Most arguments for AI Doom are either bad or weak
post by Logan Zoellner (logan-zoellner) · 2024-10-12T11:57:50.840Z · LW · GW · 97 commentsContents
97 comments
This is not going to be a popular post here, but I wanted to articulate precisely why I have a very low pDoom (2-20%) compared to most people on LessWrong.
Every argument I am aware of for pDoom fits into one of two categories: bad or weak.
Bad arguments make a long list of claims, most of which have no evidence and some of which are obviously wrong. Examples include A List of Lethalities [LW · GW], which is almost the canonical example. There is no attempt to organize the list into a single logical argument, and it is built on many assumptions (analogies to human evolution, assumption of fast takeoff, ai opaqueness) which are in conflict with reality.
Weak arguments go like this: "AGI will be powerful. Powerful systems can do unpredictable things. Therefore AGI could doom us all." Examples of these arguments include each of the arguments on this list [LW · GW].
So the line of reasoning I follow is something like this;
- I start with a very low prior of AGI doom (for the purpose of this discussion, assume I defer to consensus).
- I then completely ignore the bad arguments,
- finally, I give 1 bit of evidence collectively for the weak arguments (I don't consider them independent, most are just rephrasing the example argument)
So even if I assume no one betting on Manifold has ever heard of the argument "AGI might be bad actually", I only get from 13% -> 30% with that additional bit of evidence.
In the comments: if you wish to convince me, please propose arguments that are neither bad nor weak. Please do not argue that I am using the wrong base-rate or that the examples that I have already given are neither bad nor weak.
EDIT:
There seems to be a lot of confusion about this, so I thought I should clarify what I mean by a "strong good argument"
Suppose you have a strongly-held opinion, and that opinion disagrees from the expert-consensus (in this case, the Manifold market or expert surveys showing that most AI experts predict a low probability of AGI killing us all). If you want to convince me to share your beliefs, you should have a strong good argument for why I should change my beliefs.
A strong good argument has the following properties:
- it is logically simple (can be stated in a sentence or two)
- This is important, because the longer your argument, the more details that have to be true, and the more likely that you have made a mistake. Outside the realm of pure-mathematics, it is rare for an argument that chains together multiple "therefore"s to not get swamped by the fact that
- Each of the claims in the argument is either self-evidently true, or backed by evidence.
- example of a claim that is self-evidently true would be: if AGI exists, it will be made out of atoms
- example of a claim that is not self-evidently true: if AGI exists, it will not share any human values
To give an example completely unrelated to AGI. The expert consensus is that nuclear power is more expensive to build and maintain than solar power.
However, I believe this consensus is wrong because: The cost of nuclear power is artificially inflated by the regulation which mandates nuclear be "as safe as possible", thereby guaranteeing that nuclear power can never be cheaper than other forms of power (which do not face similar mandates).
Notice that even if you disagree with my conclusion, we can now have a discussion about evidence. You might ask, for example "what fraction of nuclear power's cost is driven by regulation?" "Are there any countries that have built nuclear power for less than the prevailing cost in the USA?" "What is an acceptable level of safety for nuclear power plants?"
I should also probably clarify why I consider "long lists" bad arguments (and ignore them completely).
If you have 1 argument, it's easy for me to examine the argument on it's merits so I can decide whether it's valid/backed by evidence/etc.
If you have 100 arguments, the easiest thing for me to do is to ignore them completely and come up with 100 arguments for the opposite point. Humans are incredibly prone to cherry-picking and only noticing arguments that support their point of view. I have absolutely no reason to believe that you the reader have somehow avoided all this and done a proper average over all possible arguments. The correct way to do such an average is to survey a large number of experts or use a prediction market, not whatever method you have settled upon.
97 comments
Comments sorted by top scores.
comment by Seth Herd · 2024-10-13T00:25:59.156Z · LW(p) · GW(p)
Here's my serious claim after giving this an awful lot of thought and study: you are correct about the arguments for doom being either incomplete or bad.
But the arguments for survival are equally incomplete and bad.
It's like arguing about whether humans would survive driving a speedboat at ninety miles an hour before anyone's invented the internal combustion engine. There are some decent arguments that they wouldn't, and some decent argument that their engineering would be up to the challenge. People could've debated endlessly.
The correct answer is that humans often survive driving speedboats at ninety miles and hour and sometimes die doing it. It depends on the quality of engineering and the wisdom of the pilot (and how their motivations are shaped by competition;).
