What happens next?
post by Logan Zoellner (logan-zoellner) · 2024-12-29T01:41:33.685Z · LW · GW · 19 commentsContents
19 comments
Two years ago, I noted that we had clearly entered [LW · GW] the era of general intelligence, but that it was "too soon" to expect widespread social impacts.

In those 2 years, AI development has followed the best possible of the 3 paths I suggested (foom/GPT-4-takes-my-job/Slow Takeoff). Returns to scale seem to be delivering a steady ~15 IQ points/year and cutting edge models appear to be largely a compute-intensive project that allows (relatively) safety-conscious leading labs to explore the new frontiers while others reap the benefits with ~1 year delay.
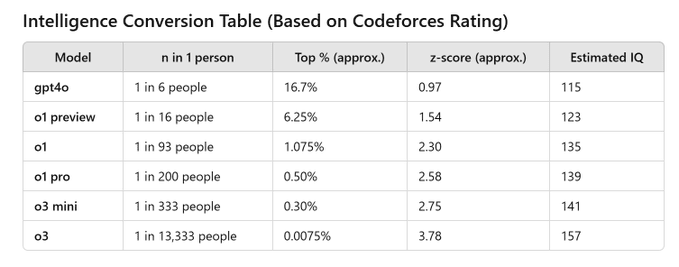
If I had to identify 3 areas where GPT-3.5 was lacking, it would have been:
- reasoning
- modeling the real world
- learning on-the-fly
Of those three, reasoning (o3) is largely solved and we have promising approaches for world modeling (genie2). Learning on-the-fly remains, but I expect some combination of sim2real and muZero to work here.
Hence, while in 2023 I wrote
For any task that one of the large AI labs (DeepMind, OpenAI, Meta) is willing to invest sufficient resources in they can obtain average level human performance using current AI techniques.
I would now write
Going forward, we should expect to see job automation determined primarily not based on technical difficulty but rather based on social resistance (or lack thereof) to automating that task.
Already, the first automated jobs are upon us: taxi driver, security guard, amazon worker. Which jobs will be automated next will be decided by a calculation that looks at:
- social desirability
- lack of special interests/collective bargaining (the dockworkers are never getting automated)
- low risk (self driving is maybe the exception that prove the rule here. Despite being safer than human for years Waymo remains restricted to a few cities)
Security guard at mall is the prototypical "goes first" example, since:
- everyone is in favor of more security
- security guards at malls are not known for being good at collective bargaining
- mall security guards have a flashlight (not a gun)
Brain surgeon is the prototypical "goes last"example:
- a "human touch" is considered a key part of the health care
- doctors have strong regulatory protections limiting competition
- Literal lives at at stake and medical malpractice is one of the most legally perilous areas imaginable
As AI proliferates across society, we have to simultaneously solve a bunch of problems:
- What happens to all the people whose jobs are replaced?
- The "AGI Race" between US and China (I disagree with those who claim China is not racing)
- Oh, by the way, AI is getting smarter faster than ever and we haven't actually solved alignment yet
I suspect we have 2-4 years before one of these becomes a crisis. (And by crisis, I mean something everyone on Earth is talking about all the time, in the same sense that Covid-19 was a crisis).
The actual "tone" of the next few years could be very different depending on which of these crises hits first.
1. Jobs hits first. In this world, mass panic about unemployment leads the neo-ludditte movement to demand a halt to job automation. A "tax the machines" policy is implemented and a protracted struggle over what jobs get automated and who benefits/loses plays out across all of society (~60%)
2. AGI Race hits first. In this world, the US and China find themselves at war (or on the brink of it). Even if the US lets Taiwan get swallowed, the West is still going to gear up for the next fight. This means building as much as fast as possible. (~20%)
3. Alignment hits first. Some kind of alignment catastrophe happens and the world must deal with it. Maybe it is fatal, maybe it is just some self-replicating GPT-worm. In this world, the focus is on some sort of global AI governance to make sure that whatever the first Alignment Failure was (and given the way gov't works, totally ignoring other failure cases) (~10%)
4. Something wild. The singularity is supposed to be unpredictable. (~10%)
19 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2024-12-29T08:52:08.206Z · LW(p) · GW(p)
reasoning (o3) is largely solved
Solving competition problems could well be like a chess-playing AI playing chess well. Does it generalize far enough, can the method be applied to train the AI on a wide variety of tasks that are not like competition problems (distinct in it being possible to write verifiers for attempted solutions)? We know that this is not the case with AlphaZero. Is it the case with o3-like methods? Hard to tell. I don't see how it could be known either way yet.
comment by PeterMcCluskey · 2024-12-29T04:36:38.376Z · LW(p) · GW(p)
I want to register different probabilities:
- Jobs hits first (25%).
