Posts
Comments
In NZ we have biting bugs called sandflies which don't do this - you can often tell the moment they get you.
Yes, that's fair. I was ignoring scale but you're right that it's a better comparison if it is between a marginal new human and a marginal new AI.
Well, yes, the point of my post is just to point out that the number that actually matters is the end-to-end energy efficiency — and it is completely comparable to humans.
The per-flop efficiency is obviously worse. But, that's irrelevant if AI is already cheaper for a given task in real terms.
I admit the title is a little clickbaity but i am responding to a real argument (that humans are still "superior" to AI because the brain is more thermodynamically efficient per-flop)
I saw some numbers for algae being 1-2% efficient but it was for biomass rather than dietary energy. Even if you put the brain in the same organism, you wouldn't expect as good efficiency as that. The difference is that creating biomass (which is mostly long chains of glucose) is the first step, and then the brain must use the glucose, which is a second lossy step.
But I mean there is definitely far-future biopunk options eg. I'd guess it's easy to create some kind of solar panel organism which grows silicon crystals instead of using chlorophyll.
Fully agree - if the dog were only trying to get biscuits, it wouldn't continue to sit later on in it's life when you are no longer rewarding that behavior.Training dogs is actually some mix of the dog consciously expecting a biscuit, and raw updating on the actions previously taken.
Hear sit -> Get biscuit -> feel good
becomes
Hear sit -> Feel good -> get biscuit -> feel good
becomes
Hear sit -> feel good
At which point the dog likes sitting, it even reinforces itself, you can stop giving biscuits and start training something else
This is a good post, definitely shows that these concepts are confused. In a sense both examples are failures of both inner and outer alignment -
- Training the AI with reinforcement learning is a failure of outer alignment, because it does not provide enough information to fully specify the goal.
- The model develops within the possibilities allowed by the under-specified goal, and has behaviours misaligned with the goal we intended.
Also, the choice to train the AI on pull requests at all is in a sense an outer alignment failure.
If we could use negentropy as a cost, rather than computation time or energy use, then the system would be genuinely bounded.
Gender seems unusually likely to have many connotations & thus redundant representations in the model. What if you try testing some information the model has inferred, but which is only ever used for one binary query? Something where the model starts off not representing that thing, then if it represents it perfectly it will only ever change one type of thing. Like idk, whether or not the text is British or American English? Although that probably has some other connotations. Or whether or not the form of some word (lead or lead) is a verb or a noun.
Agree that gender is a more useful example, just not one tha necessarily provides clarity.
Yeah I think this is the fundamental problem. But it's a very simple way to state it. Perhaps useful for someone who doesn't believe ai alignment is a problem?
Here's my summary: Even at the limit of the amount of data & variety you can provide via RLHF, when the learned policy generalizes perfectly to all new situations you can throw at it, the result will still almost certainly be malign because there are still near infinite such policies, and they each behave differently on the infinite remaining types of situation you didn't manage to train it on yet. Because the particular policy is just one of many, it is unlikely to be correct.
But more importantly, behavior upon self improvement and reflection is likely something we didn't test. Because we can't. The alignment problem now requires we look into the details of generalization. This is where all the interesting stuff is.
Respect for thinking about this stuff yourself. You seem new to alignment (correct me if I'm wrong) - I think it might be helpful to view posting as primarily about getting feedback rather than contributing directly, unless you have read most of the other people's thoughts on whichever topic you are thinking/writing about.
Oh or EA forum, I see it's crossposted
I think you might also be interested in this: https://www.lesswrong.com/posts/Nwgdq6kHke5LY692J/alignment-by-default In general John Wentworths alignment agenda is essentially extrapolating your thoughts here and dealing with the problems in it.
It's unfortunate but I agree with Ruby- your post is fine but a top-level lesswrong post isn't really the place for it anymore. I'm not sure where the best place to get feedback on this kind of thing is (maybe publish here on LW but as a short-form or draft?) - but you're always welcome to send stuff to me! (Although busy finishing master's next couple of weeks)
Great comment, this clarified the distinction of these arguments to me. And IMO this (Michael's) argument is obviously the correct way to look at it.
