AI Alignment Breakthroughs this week (10/08/23)
post by Logan Zoellner (logan-zoellner) · 2023-10-08T23:30:54.924Z · LW · GW · 14 commentsContents
AI Alignment Breakthroughs this week (10/08/23) AI Lie Detector Interpreting neurons in superposition AI Alignment Breakthroughs this week AI Agents Mechanistic Interepretability AI Explainability Making AI Do what we Want Uplifting Mind Uploads Simulation AI Art Things that are not AI Alignment None 14 comments
[Cross-posted from https://midwitalignment.substack.com/p/ai-alignment-breakthroughs-this-week-a6e ]
Note: I change to a new (much longer) format based off of feedback. Please let me know if you find this helpful (or not)
AI Alignment Breakthroughs this week (10/08/23)
Hi,
Based off of some feedback, I’m going to try and change the format a little bit. For each entry I will try to give:
A brief description
Why this is a breakthrough
How it helps with alignment
I’m still going to try things somewhat short in order to save my (and hopefully your) time.
That being said, there there were two major breakthroughs this week that I want to highlight (both in Mechanistic Interpretability), AI Lie Detector and Interpreting Neuron Superposition.
AI Lie Detector

( https://twitter.com/OwainEvans_UK/status/1707451418339377361 )
There’s a good writeup of this here [LW · GW], but the most interesting thing is that it was trained to detect lies on one model (GPT-3.5), but actually works on a number of others models. The fact that it generalizes to other models gives us strong hope that it is the kind of thing we can robustly use when scaling up AI (as long as we are using similar architectures).
Obviously this might stop working if we switch to a radically different architecture. And it also might stop working if we apply too much optimization pressure (say we start using gradient descent to find plans the lie-detector says are truthful). Still, used appropriately, it seems like a valuable tool to for an aligner to use to double-check the output of an LLM.
Interpreting neurons in superposition
This one is a little harder to explain than the AI lie detector, but it’s arguably a much bigger breakthrough.
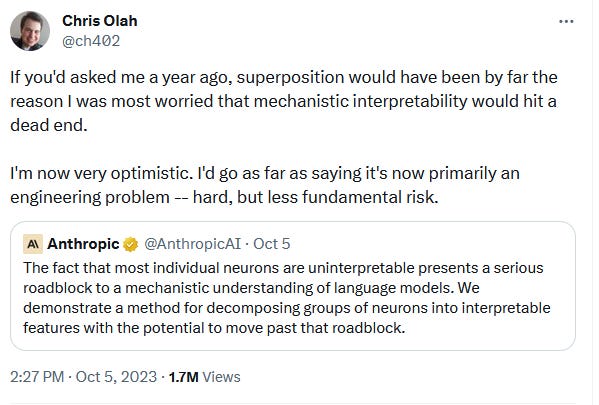
( https://twitter.com/ch402/status/1709998674087227859)
Anthropic claims to have a method that allows them to understand neurons in a neural network that are in superposition. In this case, there’s no spooky quantum weirdness going on, rather superposition simply means that a neuron can encode more than one concept. For example, if a neuron held two bits of state, one of them could mean “black vs white” and one of them could mean “cat vs dog”. In this case, the four possible values would be:
00: “black cat”
01: “white cat”
10: “black dog”
11: “white dog”
Obviously in a real neural network the superposition could be much more complicated than this, and finding a way to peel apart these layers was considered a major obstacle to be overcome.
AI Alignment Breakthroughs this week
Okay, without further ado, let’s get to our other breakthroughs.
This week, there were breakthroughs in the areas of:
AI Agents
Mechanistic Interepretability
AI Explainability
Making AI Do what we Want
Uplifting (NEW)
Mind Uploads
Simulation (NEW)
AI Art
And I’m also adding a section: “Things that are not AI Alignment” for news topics that are not alignment breakthroughs but are highly relevant to the topic of AI Alignment.

AI Agents
Microsoft AutoGen: ( https://twitter.com/AlphaSignalAI/status/1711074491399352807 )
what is it: AutoGen is a framework that allows LLM agents to chat with each other to solve your tasks.
