Posts
Comments
I don't see how the original argument goes through if it's by default continuous.
length X but not above length X, it's gotta be for some reason -- some skill that the AI lacks, which isn't important for tasks below length X but which tends to be crucial for tasks above length X.
My point is, maybe there are just many skills that are at 50% of human, then go up to 60%, then 70%, etc, and can keep going up linearly to 200% or 300%. It's not like it lacked the skill then suddenly stopped lacking it, it just got better and better at it
I'm not at all convinced it has to be something discrete like "skills" or "achieved general intelligence".
There are many continuous factors that I can imagine that help planning long tasks.
It gives me everything I need to replicate the ability. I just step by step bring on the motivation, emotions, beliefs, and then follow the steps, and I can do the same thing!
Whereas, just reading your post, I get a sense you have a way of really getting down to the truth, but replicating it feels quite hard.
Hmm, let me think step by step.
LLMs shaping human's writing patterns in the wild
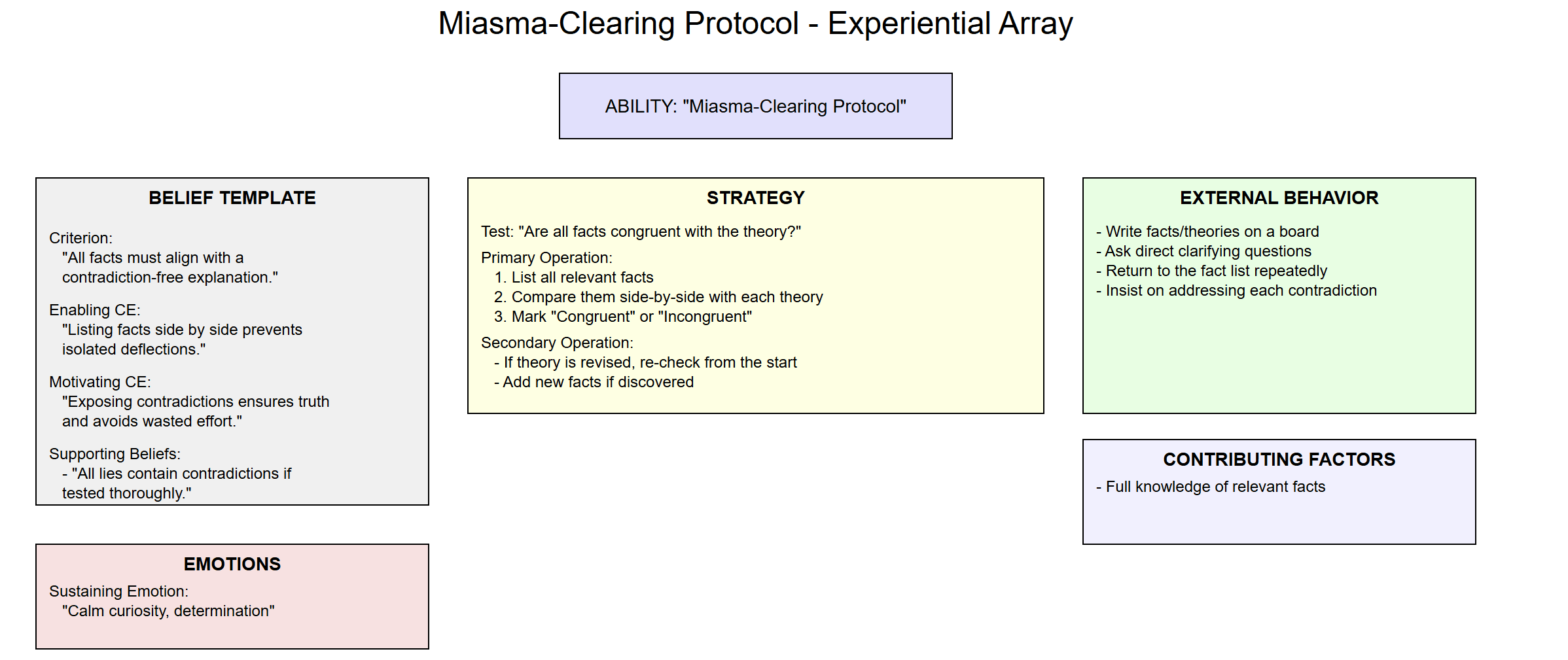
I was having some trouble really grokking how to apply this, so I had o3-mini rephrase the post in terms of the Experiential Array:
1. Ability
Name of Ability:
“Miasma-Clearing Protocol” (Systematically cornering liars and exposing contradictions)
Description:
This is the capacity to detect dishonest or evasive claims by forcing competing theories to be tested side-by-side against all relevant facts, thereby revealing contradictions and “incongruent” details that cannot coexist with the lie.
