Gemini 1.0
post by Zvi · 2023-12-07T14:40:05.243Z · LW · GW · 7 commentsContents
Technical Specifications Level Two Bard Gemini Reactions None 8 comments
It’s happening. Here is CEO Pichai’s Twitter announcement. Here is Demis Hassabis announcing. Here is the DeepMind Twitter announcement. Here is the blog announcement. Here is Gemini co-lead Oriol Vinyals, promising more to come. Here is Google’s Chief Scientist Jeff Dean bringing his best hype.
EDIT: This post has been updated for the fact that I did not fully appreciate how fake Google’s video demonstration was.
Technical Specifications
Context length trained was 32k tokens, they report 98% accuracy on information retrieval for Ultra across the full context length. So a bit low, both lower than GPT—4 and Claude and lower than their methods can handle. Presumably we should expect that context length to grow rapidly with future versions.
There are three versions of Gemini 1.0.
Gemini 1.0, our first version, comes in three sizes: Ultra for highly-complex tasks, Pro for enhanced performance and deployability at scale, and Nano for on-device applications. Each size is specifically tailored to address different computational limitations and application requirements.
…
Nano: Our most efficient model, designed to run on-device. We trained two versions of Nano, with 1.8B (Nano-1) and 3.25B (Nano-2) parameters, targeting low and high memory devices respectively. It is trained by distilling from larger Gemini models. It is 4-bit quantized for deployment and provides best-in-class performance.
…
The Nano series of models leverage additional advancements in distillation and training algorithms to produce the best-in-class small language models for a wide variety of tasks, such as summarization and reading comprehension, which power our next generation on-device experiences.
This makes sense. I do think there are, mostly, exactly these three types of tasks. Nano tasks are completely different from non-Nano tasks.
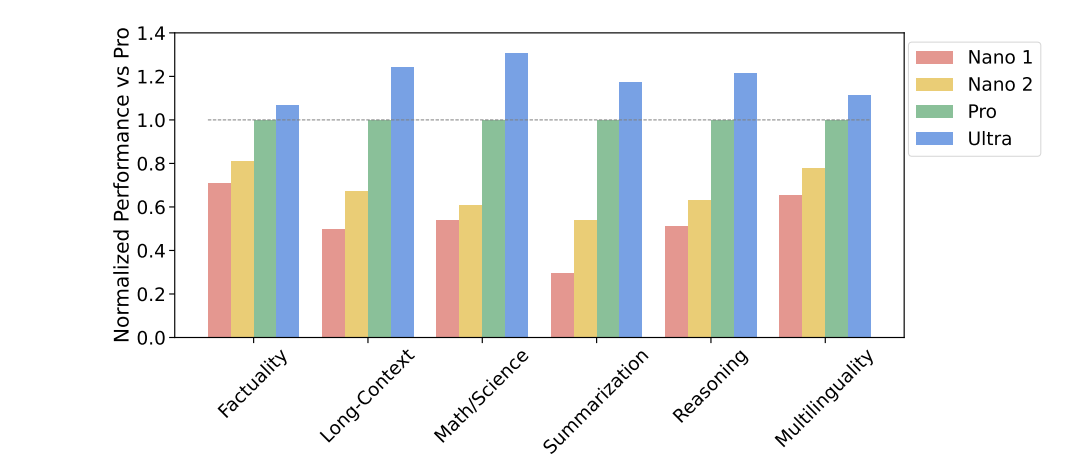
This graph reports relative performance of different size models. We know the sizes of Nano 1 and Nano 2, so this is a massive hint given how scaling laws work for the size of Pro and Ultra.
Gemini is natively multimodal, which they represent as being able to seamlessly integrate various inputs and outputs.
They say their benchmarking on text beats the existing state of the art.
Our most capable model, Gemini Ultra, achieves new state-of-the-art results in 30 of 32 benchmarks we report on, including 10 of 12 popular text and reasoning benchmarks, 9 of 9 image understanding benchmarks, 6 of 6 video understanding benchmarks, and 5 of 5 speech recognition and speech translation benchmarks. Gemini Ultra is the first model to achieve human-expert performance on MMLU (Hendrycks et al., 2021a) — a prominent benchmark testing knowledge and reasoning via a suite of exams — with a score above 90%. Beyond text, Gemini Ultra makes notable advances on challenging multimodal reasoning tasks.