What is the breakthrough: a new software package that allows you to work with multiple agents
What alignment projects is it relevant to: AI projects that use multiple agents either for scaling, or interpretability such as factored cognition [? · GW])
Socratic AI: ( https://twitter.com/IntuitMachine/status/1709212785878462879 )
What is it: simulating a group of agents discussing a problem
What is the breakthrough: by critiqing other agents and referencing external data sources, AI agents can get better results
What is this good for: Factored Congnition, Bueracracy of AIs
Mechanistic Interepretability
Neural Networks Extrapolate Predictably: ( https://twitter.com/katie_kang_/status/1709643099310555268)
What is it: New research on how neural networks handle OOD (out of domain) inputs
What is the breakthrough: It was discovered that neural networks tend to produce “average” predictions on OOD inputs
What is this good for: A big concern with neural networks is that they will do something ridiculous if you give then inputs that they aren’t trained on. For example, if you ask a neural network trained on MNIST what “digit” a picture of a car is. This research suggests neural networks give a “sensible” answer, essential the Bayesian equivalent of “I don’t know”.
AI Explainability
InstructScore: ( https://twitter.com/IntuitMachine/status/1711013179084390802 )
What is it: InstructScore can help diagnose and explain errors in the output of LLMs
What is the breakthrough: Instead of a numerical score, you can have a human readable explanation of what went wrong
What it it useful for: Pretty much all alignment projects depend on being able to accurately find and fix errors in the model’s output
ThoughtCloning: (https://twitter.com/IntuitMachine/status/1707045998269227408)
What is it: a method to enable machine learning models to think about the reasons behind human actions
What is the breakthrough: By reasoning about the explanations behind behaviors, AIs can better understand their instructions. Also because the thoughts are represented internally as text, they can be easily examined by the person training the AI
What is it good for: Getting the AI to imitate human reasoning is a key challenge of inner alignment [? · GW]. Having the thoughts easy to view/interpret should help protect against deceptive alignment.
Making AI Do what we Want
AgentInstruct: (https://twitter.com/IntuitMachine/status/1710611118920495429)
What is it: AgentInstruct breaks down a task into a series of high quality instructions for the LLM to follow
What is the breakthrough: Training an autonomous agent to guide the LLM
What is it good for: By creating a set of instructions for the LLM to follow, we get better control, since we can fine-tune on how the list of instructions is generated. We also get better interoperability, since we can review the list of instructions.
Learning Optimal Advantage from Preferences: ( https://twitter.com/SerenaLBooth/status/1709918912056267080 )
What is it: A new method for training AI models on human preferences
What is the breakthrough: This method minimizes a different score (regret) that better corresponds to human preferences than RLHF
What is it good for: Any alignment plan that involves training the AI to understand human preferences (which is most of them)
Rapid Network Adaptation: ( https://twitter.com/zamir_ar/status/1709338156233851096 )
What is it: a method that allows neural networks to adapt on the fly to new information
What is the breakthrough: By using a small side network, the AI can quickly adapt to new data
What is it good for: Adjusting to data that it hasn’t been trained on is a key requirement for having AI that can actually operate in the real-world in a reliable way.
Uplifting
CryAnalyzer: (https://twitter.com/ProductHunt/status/1710339232156561779)
What is it: An app that tells you why your baby is crying
What is the breakthrough: Literally never seen anything like this before
What is it good for: Besides the obvious (know why your baby is crying), this seems like a first step towards cross-species communication.
LearnBot: (https://twitter.com/Austen/status/1709234099884580955)
What is it: An AI tutor by BloomTech
What is the breakthrough: by giving every student a 1-on-1 mentor, we can dramatically improve education outcomes
What is it good for: Making humans smarter can only help towards solving the Alignment Problem
Mind Uploads
Decoding Speech from non-invasive brain Recordings: ( https://twitter.com/JeanRemiKing/status/1709957806030311798 )
What is it: A way to recreate human speech using only magneto-encephalography signals
What is the breakthrough: Allows us to read read human thoughts without a dangerous embedded chip (like Neuralink uses)
What is it good for: creating high bandwidth datalink between humans and AIs is on the critical path for alignment via human-machine hybrids.
Simulation
GAIA-1: ( https://twitter.com/Jamie_Shotton/status/1709137676102758760 )
What is it: a highly realistic generated world for training self-driving cars
What is the breakthrough: this is most realistic generated long-videos that I’ve seen
What is it good for: Besides the obvious (saving human lives from being lost in car crashes), creating highly realistic simulation environments is useful for many AI alignment techniques such as AI Boxing [? · GW].
