My tentative interpretability research agenda - topology matching.
post by Maxwell Clarke (maxwell-clarke) · 2022-10-08T22:14:05.641Z · LW · GW · 2 commentsContents
TL;DR
Topology visualizations
The core idea: Topology matching
Background
Datasets as "empirical" probability distributions
Auto-encoders
(Adversarially-regularized?) Flow Auto-encoders
None
2 comments
I'm looking for feedback on these ideas before I start working on them in November.
The goal of interpretability is to understand representations, and to be able to translate between them. This idea tries to discover translations between the representations of two neural networks, but without necessarily discovering a translation into our representations.
TL;DR
Learn auto-encoders in such a way that we know the learned topology of the latent space. Use those topologies to relate the latent spaces of two or more such auto-encoders, and derive (linear?) transformations between the latent spaces. This should work without assuming any kind of privileged basis.
My biggest uncertainty is about whether any of my various approaches to not constraining the topology will work. We have to discover the topology, but still know it afterwards.
Note: I've put the background section at the end. If you are confused I recommend reading that first.
Topology visualizations
Here is an example of the topology of an input space. The data may be knotted or tangled, and includes noise. The contours show level sets , i.e. each boundary is a D-1 dimensional manifold of equal probability density.
Input space (3D)
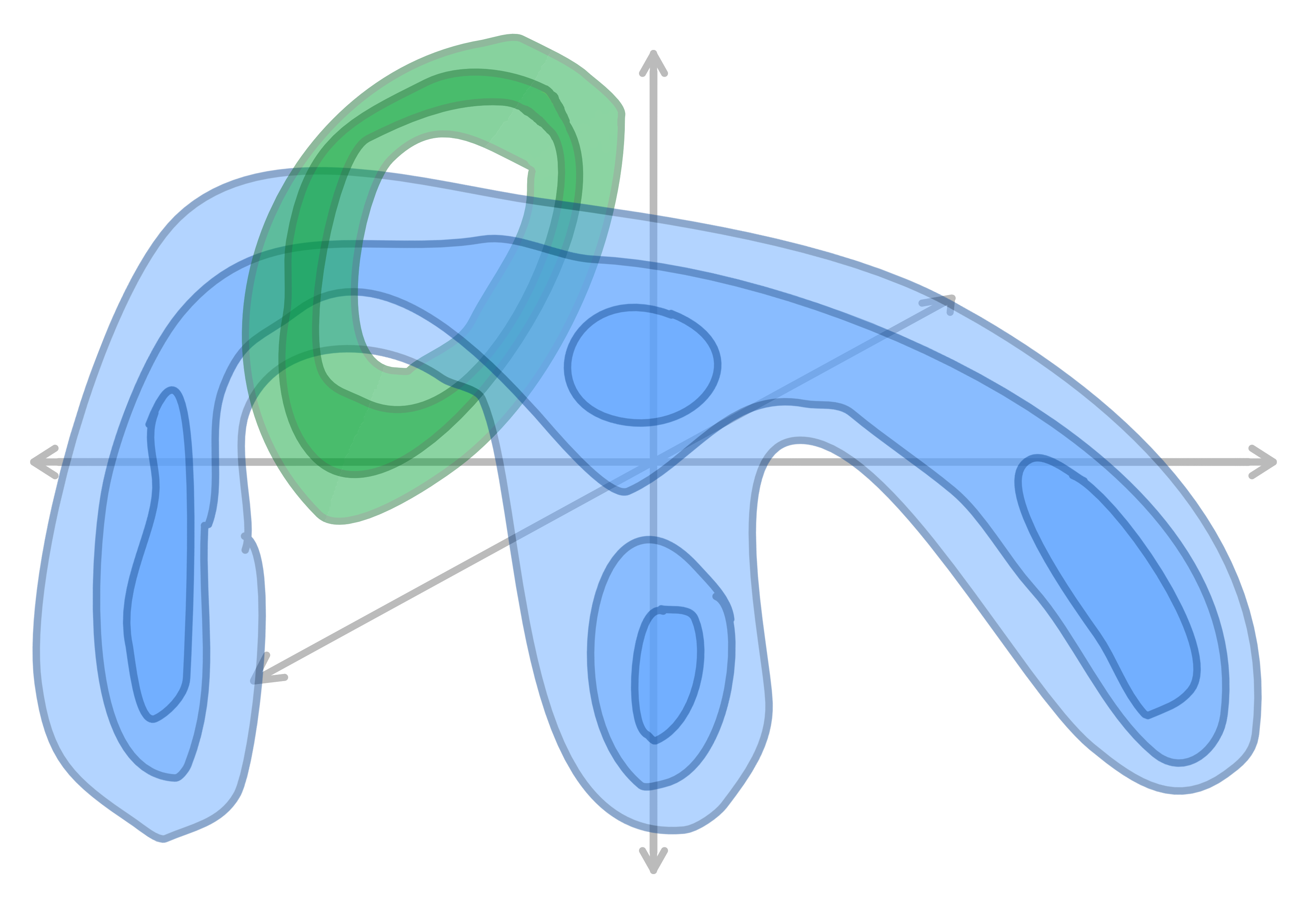
The model projects the data into a new, arbitrary basis, and passes it through some kind of volume-preserving non-linearity. (eg. an ODE, see Continuous Normalizing Flows) We regularize one of the dimensions to be isotropic Gaussian noise, and elide it in the below image. We now see all the information represented in just two dimensions. The topology hasn't changed!
