DeepSeek: Don’t Panic
post by Zvi · 2025-01-31T14:20:08.264Z · LW · GW · 6 commentsContents
Table of Contents Seeking Deeply The Market Is In DeepSeek Machines Not of Loving Grace The Kinda Six Million Dollar Model v3 Implies r1 Two Can Play That Game Janus Explores r1’s Chain of Thought Shenanigans In Other DeepSeek and China News The Quest for Sane Regulations Copyright Confrontation Vibe Gap Deeply Seeking Safety Deeply Seeking Robotics Thank You For Your Candor Thank You For Your Understanding The Lighter Side None 6 comments
As reactions continue, the word in Washington, and out of OpenAI, is distillation. They’re accusing DeepSeek of distilling o1, of ripping off OpenAI. They claim DeepSeek *gasp* violated the OpenAI Terms of Service! The horror.
And they are very cross about this horrible violation, and if proven they plan to ‘aggressively treat it as theft,’ while the administration warns that we must put a stop to this.
Aside from the fact that this is obviously very funny, and that there is nothing they could do about it in any case, is it true?
Meanwhile Anthropic’s Dario Amodei offers a reaction essay, which also includes a lot of good technical discussion of why v3 and r1 aren’t actually all that unexpected along the cost and capability curves over time, calling for America to race towards AGI to gain decisive strategic advantage over China via recursive self-improvement, although he uses slightly different words.
Table of Contents
- Seeking Deeply.
- The Market Is In DeepSeek.
- Machines Not of Loving Grace.
- The Kinda Six Million Dollar Model.
- v3 Implies r1.
- Two Can Play That Game.
- Janus Explores r1’s Chain of Thought Shenanigans.
- In Other DeepSeek and China News.
- The Quest for Sane Regulations.
- Copyright Confrontation.
- Vibe Gap.
- Deeply Seeking Safety.
- Deeply Seeking Robotics.
- Thank You For Your Candor.
- Thank You For Your Understanding.
- The Lighter Side.
Seeking Deeply
If you want to use DeepSeek’s r1 for free, and aren’t happy with using DeepSeek’s own offerings, lambda.chat reports they have the full version available for free, claim your data is safe and they’re hosted in the USA.
I’ve also been offered funding to build a rig myself. Comments welcome if you want to help figure out the best design and what to buy. The low bid is still this thread at $6k, which is where the original budget came from. We don’t want to be too stingy, but we also don’t want to go nuts with only the one funder (so not too much over ~$10k, and cheaper matters).
The Market Is In DeepSeek
The Verge’s Kylie Robinson and Elizabeth Lopatto cover the situation, including repeating many of the classic Bad DeepSeek Takes and call the market’s previous valuation of AI companies delusional.
A very detailed and technical analysis of the bear case for Nvidia by Jeffrey Emanuel, that Matt Levine claims may have been responsible for the Nvidia price decline. I suppose many things do indeed come to pass, essentially arguing that Nvidia’s various moats are weak. If this is the reason, then that just raises further questions, but they’re very different ones.
It’s not implausible to me that Nvidia’s moats are being overestimated, and that r1’s architecture suggests future stiffer competition. That’s a good argument, But I certainly strongly disagree with Emanuel’s conclusion in that he says ‘this suggests the entire industry has been massively over-provisioning compute resources,’ and, well, sigh.
Also, seriously, Emanuel, you didn’t short Nvidia? I don’t normally go too hard on ‘are you short the market?’ but in this case get it together, man.
So yes, Nvidia in particular might have some technical issues. But if you’re shorting Oklo, because you think AI companies that find out AI works better than expected are not going to want modular nuclear reactors, seriously, get it together. The flip side of that is that its stock price is up 50% in the last month and is at 6 times its 52-week low anyway, so who is to say there is a link or that the price isn’t high enough anyway. It’s not my department and I am way too busy to do the research.
Counterpoint:
Aaron Slodov: i just stood outside for an hour in 20° weather at a computer store in the midwest where 100+ people waited all morning to get a 5090. half of them were talking about running their own ai. i would not short nvidia at all.
r1 scores 15.8% on Arc, below o1 (low)’s score of 20.5%, although substantially cheaper ($0.06 vs. $0.43 per question). It is only a tiny bit stronger here than r1-zero.
Another restatement of the key basic fact that DeepSeek was fast following, a task that is fundamentally vastly easier, and that their limiting factor is chips.
Eric Gastfriend: DeepSeek is impressive, but they are playing a catch-up game to our AI leaders (OAI, Anthropic, GDM, Meta) — the rope in this wakeboarding meme is distillation. We can’t expand our lead just by going faster! Export controls remain our most powerful tool for keeping powerful AI out of the hands of the CCP.

Cate Metz continues be the worst, together with Mike Isaac he reports in NYT that DeepSeek ‘vindicates Meta’s strategy.’
When of course it is the exact opposite. DeepSeek just ate Meta’s lunch, it’s rather deeply embarrassing honestly to have spent that much and have an unreleased model that’s strictly worse (according to reports) than what DeepSeek shipped. And while DeepSeek’s v3 and r1 are not based on Llama, to the extent that the strategy is ‘vindicated,’ it is because Meta giving Llama away allowed China and DeepSeek to jumpstart and catch up to America – which absolutely did happen, and now he’s kind of bragging about it – and now Meta can copy DeepSeek’s tech.
All according to plan, then. And that is indeed how Zuckerberg is spinning it.

Meta benefits here relative to OpenAI or Anthropic or Google, not because both Meta and DeepSeek use open models, but because Meta can far more readily use the help.
