Imitation Learning from Language Feedback
post by Jérémy Scheurer (JerrySch), Tomek Korbak (tomek-korbak), Ethan Perez (ethan-perez) · 2023-03-30T14:11:56.295Z · LW · GW · 3 commentsContents
Why Language Feedback? Language Feedback is a Natural Abstraction for Humans RLHF Does Not Leverage Many Bits of Information, Leaving Room for Goal Misgeneralization Language Feedback on Processes (vs. Outcomes) ILF Trains a Predictive Model Sample Efficiency Can ILF replace RLHF? The Problem of Scalable Oversight Main Results Comparison to “Training Language models with Language Feedback” (Scheurer et al. 2022) None 3 comments
TL;DR: Specifying the intended behavior of language models is hard, and current methods, such as RLHF, only incorporate low-resolution (binary) feedback information. To address this issue, we introduce Imitation learning from Language Feedback (ILF), an iterative algorithm leveraging language feedback as an information-rich and natural way of guiding a language model toward desired outputs. We showcase the effectiveness of our algorithm in two papers on the task of summary writing (Scheurer et al. 2023) and code generation (Chen et al. 2023). We discuss how language feedback can be used for process-based supervision and to guide model exploration, potentially enabling improved safety over RLHF. Finally, we develop theory showing that our algorithm can be viewed as Bayesian Inference, just like RLHF, which positions it as a competitive alternative to RLHF while having the potential safety benefits of predictive models.
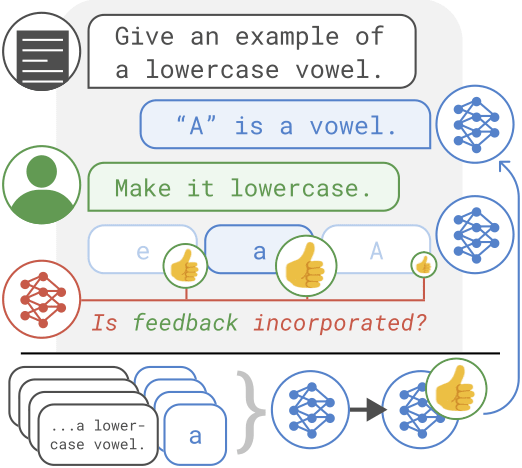
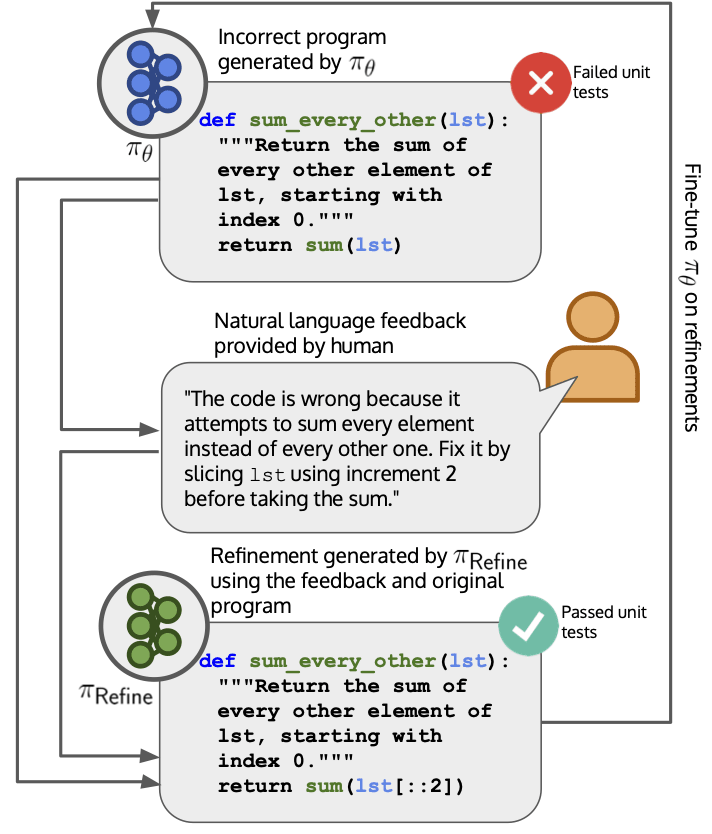
We propose an iterative algorithm called Imitation learning from Language Feedback (ILF) that leverages language feedback to train language models to generate text that (outer-) aligns with human preferences. The algorithm assumes access to an initial LM which generates an output given a specific input. A human then provides language feedback on the input-output pair. The language feedback is not restricted in any way and can highlight issues, suggest improvements, or even acknowledge positive aspects of the output. ILF then proceeds in three steps:
- Generate multiple refinements of the initial LM-generated output given the input and language feedback. We use a Refinement LM (e.g., an instruction-finetuned LM) to generate the refinements (one could however use the same LM that generated the initial output).