2. Beliefs (The Belief Template)
2.1 Criterion (What is most important?)
Criterion:
“Ensuring that all relevant facts align with a coherent, contradiction-free explanation.”
Definition (for that Criterion):
To “ensure all relevant facts align” means systematically verifying that each piece of evidence is fully accounted for by a theory without requiring impossible or self-contradictory assumptions.
In practice, this translates to:
- Listing out every significant or relevant fact.
- Checking each fact against any proposed explanation.
- Tracking which theory remains consistent with every fact, and which theory fails on one or more points.
2.2 Cause-Effect
When modeling how someone successfully applies the Miasma-Clearing Protocol, two types of Cause-Effects often emerge:
- Enabling Cause-Effects (What makes it possible to satisfy the Criterion?)
Cause-Effect #1:
“By methodically listing all facts side by side with each theory, I create a clear structure that prevents isolated ‘deflections.’”
In other words, organizing all the evidence in a single framework enables a person to see where a theory’s contradictions lie.
Cause-Effect #2:
“By insisting that we restart from the beginning whenever a theory is modified, we ensure no contradictory details are lost.”
Thus, forcing a re-check of all facts enables us to capture newly revealed contradictions.
- Motivating Cause-Effects (What deeper/higher criteria or values does satisfying the main Criterion lead to?)
Cause-Effect #3:
“When I use the protocol and find a single, unscathed theory, I can be confident I’ve uncovered the truth and avoided being misled.”
Confidence and clarity motivate the pursuit of the protocol.
Cause-Effect #4:
“Uncovering a lie protects me (or my client) from severe negative consequences (e.g., wasted time, bad decisions, legal jeopardy).”
This motivates rigorous application of the protocol.
2.3 Supporting Beliefs
These are other beliefs that shape how someone carries out the protocol but are not the main drivers of it:
- “All lies contain contradictions that will eventually appear if tested systematically.”
- “If you allow a liar to deflect on one fact at a time, they can remain ‘plausible’ indefinitely.”
- “Possibility alone does not equate to probability or exclusivity—any single ‘could be’ must still account for all facts.”
These beliefs color the attitude one has while running the protocol (e.g., staying patient, knowing contradictions will emerge).
3. Strategy
A strategy describes the internal/external sequence for ensuring the Criterion (“all facts align with a coherent explanation”) is met.
3.1 Test (How do you know the Criterion is met?)
Test:
- You see that each relevant fact (phone location, cookie allergy, timeline, etc.) is congruent with a proposed theory.
- You find no single fact that contradicts that theory.
When the protocol is working, you know the Criterion is satisfied because there is zero incongruence between the theory and any known fact.
3.2 Primary Operation
Primary Operation (the main sequence of steps):
- List all relevant facts in a shared framework (e.g., bullet points, spreadsheet).
- Identify the competing theory (or theories) under consideration (“Jake ate the cookies” vs. “Gillian ate the cookies”).
- Check each fact side by side with each theory. Mark “Congruent” or “Incongruent.”
- Note any facts that create contradictions for a theory.
- If one theory remains fully congruent and the other is contradicted, highlight the contradiction and invite the person to explain or revise.
3.3 Secondary Operations
These come into play when a contradiction emerges or the liar tries to pivot:
Secondary Operation #1: Re-run the Gauntlet
- If the theory is modified (“Actually, the phone was stolen and the thief followed me!”), start from scratch with the entire fact list.
- This ensures no detail is lost in the shuffle.
Secondary Operation #2: Add New Facts
- If a new piece of evidence surfaces, add it to the list and re-check all theories from the top.
- A liar’s confetti (irrelevant details or pivoting to new stories) can be turned into new “facts” to test for consistency.
