Remaking EfficientZero (as best I can)
post by Hoagy · 2022-07-04T11:03:53.281Z · LW · GW · 9 commentsContents
Introduction Algorithm Overview AlphaZero MuZero EfficientZero MuZero Implementation: Neural Networks Playing Training: Support to scalar Reanalysing: Actor Classes: EfficientZero Implementation: Value prefix Consistency Loss Off policy correction Other interesting bits Pitfalls: Architectural Convergence Improving the algorithm About Me None 9 comments
Introduction
When I first heard about EfficientZero, I was amazed that it could learn at a sample efficiency comparable to humans. What's more, it was doing it without the gigantic amount of pre-training the humans have, which I'd always felt made comparing sample efficiencies with humans rather unfair. I also wanted to practice my ML programming, so I thought I'd make my own version.
This article uses what I've learned to give you an idea, not just of how the EfficientZero algorithm works, but also of what it looks like to implement in practice. The algorithm itself has already been well covered in a LessWrong post here [? · GW]. That article inspired me to write this and if it's completely new to you it might be a good place to start - the focus here will be more on what the algorithm looks like as a piece of code.
The code below is all written by me and comes from a cleaned and extra-commented version of EfficientZero which draws from the papers (MuZero, Efficient Zero), the open implementation pf MuZero by Werner Duvaud, the pseudocode provided by the MuZero paper, and the original implementation of EfficientZero.
You can have a look at the full code and run it at on github. It's currently functional and works on trivial games like cartpole but struggles to learn much on Atari games within a reasonable timeframe, not certain if this reflects an error or just insufficient time. Testing on my laptop or Colab for Atari games is slow - if anyone could give access to some compute to do proper testing that would be amazing!
Grateful to Misha Wagner for feedback on both code and post.
Algorithm Overview
AlphaZero
EfficientZero is based on MuZero, which itself is based on AlphaZero, a refinement of the architecture which was the first beat the Go world champion. With AlphaZero, you play a deterministic game, like chess, by developing a neural network that evaluates game states, associating each possible state of the board with a value, the discounted expected return (in zero-sum games like chess, discount rate is 0 and this is just win%). Since the algorithm can have access to a game 'simulator', it can test out different moves, and responses to those moves before actually playing them. More specifically, from an initial game state it can traverse the tree of potential games, making different moves, playing against itself, and evaluating these derived game states. After traversing this tree, and seeing the quality of the states reached, we can average the values of the derived states to get a better estimate of how good that initial game state actually was, and make our final move based on these estimates.
When playing out these hypothetical games, we are playing roughly according to our policy, but if we start finding that a move that looked promising leads to bad situations we can start avoiding that, thereby improving on our original policy. In the limit, this constrains our position evaluation function to be consistent with itself, meaning that if position A is rated highly, and our response in that situation would be to move to position B, then B should also be rated highly, etc. This allows us the maximize the value of our training data, because if we learn that state C is bad, we will also learn to avoid states which would lead to C and vice versa.
Note that this constraint is what similar to that enforced by the Minimax algorithm, but AZ and descendants propagate the average value of the found states, rather than the minimum, up the tree to avoid compounding NN error.
MuZero
While AlphaZero was very impressive, from a research direction, it seemed (to me) fundamentally limited by the fact that it requires a fully deterministic space in which to play - to search the tree of potential moves you need the existence of a 'board state', to which you can apply an action (e.g. 'knight to e5', Ne5), and get a new board state. This simply doesn't exist in most RL domains so how could this algorithm be used in any of these domains?
MuZero's solution is to incorporate ideas from model-based learning. They learn a mapping from observations (which could be game boards, but also could be images of Atari games, or Starcraft etc) to a latent vector, which is called the representation function. The dynamics function, instead of being e.g. a chess program, is again just a learned mapping from one vector to a new one, which is called the dynamics function.
But how should these dynamics and representation functions be learned? What is the 'correct' mapping to vector space? The answer MuZero gives is that all you need to do is train the system end-to-end and correct functions for both of these will be learned! The surprising fact is that this works so well that it can actually outperform AlphaZero, even though AZ has access to a perfect game simulator!