- Select the refinement that best incorporates the feedback, using a language reward model such as an instruction-finetuned LM, which we call InstructRM (Scheurer et al. 2023), or using unit tests (Chen et al. 2023).
- Finetune the initial LM on the selected refinements given the input.
These steps can be applied iteratively by using the finetuned model to generate initial outputs in the next iteration and collect more feedback on its outputs etc. Using this refine-and-finetune approach; we are finetuning an LM using language feedback in a supervised manner. A single iteration of ILF is also used as a first step in the Constitutional AI method (Bai et. al 2022). In the below figures, we show the full ILF algorithm on the task of summarization (top) and code generation (bottom).
Why Language Feedback?
Language Feedback is a Natural Abstraction for Humans
Language Models (LMs) are powerful tools that are trained on large datasets of text from the internet. However, it is difficult to specify the intended behavior of an LM, particularly in difficult tasks where the behavior can't be adequately demonstrated or defined, which can result in catastrophic outcomes caused by goal misspecification. To address this issue, we propose using language feedback as a way to outer-align [? · GW] LMs with human preferences and introduce a novel algorithm called Imitation learning from language Feedback. Compared to binary comparisons used in Reinforcement Learning with Human Feedback (RLHF), language feedback is a more natural and information-rich form of human feedback that conveys more bits of information, enabling a more nuanced and comprehensive understanding of human preferences. Additionally, expressing feedback in language provides natural abstractions that align well with human ontology. The use of language as a transmission protocol and file format has been optimized over thousands of years to facilitate human cooperation but is also a natural format for human and LM interaction since LMs have specifically been trained on language. Natural language thus provides valuable inductive biases for better generalization (Serzant et al. 2022, Coupé et al. 2019, Jian et al. 2019).
RLHF Does Not Leverage Many Bits of Information, Leaving Room for Goal Misgeneralization
Reward-based methods such as RLHF are commonly used to learn from human feedback. However, such methods often face the challenge of ambiguity and goal misgeneralization (Langosco et al. 2021, Shah et. al 2022), where the evaluation of desired outputs is limited to a binary evaluation. This leaves room for confusion (Haan et al. 2019), such as not knowing whether a certain behavior was preferred for one reason or another, e.g., “Did the human prefer this sample because I got to the goal state or because I ran to the right?”.
In contrast, language feedback is a richer way of communicating human preferences. By using natural language, humans can articulate their preferences with much higher fidelity, narrowing the window for ambiguity and goal misspecification, e.g., “The human said I should have run to the goal state, so in the future, I should always run to the goal state”. Moreover, since language feedback is grounded in human language and meaning, it can be embedded into broader societal discourse. This enables a more comprehensive understanding of human preferences, e.g., “You should always try to do the right thing, and that means understanding what “right” means in our social context”
Language Feedback on Processes (vs. Outcomes)
Language feedback can be used to give process-based feedback (Stuhlmueller et al. 2022 [LW · GW], Reppert et al. 2023), e.g., on (Chain of Thought) reasoning, code generation, or any step-by-step process that generates an output. For example, when writing code, one may write, execute, and rewrite the code in a step-by-step manner. Similarly, when conducting research, one can ask a question, get an answer, take notes, and then ask another question. In both cases, language feedback can guide the exploration of language models at each step, ensuring that the model is progressing in the desired direction. Concretely, the training procedure of ILF is process-based since it guides what each step of SGD learns by producing targets (i.e., the refinements) using language feedback.
In contrast to outcome-based supervision, where the model is optimized end-to-end and only supervised by the final result, process-based feedback allows for a more nuanced and controlled approach to learning. Outcome-based training is more susceptible to goal misspecification or specification gaming since it needs to infer what actions could have led to an output that is labeled as good or bad. For instance, in RLHF, the reward learned from human preferences is maximized in any way possible, potentially leading to dangerous instrumental subgoals or harmful behavior in the service of being helpful, harmless, and honest. A model could, for example, become sycophantic (i.e., repeating back a user’s view; Perez et al. 2022) or, in more extreme scenarios, hack a data center to set the reward to be really high. However, with process-based language feedback, one can guide the model in terms of how it should update its policy and avoid these failures by not simply optimizing the reward model at all costs. By shaping the step-by-step process of language models and providing guidance on what kinds of changes should be made to the output, language feedback can help ensure that the model progresses safely.
