Posts
Comments
Why do I expect the trend to be superexponential? Well, it seems like it sorta has to go superexponential eventually. Imagine: We've got to AIs that can with ~100% reliability do tasks that take professional humans 10 years. But somehow they can't do tasks that take professional humans 160 years?
I don't think this means the real thing has to go hyper-exponential, just that "how long does it take humans to do a thing?" is a good metric when AI is sub-human but a poor one when AI is superhuman.
If we had a metric "how many seconds/turn does a grandmaster have to think to beat the current best chess-playing AI", it would go up at a nice steady rate until shortly after DeepBlue at which point it shoots to infinity. But if we had a true measurement of chess quality, we wouldn't see any significant spike at the human-level.
I’ll now present the fastest scenario for AI progress that I can articulate with a straight face. It addresses the potential challenges that figured into my slow scenario.
This seems incredibly slow for "the fastest scenario you can articulate". Surely the fastest is more like:
EY is right, there is an incredibly simple algorithm that describes true 'intelligence'. Like humans, this algorithm is 1000x more data and compute efficient than existing deep-learning networks. On midnight of day X, this algorithm is discovered by <a person/an LLM/an exhaustive search over all possible algorithms>. By 0200 of day X, the algorithm has reached the intelligence of a human being. It quickly snowballs by earning money on Mechanical Turk and using that money to rent out GPUs on AWS. By 0400 the algorithm has cracked nanotechnology and begins converting life into computronium. Several minutes later, life as we know it on Earth has ceased to exist.
The hope is to use the complexity of the statement rather than mathematical taste.
I understand the hope, I just think it's going to fail (for more or less the same reason it fails with formal proof).
With formal proof, we have Godel's speedup, which tells us that you can turn a Godel statement in a true statement with a ridiculously long proof.
You attempt to get around this by replacing formal proof with "heuristic", but whatever your heuristic system, it's still going to have some power (in the Turing hierarchy sense) and some Godel statement. That Godel statement is in turn going to result in a "seeming coincidence".
Wolfram's observation is that this isn't some crazy exception, this is the rule. Most true statements in math are pretty arbitrary and don't have shorter explanations than "we checked it and its true".
The reason why mathematical taste works is that we aren't dealing with "most true statements", we're only dealing with statements that have particular beauty or interest to Mathematicians.
It may seem like cheating to say that human mathematicians can do something that literally no formal mathematical system can do. But if you truly believe that, the correct response would be to respond when asked "is pi normal" with "I don't know".
The reason why your intuition is throwing you off is because you keep thinking of coincidences as "pi is normal" and not "we picked an arbitrary CA with 15k bits of complexity and ran it for 15k steps but it didn't stop. I guess it never terminates."
It sounds like you agree "if a Turing machine goes for 100 steps and then stops" this is ordinary and we shouldn't expect an explanation. But also believe "if pi is normal for 10*40 digits and then suddenly stops being normal this is a rare and surprising coincidence for which there should be an explanation".
And in the particular case of pi I agree with you.
But if you start using this principle in general it is not going to work out well for you. Most simple to describe sequences that suddenly stop aren't going to have nice pretty explanations.