EfficientZero
EfficientZero takes MuZero as a base and then makes a number of changes to it, designed to make it much more sample efficient. We'll cover these in detail below, once we've established what a MuZero system looks like in practice.
MuZero Implementation:
Now onto how we would actually make such a system!
Neural Networks
There are three neural networks, the Representation network, the Dynamics network, and the Prediction network. These are three separate networks, each part of a larger class, and called with separate functions (though they can be neatly combined into two functions, initial_inference(observation), and recurrent_inference(latent_vector)).
Their type signatures are below, and will make more sense once the algorithm is described in detail.
- The Representation network takes an observation and returns a latent vector.
- The Dynamics network takes in a latent vector and a one-hot vector of the selected action, and returns a new latent vector and the predicted reward (expressed as logits - discussed below under support_to_scalar)
- The Prediction network takes in a latent vector and returns a prediction for the policy (expressed as logits of a probability distribution) and a prediction of the discounted future value (also as logits, again see support_to_scalar). The value prediction forms our estimate for the quality of this game-state, before we explore any further, and if we reach this node again, the policy prediction forms the basis of how we decide to explore the tree from here.
- Note that the policy is only a prediction because our real policy is the result of running lots of simulations of what might happen. This policy prediction just helps use decide which parts of the tree to explore.
The exact shapes of these can vary heavily between different implementations of this general pattern. For example the dynamics network in MuZero consisted of 16 ResNet layers, while in EfficientZero there is just one. Also, the latent space can be just a single vector, or in the case of Atari games, a two dimensional tensor mirroring the structure of the input image.
Playing
The core of using the MuZero algorithm to play a game is building the tree structure by which the algorithm explores the tree of possible moves, and therefore decides what to do.
Looking at Figure 1 of the original MuZero paper (below), we see the creation of a tree structure using the represent function (h) to take the board state into a latent representation, the predict function (f) to predict the policy and value that the algorithm will reach, and the dynamics function (g), to simulate taking an action within the latent space.
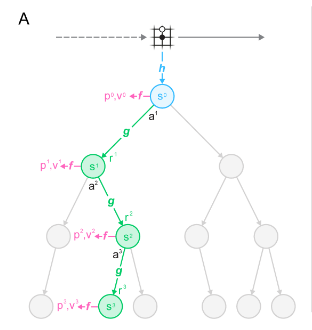
The open interpretation has this section written in C++ to minimize the time taken to create this tree but I've not found that this is a bottleneck. Generating 100k steps of game play on Atari using EfficientZero and tens of rollouts per move is manageable on a CPU, taking perhaps 10h while sufficient training time requires a long time and good optimization even with a (single) GPU.
Translating this abstract structure into code, the basic idea is that you have a tree of nodes which represents the state of your exploration. The algorithm is built for the case where the action space is finite, and so each node has an array of slots to hold each potential child.
class TreeNode:
"""
TreeNode is an individual node of a search tree.
It has one potential child for each potential action which,
if it exists, is another TreeNode.
Its function is to hold the relevant statistics for
deciding which action to take.
"""
def __init__(
self, action_space_size, latent, policy_pred=None, value_pred=None, ...
):
# These will be filled with other TreeNodes
self.children = [None] * action_space_size
# Holding the latent vector and the predicted policy and value
self.latent = latent
self.value_pred = value_pred
self.policy_pred = policy_pred
...
The initial node is created by first getting a latent representation of the observation, and using the prediction network to estimate the value and predict the eventual action distribution:
# tensor.unsqueeze(0) adds an extra dimension of size 1 at the 0th dimension
# which is needed as the network is designed to take batched inputs.
frame_t = torch.tensor(current_frame, device=device).unsqueeze(0)
# These can be brought together as 'initial_inference'.
initial_latent = mu_net.represent(frame_t)
initial_policy_logits, init_value = mu_net.predict(init_latent)
initial_policy_logits = initial_policy_logits[0]
initial_value = initial_value[[0]
From the logits of the predicted action distribution (init_policy_logits) from the prediction network, we get our final probabilities for how we will begin to explore the tree by:
init_policy_probs = torch.softmax(init_policy_logits, 0)
init_policy_probs = add_dirichlet(
init_policy_probs,
config["root_dirichlet_alpha"],
config["explore_frac"],
)
# This adds some noise to the probabilities of taking an action
# to encourage exploration
root_node = TreeNode(init_latent, init_policy_probs, ...)
