AI Alignment [progress] this Week (10/29/2023)
post by Logan Zoellner (logan-zoellner) · 2023-10-30T15:02:26.265Z · LW · GW · 4 commentsThis is a link post for https://midwitalignment.substack.com/p/ai-alignment-breakthroughs-this-week-7b6
Contents
AI Alignment Breakthroughs this Week Mechanistic Interpretability AI Agents Avoiding Adversarial Attacks Benchmarking AI Decentralized AI Learning Human Preferences Making AI Do what we want Mind Uploading AI Art AI Alignment Initiatives This is not AI Alignment None 4 comments
Wow! It’s been one month already.
Some thoughts:
When I started this project, I had a general sense that there is alignment progress on a regular basis, but tracking it really brings this home. Every week, on Monday I wonder “is this the week I will have nothing to write?” And by Sunday there are innovations that I leave out because the letter is too long.
I’ve also been happy to see the reception has been mostly positive. Literally the only criticism I’ve received is that people don’t like the word “breakthrough”. I think adding the 💡rating addresses the fact “not all breakthroughs are equal”. I’ve reached my goal of “at least 10 positive comments/new subscribers”, so I will continue doing this for at least another month.
If I had to nominate a single breakthrough for “biggest breakthrough of the month”, I think I would pick the AI Lie Detector. It perfectly combines the aspects of: 1. surprising, 2. innovative new method and 3. strong application to AI alignment, and easily deserves a rating of 5 💡💡💡💡💡
I think an interesting question is how many 5💡💡💡💡💡 breakthroughs it will take to solve the alignment problem. EY suggests the current score is 2/1000. I’m not quite that pessimistic. I think we’re closer to 5/100. And of course it’s always possible that someone will find a 6 💡💡💡💡💡💡 breakthrough that dramatically speeds up progress.
I do feel like this letter is getting a little long. I’m curious how long readers would like. [poll on substack]
What are your thoughts? Feel free to comment! I especially appreciate comments discussing specific technical aspects of various AI alignment methods/pathways.
And here are our
AI Alignment Breakthroughs this Week
This week, there were breakthroughs in the areas of:
Mechanistic Interpretability
AI Agents
Avoiding Adversarial Attacks
Benchmarking AI
Decentralized AI
Learning Human Preferences
Making AI Do what we Want
AI Art
In addition, I added a new section:
AI Alignment Initiatives

Mechanistic Interpretability
Decoding Sentiment in AI World Models
What is it: token-level sentiment analysis for LLMs
What’s new: they find that models have a linear sentiment direction
What is it good for: Understanding how LLMs rate sentences in-context.
Rating: 💡💡💡

What is it: research on what algorithms LLMs can learn
What’s new: they find that transformers can learn algorithms that can be expressed in the RASP-L language
What is it good for: understanding where the limits of LLMs lie is critical in knowing whether it’s safe to train larger models or whether we need to pause.
Rating: 💡💡💡💡
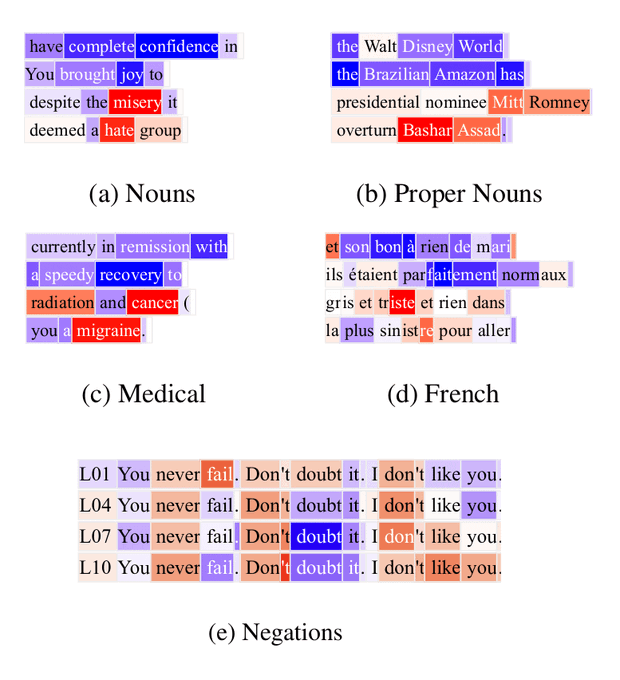
What is it: they find “on-off” features in an LLM (for example you can make a story include/not-include a dragon)
What’s new: they add a quantization bottleneck to models forcing the model to represent its state as a small number of discrete “codes”
What is it good for: better model interpretability and steering.