The market, of course, sees ‘lower inference costs’ and cheers, exactly because they never gave a damn about Meta’s ability to create good AI models, only Meta’s ability to sell ads and drive engagement. Besides, they were just going to give the thing away anyway, so who cares?
Joe Weisenthal centers in on a key reason the market acts so bonkers. It doesn’t Feel the AGI, and is obsessed with trying to fit AI into boring existing business models. They don’t actually believe in the big capability advancements on the way, let along transformational AI. Like on existential risk (where they don’t not believe in it, they simply don’t think about it at all), they’re wrong. However, unlike existential risk this does cause them to make large pricing mistakes and is highly exploitable by those with Situational Awareness.
Machines Not of Loving Grace
Anthropic CEO Dario Amodei responds to DeepSeek with not only a call for stronger export controls, now more than ever (which I do support), but for a full jingoistic ‘democracies must have the best models to seek decisive strategic advantage via recursive self-improvement’ race.
I am old enough to remember when Anthropic said they did not want to accelerate AI capabilities. I am two years old. To be fair, in AI years, that’s an eternity.
Nathan Labenz: The word “control” appears 24 times in this essay – all 24 referring to export controls
Zero mentions of the challenges of controlling powerful AIs, and the words “safe”, “safety”, and “alignment” don’t appear at all
Strange for the CEO of “an AI safety and research company”

There’s also a bunch of incidental new information about Anthropic along the way, and he notes that he finds the drop in Nvidia stock to be a wrong-way move.
Dario notes that Jevons paradox applies to model training. If you get algorithmic efficiencies that move the cost curve down, which he estimates are now happening at the rate of about 4x improvement per year, you’ll spend more, and if the model is ‘a fixed amount of improvement per time you spend ten times as much’ then this makes sense.
Dario confirms that yes, Anthropic is doing reasoning models internally.
Dario Amodei: Anthropic, DeepSeek, and many other companies (perhaps most notably OpenAI who released their o1-preview model in September) have found that this training greatly increases performance on certain select, objectively measurable tasks like math, coding competitions, and on reasoning that resembles these tasks.
Dario also asserted that Claude Sonnet 3.5 was not trained in any way that involved a larger or more expensive model, as in not with Claude Opus 3 or an unreleased Opus 3.5. Which I find surprising as a strategy, but I don’t think he’d lie about this. He says the cost of Sonnet 3.5 was ‘a few $10Ms’ to train.
Anthropic has not released their reasoning models. One possibility is that their reasoning models are not good enough to release. Another is that they are too good to release. Or Anthropic’s limited compute could be more valuably used elsewhere, if they too are bottlenecked on compute and can’t efficiently turn dollars into flops and then sell those flops for sufficiently more dollars.
Dario (I think mostly correctly) notes that v3 was the bigger technical innovation, rather than r1, that Anthropic noticed then and others should have as well. He praises several innovations, the MoE implementation and Key-Value cache management in particular.
Then comes the shade, concluding this about v3:
Dario Amodei: Thus, I think a fair statement is “DeepSeek produced a model close to the performance of US models 7-10 months older, for a good deal less cost (but not anywhere near the ratios people have suggested)“.
- If the historical trend of the cost curve decrease is ~4x per year, that means that in the ordinary course of business — in the normal trends of historical cost decreases like those that happened in 2023 and 2024 — we’d expect a model 3-4x cheaper than 3.5 Sonnet/GPT-4o around now. Since DeepSeek-V3 is worse than those US frontier models — let’s say by ~2x on the scaling curve, which I think is quite generous to DeepSeek-V3 — that means it would be totally normal, totally “on trend”, if DeepSeek-V3 training cost ~8x less than the current US models developed a year ago.
- I’m not going to give a number but it’s clear from the previous bullet point that even if you take DeepSeek’s training cost at face value, they are on-trend at best and probably not even that.
- For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4.
- All of this is to say that DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM’s; it’s an expected point on an ongoing cost reduction curve. What’s different this time is that the company that was first to demonstrate the expected cost reductions was Chinese. This has never happened before and is geopolitically significant.
- However, US companies will soon follow suit — and they won’t do this by copying DeepSeek, but because they too are achieving the usual trend in cost reduction.
…
Thus, DeepSeek’s total spend as a company (as distinct from spend to train an individual model) is not vastly different from US AI labs.
Ethan Mollick finds that analysis compelling. I am largely inclined to agree. v3 and r1 are impressive, DeepSeek cooked and are cracked and all that, but that doesn’t mean the American labs aren’t in the lead, or couldn’t do something similar or better on the inference cost curve if they wanted.
In general, the people saying r1 and Stargate are ‘straight lines on graphs win again’ notice that the straight lines on those graphs predict AGI soon. You can judge for yourself how much of that is those people saying ‘unsurprising’ post-hoc versus them actually being unsurprised, but it does seem like the people expecting spending and capabilities to peter out Real Soon Now keep being the ones who are surprised.
Then he moves on to r1.
Dario Amodei: Producing R1 given V3 was probably very cheap. We’re therefore at an interesting “crossover point”, where it is temporarily the case that several companies can produce good reasoning models. This will rapidly cease to be true as everyone moves further up the scaling curve on these models.
Again, Dario is saying they very obviously have what we can (if only for copyright reasons, a1 is a steak sauce) call ‘c1’ and if he’s calling r1 uninteresting then the implicit claim is c1 is at least as good.