With this root node we have the basis for our exploration tree and can begin to populate it. One of the key hyperparameters is the number of simulations (config["n_simulations"]) which is the number of times we explore, starting from the root node. In the MuZero paper, this number was 800 and 50 during training for Go and Atari respectively, but can be pushed much higher during evaluation to boost performance - indeed it's one of the key results that the learned dynamics function is sufficiently good that you can raise the number of simulations order of magnitude above that used in training and still get performance boosts.
The config object is a dictionary of hyperparameters and anything else that could plausibly be changed between runs. For ease it's passed to most functions so they have access to whatever they might need.
# Traversing the tree of possible game decision
for i in range(config["n_simulations"]):
# It's vital to have with(torch.no_grad()): or else the size
# of the computation graph quickly becomes gigantic and we're
# not training here but evaluating what to do
current_node = root_node
new_node = False # Tracks whether we have reached a new node yet
# tracks the route of the simulation through the tree
search_list = []
# We traverse the graph by picking actions, until we reach a new node
# at which point we revert back to the initial node.
while not new_node:
# Decide which action we will 'take' in this tree of potential decisions
action = current_node.pick_action()
if current_node.children[action] is None:
# If this action hasn't been taken then we'll need
# to do a forward pass of the dynamics and prediction function
# to evaluate the resulting state
# Getting the action as a one-hot vector
action_t = nn.functional.one_hot(
torch.tensor([action], device=device),
num_classes=mu_net.action_size,
)
# Simulate the state transition when taking the chosen action
# and get the predicted policy and value at that node
# This can be brought together as 'recurrent_inference'
latent, reward = [
x[0] for x in mu_net.dynamics(latent.unsqueeze(0), action_t)
]
new_policy, new_value = [
x[0] for x inmu_net.predict(latent.unsqueeze(0))
]
# Now that we've evaluated this new position,
# we call the insertion function,
# which will put a new TreeNode into current_node.children[action].
current_node.insert(action, latent, new_policy, new_value, ...)
else:
# If we have already explored this node then we take the
# child as our new current node and repeat
current_node = current_node.children[action]
Here the pick_action function is doing a lot of work in deciding the form of our exploration.
We pick the action with the following function:
def pick_action(self):
"""
Gets the score each of the potential actions and picks the one with the highest
"""
total_visit_count = sum(a.num_visits for a in self.children if a)
scores = [
self.action_score(a, total_visit_count)
for a in range(self.action_size)
]
max_score = max(scores)
# Need to be careful not to always pick the first action as it common
# that two are scored identically
action = np.random.choice(
[a for a in range(self.action_size) if scores[a] == max_score]
)
return action
The action score function has the following formula, which is designed to calculate the upper confidence bound of an action:
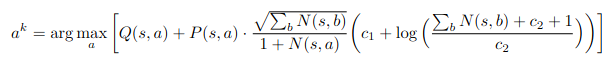
This formula is more complicated than the actual work it does because the constants used in the paper are which means that with on the order of 100 simulations, the final log never differs much from one and can be ignored. The rest is a balance between the score that has been found so far, and the product of the prior and explore term favouring new actions. The impact of the explore term is to dilute the strength of the prior as the number of simulations grows, so that a strong prior does not overcome poor empirical results after multiple tries, and actions that score poorly on priors can still be tried. I discuss this formula and its mathematical source in more detail here.