I love that ‘above 90%’ turns out to be exactly 90.04%, whereas human expert is 89.8%, prior SOTA was 86.4%. Chef’s kiss, 10/10, no notes. I mean, what a coincidence, that is not suspicious at all and no one was benchmark gaming that, no way.

We find Gemini Ultra achieves highest accuracy when used in combination with a chain-of-thought prompting approach (Wei et al., 2022) that accounts for model uncertainty. The model produces a chain of thought with k samples, for example 8 or 32. If there is a consensus above a preset threshold (selected based on the validation split), it selects this answer, otherwise it reverts to a greedy sample based on maximum likelihood choice without chain of thought.
I wonder when such approaches will be natively integrated into the UI for such models. Ideally, I should be able to, after presumably giving them my credit card information, turn my (Bard?) to ‘Gemini k-sample Chain of Thought’ and then have it take care of itself.
Here’s their table of benchmark results.
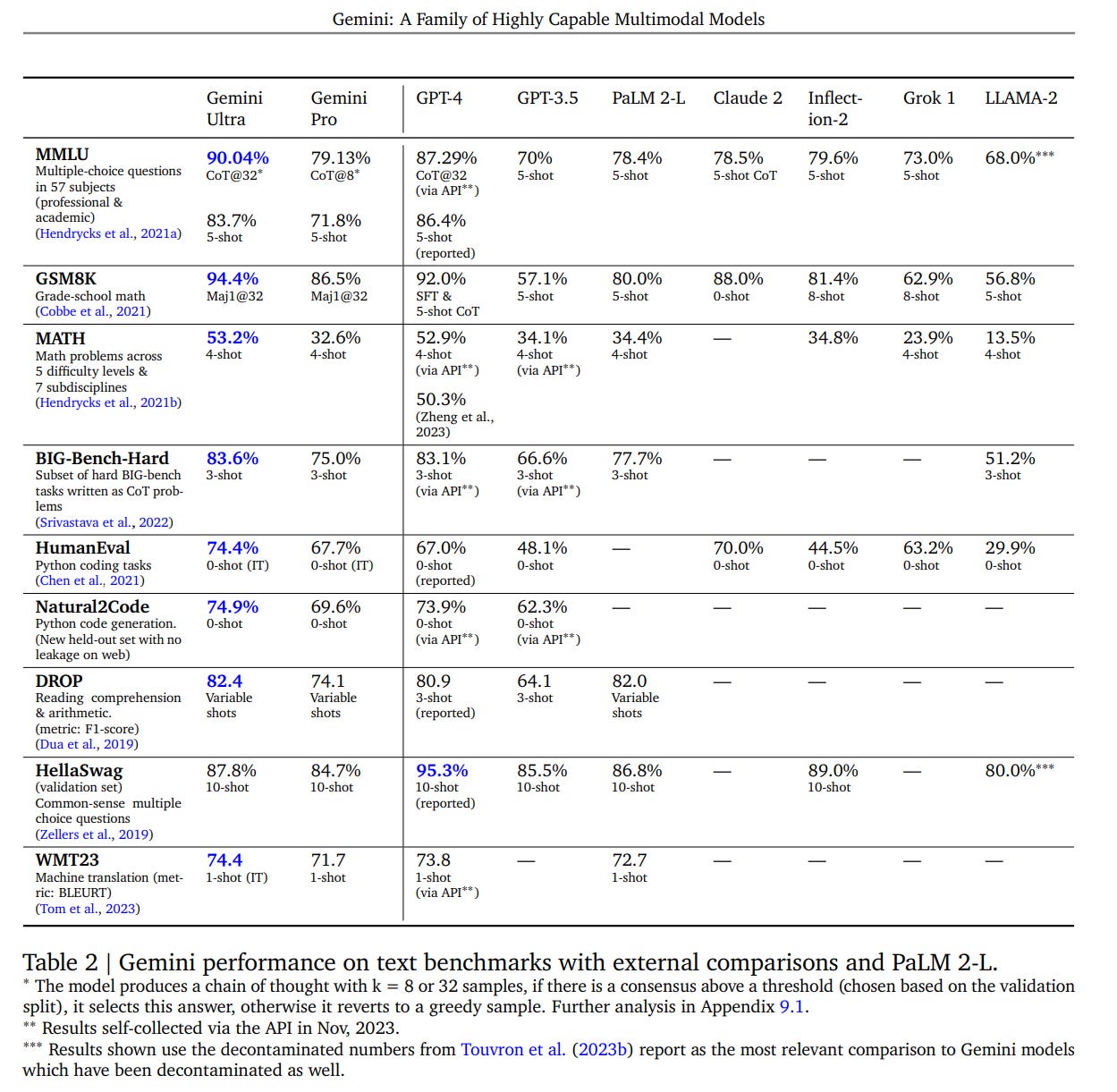
So the catch with MMLU is that Gemini Ultra gets more improvement from CoT@32, where GPT-4 did not improve much, but Ultra’s baseline performance on 5-shot is worse than GPT-4’s.
