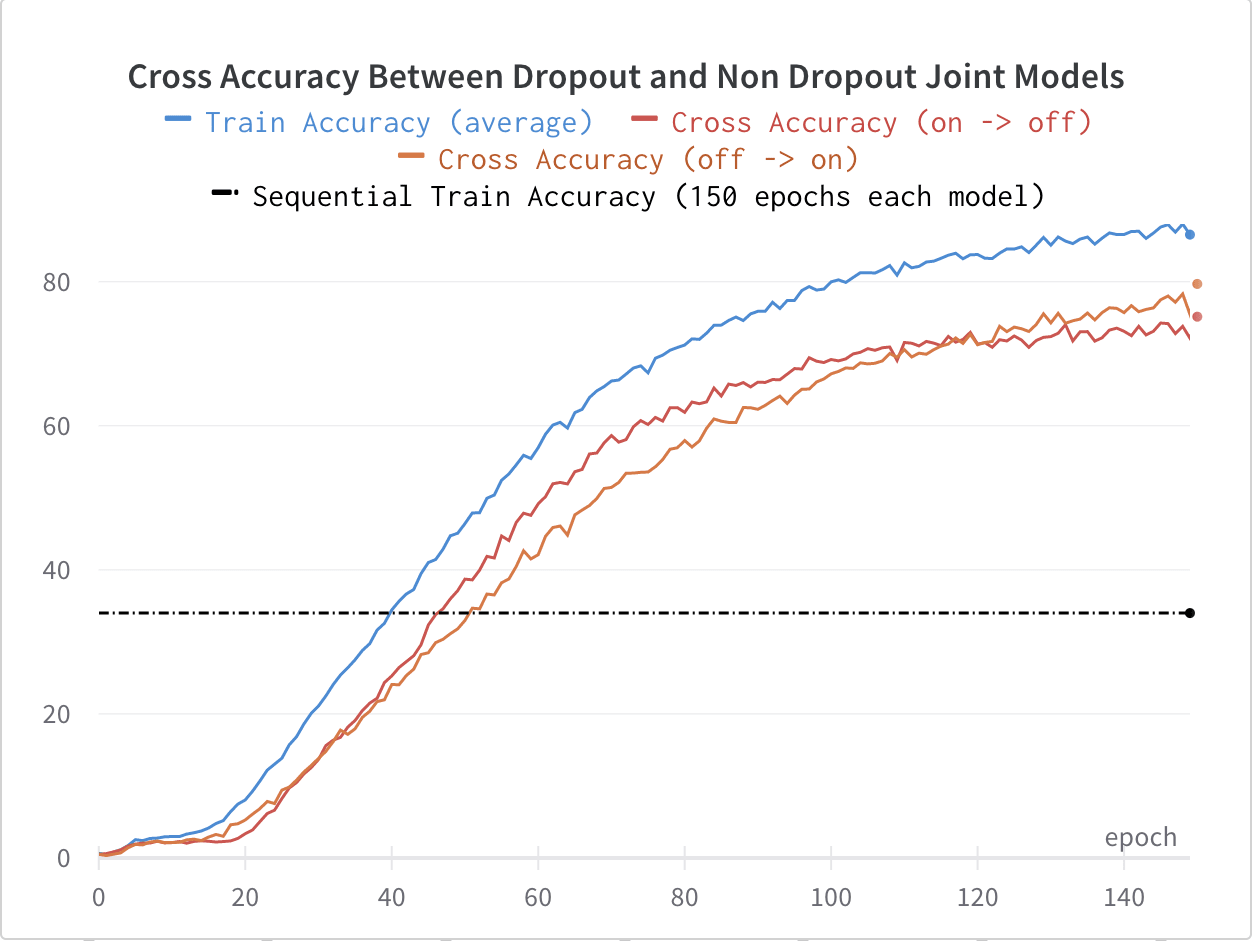
Surprisingly, adding dropout to the models consistently made the downstream performance better when fully intervening on the concepts. This is not what I expected to see, because I expected that not having dropout would make the concept-to-class classifier more sensitive to small variations in the concepts and therefore perform poorly when given the true classes, which would be further out of distribution.
