The "public debate" about AI is confusing for the general public and for policymakers because it is a three-sided debate
post by Adam David Long (adam-david-long-1) · 2023-08-01T00:08:30.908Z · LW · GW · 30 commentsContents
Example: the recent Munk Debate showed a team of "doomers" arguing with a mixed team of one booster and one realist Thought experiment: other debates. None 30 comments
Summary of Argument: The public debate among AI experts is confusing because there are, to a first approximation, three sides, not two sides to the debate. I refer to this as a 🔺three-sided framework, and I argue that using this three-sided framework will help clarify the debate (more precisely, debates) for the general public and for policy-makers.
Broadly speaking, under my proposed 🔺three-sided framework, the positions fall into three broad clusters:
- AI "pragmatists" or realists are most worried about AI and power. Examples of experts who are (roughly) in this cluster would be Melanie Mitchell, Timnit Gebru, Kate Crawford, Gary Marcus, Klon Kitchen, and Michael Lind. For experts in this group, the biggest concern is how the use of AI by powerful humans will harm the rest of us. In the case of Gebru and Crawford, the "powerful humans" that they are most concerned about are large tech companies. In the case of Kitchen and Lind, the "powerful humans" that they are most concerned about are foreign enemies of the U.S., notably China.
- AI "doomers" or extreme pessimists are most worried about AI causing the end of the world. @Eliezer Yudkowsky [LW · GW] is, of course, the most well-known to readers of LessWrong but other well-known examples include Nick Bostrom, Max Tegmark, and Stuart Russell. I believe these arguments are already well-known to readers of LessWrong, so I won't repeat them here.
- AI "boosters" or extreme optimists are most worried that we are going to miss out on AI saving the world. Examples of experts in this cluster would be Marc Andreessen, Yann LeCun, Reid Hoffman, Palmer Luckey, Emad Mostaque. They believe that AI can, to use Andreessen's recent phrase, "save the world," and their biggest worry is that moral panic and overregulation will create huge obstacles to innovation.
These three positions are such that, on almost every important issue, one of the positions is opposed to a coalition of the other two of the positions
- AI Doomers + AI Realists agree that AI poses serious risks and that the AI Boosters are harming society by downplaying these risks
- AI Realists + AI Boosters agree that existential risk should not be a big worry right now, and that AI Doomers are harming society by focusing the discussion on existential risk
- AI Boosters and AI Doomers agree that AI is progressing extremely quickly, that something like AGI is a real possibility in the next few years, and that AI Realists are harming society by refusing to acknowledge this possibility
Why This Matters. The "AI Debate" is now very much in the public consciousness (in large part, IMHO, due to the release of ChatGPT), but also very confusing to the general public in a way that other controversial issues, e.g. abortion or gun control or immigration, are not. I argue that the difference between the AI Debate and those other issues is that those issues are, essentially two-sided debates. That's not completely true, there are nuances, but, in the public's mind at their essence, they come down to two sides.
To a naive observer, the present AI debate is confusing, I argue, because various experts seem to be talking past each other, and the "expert positions" do not coalesce into the familiar structure of a two-sided debate with most experts on one side or the other. When there are three sides to a debate, then one fairly frequently sees what look like "temporary alliances" where A and C are arguing against B. They are not temporary alliances. They are based on principles and deeply held beliefs. It's just that, depending on how you frame the question, you wind up with "strange bedfellows" as two groups find common ground on one issue even though they are sharply divided on others.
Example: the recent Munk Debate showed a team of "doomers" arguing with a mixed team of one booster and one realist
The recent Munk Debate on AI and existential risk illustrates the three-sided aspect of the debates and how, IMHO the 🔺three-sided framework can help make sense of the conflict.
To summarize, Yoshua Bengio and Max Tegmark argued that “AI research and development poses an existential threat.” In other words, what I'm calling the “AI Doomer” position.
Arguing for the other side was a team made up of Yann LeCun and Melanie Mitchell. When I first listened to the debate, I thought both Mitchell and LeCun made strong arguments, but I found it hard to make their arguments fit together.
But after applying the 🔺three-sided framework, it appeared to me that LeCun and Mitchell were both strongly opposed to the “doomer” position but for very different reasons.