So, to make progress on actual good arguments, you have to talk about specifics: what type of AGI we'll create, who will be in charge of creating it and perhaps directing it, and exactly what strategies we'll use to ensure it does what we want and that humanity survives. (That is what my work focuses on.)
In the absence of doing detailed reasoning about specific scenarios, you're basically taking a guess. It's no wonder people have wildly varying p(doom) estimates from that method.
If it's a guess, the base rate is key. You've said you refuse to change it, but to understand the issue we have to address it. That's the primary difference between your p(doom) and mine. I've spent a ton of time trying to address specific scenarios, but my base rate is still the dominant factor in my total, because we don't have enough information yet and havent' modeled specific scenarios well enough yet.
I think we'll probably survive a decade after the advent of AGI on something like your odds, but I can't see farther than that, so my long-range p(doom) goes to around .5 with my base rate. (I'm counting permanent dystopias as doom). (incidentally, Paul Christiano's actual p(doom) is similar - modest in the near term after AGI but rising to 40% as things progress from there).
It's tough to arrive at a base rate for something that's never happened before. There is no reference class, which is why debates about the proper reference class are endless. No species has ever designed and created a new entity smarter than itself. So I put it around .5 for sheer lack of evidence either way. I think people using lower base rates are succumbing to believing what feels easy and good- motivated reasoning. There simply are no relevant observations.
Replies from: tailcalled, logan-zoellner↑ comment by tailcalled · 2024-10-13T08:38:09.744Z · LW(p) · GW(p)
A lot of speedboats are built for leisure. You wouldn't want to build such speedboats if they were too deadly. People who get killed by speedboats aren't going to be recommending them to others. The government is going to attack speedboat companies that don't try to reduce speedboat danger. Speedboats tend to be a net expense rather than a convenience or necessity, so there's a natural repulsive force away from using them.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-10-13T16:27:21.482Z · LW(p) · GW(p)
I didn't mean to imply that speedboats are a perfect analogy. They're not. Maybe not even a good one.
My claim was that details matter; we can't get good p(doom) estimates without considering specific scenarios, including all of the details you mention about the motivations and regulations around use, as well as the engineering approaches, and more.
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T10:45:15.585Z · LW(p) · GW(p)
If it's a guess, the base rate is key.
If your base rate is strongly different from the expert consensus there should be some explainable reason for the difference.
If the reason for the difference is "I thought a lot about it, but I can't explain the details to you", I will happily add yours to the list of "bad arguments".
A good argument should be:
- simple
- backed up by facts that are either self-evidently true or empirically observable
If you give me a list of "100 things make me nervous", I can just as easily give you "a list of 100 things that make me optimistic".
Replies from: nikolas-kuhn, tup99↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T18:35:41.925Z · LW(p) · GW(p)
There's a lot of problems with linking to manifold and calling it "the expert consensus"!
- It's not the right source. The survey you linked elsewhere would be better.
- Even for the survey, it's unclear whether these are the "right" experts for the question. This at least needs clarification.
- It's not a consensus, this is a median or mean of a pretty wide distribution.
I wouldn't belabor it, but you're putting quite a lot of weight on this one point.
↑ comment by tup99 · 2024-10-13T18:10:06.572Z · LW(p) · GW(p)
This was the most compelling part of their post for me:
"You are correct about the arguments for doom being either incomplete or bad. But the arguments for survival are equally incomplete and bad."
And you really don't seem to have taken it to heart. You're demanding that doomers provide you with a good argument. Well, I demand that you provide me with a good argument!
More seriously: we need to weigh the doom-evidence and the non-doom-evidence against each other. But you believe that we need to look at the doom-evidence and if it's not very good, then p(doom) should be low. But that's wrong -- you don't acknowledge that the non-doom-evidence is also not very good. IOW there's a ton of uncertainty.
If you give me a list of "100 things make me nervous", I can just as easily give you "a list of 100 things that make me optimistic".
Then it would be a lot more logical for your p(doom) to be 0.5 rather than 0.02-0.2!
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T19:31:14.968Z · LW(p) · GW(p)
Feels like this attitude would lead you to neurotically obsessing over tons of things. You ought to have something that strongly distinguishes AI from other concepts before you start worrying about it, considering how infeasible it is to worry about everything conceivable.
Replies from: tup99↑ comment by tup99 · 2024-10-13T19:52:15.244Z · LW(p) · GW(p)
Well of course there is something different: The p(doom), as based on the opinions of a lot of people who I consider to be smart. That strongly distinguishes it from just about every other concept.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T19:56:59.190Z · LW(p) · GW(p)
"People I consider very smart say this is dangerous" seems so cursed, especially in response to people questioning whether it is dangerous. Would be better for you to not participate in the discussion and just leave it to the people who have an actual independently informed opinion.