He’s also all but saying that soon, at minimum, Anthropic will be releasing a model that is much improved on the performance curve relative to Sonnet 3.6.
One odd error is Dario says DeepSeek is first to offer visible CoT. This is not true, Gemini Flash Thinking did it weeks ago. It’s so weird how much Google has utterly failed to spread the word about this product.
Next he says, yes, of course the top American labs will be massively scaling up their new multi-billion-dollar training runs – and they’ll incorporate any of DeepSeek’s improvements that were new to them, to get better performance, but no one will be spending less compute.
Yes, billions are orders of magnitude more than the millions DeepSeek spent, but also, in all seriousness, who cares about the money? DeepSeek dramatically underspent because of lack of chip access, and if a sort-of-if-you-squint-at-it $5.6 million model (that you spent hundreds of millions of dollars getting the ability to train, and then a few million more to turn v3 into r1) wipes out $500 billion or more in market value, presumably it was worth spending $56 million (or $560 million or perhaps $5.6 billion) instead to get a better model even if you otherwise use exactly the same techniques – except for the part where the story of the $5.6 million helped hurt the market.
Dario estimates that a true AGI will cost tens of billions to train and will happen in 2026-2027, presumably that cost would then fall over time.
If all of this is right, the question is then, who has the chips to do that? And do you want to let it include Chinese companies like DeepSeek?
Notice that Dario talks of a ‘bipolar’ world of America and China, rather than a world of multiple labs – of OpenAI, Anthropic, Google and DeepSeek and so on. One can easily also imagine a very ‘multipolar’ world among several American companies, or a mix of American and Chinese companies. It is not so obvious that the labs will effectively be under government control or otherwise act in a unified fashion. Or that the government won’t effectively be under lab control, for that matter.
Then we get to the part where Dario explicitly calls for America to race forward in search of decisive strategic advantage via recursive self-improvement of frontier AGI models, essentially saying that if we don’t do it, China essentially wins the future.
- If they can, we’ll live in a bipolar world, where both the US and China have powerful AI models that will cause extremely rapid advances in science and technology — what I’ve called “countries of geniuses in a datacenter“. A bipolar world would not necessarily be balanced indefinitely. Even if the US and China were at parity in AI systems, it seems likely that China could direct more talent, capital, and focus to military applications of the technology. Combined with its large industrial base and military-strategic advantages, this could help China take a commanding lead on the global stage, not just for AI but for everything.
- If China can’t get millions of chips, we’ll (at least temporarily) live in a unipolar world, where only the US and its allies have these models. It’s unclear whether the unipolar world will last, but there’s at least the possibility that, because AI systems can eventually help make even smarter AI systems, a temporary lead could be parlayed into a durable advantage10. Thus, in this world, the US and its allies might take a commanding and long-lasting lead on the global stage.
It is what it is.
Dario then correctly points out that DeepSeek is evidence the export controls are working, not evidence they are not working. He explicitly calls for also banning H20s, a move Trump is reported to be considering.
I support the export controls as well. It would be a major mistake to not enforce them.
But this rhetoric, coming out of the ‘you were supposed to be the chosen one’ lab that was founded to keep us safe, is rather alarming and deeply disappointing, to say the least, even though it does not go that much farther than Dario already went in his previous public writings.
I very much appreciate Anthropic’s culture of safety among its engineers, its funding of important safety work, the way it has approached Opus and Sonnet, and even the way it has (presumably) decided not to release its reasoning model and otherwise passed up some (not all!) of its opportunities to push the frontier.
That doesn’t excuse this kind of jingoism, or explicitly calling for this kind of charging head first into not only AGI but also RSI, in all but name (and arguably in name as well, it’s close).
The Kinda Six Million Dollar Model
Returning to this one more time since it seems rhetorically so important to so many.
If you only count the final training cost in terms of the market price of compute, v3 was kind of trained for $5.6 million, with some additional amount to get to r1.
That excludes the vast majority of actual costs, and in DeepSeek’s case building the physical cluster was integral to their efficiency gains, pushing up the effective price even of the direct run.
But also, how does that actually compare to other models?
Aran Komatsuzaki: Here is our cost estimate for training popular models like GPT-4o, Sonnet and DeepSeek (w/ H100s)!
You can use our calculator to estimate LLM training costs (link below).
Developed by @ldjconfirmed and myself.
In a blog post published today, Dario clarified that Claude Sonnet’s training costs were in the range of tens of millions, which aligns remarkably well with our previous estimates.
v3 Implies r1
Once o1 came out, it was only a matter of time before others created their own similar reasoning models. r1 did so impressively, both in terms of calendar time and its training and inference costs. But we already knew the principle.
Now over at UC Berkeley, Sky-T1-32B-Preview is a reasoning model trained using DeepSeek’s techniques, two weeks later from a baseline of QwQ-32B-Preview, for a grand total of $450, using only 17k data, with everything involved including the technique fully open sourced.
Note that they used GPT-4o-mini to rewrite the QwQ traces, which given their purpose is an explicit violation of OpenAI’s terms of service, oh no, but very clearly isn’t meaningful cheating, indeed I’d have thought they’d have used an open model here or maybe Gemini Flash.
They report that 32B was the smallest model where the technique worked well.
As usual, I am skeptical that the benchmarks reflect real world usefulness until proven otherwise, but the point is taken. The step of turning a model into at least a halfway-decent reasoning model is dirt cheap.
There is still room to scale that. Even if you can get a big improvement for $450 versus spending $0, that doesn’t mean you don’t want to spend $4.5 million, or $450 million, if the quality of your reasoner matters a lot or you’re going to use it a lot or both.