Latent space (2D) - one dimension is just Gaussian and is "removed" prior to the latent space.
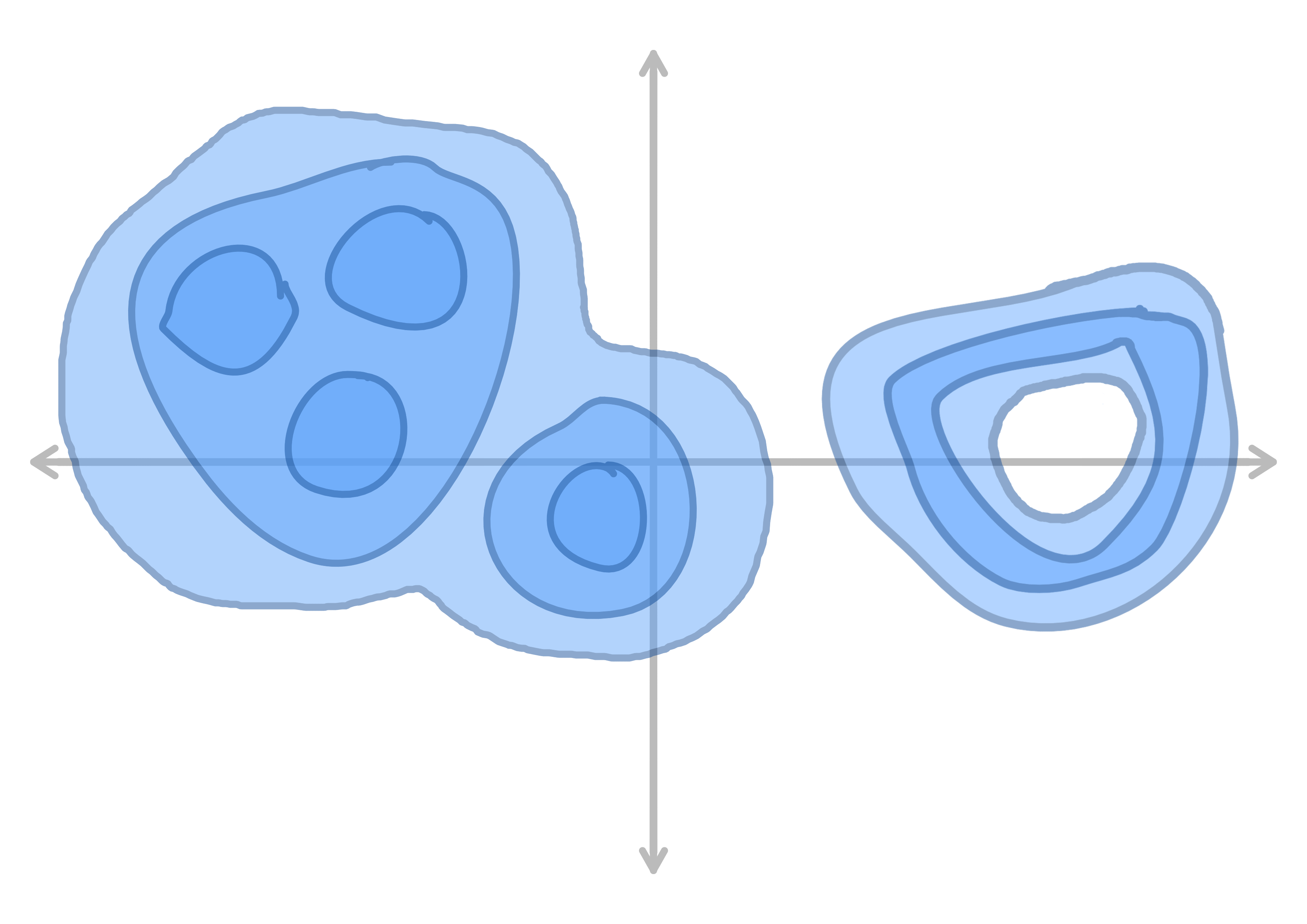
See how the level sets always form a tree?? We can view this topology as the Cartesian product of noise distributions and a hierarchical model.