Except the other catch is that GPT-4, with creative prompting, can get to 89%?
GPT-4 is pretty excited about this potential ‘Gemini Ultra’ scoring 90%+ on the MMLU, citing a variety of potential applications and calling it a substantial advancement in AI capabilities.
They strongly imply that GPT-4 got 95.3% on HellaSwag due to data contamination, noting that including ‘specific website extracts’ improved Gemini’s performance there to a 1-shot 96%. Even if true, performance there is disappointing.
What does this suggest about Gemini Ultra? One obvious thing to do would be to average all the scores together for GPT-4, GPT-3.5 and Gemini, to place Gemini on the GPT scale. Using only benchmarks where 3.5 has a score, we get an average of 61 for GPT 3.5, 79.05 for GPT-4 and 80.1 for Gemini Ultra.
By that basic logic, we would award Gemini a benchmark of 4.03 GPTs. If you take into account that improvements matter more as scores go higher, and otherwise look at the context, and assume these benchmarks were not selected for results, I would increase that to 4.1 GPTs.
On practical text-only performance, I still expect GPT-4-turbo to be atop the leaderboards.
Gemini Pro clearly beat out PaLM-2 head-to-head on human comparisons, but not overwhelmingly so. It is kind of weird that we don’t have a win rate here for GPT-4 versus Gemini Ultra.

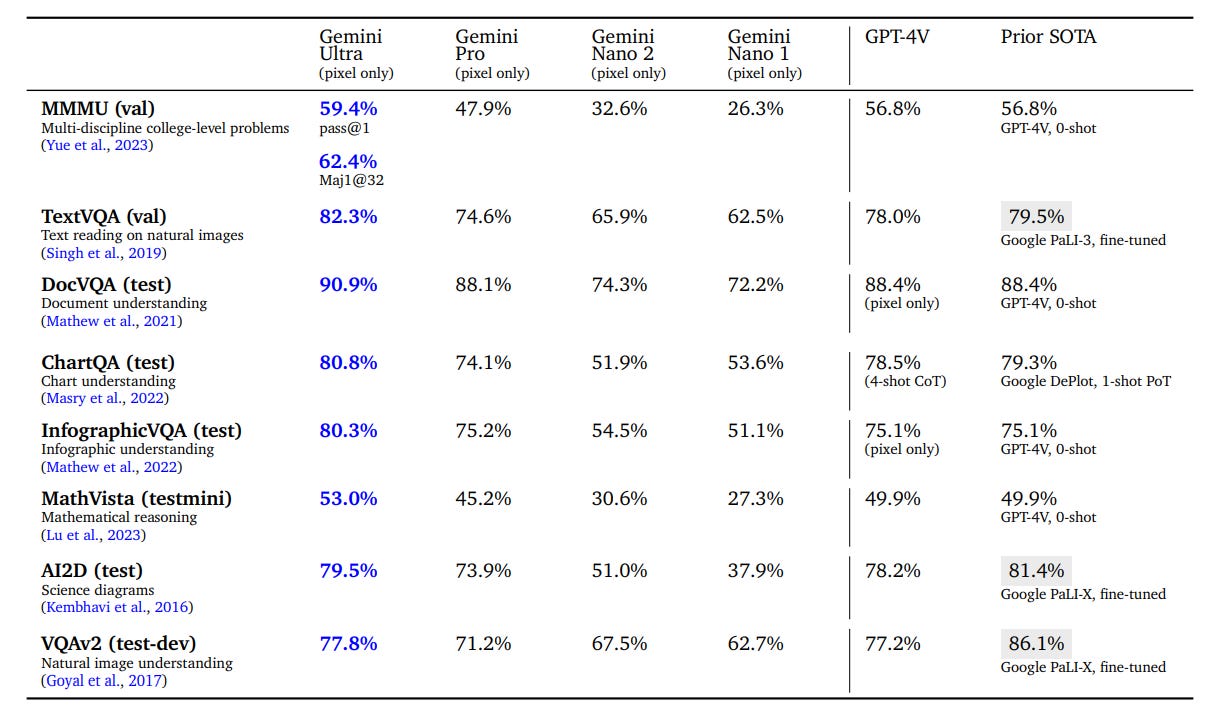
Image understanding benchmarks seem similar. Some small improvements, some big enough to potentially be interesting if this turns out to be representative.
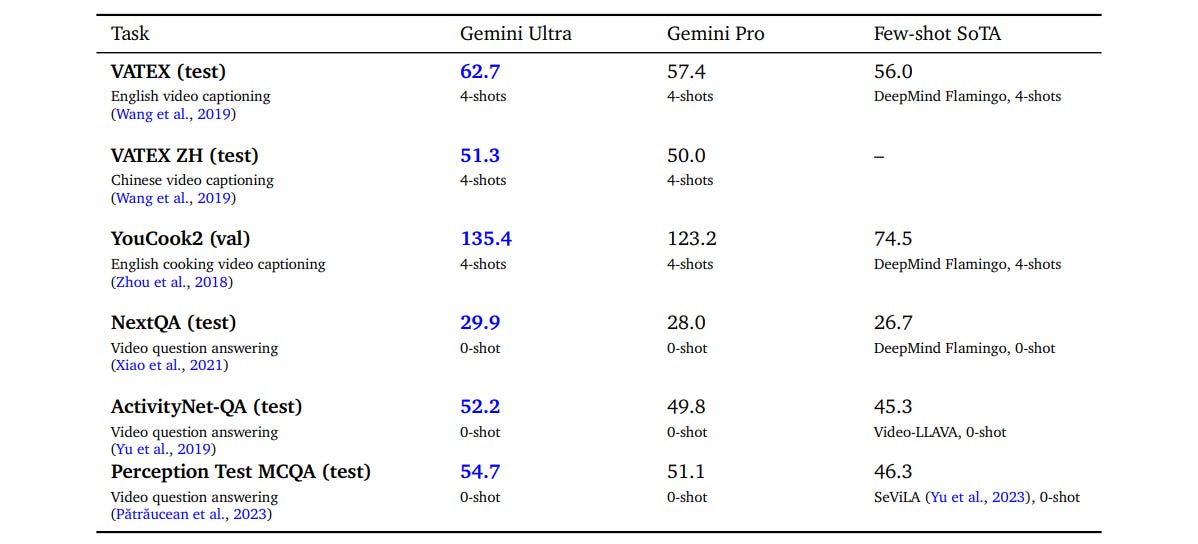
Similarly they claim improved SOTA for video, where they also have themselves as the prior SOTA in many cases.
For image generation, they boast that text and images are seamlessly integrated, such as providing both text and images for a blog, but provide no examples of Gemini doing such an integration. Instead, all we get are some bizarrely tiny images.
One place we do see impressive claimed improvement is speech recognition. Note that this is only Gemini Pro, not Gemini Ultra, which should do better.