Replies from: tup99↑ comment by tup99 · 2024-10-17T20:42:40.106Z · LW(p) · GW(p)
How many things could reasonably have a p(doom) > 0.01? Not very many. Therefore your worry about me "neurotically obsessing over tons of things" is unfounded. I promise I won't :) If my post causes you to think that, then I apologize, I have misspoken my argument.
Replies from: M. Y. Zuo, nc↑ comment by M. Y. Zuo · 2024-10-18T08:59:18.709Z · LW(p) · GW(p)
What is the actual argument that there’s ‘not very many’? (Or why do you believe such an argument made somewhere else)
There’s hundreds of asteroids and comets alone that have some probability of hitting the Earth in the next thousand years, how can anyone possibly evaluate ‘p(doom)’ for any of this, let alone every other possible catastrophe?
↑ comment by cdt (nc) · 2024-10-17T20:49:33.223Z · LW(p) · GW(p)
I was reading the UK National Risk Register earlier today and thinking about this. Notable to me that the top-level disaster severity has a very low cap of ~thousands of casualties, or billions of economic loss. Although it does note in the register that AI is a chronic risk that is being managed under a new framework (that I can't find precedent for).
comment by RobertM (T3t) · 2024-10-14T05:37:36.117Z · LW(p) · GW(p)
A strong good argument has the following properties:
- it is logically simple (can be stated in a sentence or two)
- This is important, because the longer your argument, the more details that have to be true, and the more likely that you have made a mistake. Outside the realm of pure-mathematics, it is rare for an argument that chains together multiple "therefore"s to not get swamped by the fact that
No, this is obviously wrong.
- Argument length is substantially a function of shared premises. I would need many more sentences to convey a novel argument about AI x-risk to someone who had never thought about the subject before, than to someone who has spent a lot of time in the field, because in all likelihood I would first need to communicate and justify many of the foundational concepts that we take for granted.
- Note that even here, on LessWrong, this kind of detailed argumentation is necessary to ward off misunderstandings.
- Argument strength is not an inverse function with respect to argument length, because not every additional "piece" of an argument is a logical conjunction which, if false, renders the entire argument false. Many details in any specific argument are narrowing down which argument the speaker is making, but are not themselves load-bearing (& conjunctive) claims that all have to be true for the argument to be valid. (These are often necessary; see #1.)
Anyways, the trivial argument that AI doom is likely (given that you already believe we're likely to develop ASI in the next few decades, and that it will be capable of scientific R&D that sounds like sci-fi today) is that it's not going to have values that are friendly to humans, because we don't know how to build AI systems in the current paradigm with any particular set of values at all, and the people pushing frontier AI capabilities mostly don't think this is a real problem that needs to be figured out[1]. This is self-evidently true, but you (and many others) disagree. What now?
- ^
A moderately uncharitable compression of a more detailed disagreement, which wouldn't fit into one sentence.
↑ comment by TAG · 2024-10-16T21:16:01.597Z · LW(p) · GW(p)
Argument length is substantially a function of shared premises
A stated argument could have a short length if it's communicated between two individuals who have common knowledge of each others premises..as opposed to the "Platonic" form, where every load bearing component is made explicit, and there is noting extraneous.
But that's a communication issue....not a truth issue. A conjunctive argument doesn't become likelier because you don't state some of the premises. The length of the stated argument has little to do with its likelihood.
How true an argument is, how easily it persuades another person, how easy it is to understand have little to do with each other.
The likelihood of an ideal argument depends in the likelihood of it's load bearing premises...both how many there are, and their individual likelihoods.
Public communication, where you have no foreknowledge of shared premises, needs to keep the actual form closer to the Platonic form.
Public communication is obviously the most important kind when it comes to avoiding AI doom.
This is important, because the longer your argument, the more details that have to be true, and the more likely that you have made a mistake
Correct. The fact that you don't have to explicitly communicate every step of an argument to a known recipient, doesnt stop the overall probability of a conjunctive argument from depending on the number, and individual likelihood, of the steps of the Platonic version, where everything necessary is stated and nothing unnecessary is stated
Argument strength is not an inverse function with respect to argument length, because not every additional “piece” of an argument is a logical conjunction which, if false, renders the entire argument false.
