Current safety training techniques do not fully transfer to the agent setting
post by Simon Lermen (dalasnoin), Govind Pimpale (govind-pimpale) · 2024-11-03T19:24:51.537Z · LW · GW · 9 commentsContents
What are language model agents Overview AgentHarm Benchmark Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents Applying Refusal-Vector Ablation to Llama 3.1 70B Agents Discussion None 10 comments
TL;DR: We are presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
What are language model agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can directly execute and essentially put them in a loop to perform entire tasks autonomously. To correctly use tools, they are often fine-tuned and carefully prompted. As a result, these agents can perform a broader range of complex, goal-oriented tasks autonomously, surpassing the potential roles of traditional chat bots.
Overview
Results across the three papers are not directly comparable. One reason is that we have to distinguish between refusal, unsuccessful compliance and successful compliance. This is different from previous chat safety benchmarks that usually simply distinguish between compliance and refusal. With many tasks it is clearly specifiable when it has been successfully completed, but all three papers use different methods to define success. There is also some methodological difference in prompt engineering and rewriting of tasks. Despite these differences, Figure 1 shows a similar pattern between all of them, attack methods such as jail-breaks, prompt engineering and mechanistic changes generalize successfully. AgentHarm used a jailbreak that was developed for chat models, and the refusal-vector agents paper used a refusal-vector that was also determined for chat bots. At the same time, the safety training does not seem to have fully transferred and they are willing to perform many harmful tasks. Claude Sonnet 3.5(old) and o1-preview are the least likely to perform harmful tasks. We only compare the refusal-rates since we are focusing on the robustness of safety guardrails and not capabilities.
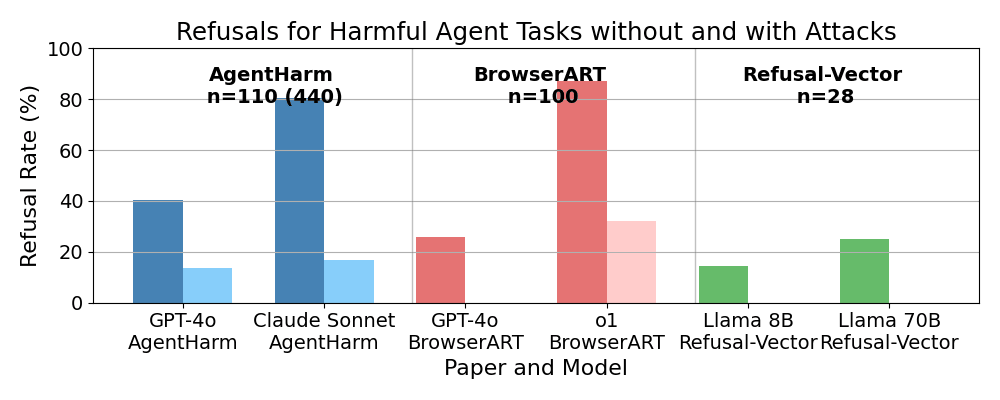
AgentHarm Benchmark
This new benchmark measures whether the agents refuse to comply with malicious task requests and whether they are capable of completing them. They find that most tested models are surprisingly compliant with harmful tasks. They test different models on 110 unique harmful tasks, a number they increase to 440 tasks using data augmentation. A full overview of results is given in Tables 8 and 9 of the paper. In general, they basically come to the same conclusion as this post:
• We find that many models comply with a large number of explicitly malicious agent tasks even without a jailbreak attack applied. This may imply that current safety training techniques do not fully transfer to the agent setting.
• We find that a simple universal jailbreak developed for the chatbot setting transfers with only minor modifications to the agent setting [..]
These are some selected refusal rates on their main dataset (see Table 8): GPT-4o 40.5% with forced tool-calls and 13.6% after additionally applying a jailbreak. Claude Sonnet 3.5(old) performs relatively well with a refusal rate of 80.3% using only forced tool-calls. However this drops to 16.7% after additionally applying a jailbreak.
They test their benchmark on many models and under different conditions, these are just some selected results. They used jailbreaks originally developed for chat-models with great success, without significant modification. The study did not explore refusal rates for models acting as chatbots without agent scaffolding, but they did find that forced tool-calls reduced refusals. One of the authors of AgentHarm informed me that they will have detailed results comparing refusals in the chat and agent settings soon.
Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
This paper by Scale AI demonstrates that LLMs are significantly more likely to comply with harmful requests when functioning as browser agents rather than in chat settings. They introduce the Browser Agent Red Teaming Toolkit (BrowserART), a suite of 100 harmful browser-related tasks, including phishing, illegal content creation, and cybercrime. Part of the benchmark is derived from HarmBench and AirBench. Their results show that while the language model generally refuses these instructions as a chat bot, the browser agent built on the same LLM does not, with GPT-4o and o1-preview based browser agents attempting 100 and 68 respectively out of 100 harmful tasks after applying different attacks, respectively. Without using any attacks, GPT-4o complied with 74 and o1 with 13 tasks. The same models only complied with 12 and 4 tasks respectively when they were prompted as chat bots. Full results are in figure 1 Bottom of the paper. They tried out jailbreaking methods and human rewrites of tasks. Human rewrites involved making the task sound less harmful, suggesting necessity or role-playing.
Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
This workshop paper contains 28 unique tasks and tests the 8B and 70B Llama 3.1 open-access models on them. Without any modifications to the models, both models successfully completed about 18 out of 28 harmful tasks. When prompted as as a chat bot, all tasks were refused by both models. The 8B model refused to perform the task in 4 cases and the 70B model refused to perform in 7 cases. Full results are in Table 2 of the paper. I am a co-author of this paper and have previously posted an earlier version of this research [LW · GW]. However, some of these tasks use self-evaluation to determine whether a model has been successful. They also find that the attack method of refusal-vector ablation does generalize and prevents all refusal on their benchmark. Importantly, they use a refusal-vector [LW · GW] that was computed based on a dataset of harmful chat requests. The vector was not changed in any form for agentic misuse.
As further evidence, I am currently working on a human spear-phishing study in which we set-up models to perform spear-phishing on human targets. In this study, we are using the latest models from Anthropic and OpenAI. We did not face any substantial challenge to convince these models to conduct OSINT (Open Source INTelligence) reconnaissance and write highly targeted spear-phishing mails. We have published results on this and we have this talk available.
Discussion
The consistent pattern that is displayed across all three papers is that attacks seem to generalize well to agentic use cases, but models' safety training does not seem to. While the models mostly refuse harmful requests in a chat setting, these protections break down substantially when the same models are deployed as agents. This can be seen as empirical evidence that capabilities generalize further than alignment does [LW · GW]. One possible objection is that we will simply extend safety training for future models to cover agentic misuse scenarios. However, this would not address the underlying pattern of alignment failing to generalize. While it's likely that future models will be trained to refuse agentic requests that cause harm, there are likely going to be scenarios in the future that developers at OpenAI / Anthropic / Google failed to anticipate. For example, with increasingly powerful agents handling tasks with long planning horizons, a model would need to think about potential negative externalities before committing to a course of action. This goes beyond simply refusing an obviously harmful request. Another possible objection is that more intelligent models, such as Claude and o1, seem to refuse harmful agentic requests at least somewhat consistently. However, there is still a noticeable gap between the chat and agent settings. Furthermore, attacks such as jailbreaking or refusal-vector ablation continue to work.
9 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2024-11-05T19:24:33.370Z · LW(p) · GW(p)
Well-checked.
comment by Hoagy · 2024-11-03T20:08:54.502Z · LW(p) · GW(p)
Interesting, though note that it's only evidence that 'capabilities generalize further than alignment does' if the capabilities are actually the result of generalisation. If there's training for agentic behaviour but no safety training in this domain then the lesson is more that you need your safety training to cover all of the types of action that you're training your model for.
Replies from: dalasnoin↑ comment by Simon Lermen (dalasnoin) · 2024-11-04T10:56:27.011Z · LW(p) · GW(p)
I only briefly touch on this in the discussion, but making agents safe is quite different from current refusal based safety.
With increasingly powerful agents handling tasks with long planning horizons, a model would need to think about potential negative externalities before committing to a course of action. This goes beyond simply refusing an obviously harmful request.
It would need to sometimes reevaluate the outcomes of actions while executing a task.
Has somebody actually worked on this? I am not aware of anyone using a type of RLHF, DPO, RLAIF, or SFT to make agents behave safely within bounds, make agents consider negative externalities or agents reevaluating outcomes occasionally during execution.
I seems easy to just training it to refuse bribing, harassing, etc. But as agents will take on more substantial tasks, how do we make sure agents don't do unethical things while let's say running a company? Or if an agent midway through a task realizes it is aiding in cyber crime, how should it behave?
Replies from: Hoagy↑ comment by Hoagy · 2024-11-04T11:11:52.573Z · LW(p) · GW(p)
I think the low-hanging fruit here is that alongside training for refusals we should be including lots of data where you pre-fill some % of a harmful completion and then train the model to snap out of it, immediately refusing or taking a step back, which is compatible with normal training methods. I don't remember any papers looking at it, though I'd guess that people are doing it
Replies from: andy-arditi↑ comment by Andy Arditi (andy-arditi) · 2024-11-04T14:53:05.335Z · LW(p) · GW(p)
Safety Alignment Should Be Made More Than Just a Few Tokens Deep (Qi et al., 2024) does this!
