Coordinate-Free Interpretability Theory
post by johnswentworth · 2022-09-14T23:33:49.910Z · LW · GW · 16 commentsContents
What Does Coordinate Freedom Mean? What Kind Of Coordinate Free Internal Structure Is Even Possible? Are There Any Other Coordinate Free Internal Structures? … So Now What? None 16 comments
Some interpretability work assigns meaning to activations of individual neurons or small groups of neurons. Some interpretability work assigns meaning to directions in activation-space. These are two different ontologies through which to view a net’s internals. Probably neither is really the “right” ontology, and there is at least one other ontology which would strictly outperform both of them in terms of yielding accurate interpretable structure.
One of the core problems of interpretability (I would argue the core problem) is that we don’t know what the “right” internal ontology is for a net - which internal structures we should assign meaning to. The goal of this post is to ask what things we could possibly assign meaning to under a maximally-general ontology constraint: coordinate freedom.
What Does Coordinate Freedom Mean?
Let’s think of a net as a sequence of activation-states , with the layer layer function given by .
We could use some other coordinate system to represent each . For instance, we could use (high dimensional) polar coordinates, with and a high-dimensional angle (e.g. all but one entry of a unit vector). Or, we could apply some fixed rotation to , e.g. in an attempt to find a basis which makes things sparse. In general, in order to represent in some other coordinate system, we apply a reversible transformation , where is the representation under the new coordinate system. In order to use these new coordinates while keeping the net the same overall, we transform the layer transition functions:
In English: we transform into the new coordinate system when calculating the layer state , and undo that transformation when computing the next layer state . That way, the overall behavior remains the same while using new coordinates in the middle
The basic idea of coordinate freedom is that our interpretability tools should not depend on which coordinate system we use for any of the internal states. We should be able to transform any layer to any coordinate system, and our interpretability procedure should still assign the same meaning to the same (transformed) internal structures.
What Kind Of Coordinate Free Internal Structure Is Even Possible?
Here’s one example of a coordinate free internal structure one could look for: maybe the layer function can be written as
for some low-dimensional . For instance, maybe and are both 512-dimensional, but can be calculated (to reasonable precision) from a 22-dimensional summary . We call this a low-dimensional “factorization” of .
(Side note: I’m assuming throughout this post that everything is differentiable. Begone, pedantic mathematicians; you know what you were thinking.)
This kind of structure is also easy to detect in practice: just calculate the singular vector decomposition of the jacobian at a bunch of points, and see whether the jacobian is consistently (approximately) low rank. In other words, do the obvious thing which we were going to do anyway.
Why is this structure coordinate free? Well, no matter how we transform and , so long as the coordinate changes are reversible, the transformed function will still factor through a low-dimensional summary. Indeed, it will factor through the same low-dimensional summary, up to isomorphism. We can also see the corresponding fact in the first-order approximation: we can multiply the jacobian on the left and right by any invertible matrix, its rank won’t change, and low-rank components will be transformed by the transformation matrices.
… and as far as local structure goes (i.e. first-order approximation near any given point), that completes the list of coordinate free internal structures. It all boils down to just that one (and things which can be derived/constructed from that one). Here’s the argument: by choosing our coordinate transformations, we can make the jacobian anything we please, so long as the rank and dimensions of the matrix stay the same. The rank is the only feature we can’t change.
But that’s only a local argument. Are there any other nonlocal coordinate free structures?
Are There Any Other Coordinate Free Internal Structures?
Let’s switch to the discrete case for a moment. Before we had mapping from a 512-dimensional space to a 512-dimensional space, but factoring through a 22-dimensional “summary”. A simple (and smaller) discrete analogue would be a function which maps the five possible values {1, 2, 3, 4, 5} to the same five values, but factors through a 2-value summary. For instance, maybe the function maps like this:

Coordinate freedom means we can relabel the 1, 2, 3, 4, 5 any way we please, on the input or output side. While maintaining coordinate freedom, we can still identify whether the function factors through some “smaller” intermediate set - in this case the set {“a”, “b”}. Are there any other coordinate free structures we can identify? Or, to put it differently: if two functions factor through the same intermediate sets, does that imply that there exists some reversible coordinate transformation between the two?