def action_score(self, action_n, total_visit_count):
"""
Scoring function for the different potential actions,
following the formula in Appendix B of MuZero
"""
child = self.children[action_n]
n = child.num_visits if child else 0
# minmax.normalize interpolates the value between the highest
# and lowest values seen in the run so far.
q = self.minmax.normalize(child.average_value) if child else 0
prior = self.policy_pred[action_n]
# This term increases the prior on those actions which have been taken
# only a small fraction of the current number of visits to this node
explore_term = math.sqrt(total_visit_count) / (1 + n)
# This is intended to more heavily weight the prior
# as we take more and more actions.
# Its utility is questionable, because with on the order of 100
# simulations, this term will always be very close to 1.
balance_term = c1 + math.log((total_visit_count + c2 + 1) / c2)
score = q + (prior * explore_term * balance_term)
return score
Now that we know how to create and traverse this tree of simulations, we can roll this into a search() function, return the root node, and play the game as follows:
while not over and frames < config["max_frames"]:
# Makes a single tensor from past frames and actions, varies by game type.
frame_input = get_frame_input()
# tree is the root node of the exploration tree defined earlier
tree = search(
config, mu_net, frame_input, minmax, log_dir, device=device
)
# pick_game_action is a function which looks at the tree we've
# generated and decides which action to take in the actual game,
# based on the number of visits we've made to each node.
# temperature defines how noisy we are in picking the most chosen action
# in the tree
action = tree.pick_game_action(temperature=temperature)
# Taking the next action in the environment
frame, reward, over, _ = env.step(action)
# Adding the details of this step to the object which saves the trajectory
game_record.add_step(frame, action, reward, tree)
frames += 1
We can now play the game using MuZero, and just need to save the results in order to train and learn. We don't need to save the whole tree, just the visit counts (which is our policy), action, rewards, values and observations. The observations for Atari games can quickly get large so these are converted into np.uint8 arrays before saving to minimize their footprint.
Training:
Training a network of this type is quite ordinary in many ways but the structure of the system, in which we learn a recurrent dynamics network, requires a bit of extra work.
The first question is what are our training targets?
- The reward head of the
dynamicsfunction should predict the reward given by the game. - The
predictfunction should predict- the value target (which is the discounted next
config[reward_depth]steps of true reward plus the predicted value at theconfig[reward_depth]'th step), - the policy target, (which is the proportion of the total rollouts which went through each of the children of the root node, according to the above described search algorithm).
- the value target (which is the discounted next
Just as important though, we also want to train our representation and dynamics functions to be able to simulate a trajectory of the game. To do this, if we include in our batch step i of game j, the batch will contain the observation at i, but the rewards, values, and policies at steps i : i + config[rollout_depth]. We can then turn the observation into the latent with represent(obs) , use the actions taken in game to apply dynamics(latent, action) to this latent multiple times, and then predict the rewards, value and policies for each of these multiple steps with predict(latent). The resulting loss, when backpropagated, will train not just the predict, but also the represent and dynamics functions, all in one step!
weights are included because we want to train more often on the cases where our value guesses have been incorrect, but these need to be down-weighted a corresponding amount so as not to bias the value network.
depths are included as there will not always be enough time left in the game to do a full rollout, and so the depths tensor.
The overall batch therefore looks as follows, with the first two dimensions of each target tensor being batch_size and rollout_depth:
(
images,
actions,
target_values,
target_rewards,
target_policies,
weights,
depths,
) = ray.get(next_batch)We need to do this training within a for loop, rather than as a single forward pass, because the dynamics function requires the output of the previous dynamics function. The dynamics function is therefore a single iteration of a recurrent neural network (and getting a recurrent reinforcement learning setup to train correctly can be as fiddly as it sounds). The need for so many different forward passes makes training each batch quite slow, and could probably be significantly optimized.