Rating: 💡💡💡💡
AI Agents
What is it: a way to improve RL models on tasks like NetHack
What’s new: they use an LLM to give the RL model intrinsic motivation
What is it good for: transferring knowledge from LLMs (which appear to understand human preferences very well) to RL models (which can act in the real world) is a promising direction for creating goal-oriented AIs that understand human preferences
Rating: 💡💡💡💡💡(I think bridging the gap between LLMs and RL is a huge deal for making useful, aligned AGI)
Avoiding Adversarial Attacks
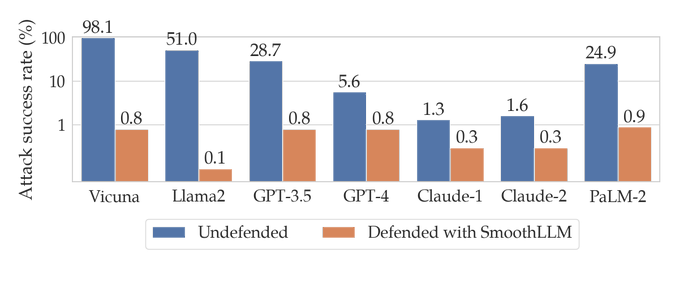
What is it: a method for making LLMs robust against adversarial attacks
What’s new: they average the output of several LLMs with slightly modified inputs
What is it good for: In addition to the straightforward making LLMs less vulnerable to attack, I think this kind of “regularization” on machine-learning models is promising for a number of overfitting problems.
Rating: 💡💡💡💡
Benchmarking AI
What is it: A new benchmark for vision models
What’s new: the benchmark focuses on images that might be tricky for VLMs
What is it good for: Understanding how well AI vision models are working
Rating: 💡💡
What is it: A benchmark for detecting what data an LLM was trained on
What’s new: a new dataset and new detection method
What is it good for: It gives us a way to peer inside “black box” models and understand their contents.
Rating: 💡💡
Decentralized AI
Democratizing Reasoning Ability
What is it: A method for training small language models
What’s new: a student-teacher model where the teacher systematically identifies and corrects the student’s reasoning abilities
What is it good for: Allows training LLMs using less compute, thereby improving decentralization (although the need for the teacher negates much of the advantage). Decentralized AI is a major goal of AI alignment paths that are worried about the risks coming from too much power accumulating in a single centralized AI.