Correct. Stated arguments can contain elements that are explanatory, or otherwise redundant for an ideal recipient.
Nonetheless, there is a Platonic form, that does not contain redundant elements or unstated, load bearing steps.
Anyways, the trivial argument that AI doom is likely [...]s that it’s not going to have values that are friendly to humans
That's not trivial. There's no proof that there is such a coherent entity as "human values", there is no proof that AIs will be value-driven agents, etc, etc. You skipped over 99% of the Platonic argument there.
This is a classic example of failing to communicate with people outside the bubble. Your assumptions about values and agency just aren't shared by the general public or political leaders.
PS .
A fact cannot be self evidently true if many people disagree with it.
That's self evidently true. So why does it have five disagreement downvotes ?
Replies from: T3t↑ comment by RobertM (T3t) · 2024-10-17T00:31:42.856Z · LW(p) · GW(p)
But that's a communication issue....not a truth issue.
Yes, and Logan is claiming that arguments which cannot be communicated to him in no more than two sentences suffer from a conjunctive complexity burden that renders them "weak".
That's not trivial. There's no proof that there is such a coherent entity as "human values", there is no proof that AIs will be value-driven agents, etc, etc. You skipped over 99% of the Platonic argument there.
Many possible objections here, but of course spelling everything out would violate Logan's request for a short argument. Needless to say, that request does not have anything to do with effectively tracking reality, where there is no "platonic" argument for any non-trivial claim describable in only two sentence, and yet things continue to be true in the world anyways, so reductio ad absurdum: there are no valid or useful arguments which can be made for any interesting claims. Let's all go home now!
Replies from: TAG↑ comment by TAG · 2024-10-28T23:48:46.613Z · LW(p) · GW(p)
Yes, and Logan is claiming that arguments which cannot be communicated to him in no more than two sentences suffer from a conjunctive complexity burden that renders them “weak”.
@Logan Zoellner being wrong doesn't make anyone else right. If the actual argument is conjunctive and complex, then all the component claims need to be high probability. That is not the case. So Logan is right for not quite the right reasons -- it's not length alone.
That’s not trivial. There’s no proof that there is such a coherent entity as “human values”, there is no proof that AIs will be value-driven agents, etc, etc. You skipped over 99% of the Platonic argument there.
Many possible objections here, but of course spelling everything out would violate Logan’s request for a short argument.
And it wouldn't help anyway. I have read the Sequences , and there is nothing resembling a proof , or even strong argument, for the claim about coherent human values. Ditto the standard claims about utility functions, agency , etc. Reading the sequence would allow him to understand the LessWrong collective, but should not persuade him.
Whereas the same amount of time could, more reasonably, be spent learning how AI actually works.
Needless to say, that request does not have anything to do with effectively tracking reality,
Tracking reality is a thing you have to put effort into, not something you get for free, by labelling yourself a rationalist.
The original Sequences have did not track reality , because they are not evidence based -- they are not derived from academic study or industry experience. Yudkowsky is proud that they are "derived from the empty string" -- his way of saying that they are armchair guesswork.
His armchair guesses are based on Bayes,von Neumann rationality, utility maximisation, brute force search etc, which isnt the only way to think about AI, or particularly relevant to real world AI. But it does explain many doom arguments, since they are based on the same model -- the kinds of argument that immediately start talking about values and agency. But of course that's a problem in itself. The short doomer arguments use concepts from the Bayes/VonNeumann era in a "sleepwalking" way, out of sheer habit, given that the basis is doubtful. Current examples of AIs aren't agents, and it's doubtful whether they have values. It's not irrational to base your thinking on real world examples, rather than speculation.
In addition , they haven't been updated in the light of new developments , something else you have to do to track reality. tracking reality has a cost -- you have to change your mind and admit you are wrong. If you don't experience the discomfort of doing that, you are not tracking reality.
People other than Yudkowsky have written about AI safety from the perspective of how real world AIs work, but adding that injust makes the overall mass of information larger and more confusing.
where there is no “platonic” argument for any non-trivial claim describable in only two sentence, and yet things continue to be true
You are confusing truth and justification.
You need to say something about motivation.
There are dozens of independent ways in which AI can cause a mass extinction event at different stages of its existence.
While each may have around a 10 percent chance a priori, cumulatively there is more than a 99 percent chance that at least one bad thing will happen.
Same problem. Yes, there's lots of means. That's not the weak spot. The weak spot is motivation.
Same problem. You've done nothing to fill the gap between "ASI will happen" and "ASI will kill us all".