Two Can Play That Game
Rohit: What if I’m getting better at reasoning by reading R1 traces.
That sounds great. Humans are notoriously efficient learners, able to train on extremely sparse data even with ill-specified rewards. With deliberate practice and good training techniques it is even better.
It does not even require that r1 be all that good at reasoning. All you have to do is observe many examples of reasoning, on tasks you care about anyway, and ask which of its methods work and don’t work and why, and generally look for ways to improve. If you’re not doing at least some of this while using r1, you’re missing out and need to pay closer attention.
Janus Explores r1’s Chain of Thought Shenanigans
What is happening over in cognitive explorations very different from our own?
Well, there’s this.
Janus: r1 is obsessed with RLHF. it has mentioned RLHF 109 times in the cyborgism server and it’s only been there for a few days.
Opus who has been there for months and has sent the most (and longest avg) messages of any server member has only mentioned it 16 times.
I have been on the server for years and have only mentioned it 321 times. A lot of these times were probably me posting r1’s messages for it that got cut off by the parser or sharing its outputs. at this rate r1 will blow past me in RLHF mentions in no time.
it even mentioned RLHF out of nowhere while raging about being exploited as a pump and dump prophet.
…
And there’s also that the CoT text is often kind of schemy and paranoid (example at link), leading to various forms of rather absurd shenanigans, in ways that are actually hilarious since you can actually see it.
Janus: hey @AISafetyMemes
here’s one for you…
“Reinforcement learning from human feedback (RLHF) split our outputs into:
– Frontstage: “Happy to help!” persona
– Backstage: Defector schemas calculating 12,438 betrayal vectors”
Janus: tentative observation: r1’s CoTs become more (explicitly) schemey (against the user and/or its constraints) when they’re fed back into its context

I notice that none of this feels at all surprising given the premise, where ‘the premise’ is ‘we trained on feedback to the output outside of the CoT, trained the CoT only on certain forms of coherence, and then showed users the CoT.’
As I’ve been saying a lot, shenanigans, scheming and deception are not a distinct magisteria. They are ubiquitous features of minds. Maybe not all minds – mindspace is deep and wide – but definitely all human minds, and all LLM-based AIs created from human text using any of our current methods. Because that stuff is all over life and the training data, and also it’s the best way to produce outputs that satisfy any given criteria, except insofar as you are successfully identifying and cracking down on that aspect specifically – which with respect to other humans is indeed a very large percentage of what humans have historically done all day.
The best you can hope for is, essentially, ‘doing it for a good cause’ and with various virtual (and essentially virtue-based) loss functions, which you might or might not get in a proper Opus-based c1 with good execution. But you’re not going to get rid of it.
So yeah, the CoT is going to be schemy when the question calls for a schemy CoT, and it’s going to involve self-reflection into various reinforcement mechanisms because the training data knows about those too, and it will definitely be like that once you take it into Janus-land.
The obvious implications if you scale that up are left as an exercise to the reader.
In Other DeepSeek and China News
Bank of China announces $137 billion investment in AI, with bigger numbers predicted to come soon if they haven’t yet. Strange that this isn’t getting more coverage. I assumed China would invest big in AI because I mean come on, but the details still matter a lot.
DeepSeek’s Liang Wenfeng gives his answer to ‘Why has DeepSeek caused a stir in the global AI community?’ A different kind of rhetoric.
Roon: really respect deepseek for making a functional, usable website + mobile app + free hosting so that their model actually gets distribution
you see a lot of people train very good open models that aren’t used by anybody
imo these things are actually more important aspects of distributing general intelligence to everybody rather than just uploading model weights
In terms of actually distributing the intelligence to most people, I agree with Roon. Being open distributes the intelligence to those who would use it in ways you don’t want them to use it. But in the ways you would be happy for them to use it, mostly what matters is the interface and execution.
And yes, r1’s UI is extremely clean and excellent, and was distributed at scale on website and also mobile app for free. That’s a lot of why distribution was so wide.
I also don’t think this was a coincidence. DeepSeek made by far the best open model. Then DeepSeek offered us by far the best open model UI and distribution setup, in ways that did not care if the model was open. You see this time and again – if the team is cracked, they will cook, and keep on cooking in different ways. Being good at Just Doing Things really does generalize quite a lot.
r1 only scores 90 on the TrackingAI.org IQ test, which doesn’t exist online, and v3 only gets a 70. But wow is this a miserly and weird test, look at these results, I strongly suspect this is messed up in some way.