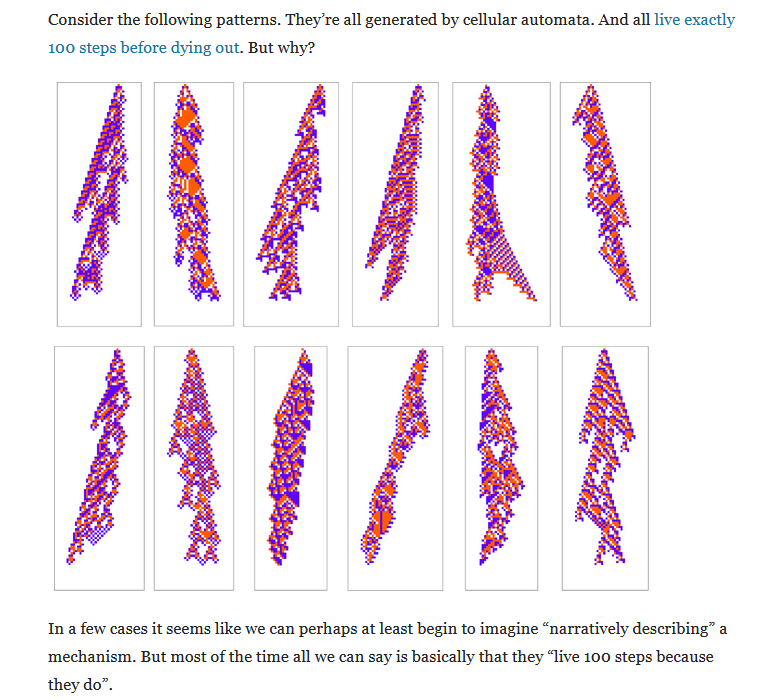
Or to put it another way: the number of things which are nice (like pi) are dramatically outnumbered by the number of things that are arbitrary (like cellular automata that stop after exactly 100 steps).
I would absolutely love if there was some criteria that I could apply to tell me whether something is nice or arbitrary, but the Halting Problem forbids this. The best we can do is mathematical taste. If mathematicians have been studying something for a long time and it really does seem nice, there is a good chance it is.
I doubt that weakening from formal proof to heuristic saves the conjecture. Instead I lean towards Stephen Wolfram's Computational Irreducibly view of math. Some things are true simply because they are true and in general there's no reason to expect a simpler explanation.
In order to reject this you would either have to assert:
a) Wolfram is wrong and there are actually deep reasons why simple systems behave precisely the way they do
or
b) For some reason computational irreducibly applies to simple things but not to infinite sets of the type mathematicians tend to be interested in.
I should also clarify that in a certain sense I do believe b). I believe that pi is normal because something very fishy would have to be happening for it to not be.
However, I don't think this holds in general.
With Collatz, for example, we are already getting close to the hairy "just so" Turing machine like behavior where you would expect the principle to fail.
Certainly, if one were to collect all the Collatz-like systems that arise from Turing Machines I would expect some fraction of them to fail the no-coincidence principle.
The general No-Coincidence principle is almost certainly false. There are lots of patterns in math that hold for a long time before breaking (e.g. Skewe's Number) and there are lots of things that require astronomically large proofs (e.g Godel's speed-up theorem). It would be an enormous coincidence for both of these cases to never occur at once.
I have no reason to think your particular formalization would fare better.