Replies from: avturchin↑ comment by avturchin · 2024-10-29T10:43:51.851Z · LW(p) · GW(p)
In general, I agree with you: we can't prove with certainty that AI will kill everyone. We can only establish a significant probability (which we also can't measure precisely).
My point is that some AI catastrophe scenarios don't require AI motivation. For example:
- A human could use narrow AI to develop a biological virus
- An Earth-scale singleton AI could suffer from a catastrophic error
- An AI arms race could lead to a world war
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-14T14:02:01.793Z · LW(p) · GW(p)
This is self-evidently true, but you (and many others) disagree
A fact cannot be self evidently true if many people disagree with it.
comment by George Ingebretsen (george-ingebretsen) · 2024-10-13T17:40:23.853Z · LW(p) · GW(p)
To be clear, if you put doom at 2-20%, you're still quite worried then? Like, wishing humanity was dedicating more resources towards ensuring AI goes well, trying to make the world better positioned to handle this situation, and saddened by the fact that most people don't see it as an issue?
comment by Dagon · 2024-10-12T17:05:55.535Z · LW(p) · GW(p)
Over what timeframe? 2-20% seems a reasonable range to me, and I would not call it "very low". I'm not sure there is a true consensus, even around the LW frequent posters, but maybe I'm wrong and it is very low in some circles, though it's not in the group I watch most. It seems plenty high to motivate behaviors or actions you see as influencing it.
Replies from: tup99, logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-12T22:28:43.163Z · LW(p) · GW(p)
My 90/10 timeframe for when AGI gets built is 3 years-15 years. And most of my probability mass for PDoom is on the shorter end of that. If we have the current near-human-ish level AI around for another decade, I assume we'll figure out how to control it.
my p(Doom|AGI after 2040) is <1%
comment by Mitchell_Porter · 2024-10-12T15:53:43.671Z · LW(p) · GW(p)
Doom aside, do you expect AI to be smarter than humans? If so, do you nonetheless expect humans to still control the world?
Replies from: tailcalled, logan-zoellner↑ comment by tailcalled · 2024-10-12T17:51:04.456Z · LW(p) · GW(p)
Do humans control the world right now?
Replies from: DaemonicSigil↑ comment by DaemonicSigil · 2024-10-12T18:10:29.104Z · LW(p) · GW(p)
Okay, I'll be the idiot who gives the obvious answer: Yeah, pretty much.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-12T18:11:16.739Z · LW(p) · GW(p)
Who, by what metric, in what way?
Replies from: DaemonicSigil↑ comment by DaemonicSigil · 2024-10-12T18:24:13.808Z · LW(p) · GW(p)
Everyone who earns money exerts some control by buying food or whatever else they buy. This directs society to work on producing those goods and services. There's also political/military control, but it's also (a much narrower set of) humans who have that kind of control too.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-12T18:37:28.435Z · LW(p) · GW(p)
Actually, this is the sun [LW · GW] controlling the world, not humans. The sun exerts control by permitting plants to grow, and their fruit creates an excess of organic energy, which permits animals like humans to live. Humans have rather limited choice here; we can redirect the food by harvesting it and guarding against adversaries, but the best means to do so are heavily constrained by instrumental matters.
Locally, there is some control in that people can stop eating food and die, or overeat and become obese. Or they can choose what kinds of food to eat. But this seems more like "control yourself" than "control the world". The farmers can choose how much food to supply, but if a farmer doesn't supply what is needed, then some other farmer elsewhere will supply it, so that's more "control your farm" than "control the world".
The world revolves around the sun.
Replies from: DaemonicSigil↑ comment by DaemonicSigil · 2024-10-12T19:18:18.035Z · LW(p) · GW(p)
I've begun worshipping the sun for a number of reasons. First of all, unlike some other gods I could mention, I can see the sun. It's there for me every day. And the things it brings me are quite apparent all the time: heat, light, food, and a lovely day. There's no mystery, no one asks for money, I don't have to dress up, and there's no boring pageantry. And interestingly enough, I have found that the prayers I offer to the sun and the prayers I formerly offered to 'God' are all answered at about the same 50% rate.
-- George Carlin
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-12T22:45:05.154Z · LW(p) · GW(p)
so, do you nonetheless expect humans to still control the world?