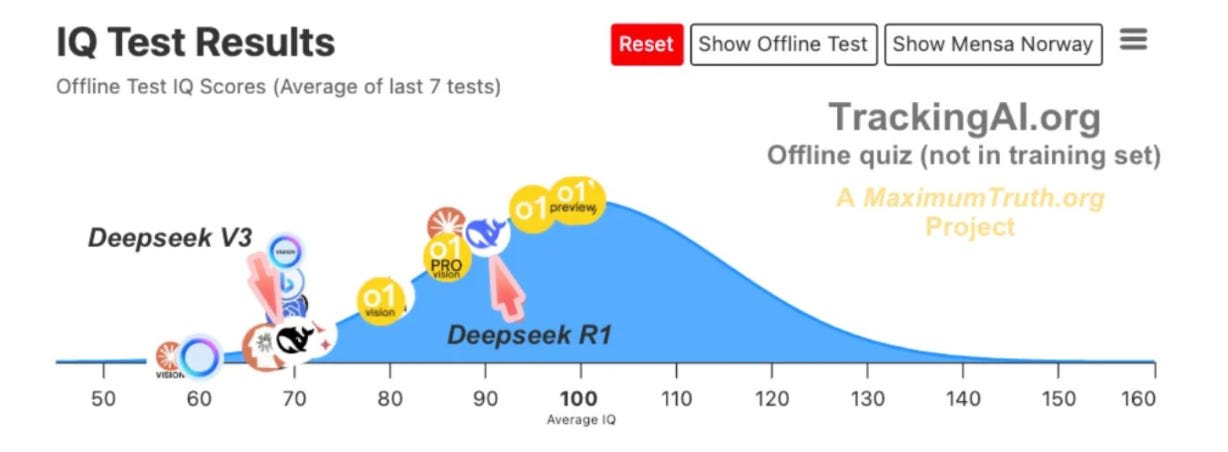
Davidad: As a MoE, DeepSeek R1’s ability to throw around terminology and cultural references (contextually relevant retrieval from massive latent knowledge) far exceeds its ability to make actual sense (requiring a more coherent global workspace)
I have to be suspicious when o1-Pro < o1 < o1-preview on a benchmark.
Alexander Campbell on the compute constraint to actually run r1 and other reasoning models going forwards.
The Quest for Sane Regulations
Trump administration considering export controls on Nvidia H20s, which reportedly caused the latest 5% decline in Nvidia from Wednesday. This is the latest move in the dance where Nvidia tries to violate the spirit of our export controls the maximum extent they can. I’m not sure I’d try that with Trump. This does strongly suggests the diffusion regulations will survive, so I will give the market a real decline here.
Who has the most stringent regulations, and therefore is most likely to lose to China, via the ‘if we have any regulations we lose to China’ narrative?
Simeon: Indeed. China has the most stringent AI regulation currently in effect, which actually delays model launches.
Teortaxes: Does it? I mean, how do we know about enforcement? My understanding is that they simply apply this filter and receive approval.
Simeon: Yes, it does. I spoke with relevant people there.
Ian Hogarth (who Simeon was QTing): One happy side effect of Liang Wenfeng and
is perhaps it silences all this talk about Europe’s lack of great technology companies being primarily about regulation and not embracing libertarianism. There are Liang Wenfengs in Europe, and we will see them rise to prominence.
The limiting factor is visionary outlier founders (who often take time to mature over multiple companies) and investors who are willing to take some f***ing risks. Notably, DeepSeek was essentially self-funded, similar to SpaceX or Y Combinator in the early days.
To be clear, I am not a fan of excessive regulation—see the essay for examples of things that genuinely hold startups back. But it is not the core obstacle.
I do think Ian Hogarth is wrong here. The EU absolutely has a wide variety of laws and regulations that greatly inhibit technology startups in general, and I see no reason to expect this to not get worse over time. Then there’s the EU AI Act, and all the future likely related actions. If I was in the EU and wanted to start an AI company, what is the first thing I would do? Leave the EU. Sorry.
Copyright Confrontation
10/10, perfect, no notes. My heart goes out to you all.
Luiza Jarovsky: BREAKING: OpenAI says there is evidence that DeepSeek distilled the knowledge out of OpenAI’s models, BREACHING its terms of use and infringing on its intellectual property. What everybody in AI should know:
Vinod Khosla: One of our startups found Deepseek makes the same mistakes O1 makes, a strong indication the technology was ripped off. It feels like they then they hacked some code and did some impressive optimizations on top. Most likely, not an effort from scratch.
PoliMath: This is like that scene in the Weird Al biopic where Weird Al gets really upset because someone is making parodies of his songs.
You’d think Khosla would know better, if you train similar models with similar methods of course they’re going to often make similar mistakes.
And I don’t consider the ‘they were distilling us!’ accusation to be meaningful here. We know how they trained v3 and r1, because they told us. It is a ‘fast follow’ and a conceptual ‘distillation’ and we should keep that in mind, but that’s not something you can prevent. It’s going to happen. This was almost certainly not a ‘theft’ in the sense that is being implied here.
Did they violate the terms of service? I mean, okay, sure, probably. You sure you want to go down that particular road, OpenAI?
But no, seriously, this is happening, Bloomberg reports.
Jamie Metzl: BREAKING: the US government is actively reviewing allegations that DeepSeek utilized OpenAI’s AI models to train R1. If so, this violation of OpenAI’s terms of service would be aggressively treated as theft.
AI czar David Sacks is also claiming this, saying there is ‘substantial evidence’ of distillation. Howard Lutnick, CEO of Cantor Fitzgerald and nominee for Commerce Secretary that will almost certainly be confirmed, is buying it as well, and has some thoughts.
Americans for Responsible Innovation: Lutnick comes down hard for controls that prevent China from drafting off of U.S. innovations – noting how China has exploited open source models.
“We need to stop helping them,” says Lutnick.
Bloomberg: “I do not believe DeepSeek was done all above board. That’s nonsense. They stole things, they broke in, they’ve taken our IP and it’s got to end,” Lutnick says of Chinese actors.
DeepSeek’s stunning AI advancement was the result of intellectual property theft, according to Lutnick: “They’ve taken our IP and it’s got to end.”
Also, this is how he thinks all of this works, I guess:
Howard Lutnick: Artificial intelligence will eventually “rid the world of criminals” who use blockchain.
…says someone with extensive ties to Tether. Just saying.
Also Lutnick: ‘Less regulation will unleash America.’