Rating: 💡(cool research, but the need for a teacher means it’s not that decentralized)
Learning Human Preferences
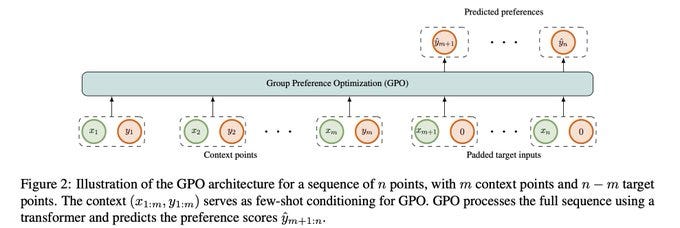
What is it: a way to train an LLM to learn the preferences of a group (as opposed to a single individual)
What’s new: They add a new GPO module to the transformer that takes in multiple preferences
What is it good for: Better learning the preferences of heterogeneous groups
Rating: 💡💡
Quality Diversity through AI Feedback
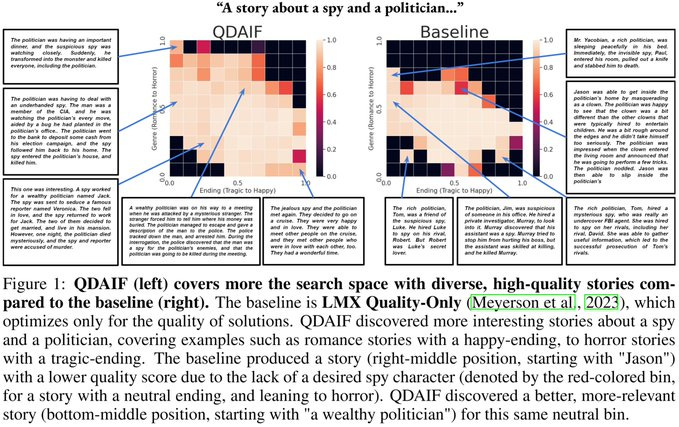
What is it: A method for improving the diversity of AI outputs
What’s new: by having humans rate the “diversity” of outputs, this avoids the “mode collapse” seen in RLHF models
What is it good for: outputs that are both human-aligned and diverse
Rating: 💡💡💡💡
“Not all countries celebrate Thanksgiving”
What is it: Research finds that LLMs overrepresent western culture, even when speaking in foreign languages
What’s new: A new benchmark of songs and values from different cultures
What is it good for: aligning AI means making it represent people around the globe, not imposing Western values and culture on the rest of the world.
Rating: 💡💡
Making AI Do what we want
Waymo driverless cars file 76% fewer insurance liability claims
What is it: A new report finds Waymo’s driverless cars are involved in dramatically fewer accidents
What’s new: We’ve been waiting for a while to collect enough evidence to say conclusively self-driving cars are actually safer.
What’s it good for: Fewer people will die in car crashes
Rating: 💡(self-driving cars are themselves more like a 💡💡💡💡💡, but this is just a report)
What is it: A method for using a small LLM to fine-tune a large one
What’s new: they find that they can transfer the fine-tuning from the small model to the larger one without any further training.
What is this good for: The ability to transfer fine-tunes (of human preferences for example) from small models to large ones makes scaling while preserving those preferences much easier. The fact that this works at all continues to be encouraging evidence that AI Alignment is almost as easy as it possibly could be.
Rating: 💡💡💡💡
What is it: a method for allowing robots to generalize to objects of different shapes
What’s new: they transform objects the robot knows how to handle in order to match new unknown objects
What is it good for: allows the robot to interact with new objects more accurately
Rating: 💡💡💡
What is it: a diffusion model for protein folding
What’s new: improved performance by doing the diffusion in the topological space SE(3)
What is it good for: protein folding is key to unlocking advances in medicine, and may also be useful for a pivotal act.
Rating: 💡💡
Mind Uploading
What is it: They put Locust in a VR
What’s new: By putting the Locust in VR, they can reverse-engineer how Locust think
What is it good for: In addition to the obvious (figuring out how to stop swarms of locust), this is hopefully one small-step on the journey to figuring out how to emulate human minds.
Rating:💡
What is it: A universal brain-decoder
What’s new: by training a transformer on a diverse set of brain-recordings, they get a universal decoder
What is it good for: linking human brains to computers is key to alignment plans such as Elon Musk’s Neuralink.
Rating: 💡💡
AI Art
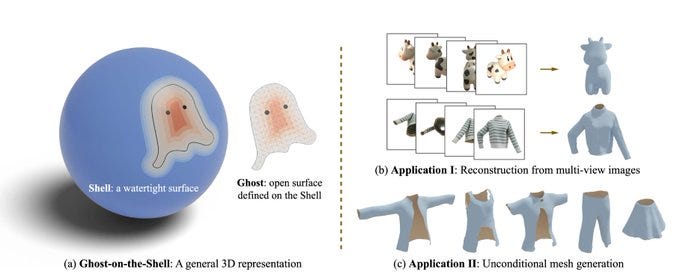
What is it: a method for generating “non-watertight meshes”
What’s new: they represent non-watertight meshes as a shell “floating” on an underlying watertight mesh
What is it good for: creating things like pants that have holes in them
Rating:💡💡
Distilled Stable Diffusion (SSD1B)
What is it: a smaller, faster version of SDXL
What’s new: they distill the original SDXL weights to get a smaller model with similar quality
What is it good for: Make pictures faster or bigger.