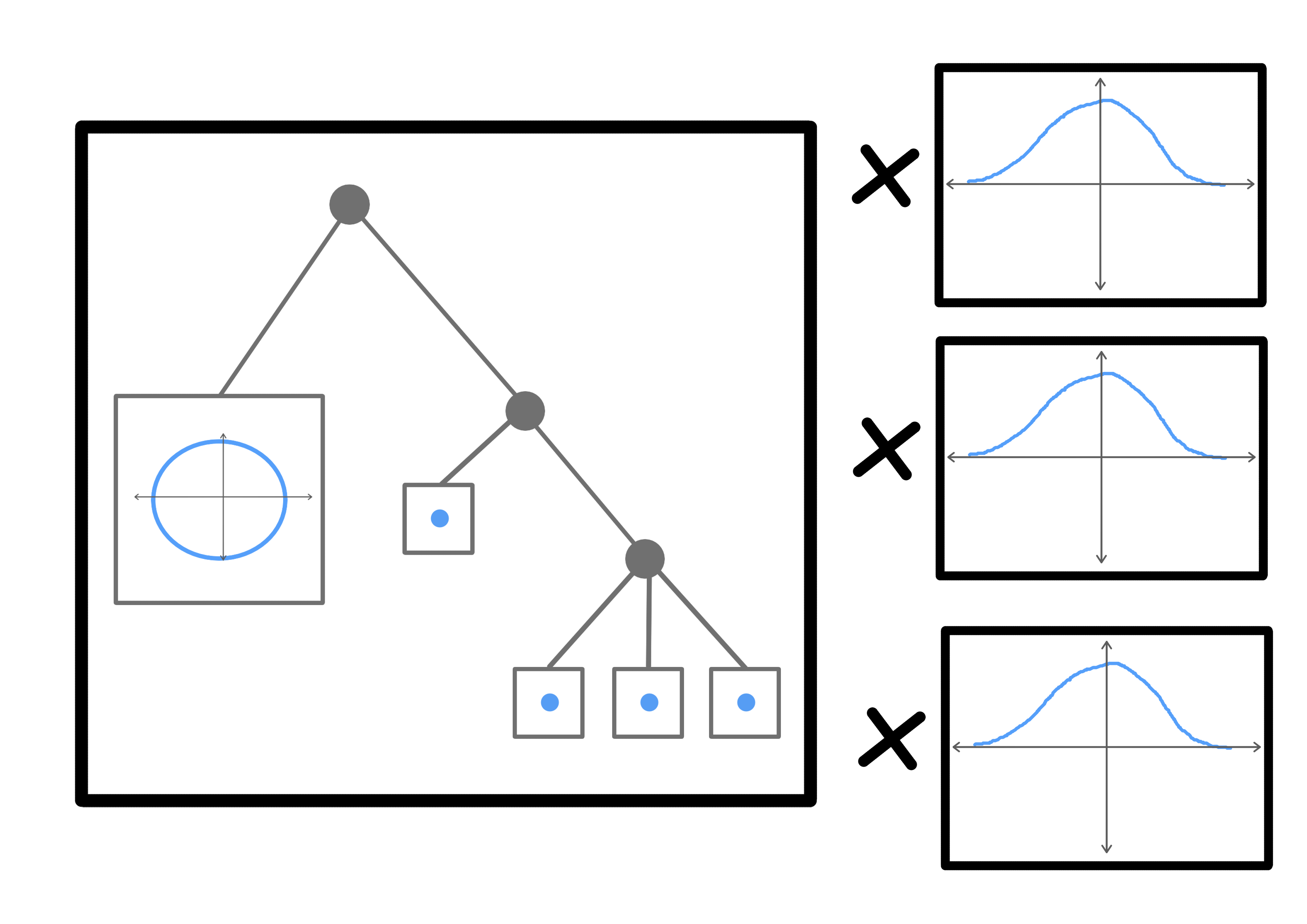
The core idea: Topology matching
If we can discover the hierarchical model above, we can match it to that of another model based on the tree structure. These trees will correspond to real relationships between natural classes/variables in the dataset! If these structures are large enough or heterogeneous enough, they may have structure that occurs across multiple domains.