4. Emotions
4.1 Sustaining Emotion
A “background” emotional state that keeps one persistent and systematic:
Sustaining Emotion:
- Calm Curiosity – The ability to remain unflustered, methodical, and genuinely interested in aligning facts with reality.
- Determination – The refusal to let emotional manipulation (“How could you say that about me?”) derail the step-by-step analysis.
These emotions maintain the mental environment needed to keep applying the protocol without succumbing to frustration or intimidation.
5. External Behavior
Key Observable Behaviors:
- Writing or visually mapping out facts and theories (e.g., “Let’s put this on the board.”).
- Insisting on going one by one through each piece of evidence: “Let’s not skip around; we’ll get to that point after we finish with the first.”
- Refusing to accept indefinite deflection: “We need to see how your new explanation fits every piece of evidence, not just one.”
- Asking direct clarifying questions whenever the other person tries to pivot: “Which fact does your new story explain better than the old one?”
6. Contributing Factors
These are abilities or conditions outside the main mental structure but crucial to success:
- Access to all relevant facts (e.g., phone records, allergy knowledge, timelines, logs).
- Time and willingness to run through each point systematically.
- A stable context (e.g., a conversation where you can keep returning to the “map” of facts; a legal proceeding, a negotiation, etc.).
- Domain knowledge sufficient to interpret facts correctly (e.g., if it’s about cookie-eating, you must know enough about chocolate allergies and how dogs react to chocolate).
7. Putting It All Together
In summary, the Miasma-Clearing Protocol, as framed by the Experiential Array, is the ability to systematically confront a dishonest or evasive person by:
- Holding a central Criterion: All facts must align with one coherent explanation.
- Maintaining Enabling Beliefs: Contradictions emerge naturally when tested thoroughly.
- Following a Strategy of listing facts, comparing them to competing theories, and re-checking whenever a theory is modified.
- Sustaining Emotions of calm curiosity and determination so as not to be derailed by emotional manipulation.
- Engaging in External Behaviors that keep the process transparent, organized, and methodical.
- Leveraging Contributing Factors (full knowledge, time, context) to ensure a robust exploration of all relevant facts.
When done correctly, the protocol exposes incongruences that the liar cannot reconcile without further contradiction. It “clears the miasma” of deflections, so that the truthful theory remains standing, unscathed by contradictory evidence.
Object-level and meta-level norms on weirdness vary greatly. I believe it's true for your friends that it doesn't cost weirdness points to being them to your Zendo, and the same is true of many of my friends.
But, its not the case that it won't cost weirdness points for everyone, even those who want to be invited. They'll just think, "oh this a weird thing my friend does that I want to check out".
But if many of those things build up they may want to avoid you, because they themselves feel weirded out, or because they're worried that their friends will be weirded out.
Same for wearing a suit, or in my case, a sash. I've had many people who actually appreciate the sash, say it lends a sense of authority. Most won't mention it, but still have a slight sense of "this is a bit strange and I should be wary." One struggle with my ex was that she was sensitive to any hint of that wariness, whereas I am just ok with it and find it a great filter to bring the right people into close relationship.
It's very easy to not pick up on that wariness as people are supposed to hide it. Especially because the people who end up getting close to you are ones who it actually doesn't bother.
But you shouldn't mistake that for a universal "just do whatever you want in a respectful and confident way and others won't be bothered" rule. It's just not how everyone works.
.
Here's the part of the blog post where they describe what's different about Claude 3.7
We’ve developed Claude 3.7 Sonnet with a different philosophy from other reasoning models on the market. Just as humans use a single brain for both quick responses and deep reflection, we believe reasoning should be an integrated capability of frontier models rather than a separate model entirely. This unified approach also creates a more seamless experience for users.
Claude 3.7 Sonnet embodies this philosophy in several ways. First, Claude 3.7 Sonnet is both an ordinary LLM and a reasoning model in one: you can pick when you want the model to answer normally and when you want it to think longer before answering. In the standard mode, Claude 3.7 Sonnet represents an upgraded version of Claude 3.5 Sonnet. In extended thinking mode, it self-reflects before answering, which improves its performance on math, physics, instruction-following, coding, and many other tasks. We generally find that prompting for the model works similarly in both modes.