LeCun, as an 🚀 AI Booster, argued for the vast potential and positive impact of AI. He acknowledged challenges but saw these as technical issues to be resolved rather than insurmountable obstacles or existential threats. He argued for AI as a powerful tool that can improve society and solve complex problems.
On the other hand, Mitchell, representing the ⚖️ AI Realist perspective, questioned whether, in the near term, AI could ever reach a stage where it could pose an existential threat. While she agreed that AI presents risks, she argued that the most important risks are related to immediate, tangible concerns like job losses or the spread of disinformation.
Analyzed under the 🔺three-sided framework, then, the Munk Debate was between:
An “All Doomer” team of Bengio and Tegmark, each making Doomer arguments; versus
A “Mixed Realist/Booster” team of “Realist” Mitchell making Realist anti-Doomer arguments and “Booster” LeCun, making Booster anti-Doomer arguments.
Thought experiment: other debates.
- Let's imagine another debate on the question "at this stage over-regulation of AI is a much bigger threat to humanity than under-regulation." My take is that the people taking what I'm calling the AI Booster position, such as Marc Andreessen, Yan LeCun, Reid Hoffman, would agree with this proposition. While both the AI Doomers, such as Yudkowsky, Bostrom, Soares, and the AI Realists, such as Melanie Mitchell and Timnit Gebru would agree that under regulation is a greater danger
- Yet another debate could be on the question: "We are likely to see something like AGI in the next 5 years" Here, the Realists -- many of whom believe that claims for AI are vastly overhype -- would argue the "no" side, while both the Booster and the Doomers would team up against the Realists to argue that yes, AGI is likely in the relatively near term.
30 comments
Comments sorted by top scores.
comment by lewis smith (lsgos) · 2023-08-01T08:58:31.629Z · LW(p) · GW(p)
I think there's some truth to this framing, but I'm not sure that people's views cluster as neatly as this. In particular, I think there is a 'how dangerous is existential risk' axis and a 'how much should we worry about AI and Power' axis. I think you rightly identify the 'booster' cluster (x-risk fake, AI +power nothing to worry about) and 'realist' (x-risk sci-fi, AI + power very concerning) but I think you are missing quite a lot of diversity in people's positions along other axes that make this arguably even more confusing for people. For example, I would characterise Bengio as being fairly concerned about both x-risk and AI+power, wheras Yudkowsky is extremely concerned about x-risk and fairly relaxed about AI+power.
I also think it's misleading to group even 'doomers' as one cluster because there's a lot of diversity in the policy asks of people who think x-risk is a real concern, from 'more research needed' to 'shut it all down'. One very important group you are missing are people who are simultaneously quite (publicly) concerned about x-risk, but also quite enthusiastic about pursuing AI development and deployment. This group is important because it includes Sam Altman, Dario Amodei and Demis Hassabis (leadership of the big AI labs), as well as quite a lot people who work developing AI or work on AI safety. You might summarise this position as 'AI is risky, but if we get it right it will save us all'. As they are often working at big tech, I think these people are mostly fairly un-worried or neutral about AI + power. This group is obviously important because they work directly on the technology, but also because this gives them a loud voice in policy and the public sphere. You might think of this as a 'how hard is mitigating x-risk' axis. This is another key source of disagreement : going from public statements alone, I think (say) Sam Altman and Eliezer Yudkowsky agree on the 'how dangerous' axis and are both fairly relaxed Silicon Valley libertarians on the 'AI+power' axis, and mainly disagree on how difficult is it to solve x-risk. Obviously people's disagreements on this question have a big impact on their desired policy!
Replies from: GuySrinivasan, adam-long↑ comment by SarahNibs (GuySrinivasan) · 2023-08-01T16:35:10.185Z · LW(p) · GW(p)
I am quite sure that in a world where friendly tool AIs were provably easy to build and everyone was gonna build them instead of something else and the idea even made sense, basically a world where we know we don't need to be concerned about x-risk, Yudkowsky would be far less "relaxed" about AI+power. In absolute terms maybe he's just as concerned as everyone else about AI+power, but that concern is swamped by an even larger concern.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2023-08-01T17:30:10.098Z · LW(p) · GW(p)
Maybe I shouldn't have used EY as an example, I don't have any special insight into how he thinks about AI and power imbalances. Generally I get the vibe from his public statements that he's pretty libertarian and thinks pros outweigh cons on most technology which he thinks isn't x-risky. I think I'm moderately confident that hes more relaxed about, say, misinformation or big tech platforms dominance than (say) Melanie Mitchell but maybe i'm wrong about that.