It turns out that we can find an additional structure. Here’s another function from {1, 2, 3, 4, 5} to itself, which factors through the same intermediate sets as our previous function, but is not equivalent under any reversible coordinate transformation:
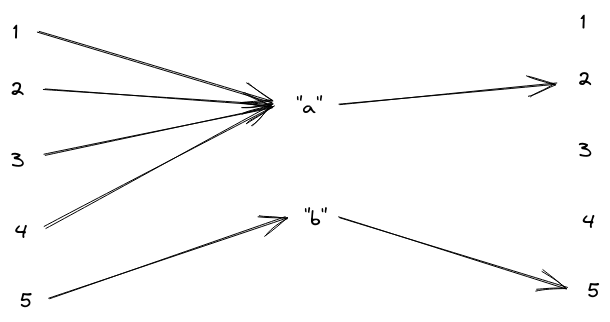
Why is this not equivalent? Well, no matter how we transform the input set in the first function, we’ll always find that three input values map to one output value, and the other two input values map to another output value. The “level sets” - i.e. sets of inputs which map to the same output - have size 3 and 2, no matter what coordinates we use. Whereas, for the second function, the level sets have size 4 and 1.
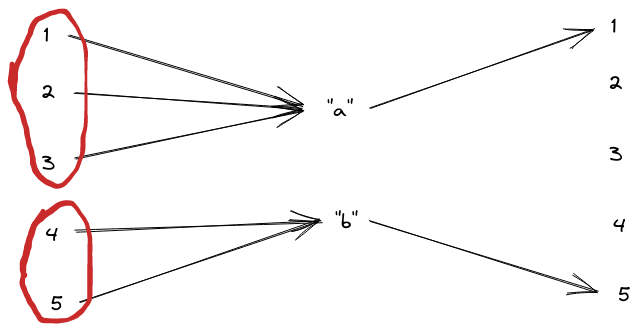
Does that complete the list of coordinate free internal structures in the discrete case? Yes: if we have two functions with the same level set sizes, whose input and output spaces are the same size, then we can reversibly map between them. Just choose the coordinate transformation to match up level sets of the same size, and then match up the corresponding outputs.
Ok, so that’s the discrete case. Switching back to the continuous case (and bringing back the differentiable transformation constraint), what other coordinate free internal structure might exist in a net?
Well, in the continuous case, “size of the level set” isn’t really relevant, since e.g. we can reversibly map the unit interval to the real line. But, since our transformations need to be smooth, topology is relevant - for instance, if the set of inputs which map to 0 is 1 dimensional, is it topologically a circle? A line? Two circles and a line? A knot?
Indeed, “structure which is invariant under smooth reversible transformation” is kinda the whole point of topology! Insofar as we want our interpretability tools to be coordinate free, topological features are exactly the structures to which we can try to assign meaning.
Great, we’ve reinvented topology.
… So Now What?
There are some nontrivial things we can build up just from low-dimensional summaries between individual layers and topological features. But ultimately, I don’t expect to unlock most of interpretability this way. I’d guess that low-dimensional summaries of the particular form relevant here unlock a bit less than half of interpretability (i.e. all the low-rank stuff, along the lines of the Rome paper), and other topological structures add a nonzero but small chunk on top of that. (For those who are into topology, I strongly encourage you to prove me wrong!) What's missing? Well, for instance, one type of structure which should definitely play a big role in a working theory of interpretability is sparsity. With full coordinate freedom, we can always choose coordinates in which the layer functions are sparse, and therefore we gain no information by finding sparsity in a net.
So let’s assume we can’t get everything we want from pure coordinate free interpretability. Somehow, we need to restrict allowable transformations further. Next interesting question: where might a preferred coordinate system or an additional restriction on transformations come from?
One possible answer: the data. We’ve implicitly assumed that we can apply arbitrary coordinate transformations to the data, but that doesn’t necessarily make sense. Something like a stream of text or an image does have a bunch of meaningful structure in it (like e.g. nearby-ness of two pixels in an image) which would be lost under arbitrary transformations. So one natural next step is to allow coordinate preference to be inherited from the data. On the other hand, we’d be importing our own knowledge of structure in the data; really, we’d prefer to only use the knowledge learned by the net.
Another possible answer: the initialization distribution of the net parameters. For instance, there will always be some coordinate transformation which makes every layer sparse, but maybe that transformation is highly sensitive to the parameter values. That would indicate that any interpretation which relies on that coordinate system is not very robust; some small change in theta which leaves network behavior roughly the same could totally change the sparsifying coordinate system. To avoid that, we could restrict ourselves to transformations which are not very parameter-sensitive. I currently consider that the most promising direction.