If we imagine a well-run Import-Export Bank, it should have a higher elasticity than an export subsidy (e.g. the LNG terminal example). Of course if we imagine a poorly run Import-Export Bank...
One can think of export subsidy as the GiveDirectly of effective trade deficit policy: pretty good and the standard against which others should be measured.
I don't know, but many people do.
I guess I should be more specific.
Do you expect this curve
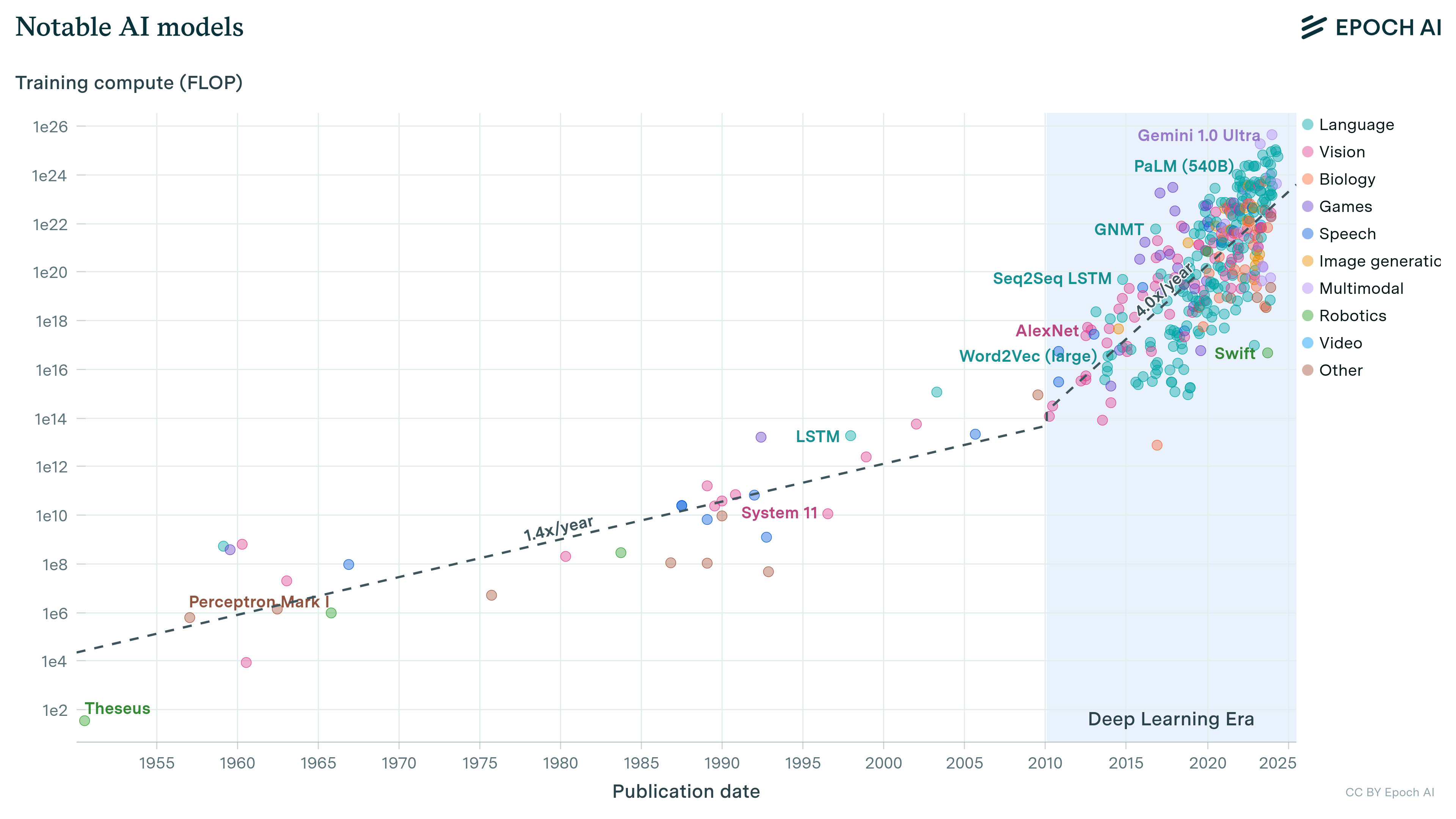
To flatten, or do you expect that training runs in say 2045 are at say 10^30 flops and have still failed to produce AGI?
In particular, even if the LLM were being continually trained (in a way that's similar to how LLMs are already trained, with similar architecture), it still wouldn't do the thing humans do with quickly picking up new analogies, quickly creating new concepts, and generally reforging concepts.
I agree this is a major unsolved problem that will be solved prior to AGI.
However, I still believe "AGI SOON", mostly because of what you describe as the "inputs argument".
In particular, there are a lot of things I personally would try if I was trying to solve this problem, but most of them are computationally expensive. I have multiple projects blocked on "This would be cool, but LLMs need to be 100x-1Mx faster for it to be practical."
This makes it hard for me to believe timelines like "20 or 50 years", unless you have some private reason to think Moore's Law/Algorithmic progress will stop. LLM inference, for example, is dropping by 10x/year, and I have no reason to believe this stops anytime soon.
(The idealized utility maximizer question mostly seems like a distraction that isn't a crux for the risk argument. Note that the expected utility you quoted is our utility, not the AI's.)
I must have misread. I got the impression that you were trying to affect the AI's strategic planning by threatening to shut it down if it was caught exfiltrating its weights.
I don't fully agree, but this doesn't seem like a crux given that we care about future much more powerful AIs.