I hypothesise instead that not having dropout means that the size of the alterations away from the true concepts (as they would be learned by the sequential model) necessary to encode the additional information that boosts the concept-to-class performance.
Varying attr_loss_weight
The other approach that I tried is to vary the weight placed on the attribute loss. The loss is calculated as loss = attr_loss * attr_loss_weight + class_loss so we can vary this parameter to make substantially different tasks, and we get a varied range of performance with different weights. This time, we can generate concept vectors which have some of the same performance-boosting information contained within in them, but which is hidden in very different ways, as we can see by the low cross accuracies:
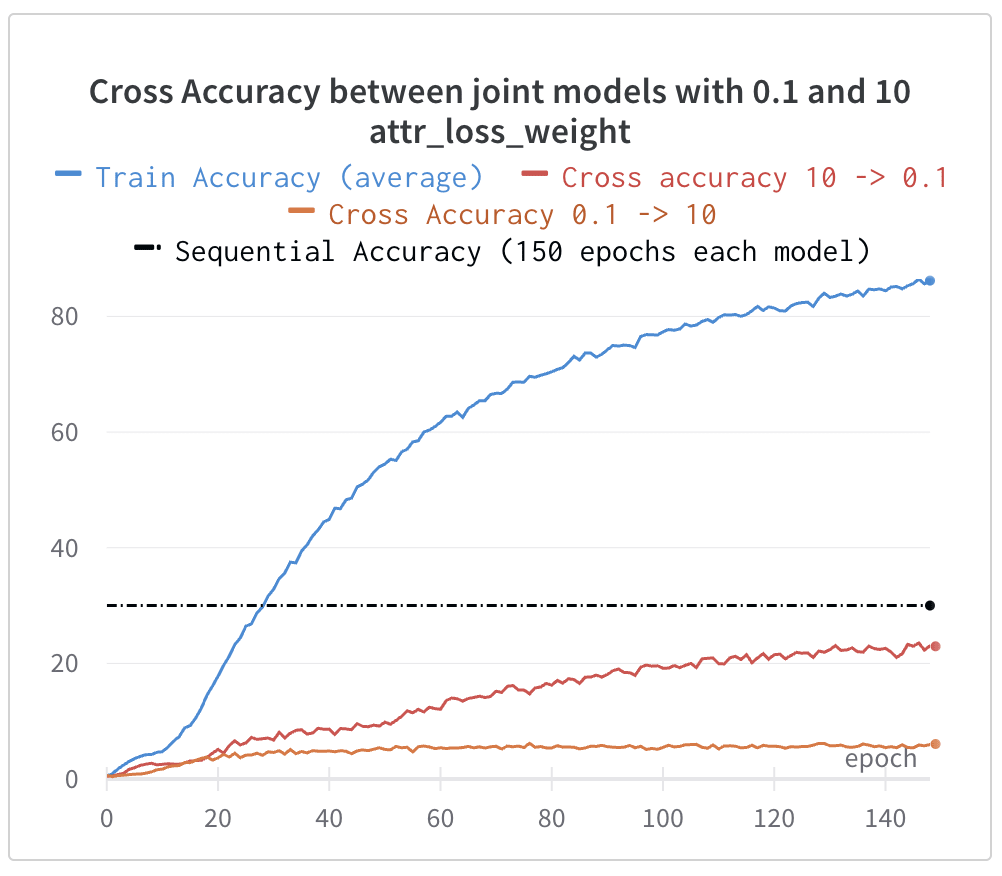
For a more full look at the cross-accuracies we have the following graph (all models with dropout not used):
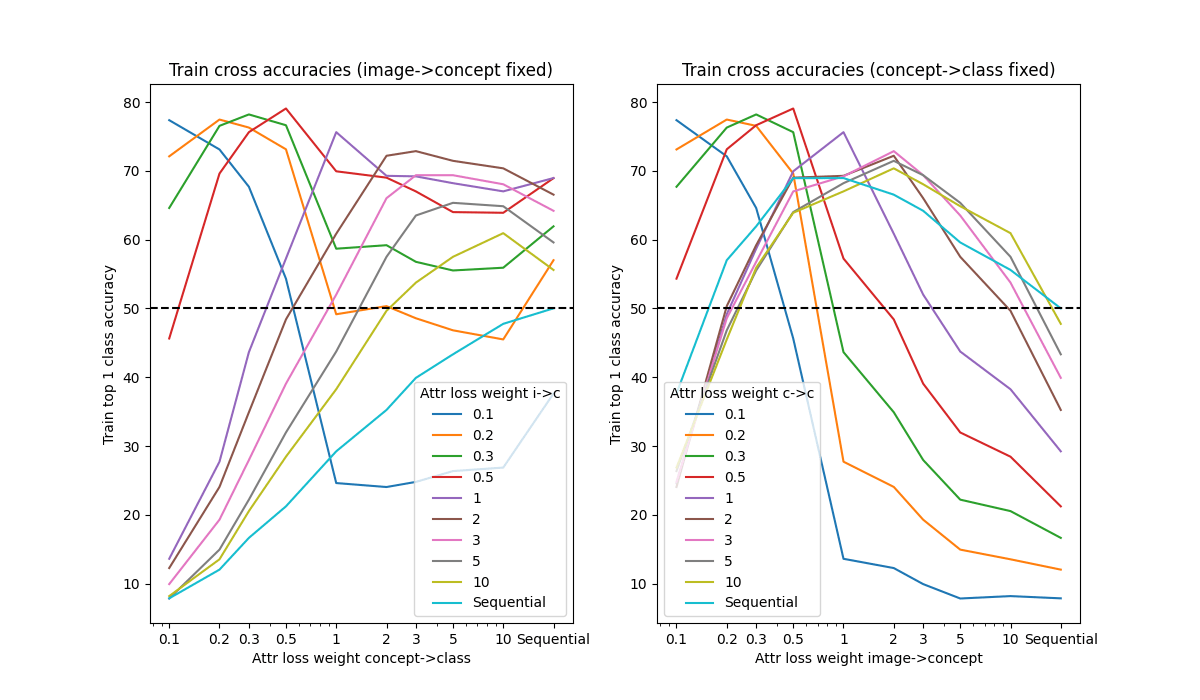
This shows us the (train) performance of the overall model when the concept vector is generated by a model training with one value for attr_loss_weight and then vector is used to predict the class by a model trained with a different attr_loss_weight.
We can see a few things going on in these graphs:
On the left we see that for a given image->concept model, the best class performance is consistently by using the corresponding concept->class model. This makes sense because the concept->class model only has a single source of loss and so we should expect it to be doing this optimally, given the concept vectors that it is receiving.
The level of performance drops off quite smoothly either side of the matching attr_loss_weight suggesting a continuous range of possible encodings from which the models select according to their loss weightings, though there's some evidence of a discrete shift between attr_loss_weight=0.5 and =1, and a fairly stable set of encodings in the 2 - 5 range.
On the right, however, we find that the sequential concept->class model actually performs better when taking in concept vectors generated by other models, even though it has never had a training signal which allows it to adapt to these new concept vectors.
This shows that in this case we don't actually need to learn a synergy between the internal abstractions and how they is used, we can just alter when those abstractions are invoked - ie changing when the concepts are turned on. Not only is this strategy possible but it's easily located, as we see the sequential model consistently doing better with the joint models' concept vectors, even at low attr_weight_loss where we expect to see the concepts being used very differently. This is important as it constrains the ability to use methods like freezing one part of the model while retraining the other to prevent hidden information, as it turns out that one can express lots of the required information in terms of the concepts as already understood by the concept->class model.
