Distilled Representations Research Agenda
post by Hoagy, mishajw · 2022-10-18T20:59:20.055Z · LW · GW · 2 commentsContents
Introduction Intuition Testing Toy Setup Toy Results Applications Eliciting Latent Knowledge (ELK) Interpretability Chain of Thought Prompting Potential Drawbacks Plans for next few months None 2 comments
Introduction
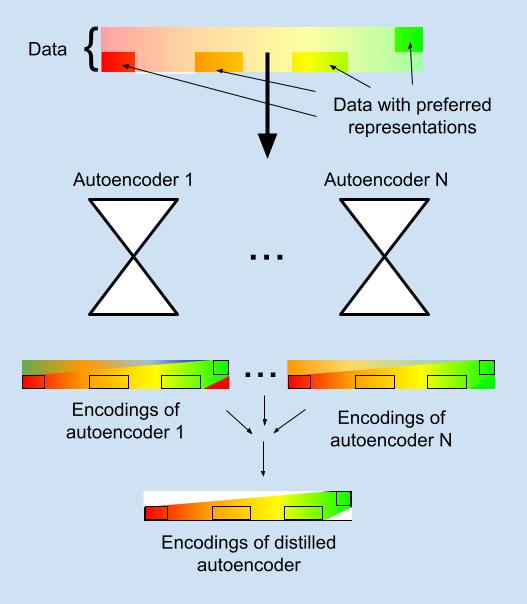
I’ve recently been given funding from the Long Term Future Fund to develop work on an agenda I'll tentatively call Distilled Representations, and I'll be working on this full-time over the next 6 months with Misha Wagner (part time).
We're working on a way of training autoencoders so that they can only represent information in certain ways - ways that we can define in a flexible manner.
It works by training multiple autoencoders to encode a set of objects, while for some objects defining a preferred representation that the autoencoders are encouraged to encode the objects as. We then distill these multiple autoencoders into single autoencoder which encodes only that information which is encoded in the same way across the different autoencoders. If we are correct, this new autoencoder should only encode information using the preferred strategy. Vitally, this can be not just the original information in the preferred representations, but also information represented by generalizations of that encoding strategy.
It is similar to work such as Concept Bottleneck Models but we hope the distillation from multiple models should allow interpretable spaces in a much broader range of cases.
The rest of this post gives more detail of the intuition that we hope to build into a useful tool, some toy experiments we’ve performed to validate the basic concepts, the experiments that we hope to build in the future, and the reasons we hope it can be a useful tool for alignment.
We'd like to make sure we understand what similar work has been done and where this work could be useful. If you're familiar with disentangled representations, or interpretability tools more generally, we're interested in having a chat. You can reach me here on LessWrong or at hoagycunningham@gmail.com.
Previous versions of similar ideas can be found in my ELK submission [LW · GW] and especially Note-taking Without Hidden Messages [LW · GW].
Intuition
The intuition that this work builds on is the following:
- With neural networks, the meanings of the weights and activations are usually opaque but we're often confident about the kind of thing that the network must be representing, at least for some cases or parts of the input distribution.
- In those cases where we understand what the network is representing, we can condense this understanding into a vector, thus defining a 'preferred representation' which encapsulates that knowledge.
- We can compress the NN's state with an autoencoder, while in those cases with preferred representations, encouraging the encoding to be as close as possible to the preferred representation.
- We expect that this running this compression results in the known information being compressed in the manner specified by the preferred representations, while other important information is snuck in wherever possible.
- If we then train multiple encoder/decoder systems, they will use the preferred representation, but also will use generalizations of the preferred representations.
- Additional info that is not a generalization of the preferred representation scheme will also be encoded, but the encoding scheme for additional information will vary between different encoder/decoder pairs.
- Using methods such as retraining a new encoder to encode for randomly shuffled decoders at each batch, we can create an encoder that uses a generalization of our preferred encoding scheme, without containing additional, misleading information.
There are quite a few leaps in this reasoning, and we view the key assumptions / hypotheses to be tested as the following:
- In relevant situations we can define preferred representations.
- We can force encoders to use not just these representations but meaningful generalizations of them, which correspond to our intuitive interpretation, given the preferred representation.
- There will not be a common form of encoding for the rest of the information.
- We can use tricks like those in point 7 above to extract only the information that we would understand.