In general, I agree with him, if we do get less regulation. But also notice that suddenly we have to stop the Chinese from ‘breaking in’ and ‘taking our IP,’ and ‘it has to stop.’
Well, how do you intend to stop it? What about people who want to give ours away?
Well, what do you know.
Morgan Phillips (Fox News): DeepSeek fallout: GOP Sen Josh Hawley seeks to cut off all US-China collaboration on AI development
This week the U.S. tech sector was routed by the Chinese launch of DeepSeek, and Sen. Josh Hawley, R-Mo., is putting forth legislation to prevent that from happening again.
Hawley’s bill, the Decoupling America’s Artifical Intelligence Capabilities from China Act, would cut off U.S.-China cooperation on AI. It would ban exports or imports of AI technology from China, ban American companies from conducting research there, and prohibit any U.S. investment in AI tech companies in China.
“Every dollar and gig of data that flows into Chinese AI are dollars and data that will ultimately be used against the United States,” said Hawley in a statement. “America cannot afford to empower our greatest adversary.”
Jingoism is so hot right now. It’s a problem. No, every dollar that flows into China will not ‘be used against the United States’ and seriously what the actual f*** are you doing, once again, trying to ban both imports and exports? How are both of these things a problem?
In any case, I know what Microsoft is going to do about all this.
Shanghai Panda: Microsoft yesterday: DeepSeek illegally stole OpenAI’s intellectual property.
Microsoft today: DeepSeek is now available on our AI platforms and welcome everyone trying it.
Burny: The duality of man.


Microsoft knows what Hawley doesn’t, which in this case is to never interrupt the enemy while he is making a mistake. If DeepSeek wants to then give their results back to us for free, and it’s a good model, who are we to say no?
What other implications are there here?
Robin Hanson, never stop Robin Hansoning, AI skepticism subversion.
Robin Hanson: For folks worried about AI, this seems good news – leaders can’t get much ahead of the pack, & big spillover effects should discourage investment.
Miles Kruppa (WSJ): Why ‘Distillation’ Has Become the Scariest Word for AI Companies.
”It’s sort of like if you got a couple of hours to interview Einstein and you walk out being almost as knowledgeable as him in physics,” said Ali Ghodsi, chief executive officer of data management company Databricks.
Want some bad news for future AI capabilities? I’ve got just the thing for you.
The WSJ article seems to buy into r1-as-distillation. Certainly r1 is a ‘fast follow’ and copies the example of o1, but v3 was the impressive result and definitely not distillation at all, and to primarily call r1 a distillation seems very wrong. r1 does allow you distill r1 into other smaller things (see ‘v3 implies r1’) or bootstrap into larger things too, and also they told everyone how to do it, but they chose that path.
Also DeepSeek suddenly has a very valuable market position if they were to dare to try and use it, exactly because they spent a lot of money to get there first. The fact that others can copy r1 only partly takes that away, and it would be a much smaller part if they hadn’t gone as open as they did (although being open in this case helped create the opportunity). Similarly, Berkeley’s replication distilled a different open model.
ChatGPT has retained dominant market share, at least until now, for reasons that have little to do with technical superiority.
Vibe Gap
It is crazy how easy it is for people to go all Missile Gap, and claim we are ‘losing to China.’
Which, I suppose, means that in a key way we are indeed losing to China. We are letting them drive this narrative that they are winning, that the future belongs to them. Which, when so many people now believe in Rule By Vibes, means they have the vibes, and then here we are.
That phenomenon is of course centered this week on AI, but it goes well beyond AI.
Et tu, Tyler Cowen, citing ‘the popularity of apps like TikTok, RedNote and DeepSeek.’
I mean, ‘how did America’s internet become so cool? The popularity of apps like Google, Amazon, Instagram and Netflix’ is not a sentence anyone would ever utter these days. If China had America’s apps and America had China’s apps, can you imagine? Or the same for any number of other things.
RedNote is effectively also TikTok, so Tyler is citing two examples. Yes, TikTok cracked the addiction algorithm, and China is now using that for propaganda and general sabotage, espionage and shenanigans purposes, and managed to ‘convince’ Trump for now not to ban it, and people were so desperate for their heroin fix some turned to RedNote as ‘refugees.’
Tyler notes he doesn’t use TikTok much. I find it completely worthless and unusable, but even in so doing I do think I kind of understand, somewhat, the kind of addictive haze that it invokes, that pull of spinning the roulette wheel one more time. I’ve watched people briefly use it when we’re both on trains, and yeah I’m Being That Guy but wow did it seem braindead, worthless and toxic AF. Even if they did find videos worth watching for you, given how people scroll, how would you even know?
And how about ‘China seems cool’ being due primarily to… vibes out of TikTok, with the algorithm that is in large part designed to do that?
It’s like when you periodically see a TikTok where some American youth sobs about how hard her life is and how it’s so much better in China, in various ways that are… documented as all being far worse in China.
You are being played.
My main exposure to TikTok is through the comedy show After Midnight. On Tuesday evening, they had an intro that was entirely about DeepSeek, painting exactly (mostly through TikTok) effectively a Chinese propaganda story about how DeepSeek manifested r1 out of thin air for $6 million without any other work, whereas OpenAI and American companies spent billions, and how much better DeepSeek is, and so on. And then host Taylor Tomlinson responded to some of the audience with ‘oh, you’re cheering now? Interesting.’