Benchmarking
CogEval: ( https://twitter.com/IntuitMachine/status/1709148951687897190 )
What is it: A new benchmark for LLMs
What is the breakthrough: A science inspired protocol that lets us better evaluate how smart LLMs are
What is it good for: Knowing exactly how smart an AI is is a key need for many AI alignment projects. For example if we want to know whether it’s safe
to unbox an AI. Or determining the optimal timing for a strategic pause.
AI Art
Wurstchen V3: ( https://twitter.com/dome_271/status/1710957718565998600 )
What is it: A new version of the Wurstchen text-to-image model
What is the breakthrough: looks like a step-jump in image quality (think SDXL vs SD 1.5)
What is it good for: making pretty pictures

DiffPoseTalk: ( https://twitter.com/dreamingtulpa/status/1710925592030290031 )
What is it: DiffPoseTalk can generate 3d animated heads driven by speech
What is the breakthrough: 3d and significantly more emotion than previous methods (sadTalker, wav2lip)
What is it good for: making videos of talking heads
LLaVA-1.5: ( https://twitter.com/imhaotian/status/1710192818159763842 )
What is it: a new model for image question answering
What is the breakthrough: new state of the art for this type of model
What is it good for: You can use this to ask questions about a picture like “What is in this picture?” or “How many apples are there?”
FaceBuilder: ( https://twitter.com/dmvrg/status/1710120606753247304 )
What is it: AI model to create a 3d model of a head based off of a single photograph
What is the breakthrough: Seems much better than previous approaches I’ve seen.
What is it good for: making 3d avatars of people for animation/video games
Consistent 1-to-3: ( https://twitter.com/jerrykingpku/status/1710187832437014894 )
What is it: a new method for generating multiple images of a input image from different angles
What is the breakthrough: By requiring the inputs to be consistent in 3d space, quality is greatly improved
What is it good for: 2d-image to 3d-model generation
HotShotXL: https://twitter.com/PurzBeats/status/1709983075684208646
What is it: A new model for text-to-video
What is the breakthrough: applies a similar method as AnimateDiff to SDXL producing much higher quality videos
What is it good for: producing funny GIFs
4-bit SDXL: https://twitter.com/xiuyu_l/status/1708911683698405684
What is it: quantize SDXL to use 4 bits (half as much memory)
What is the breakthrough: previously quantization worked great for LLMs but poorly on image models
What is it good for: use less memory (and maybe go faster?) when generating images
MVDream: ( https://twitter.com/YangZuoshi/status/1697511835547939009 )
What is it: a new text-to-3d/image-to-3d method
What is the breakthrough: looks like a new state of the art in terms of quality
What is it good for: making cool 3d models
Things that are not AI Alignment
Deepfake scams come for Mr Beast: (https://twitter.com/MrBeast/status/1709046466629554577 )
What is it: New deepfake scam campaign claiming Mr Beast will give you an iPhone
What does this mean: Very soon, we are going to have to come to a reckoning with completely realistic deepfake voice/video. My preferred solution is some kind of blockchain-like-network where people can attest that videos/images/audio was really generated by them. My least favorite solution is banning all AI models capable of producing deepfakes, since this is both authoritarian and impossible.
Teacher Falsely accuses Student of AI Plagerism: ( https://twitter.com/rustykitty_/status/1709316764868153537 )
What is it: Teachers are using a “was this written by AI” website to review student papers. Needless to say, it doesn’t work.
What does this mean: Education is going to have to change to adapt to the existence of GPT-4. But this is not the way. I suggest more one-on-one mentoring, more “open book” tests, and more in-class application of knowledge.
14 comments
Comments sorted by top scores.
comment by Alex_Altair · 2023-10-11T00:07:40.046Z · LW(p) · GW(p)
FWIW I don't think it's honest to title this "breakthroughs". It's almost the opposite, a list of incremental progress.
Replies from: sharmake-farah, logan-zoellner↑ comment by Noosphere89 (sharmake-farah) · 2023-10-11T14:51:48.788Z · LW(p) · GW(p)
This. I think incremental progress is important to report on, and I do buy there have been breakthroughs in alignment, but most of these results are incremental progress at best, not breakthroughs, and I wish there was less hype in this newsletter.