↑ comment by Adam David Long (adam-long) · 2023-08-01T18:09:23.576Z · LW(p) · GW(p)
Thanks for that feedback. Perhaps this is another example of the tradeoffs in the "how many clusters are there in this group?" decision. I'm kind of thinking of this as a way to explain, e.g., to smart friends and family members, a basic idea of what is going on. For that purpose I tend, I guess, to lean in favor of fewer rather than more groups, but of course there is always a danger there of oversimplifying.
I think I may also need to do a better job distinguishing between describing positions vs describing people. Most of the people thinking and writing about this have complicated, evolving views on lots of topics, and perhaps many don't fit neatly, as you say. Since the Munk Debate, I've been trying to learn more about, e.g. Melanie Mitchell's views, and in at least one interview I heard, she acknowledged that existential risk was a possibility, she just thought it was a lower priority than other issues.
I need to think more about the "existential risk is a real problem but we are very confident that we can solve it on our current path" typified by Sam Altman and (maybe?) the folks at Anthropic. Thanks for raising that.
As you note, this view contrasts importantly with both the (1) boosters and (2) the doomers.
My read is that the booster arguments put forth by, Marc Andreessen or Yann LeCun, argue that "existential risk" concerns are like worrying about "what happens if Aliens invade our future colony on Mars?" -- view that "this is going to be airplane development -- yes there are risks but we are going to handle it!"
I think you've already explained very well the difference between the Sam Altman view and the Doomer view. Maybe this needs to be a 2 by 2 matrix? OTOH, perhaps there, in the oversimplified framework, there are two "booster" positions on why we shouldn't be inordinatetly worried about existential risk: (1) it's just not a likely possibility (Andreessen, LeCun) (2) "yes it's a problem but we are going to solve it and so we don't need to, e.g. shut down AI development" (Altman)
Thinking about another debate question, I wonder about the question
"We should pour vastly more money and resources into fixing [eta: solving] the alignment problem"
I think(??) that Altman and Yudkowsky would both argue YES, and that Andreessen and LeCun would (I think?) argue NO.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2023-08-01T21:33:36.379Z · LW(p) · GW(p)
Any post along the lines of yours needs a 'political compass' diagram lol.
I mean it's hard to say what Altman would think in your hypothetical debate: assuming he has reasonable freedom of action at OpenAI his revealed preference seems to be to devote <= 20% of the resources available to his org to 'the alignment problem'. If he wanted to assign more resources into 'solving alignment' he could probably do so. I think Altman thinks he's basically doing the right thing in terms of risk levels. Maybe that's a naive analysis, but I think it's probably reasonable to take him more or less at face value.
I also think that it's worth saying that easily the most confusing argument for the general public is exactly the Anthropic/OpenAI argument that 'AI is really risky but also we should build it really fast'. I think you can steelman this argument more than I've done here, and many smart people do, but there's no denying it sounds pretty weird, and I think it's why many people struggle to take it at face value when people like Altman talk about x-risk - it just sounds really insane!
In constrast, while people often think it's really difficult and technical, I think yudkowsky's basic argument (building stuff smarter than you seems dangerous) is pretty easy for normal people to get, and many people agree with general 'big tech bad' takes that the 'realists' like to make.
I think a lot of boosters who are skeptical of AI risk basically think 'AI risk is a load of horseshit' for various not always very consistent reasons. It's hard to overstate how much 'don't anthropomorphise' and 'thinking about AGI is distracting sillyness by people who just want to sit around and talk all day' are frequently baked deep into the souls of ML veterans like LeCun. But I think people who would argue no to your proposed alignment debate would, for example, probably strongly disagree that 'the alignment problem' is like a coherent thing to be solved.
comment by tailcalled · 2023-08-01T06:51:06.009Z · LW(p) · GW(p)
It's worth remembering that the explicit goal of a lot of AI alignment research is to make AI controllable, which makes AI "doomers" in a sense allied with (or at least, building a superweapon for) the people in power that the AI "realists" are worried about.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-08-02T14:09:13.226Z · LW(p) · GW(p)
AI alignment is more often than not assumed to be with some abstract "human values" which are ought to be collected from the general public and aggregated with some clever, yet undeveloped algorithms. I don't think anyone in AI alignment, once "solved" this problem, would hand the technology over to POTUS or any other powerful leader or a clique.