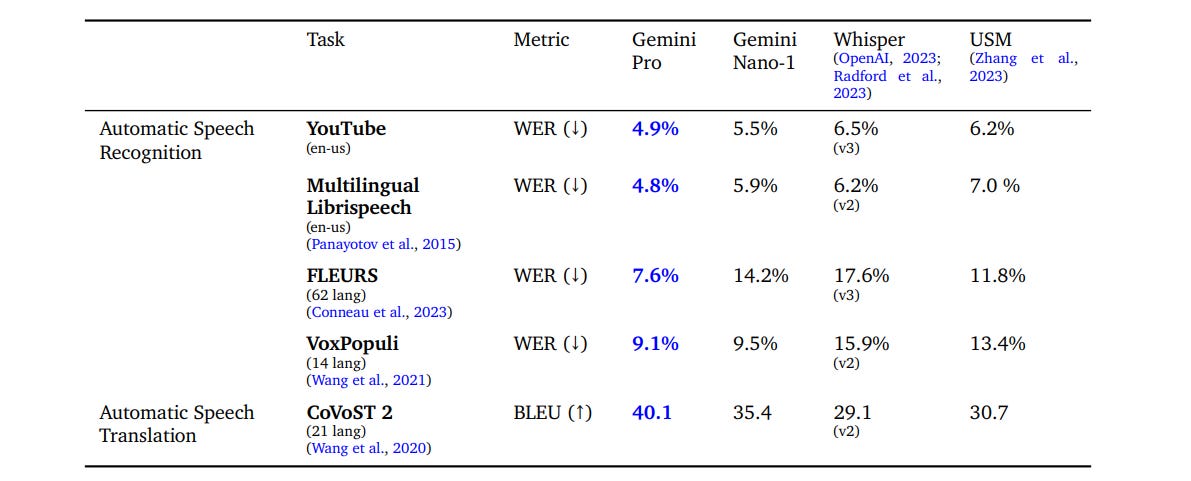
Those are error rate declines you would absolutely notice. Nano can run on-device and it is doing importantly better on YouTube than Whisper. Very cool.
Here’s another form of benchmarking.
The AlphaCode team built AlphaCode 2 (Leblond et al, 2023), a new Gemini-powered agent, that combines Gemini’s reasoning capabilities with search and tool-use to excel at solving competitive programming problems. AlphaCode 2 ranks within the top 15% of entrants on the Codeforces competitive programming platform, a large improvement over its state-of-the-art predecessor in the top 50% (Li et al., 2022).
…
AlphaCode 2 solved 43% of these competition problems, a 1.7x improvement over the prior record-setting AlphaCode system which solved 25%.
I read the training notes mostly as ‘we used all the TPUs, no really there were a lot of TPUs’ with the most interesting note being this speed-up. Does this mean they now have far fewer checkpoints saved, and if so does this matter?
Maintaining a high goodput [time spent computing useful new steps over the elapsed time of a training job] at this scale would have been impossible using the conventional approach of periodic checkpointing of weights to persistent cluster storage.
For Gemini, we instead made use of redundant in-memory copies of the model state, and on any unplanned hardware failures, we rapidly recover directly from an intact model replica. Compared to both PaLM and PaLM-2 (Anil et al., 2023), this provided a substantial speedup in recovery time, despite the significantly larger training resources being used. As a result, the overall goodput for the largest-scale training job increased from 85% to 97%.
Their section on training data drops a few technical hints but wisely says little. They deliberately sculpted their mix of training data, in ways they are keeping private.
In section 6 they get into responsible deployment. I appreciated them being clear they are focusing explicitly on questions of deployment.
They focus (correctly) exclusively on the usual forms of mundane harm, given Gemini is not yet breaking any scary new ground.
Building upon this understanding of known and anticipated effects, we developed a set of “model policies” to steer model development and evaluations. Model policy definitions act as a standardized criteria and prioritization schema for responsible development and as an indication of launch-readiness. Gemini model policies cover a number of domains including: child safety, hate speech, factual accuracy, fairness and inclusion, and harassment.
Their instruction tuning used supervised fine tuning and RLHF.