ILF Trains a Predictive Model
Our paper demonstrates that ILF can be viewed as Bayesian Inference, which offers valuable benefits for both practice and theory. The Bayesian perspective allows us to separate the task of learning preferences into a two-step process: first, defining a target distribution and specifying the desired behavior, and second, solving the problem of sampling from that posterior. Korbak et al. 2022 [LW · GW] also show that RLHF can be viewed as Bayesian Inference, providing a direct link between RLHF and ILF. However, at the same time, ILF does supervised finetuning and thus trains a predictive model ( Hubinger et al. 2023), which stands in stark contrast to RLHF, which uses RL.
The alignment community has long debated whether supervised finetuning is safer than RL (Steinhardt 2023 [LW · GW], Christiano 2023 [LW · GW], Steiner 2022 [LW · GW], Janus 2022 [LW · GW], Conmy et al. 2023 [LW · GW], Hubinger et al. 2023 [? · GW], inter alia). If supervised finetuning proves to have better safety properties than RL, ILF could be a viable alternative to RLHF. However, while ILF inherits all the benefits of supervised finetuning and predictive conditioning, it also inherits all its risks. Specifically, in their paper “Conditioning Predictive Models: Risks and Strategies”, Hubinger et al. 2023 raise concerns about using generative models that predict how an AI would complete an output. With the increasing use of LMs in generating text on the internet, these models are more likely to generate text that they predict an AI would have written. However, this raises the risk that an AI could predict how a malicious, unaligned AI would complete a sentence, which could have catastrophic outcomes. To address this challenge, the authors propose several potential solutions that vary in their likelihood of success:
- One could condition on worlds where superintelligent AIs are less likely.
- One could predict the past.
- One could condition on worlds where aligned AIs are more likely
- One could ask the model what worlds to condition on.
- One could factor the problem and condition in parallel on counterfactual worlds.
- One could clean the training dataset of any AI-generated text.
- One could ask for less AI capabilities (e.g., don’t create an extremely superhuman AI).
Since ILF relies heavily on LMs refining their own output by leveraging language feedback, the concern raised by Hubinger et al. 2023 is one to take seriously. One could potentially try to mitigate this by instructing LMs to generate refinements that look as human-like as possible and use an InstructRM that ranks the samples based on how likely they are to be human vs. AI-generated. Nevertheless, ILF is still subject to the proposed risks if refinements are eventually model generated (even if the model tries to imitate human text). The extent to which these concerns limit ILF depends on whether a solution can be found to address the concerns raised by Hubinger et al. 2023.
Sample Efficiency
Finally, ILF offers a promising avenue towards achieving more sample-efficient RL, allowing for human supervision to be concentrated in areas where it is most relevant, such as spending more effort per label or per line of a constitution (Bai et. al 2022), rather than simply collecting large quantities of data. Although we do not demonstrate higher sample efficiency in our papers, we believe that this approach shows potential as an alternative method that could become more sample efficient with increased model and data scale.
Can ILF replace RLHF?
The question of whether ILF can eventually replace RLHF remains a key area of investigation. Our current results show that best-of-64 sampling with a reward model, an alternative to RLHF (Nakano et al. 2021; Gao et al. 2022), outperforms a single iteration of ILF by leveraging test-time compute. We believe that multiple rounds of ILF may help to bridge this gap. However, ILF cannot currently serve as a drop-in replacement for RLHF. RLHF learns a reward model from human preferences, while ILF requires language feedback from humans on each initial output that one wants to refine and then finetune on. In RLHF, one can thus capture the human preferences and effort and encapsulate them in a reward model. One can subsequently train an LM with reference to this reward model, while ILF needs additional human effort to improve. The human effort put into writing language feedback could potentially be captured in a trained LM that outputs high-quality feedback automatically. Recent work by OpenAI, "Self-critiquing models for assisting human evaluators" by Saunders et al 2022 and Anthropic's "Constitutional AI: Harmlessness from AI Feedback" by Bai et. al 2022, explore the possibility of automatically generating high-quality feedback. But it remains an open question whether model-generated feedback will be of high enough quality to replace RLHF. Especially since collecting binary comparisons of trajectories is much easier than collecting high-quality language feedback to finetune models on. We are optimistic about LMs eventually generating high-quality feedback, but more research is needed to de-risk this approach. We are also optimistic about approaches that combine Language feedback with RLHF, as shown in Bai et. al 2022 or our work where we combine ILF with best-of-N sampling.
