An embedding decoder model, trained with a different objective on a different dataset, can decode another model's embeddings surprisingly accurately
post by Logan Zoellner (logan-zoellner) · 2023-09-03T11:34:20.226Z · LW · GW · 1 commentsContents
P.S. None 1 comment
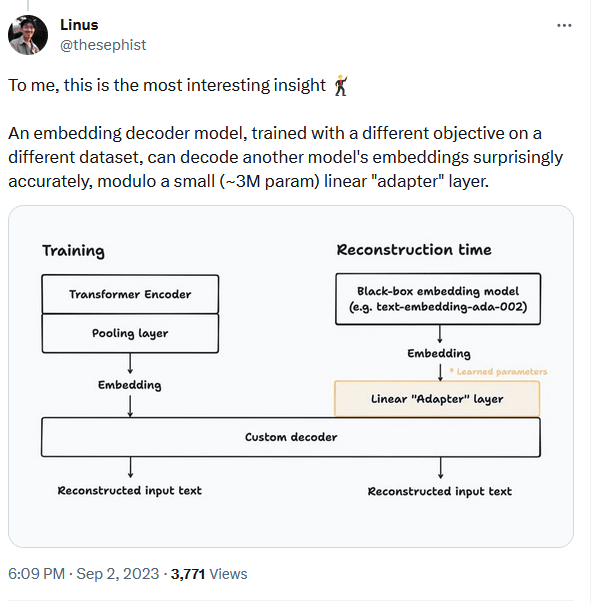
Seems pretty relevant to the Natural Categories [LW · GW] hypothesis.
P.S.
My current favorite story for "how we solve alignment" is
- Solve the natural categories hypothesis
- Add corrigibility [LW · GW]
- Combine these to build an AI that "does what I meant, not what I said"
- Distribute the code/a foundation model for such an AI as widely as possible so it becomes the default whenever anyone is building a AI
- Build some kind of "coalition of the willing" to make sure that human-compatible AI always has big margin of advantage in terms of computation
1 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-09-03T22:06:37.702Z · LW(p) · GW(p)
Could you explain a bit more how this is relevant to building a DWIM AI?