Replies from: tailcalled↑ comment by tailcalled · 2023-08-02T14:29:27.835Z · LW(p) · GW(p)
Maybe sometimes? Mostly I disagree.
My impression is that MIRI would prefer some sort of TESCREAList future, with emulated minds colonizing all of space, or something like that. This is probably something most people would be afraid of. MIRI isn't the only AI alignment research org, but I don't really see other rationalist alignment researchers opposing this desire, I think because they're all TESCREALists?
Of course MIRI doesn't seem to be on track towards grabbing control over the world themselves to implement TESCREALism, so more realistically MIRI might produce something that the leading tech companies like OpenAI can incorporate in their work. But "tech companies" were one of the original sides mentioned in the OP that "realists" were worried about.
And furthermore, the tech companies have recently decided that they don't know how to control the AI and begged the US government to take control. Rationalists don't really expect the government to do well with this on its own, but I think there is hope that AI safety researchers could produce some tools that the US government could make mandates about using? But that would also mean that "doomers" are giving the US government a lot of power?
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-08-02T15:04:05.591Z · LW(p) · GW(p)
And furthermore, the tech companies have recently decided that they don't know how to control the AI and begged the US government to take control. Rationalists don't really expect the government to do well with this on its own, but I think there is hope that AI safety researchers could produce some tools that the US government could make mandates about using? But that would also mean that "doomers" are giving the US government a lot of power?
I think you mischaracterise what's happening a lot. Tech companies don't "beg US government to control AI", they beg it to regulate the industry. That's a very big difference. They didn't yet say anything about the control of AI, once it's build, and (presumably) "aligned", apart from well-sounding for PR phrases like "we will increasingly involve input from more people about where do we take AI". In reality, they just don't know yet who and how should "control" AI (if anyone), and align with whose "values". They hope that the "alignment MVP", a.k.a. AGI which is an aligned AI safety and alignment scientist, will actually tell them the "right" answers to these questions (as per OpenAI's "superalignment" agenda).
comment by Chris Elster (chris-elster) · 2023-08-02T07:04:54.543Z · LW(p) · GW(p)
Your three sided debate maps on to the Collective Intelligence Project's "Transformative Technology Trilemma", which has corners on "participation", "safety", and "progress". https://cip.org/whitepaper#trilemma
Replies from: adam-long↑ comment by Adam David Long (adam-long) · 2023-08-02T16:30:35.305Z · LW(p) · GW(p)
Was not aware of this Collective Intelligence Project and glad to learn about them. I'll take a look. Thanks.
I'm very eager to find other "three-sided" frameworks that this one might map onto.
Maybe OT, but I also have been reading Arnold Kling's "Three Languages of Politics" but so far have been having trouble mapping Kling's framework onto this one
comment by Stefan_Schubert · 2023-08-02T06:17:44.206Z · LW(p) · GW(p)
Realist and pragmatist don't seem like the best choices of terms, since they pre-judge the issue a bit in the direction of that view.
Replies from: Avnix, adam-long↑ comment by Sweetgum (Avnix) · 2023-08-02T17:07:00.968Z · LW(p) · GW(p)
Maybe something like "mundane-ist" would be better. The "realists" are people who think that AI is fundamentally "mundane" and that the safety concerns with AI are basically the same as safety concerns with any new technology (increases inequality by making the powerful more powerful, etc.) But of course "mundane-ist" isn't a real word, which is a bit of a problem.
↑ comment by Adam David Long (adam-long) · 2023-08-02T16:25:52.470Z · LW(p) · GW(p)
Thanks. To be honest, I am still wrestling with the right term to use for this group. I came up with "realist" and "pragmatist" as the "least bad" options after searching for a term that meets the following criteria:
- short, ideally one word
- conveys the idea of prioritizing (a) current or near-term harms over (b) far-term consequences
- minimizes the risk that someone would be offended if the label were applied to them
I also tried playing around with an acronym like SAFEr for "Skeptical, Accountable, Fair, Ethical" but couldn't figure out an acronym that I liked.