If we relate (or partially relate) the two hierarchies, then we can derive a transformation between the latent spaces, without using any privileged basis at all.
We can also create some kind of transformation between these latent spaces and something actually meaningful for humans.
Background
I'm first going to explain the interpretation I'm taking on data manifolds etc., and second explaining actual model classes that we can use in order to get some of these guarantees.
Datasets as "empirical" probability distributions
We can picture a dataset in the following way:
- There are N examples, which are vectors "x", which are D-dimensional.
- For MNIST, N=60000, x is a single images, and D=784
- Every example "x_i" is a point in a D-dimensional space.
- The dataset is a point cloud of many points in the D-dimensional space. If we imagine a continuous cloud in this space, which has density in the regions where there are points, we can see how a dataset can be considered an empirical approximation to a probability distribution.
- The point cloud does not cover all of the D-dimensional space.
- For images, a dataset which covered the entire space would need to be almost entirely made of images that look like random noise.
- The hyper-volume within the D-dimensional space that the point cloud does cover is typically (approximately) significantly lower dimensional than D. We call this the data manifold.
- Even on the data manifold, especially for images, most of the hyper-volume is taken up by noise, and the interesting information is then lower dimensional again.
Auto-encoders
- Auto-encoders are networks that attempt to discover this manifold of interesting information, by pushing the data in and out of a low-dimensional bottleneck, which we call the latent space.
- I don't like variational auto-encoders for many reasons and you can assume I'm not talking about them. Instead I'm talking about either "plain" auto-encoders, or adversarially-regularized auto-encoders.
- If we train two auto-encoders on the same data, can we systematically (and ideally, tractably) analyze the point clouds in their latent spaces and find a translation between those latent spaces? (By methods other than just blindly learning!)
- What restrictions can we place on the models so that we get more guarantees about the behaviour, and can utilize more assumptions when trying to find the mapping?
(Adversarially-regularized?) Flow Auto-encoders
- Auto-encoder: We want to do representation learning and form a low-dimensional latent space.
- Flow: We want to be always able to interpret activations throughout the network as points drawn from some distribution. We can restrict the model class so that this interpretation is always valid by making it a flow model. This limits transformations to ones with a determinant of 1, ie. ones that preserve the "volume" (I'm forgetting the right word here) of the probability distribution.
- Flow models can't change the input dimensionality. To construct an auto-encoder therefore, we direct most of the dimensions off to noise in the encoder, and then sample from those distributions in the generator.
- Adversarially-regularized: We need to introduce an explicit (analytic) probability distribution interpretation so that we can evaluate the probability density. We can regularize the activations in the latent layer during training, to constrain them into a particular distribution.
However, an here is my biggest uncertainty with this idea: we have to do so without imposing (too many) constraints on the topology of the manifold in the latent space.
Some ways we might do this (regularize the latent activations to a probability distribution with a closed form density, without constraining the topology):- There are some variants of adversarial auto encoders that allow one to learn the distribution which the latent space is being constrained to.
- We use a big Gaussian mixture, which can approximate most topologies.
- I have a fuzzy idea for a model that can be regularized by a "superposition" of distributions of different topologies.
- We can do a big hyper-parameter search over distribution types and assume that the distribution classes with the lowest adversarial loss are the ones that most faithfully match the natural topology of the manifold.
If we combine these elements we get a model that:
- Learns a low-dimensional latent space
- In which the activations can be directly interpreted as points in a distribution.
- Where we can evaluate the probability density, because we also have a richer interpretation of the latent space as a probability distribution, because we constrained the model into it.
2 comments
Comments sorted by top scores.
comment by alexlyzhov · 2022-10-19T02:16:50.803Z · LW(p) · GW(p)
This idea tries to discover translations between the representations of two neural networks, but without necessarily discovering a translation into our representations.
I think this has been under investigation for a few years in the context of model fusion in federated learning, model stitching, and translation between latent representations in general.
Relative representations enable zero-shot latent space communication - an analytical approach to matching representations (though this is a new work, it may be not that good, I haven't checked)
Git Re-Basin: Merging Models modulo Permutation Symmetries - recent model stitching work with some nice results
Latent Translation: Crossing Modalities by Bridging Generative Models - some random application of unsupervised translation to translation between autoencoder latent codes (probably not the most representative example)
↑ comment by Maxwell Clarke (maxwell-clarke) · 2022-10-19T11:51:30.046Z · LW(p) · GW(p)
Thanks for these links, especially the top one is pretty interesting work