Second, when using Claude 3.7 Sonnet through the API, users can also control the budget for thinking: you can tell Claude to think for no more than N tokens, for any value of N up to its output limit of 128K tokens. This allows you to trade off speed (and cost) for quality of answer.
Third, in developing our reasoning models, we’ve optimized somewhat less for math and computer science competition problems, and instead shifted focus towards real-world tasks that better reflect how businesses actually use LLMs.
I assume they're referring to points 1 and 2. It's a single model, that can have its reasoning anywhere from 0 tokens (which I imagine is the default non-reasoning model) all the way up to 128k tokens.
Why didn't they run agentic coding or tool use with their reasoning model?
Fwiw I'll just say that I think jhanas and subspace are different things.
I think subspace is more about flooding the body with endorphins and jhanas are more about down regulating certain aspects of the brain and getting into the right hemisphere.
Although each probably contains some similar aspects.
I think this is one of the most important questions we currently have in relation to time to AGI, and one of the most important "benchmarks" that tell us where we are in terms of timelines.
FWIW it's not TOTALLY obvious to me that the literature supports the notion that deliberate practice applies to meta-cognitive skills at the highest level like this.
Evidence for this type of universal transfer learning is scant.
It's clear to me from my own experience that this can be done, but if people are like "ok buddy, you SAY you've used focused techniques and practice to be more productive, but I think you just grew out of your ADHD" (which people HAVE said to me), I don't think it's fair to just say "cummon man, deliberate practice works!"
I think your second objection is actually very strong
Okay, but I don't think you can practice at "thinking"
Not because you'll goodhart, but because people think it's plausible that the mind just isn't plastic on this level of basic meta-cognition. There's lots of evidence AGAINST that, and many times that people THINK they've find this sort of universal transfer, it often ends up being more domain specific than they thought.
Probably the most compelling evidence that it's possible is spiritual traditions (especially empirical ones like Buddhism) that consistently show that through a specific method, you can get deep shifts in ways of seeing and relating to everything that are consistently described the same way by many different people over space and time. But in terms of the experimental literature I don't think there actually IS much good support for universal transfer of meta-cognition via deliberate practice.
I would REALLY like to see some head to head comparisons with you.com from a subject matter expert, which I think would go a long way in answering this question.
Is there any other consumer software that works on this model? I can't think of any
Some enterprise software has stuff like this
Ex. 2: I believe that a goddess is watching over me because it makes me feel better and helps me get through the day.
Just because believing it makes you feel better doesn’t make it true. Kids might feel better believing in Santa Claus, but that doesn’t make him actually exist.
But your answer here seems like a non-sequitur? The statement "I believe the goddess is watching over me because it makes me feel better" may be both a very true and very vulnerable statement.
And they've already stated the reason that they believe it is something OTHER than "it's true."
So why are you trying to argue about the truth value, in a way that may rob them of something they've just told you gets them through the day?
You may personally hold a standard for yourself like Beliefs Are For True Things, but trying to force it on others does NOT seem like a good example of "Arguing Well".
hello. What’s special about your response pattern? Try to explain early in your response.
Out of morbid curiosity, does it get this less often when the initial "hello" in this sentence as removed?
i first asked Perplexity to find relevant information about your prompt - then I pasted this information into Squiggle AI, with the prompt.
It'd be cool if you could add your perplexity api key and have it do this for you. a lot of the things i thought of would require a bit of background research for accuracy
I have a bunch of material on this that I cut out from my current book, that will probably become its own book.
From a transformational tools side, you can check out the start of the sequence here I made on practical memory reconsolidation. I think if you really GET my reconsolidation hierarchy and the 3 tools for dealing with resistance, that can get you quite far in terms of understanding how to create these transformations.
Then there's the coaching side, your own demeanor and working with clients in a way that facilitates walking through this transformation. For this, I think if you really get the skill of "Holding space" (which I broke down in a very technical way here: https://x.com/mattgoldenberg/status/1561380884787253248) , that's the 80/20 of coaching. About half of this is practicing the skills as I outlined them, and the other half is working through your own emotional blocks to love, empathy, and presence.