Would very much appreciate feedback or suggestions on a better term. FWIW, I am trying to steelman the position but not pre-judge the overall debate.
↑ comment by Stefan_Schubert · 2023-08-02T18:27:51.895Z · LW(p) · GW(p)
Not exactly what you're asking for, but maybe a 2x2 could be food for thought.
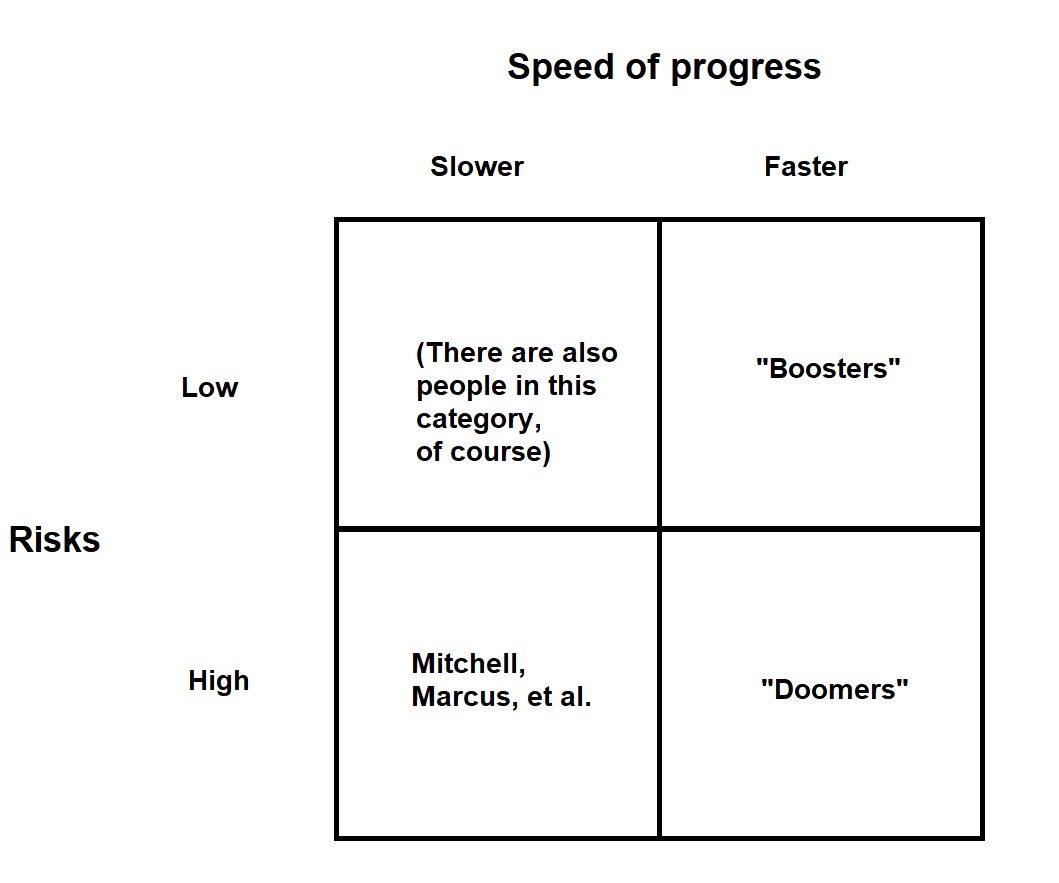
↑ comment by Adam David Long (adam-long) · 2023-08-02T22:34:27.934Z · LW(p) · GW(p)
Thanks. I think this is useful and I'm trying to think through who is in the upper left hand corner. Are there "AI researchers" or, more broadly, people who are part of the public conversation who believe (1) AI isn't moving all that fast towards AGI and (2) that it's not that risky?
I guess my initial reaction is that people in the upper left hand corner just generally think "AI is kind of not that big a deal" and that there are other societal problems to worry about. does that sound right? Any thoughts on who should be placed in the upper left?
↑ comment by Stefan_Schubert · 2023-08-03T09:49:55.789Z · LW(p) · GW(p)
Yeah, I think so. But since those people generally find AI less important (there's both less of an upside and less of a downside) they generally participate less in the debate. Hence there's a bit of a selection effect hiding those people.