We've been able to validate all of these assumptions in toy scenarios using compression of random binary vectors. The question now is whether we'll be able to make this a useful tool which scales to more complex environments.
Testing
Toy Setup
We train an autoencoder to reconstruct -digit binary strings using a latent space of . On top of the reconstruction loss, we introduce a representation loss, which is the gap between the encoded digits and our preferred representation. This incentivizes the model to use the th latent variable to represent the th binary digit. The th to th binary digits have no preferred representation.
vector = random_binary_vector() # shape=2N
latent_vector = encoder(vector) # shape=N
reconstructed_vector = decoder(latent_vector) # shape=2N
preferred_representation = vector[:N]
reconstruction_loss = torch.nn.MSELoss()(vector, reconstructed_vector)
representation_loss = torch.nn.MSELoss()(latent_vector, preferred_representation)
loss = reconstruction_loss + representation_loss
We find that, perhaps unsurprisingly, the autoencoder learns to “hide” the second half of the vector in the representation of first half. As one would expect, the encoder learns to map the first digits closely to themselves, and then hide the second digits in small variations around the preferred representations.
To remove this additional, hidden information, we train multiple encoder/decoder pairs, and then freeze the weights of the decoders while training a new encoder from scratch. When training this new encoder, the encoded representations are decoded by decoded that is randomly selected each batch.
Toy Results
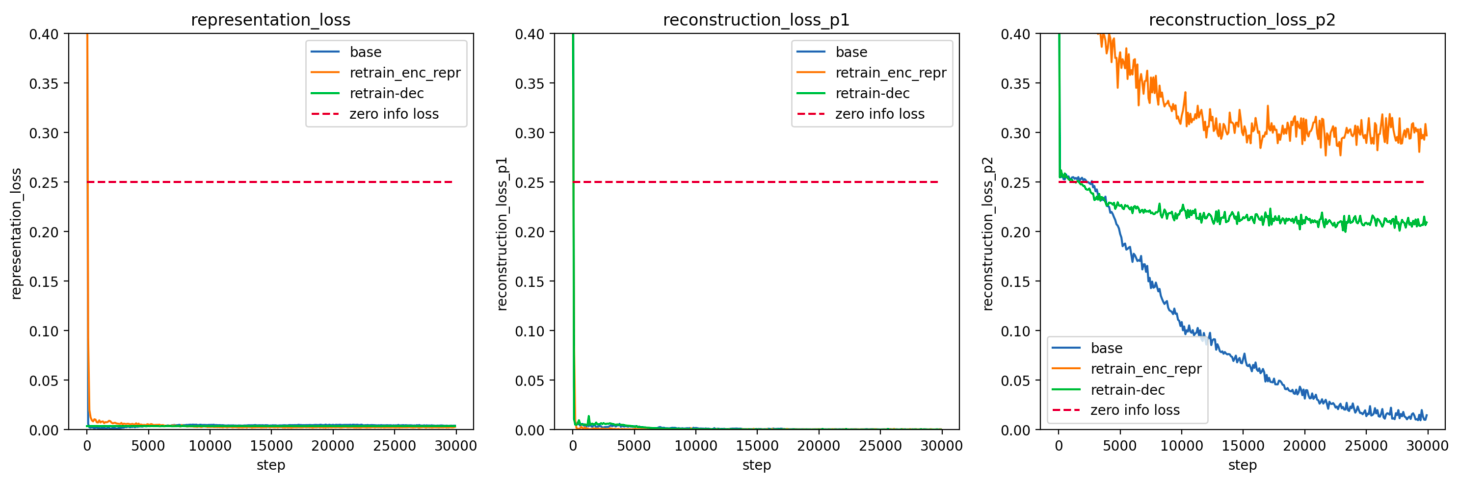
What we find is that when training 8 separate autoencoders (averaged into blue line), the information which has a preferred representation is encoded very quickly (p1_representation_loss) while the other information is learned more slowly by the separate models (p2_representation_loss). The representation loss is the loss from the gap between representation and preferred representation.
Then, when training a new set of encoders (orange line), which are responding to vectors from randomly chosen decoders - the weights of which are frozen - the information that had a preferred representation is again very quickly communicated. Meanwhile the rest of the information, being encoded in different ways, is mostly not successfully encoded - in fact it consistently does worse than having no information at all, though this is somewhat strange and is not true when retraining decoders (green line). We can tell it's close or worse than communicating no useful information because it's not far below (or ever above) the red line, which is the error with zero information (always guessing for every binary value).