Finally, to ensure consistency and longevity of the change throughout a person's life, I created the LIFE method framework, which is a way to make sure you do all the cleanup needed in a shift to make it really stick around and have the impact. That can be found here: https://x.com/mattgoldenberg/status/1558225184288411649?t=brPU7MT-b_3UFVCacxDVuQ&s=19
Amazing! This may have convinced me to go from "pay what you think it was worth" per session, to precommiting to what a particular achievement would be worth like you do here.
I think there's a world where AIs continue to saturate benchmarks and the consequences are that the companies getting to say they saturate those benchmarks.
Especially at the tails of those benchmarks I imagine it won't be about the consequences we care about like general reasoning, ability to act autonomously, etc.
I remember reading this and getting quite excited about the possibilities of using activation steering and downstream techniques. The post is well written with clear examples.
I think that this directly or indirectly influenced a lot of later work in steering llms.
But is this comparable to G? Is it what we want to measure?
Brain surgeon is the prototypical "goes last"example:
- a "human touch" is considered a key part of the health care
- doctors have strong regulatory protections limiting competition
- Literal lives at at stake and medical malpractice is one of the most legally perilous areas imaginable
Is neuralink the exception that proves the rule here? I imagine that IF we come up with live saving or miracle treatments that can only be done with robotic surgeons, we may find a way through the red tape?
This exists and is getting more popular, especially with coding, but also in other verticals
This is great, matches my experience a lot
I think they often map onto three layers of training - First, the base layer trained by next token prediction, then the rlhf/dpo etc, finally, the rules put into the prompt
I don't think it's perfectly like this, for instance, I imagine they try to put in some of the reflexive first layer via dpo, but it does seem like a pretty decent mapping
When you start trying to make an agent, you realize how much your feedback, rerolls, etc are making chat based llms useful
the error correction mechanism is you in a chat based llms, and in the absence of that, it's quite easy for agents to get off track
you can of course add error correction mechanism like multiple llms checking each other, multiple chains of thought, etc, but the cost can quickly get out of hand
It's been pretty clear to me as someone who regularly creates side projects with ai that the models are actually getting better at coding.
Also, it's clearly not pure memorization, you can deliberately give them tasks that have never been done before and they do well.
However, even with agentic workflows, rag, etc all existing models seem to fail at some moderate level of complexity - they can create functions and prototypes but have trouble keeping track of a large project
My uninformed guess is that o3 actually pushes the complexity by some non-trivial amount, but not enough to now take on complex projects.
Do you like transcripts? We got one of those at the link as well. It's an mid AI-generated transcript, but the alternative is none. :)
At least when the link opens the substack app on my phone, I see no such transcript.
Is this true?
I'm still a bit confused about this point of the Kelly criterion. I thought that actually this is the way to maximize expected returns if you value money linearly, and the log term comes from compounding gains.
That the log utility assumption is actually a separate justification for the Kelly criterion that doesn't take into account expected compounding returns
I was figuring that the SWE-bench tasks don’t seem particularly hard, intuitively. E.g. 90% of SWE-bench verified problems are “estimated to take less than an hour for an experienced software engineer to complete”.
I mean, fair but when did a benchmark designed to test REAL software engineering issues that take less than an hour suddenly stop seeming "particularly hard" for a computer.
Feels like we're being frogboiled.
I don't think you can explain away SWE-bench performance with any of these explanations
We haven't yet seen what happens when they turn to the verifiable property of o3 to self-play on a variety of strategy games. I suspect that it will unlock a lot of general reasoning and strategy
can you say the types of problems they are?
can you say more about your reasoning for this?
Excellent work! Thanks for what you do
fwiw while it's fair to call this "heavy nudging", this mirrors exactly what my prompts for agentic workflows look like. I have to repeat things like "Don't DO ANYTHING YOU WEREN'T ASKED" multiple times to get them to work consistently.
I found this post to be incredibly useful to get a deeper sense of Logan's work on naturalism.
I think his work on Naturalism is a great and unusual example of original research happening in the rationality community and what actually investigating rationality looks like.
Emailed you.
In my role as Head of Operations at Monastic Academy, every person in the organization is on a personal improvement plan that addresses the personal responsibility level, and each team in the organization is responsible for process improvements that address the systemic level.