There are some people who arguably are in that corner who do participate in the debate, though - e.g. Robin Hanson. (He thinks some sort of AI will eventually be enormously important, but that the near-term effects, while significant, will not be at the level people on the right side think).
Looking at the 2x2 I posted I wonder if you could call the lower left corner something relating to "non-existential risks". That seems to capture their views. It might be hard to come up with a catch term, though.
The upper left corner could maybe be called "sceptics".
comment by Hoagy · 2023-08-01T01:57:52.603Z · LW(p) · GW(p)
A useful model for why it's both appealing and difficult to say 'Doomers and Realists are both against dangerous AI and for safety - let's work together!'.
Replies from: o-o, adam-long↑ comment by O O (o-o) · 2023-08-01T02:30:40.604Z · LW(p) · GW(p)
AI realism also risks a Security theater that obscures existential risks of AI.
Replies from: adam-long↑ comment by Adam David Long (adam-long) · 2023-08-01T06:14:31.505Z · LW(p) · GW(p)
Yes agreed. Indeed one of the things that motivated me to propose this three-sided framework is watching discussions of the following form:
1. A & B both state that they believe that AI poses real risks that the public doesn't understand.
2. A takes (what I now call) the "doomer" position that existential risk is serious and all other risks pale in comparison: "we are heading toward an iceberg and so it is pointless to talk about injustices on the ship re: third class vs first class passengers"
3. B takes (what I now call) the "realist" or "pragmatist position" that existential risk is, if not impossible, very remote and a distraction from more immediate concerns, e.g. use of AI to spread propaganda or to deny worthy people of loans or jobs: "all this talk of existential risk is science fiction and obscuring the REAL problems"
4. A and B then begin vigorously arguing with each other, each accusing the other of wasting time on unimportant issues.
My hypothesis/theory/argument is that at this point the general public throws up its hands because both the critics/experts can't seem to agree on the basics.
By the way, I hope it's clear that I'm not accusing A or B of doing anything wrong. I think they are both arguing in good faith from deeply held beliefs.
↑ comment by Adam David Long (adam-long) · 2023-08-01T06:19:57.370Z · LW(p) · GW(p)
yes, this has been very much on my mind: if this three-sided framework is useful/valid, what does it mean for the possibility of the different groups cooperating?
I suspect that the depressing answer is that cooperation will be a big challenge and may not happen at all. Especially as to questions such as "is the European AI Act in its present form a good start or a dangerous waste of time?" It strikes me that each of the three groups in the framework will have very strong feelings on this question
- realists: yes, because, even if it is not perfect, it is at least a start on addressing important issues like invasion of privacy.
- boosters: no, because it will stifle innovation
- doomers: no, because you are looking under the lamp post where the light is better, rather than addressing the main risk, which is existential risk.
comment by Review Bot · 2024-05-02T15:03:32.025Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Shayne O'Neill (shayne-o-neill) · 2023-08-04T04:41:28.223Z · LW(p) · GW(p)
I suspect most of us occupy more than one position in this taxonomy. I'm a little bit doomer and a little bit accelerationist. I theres significant, possibly world ending, danger in AI, but I also think as someone who works on climate change in my day job, that climate change is a looming significant civilization ending risk or worse (20%-ish) for humanity and worry humans alone might not be able to solve this thing. Lord help us if the siberian permafrost melts,we might be boned as a species.
So as a result, I just don't know how to balance these two potential x risk dangers. No answers from me, alas, but I think we need to understand that for many, maybe most of us, we haven't really planted our flag in any of these camps exclusively, we're still information gathering.
↑ comment by Adam David Long (adam-long) · 2023-08-04T23:04:05.987Z · LW(p) · GW(p)
Thanks for this comment. I totally agree and I think I need to make this clearer. I mentioned elsewhere ITT that I realized that I need to do a better job distinguishing between "positions" vs. "people" especially when debate gets heated.
These are tough issues with a lot of uncertainty and I think smart people are wrestling with these.