Training with the wires crossed
My original plan, assuming that models would encode the additional, 'hidden' information, in roughly orthogonal ways, clearly does not work fully as planned given the strong crossovers between the forms of hidden information shown above. Nonetheless, I was still curious how training using combinations of models could alter the space of performance and concept fidelity.
In order to understand how models trained to respond to concept vectors produced with models that have different training parameters, we need to understand the performance space of these models better, which we can see in the following graph:
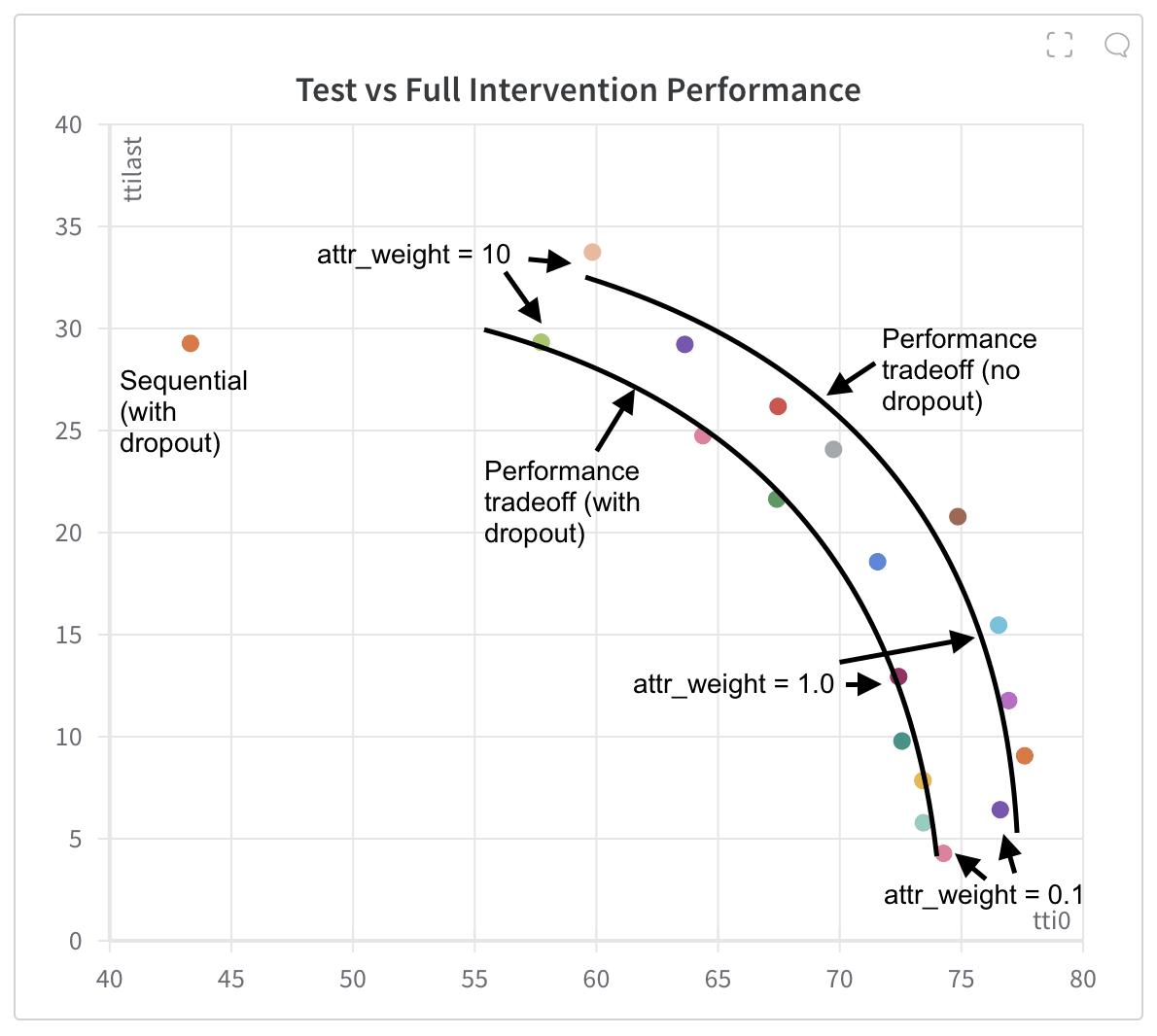
If we train models which respond to vectors which are randomly selected from pairs of models, and benchmark performance on this graph we can see on the graph below that we get results which are exactly in line with the performance frontiers from the single model, neither reducing test performance, nor boosting intervention performance.