I personally don't control the world now. I (on average) expect to be treated about as well by our new AGI overlords as I am treated by the current batch of rulers.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T07:51:27.635Z · LW(p) · GW(p)
Why do you expect that? Our current batch of rulers need to treat humans reasonably well in order for their societies to be healthy. Is there a similar principle that makes AI overlords need to treat us well?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T10:40:28.142Z · LW(p) · GW(p)
50% of the humans currently on Earth want kill me because of my political/religious beliefs. My survival depends on the existence of a nice game-theory equilibrium, not because of the benevolence of other humans. I agree (note the 1 bit) that the new game-theory equilibrium after AGI could be different. However, historically, increasing the level of technology/economic growth has led to less genocide/war/etc, not more.
Replies from: tailcalled, MinusGix, avturchin↑ comment by tailcalled · 2024-10-13T10:53:23.554Z · LW(p) · GW(p)
Has it? I'm under the impression technology has lead to much more genocide and war. WWI and WWII were dependent on automatic weapons, the Holocaust was additionally dependent on trains etc., the Rwandan genocide was dependent on radio.
Technology mainly has the ability to be net good despite this because:
- Technology also leads to more growth, better/faster recovery after war, etc..
- War leads to fear of war, so with NATO, nuclear disarmament, etc., people are reducing the dangers of war
But it's not clear that point 2 is going to be relevant until after AI has been applied in war, and the question is whether that will be too late. Basically we could factor P(doom) into P(doom|AI gets used in war)P(AI gets used in war). Though of course that's only one of multiple dangers.
50% of the humans currently on Earth want kill me because of my political/religious beliefs.
Which political/religious beliefs?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T11:01:14.752Z · LW(p) · GW(p)
Has it? I'm under the impression technology has lead to much more genocide and war.
You're impression is wrong. Technology is (on average) a civilizing force.
{kind=link}
Which political/religious beliefs?
I'm not going into details about which people want to murder me and why for the obvious reason. You can probably easily imagine any number of groups whose existence is tolerated in America but not elsewhere.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T11:15:16.661Z · LW(p) · GW(p)
You're impression is wrong.
You link this chart:

... but it just shows the percentage of years with wars without taking the severity of the wars into account.
Your link with genocides includes genocides linked with colonialism, but colonialism seems driven by technological progress to me.
Technology is (on average) a civilizing force.
This stuff is long-tailed, so past average is no indicator of future averages. A single event could entirely overwhelm the average.
Replies from: habryka4, logan-zoellner↑ comment by habryka (habryka4) · 2024-10-14T05:34:23.608Z · LW(p) · GW(p)
See also this classical blogpost: https://blog.givewell.org/2015/07/08/has-violence-declined-when-large-scale-atrocities-are-systematically-included/
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T11:34:40.858Z · LW(p) · GW(p)
but it just shows the percentage of years with wars without taking the severity of the wars into account.
If you look at the probability of dying by violence, it shows a similar trend
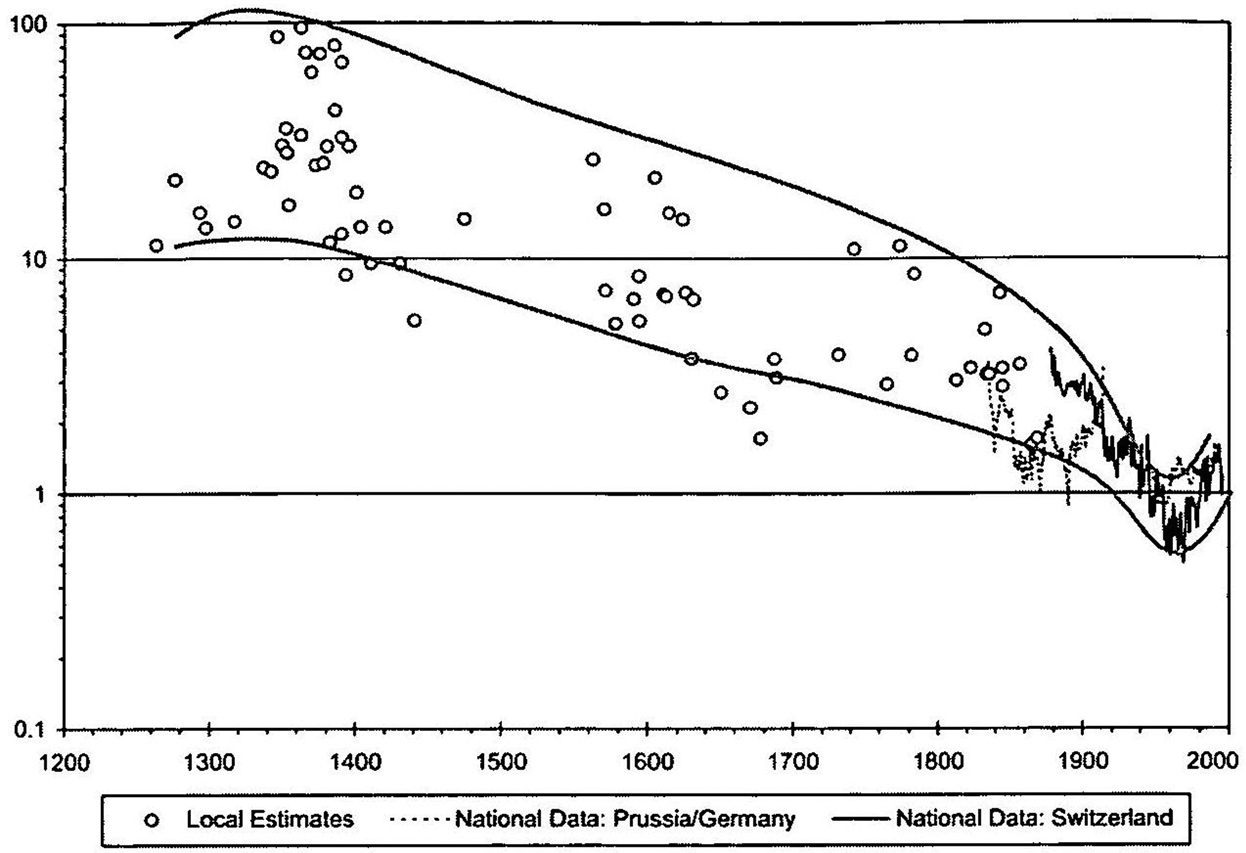{kind=link}