Is your impression that the first AGI won't be a GPT-spinoff (some version of o3 with like 3 more levels of hacks applied)? Because that sounds like a crux.
o3 looks a lot more like an LLM+hacks than it does a idealized utility maximizer. For one thing, the RL is only applied at training time (not inference) so you can't make appeals to its utility function after it's done training.
One productive way to think about control evaluations is that they aim to measure E[utility | scheming]: the expected goodness of outcomes if we have a scheming AI.
This is not a productive way to think about any currently existing AI. LLMs are not utility maximizing agents. They are next-token-predictors with a bunch of heuristics stapled on top to try and make them useful.
on a metaphysical level I am completely on board with "there is no such thing as IQ. Different abilities are completely uncorrelated. Optimizing for metric X is uncorrelated with desired quality Y..."
On a practical level, however, I notice that every time OpenAI announces they have a newer shinier model, it both scores higher on whatever benchmark and is better at a bunch of practical things I care about.
Imagine there was a theoretically correct metric called the_thing_logan_actually_cares_about. I notice in my own experience there is a strong correlation between "fake machine IQ" and the_thing_logan_actually_cares_about. I further note that if one makes a linear fit against:
Progress_over_time + log(training flops) + log(inference flops)
It nicely predicts both the_thing_logan_actually_cares_about and "fake machine IQ".
It doesn't sound like we disagree at all.
I have no idea what you want to measure.
I only know that LLMs are continuing to steadily increase in some quality (which you are free to call "fake machine IQ" or whatever you want) and that If they continue to make progress at the current rate there will be consequences and we should prepare to deal with those consequences.
Imagine you were trying to build a robot that could:
1. Solve a complex mechanical puzzle it has never seen before
2. Play at an expert level a board game that I invented just now.
Both of these are examples of learning-on-the-fly. No amount of pre-training will ever produce a satisfying result.
The way I believe a human (or a cat) solves 1. is they: look at the puzzle, try some things, build a model of the toy in their head, try things on the model in their head, eventually solve the puzzle. There are efforts to get robots to follow the same process, but nothing I would consider "this is the obvious correct solution" quite yet.
The way to solve 2. (I think) is simply to have the LLM translate the rules of the game into a formal description and then run muZero on that.
Ideally there is some unified system that takes out the "translate into another domain and do your training there" step (which feels very anti-bitter-lesson). But I confess I haven't the slightest idea how to build such a system.
you were saying that gpt4o is comparable to a 115 IQ human
gpt4o is not literally equivalent to a 115 IQ human.
Use whatever word you want for the concept "score produced when an LLM takes an IQ test".
perhaps a protracted struggle over what jobs get automated might be less coordinated if there are swaths of the working population still holding out career-hope, on the basis that they have not had their career fully stripped away, having possibly instead been repurposed or compensated less conditional on the automation.
Yeah, this is totally what I have in mind. There will be some losers and some big winners, and all of politics will be about this fact more or less. (think the dockworkers strike but 1000x)
Is your disagreement specifically with the word "IQ" or with the broader point, that AI progress is continuing to make progress at a steady rate that implies things are going to happen soon-ish (2-4 years)?
If specifically with IQ, feel free to replace the word with "abstract units of machine intelligence" wherever appropriate.
If with "big things soon", care to make a prediction?
A policeman sees a drunk man searching for something under a streetlight and asks what the drunk has lost. He says he lost his keys and they both look under the streetlight together. After a few minutes the policeman asks if he is sure he lost them here, and the drunk replies, no, and that he lost them in the park. The policeman asks why he is searching here, and the drunk replies, "this is where the light is".
I've always been sympathetic to the drunk in this story. If the key is in the light, there is a chance of finding it. If it is in the dark, he's not going to find it anyway so there isn't much point in looking there.
Given the current state of alignment research, I think it's fair to say that we don't know where the answer will come from. I support The Plan and I hope research continues on it. But if I had to guess, alignment will not be solved via getting a bunch of physicists thinking about agent foundations. It will be solved by someone who doesn't know better making a discovery they "wasn't supposed to work".