If I can risk the "personal blog" tag: I showed an earlier draft of the essay that became this post to a friend who is very smart but doesn't follow these issues very closely. He put me on the spot by asking me "ok, so which are you? You are putting everyone else in a box, so which box are you in?" And it made me realize, "I don't know -- it depends on which day you ask me!"
comment by False Name (False Name, Esq.) · 2023-08-02T14:52:55.133Z · LW(p) · GW(p)
Autonomous lethal weapons (ALWs; we need a more eerie, memetic name) could make the difference. Against the "realists", whereas bias is not a new problem, ALWs emphatically are. Likewise no reflexive optimism from the boosters lessens the need for sober regulation to lessen the self-evident risk of ALWs.
And this provides a "narrative through-line" for regulation - we must regulate ALWs, and so, AI systems that could design ALWs. It follows, we must regulate AI systems that design other AI systems in general, and so too, we must therefore regulate AI artificial intelligence researchers, or recursive self-improving systems. The regulations can logically follow, and lead to the (capability, at least) of regulating projects conducive to AGI.
All this suggests a scenario plan: on assumption ALWs will be used in combat, and there are confirmed fatalities therefrom, we publicise like hell: names, faces, biographies - which the ALW didn't, and couldn't have, appreciated, but it killed them anyway. We observe that it chose to kill them - why? On what criteria? What chain of reasoning? No one alive knows. With the anxiety from ALWs in general, and such a case in particular, we are apt to have more public pressure for regulation in general.
If that regulation focuses on ALWs, and what ensures more safety, to the "stair-steps" of regulation against risk to humans in general, we have a model that appeals to "realists": ALWs given a photograph, of epicanthic folds, dark skin, blue eyes, whatever - enables the ultimate "discrimination", of genocide. Whereas the boosters have nothing to say against regulations, since such lethal uses by AI can't be "made safe", particularly if multiple antagonists have them.
We leverage ALW regulation to get implicitly existence-risk averse leadership into regulatory bodies (since in a bureaucracy, who wins the decision makers wins the decisions). Progress.
OP's analysis seems sound - but observe that the media are also biased toward booster-friendly, simpler, hyperbolic narratives; whereas they've no mental model of, not robots with human minds, but the minds themselves supplanted. Not knowing what's happening, they default to their IT shibboleths, "realist"-friendly bias concerns. As for "doomers", they don't know what to do.
If somebody knows how to make a press release for such a use described: go for it.
Replies from: Avnix, KaynanK↑ comment by Sweetgum (Avnix) · 2023-08-02T17:14:47.365Z · LW(p) · GW(p)
Autonomous lethal weapons (ALWs; we need a more eerie, memetic name)
There's already a more eerie, memetic name. Slaughterbots.
↑ comment by Multicore (KaynanK) · 2023-08-02T23:20:27.700Z · LW(p) · GW(p)
I think ALWs are already more of a "realist" cause than a doomer cause. To doomers, they're a distraction - a superintelligence can kill you with or without them.
ALWs also seem to be held to an unrealistic standard compared to existing weapons. With present-day technology, they'll probably hit the wrong target more often than human-piloted drones. But will they hit the wrong target more often than landmines, cluster munitions, and over-the-horizon unguided artillery barrages, all of which are being used in Ukraine right now?
comment by trevor (TrevorWiesinger) · 2023-08-02T00:08:40.707Z · LW(p) · GW(p)
Although I don't see anything wrong with your doomer/booster delineation here, your doomer/realist delineation is catastrophic. Although nearterm AI power realities are ultimately a distraction from AI risk, they are also essential for understanding AGI macrostrategy e.g. race dynamics.
By lumping things like US-China affairs in the same camp as spin doctors like Gebru and Mitchell, you're basically labeling those factors as diametrically opposed to the AI safety community, which will only give bad actors more control/monopoly over the overton window (both the overton window for the general public and the separate one within the AI safety community).
The nearterm uses of AI are critical to understand the gameboard and to weigh different strategies. It's not intrinsically valuable, but it's instrumentally convergent to understand the world's current "AI situation". It's a bad idea to lump it in the same category with opportunistic woke celebrities.
comment by Kevin Varela-O'Hara (kevin-varela-o-hara) · 2023-08-01T18:23:57.934Z · LW(p) · GW(p)
I don’t think all boosters would agree with “We are likely to see something like AGI in the next 5 years”. Yan LeCun Has explicitly said that LLMs are an off-ramp on the path to AI, and that we haven’t made an AI that as smart as a cat at this point so AGI is still a long way off.