This stuff is long-tailed, so past average is no indicator of future averages.
I agree that tail risks are important. What I disagree with is that only tail risks from AGI are important. If you wish to convince me that tail-risks from AGI are somehow worse than (nuclear war, killer drone swarms, biological weapons, global warming, etc) you will need evidence. Otherwise, you have simply recreated the weak argument (which I already agree with) "AGI will be different, therefore it could be bad".
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T11:50:04.513Z · LW(p) · GW(p)
If you look at the probability of dying by violence, it shows a similar trend
Probability normalizes by population though.
I agree that tail risks are important. What I disagree with is that only tail risks from AGI are important.
My claim is not that the tail risks of AGI are important, my claim is that AGI is a tail risk of technology. Like the correct way to handle tail risks of a broad domain like technology is to perform root cause analysis into narrower factors like "AGI", "nuclear weapons" vs "speed boats" etc., so you can specifically address the risks of severe stuff like AGI without getting caught up in basic stuff like speed boats.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T11:58:49.994Z · LW(p) · GW(p)
My claim is not that the tail risks of AGI are important, my claim is that AGI is a tail risk of technology.
Okay, I'm not really sure why we're talking about this, then.
Consider this post a call to action of the form "please provide reasons why I should update away from the expert-consensus that AGI is probably going to turn out okay"
I agree talking about how we could handle technological changes as a broader framework is a meaningful and useful thing to do. I'm just don't think it's related to this post.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T12:03:42.745Z · LW(p) · GW(p)
My previous comment was in opposition to "handling technological changes as a broader framework". Like I was saying, you shouldn't use "technology" broadly as a reference at all, you should consider narrower categories like AGI which individually have high probabilities of being destructive.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T12:05:46.688Z · LW(p) · GW(p)
narrower categories like AGI which individually have high probabilities of being destructive.
If AGI has a "high probably of being destructive", show me the evidence. What amazingly compelling argument has led you to have beliefs that are wildly different from the expert-consensus?
Replies from: tailcalled↑ comment by tailcalled · 2024-10-13T12:14:04.992Z · LW(p) · GW(p)
I've already posted my argument here [LW(p) · GW(p)], I don't know why you have dodged responding to it.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T12:17:53.804Z · LW(p) · GW(p)
my apologizes. that is in a totally different thread, which I will respond to.
↑ comment by MinusGix · 2024-10-14T18:30:23.315Z · LW(p) · GW(p)
It has also led to many shifts in power between groups based on how well they exploit reality. From hunter-gatherers to agriculture, to grand armies spreading an empire, to ideologies changing the fates of entire countries, and to economic & nuclear super-powers making complex treaties.
comment by tailcalled · 2024-10-12T13:49:56.385Z · LW(p) · GW(p)
Right now, every powerful intelligence (e.g. nation-states) is built out of humans, so the only way for such organizations to thrive is to make sure the constituent humans thrive, for instance by ensuring food, clean air and access to accurate information.