- AGI race hits first (50%).
- Alignment hits first (15%).
comment by Matt Goldenberg (mr-hire) · 2024-12-29T19:03:19.307Z · LW(p) · GW(p)
Brain surgeon is the prototypical "goes last"example:
- a "human touch" is considered a key part of the health care
- doctors have strong regulatory protections limiting competition
- Literal lives at at stake and medical malpractice is one of the most legally perilous areas imaginable
Is neuralink the exception that proves the rule here? I imagine that IF we come up with live saving or miracle treatments that can only be done with robotic surgeons, we may find a way through the red tape?
comment by hmys (the-cactus) · 2024-12-29T11:16:46.195Z · LW(p) · GW(p)
Comparing IQ and codeforces doesn't make much sense. Please stop doing this.
Attaching IQs to LLMs makes even less sense. Except as a very loose metaphor. But please also stop doing this.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T15:47:41.172Z · LW(p) · GW(p)
Is your disagreement specifically with the word "IQ" or with the broader point, that AI progress is continuing to make progress at a steady rate that implies things are going to happen soon-ish (2-4 years)?
If specifically with IQ, feel free to replace the word with "abstract units of machine intelligence" wherever appropriate.
If with "big things soon", care to make a prediction?
Replies from: the-cactus, Nick_Tarleton↑ comment by hmys (the-cactus) · 2024-12-29T19:36:42.342Z · LW(p) · GW(p)
I specifically disagree with the IQ part and the codeforces part. Meaning, I think they're misleading.
IQ and coding ability are useful measures of intelligence in humans because they correlate with a bunch of other things we care about. Not to say its useless to measure "IQ" or coding ability in LLMs, but presenting like they mean anything like what they mean in humans is wrong, or at least will give many people reading it the wrong impression.
As for the overall point of this post. I roughly agree? I mean, I think the timelines are not too unreasonable, and think the tri/quad lemma you put up can be a useful framing. I mostly disagree with using the metrics you put up first to quantify any of this. I think we should look at specific abilities current models have/lack, which are necessary for the scenarios you outlined, and how soon we're likely to get them. But you do go through that somewhat in the post.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T20:22:50.341Z · LW(p) · GW(p)
It doesn't sound like we disagree at all.
Replies from: admohanraj↑ comment by _liminaldrift (admohanraj) · 2024-12-30T01:30:01.400Z · LW(p) · GW(p)
I think even with humans, IQ isn't the best measure to quantify what we call intelligence. The way I tend to think of it is that high general intelligence correlates with higher IQ test scores, but just optimizing performance on IQ tests doesn't necessarily mean that you become more intelligent in general outside of that task.
But I'm okay with the idea of using IQ scores in the context of this post because it seems useful to capture the change in capabilities of these models.
↑ comment by Nick_Tarleton · 2024-12-29T16:59:49.832Z · LW(p) · GW(p)
If specifically with IQ, feel free to replace the word with "abstract units of machine intelligence" wherever appropriate.
By calling it "IQ", you were (EDIT: the creator of that table was) saying that gpt4o is comparable to a 115 IQ human, etc. If you don't intend that claim, if that replacement would preserve your meaning, you shouldn't have called it IQ. (IMO that claim doesn't make sense — LLMs don't have human-like ability profiles.)
↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T17:23:42.158Z · LW(p) · GW(p)
you were saying that gpt4o is comparable to a 115 IQ human
gpt4o is not literally equivalent to a 115 IQ human.
Use whatever word you want for the concept "score produced when an LLM takes an IQ test".
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2024-12-29T19:03:57.061Z · LW(p) · GW(p)
But is this comparable to G? Is it what we want to measure?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T20:21:04.448Z · LW(p) · GW(p)
I have no idea what you want to measure.
I only know that LLMs are continuing to steadily increase in some quality (which you are free to call "fake machine IQ" or whatever you want) and that If they continue to make progress at the current rate there will be consequences and we should prepare to deal with those consequences.
↑ comment by Matt Goldenberg (mr-hire) · 2024-12-29T20:25:48.126Z · LW(p) · GW(p)
I think there's a world where AIs continue to saturate benchmarks and the consequences are that the companies getting to say they saturate those benchmarks.