The last answer I currently see is SGD. We could maybe argue that SGD introduces a preferred coordinate system, but then the right move is to probably look at the whole training process in a coordinate free way rather than just the trained net by itself. That does sound potentially useful, although my guess is that it mostly just reproduces the parameter-sensitivity thing.
Meta note: I’d be surprised if the stuff in this post hasn’t already been done; it’s one of those things where it’s easy and obvious enough that it’s faster to spend a day or two doing it than to find someone else who’s done it. If you know of a clean write-up somewhere, please do leave a link, I’d like to check whether I missed anything crucial.
16 comments
Comments sorted by top scores.
comment by Jacob_Hilton · 2022-09-15T05:26:48.868Z · LW(p) · GW(p)
The notion of a preferred (linear) transformation for interpretability has been called a "privileged basis" in the mechanistic interpretability literature. See for example Softmax Linear Units, where the idea is discussed at length.
In practice, the typical reason to expect a privileged basis is in fact SGD – or more precisely, the choice of architecture. Specifically, activation functions such as ReLU often privilege the standard basis. I would not generally expect the data or the initialization to privilege any basis beyond the start of the network or the start of training. The data may itself have a privileged basis, but this should be lost as soon as the first linear layer is reached. The initialization is usually Gaussian and hence isotropic anyway, but if it did have a privileged basis I would also expect this to be quickly lost without some other reason to hold onto it.
Replies from: johnswentworth, tailcalled↑ comment by johnswentworth · 2022-09-15T16:39:38.325Z · LW(p) · GW(p)
Yeah, I'm familiar with privileged bases. Once we generalize to a whole privileged coordinate system, the RELUs are no longer enough.
Isotropy of the initialization distribution still applies, but the key is that we only get to pick one rotation for the parameters, and that same rotation has to be used for all data points. That constraint is baked in to the framing when thinking about privileged bases, but it has to be derived when thinking about privileged coordinate systems.
↑ comment by tailcalled · 2022-09-15T07:46:05.215Z · LW(p) · GW(p)
The data may itself have a privileged basis, but this should be lost as soon as the first linear layer is reached.
Not totally lost if the layer is e.g. a convolutional layer, because while the pixels within the convolutional window can get arbitrarily scrambled, it is not possible for a convolutional layer to scramble things across different windows in different parts of the picture.
Replies from: Jacob_Hilton↑ comment by Jacob_Hilton · 2022-09-15T16:03:49.669Z · LW(p) · GW(p)
Agreed. Likewise, in a transformer, the token dimension should maintain some relationship with the input and output tokens. This is sometimes taken for granted, but it is a good example of the data preferring a coordinate system. My remark that you quoted only really applies to the channel dimension, across which layers typically scramble everything.
comment by Maxwell Clarke (maxwell-clarke) · 2022-09-18T07:01:36.597Z · LW(p) · GW(p)
I think we can get additional information from the topological representation. We can look at the relationship between the different level sets under different cumulative probabilities. Although this requires evaluating the model over the whole dataset.
Let's say we've trained a continuous normalizing flow model (which are equivalent to ordinary differential equations). These kinds of model require that the input and output dimensionality are the same, but we can narrow the model as the depth increases by directing many of those dimensions to isotropic gaussian noise. I haven't trained any of these models before, so I don't know if this works in practice.
Here is an example of the topology of an input space. The data may be knotted or tangled, and includes noise. The contours show level sets .
