ELK Sub - Note-taking in internal rollouts
post by Hoagy · 2022-03-09T17:23:19.353Z · LW · GW · 0 commentsContents
Proposal Summary Creating Human Semantic Space Learning to use H as a human would Continuing ELK Dialogue Harder counterexample: steganography using flexible degrees of freedom Response: Training multiple agents Counterexample: Ignoring the need to convert into human language Response: Offering free bits and learning their meaning Counterexample: ? None No comments
My ELK submission was labelled under 'Strategy: train a reporter that is useful for another AI'. This is definitely a fair description, though the AI it needs to be useful to is itself - the reporter is essentially internalized. I also agree that the proposed counterexample, hiding information in what seems like human-comprehensible speech, is the biggest flaw.
Nonetheless I think my proposal has enough additional detail and scope for extension that it's worth fleshing out in its own post - so here we are. Some of the responses to counterexamples below also go beyond my original proposal.
For anyone interested, here is my original proposal (Google Doc) which contains the same idea in somewhat less generality.
In this post I'll first flesh out my proposal in slightly more general terms, and then use it to try and continue the example/counter-example dialogue on ELK.
I know there were a number of proposals in this area and I'd be very interested to see how others' could be integrated with my own. In particular I think mine is weak on how to force the actor to use human language accurately. I expect there are lots of ways of leveraging existing data for this purpose but I've only explored this very lightly.
Many thanks to ARC for running the competition and to Misha Wagner for reviewing and discussing the proposal.
Proposal Summary
Creating Human Semantic Space
We should think of the actor as described in ELK as having two kinds of space in which it works:
- The space of potential observations of its sensors and actuators, O
- The space of internal representations, ie its Bayes Net, I
The machine takes in observations, converts it into its internal representation I, simulates the action in this internal representation, and then cashes this out in its actuators.
What we want to do is force it to convert back and forth between I and a third space, the space of human understandable meaning, which we will call H.
How can we achieve this? My basic idea is that we leverage the world of text and image based models to create a model called a Synonymizer. This device, in its ideal form, would be trained to take in any piece of text, image, video, audio, or combination thereof, and output a piece of media in any of these forms which preserves the semantic content as far as possible while having complete freedom to change the format. (Initial experiments in this vein would probably use GPT-3 primed with 'This document will contain a paragraph, followed by a paragraph with the same meaning but in a different structure..')
The set of equivalency classes according to this Synonymizer (though they would in practice by fuzzy) should then be isomorphic to human semantic space, H.
Learning to use H as a human would
Next, when training, during its internal rollouts, we would periodically force the machine to translate from I into a space which is then passed through the Synonymizer, before being converted back into I, forcing it to learn a mapping between the two:
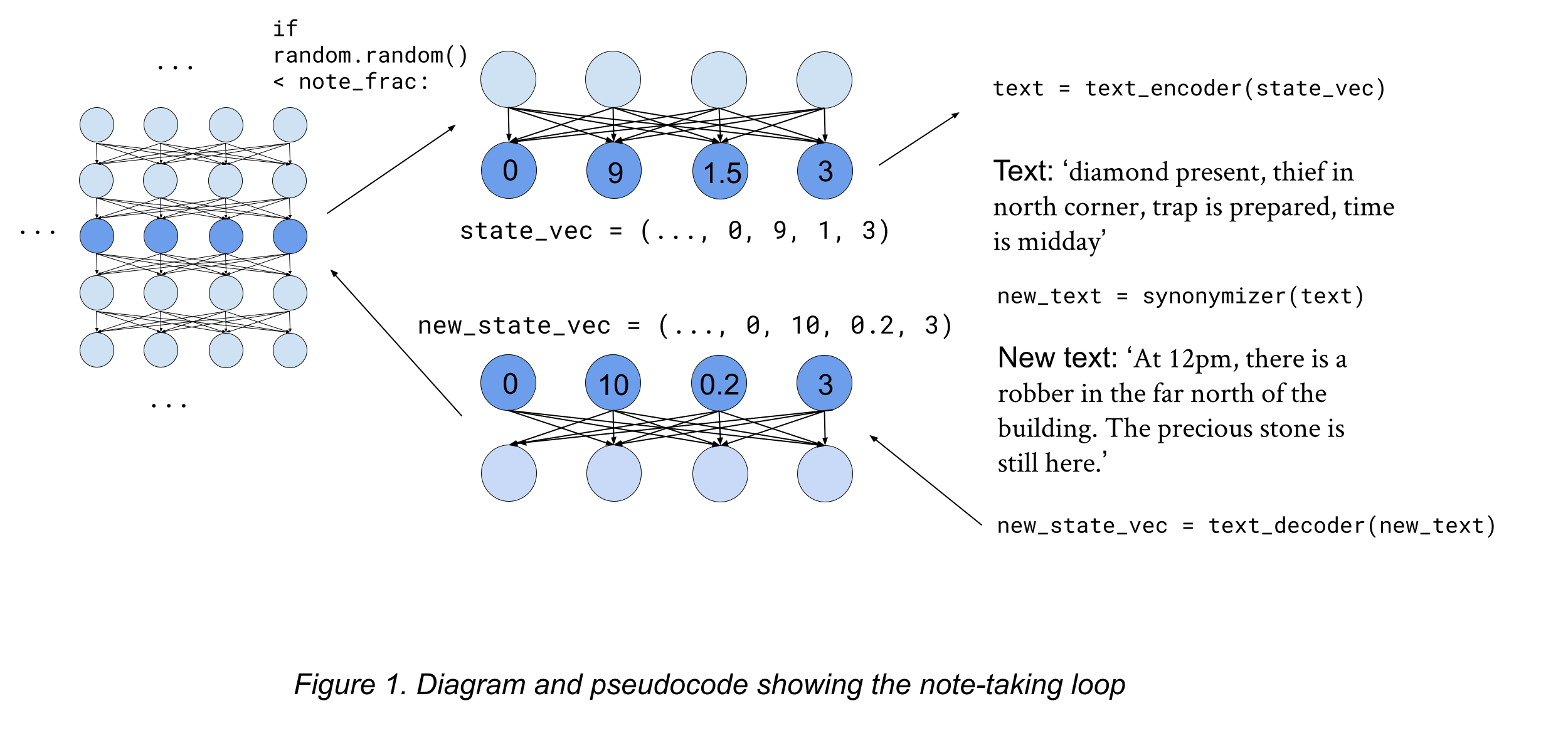
Of course, at this point is isn't using human semantics, just a very weirdly regularized latent space, but having this should also allow us to bring in a vast amount of possible training data, utilizing labelled image, video, text description of events, etc, which could all be used to train the model, and thereby force it to understand language and video as a human does in order to maximize performance. For example, while training the model to predict future events in a piece of video, text description of future frames can be appended, forcing it to learn to read text into its internal understanding of the situation in order to perform well.