↑ comment by Logan Zoellner (logan-zoellner) · 2023-10-11T13:26:41.986Z · LW(p) · GW(p)
I'm not interested in arguing about the definitions of words [LW · GW].
When I use the phase "alignment breakthrough" in my title I mean:
- someone invented a new technique
- Which allowed them to get a new result better than was previously possible
- and this result is plausibly applicable to AI alignment
↑ comment by Amalthea (nikolas-kuhn) · 2023-10-11T13:37:37.420Z · LW(p) · GW(p)
I don't think that essay does what you want. It seems to be about "you can't always capture the meaning of something by writing down defining a simple precise definition", while the complaint is that you're not using the word according to its widely agreed-upon meaning. If you don't want to keep explaining what you specifically mean by "breakthrough" in your title each time, you could simply change to a more descriptive word.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-10-12T12:48:46.267Z · LW(p) · GW(p)
A quick google search should show you that the way I am using the word "breakthrough" is in accordance with the common parlance.
comment by trevor (TrevorWiesinger) · 2023-10-09T06:13:02.168Z · LW(p) · GW(p)
How long do we normally have to wait to see if CryAnalyzer and Decoding Speech from Brain Recordings will replicate? Both of these have rather serious geopolitical implications.
Does human reasoning research automation like ThoughtCloning tend to get openly censored/refused or uncharacteristically weak responses on closed source systems like GPT4? That also has geopolitical implications I.e. indicates that providers at some point became wary of actors trying to use their systems for those kinds of applications (which further indicates that such actors already exist, rather than might exist in the future).
Replies from: amayhew@uwo.ca↑ comment by amayhew (amayhew@uwo.ca) · 2023-10-10T02:09:59.649Z · LW(p) · GW(p)
The reviews on CryAnalyzer at least are pretty bad. I think we may still have a long way to go
comment by Viliam · 2023-10-09T13:48:27.742Z · LW(p) · GW(p)
New deepfake scam campaign claiming Mr Beast will give you an iPhone
I am just watching a YouTube ad where robotically speaking Stephen Colbert interviews robotically speaking Elon Musk about his latest invention, which is a quantum artificial intelligence investing on a financial market. You just have to click on the website, fill out a contact form, and an employee of the robotic Elon Musk will contact you later to tell you how you can most safely invest your money for a guaranteed profit.
I reported the ad. There is no "deepfake" category, but there is "impersonation", so I guess that will suffice.
comment by Adele Lopez (adele-lopez-1) · 2023-10-09T02:55:57.696Z · LW(p) · GW(p)
What is the breakthrough: It was discovered that neural networks tend to produce “average” predictions on OOD inputs
This seems like somewhat good news for Goodhart's curse being easier to solve! (Mostly I'm thinking about how much worse it would be if this wasn't the case).
Replies from: TurnTrout, maxime-riche↑ comment by TurnTrout · 2023-10-09T05:46:45.209Z · LW(p) · GW(p)
Average predictions OOD is also evidence against goal-directed inner optimizers, in some sense; though it depends what counts as "OOD."
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-10-12T14:23:48.610Z · LW(p) · GW(p)
Yep, that's the big one. It suggests that NNs aren't doing anything very weird if we subject them to OOD inputs, which is evidence against the production of inner optimization, or at least not inner misaligned optimizers.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-10-16T18:51:31.177Z · LW(p) · GW(p)
I actually now think the OOD paper is pretty weak evidence about inner optimizers.
I think the OOD paper tells you what happens as the low-level and mid-level features stop reliably/coherently firing because you're adding in so much noise. Like, if my mental state got increasingly noised across all modalities, I think I'd probably adopt some constant policy too, because none of my coherent circuits/shards would be properly interfacing with the other parts of my brain. But I dont think that tells you much about alignment-relevant OOD.
↑ comment by Maxime Riché (maxime-riche) · 2023-10-09T09:31:35.113Z · LW(p) · GW(p)
I wonder if the result is dependent on the type of OOD.
If you are OOD by having less extractable information, then the results are intuitive.
If you are OOD by having extreme extractable information or misleading information, then the results are unexpected.
Oh, I just read their Appendix A: "Instances Where “Reversion to the OCS” Does Not Hold"
Outputting the average prediction is indeed not the only behavior OOD. It seems that there are different types of OOD regimes.