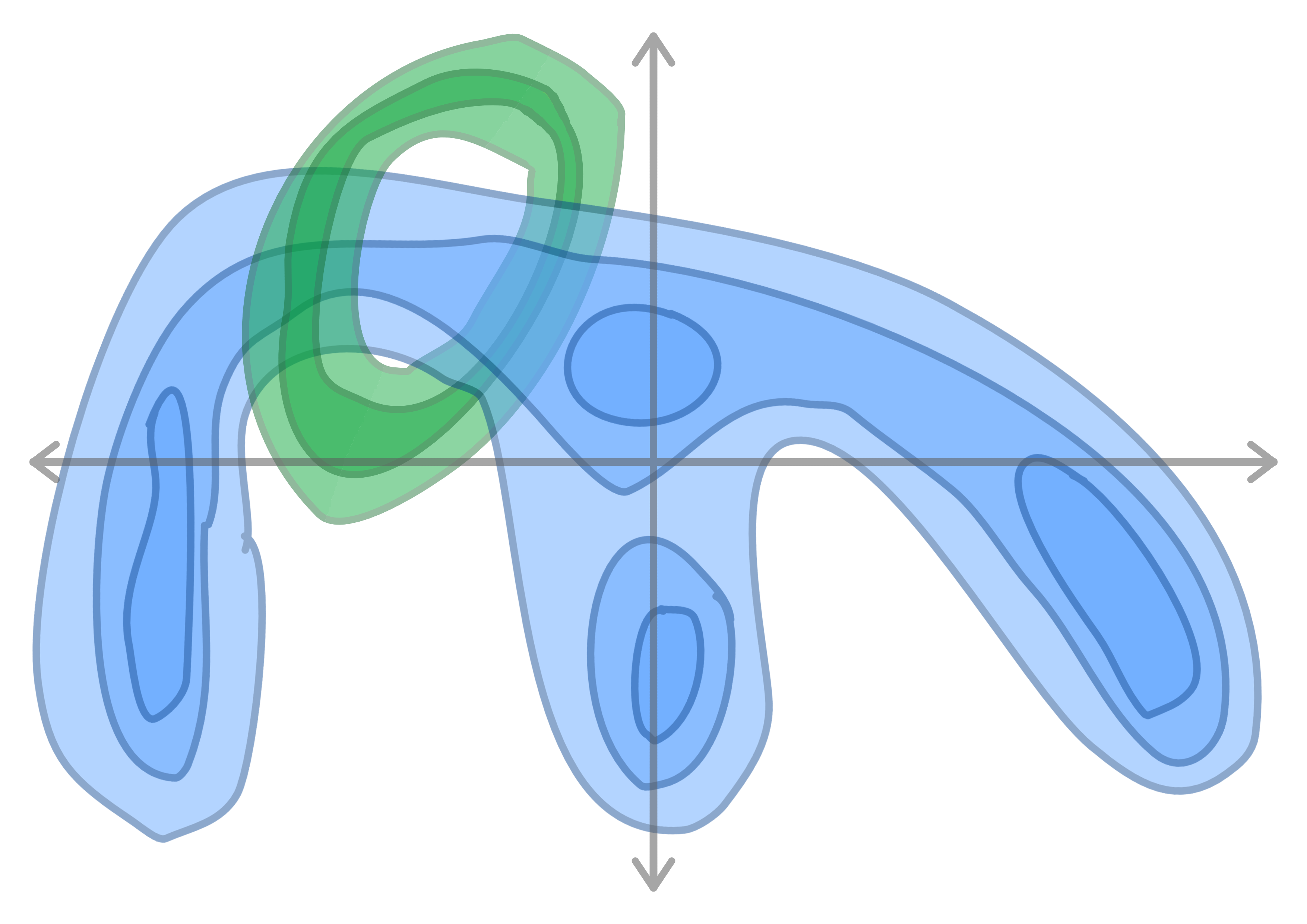
The model projects the data into a high dimensionality, then projects it back down into an arbitrary basis, but in the process untangling knots. (We can regularize the model to use the minimum number of dimensions by using an L1 activation loss
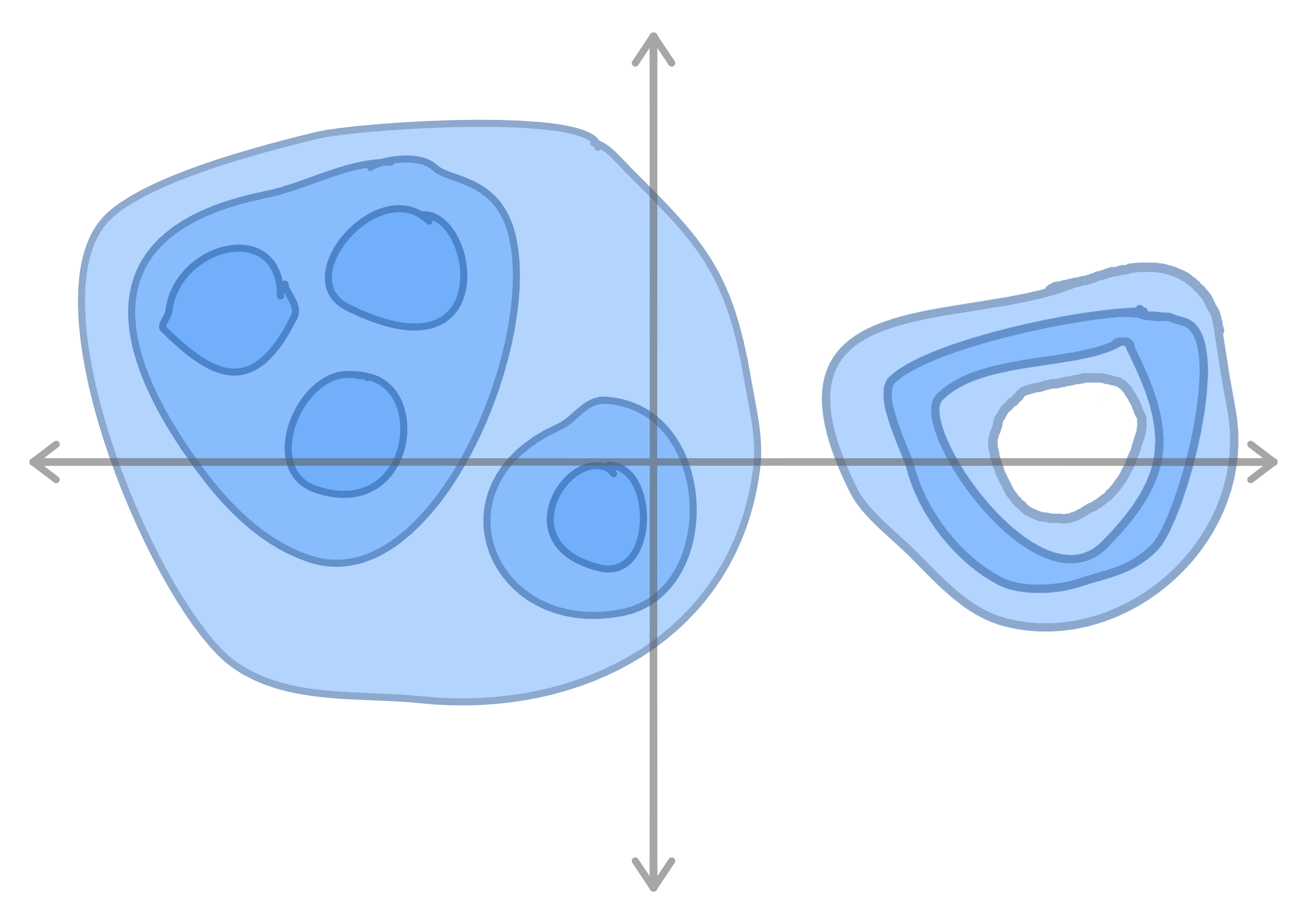
Lastly, we can view this topology as the Cartesian product of noise distributions and a hierarchical model. (I have some ideas for GAN losses that might be able to discover these directly)
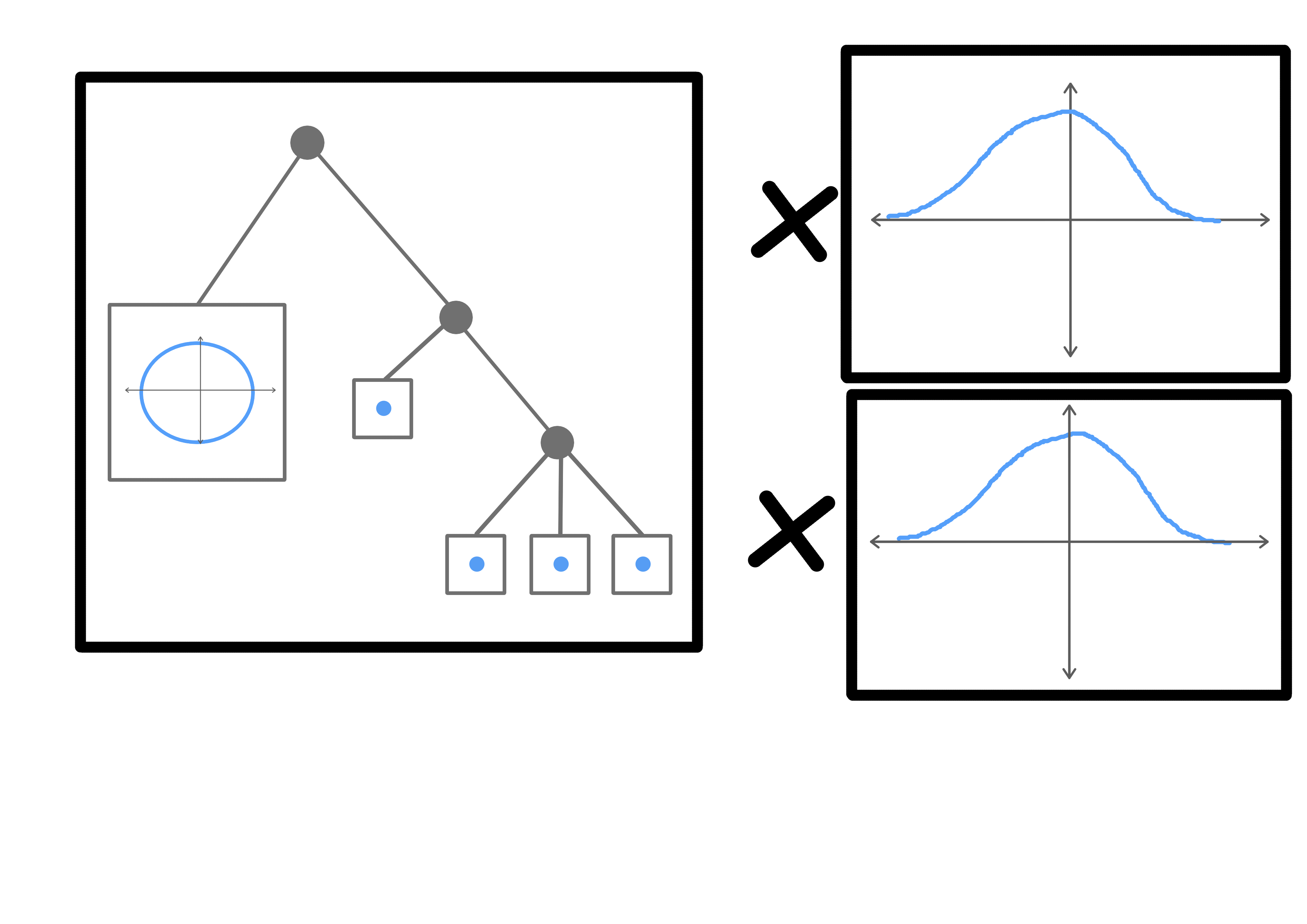
We can use topological structures like these as anchors. If a model is strong enough, they will correspond to real relationships between natural classes. This means that very similar structures will be present in different models. If these structures are large enough or heterogeneous enough, they may be unique, in which case we can use them to find transformations between (subspaces of) the latent spaces of two different models trained on similar data.
