Natural Categories Update
post by Logan Zoellner (logan-zoellner) · 2022-10-10T15:19:11.107Z · LW · GW · 6 commentsContents
there is no known way to use the paradigm of loss functions, sensory inputs, and/or reward inputs, to optimize anything within a cognitive system to point at particular things within the environment
The Natural Category Hypothesis
Implications for Alignment
What updates should you take from this?
None
6 comments
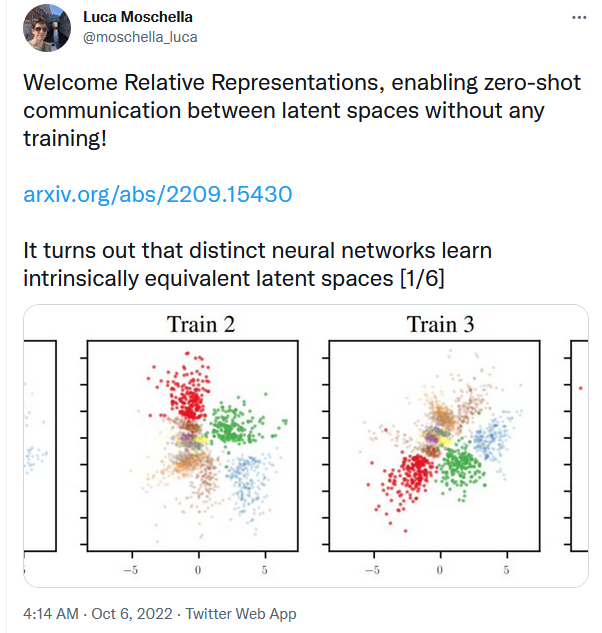
One concern in the AI-Alignment problem is that neural networks are "alien minds". Namely the representations that they learn of the world are too weird/different to allow effect communication of human goals and ideas.
For example, EY writes
there is no known way to use the paradigm of loss functions, sensory inputs, and/or reward inputs, to optimize anything within a cognitive system to point at particular things within the environment
Recent developments in neural networks have led me to think this is less likely to be a problem. Hence, I am more optimistic about AI alignment on the default path [LW · GW].
For example, this paper
One excellent project I would suggest anyone looking to "get a feel" for how natural categories work in contemporary machine learning is Textual Inversion. This allows you to "point to" a specific spot in the latent space of an image-to-text model using only a few images.
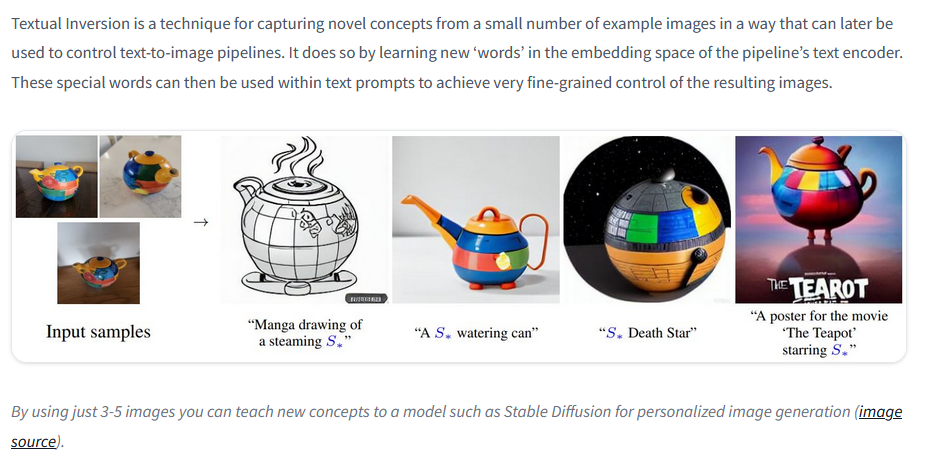
Importantly, textual inversion models can be trained on both objects and styles.
The Natural Category Hypothesis
Suppose that we assume an extremely strong version of the "natural categories" hypothesis is true:
Any concept that can be described to a human being already familiar with that concept using only a few words or pictures is a natural category. Such a concept can also be found in the embedding space of a trained neural network. Furthermore, it is possible to map a concept from one neural network onto another new network.
Implications for Alignment
What problems in AI-Alignment does this make easier?