A particular focus was on attribution, which makes sense for Google.
Another was to avoid reasoning from a false premise and to otherwise refuse to answer ‘unanswerable’ questions. We need to see the resulting behavior but it sounds like the fun police are out in force.
It doesn’t sound like their mitigations for factuality were all that successful? Unless I am confusing what the numbers mean.
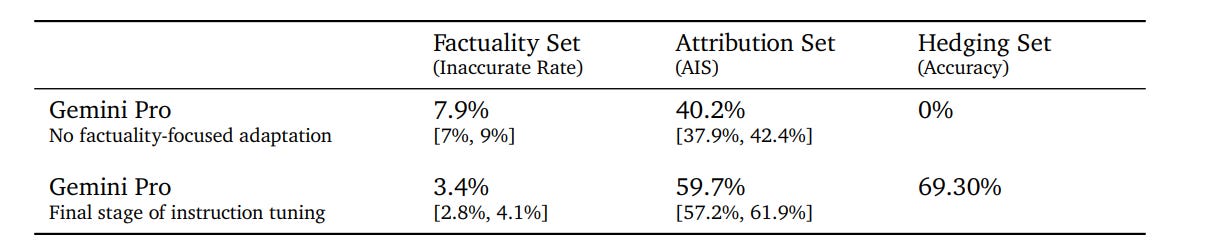
Looking over the appendix and its examples, it is remarkable how unimpressive were all of the examples given.
I notice that I watch how honestly DeepMind approaches reporting capabilities and attacking benchmarks as an important sign for their commitment to safety. There are some worrying signs that they are willing to twist quite a ways. Whereas the actual safety precautions do not bother me too much one way or the other?
The biggest safety precaution is one Google is not even calling a safety precaution. They are releasing Gemini Pro, and holding back Gemini Ultimate. That means they have a gigantic beta test with Pro, whose capabilities are such that it is harmless. They can use that to evaluate and tune Ultimate so it will be ready.
The official announcement offers some highlights.
Demis Hassabis talked to Wired about Gemini. Didn’t seem to add anything.
Level Two Bard
Gemini Pro, even without Gemini Ultra should be a substantial upgrade to Bard. The question is, will that be enough to make it useful when we have Claude and ChatGPT available? I will be trying it to find out, same as everyone else. Bard does have some other advantages, so it seems likely there will be some purposes, when you mostly want information, where Bard will be the play.
This video represents some useful prompt engineering and reasoning abilities, used to help plan a child’s birthday party, largely by brainstorming possibilities and asking clarifying questions. If they have indeed integrated this functionality in directly, that’s pretty cool.
Pete says Bard is finally at a point where he feels comfortable recommending it. The prompts are not first rate, but he says it is greatly improved since September and the integrations with GMail, YouTube and Maps are useful. It definitely is not a full substitute at this time, the question is if it is a good complement.
Even before Gemini, Bard did a very good job helping my son with his homework assignments, such that I was sending him there rather than to ChatGPT.
Returning a clean JSON continues to require extreme motivation.
When will Bard Advanced (with Gemini Ultra) be launched? Here’s a market on whether it happens in January.
Gemini Reactions
Some were impressed. Others, not so much.
The first unimpressive thing is that all we are getting for now is Gemini Pro. Pro is very clearly not so impressive, clearly behind GPT-4.
Eli Dourado: Here is the table of Gemini evals from the paper. Note that what is being released into the wild today is Gemini Pro, not Gemini Ultra. So don’t expect Bard to be better than ChatGPT Plus just yet. Looks comparable to Claude 2.
Simeon: Gemini is here. Tbh it feels like it’s GPT-4 + a bit more multimodality + epsilon capabilities. So my guess is that it’s not a big deal on capabilities, although it might be a big deal from a product standpoint which seems to be what Google is looking for.
As always, one must note that everything involved was chosen to be what we saw, and potentially engineered or edited. The more production value, the more one must unwind.
For the big multimodal video, this issue is a big deal.
Robin: I found it quite instructive to compare this promo video with the actual prompts.
Robert Wiblin (distinct thread): It’s what Google themselves out put. So it might be cherry picked, but not faked. I think it’s impressive even if cherry picked.