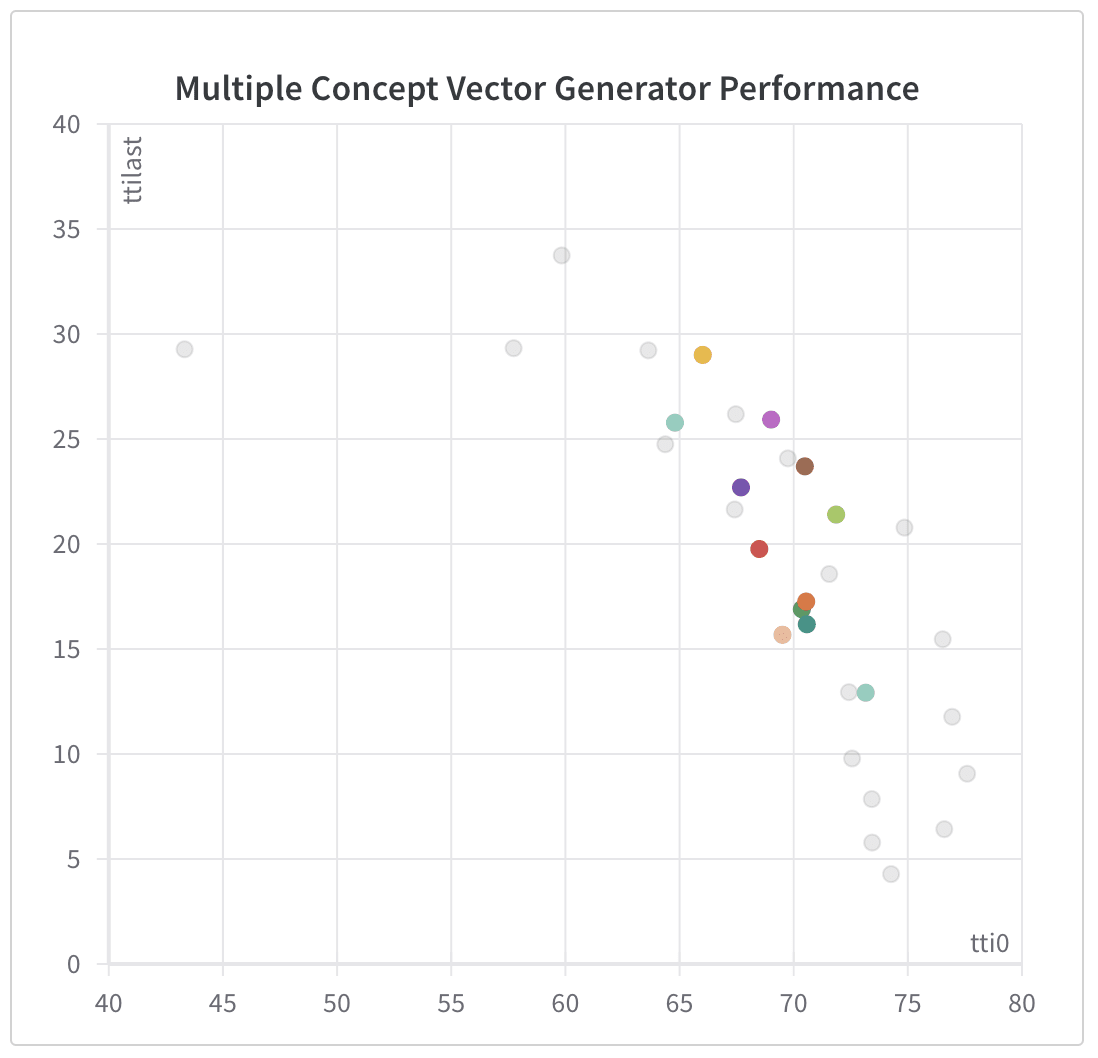
attr_loss_weights, with and without dropout. Grey points are from the graph above, illustrating the performance frontier with ordinary joint models.The unremarkableness of these results, even with extreme differences in attr_loss_weight suggests a deep problem with this approach which is that the concept-to-class model may be capable of detecting, with quite high accuracy, which image-to-concept model generated a given concept vector, and if we check, this is in fact what we find, especially for models which use dropout, even with similar attr_loss_weights where they should be least distinguishable:
| Validation accuracy of a two-layer model predicting source of concept vector. | ||
| Model A | Model B | Accuracy |
attr_loss=0.5, dropout=True | attr_loss=2.0, dropout=True | 0.979 |
attr_loss=0.5, dropout=False | attr_loss=2.0, dropout=False | 0.860 |
attr_loss=1.0, dropout=True | attr_loss=1.0, dropout=True | 0.981 |
attr_loss=1.0, dropout=False | attr_loss=1.0, dropout=False | 0.823 |
This means that we can't assume that just because a concept-to-class model is trained on concept vectors from both models, that it is responding to them as if they are created by the same generating procedure- it can distinguish them well enough to learn different sets of responses for the two. From the perspective of preventing hidden information, though, this is also encouraging as it suggests the distribution shift induced by hiding information is noticeable
One could somewhat alleviate this issue by retraining the image->concept model when the concept vectors are being processed by a one of a varied set of concept->class models. However, the results shown in the last paragraph of "Varying attr_loss_weight" suggest that you could boost the performance of the sequential model, just by retraining the image->concept model, and freezing the concept->class model, which suggests that the potential of this approach will be limited.
Predicting where information is hidden
One question this raises is whether we can learn where the information is going to be hidden before we actually see where it is hidden. One basic guess is that, since it has a limited set of channels to push as much information as possible into, it will put the additional information into the channels which aren't being used much in the sequential model, which will be those with low entropy of the concept labels.
I compare the entropy of the different concepts in their ground truth labels with the average absolute difference between the prediction of the sequential model with the prediction of various other joint models, with and without dropout and with varied attr_loss_weight. Calculating the correlation across the concepts, I find a consistent negative relationship though the strength of the relationship is surprisingly inconsistent given the deep similarities between the different models' approaches to hiding the information.