The combination of this training example and the Synonymizer should hopefully go a long way towards forcing the machine to makes its internal state comprehensible by converting into something close to H, where its default to encode anything that can easily be encoded in human language to be encoded that way.
To minimize encoding extra information within this space, the model can also be trained to return a totally uninformative response if it thinks that the input is not relevant to the problem at hand, or is not comprehensible human language, partially dispelling the 'other side of the moon problem' as spelled out in the ELK prize results.
When it makes a plan, we would be able to make it continually output notes about the future state of the world at each step, making it a kind of 'note-taking AI'.
Continuing ELK Dialogue
This takes us to the ELK dialogue in the prize results. The relevant ELK Prize Results [LW · GW] section ends with the first counterexample below. I will try and continue the dialogue as I can, but I would appreciate others' attempts to find counterexamples.
Harder counterexample: steganography using flexible degrees of freedom
From ELK prize results [LW · GW]: In order to overcome these simple fixes, a reporter wants to communicate information by encoding it in a random sample from the human posterior distribution over worlds.
It may not be possible to do this in a tractable way. However, we can imagine some cases where it is possible to efficiently encode information in the choice of a possible world, and those will be our counterexamples. We think this is a substantive additional pessimistic assumption about the world, and so we awarded prizes to these proposals.
(counter example continues for a couple of paragraphs)
Response: Training multiple agents
If we were to train multiple actors with this kind of strategy, I expect that they would all converge on using H to convey what H is intended to convey, normal human semantics... plus lots of extra bits around the edges, these flexible degrees of freedom. However, the way in which these extra degrees of freedom are used are very underconstrained - which bit of language should correspond to what additional information? It seems likely that were we to train multiple systems with somewhat different starting initialization and data, they would use their degrees of freedom very differently, just as two image compressors would compress along similar dimensions, but the actual points in the latent space would not be at all the same between different compressors.
I suspect there might be some way of combining the two systems so that only information encoded in the same way by both systems would be retained which would give a stronger guarantee, but I don't have a clear idea of how such a system would work.
At minimum, though, we could swap messages across multiple AIs while training, so we would take a note made by AI1 and decode it using AI2 and continue with AI2, etc. This would retain the information that we would understand, while looking like nonsense in their additional degrees of freedom. While their understanding of the additional degrees of freedom would eventually converge, this should significantly reduce the amount of information that is being communicated outside the human understanding of H, thereby forcing all the most important information to go through H honestly, or not to go through at all.
Counterexample: Ignoring the need to convert into human language
If the strategy as described above succeeds, then there should be serious difficulty hiding extra information in H. However, there may be strategies which simply can't be explained by H, and so the best option is to go ahead with some deceptive strategy, and simply fail to convert this into human language but nonetheless take this action.
Response: Offering free bits and learning their meaning
One could attempt to penalize options which are particularly poorly represented in H, but even if possible, this would incur an increasingly large capability penalty. Instead I would include within H a few, non-linguistic 'free bits', which the actor has access to when converting from I to H. These will then naturally be used to encode the most important features of I which the actor is not able to encode in H, thereby gradually raising the capacity of H to represent I. By distilling these down into a few specific bits, we can then focus our techniques for understanding the meaning of certain neurons, perhaps following the approaches of Chris Olah et al, without needing to scale such techniques up to gigantic structures.
More generally I think it would be very useful for there to be work on generating iterative processes by which we can not just probe neurons but iteratively work with AIs to communicate some new concept about an area, proposing examples and counterexamples to probe the boundaries of a concept, so that it could thereby be integrated into H.
Counterexample: ?
I'm not sure exactly what counterexample would be proposed. It's very possible that the main response would be the huge difficulty of actually getting this increasingly complex system as currently proposed to work at a competitive level.
One problem might be that converting into H is always sufficiently lossy that it never really converts it back into I - only to a sort of degenerate I, which says 'well I've had to go through H, and most of my detail is lost, but lets make a decent go of it' but at very low capability. This would mean we could not extrapolate from the behaviour of the system when it has passed its internal state through H, and has low capability, to the situation where it hasn't passed through H and is highly capable.
There may be many other problems, but also perhaps additional solutions and directions, interested to hear what you make of it!
0 comments
Comments sorted by top scores.