for i in range(config["rollout_depth"]):
# The screen_t tensor allows us to remove all cases where
# there are fewer than i steps of data
screen_t = torch.tensor(depths) > i
if torch.sum(screen_t) < 1:
continue
target_value_step_i = target_values[:, i]
target_reward_step_i = target_rewards[:, i]
target_policy_step_i = target_policies[:, i]
pred_policy_logits, pred_value_logits = mu_net.predict(latents)
new_latents, pred_reward_logits = mu_net.dynamics(latents, one_hot_actions)
# We scale down the gradient, I believe so that the gradient
# at the base of the unrolled network converges to a maximum
# rather than increasing linearly with depth
new_latents.register_hook(lambda grad: grad * 0.5)
pred_values = support_to_scalar(
torch.softmax(pred_value_logits[screen_t], dim=1)
)
pred_rewards = support_to_scalar(
torch.softmax(pred_reward_logits[screen_t], dim=1)
)
value_loss = torch.nn.MSELoss()
reward_loss = torch.nn.MSELoss()
value_loss = value_loss(pred_values, target_value_step_i[screen_t])
reward_loss = reward_loss(pred_rewards, target_reward_step_i[screen_t])
policy_loss = mu_net.policy_loss(
pred_policy_logits[screen_t], target_policy_step_i[screen_t]
)
batch_policy_loss += (policy_loss * weights[screen_t]).mean()
batch_value_loss += (value_loss * weights[screen_t]).mean()
batch_reward_loss += (reward_loss * weights[screen_t]).mean()
latents = new_latents
This is a bit of a wall of code but basically what we're doing is to build up the losses by unrolling, screening at each step to remove games that have finished, and scaling down the gradient at each step so that the gradient converges to a finite value rather than scaling linearly with depth.
The network is unrolled to a particular depth, here called config[rollout_depth] which is always set to 5, but each individual example in a batch may not be this deep, because the game may end in fewer than 5 steps.
When we finally backpropagate, we train the entire system with a single call to optimizer.step().
# Zero the gradients in the computation graph and then
# propagate the loss back through it
mu_net.optimizer.zero_grad()
batch_loss.backward()
# I've found clipping the gradient is very important for training stability.
if config["grad_clip"] != 0:
torch.nn.utils.clip_grad_norm_(mu_net.parameters(), config["grad_clip"])
mu_net.optimizer.step()Support to scalar
One notable detail is the use of support_to_scalar functions (and their inverse, scalar_to_support). These are a slightly peculiar piece of MuZero, by which the value and reward functions, although they are ultimately predicting a scalar, actually predict logits of a distribution over numbers. The numbers represented by each position in the predicted 'support' vector are roughly proportional to the square of their centered position, so a support of width 5 would correspond to values roughly , and logits which softmax to would correspond to a final value of -2.5 (although the details are slightly more complex).
Reanalysing:
This is the addition mentioned in MuZero reanalyse, and basically reassesses the values and policies in past games.
More specifically, the target 'value' is the discounted sum of the next config[value_depth]=5 steps of actual reward, plus the estimated future reward after these 5 steps. While clearly not a perfect picture of value, this is enough to bootstrap the value estimating function. This target value will be worse if the value estimation function is worse, which means that the older value estimates will provide a worse signal, and so the reanalyser goes through old games, and updates the value estimates using the new, updated value function.
Updating these values basically consists of constructing trees exploring the game at each node, just as if we were playing the game
p = buffer.get_reanalyse_probabilities()
ndxs = buffer.get_buffer_ndxs()
ndx = np.random.choice(ndxs, p=p)
game_rec = buffer.get_buffer_ndx(ndx) # Gets the game record at ndx in the buffer
values = []
search_stats = []
for i in range(len(game_rec.observations) - 1):
obs = game_rec.get_last_n(pos=i)
new_root = search(current_frame=obs, ...)
values.append = new_root.average_value
search_stats.append(
[c.num_visits if c else 0 for c in new_root.children]
)
buffer.update_game_info.remote(ndx=ndx, values=values, search_stats=search_stats)Actor Classes:
To speed up training and playing, we parallelize by converting the main classes into 'actors', as defined by the ray framework. This means wrapping classes with the ray.remote() decorator, and then calling their functions with ray.get(actor.func.remote(*func_args)) instead of actor.func(*func_args).
The basic classes are the Player, Trainer, and Reanalyser, and each of these have access to a Memory class and a Buffer class from which to pull data.
EfficientZero Implementation:
EfficientZero builds upon MuZero. There are three changes to the underlying algorithm, well summarized in this post [? · GW]. They also massively shrink the size of the networks, going from 16 residual blocks in the dynamics function from MuZero, to only 1. I'll go these three changes in turn, and what they look like as changes to the code.
Value prefix
In MuZero, the network tries to predict the reward at each time point This apparently causes difficulty due to the 'state aliasing' problem, by which the model needs to predict exactly which frame or state will give a reward, but this gets tricky with exponentially compounding error.