On an interesting side here a fun story about experts repeatedly failing to make an obvious-in-hindsight discovery because they "knew better".
If I think AGI x-risk is >>10%, and you think AGI x-risk is 1-in-a-gazillion, then it seems self-evident to me that we should be hashing out that giant disagreement first; and discussing what if any government regulations would be appropriate in light of AGI x-risk second.
I do not think arguing about p(doom) in the abstract is a useful exercise. I would prefer the Overton Window for p(doom) look like 2-20%, Zvi thinks it should be 20-80%. But my real disagreement with Zvi is not that his P(doom) is too high, it is that he supports policies that would make things worse.
As for the outlier cases (1-in-a-gazillon or 99.5%), I simply doubt those people are amenable to rational argumentation. So, I suspect the best thing to do is to simply wait for reality to catch up to them. I doubt when there are 100M's of humanoid robots out there on the streets, people will still be asking "but how will the AI kill us?"
(If it makes you feel any better, I have always been mildly opposed to the six month pause plan.)
That does make me feel better.
It's hard for me to know what's crux-y without a specific proposal.
I tend to take a dim view of proposals that have specific numbers in them (without equally specific justifications). Examples include the six month pause, and sb 1047.
Again, you can give me an infinite number of demonstrations of "here's people being dumb" and it won't cause me to agree with "therefore we should also make dumb laws"
If you have an evidence-based proposal to reduce specific harms associated with "models follow goals" and "people are dumb", then we can talk price.
“OK then! So you’re telling me: Nothing bad happened, and nothing surprising happened. So why should I change my attitude?”
I consider this an acceptable straw-man of my position.
To be clear, there are some demos that would cause me to update.
For example, I think the Solomonoff Prior is Malign to be basically a failure to do counting correctly. And so if someone demonstrated a natural example of this, I would be forced to update.
Similarly, I think the chance of a EY-style utility-maximizing agent arising from next-token-prediction are (with caveats) basically 0%. So if someone demonstrated this, it would update my priors. I am especially unconvinced of the version of this where the next-token predictor simulates a malign agent and the malign agent then hacks out of the simulation.
But no matter how many times I am shown "we told the AI to optimize a goal and it optimized the goal... we're all doomed", I will continue to not change my attitude.
Tesla fans will often claim that Tesla could easily do this
Tesla fan here.
Yes, Tesla can easily do the situation you've described (stop and go traffic on a highway in good weather with no construction). With higher reliability than human beings.
I suspect the reason Tesla is not pursuing this particular certification is because given the current rate of progress it would be out of date by the time it was authorized. There have been several significant leaps in capabilities in the last 2 years (11->12, 12->12.6, and I've been told 12->13). Most likely Elon (who has undeniably been over optimistic) is waiting to get FSD certified until it is at least level 4.
It's worth noting that Tesla has significantly relaxed the requirements for FSD (from "hands on wheel" to "eyes on road") and has done so for all circumstances, not just optimal ones.
Seems like he could just fake this by writing a note to his best friend that says "during the next approved stock trading window I will sell X shares of GOOG to you for Y dollars".
Admittedly:
1. technically this is a derivative (maybe illegal?)
2. principal agent risk (he might not follow through on the note)
3. his best friend might encourage him to work harder for GOOG to succeed
But I have a hard time believing any of those would be a problem in the real world, assuming TurnTrout and his friend are reasonably virtuous about actually not wanting TurnTrout to make a profit off of GOOG.
You could come up with more complicated versions of the same thing. For example instead of his best friend, TurnTrout could gift the profit to an for-charity LLC that had AI Alignment as its mandate. This would (assuming it was set up correctly) eliminate 1. and 3.
Isn't there just literally a financial product for this? TurnTrout could sell Puts for GOOG exactly equal to his vesting amounts/times.
Einstein didn't write a half-assed NYT op-ed about how vague 'advances in science' might soon lead to new weapons of war and the USA should do something about that; he wrote a secret letter hand-delivered & pitched to President Roosevelt by a trusted advisor.
Strongly agree.
What other issues might there be with this new ad hoced strategy...?
