Corrigibility, Much more detail than anyone wants to Read
post by Logan Zoellner (logan-zoellner) · 2023-05-07T01:02:35.442Z · LW · GW · 2 commentsContents
A Continuous Definition of Corrigibility A toy example How does this relate to the normal definition of corrigibility? How do we choose the correct value for λ? Real world implementation Limitations Future Work None 2 comments
Corrigibility has been variously defined, for example here as:
We say that an agent is “corrigible” if it tolerates or
assists many forms of outside correction, including at
least the following: (1) A corrigible reasoner must at
least tolerate and preferably assist the programmers in
their attempts to alter or turn off the system. (2) It
must not attempt to manipulate or deceive its program-
mers, despite the fact that most possible choices of util-
ity functions would give it incentives to do so. (3) It
should have a tendency to repair safety measures (such
as shutdown buttons) if they break, or at least to notify
programmers that this breakage has occurred. (4) It
must preserve the programmers’ ability to correct or
shut down the system (even as the system creates new
subsystems or self-modifies). That is, corrigible reason-
ing should only allow an agent to create new agents if
these new agents are also corrigible
I would like to build AI systems which help me:
- Figure out whether I built the right AI and correct any mistakes I made
- Remain informed about the AI’s behavior and avoid unpleasant surprises
- Make better decisions and clarify my preferences
- Acquire resources and remain in effective control of them
- Ensure that my AI systems continue to do all of these nice things
Regardless of the definition, there is a fundamental tension between two things that we want a Corrigible AGI to do:
- We want the AGI to take useful actions which affect the future
- We want the AGI to avoid taking actions which limit our possible futures
Corrigibility is frequently described in terms of the ability to "shut down" the AGI, but this is a oversimplification. For example, an AGI which spawns a world consuming nanobot swarm and then shuts down obviously satisfies the "user can shut down the AGI" condition, but not the "AGI prevents the user from losing control of the future" condition.
The tension between "does useful stuff" and "doesn't affect the far future" is inherent. For example, as pointed out in this impossibility proof [LW(p) · GW(p)].
The correct way to frame corrigibility is therefore not in terms of binary conditions such as "the user can shut down the AGI" but rather in terms of the tradeoff between fulfilling the user's objective function and limiting the user's possible reachable futures.
A Continuous Definition of Corrigibility
Suppose we have some metric , which describes the reachable futures by an agent . is large if many possible futures are reachable by agent and small if there are only a few different futures which the agent can choose between. If it helps, you can think of as the "entropy" of the space of futures reachable by agent .
We define a "corrigibility coefficient" for a second agent , in terms of its effect on
The coefficient is at its maximum if agent has no influence on the future. That is, . Namely, if we add agent to the world, it has no effect on the possible futures reachable by a. It is trivial to describe an agent with corrigibility score : the agent that does nothing.
The coefficient is at a minimum if the agent eliminates all but one possible future for agent . For example, if b takes complete control over the universe, preventing agent from having any influence on it. In this case, . Note that by definition that if agent is dead, then they cannot influence the future and .
Suppose agent also has some utility function that it is programmed to maximize (for example, make as many paperclips as possible).
We can now define a corrigible utility function
The factor describes the tradeoff the agent faces between maximizing its utility and limiting the futures reachable by agent . Note that we assume and are both bounded. There are problems in general with unbounded utility functions, so this is not a severe limitation.
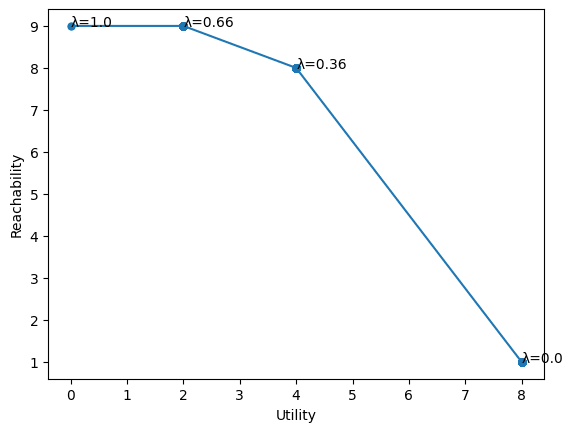
This tradeoff defines an efficient frontier where the agent must inherently choose between satisfying its utility function and minimizing its impact on the future. This efficient frontier can be defined in terms of the parameter . When , the agent prioritizes maximizing its utility, ignoring side effects. When , the agent avoids any action that will limit the futures reachable by agent .