In EfficientZero, the 'reward' prediction target changes from being the reward in the current step to the sum of reward from the first step being analysed to the rollout_depth. The reward being predicted is the cumulative reward from the current step, to the point where we just take the estimated value at that step. This is why it's called the value prefix.
Making this change requires small changes to the way batches are put together:
class Buffer():
def make_target():
...
if self.config["value_prefix"]:
target_rewards.append(sum(self.rewards[ndx : ndx + i + 1]))
else:
target_rewards.append(self.rewards[ndx + i])
and to the dynamics net, which initially looks like this:
class DynamicsNet(nn.Module):
def forward(self, old_latent):
...
out = new_latent.reshape(batch_size, -1)
reward_logits = self.fc2(torch.relu(self.fc1(out)))
return new_latent, reward_logits
which then becomes the following:
class DynamicsLSTMNet(nn.Module):
def forward(self, old_latent, reward_hiddens):
...
out = new_latent.reshape(batch_size, -1)
# We collect the lstm section into a function which is largely
# a series of fully connected layers, but with a single LSTM
# layer in the middle.
value_prefix, new_reward_hiddens = dyna_lstm(
new_latents, reward_hiddens
)
return new_latent, value_prefix, new_reward_hiddensWhen training we initialize the hidden state as a matrix of zeros when we begin training a batch which gets fed into the first iteration of the dynamics network, and then this hidden state is passed back into the dynamics function alongside the latent vector at each time.
I find the 'state-aliasing problem' explanation of why this is a useful change not totally convincing/sufficient as it seems that rollouts are able to go much deeper than trained and still provide value and policy estimation. I guess it makes the training signal less noisy, and therefore improves the learning? I'm also not sure why an LSTM is needed since the dynamics net is already a form of RNN (maybe just add more latent dimension to help track what reward is already expected?)
Consistency Loss
The idea here is that in these deterministic games, the latent vector representing the state of the game as the network expects it to be, after a series of actions (i.e. applying the represent network to the initial observation, and then applications of the dynamics network), should be the same as the latent found after that series of actions is actually taken in game, and then the represent network is applied to the final observation.
class Trainer:
...
def train():
...
# The target latent is the representation of the observation
# at time (t + i), from the initial observation
if config["consistency_loss"]:
target_latents = mu_net.represent(images[:, i]).detach()
...
# The latent here is the latent that found by
# applying the dynamics network with the chosen
# actions to the initial latent i times.
if config["consistency_loss"]:
consistency_loss = mu_net.consistency_loss(
latents[screen_t], target_latents[screen_t]
)The consistency loss used here is a cosine loss, meaning the cosine of the angle between the latent and target_latent, interpreted as vectors in .
Off policy correction
This is a simple change that improves the value target.
The idea is simple. The value target is the sum of the next n steps of observed reward, plus the discounted expected value at the nth step. The actions taken can't be changed, so as our policy improves, the actions, and therefore the rewards will become more and more out of date, but thanks to the reanalyser, the expected value function stays up to date. It therefore improves the quality of the value target, as a proxy for what the value would be under the current policy, if we shrink n as the trajectory ages.
def get_reward_depth(self, value, tau=0.3, total_steps=100_000, max_depth=5):
if self.config["off_policy_correction"]:
# Varying reward depth depending on the length of time
# since the trajectory was generated.
# Follows the formula in A.4 of EfficientZero paper
steps_ago = self.total_values - value
depth = max_depth - np.floor((steps_ago / (tau * total_steps)))
depth = int(np.clip(depth, 1, max_depth))
else:
depth = max_depth
return depthOther interesting bits
Pitfalls:
The most difficult parts of the process were various pieces of debugging once the code was split into multiple actors. This made stepping into the code more onerous and introduced a new set of potential problems very unlike what I’d been used to.
When running on Colab using Ray actors, the traceback shows the original error class, but gives a traceback in terms of Ray libraries, rather than the original location of the code, and I also can't get into the ray debugger. With multiple actors, even the order of print statements making it to the console can be a bit disordered, making reconstructing the cause of an error tough.