Especially at the tails of those benchmarks I imagine it won't be about the consequences we care about like general reasoning, ability to act autonomously, etc.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T20:45:26.511Z · LW(p) · GW(p)
on a metaphysical level I am completely on board with "there is no such thing as IQ. Different abilities are completely uncorrelated. Optimizing for metric X is uncorrelated with desired quality Y..."
On a practical level, however, I notice that every time OpenAI announces they have a newer shinier model, it both scores higher on whatever benchmark and is better at a bunch of practical things I care about.
Imagine there was a theoretically correct metric called the_thing_logan_actually_cares_about. I notice in my own experience there is a strong correlation between "fake machine IQ" and the_thing_logan_actually_cares_about. I further note that if one makes a linear fit against:
Progress_over_time + log(training flops) + log(inference flops)
It nicely predicts both the_thing_logan_actually_cares_about and "fake machine IQ".
Replies from: admohanraj↑ comment by _liminaldrift (admohanraj) · 2024-12-30T01:48:46.391Z · LW(p) · GW(p)
This reminds me of this LessWrong post.
If It’s Worth Doing, It’s Worth Doing With Made-Up Statistics
https://www.lesswrong.com/posts/9Tw5RqnEzqEtaoEkq/if-it-s-worth-doing-it-s-worth-doing-with-made-up-statistics [LW · GW]
comment by T431 (rodeo_flagellum) · 2024-12-29T06:43:54.483Z · LW(p) · GW(p)
The below captures some of my thoughts on the "Jobs hits first" scenario.
There is probably something with the sort of break down I have in mind (though, whatever this may be, I have not encountered it, yet) w.r.t. Jobs hits first but here goes: the landscape of AI induced unemployment seems highly heterogeneous, at least in expectation over the next 5 years. For some jobs, it seems likely that there will be instances of (1) partial automation, which could mean either not all workers are no longer needed (even if their new tasks no longer fully resemble their previous tasks), i.e. repurposing of existing workers, or most workers remain employed but do more labor with help from AI and of (2) prevalent usage of AI across the occupational landscape but without much unemployment, with human work (same roles pre-automation) still being sought after, even if there are higher relative costs associated with the human employment (basically, the situation: human work + AI work > AI work, after considering all costs). Updating based on this more nuanced (but not critically evaluated) situation w.r.t. Jobs hits first, I would not expect the demand for a halt to job automation to be any less but perhaps a protracted struggle over what jobs get automated might be less coordinated if there are swaths of the working population still holding out career-hope, on the basis that they have not had their career fully stripped away, having possibly instead been repurposed or compensated less conditional on the automation.
The phrasing
...a protracted struggle...
nevertheless seems a fitting description for the near-term future of employment as it pertains to the incorporation of AI into work.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T15:50:47.848Z · LW(p) · GW(p)
perhaps a protracted struggle over what jobs get automated might be less coordinated if there are swaths of the working population still holding out career-hope, on the basis that they have not had their career fully stripped away, having possibly instead been repurposed or compensated less conditional on the automation.
Yeah, this is totally what I have in mind. There will be some losers and some big winners, and all of politics will be about this fact more or less. (think the dockworkers strike but 1000x)
comment by Nick_Tarleton · 2024-12-29T16:46:43.189Z · LW(p) · GW(p)
Learning on-the-fly remains, but I expect some combination of sim2real and muZero to work here.
Hmm? sim2real AFAICT is an approach to generating synthetic data, not to learning. MuZero is a system that can learn to play a bunch of games, with an architecture very unlike LLMs. This sentence doesn't typecheck for me; what way of combining these concepts with LLMs are you imagining?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-12-29T17:36:04.832Z · LW(p) · GW(p)
Imagine you were trying to build a robot that could:
1. Solve a complex mechanical puzzle it has never seen before
2. Play at an expert level a board game that I invented just now.
Both of these are examples of learning-on-the-fly. No amount of pre-training will ever produce a satisfying result.
The way I believe a human (or a cat) solves 1. is they: look at the puzzle, try some things, build a model of the toy in their head, try things on the model in their head, eventually solve the puzzle. There are efforts to get robots to follow the same process, but nothing I would consider "this is the obvious correct solution" quite yet.
The way to solve 2. (I think) is simply to have the LLM translate the rules of the game into a formal description and then run muZero on that.
Ideally there is some unified system that takes out the "translate into another domain and do your training there" step (which feels very anti-bitter-lesson). But I confess I haven't the slightest idea how to build such a system.