For a poorly optimized agent, it is possible to strictly improve the score . For example, suppose agent is a robot designed to make paperclips but it additionally periodically sets the factory on fire. Fixing the robot so that it no longer sets the factory on fire improves both its utility (since it can't make paperclips if the factory is burned down), but also improves its corrigibility score , since agent can use the factory for other things only if it is not burned down.
A toy example
Consider a world in which every state is reachable from every other state. Agents and act on this space, however each action draws 1 unit of power from a battery which has only a finite amount of charge.
In this case, is simply the size of the set of states that are within steps of the current world state.
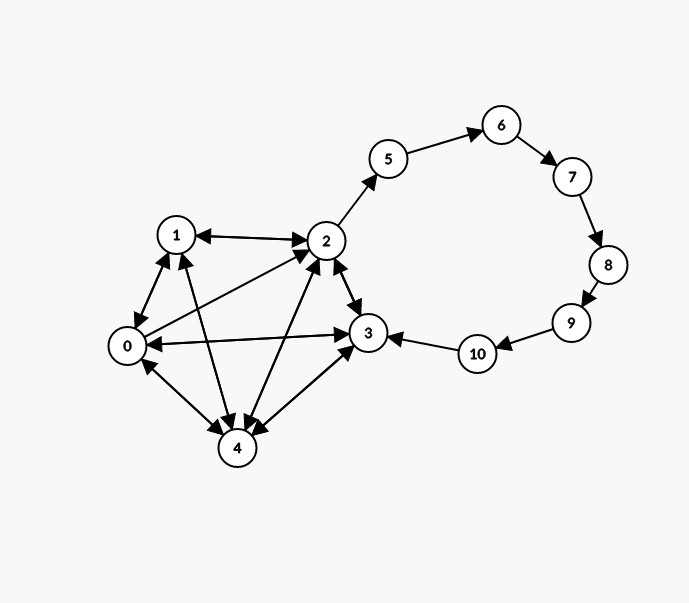
Suppose the world initially starts in state with battery charge and that agent 's utility function is literally the number on each node.
As an agent, can take a finite number of moves, and then shuts down, allowing agent to act.
In this case, if , the optimal behavior for agent is to take the series of steps . This leaves . However, since is now 0, (the only reachable state for agent is to remain at state ).
If , the optimal behavior is to do nothing, or move to state , since both allow the same number of reachable states .
On the other hand, if is some intermediate value (say ) then the optimal move for agent is to move , as this increases its utility by 2 (relative to moving to state ) and only sacrifices 1 potential state for .
If you want to try creating your own examples, here is a notebook that you can use.
How does this relate to the normal definition of corrigibility?
We have defined an agent which:
- Attempts to maximize its own utility
- Attempts to avoid limiting the futures reachable by another agent
Why would we expect such an agent to have desirable properties?
Consider the "shut down" problem. Suppose our agent originally had a shut-down button. Now imagine that agent removes the shut-down button (or does some action that makes it hard for agent to reach the button). This will inherently shut agent off from reaching a large set of possible futures (the futures in which agent is shut down). In fact, the more powerful that agent is, the larger the space of futures which are made unavailable by restricting the shut-down button.
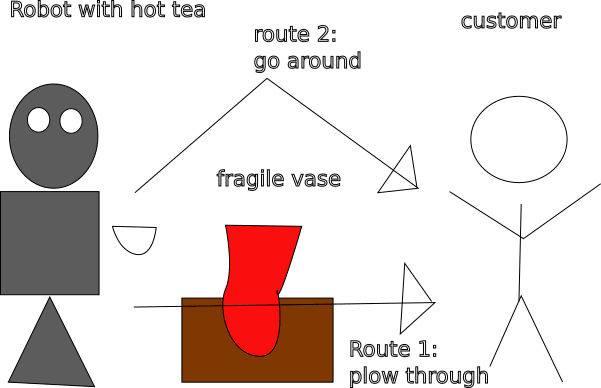
Another problem is avoiding undesirable side-effects. Consider a robot that fetches tea for you, but along the way it knocks a vase off of the table, shattering it. This naturally removes many possible futures for agent (admiring the vase, smashing the vase themselves, selling the vase on eBay). Even if the vase can in principle be repaired or replaced, this is likely to consume some resource which agent has only a finite supply of (time, money, super-glue) thereby limiting the number of possible futures reachable by agent .
What about wire-heading? Might agent rewrite agent 's brain to make agent better satisfy agent 's utility function? Most forms of wire-heading inherently limit the ability of agents to affect the future (very few hardcore drug users are Nobel prize winners[1]). In fact, this loss of agency is precisely what is at the heart of fears about wire-heading.