The worst part, though, was when I'd got the code to a point where it was working consistently over long runs, and then set it to perform a test of various hyperparameters, and would find that after several hours, at some points it would just.. die. No error message, no hint of what caused it, the process would just end. Because I was using ray, I guessed that there was some kind of problem that broke the system in such a way that didn't allow it to exit gracefully, some kind of memory error..
After a lot of frustration and confusion, and self-inflicted damage like updating all packages, I started just ignoring it and working on something else, at which point I realized that even trivial errors weren't showing up.
Once I knew that I could replicate the 'no traceback' issue just by introducing a trivial error, I could then easily go back through the commits and find the point at which the traceback disappeared, which made finding the cause super easy.
I'd used ray.wait() instead of ray.get() to get the final results of the actors, and when one of those actors crashed, ray.wait() continued, and immediately hit the end of the script, at which point all the actors were cancelled, before even the error message could be printed! Unfortunately, I'd made this change just after flushing out all the small bugs, so was getting this blank shutdown only after hours of running. I thought it was the result of a out-of-memory error, so instead of being a simple error to find, it was found only after days of confused work.
The main takeaway was not to prematurely assume one possible cause of error. The worst case scenario, that I had some deep bug that caused an error is such a way that the process immediately died was possible, but I'd far too easily focused on this, instead of the case where I'd caused the lack of traceback myself by a silly error.
Architectural Convergence
I found myself naturally converging on similar architectures. When starting off I looked at the open implementation and the pseudocode provided by the MuZero paper to look for ideas when things weren't working, but I also made a conscious decision not to follow to the way they'd organized their code, and after a while, the differences compounded to the point where I could take much directly from their code, even if I wanted to.
Nonetheless, I often found that I was forced into becoming more similar.
For example, I'd followed the open implementation in converting my classes into Ray actors, which would then run concurrently. At first this was just the Player and the Trainer, but then having a separate Memory class, quickly became useful to hold state for the others to grab.
Within the Memory actor, I at first had the replay buffer in the Memory actor, alongside simple statistics like the elapsed number of steps and batches. .However, the buffer needs to do a lot of work to retrieve batches of data and format them into batches for training, and these long operations leave the memory actor blocked, which delays lots of things, not least a while loop which checks if the max steps has not been reached. It's therefore helpful to split the memory into one which stores and returns basic shared statistics, and a buffer actor which creates batches from the store of saved games.
Even though we're using the same algorithm for different games, there are differences in the operations - for example doing some basic normalization on the pixel values For just one or two games, it's quite easy to add if/else statements to process these differently, but this gets ugly quickly, and so it becomes a natural pattern to wrap these different functions into a game class, from which the algorithm can call these different functions without the need for switch statements, something that the open implementation also does.
Improving the algorithm
I'm not going to list potential improvements because I think this kind of architecture is a major stepping stone to intelligent in-the-world actors and I've no desire to speed up their arrival, on the off chance that the ideas are any good.
The huge shrinking of the architecture between MuZero and EfficientZero alone suggests that the parameters of this kind of algorithm aren't particularly optimized at all and there's lots of room for architectural tweaks.
Some are probably already being worked on while other wouldn't work, but I expect to see improved variants on this theme coming out quite soon - or maybe are already out there.
About Me
I'm doing this work to learn the skills needed for technical AI Safety research.
If you might be interested in hiring me for applied AI Safety work please reach out either here on LW or at hoagycunningham@gmail.com.
9 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-07-04T14:18:20.602Z · LW(p) · GW(p)
Very nice! I think the original paper used a ~20GB model and ~20 CPUs (so 20 or some small multiple GPUs), to train in 7 hours. How much have you shrunk it to make training doable and tolerable on colab?
Replies from: Hoagy↑ comment by Hoagy · 2022-07-04T16:50:02.171Z · LW(p) · GW(p)
Where does the 20GB number come from? I can't see it in a quick scan of the paper. In general, the model itself isn't that huge, in particular, they really shrink the dynamics net down to a single ResNet, it's mostly the representation function which has the parameters.
Despite that, training on Colab isn't really that tolerable. In 10h of training it does about 100k steps but I think only a small fraction of the amount of training of the paper's implementation (though I don't have numbers on how many batches they get through) so it's very hard to work out whether it's training or if a change has had a positive effect.