It's trivial to force a correct representation if we always know exactly what our preferred representation should be. The test is whether we can do this in cases where the preferred representation is sparse and incomplete. We can make this signal sparse and restrict the signal only to a small fraction of the orthants (n-dimensional quadrant) and find that this also works. Below it the same setup, but where the preferred representation is only added for fewer than 20% of orthants, and even then only added 10% of the time - so the preferred representation is only given for under 1 in 50 cases.
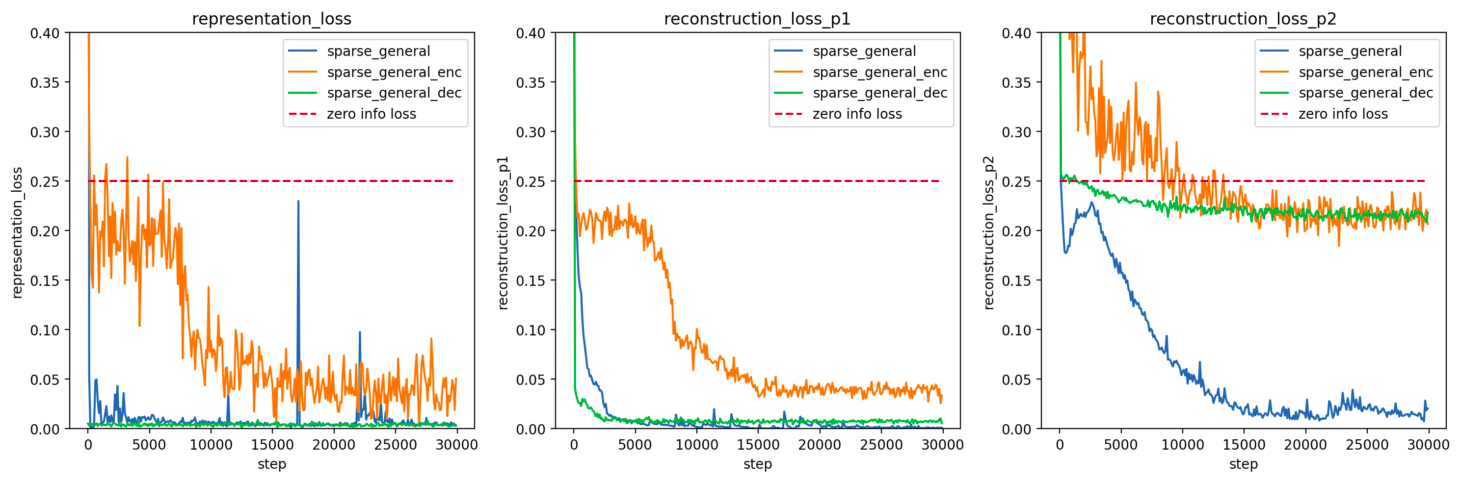
sum(vector) < 4 and random.random() < 0.1.These results with sparse inputs show that the method can work well even when preferred representations are not always present, and don't ever cover the full range of inputs. We also see the fact that it learns to encode info in the preferred representation much faster than it adds additional info, so we would get the same property simply by stopping early, though we don't expect this effect to be as stark in more complex environments.
We have also got similar results for cases where the preferred representation is more complex than just the identity function of a subset the input, though the learning process is slower.
Still, this requires only a very basic kind of generalization compared to the kind of generalization we would hope for in an ELK scenario - ideally, using language as humans do to represent situations, thereby being a direct translator rather than a human simulator, so we'll test the setup on progressively more complex environments.
Applications
Eliciting Latent Knowledge (ELK)
This idea comes from working on the Eliciting Latent Knowledge (ELK) challenge and is basically the combination of two posts in the ELK prizes [LW · GW] - 'Train a reporter that is useful for another AI' (my own, amongst others) and 'Train different reporters and require them to agree'. If you are the person who suggested the latter then thank you!
The picture that I think is hopeful for this kind of system starts with the background of Eliciting Latent Knowledge, in which we have a powerful system which we can ask questions of in certain situations where it knows the answer. These may be detailed Q&As or it may simply be a case where we know the state of the system and so we know the world-variables that it should be representing.