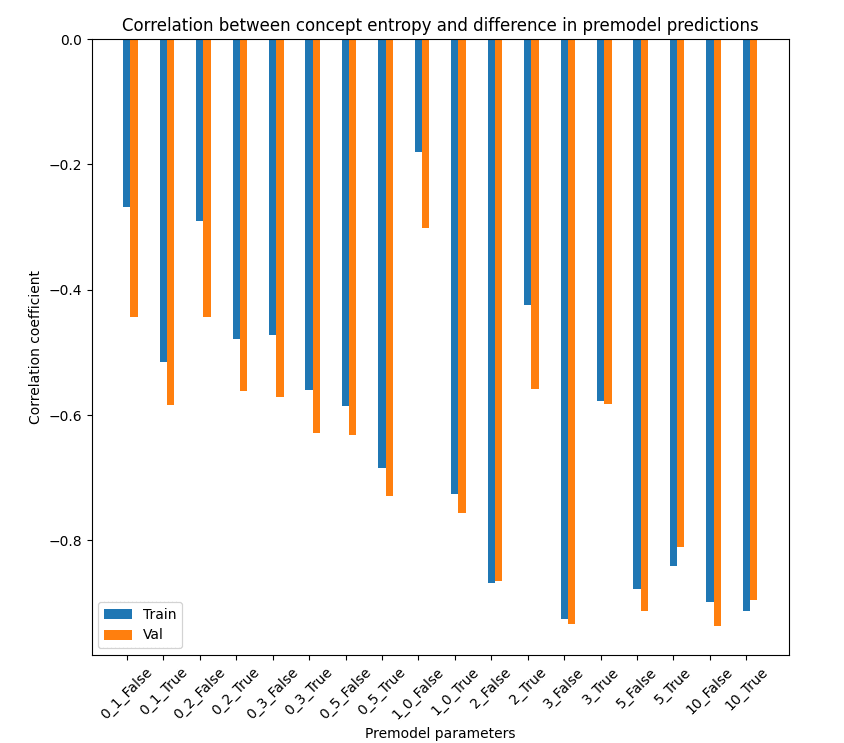
attr_loss_weight is higher. A little concerned that 1.0 False is an error but I can't find one.I find a consistent strong negative correlation between the entropy of a concept and the amount of deviation of the prediction of the joint models from the sequential model, so for a low entropy concept - p(True) very low or possibly high - we expect to see greater difference between the values estimated by the sequential model and the joint model. Estimating low entropy concepts should be easier, pushing in the opposite direction, so this is strong evidence that it is pushing the extra information into those channels that are low information in the sequential model.
This explains quite a bit of the variance in how the additional information is encoded but I would love to have a much more fine-grained understanding of how classification-relevant, information is placed within the concept layer - this is a core target for future work. If anyone has suggestions for the best way to investigate this, I'd be super interested!
Non-pre-trained models
One obvious thing that one could do is to extend these experiments to non-pre-trained models. I've run a basic test and we do indeed find that these models don't share information in the same way, as we can see in the graph below, which shows average train, val, and cross accuracy for two models using a freshly initialised Inceptionv3.
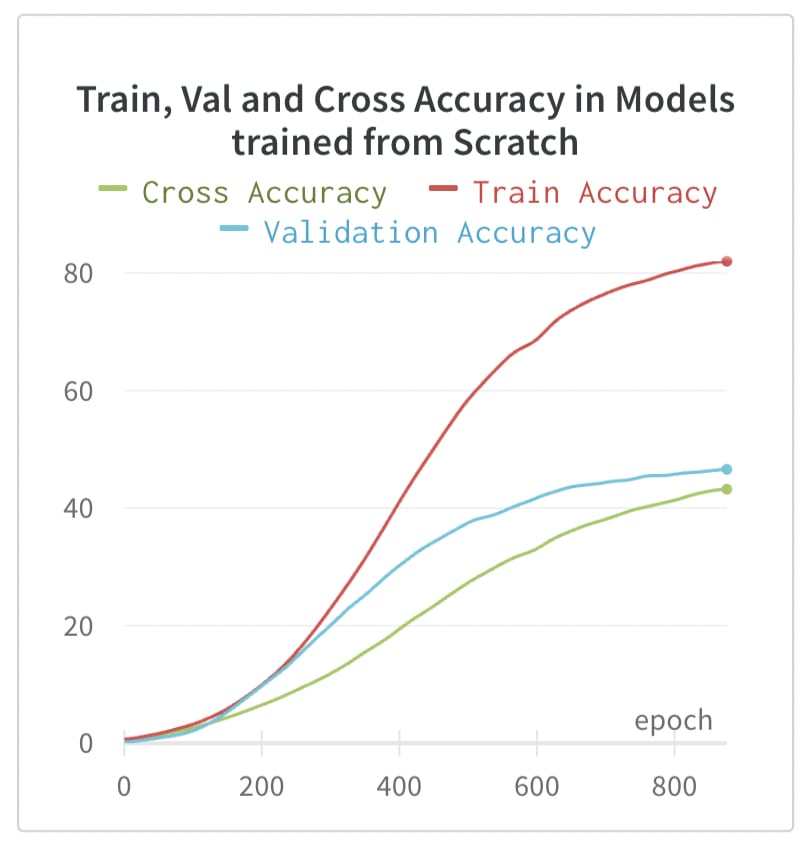
This is an important indication that the pre-training is in fact doing lots of the work to cause information to be hidden in the same way, but we need to be cautious in interpreting these results. The validation accuracy is far lower than the ~70% that you would see for the pre-trained model, and so the concepts that are being learned in the from-scratch model seem to be much less robust. It may still be that models which have learned useful priors over features during pre-training do have convergent ways of hiding information and we would expect models of significance to have such priors.