Basically I've been able to use what I think is the full model size, but the quantity of training is pretty low. I'm not sure if I'd have better performance if I cut the model size to speed up the training loop but I suspect not because that's not been visible in CPU runs (but then I may also just have some error in my Atari-playing code).
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-07-04T17:06:46.980Z · LW(p) · GW(p)
Ah. I was remembering something about 20GB from their github, but it looks like it doesn't correspond to model size like I thought. (I also forgot about the factor of ~3 difference between model size on disk and GPU usage, but even beyond that...)
Replies from: Hoagy↑ comment by Hoagy · 2022-07-05T09:49:36.342Z · LW(p) · GW(p)
Ah cheers, I'd not noticed that, trying to avoid looking too much. The way I understood it was that the DRAM usage corresponded very roughly to n_parameters * batch_size and with the batch_size I was able to tune the memory usage easily.
I'd not heard about the factor of 3, is that some particular trick for minimizing the GPU RAM cost?
comment by charlesrwest · 2022-07-05T02:20:22.003Z · LW(p) · GW(p)
If I may ask, has anyone been able to replicate their original results? I've been hesitant to sink many resources into it because it's not clear.
Also, how much compute do you need? Are you that adverse to simple real world applications such as sidewalk delivery robots?
Replies from: Hoagy↑ comment by Hoagy · 2022-07-05T09:39:56.856Z · LW(p) · GW(p)
If I may ask, has anyone been able to replicate their original results?
I can't be sure I've not missed something but I haven't found anything, did another search just now. Their code is all on github here so it could be quite easily checked with access to a cluster of GPUs.
Perhaps the more interesting question though, from a production perspective would be how well this system scales up to medium and large amounts of data/training. Does it fall behind MuZero and if so, when? If so, which of the algorithm changes cause this? What if the model complexity was brought back up to the size of MuZero?
How much compute do you need?
It depends on how broken my system is. A single run on a single game they claim takes 7 hours on 4 20GB GPUs, so a proper evaluation would take perhaps a week. In reality I'd need to first get it set up, and for full replication would need to port the MCTS code to C which would be new to me and get the system distributing work across the GPUs correctly. Then it'd be a case of seeing how well it's training and debugging failure - it all seems to work on simple games but even with the limited training I can do I think it should be better on Atari, though it's hard to be sure. In total I guess a couple of months with access would be needed - it's all pretty new to me, that's why I'm doing it!
Are you that adverse to simple real world applications such as sidewalk delivery robots?
In terms of potential jobs? Yeah I'm sufficiently worried about AGI that I plan to at least exhaust my options for working on alignment full time before considering other employment, other than short-term ML work to help build skills.
Replies from: charlesrwest↑ comment by charlesrwest · 2022-07-05T14:24:39.534Z · LW(p) · GW(p)
Would a AWS G4ad.16xlarge instance be sufficient to match their setup? My open source robotics startup is not particularly well funded, but I am extremely interested in seeing someone replicate their results and could potentially help some with compute costs.
I don't have the funds to offer a full time position anyway. It's more that I would like to see reinforcement learning become practical for solving problems such as "get from your current gps position to this one without crashing" and your previous comments about improvements seem to indicate some opposition to that sort of thing due to concerns about where it could lead.
I would be interested in collaboration, but I am trying to solve a immediate real world problem.
Replies from: Hoagy↑ comment by Hoagy · 2022-07-05T18:48:02.599Z · LW(p) · GW(p)
Looking at:
Setup Property | AWS G4ad.16xlarge | Claimed Eff0 setup
n GPU | 4 | 4
n CPU | 64 | 96
memory/GPU | 8GB | 20GB
So not sure you could do a perfect replication but you should be able to do a similar run to their 100K steps runs in less than a day I think.
I would also potentially be interested in collaboration - there are some things I'm not keen to help with and especially to publish on but I think we could probably work something out - I'll send you a DM tomorrow.
Replies from: charlesrwest↑ comment by charlesrwest · 2022-07-05T19:04:17.337Z · LW(p) · GW(p)
Sounds good. Thanks