This information represents a preferred representation, and we restrict this representation to cases where we we're confident that it doesn't favour the human-simulation over the honest translator. We then train these systems to compress as much of their internal state into the answers to these questions, while ensuring that known information uses the preferred representation. The need to compress the information should then ensure we get something that is a direct translator, but much of this 'translation' will not be in an interpretable form, and so we use the multi-encoder strategy to get only the parts of the direct translator that we are able to understand.
This work can be thought of as trying to unify question-answering and autoencoders. Question-answering gives an easily comprehensible response but it's hard to ensure that it actually contains the right information. Autoencoders condense the information, but not in a way that is easily interpretable. The question that this work hopes to answer is 'Can we use question-answering as a form of autoencoder, without hiding a pile of incomprehensible information through the answers?'. This technique of distilled representations is step towards a working unification of these two ways of understanding a system.
Interpretability
While this is the most ambitious form of hope for this approach, we think that there's potential for it to be useful as an interpretability tool.
It can be seen as a contribution to the related field of disentangled representations, which creates latent representations, usually of images, but where the dimensions correspond to human-identifiable concepts.
This procedure could potentially be used to automatically make these, by labeling images according to certain dimensions, encoding images while deriving preferred representations from these labels, and then distilling out non-shared variability in encoding to get a latent space where the variables strictly only vary the dimensions of interest.
It also may be possible to use it within networks to create neurons which only respond in particular situations without having any additional meanings, making mechanistic interpretability easier.
Chain of Thought Prompting
There have been proposals [LW · GW] for using chain-of-thought reasoning to make superhuman reasoning interpretable by default, and concerns [LW · GW] that this could lead to steganography in the 'thoughts'.
I hope that this kind of system could be used to prevent a chain-of-thought reasoner from hiding addition information in what appeared to be trivially understandable written statements, and concern that (In this situation the preferred representation would be implicitly created by the large pre-training dataset and refined during fine tuning phases).
Potential Drawbacks
- Difficulty of setup: although we've managed to demonstrate the basic parameters, there have still been quite a few configurations in which it hasn't worked. For example, using encoders that are too weak, retraining first encoders and then decoders. This suggests that at higher complexity, getting such a system working and properly tuned may be difficult even if it works.
- Overhead: this system will always require training multiple autoencoders. These could, however, be much smaller than the system which they are trying to provide insight into.
- Schelling points for misleading communication. The setup relies on the fact that the things that the multiple encoders have in common - generalizations that the encoders make from the preferred representation - are a subset of the ways humans would understand the representation. It may simply be that there are convergent ways of representing even non-understandable information in some situations, which would then be mistaken for comprehensible signal about what's going on.
- Not enough useful generalizations: these systems may simply not find enough generalizations from the preferred representations we are able to provide useful insight.
Plans for next few months
- Test removing non-informative latent variables
- In our basic scenario it does not manage to communicate any info about the second half of the vector. That doesn't mean that it isn't varying the encoding in an attempt to. In more complex scenarios we would want these systems to actively flag, or refrain from communicating useless info. We'll test this first in our basic setup by incentivizing the system to flag as much of the latent space as possible as to be ignored.
- Conduct a lit review around disentangled representations (if you know of related work please let us know!).
- Run much more comprehensive testing to understand the performance of our toy system and the configurations which lead to best performance.
- Write up the method and surrounding idea in formal terms for precision and ability to connect with related fields
- Test in progressively more complex environments, which provide options for increasing complexity of generalization from preferred representation.
- First to procedurally generated images with fixed dimensions of variations
- Then to natural images
- Aspirationally to language models (probably needs more time/resources).
- Write up approach and results in as a paper.
- Experiment with setups involving 'free bits', which would not be shuffled and which should come to represent the highest order bits of the hidden information, and therefore act as targets for interpretability in order to better understand the information being compressed.
All work done in collaboration with Misha Wagner. Graphs and code on GitHub. Work supported by the Long Term Future Fund.
2 comments
Comments sorted by top scores.
comment by Maxwell Clarke (maxwell-clarke) · 2022-10-21T03:59:48.382Z · LW(p) · GW(p)
Hey - reccommend looking at this paper: https://arxiv.org/abs/1807.07306
It shows a more elegant way than KL regularization for bounding the bit-rate of an auto-encoder bottleneck. This can be used to find the representations which are most important at a given level of information.