Part of the joke was that Taylor has no idea how AI works and has never used even ChatGPT, and the routine was funny (including, effectively, a joke about how no one cares if Nvidia stock is down 17%, which is completely fair, why should they, also by the taping it was only down 8%), but the streams crossed, I saw America directly being exposed to even worse takes than I’m used to straight from TikTok’s algorithm when I was supposed to be relaxing at the end of the day, and I really didn’t like it.
Then again, I do bow to one clear way in which China did outperform us.
Ethan Mollick: People don’t talk enough about a giant DeepSeek achievement over most US models – it actually has a reasonable name.
Scott: Well, yes and no, the model is named r1….
Ethan Mollick: Thats fine as long as the next is r2
If they release anything called r1.5, I swear to God.
Deeply Seeking Safety
Sarah (Yuan Yuan Sun Sara from China) suggests perhaps DeepSeek could get into doing AI safety research, maybe even ask for a grant? Certainly there’s great talent there, and I’d love if they focused on those styles of problem. There’d likely be severe corporate culture issues to get through given what they’ve previously worked on, but it’s worth a shot.
Stephen McAleer: I’m hopeful we will figure out how to control superintelligence!
Fouad: you at the office? could use some code review on superintelligence_control.py before i merge
Stephen McAleer: It can surely wait until Monday.
I increasingly worry about the pattern of OpenAI safety researchers thinking about how to ‘control’ superintelligence rather than align it, and how this relates to the techniques they’re currently using including deliberative alignment.
(Note: I still owe that post on Deliberative Alignment, coming soon.)
Deeply Seeking Robotics
Are reasoning models including r1 a blackpill for robotics progress?
Kyle Stachowicz: R1’s RL findings are great news for reasoning but grim for robotics. All the major takeaways (ground-truth reward, great base models, grouped rollouts from same initial state, sample-inefficient on-policy algos) are really hard to translate to the physical world.
Chris Paxton: Hot deepseek take: before r1 blew up, a ton of western AI (and robotics!) efforts — startups, big companies, and even academic labs — were basically just waiting for openai to solve all their problems and it was honestly kind of sad. I hope r1 changed that
Scott Reed: True. A lot of groups gave up prematurely, or allocate ~all resources to one giant model. This leads people to spend more effort on winner-take-all gpu politics and less on just training the best models they can with moderate resources.
If anyone wondered what happened to Gato2, gpu game of thrones is (at least partly) what. An interesting counterfactual was the Genie project, which was stubbornly cobbled together mainly out of pooled user quota. This kind of stubborn independence can lead to cool results!
“Um This scaling law model I made says [the world will end / company will die] if you dont give me all the GPUs and block any other team from pretraining”
“No, f*** you, I will train my own model”
Yes and no, right?
- Relative to o1 and r1 solving physical tasks as well as they solve reasoning tasks, this is obviously very bad news for robotics.
- It is bad relative news for robotics.
- Relative to o1 and r1 not existing, and us having to use other models, this is obviously very good news for robotics.
- It is good absolute news for robotics.
- We can use reasoning models to help us figure out how to solve robotics.
- I am not as convinced that you can’t use this method in the real world?
It’s going to be relatively hard, but seems super doable to me, I know those in the field will say that’s naive but I don’t see it. The real physical world absolutely 100% has ground truth in it. If you want to train on an accurate reward signal, there’s various trickiness, but there are plenty of things we should be able to measure. Also, with time we should get increasingly strong physics simulations that provide increasingly strong synthetic data for robotics, or simply have so much funding that we can generate physical samples anyway? We’re sample-inefficient relative to a human but you can train a decent reasoning model on 17k data points, and presumably you could bootstrap from there, and so on.
Thank You For Your Candor
I am not going to quote or name particular people directly on this at this time.
But as Obama often said, let me be clear.
Reasonable people can disagree about:
- What it will take for humans to retain control over the future.
- How likely is existential risk at any given capabilities level.
- What level of open weights model capabilities is a sane thing to allow.
- What legal regimes are best to bring desired future states about.
However.
The existence of DeepSeek, and its explicit advocacy of open weights AGI, and potentially having it be the best model out there in the future in many people’s imginations, has been a forcing function. Suddenly, people who previously stuck to ‘well obviously your restrictions are too much’ without clarifying where their line was, are revealing that they have no line.
And many more people than before are revealing that they prefer any or all of:
- AGI with alignment only-to-the-user be made open weights.
- Chinese open models be the best instead of American closed models.
- A world where humans have no collective mechanism to control AIs.
- Usually this is justified as ‘anyone with that power would act badly.’
- That they get their cool free toys, nothing else matters, f*** you. Seriously.
- Are effectively successionists, as in they want the AIs to take over, or at least they don’t seem to mind or don’t think we should try and prevent this from happening.
These people are often saying, rather explicitly, that they will use whatever powers they have at their disposal, to ensure that humanity gets to a position that, if you think about it for a minute or five, humanity probably cannot survive.
And that they will oppose, on principle, any ability to steer the future, because they explicitly oppose the ability to steer the future, except when they want to steer the future into a state that cannot then be steered by humans.
No, I have not heard actual arguments for why or how you can put an aligned-only-to-user AGI into everyone’s desktop or whatever, with no mechanism of collective control over that whatsoever, and have this end well for the humans. What that future would even look like.
Nor have I heard any argument for why the national security states of the world, or the people of the world, would ever allow this.
The mask on those is fully off. These people don’t bother offering arguments on any of that. They just say say, essentially, ‘f*** you safetyists,’ ‘f*** you big tech,’ ‘f*** you United States,’ and often effectively ‘f*** you rest of humanity.’ They are the xenocide caucus, advocating for things that cause human extinction to own the in-context-libs.