comment by Zach Furman (zfurman) · 2023-03-22T04:10:32.125Z · LW(p) · GW(p)
Since nobody here has made the connection yet, I feel obliged to write something, late as I am.
To make the problem more tractable, suppose we restrict our set of coordinate changes to ones where the resulting functions can still (approximately) be written as a neural network. (These are usually called "reparameterizations.") This occurs when multiple neural networks implement (approximately) the same function; they're redundant. One trivial example of this is the invariance of ReLU networks to scaling one layer by a constant, and the next layer by the inverse of that constant.
Then, in the language of parametric statistics, this phenomenon has a name: non-identifiability! Lucky for us, there's a decent chunk of literature on identifiability in neural networks out there. At first glance, we have what seems like a somewhat disappointing result: ReLU networks are identifiable up to permutation and rescaling symmetries.
But there's a catch - this is only true except for a set of measure zero. (The other catch is that the results don't cover approximate symmetries.) This is important because there are reasons to suggest real neural networks are pushed close to this set during training. This set of measure zero corresponds to "reducible" or "degenerate" neural networks - those that can be expressed with fewer parameters. And hey, funny enough, aren't neural networks quite easily pruned?
In other parts of the literature, this problem has been phrased differently, under the framework of "structure-function symmetries" or "canonicalization." It's also often covered when discussing the concepts of "inverse stability" and "stable recovery." For more on this, including a review of the literature, I highly recommend Matthew Farrugia-Roberts' excellent master's thesis on the topic.
(Separately, I'm currently working on the issue of coordinate-free sparsity. I believe I have a solution to this - stay tuned, or reach out if interested.)