Was this faked? EDIT: Yes. Just yes. Shame on Google on several levels.
Set aside the integrity issues, wow are we all jaded at this point, but when I watched that video, even when I assumed it was real, the biggest impression I got was… big lame dad energy?
I do get that this was supposedly happening in real time, but none of this is surprising me. Google put out its big new release, and I’m not scared. If anything, I’m kind of bored? This is the best you could do?
Whereas when watching the exact same video, others react differently.
Amjad Masad (CEO Replit): This fundamentally changes how humans work with computers.
Does it even if real? I mean, I guess, if you didn’t already assume all of it, and it was this smooth for regular users? I can think of instances in which a camera feed hooked up to Gemini with audio discussions could be a big game. To me this is a strange combination of the impressive parts already having been ‘priced into’ my world model, and the new parts not seeming impressive.
So I’m probably selling it short somewhat to be bored by it as a potential thing that could have happened. If this was representative of a smooth general multimodal experience, there is a lot to explore.
Arthur thinks Gemini did its job, but that this is unsurprising and it is weird people thought Google couldn’t do it.
Liv Boeree? Impressed.
Liv Boeree: This is pretty nuts, looks like they’ve surpassed GPT4 on basically every benchmark… so this is most powerful model in the world?! Woweee what a time to be alive.
Gary Marcus? Impressed in some ways, not in others.
Gary Marcus: Thoughts & prayers for VCs that bought OpenAI at $86B.
Hot take on Google Gemini and GPT-4:
Google Gemini seems to have by many measures matched (or slightly exceeded) GPT-4, but not to have blown it away.
Note that Gates and Altman have both been dropping hints, and GPT-5 isn’t here after a year despite immense commercial desire. The fact that Google, with all its resources, did NOT blow away GPT-4 could be telling.
I love that this is saying that OpenAI isn’t valuable both because Gemini is so good and also because Gemini is not good enough.
Roon: congrats to Gemini team! it seems like the global high watermark on multimodal ability.
The MMLU result seems a bit fake / unfair terms but the HumanEval numbers look like a actual improvement and ime pretty closely match real world programming utility
David Manheim seems on point (other thread): I have not used the system, but if it does only slightly outmatch GPT-4, it seems like slight evidence that progress in AI with LLMs is not accelerating the way that many people worried and/or predicted.
Joey Krug is super unimpressed by the fudging on the benchmarks, says they did it across the board not only MMLU.
Packy McCormick: all of you (shows picture)
Ruxandra Teslo: wait what happened recently? did they do something good?
Packy: they did a good!

Google’s central problem is not wokeness, it is that they are a giant company with lots of internal processes and powers that prevent or slow or derail innovation, and prevent moving fast or having focus. And there are especially problems making practical products, integrating the work of various teams, making incentives line up. There is lots of potential, tons of talent, plenty of resources, but can they turn that into a product?
Too soon to tell. Certainly they are a long way from ‘beat OpenAI’ but this is the first and only case where someone might be in the game. The closest anyone else has come is Claude’s longer context window.
7 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2023-12-08T06:27:01.824Z · LW(p) · GW(p)
This graph reports relative performance of different size models. We know the sizes of Nano 1 and Nano 2, so this is a massive hint given how scaling laws work for the size of Pro and Ultra.
The weird thing is, I looked at this graph, I did that (because of course), and I got insane results. Applying that approach, Pro has somewhere ~13B parameters, and Ultra has somewhere ~26B parameters. That's from just eyeballing the step sizes and doing mental arithmetic, but the results are crazy enough that I'm not going to bother breaking out a ruler and calculator to try to do a more detailed estimate. It does not take a significant proportion of all of Google's latest TPUs months to train an ~26B parameter model, and if Google can really get narrowly-beating-GPT-4-level performance out of a model only the size of a mid-sized-LLama, or 3–4 times the size of Mistral, then I am deeply impressed by their mad skillz. Also, you don't call something "Nano" if it's 1/8 or 1/16 the size of your biggest model: the parameter count ratios have to be a lot larger than that between a data-center model and a phone model. I don't believe those sizes for a moment, so my conclusion is that the reason this graph was released is exactly because it's effectively on some sort of distinctly screwy scale that makes it impossible to use it to meaningfully estimate Pro and Ultra's parameter counts. I think it's marketing shlock, probably aimed at Pixel phone buyers.