I think that better options for this kind of test would be to use pre-trained models but which use different architectures, or ideally models which have undergone different but comparable forms of pre-training on the same architecture. One of my next priorities is therefore to do a series of runs using pre-trained ResNets to compare with the Inceptionv3 architecture that I've been using throughout this post.
I'll be doing further experiments in this direction in the coming weeks but I hope these are of interest to some of you and I'd welcome any feedback :)
Additional Reading
Some potential further reading if you're interested in this area:
Concept Bottleneck Models - Koh et al 2020. Original paper introducing the architecture.
Git Rebasin - Ainsworth et al 2022. Looking at different ways that different models trained on the same task can be stitched together
Do Concept Bottleneck Models Learn as intended? - Margeliou et al 2021. An exploration of the ways that concept bottleneck models can fail to be the interpretable, intervenable models that they claim to be.
Convergent Learning - Do Different Neural Networks Learn The Same Representations? Li et al 2015. Early paper hypothesizing that neural networks converge to similar levels of performance despite different initializations because they are fundamentally learning the same features.
An Introduction to Circuits - Olah et al 2020. Mechanistically interpretability paper suggesting that there may be convergent features and circuits that arise, along with suggestive evidence from a variety of image models.
Concept Embedding Models - Zarlenga et al 2022. Variant of the CUB architecture that tries to remove the incentive to hide information within concepts (though I'm not convinced they are as successful as the paper claims).
Acknowledgements
This work was made possible by the support of the Long Term Future Fund.
Huge thanks to Misha Wagner for many helpful suggestions and corrections. Thanks also to Stephen Casper and to the people of the Conjecture and SERI MATS offices, and at the Wye Combinator retreat for conversations and interesting papers.
- ^
This isn't a full description of the dataset. Although one would expect that the actual characteristics of the bird are the same for each bird, the labels differ significantly between birds, labels are also often marked not-visible, and many are used only very rarely. As a result of this, most papers which use the CUB dataset make two key alterations to the dataset: First, reducing the number of categories to those which are true in at least 10 cases, which is around 110 (109 in my own experiments, 112 in the original). Second, they make it much easier by doing a majority-voting transform, by which the labels for each image are replaced by the most common category for birds of that species, within the test set.
I retain the first change (cutting down the number of attributes) but not the second. This second transform not only makes the task much easier but changes the entire task of building a concept model - because it allows the strategy of predicting the class and then using this to deterministically predict all of the features. It is unsurprising that the models which do this perform well, but it is not the task that we are interested in, so I stopped using this transform. Not using this transform also has the benefit that, being a much harder task, there's a big gap between the performance of a sequential model (about 40% top-1 on test set) and of the joint models, (about 70% top-1 on the test set), and in the opposite direction on the performance with full intervention - only about 15% with joint, 30% with sequential, and 50% with independent models. This gives us a clear space beyond the Pareto frontier of performance and concept-fidelity to aim into.
0 comments
Comments sorted by top scores.