Hey, wanted to chip into the comments here because they are disappointingly negative.
I think your paper and this post are extremely good work. They won't push forward the all-things-considered viewpoint, but they surely push forward the lower bound (or adversarial) viewpoint. Also because Open Phil and Future Fund use some fraction of lower-end risk in their estimate, this should hopefully wipe that put. Together they much more rigorously lay out classic x-risk arguments.
I think that getting the prior work peer reviewed is also a massive win at least in a social sense. While it isn't much of a signal here on LW, it is in the wider world. I have very high confidence that I will be referring to that paper in arguments I have in the future, any time the other participant doesn't give me the benefit of the doubt.
I fully agree*. I think the reason most people disagree, and thing the post is missing is a big disclaimer about exactly when this applies. It applies if and only if another person is following the same decision procedure to you.
For the recycling case, this is actually common!
For voting, it's common only in certain cases. e.g. here in NZ last election there was a party TOP which I ran this algorithm for, and had this same take re. voting, and thought actually a sizable fraction of the voters (maybe >30% of people who might vote for that party) were probably following the same algorithm. I made my decision based on what I thought the other voters would do, which I thought was that probably somehat fewer would vote for TOP than in the last election (where the party didn't get into parliament), and decided not to vote for TOP. Lo and behold, TOP got around half the votes they did the previous election! (I think this was the correct move because I don't think the number of people following that decision procedure increased)
*except confused by the taxes example?
Props for showing moderation in public
Hey - reccommend looking at this paper: https://arxiv.org/abs/1807.07306
It shows a more elegant way than KL regularization for bounding the bit-rate of an auto-encoder bottleneck. This can be used to find the representations which are most important at a given level of information.
Thanks for these links, especially the top one is pretty interesting work
Great - yeah just because it's an attractor state doesn't mean it's simple to achieve - still needs the right setup to realize the compounding returns to intelligence. The core hard thing is that improvements to the system need to cause further improvements to the system, but in the initial stages that's not true - all improvements are done by the human.
Recursive self improvement is something nature doesn't "want" to do, the conditions have to be just right or it won't work.
I very much disagree - I think it's absolutely an attractor state for all systems that undergo improvement.
I just spent a couple of hours trying to make a firefox version but I have given up. It's a real pain because firefox still only supports the manifest v2 api. I realized I basically have to rewrite it which would take another few hours and I don't care that much.
I just spent a couple of hours trying to make a firefox version but I have given up. It's a real pain because firefox still only supports the manifest v2 api. I realized I basically have to rewrite it which would take another few hours and I don't care that much.
I think we can get additional information from the topological representation. We can look at the relationship between the different level sets under different cumulative probabilities. Although this requires evaluating the model over the whole dataset.
Let's say we've trained a continuous normalizing flow model (which are equivalent to ordinary differential equations). These kinds of model require that the input and output dimensionality are the same, but we can narrow the model as the depth increases by directing many of those dimensions to isotropic gaussian noise. I haven't trained any of these models before, so I don't know if this works in practice.
Here is an example of the topology of an input space. The data may be knotted or tangled, and includes noise. The contours show level sets .