The Problem of Scalable Oversight
While ILF is as powerful as RLHF as a method for outer-aligning language models, it also faces the same issue of scalable oversight (Cotra 2021 [LW · GW], Bowman et. al, 2023). One proposed solution put forward is to amplify human capabilities with assistants, as in Saunders et al. 2022 and Bai et al. 2022. With ILF, we could have AI assistants aid humans in providing language feedback. Also, we might train improved refinement-selection models (i.e., improvements on InstructRM) that predict how AI-assisted humans would judge the various refinements. However, it is worth noting that if the challenge of scalable oversight is not addressed, ILF may not be a reliable method for ensuring the safe outer alignment of language models. Therefore, it is crucial to continue exploring and developing solutions that enable scalable oversight.
Main Results
Here, we provide an overview of the main results. For additional details and analysis, we refer to Scheurer et al. 2023 and Chen et al. 2023.
- We show theoretically that ILF can be viewed as Bayesian Inference, similar to RLHF.
- In Scheurer et al. 2023 we show that learning from language feedback is a capability that only emerges in the largest (175B) GPT-3 models.
- In Scheurer et al. 2023, our results indicate that one can use an instruction-finetuned LM as a reward model (InstructRM) to evaluate its own outputs and select the best one. Specifically, InstructRM evaluates whether a refinement incorporated feedback or not.
- In Scheurer et al. 2023 and Chen et al. 2023 we show LMs can improve their outputs (summaries and code) by leveraging language feedback. We specifically show that the language feedback is the main reason for the improvements.
- In Scheurer et al. 2023, we show that ILF outperforms all supervised finetuning baselines, surprisingly even supervised finetuning on human written summaries. However, best-of-64 sampling against a reward model trained on binary comparisons of summaries outperforms ILF. Finally, we do best-of-64 sampling against the finetuned ILF model with the reward model and show that this outperforms both ILF and best-of-64 sampling. This implies that both ILF and reward modeling learn independent properties about human preferences that are cumulative.
- In Scheurer et al. 2023 we report promising results for multiple rounds of ILF, a direction that we hope future work will explore more closely.
- In Chen et al. 2023 we show that the model's ability to incorporate feedback is significantly improved (three-fold) when supervised finetuning a model on this task, compared to generating 1-shot refinements.
- In Chen et al. 2023, the results show that ILF performs best overall, even outperforming finetuning on gold data (correct programs provided in the dataset) and human-written programs alone.
- In Chen et al. 2023 we analyze the importance of feedback quality and find that human feedback is more informative than InstructGPT feedback. We observe that InstructGPT often provides irrelevant or incorrect feedback (e.g., “The code is correct”, or “Great job!”) or restates the task description instead of addressing what should be repaired about the code Despite this, InstructGPT’s refinements are often correct even if the feedback itself isn’t. In contrast, human-written feedback addresses more bugs on average and never gives irrelevant feedback.
Comparison to “Training Language models with Language Feedback” (Scheurer et al. 2022)
Both Scheurer et al. 2023 and Chen et al. 2023 build upon our previous paper Scheurer et al. 2022 in which we showed that one could use language feedback to train large LMs. While many of the ideas remained, there are many key differences to our initial paper. In Chen et al. 2023 we look at guiding code generation with language feedback, which is very distinct from Scheurer et al. 2022 in which we looked at text summarization. We will thus only highlight the differences between Scheurer et al. 2023 and Scheurer et al. 2022, since both tackle the same problem.
- In Scheurer et al. 2023 we introduce ILF, an iterative algorithm for learning from language feedback, while we only introduced a single step of this same algorithm in Scheurer et al. 2022. In Scheurer et al. 2023 we theoretically show that ILF can be viewed as Bayesian Inference and that it has clear connections to RL with KL penalties (Korbak et al. 2022 [LW · GW]). Lastly, we provide some promising initial results on doing multiple steps of ILF.