Replies from: johnswentworth↑ comment by johnswentworth · 2023-03-22T04:16:54.554Z · LW(p) · GW(p)
That's a great connection which I had indeed not made, thanks! Strong-upvoted.
comment by mtaran · 2022-09-15T00:43:20.128Z · LW(p) · GW(p)
No super detailed references that touch on exactly what you mention here, but https://transformer-circuits.pub/2021/framework/index.html does deal with some similar concepts with slightly different terminology. I'm sure you've seen it, though.
comment by tailcalled · 2022-09-15T07:52:57.574Z · LW(p) · GW(p)
One possible answer: the data. We’ve implicitly assumed that we can apply arbitrary coordinate transformations to the data, but that doesn’t necessarily make sense. Something like a stream of text or an image does have a bunch of meaningful structure in it (like e.g. nearby-ness of two pixels in an image) which would be lost under arbitrary transformations. So one natural next step is to allow coordinate preference to be inherited from the data. On the other hand, we’d be importing our own knowledge of structure in the data; really, we’d prefer to only use the knowledge learned by the net.
It's worth remembering that we often import our own knowledge of the data in when designing the nets too, e.g. convolutional layers for image processing respect exactly this kind of locality.
Also, one piece of structure that will always be present in the data regardless if it is images or text or whatever is that it is separated into data points. So one could e.g. think about whether there's a low-dimensional summary or tangent space for each data point that describes the network's behavior on it in an interpretable way (though one difficulty with this is that networks are typically not robust, so even tiny changes could completely change the classification).
Replies from: johnswentworth↑ comment by johnswentworth · 2022-09-15T16:46:06.833Z · LW(p) · GW(p)
Yup, I'm ideally hoping for a framework which automatically rediscovers any architectural features like that. For instance, one reason I think the parameter-sensitivity thing is promising is that it can automatically highlight architectural sparsity patterns, like e.g. the sort induced by convolutional layers.
Replies from: tailcalled↑ comment by tailcalled · 2022-09-15T16:55:17.279Z · LW(p) · GW(p)
I think one major challenge with convolutions is that they are translation-invariant. It's not just an architectural sparsity pattern, the sparsity pattern also has a huge number of symmetries. But automatically discovering those symmetries seems difficult in general.
(And this gets even more difficult when the symmetries only make sense from a bigger picture view, e.g. as I recall Chris Olah discovered 3D symmetries based on perspective, like street going left vs right, but they weren't enforced architecturally.)
comment by Lucius Bushnaq (Lblack) · 2022-09-15T11:17:22.339Z · LW(p) · GW(p)
Curious how looking at properties of the functions the embed through their activation patterns fits into this picture.
For example, take the L2 norms of the activations of all entries of , averaged over some set of network inputs. The sum and product of those norms will both be coordinate independent.
In fact, we can go one step further, and form , the matrix of the L2 inner products of all the layer base elements with each other. The eigendecomposition of this matrix is also coordinate independent, up to degeneracy in the eigenvalues.
(This eigenbasis also sure looks like a uniquely determined basis to me)
You can think of these quantities as measures of the number of "unique" activation patterns and their "size" that exist in the layer.
In your framing, does this correspond to adding in topological information from all the previous layers, through the mapping ?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-09-15T16:43:50.273Z · LW(p) · GW(p)
For example, take the L2 norms of the activations of all entries of , averaged over some set of network inputs. The sum and product of those norms will both be coordinate independent.
That would be true if the only coordinate changes we consider are rotations. But the post is talking about much more general transformations than that - we're allowing not only general linear transformations (i.e. stretching in addition to rotations), but also nonlinear transformations (which is why RELUs don't give a preferred coordinate system).
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-09-15T18:50:22.042Z · LW(p) · GW(p)
Ah, right, you did mention polar coordinates.
Hm, stretching seems handleable. How about also using the weight matrix, for example? Change into the eigenbasis above, then apply stretching to make all L2 norms size 1 or size 0. Then look at the weights, as stretching-and-rotation invariant quantifiers of connectedness?
Maybe doesn't make much sense when considering non-linear transformations though.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-09-15T19:24:39.532Z · LW(p) · GW(p)
I think that's the same as finding a low-rank decomposition, assuming I correctly understand what you're saying?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-09-19T12:10:03.249Z · LW(p) · GW(p)
Sai, who is a lot more topology-savy than me, now suspects that there is indeed a connection between this norm approach and the topology of the intermediate set. We'll look into this.