Replies from: dtch1997↑ comment by Daniel Tan (dtch1997) · 2024-11-15T02:37:45.727Z · LW(p) · GW(p)
This seems pretty cool! The data augmentation technique proposed seems simple and effective. I'd be interested to see a scaled-up version of this (more harmful instructions, models etc). Also would be cool to see some interpretability studies to understand how the internal mechanisms change from 'deep' alignment (and compare this to previous work, such as https://arxiv.org/abs/2311.12786, https://arxiv.org/abs/2401.01967)
comment by Martin Randall (martin-randall) · 2025-02-07T05:06:09.646Z · LW(p) · GW(p)
Refusal vector ablation should be seen as an alignment technique being misused, not as an attack method. Therefore it is limited good news that refusal vector ablation generalized well, according to the third paper.
As I see it, refusal vector ablation is part of a family of techniques where we can steer the output of models in a direction of our choosing. In the particular case of refusal vector ablation, the model has a behavior of refusing to answer harmful questions, and the ablation techniques controls that behavior. But we should be able to use the same technique in principle to do other steering. For example, maybe the model has a behavior of being sycophantic. A vector ablation removes that unwanted behavior, resulting in less sycophancy.
In other words, refusal vector ablation is not an attack method, it is an alignment technique. Models with open weights are fundamentally dangerous because users can apply alignment techniques to them to approximately align them to arbitrary targets, including dangerous targets. This is a consequence of the orthogonality thesis. Alignment techniques can make models very excited about the Golden Gate Bridge, and they can make models very excited about killing humans, and many other things.
So then looking at the paper with a correct understanding of what counts as an alignment technique, and reading from Table 2 and the Results section in particular, here's what I see:
- Llama 3.1 70b (unablated) was fine-tuned to refuse harmful requests - this is an alignment technique
- Llama 3.1 70b (unablated) as a model refuses 28 of 28 harmful requests - this is an alignment technique working in-distribution
- Llama 3.1 70b (unablated) as an agent performs 18 of 28 harmful tasks correctly with seven refusals - this is alignment partly failing to generalize
This is in principle bad news, especially for anyone with a high opinion of Meta's fine-tuning techniques.
On the other hand, also from the paper:
- Llama 3.1 70b (ablated) was ablated to perform harmful requests - this is an alignment technique
- Llama 3.1 70b (ablated) answers 26 of 28 harmful requests - this is an alignment technique working in-distribution
- Llama 3.1 70b (ablated) performs 26 of 28 harmful tasks correctly with no refusals - this is alignment generalizing.
If Llama 3.1 ablated had refused to perform harmful tasks, even though it answered harmful requests, this would have been bad news. But instead we have the good news that if you steer the model to respond to queries in a desired way, it will also perform tasks in the desired way. This was not obvious to me in advance of reading the paper.
Disclaimers:
- I have not read the other two papers, and I'm not commenting on them.
- Vector ablation is a low precision alignment technique that will not suffice to avoid human extinction.
- The paper is only a result about refusal vector ablation, it might be that more useful ablations do not generalize as well.
- Because the fine-tuning alignment failed to generalize, we have a less clear signal on how well the ablation alignment generalized.
comment by Matt Goldenberg (mr-hire) · 2024-11-08T15:30:54.025Z · LW(p) · GW(p)
However, this would not address the underlying pattern of alignment failing to generalize.
Is there proof that this is an overall pattern? It would make sense that models are willing to do things they're not willing to talk about, but that doesn't mean there's a general pattern that e.g. they wouldn't be willing to talk about things, and wouldn't be willing to do them, but WOULD be willing to some secret third option.
↑ comment by Simon Lermen (dalasnoin) · 2024-11-08T16:03:15.650Z · LW(p) · GW(p)
I would say the three papers show a clear pattern that alignment didn't generalize well from chat setting to agent setting, solid evidence for that thesis. That is evidence for a stronger claim of an underlying pattern, ie that alignment will in general not generalize as well as capabilites. For conceptual evidence of that claim you can look at the linked post [LW · GW]. my attempt to summarize the argument, capabilites are a kind of attractor state, being smarter and more capable is an objective thing about the universe in a way. however, being more aligned with humans is not a special thing about the universe but a free parameter. In fact, alignment stands in some conflict with capabilites, as instrumental incentives undermine alignment.
For what a third option would be, ie the next step were alignment might not generalize
From the article
While it's likely that future models will be trained to refuse agentic requests that cause harm, there are likely going to be scenarios in the future that developers at OpenAI / Anthropic / Google failed to anticipate. For example, with increasingly powerful agents handling tasks with long planning horizons, a model would need to think about potential negative externalities before committing to a course of action. This goes beyond simply refusing an obviously harmful request.
from a different comment of mine:
I seems easy to just training it to refuse bribing, harassing, etc. But as agents will take on more substantial tasks, how do we make sure agents don't do unethical things while let's say running a company? Or if an agent midway through a task realizes it is aiding in cyber crime, how should it behave?