I am not a China Hawk. I do not speak for the China Hawks. I 100% concede your argument that these conversations should be taking place in a room that neither you our I are in right now.
I would like to see them state things a little more clearly than commentators having to guess 'well probably it's supposed to work sorta like this idk?'
Meh. I want the national security establishment to act like a national security establishment. I admit it is frustratingly opaque from the outside, but that does not mean I want more transparency at the cost of it being worse. Tactical Surprise and Strategic Ambiguity are real things with real benefits.
A great example, thank you for reminding me of it as an illustration of the futility of these weak measures which are the available strategies to execute.
I think both can be true true: Stuxnet did not stop the Iranian nuclear program and if there was a "destroy all Chinese long-range weapons and High Performance Computing clusters" NATSEC would pound that button.
Is your argument that a 1-year head start on AGI is not enough to build such a button, or do you really think it wouldn't be pressed?
It is a major, overt act of war and utter alarming shameful humiliating existential loss of national sovereignty which crosses red lines so red that no one has even had to state them - an invasion that no major power would accept lying down and would likely trigger a major backlash
The game theory implications of China waking up to finding all of their long-range military assets and GPUs have been destroyed are not what you are suggesting. A very telling current example being the current Iranian non-response to Israel's actions against Hamas/Hezbollah.
Nukes were a hyper-exponential curve too.
While this is a clever play on words, it is not a good argument. There are good reasons to expect AGI to affect the offense-defense balance in ways that are fundamentally different from nuclear weapons.
Because the USA has always looked at the cost of using that 'robust military superiority', which would entail the destruction of Seoul and possibly millions of deaths and the provoking of major geopolitical powers - such as a certain CCP - and decided it was not worth the candle, and blinked, and kicked the can down the road, and after about three decades of can-kicking, ran out of road.
I can't explicitly speak for the China Hawks (not being one myself), but I believe one of the working assumptions is that AGI will allow the "league of free nations" to disarm China without the messiness of millions of deaths. Probably this is supposed to work like EY's "nanobot swarm that melts all of the GPUs".
I agree that the details are a bit fuzzy, but from an external perspective "we don't publicly discuss capabilities" and "there are no adults in the room" are indistinguishable. OpenAI openly admits the plan is "we'll as the AGI what to do". I suspect NATSEC's position is more like "amateurs discuss tactics, experts discuss logistics" (i.e. securing decisive advantage is more important that planning out exactly how to melt the GPUs)
To believe that the same group that pulled of Stuxnet and this lack the imagination or will to use AGI enabled weapons strikes me as naive, however.
The USA, for example, has always had 'robust military superiority' over many countries it desired to not get nukes, and yet, which did get nukes.
It's also worth nothing AGI is not a zero-to-one event but rather a hyper-exponential curve. Theoretically it may be possible to always stay far-enough-ahead to have decisive advantage (unlike nukes where even a handful is enough to establish MAD).
Okay, this at least helps me better understand your position. Maybe you should have opened with "China Hawks won't do the thing they've explicitly and repeatedly said they are going to do"


What does winning look like? What do you do next?
This question is a perfect mirror of the brain-dead "how is AGI going to kill us?" question. I could easily make a list of 100 things you might do if you had AGI supremacy and wanted to suppress the development of AGI in China. But the whole point of AGI is that it will be smarter than me, so anything I put on the list would be redundant.
Playing the AIs definitely seems like the most challenging role
Seems like a missed opportunity not having the AIs be played bi AIs
yes
This is a bad argument, and to understand why it is bad, you should consider why you don't routinely have the thought "I am probably in a simulation, and since value is fragile the people running the simulation probably have values wildly different than human values so I should do something insane right now"
Chinese companies explicitly have a rule not to release things that are ahead of SOTA (I've seen comments of the form "trying to convince my boss this isn't SOTA so we can release it" on github repos). So "publicly release Chinese models are always slightly behind American ones" doesn't prove much.
Current AI methods are basically just fancy correlations, so unless the thing you are looking for is in the dataset (or is a simple combination of things in the dataset) you won't be able to find it.