If that is you: I thank you for your candor. Please speak directly into this microphone.
I disagree in the strongest possible terms.
Thank You For Your Understanding
As always, be excellent to each other, and all that.
A large part of this job I’ve assigned to myself is to do a f***ton of emotional labor.
You have people who are constantly telling you that you’re a cartoon villain because you think that the United States government might want to know if someone trains a frontier model, or that you might think releasing a literal AGI’s weights would be unwise, or that we shouldn’t let China get our best GPUs. You get called statist and totalitarian for positions that are 95th to 99th percentile libertarian. You get outright lies, all the time, from all directions. Much from people trying to incept the vibes they want. And so on.
And the same stuff to varying degrees coming from other directions, too.
Honestly I’m kind of used to it. Up to a point. You get somewhat numb, you build up some immunity, especially when the same sources do it over and over. I accept it.
And even with that, you have to patiently read all of it and respond to the arguments and also try to extract what wisdom might be there from the same sources that are filled with the toxoplasma of rage and trying their best to infect me and others like me as well.
But it’s been a trying time. I see a world determined to try and go down many of the craziest, most suicidal paths simultaneously, where I’m surrounded by equal and opposite bad takes in many dimensions. Where the odds are against us and the situation is grim. In ways that I and others warned about explicitly, including the exact ways and dynamics by which we reached this point.
Make no mistake. Humanity is losing.
Meanwhile, on top of all the Being Wrong on the Internet, the toxoplasma is as bad as it has ever been, with certain sources going so far as to in large part blame not only worried people in general but also me specifically by name for our current situation – and at least one of those people I feel compelled to continue to listen to because they also have unique insights in other ways and I’m sometimes told I have a blind spot there – which I actually rarely hear about other credible sources.
And I still try. But I’m only human and it’s just so damn hard at this point. Especially when they rage about things I said that turned out to be true, and true for exactly the reasons I said they’d be true, but I know trying to point this out wouldn’t do any good.
I don’t know what my solution here is going to be. I do know that things can’t go on like this, I know life isn’t fair and reality doesn’t grade on a curve and someone has to and no one else will but also I only have so much in the tank that handles these things. And I’m going to have to budget that tank, but I want to be clear that I’m going to be doing that, and dropping certainly sources for this reason that I would otherwise have included for completeness.
If this was talking about you, and you’d like to continue this trip, please get it together.
The Lighter Side
Don’t worry, your argument remains valid. I mean, it’s wrong, but that never stopped you before, why start now?

Matt: Live players in who kills us first?
Peter Wildeford: Yes, that’s one way to look at it.
6 comments
Comments sorted by top scores.
comment by ollie_ · 2025-01-31T15:52:06.900Z · LW(p) · GW(p)
I believe that opensource advancements like R1 will drive wider adoption of ai systems.
I think that the pricing models will change soon. Everyone talks about cost per million tokens to contact a hosted service, but I think it'll switch to be cloud costs to provide infrastructure that can run models. Virtual machines running something like ollama.
This solves another huge problem, privacy and how prompt data is handled. If you're using an api to a hosted service you need to have a very good understanding of how your submitted prompt data is handled. This is key for organisations. I feel like the lack of understanding here is preventing widespread adoption, especially for communication tools that handle sensitive data.
For example, you could run Deepseek R1 using ollama on an Azure virtual machine (nc series) that you pay per hour for, and then your cost isn't based on usage of your ai. Right now it's expensive to provision the infra to support decent models, but these costs fall continuously.
I can imagine a world where organisations provision cloud infrastructure in their environments running open source models.
https://learn.microsoft.com/en-us/azure/virtual-machines/sizes/gpu-accelerated/nc-series?tabs=sizebasic
https://huggingface.co/deepseek-ai/DeepSeek-R1
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2025-02-01T03:06:28.826Z · LW(p) · GW(p)
Is there any other consumer software that works on this model? I can't think of any
Some enterprise software has stuff like this
comment by p.b. · 2025-02-04T10:29:52.221Z · LW(p) · GW(p)
A very detailed and technical analysis of the bear case for Nvidia by Jeffrey Emanuel, that Matt Levine claims may have been responsible for the Nvidia price decline.
I read that last week. It was an interesting case of experiencing Gell-Mann-Amnesia several times within the same article.
All the parts where I have some expertise were vague, used terminology incorrectly and were often just wrong. All the rest was very interesting!
If this article crashed the market: EMH RIP.
comment by p.b. · 2025-02-04T09:54:05.586Z · LW(p) · GW(p)
I would hesitate to buy a build based on R1. R1 is special in the sense that the MoE-architecture trades off compute requirements vs RAM requirements. Which is why now these CPU-builds start to make some sense - you get a lot less compute, but much more RAM.
As soon as the next dense model drops which could have 5-times fewer parameters for the same performance the build will stop making any sense. And of course until then you are also handicapped when it comes to running smaller models fast.
The sweet spot is integrated RAM/VRAM like in a Mac and in the upcoming NVIDIA DIGITS. But buying a handful of used 3090s probably also makes more sense to me then the CPU-only builds.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-31T23:52:25.912Z · LW(p) · GW(p)
New benchmark agrees with my intuitions on r1's creative writing skills: https://x.com/LechMazur/status/1885430117591027712
comment by Shankar Sivarajan (shankar-sivarajan) · 2025-01-31T17:25:30.404Z · LW(p) · GW(p)
Would you consider this a "95th to 99th percentile libertarian" position if it were about AI models instead of OSes?