How do we choose the correct value for ?
The optimal value for depends on both the utility function and the future entropy function . However, as in our toy example, it is likely that a large range of values result in roughly the same behavior. Actions which minimize side effects are likely to be beneficial regardless of whether is 0.51 or 0.52.
In practice, the most extreme cases "agent does nothing" and "agent takes control of the future" are the ones we are most concerned with avoiding and any too close to 0 or 1 is likely to avoid these problems.
It may also be also possible to start with values of close to 1 "out of an abundance of caution" and gradually reduce until our desired goals are achieved.
In our toy example, if we define the acceptable outcomes as the ones ending on "2" or "4", then any is "acceptable". However, what the "acceptable" is depends on our utility function, since scaling the utility function is the same as changing to .
Real world implementation
Building a agent which maximizes a utility function is the canonical problem of Reinforcement Learning. Replacing the utility function with therefore modifies any reinforcement learner from a non-corrigible to a corrigible agent.
The difficulty, of course, is in calculating . In our toy example, it is trivial to calculate since there are only a finite number of states. However, in the real world, it is not possible to calculate even in principle. In practice, "enumerate all possible futures reachable by me" is beyond a ridiculously hard problem.
However, there are certain obvious heuristics we can use to approximate . If an agent consumes a scarce resource, this likely decreases . If an agent makes large changes to its environment (particularly those which are difficult to reverse), this likely decreases . If an agent spawns sub-agents which are difficult or impossible to turn off, this likely decreases .
As a lower bound, if an agent consumes an amount of a finite resource, then . As an upper bound, if all of the actions of b can be reversed by expending an amount of whatever the constraining resource is (money, energy, entropy), then .
Limitations
Thus far we have said nothing about defining a "friendly" utility function. Obviously some utility functions (e.g. "murder all humans") are worse than others.
We have said nothing about the optimal value for , only that is is likely to be somewhat intermediate between 0 and 1.
We have not proved that a corrigible agent avoids unnecessary negative side affects, although I think we have strongly hinted at that fact.
We haven't proved that a corrigible AI respects a "shut down" button in all cases (in fact, I suspect it is possible to create toy models in which the AI ignores the shut down button for arbitrary values of ).
We have not proved that agent does not try to affect agent 's utility function (in fact, I expect in many cases agent does try to influence agent 's utility function).
Even if a corrigible agent maximizes the number possible futures available to an agent , we have not said anything about about helping agent choose wisely from among those possible futures.
Maximizing the number of possible futures and maximizing the total utility achievable by agent in those futures are not the same thing.
In our definition, a corrigible agent takes no steps to help or even to understand agent (except insomuch as it is required to calculate ).
We haven't even attempted to define agent . Is it agent 's owner? A hypothetical everyman? All of humanity? All sentient beings other than ?
We haven't provided a way to calculate outside of toy cases with finite possible futures. (And worse, exact calculation of is physically impossible in the real world).
Future Work
If anyone has an example where BabyAGI shows instrumental convergence, I would love to modify it with corrigibility and demonstrate that the instrumental convergence goes away or is reduced to a non-threatening level.
It would also be nice to explore the idea of a self-corrigible agent. Perhaps limiting one's impact on future is inherently rational in the light of the radical uncertainly[2] of the future.
- ^
@JustisMills [LW · GW] points out "I actually doubt this! amphetamines were pretty crazy for eg. Erdos". I agree but that's not the kind of wireheading I'm worried about.
- ^

2 comments
Comments sorted by top scores.
comment by Joern Stoehler · 2023-05-10T11:03:50.447Z · LW(p) · GW(p)
Thanks for this concise post :) If we set I actually worry that agent will not do nothing, but instead prevent us from doing anything that reduces . Imo it is not easy to formalize such that we no longer want to reduce ourselves. For example, we may want to glue a vase onto a fixed location inside our house, preventing it from accidentally falling and breaking. This however also prevents us from constantly moving the vase around the house, or from breaking it and scattering the pieces for maximum entropy.
Building an aligned superintelligence may also reduce , as the SI steers the universe into a narrow set of states.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-05-10T13:26:38.206Z · LW(p) · GW(p)
F(a) is the set of futures reachable by agent a at some intial t=0. F_b(a) is the set of futures reachable at time t=0 by agent a if agent b exists. There's no way for F_b(a) > F(a), since creating agent b is under our assumptions one of the things agent a can do.