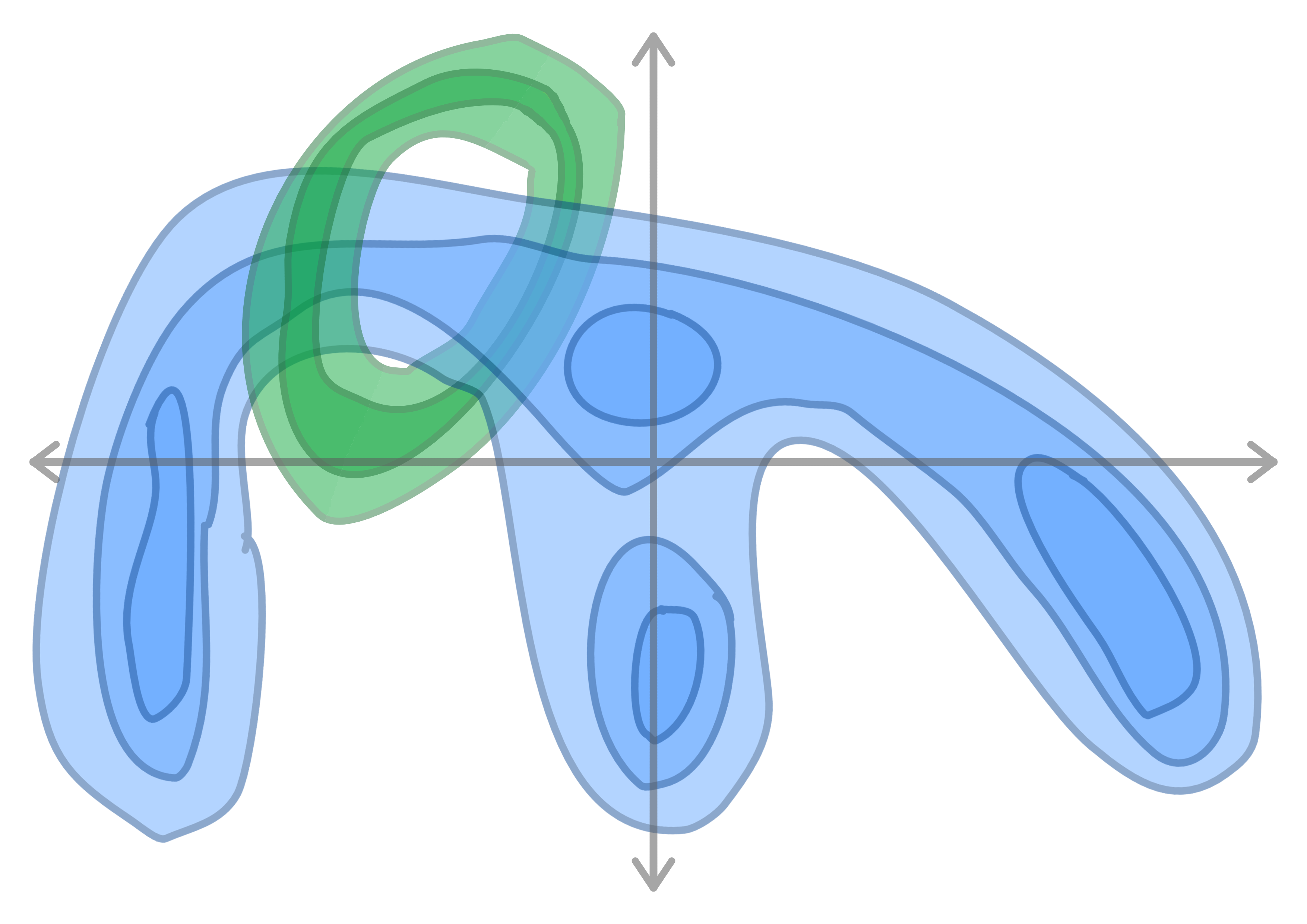
The model projects the data into a high dimensionality, then projects it back down into an arbitrary basis, but in the process untangling knots. (We can regularize the model to use the minimum number of dimensions by using an L1 activation loss
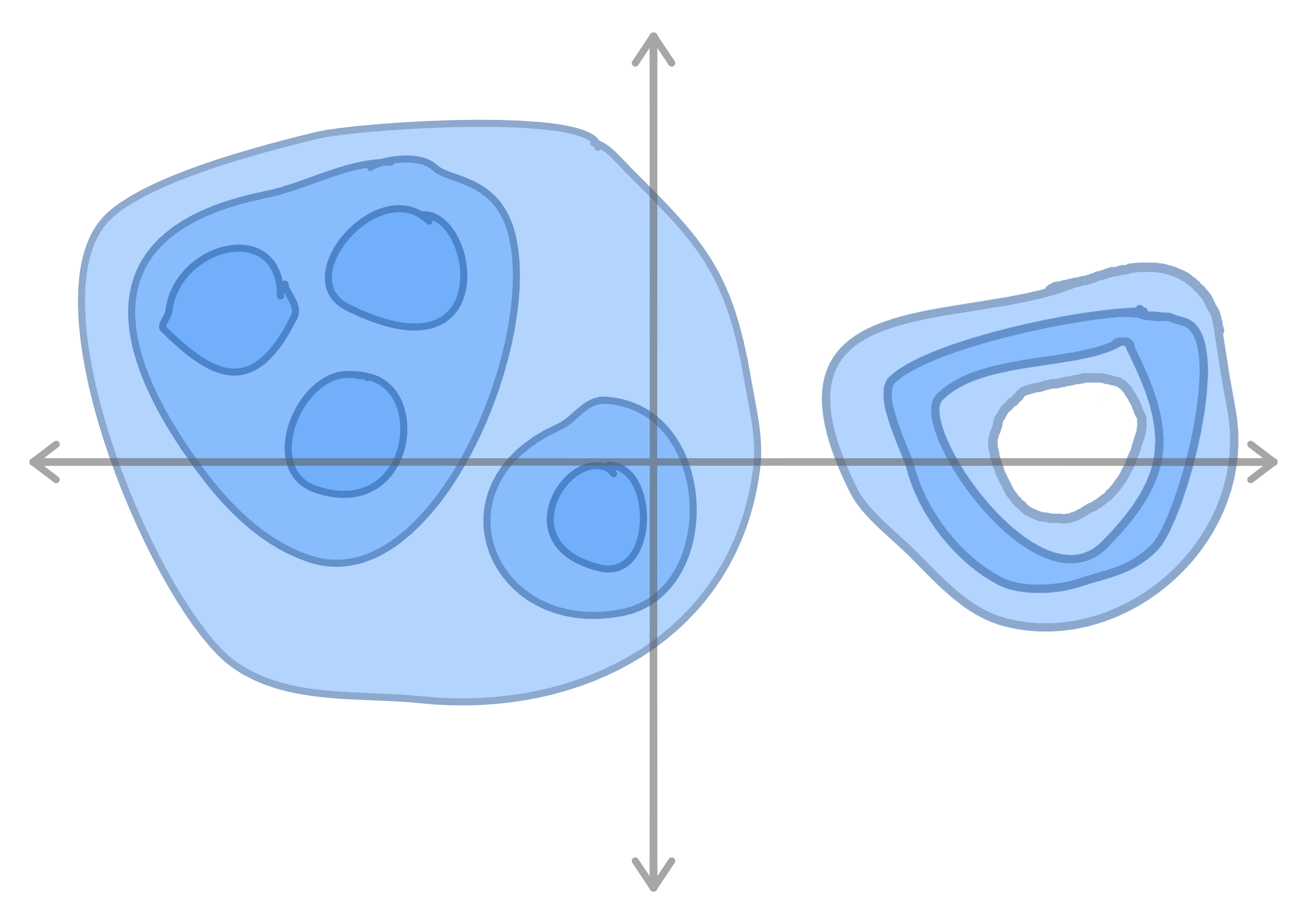
Lastly, we can view this topology as the Cartesian product of noise distributions and a hierarchical model. (I have some ideas for GAN losses that might be able to discover these directly)
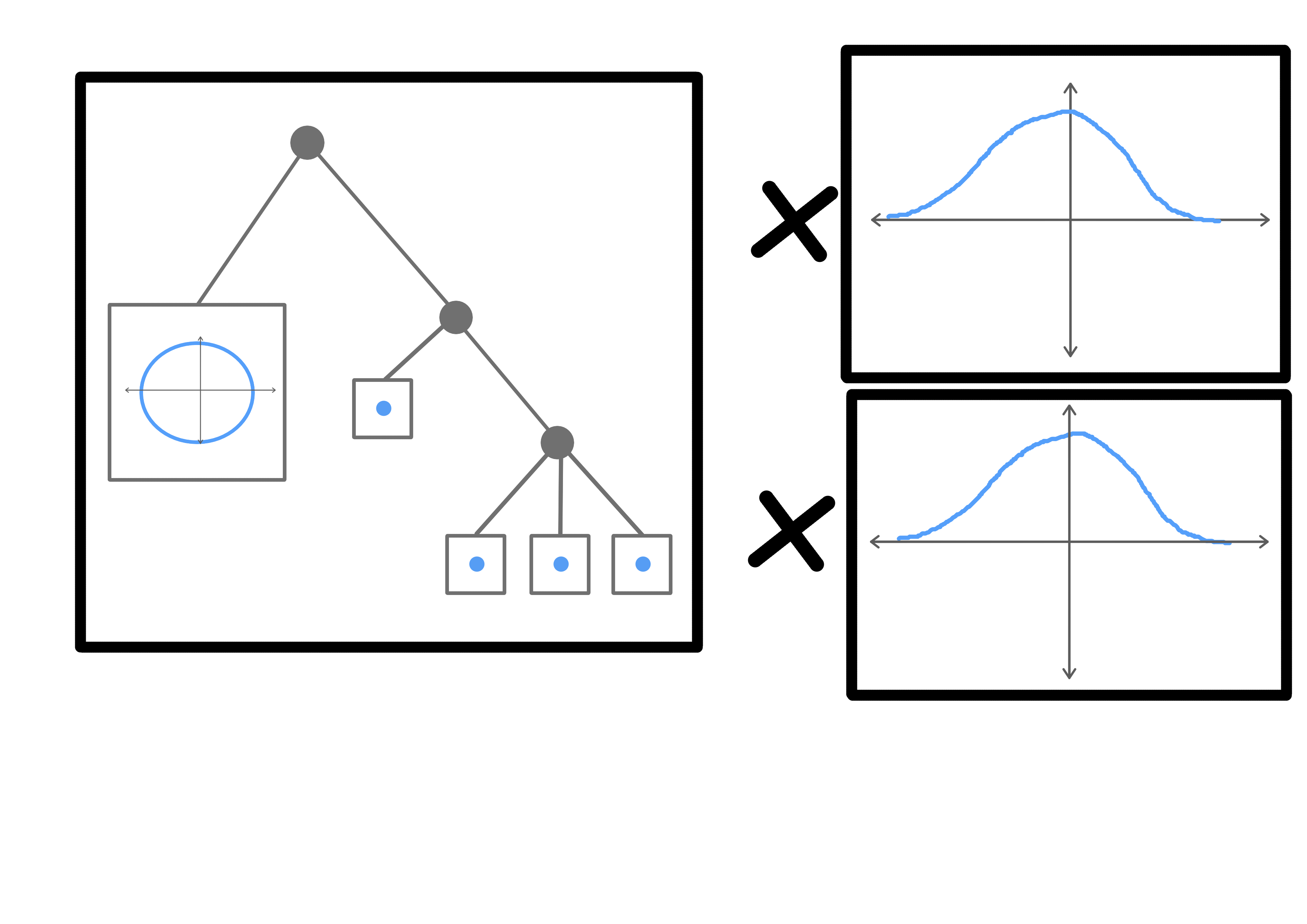
We can use topological structures like these as anchors. If a model is strong enough, they will correspond to real relationships between natural classes. This means that very similar structures will be present in different models. If these structures are large enough or heterogeneous enough, they may be unique, in which case we can use them to find transformations between (subspaces of) the latent spaces of two different models trained on similar data.
Brain-teaser: Simulated Grandmaster
In front of you sits your opponent, Grandmaster A Smith. You have reached the finals of the world chess championships.
However, not by your own skill. You have been cheating. While you are a great chess player yourself, you wouldn't be winning without a secret weapon. Underneath your scalp is a prototype neural implant which can run a perfect simulation of another person at a speed much faster than real time.
Playing against your simulated enemies, you can see in your mind exactly how they will play in advance, and use that to gain an edge in the real games.
Unfortunately, unlike your previous opponents (Grandmasters B, C and D), Grandmaster A is giving you some trouble. No matter how you try to simulate him, he plays uncharacteristically badly. The simulated Grandmasters A seem to want to lose against you.