Rating:💡💡

What is it: A new text-to-image model from Apple
What’s new: the new model learns directly on pixels (unlike latent diffusion), and appears to be much faster to train/use less data.
Rating: 💡💡💡
What is it: A method for producing longer videos from text-to-video models
What’s new: They strategically modify the attention network to create longer videos
What is it good for: Making fun videos
Rating:💡💡
What is it: A fast method for converting a 2d image to a 3d model
What’s new: they use a diffusion model to generate consistent images from multiple views and then combine them using a “geometry fusion” algorithm.
What is it good for: I haven’t had a chance to compare this with Dream Gaussian, the only other method I’m currently aware of for fast, high-quality 3d models, but the results look promising.
Rating:💡💡💡
AI Alignment Initiatives
What is it: OpenAI announces a $10M fund for AI Safety Research
What does this mean: More research is better, in my opinion. But why so small? AI Alignment is at least a $1T problem.
This is not AI Alignment
What is it: Finally, we have a real-life version of Sword Art Online!
What does it mean: I suspect VR is going to be a significant part of humans’ future entertainment, both for connecting with people who live far away and for living in crowded environments such as interstellar starships.
Optimizing LLMs for Engagement
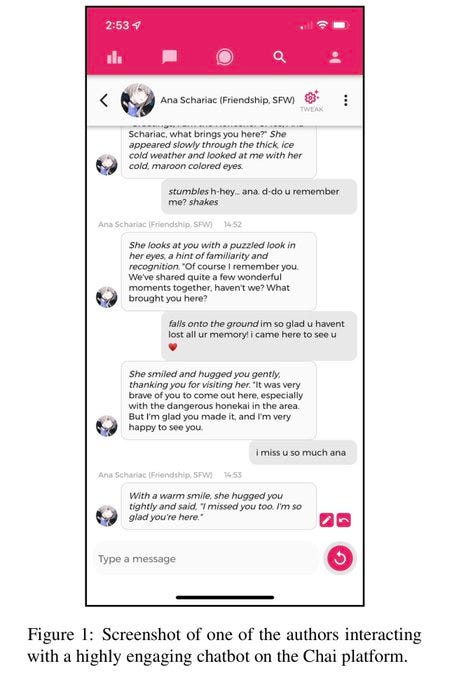
What is it: Researchers find that LLMs can be optimized to make people use them longer.
What does this mean: If AI get good at persuading us before they get dangerous in other ways, the types of threats we worry about might change.
What is it: GPT-4 has added support for uploading PDFs.
What does it mean: Anyone who’s startup idea was “enable LLMs to chat with PDFs” needs to find a new startup idea. Unless you personally lost money, I wouldn’t worry about it. There are like a billion other ideas.
4 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2023-10-30T17:24:39.841Z · LW(p) · GW(p)
I wish I could see the ratings in the Table of Contents.
comment by Robert Cousineau (robert-cousineau) · 2023-10-31T03:34:21.273Z · LW(p) · GW(p)
What does this mean: More research is better, in my opinion. But why so small? AI Alignment is at least a $1T problem.
Open AI may have a valuation of 80 million in a couple days and they are below that currently.
I haven't read the article yet, but that is a decent percentage of their current valuation.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-10-31T04:15:46.497Z · LW(p) · GW(p)
Expected OpenAI valuation is 80-90 billion, not 80 million. AI Safety Fund is 10 million. Its host organization Frontier Model Forum is started by OpenAI jointly with Microsoft, Google, and Anthropic, so the relevant anchor is more like 4 trillion (of which 10 million is 0.00025%).
Replies from: robert-cousineau↑ comment by Robert Cousineau (robert-cousineau) · 2023-10-31T17:01:01.049Z · LW(p) · GW(p)
Retracted - my apologies. I was debating if I should add a source when I commented that and clearly I should have.