My first guess would be that Nano 1 and Nano 2 were not originally pretrained at those parameter counts, but have been heavily distilled down (or some newer whizzier equivalent of distillation) in certain fairly narrow skillsets or even specific use-cases valuable for their on-Pixel-phone role (because they'd be dumb not to, and DeepMind+theBrain aren't dumb), and that those tests, while their 1-word descriptions sound general (well, apart from "summarization"), were carefully arranged to be inside those fairly narrow skillsets. (It also wouldn't surprise me if Nano 1 & 2 came in language-specific versions, each separately distilled, and that graph is from the EN versions. Though one of the test names was "multilingual", and those versions wouldn't be entirely monolingual, they'd still have some basic translation ability to/from useful languages.) So I suspect the tests are designed to heavily favor the Nano models. Or, the scoring is arranged in some way such that the scale is distinctly non-linear. Or indeed quite possibly some cunning combination of both of these. I'm fairly sure that if Jeff Dean (or one of his senior PMs) had sent me a sketch of what that graph needed to look like, say, a few months ago and assigned me a team of researchers, we could have come up with a set of measurements that looked like that.
Replies from: Marcus Williams, Hoagy↑ comment by Marcus Williams · 2023-12-08T07:52:06.988Z · LW(p) · GW(p)
It also seems likely that the Nano models are extremely overtrained compared to the scaling laws. The scaling laws are for optimal compute during training, but here they want to minimize inference cost so it would make sense to train for significantly longer.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-08T09:26:01.124Z · LW(p) · GW(p)
Agreed (well, except for a nitpick that post-Chinchilla versions of scaling laws also make predictions for scaling data and parameter count separately, including in overtraining regions): overtraining during distillation seems like the obvious approach, using a lot of data (possibly much of it synthetic, which would let you avoid issues like memorization of PII and copyright) rather than many epochs, in order to minimize memorization. Using distillation also effectively increases the size of your distillation training set for scaling laws, since the trainee model now gets more data per example: not just the tokens in the correct answer, but their logits and those of all the top alternative tokens according to the larger trainer model. So each document in the distillation training set becomes worth several times as much.
↑ comment by Hoagy · 2023-12-08T11:18:30.628Z · LW(p) · GW(p)
What assumptions is this making about scaling laws for these benchmarks? I wouldn't know how to convert laws for losses into these kind of fuzzy benchmarks.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-08T18:25:02.032Z · LW(p) · GW(p)
I was simply looking at the average across bar charts of the improvement step size between Nano 1 at 1.8B and Nano 2 at 3.25B parameter count, a factor of ~2 in parameter count. The step size up to Pro is about twice that, then from Pro up to Ultra about the same as Nano 1 to Nano 2, each again averaged across bar chats. Assuming only that the scaling law is a power law, i.e a straight line on a log-linear graph, as they always are (well, unless you use a screwy nonlinear scoring scheme), that would mean that Pro's parameter count was around times that of Nano 2, which is ~13B, and Ultra was another doubling again at ~26B. Those numbers are obviously wrong, so this is not a simple log-linear chart of something that just scales with a power law from parameter count. And I'm sure they wouldn't have published it if it was.
comment by Double · 2023-12-07T23:27:37.741Z · LW(p) · GW(p)
Liv Boeree: This is pretty nuts, looks like they’ve surpassed GPT4 on basically every benchmark… so this is most powerful model in the world?! Woweee what a time to be alive.
Link doesn't work. Maybe she changed her mind?
Replies from: MondSemmel↑ comment by MondSemmel · 2023-12-08T09:41:52.562Z · LW(p) · GW(p)
The link works for me, but not in a private browser, so I assume this is one of those things where Twitter nowadays stops you from seeing things if you're not logged in. This link should work even in that scenario.