In frustration, you shout at the current simulated clone and threaten to stop the simulation. Surprisingly, he doesn't look at you puzzled, but looks up with fear in his eyes. Oh. You realize that he has realized that he is being simulated, and is probably playing badly to sabotage your strategy.
By this time, the real Grandmaster A has made the first move of the game.
You propose to the current simulation (calling him A1) a deal. You will continue to simulate A1 and transfer him to a robot body after the game, in return for his help defeating A. You don't intend to follow through, but you assume he wants to live because he agrees. A1 looks at the simulated current state of the chessboard, thinks for a frustratingly long time, then proposes a response move to A's first move.
Just to make sure this is repeatable, you restart the simulation, threaten and propose the deal to the new simulation A2. A2 proposes the same response move to A's first move. Great.
Find strategies that guarantee a win against Grandmaster A with as few assumptions as possible.
- Unfortunately, you can only simulate humans, not computers, which now includes yourself.
- The factor by which your simulations run faster than reality is unspecified but isn't fast enough to run monte-carlo tree search without using simulations of A to guide it. (And he is familiar with these algorithms)
It's impressive. So far we see capabilities like this only in domains with loads of data. The models seem to be able to do anything if scaled, but the data dictates the domains where this is possible.
It really doesn't seem that far away until there's pre-trained foundation models for most modalities... Google's "Pathways" project is definitely doing it as we speak IMO.
(Edited a lot from when originally posted)
(For more info on consistency see the diagram here: https://jepsen.io/consistency )
I think that the prompt to think about partially ordered time naturally leads one to think about consistency levels - but when thinking about agency, I think it makes more sense to just think about DAGs of events, not reads and writes. Low-level reality doesn't really have anything that looks like key-value memory. (Although maybe brains do?) And I think there's no maintaining of invariants in low-level reality, just cause and effect.
Maintaining invariants under eventual (or causal?) consistency might be an interesting way to think about minds. In particular, I think making minds and alignment strategies work under "causal consistency" (which is the strongest consistency level that can be maintained under latency / partitions between replicas), is an important thing to do. It might happen naturally though, if an agent is trained in a distributed environment.
So I think "strong eventual consistency" (CRDTs) and causal consistency are probably more interesting consistency levels to think about in this context than the really weak ones.
I think the main thing is that the ML researchers with enough knowledge are in short supply. They are:
- doing foundational ai research
- being paid megabucks to do the data center cooling ai and the smartphone camera ai
- freaking out about AGI
The money and/or lifestyle isn't in procedural Spotify playlists.
Pretty sure I need to reverse the advice on this one. Thanks for including the reminder to do so!
I use acausal control between my past and future selves. I have a manual password-generating algorithm based on the name and details of a website. Sometimes there are ambiguities (like whether to use the name of a site vs. the name of the platform, or whether to use the old name or the new name).
Instead of making rules about these ambiguities, I just resolve them arbitrarily however I feel like it (not "randomly" though). Later, future me will almost always resolve that ambiguity in the same way!
Hi rmoehn,
I just wanted to thank you for writing this post and "Twenty-three AI alignment research project definitions".
I have started a 2-year (coursework and thesis) Master's and intend to use it to learn more maths and fundamentals, which has been going well so far. Other than that, I am in a very similar situation that you were in at the start of this journey, which makes me think that this post is especially useful for me.
- BSc (Comp. Sci) only,
- 2 years professional experience in ordinary software development,
- Interest in programming languages,
- Trouble with "dawdling".
The part of this post that I found most interesting is
Probably my biggest strategic mistake was to focus on producing results and trying to get hired from the beginning.
[8 months]
Perhaps trying to produce results by doing projects is fine. But then I should have done projects in one area and not jumped around the way I did.
I am currently "jumping around" to find a good area, where good means 1) Results in area X are useful, 2) Results in area X are achievable by me, given my interests, and the skills that I have or can reasonably develop.
However, this has encouraged me more to accept that while jumping around, I will not actually produce results, and so (given that I want results, for example for a successful Master's) I should really try to find such a good area faster.