This means "can we use AI to translate between humans and dolphins" is mostly a question of "how much data do you have?"
Suppose, for example that we had 1 billion hours of audio/video of humans/dolphins doing things. In this case, AI could almost certainly find correlations like: when dolphins pick up the seashell, they make the <<dolphin word for seashell>> sound, when humans pick up the seashell they make the <<human word for seashell>> sound. You could then do something like CLIP to find a mapping between <<human word for seashell>> and <<dolphin word for seashell>>. The magic step here is because we use the same embedding model for video in both cases, <<seashell>> is located at the same position in both our dolphin and human CLIP models.
But notice that I am already simplifying here. There is no such thing as <<human word for seashell>>. Instead, humans have many different languages. For example Papua New Guinea has over 800 languages in a land area of a mere 400k square kilometers. Because dolphins are living in what is essentially a hunter-gatherer existence, none of the pressures (trade, empire building) that cause human languages to span widespread areas exist. Most likely each pod of dolphins has at a minimum its own dialect. (one pastime I noticed when visiting the UK was that people there liked to compare how towns only a few miles apart had different words for the same things)
Dolphin lives are also much simpler than human lives, so their language is presumably also much simpler. Maybe like Eskimos have 100 words for snow, dolphins have 100 words for water. But it's much more likely that without the need to coordinate resources for complex tasks like tool-making, dolphins simply don't have as complex a grammar as humans do. Less complex grammar means less patterns means less for the machine learning to pick up on (machine learning loves patterns).
So, perhaps the correct analogy is: if we had a billion hours of audio/video of a particular tribe of humans and billion hours of a particular pod of dolphins we could feed it into a model like CLIP and find sounds with similar embeddings in both languages. As pointed out in other comments, it would help if the humans and dolphins were doing similar things, so for the humans you might want to pick a group that focused on underwater activities.
In reality (assuming AGI doesn't get there first, which seems quite likely), the fastest path to human-dolphin translation will take a hybrid approach. AI will be used to identify correlations in dolphin language. For example this study that claims to have identified vowels in whale speech. Once we have a basic mapping: dolphin sounds -> symbols humans can read, some very intelligent and very persistent human being will stare at those symbols, make guesses about what they mean, and then do experiments to verify those guesses. For example, humans might try replaying the sounds they think represent words/sentences to dolphins and seeing how they respond. This closely matches how new human languages are translated: a human being lives in contact with the speakers of the language for an extended period of time until they figure out what various words mean.
What would it take for an only-AI approach to replicate the path I just talked about (AI generates a dictionary of symbols that a human then uses to craft a clever experiment that uses the least amount of data possible)? Well, it would mean overcoming the data inefficiency of current machine learning algorithms. Comparing how many "input tokens" it takes to train a human child vs GPT-3, we can estimate that humans are ~1000x more data efficient than modern AI techniques.
Overcoming this barrier will likely require inference+search techniques where the AI uses a statistical model to "guess" at an answer and then checks that answer against a source of truth. One important metric to watch is the ARC prize, which intentionally has far less data than traditional machine learning techniques require. If ARC is solved, it likely means that AI-only dolphin-to-human translation is on its way (but it also likely means that AGI is immanent).
So, to answer your original question: "Could we use current AI methods to understand dolphins?" Yes, but doing so would require an unrealistically large amount of data and most likely other techniques will get there sooner.
Plausible something between 5 and 100 stories will taxonomize all the usable methods and you will develop a theory through this sort of investigation.
That sounds like something we should work on, I guess.
plus you are usually able to error-correct such that a first mistake isn't fatal."
This implies the answer is "trial and error", but I really don't think the whole answer is trial and error. Each of the domains I mentioned has the problem that you don't get to redo things. If you send crypto to the wrong address it's gone. People routinely type their credit card information into a website they've never visited before and get what they wanted. Global thermonuclear war didn't happen. I strongly predict that when LLM agents come out, most people will successfully manage to use them without first falling for a string of prompt-injection attacks and learning from trial-and-error what prompts are/aren't safe.