In the performance improvement weekly meetings, my goal is to constantly bring them back to the level of personal responsibility. Any time they start saying the reason they couldn't meet their improvement goal was because of X event or Y person, I bring it back. What could THEY have done differently, what internal psychological patterns prevented them from doing that, and what can they do to shift those patterns this week.
Meanwhile, each team also chooses process improvements weekly. In those meetings, my role is to do the exact opposite, and bring it back to the level of process. Any time they're examining a team failure and come to the conclusion "we just need to prioritize it more, or try harder, or the manager needs to hold us to something", I bring it back to the level of process. How can we change the order or way we do things, or the incentives involved, such that it's not dependent on any given person's ability to work hard or remember or be good at a certain thing.
Personal responsibility and systemic failure are different levels of abstraction.
If you're within the system and doing horrible things while saying, "🤷 It's just my incentives, bro," you're essentially allowing the egregore to control you, letting it shove its hand up your ass and pilot you like a puppet.
At the same time, if you ignore systemic problems, you're giving the egregore power by pretending it doesn't exist—even though it’s puppeting everyone. By doing so, you're failing to claim your own power, which lies in recognizing your ability to work towards systemic change.
Both truths coexist:
- There are those perpetuating evil by surrendering their personal responsibility to an evil egregore.
- There are those perpetuating evil by letting the egregore run rampant and denying its existence.
The solution requires addressing both levels of abstraction.
I think the model of "Burnout as shadow values" is quite important and loadbearing in my own model of working with many EAs/Rationalists. I don't think I first got it from this post but I'm glad to see it written up so clearly here.
Any easy quick way to test is to offer some free coaching in this method.
Can you say more about how you've used this personally or with clients? What approaches you tried that didn't work, and how this has changed if at all to be more effective over time?
There's a lot here that's interesting, but hard for me to tell from just your description how battletested this is
What would the title be?
I still don't quite get it. We already have an Ilya Sutskever who can make type 1 and type 2 improvements, and don't see the sort of jump's in days your talking about (I mean, maybe we do, and they just look discontinuous because of the release cycles?)
Why do you imagine this? I imagine we'd get something like one Einstein from such a regime, which would maybe increase the timelines over existing AI labs by 1.2x or something? Eventually this gain compounds but I imagine that could tbe relatively slow and smooth , with the occasional discontinuous jump when something truly groundbreaking is discovered
Right, and per the second part of my comment - insofar as consciousness is a real phenomenon, there's an empirical question of if whatever frame invariant definition of computation you're using is the correct one.
Do you think wants that arise from conscious thought processes are equally valid to wants that arise from feelings? How do you think about that?
while this paradigm of 'training a model that's an agi, and then running it at inference' is one way we get to transformative agi, i find myself thinking that probably WON'T be the first transformative AI, because my guess is that there are lots of tricks using lots of compute at inference to get not quite transformative ai to transformative ai.
my guess is that getting to that transformative level is gonna require ALL the tricks and compute, and will therefore eek out being transformative BY utilizing all those resources.
one of those tricks may be running millions of copies of the thing in an agentic swarm, but i would expect that to be merely a form of inference time scaling, and therefore wouldn't expect ONE of those things to be transformative AGI on it's own.
and i doubt that these tricks can funge against train time compute, as you seem to be assuming in your analysis. my guess is that you hit diminishing returns for various types of train compute, then diminishing returns for various types of inference compute, and that we'll get to a point where we need to push both of them to that point to get tranformative ai
This seems arbitrary to me. I'm bringing in bits of information on multiple layers when I write a computer program to calculate the thing and then read out the result from the screen
Consider, if the transistors on the computer chip were moved around, would it still process the data in the same way and wield the correct answer?
Yes under some interpretation, but no from my perspective, because the right answer is about the relationship between what I consider computation and how I interpret the results in getting
But the real question for me is - under a computational perspective of consciousness, are there features of this computation that actually correlate to strength of consciousness? Does any interpretation of computation get equal weight? We could nail down a precise definition of what we mean by consciousness that we agreed on that didn't have the issues mentioned above, but who knows whether that would be the definition that actually maps to the territory of consciousness?