- It means we can more easily explain concepts like "produce paperclips" or "don't murder" to AIs
- It means interetable AI [? · GW] is much easier/more tractable
- Bootstrapping FAI should be much easier since concepts can be transferred from a weaker AI to a more powerful one
In the most extreme case, if FAI is a natural category, then AI Alignment practically solves itself. (I personally doubt this is the case, since I think like "general intelligence", "friendly intelligence" is a nebulous concept with no single meaning)
What problems do natural categories not solve?
- Goodhearting. Even if it's easy to tell an AI "make paperclips", it doesn't follow that it's easy to tell it "and don't do anything stupid that I wouldn't approve of while you're at it"
- Race Conditions, coordination problems, unfriendly humans
- Hard Left Turns.
What updates should you take from this?
If you previously thought that natural categories/pointing to things in the world was a major problem for AI Alignment and this research comes as a surprise to you, I would suggest the following update:
Spend less of your effort worrying about specifying correct utility functions and more of it worrying about coordination problems.
6 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-10-10T18:37:08.632Z · LW(p) · GW(p)
One concern in the AI-Alignment problem is that neural networks are "alien minds". Namely the representations that they learn of the world are too weird/different to allow effect communication of human goals and ideas.
People reading the sequences (as in nearly everyone in AI-Alignment) tend to just absorb/accept this "alien minds" belief, but even back in 2007/2008 it was not the majority position amongst AI-futurists. The MIT AI-futurists (Moravec/Minsky/Kurzweil) believed that AI would be our "mind children", absorbing our culture and beliefs by default. Robin Hanson believed/believes AI will be literal brain uploads. EY was a bit on the fringe with this idea that AI would be unfathomable aliens.
If you are making this update only just now, consider why - trace the roots of these beliefs, and compare them to those who made the update long earlier.
I've spent a bit of time tracing this down to specific viewpoints on the brain and AI that are encoded in the sequences [LW(p) · GW(p)].
Replies from: joebiden↑ comment by joebiden · 2022-10-10T23:47:21.344Z · LW(p) · GW(p)
The MIT AI-futurists (Moravec/Minsky/Kurzweil) believed that AI would be our "mind children", absorbing our culture and beliefs by default
At this stage, this doesn’t seem obviously wrong,. If you think that the path from AGI will come via LLM extension rather than experiencing the world in an RL regime, it will only have our cultural output to make sense of the world.
comment by Charlie Steiner · 2022-10-10T23:59:57.629Z · LW(p) · GW(p)
Yeah, I think GPT2 was a big moment for this for a lot of people around here. Here was me in 2019 [LW · GW]. Still, I'd push back on some of the things you'd call "easy" - actually doing them (especially doing them in safety-critical situations where it's not okay to do the equivalent of spelling Teapot as "Tearot") still requires a lot of alignment research.
One pattern is that interpretability is easy on human-generated data, because of course something that learns the distribution of that data is usually incentivized to learn human-obvious ways of decomposing the data. Interpretability is going to be harder for something like MuZero that learns by self-play and exploration. A problem this presents us with is that interpretability, or just generally being able to point the AI in the right direction, is going to jump in difficulty precisely when the AI is pushing past the human level, because we're going be bottlenecked on superhuman-yet-still-human-comprehensible training data.
A recent example is that Minerva can do an outstanding job solving advanced high-school math problems. Why can't we do the same to solve AI alignment problems? Because Minerva was trained on 5+ billion tokens of math papers where people clearly and correctly solve problems. We don't have 5 billion tokens of people clearly and correctly solving AI alignment problems, so we can't get a language model to do that for us.
comment by Raemon · 2022-10-10T18:00:13.627Z · LW(p) · GW(p)
Brief meta note: this post motivated me to create a Natural Abstraction Hypothesis [? · GW] tag. People who talk about that a lot should consider either fleshing out the tag, and/or linking to it in places they previously just mentioned it.
(generally the LW team policy is to avoid tags that have less than 3 posts, and probably avoid tags if there aren't at least two different authors writing about it, but Natural Abstraction Hypothesis now clears that bar)
comment by tailcalled · 2022-10-10T16:50:11.686Z · LW(p) · GW(p)
I don't think you are interpreting Eliezer correctly. I think he is talking about the difficulty of specifying the actual objects in the physical world, distinguished such that e.g. a picture of the object wouldn't count.
comment by the gears to ascension (lahwran) · 2022-10-11T01:14:23.616Z · LW(p) · GW(p)
<unfinished comment posted as draft in shortform> [LW(p) · GW(p)]