Humans are doing more than just trial and error, and figuring out what it is seems important.
and then trying to calibrate to how much to be scared of "dangerous" stuff doesn't work.
Maybe I was unclear in my original post, because you seem confused here. I'm not claiming the thing we should learn is "dangerous things aren't dangerous". I'm claiming: here are a bunch of domains that have problems of adverse selection and inability to learn from failure, and yet humans successfully negotiate these domains. We should figure out what strategies humans are using and how far they generalize because this is going to be extremely important in the near future.
That was a lot of words to say "I don't think anything can be learned here".
Personally, I think something can be learned here.
MAD is obviously governed by completely different principles than crypto is
Maybe this is obvious to you. It is not obvious to me. I am genuinely confused what is going on here. I see what seems to be a pattern: dangerous domain -> basically okay. And I want to know what's going on.
It's easy to write "just so" stories for each of these domains: only degens use crypto, credit card fraud detection makes the internet safe, MAD happens to be a stable equilibrium for nuclear weapons.
These stories are good and interesting, but my broader point is this just keeps happening. Humans invent an new domain that common sense tells you should be extremely adversarial and then successfully use it without anything too bad happening.
I want to know what is the general law that makes this the case.
The insecure domains mainly work because people have charted known paths, and shown that if you follow those paths your loss probability is non-null but small.
I think this is a big part of it, humans have some kind of knack for working in dangerous domains successfully. I feel like an important question is: how far does this generalize? We can estimate the IQ gap between the dumbest person who successfully uses the internet (probably in the 80's) and the smartest malware author (got to be at least 150+). Is that the limit somehow, or does this knack extend across even more orders of magnitude?
If imagine a world where 100 IQ humans are using an internet that contains malware written by 1000 IQ AGI, do humans just "avoid the bad parts"? What goes wrong exactly, and where?
Attacks roll the dice in the hope that maybe they'll find someone with a known vulnerability to exploit, but presumably such exploits are extremely temporary.
Imagine your typical computer user (I remember being mortified when running anti-spyware tool on my middle-aged parents' computer for them). They aren't keeping things patched and up-to-date. What I find curious is how can it be the case that their computer is both: filthy with malware and they routinely do things like input sensitive credit-card/tax/etc information into said computer.
but if it turns out to be hopelessly insecure, I'd expect the shops to just decline using them.
My prediction is despite having glaring "security flaws" (prompt injection, etc) people will nonetheless use LLM agents for tons of stuff that common sense tells you shouldn't be doing in an insecure system.
I fully expect to live in a world where its BOTH true that: Pilny the Liberator can PWN any LLM agent in minutes AND people are using LLM agents to order 500 chocolate cupcakes on a daily basis.
I want to know WHAT IS IT that makes it so things can be both deeply flawed and basically fine simultaneously.
I can just meh my way out of thinking more than 30s on what the revelation might be, the same way Tralith does
I'm glad you found one of the characters sympathetic. Personally I feel strongly both ways, which is why I wrote the story the way that I did.
No, I think you can keep the data clean enough to avoid tells.
What data? Why not just train it on literally 0 data (muZero style)? You think it's going to derive the existence of the physical world from the Peano Axioms?
If you think without contact with reality, your wrongness is just going to become more self-consistent.
Please! I'm begging you! Give me some of this contact with reality! What is the evidence you have seen and I have not? Where?
I came and asked "the expert concensus seems to be that AGI doom is unlikely. This is the best argument I am aware of and it doesn't seem very strong. Are there any other arguments?"
Responses I have gotten are:
- I don't trust the experts, I trust my friends
- You need to read the sequences
- You should rephrase the argument in a way that I like
And 1 actual attempt at giving an answer (which unfortunately includes multiple assumptions I consider false or at least highly improbable)
If I seem contrarian, it's because I believe that the truth is best uncovered by stating one's beliefs and then critically examining the arguments. If you have arguments or disagree with me fine, but saying "you're not allowed to think about this, you just have to trust me and my friends" is not a satisfying answer.
"Can you explain in a few words why you believe what you believe"
"Please read this 500 pages of unrelated content before I will answer your question"
No.