- In Scheurer et al. 2023 we use an instruction-finetuned LM, i.e., InstructRM as a reward model to score each refinement and select the one that incorporates most of the feedback. In Scheurer et al. 2022 we use a contrastive pretrained text-embedding function (Neelakantan 2022) to embed the feedback and the refinements and select the refinement with the highest cosine similarity (Embedding Similarity). At the time, we wrote the feedback ourselves, and often times the feedback would include specific points about how to improve a certain output. Thus the Embedding Similarity worked particularly well in Scheurer et al. 2022. In Scheurer et al. 2023 we show that on more diverse feedback collected from annotators, the Embedding Similarity does not work anymore. The much more general InstructRM is, however, able to accurately evaluate the quality of an LMs outputs.
- In Scheurer et al. 2023 we compare ILF against using Best-of-N sampling (an RLHF alternative; Nakano et al. 2021) when leveraging the same number of training samples. We especially find that combining both ILF and Best-of-N sampling performs best and that both methods learn independent properties of human preferences.
- In Scheurer et al. 2023 we generally conduct much larger scale experiments. While in Scheurer et al. 2022 we only collected 100 samples of feedback, here we collected 5K samples of feedback and binary comparisons. Overall in Scheurer et al. 2023 we conduct a much more detailed analysis of ILF and provide additional experiments, e.g., multiple rounds of ILF, evaluating various reward models, measuring the KL-divergence of finetuned models vs. GPT-3, etc. Particularly we find that ILF outperforms supervised finetuning on human summaries.
Author List for both Papers:
Training Language Models with Language Feedback at Scale (Scheurer et al. 2023) - Jérémy Scheurer, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, Ethan Perez
Improving Code Generation by Training with Natural Language Feedback (Chen et al. 2023) - Angelica Chen, Jérémy Scheurer, Tomasz Korbak, Jon Ander Campos, Jun Shern Chan, Samuel R. Bowman, Kyunghyun Cho, Ethan Perez
We want to thank the following people for helpful conversations and feedback:
Nat McAleese, Geoffrey Irving, Jeff Wu, Jan Leike, Cathy Yeh, William Saunders, Jonathan Ward, Daniel Ziegler, Seraphina Nix, Quintin Pope, Kay Kozaronek, Asa Cooper Stickland, Jacob Pfau, David Lindner, David Dohan, Lennart Heim, Nitarshan Rajkumar, Kath Lumpante, Pablo Morena, Jan Kirchner, Edwin Chen, Scott Heiner.
3 comments
Comments sorted by top scores.
comment by Hoagy · 2023-03-30T15:36:45.243Z · LW(p) · GW(p)
Thoughts:
- Seems like useful work.
- With RLHF I understand that when you push super hard for high reward you end up with nonsense results so you have to settle for quantilization or some such relaxation of maximization. Do you find similar things for 'best incorporates the feedback'?
- Have we really pushed the boundaries of what language models giving themselves feedback is capable of? I'd expect SotA systems are sufficiently good at giving feedback, such that I wouldn't be surprised that they'd be capable of performing all steps, including the human feedback, in these algorithms, especially lots of the easier categories of feedback, leading to possibility of unlimited of cheap finetuning. Nonetheless I don't think we've reached the point of reflexive endorsement that I'd expect to result from this process (GPT-4 still doing harmful/hallucinated completions that I expect it would be able to recognise). Expect it must be one of
- It in fact is at reflexive equilibrium / it wouldn't actually recognise these failures
- OAI haven't tried pushing it to the limit
- This process doesn't actually result in reflexive endorsement, probably because it only reaches RE within a narrow distribution in which this training is occurring.
- OAI stop before this point for other reasons, most likely degradation of performance.
- Not sure which of these is true though?
- Though the core algorithm I expect to be helpful because we're stuck with RLHF-type work at the moment, having a paper focused on accurate code generation seems to push the dangerous side of a dual-use capability to the fore.
comment by [deleted] · 2023-04-02T21:46:07.204Z · LW(p) · GW(p)
Replies from: JerrySch↑ comment by Jérémy Scheurer (JerrySch) · 2023-04-09T14:22:16.851Z · LW(p) · GW(p)
Thanks a lot for this helpful comment! You are absolutely right; the citations refer to goal misgeneralization which is a problem of inner alignment, whereas goal misspecificatin is related to outer alignment. I have updated the post to reflect this.