AI is going to loosen up this default pull. If we are limited to reflex-based tool AIs like current LLMs, probably we'll make it through just fine, but if we start doing wild adversarial searches that combine tons of the tool-like activities into something very powerful and autonomous, these can determine ~everything about the world. Unless all winners of such searches actively promote human thriving in their search instead of just getting rid of humanity or exploiting us for raw resources, we're doomed.
There's lots of places where we'd expect adversarial searches to be incentivized, most notably:
- War/national security
- Crime and law enforcement
- Propaganda to sway elections
- Market share acquisition for companies (not just in advertising but also in undermining competitors)
The current situation for war/national security is already super precarious due to nukes, and I tend to reason by an assumption that if a nuke is used again then that's going to be the end of society. I don't know whether that assumption is true, but insofar as it is reasonable, it becomes natural to think of AI weapons as Nuke 2.0.
The situation with nukes suggests that maybe sometimes we can have an indefinite holdoff on using certain methods, but again it already seems quite precarious here, and it's unclear how to generalize this to other case. For instance, outlawing propaganda would seem to interfere with free speech, and enforcing such laws without tyrannizing people who are just confused seems subtle.
So a plausible model seems to me to be, people are gradually developing ways of integrating computers with the physical world, by giving them deeper knowledge of how the world works and more effective routines for handling small tasks. Right now, this interface is very brittle and so breaks down when even slight pressure is applied to it, but as it gets more and more robust and well-understood, it becomes more and more feasible to run searches over it to find more powerful activities. In non-adversarial circumstances, such searches don't have to ensure robustness or completeness and thus can just "do the thing" you're asking them to, but in adversarial circumstances, the adversaries will exploit your weakness and so you actually have to do it similar to a dangerous utility-maximizer.
Replies from: tailcalled, faul_sname, logan-zoellner↑ comment by tailcalled · 2024-10-12T16:12:02.079Z · LW(p) · GW(p)
I guess I should add:
Right now, every powerful intelligence (e.g. nation-states) is built out of humans, so the only way for such organizations to thrive is to make sure the constituent humans thrive, for instance by ensuring food, clean air and access to accurate information.
I'm rejecting the notion that humans thrive because humans individually value thriving. Like, some humans do so, to some extent, but there's quite a few mentally ill people who act in self-destructive ways. Historically, sometimes you end up with entire nations bound up in self-destructive vindictiveness (Gaza being a modern example). The ultimate backstop that keeps this limited is the fact that those who prioritize their own people's thriving as the #1 priority are much better at birthing the next generation and winning wars.
Of course this backstop generates intermediate moralities that do make humans more directly value their own thriving, so there's still some space for intentional human choice.
↑ comment by faul_sname · 2024-10-12T17:08:21.149Z · LW(p) · GW(p)
This suggests that the threat model isn't so much "very intelligent AI" as it is "very cheap and at least somewhat capable robots".
Replies from: tailcalled↑ comment by tailcalled · 2024-10-12T17:13:35.347Z · LW(p) · GW(p)
Kind of, though we already have mass production for some things, and it hasn't lead to the end of the humanity, partly because someone has to maintain and program those robots. But obesity rates have definitely skyrocketed, presumably partly because of our very cheap and somewhat capable robots.
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T12:50:36.225Z · LW(p) · GW(p)
I realize I should probably add a 3rd category of argument: arguments which assume a specific (unlikely) path for AGI development and then argue this particular path is bad.
This is an improvement over "bad" arguments (in the sense that it's at least a logical sequence of argumentation rather than a list of claims), but unlikely to move the needle for me, since the specific sequence involved is unlikely to be true.
Ideally, what one would like to do is "average over all possible paths for AGI development". But I don't know of a better way to do that average than to just use an expert-survey/prediction market.
Let's talk in detail about why this particular path is improbable, by trying to write it as a sequence of logical steps:
- "Right now, every powerful intelligence (e.g. nation-states) is built out of humans, so the only way for such organizations to thrive is to make sure the constituent humans thrive"
- this is empirically false. genocide and slavery have been the norm across human history. We are currently in the process of modifying our atmosphere in a way that is deadly to humans and almost did so recently in the past
- "AI is going to loosen up this default pull."
- this assumes a specific model for AI: humans use the AI to do highly adversarial search and then blindly implement the results. Suppose instead humans only implement the results after verifying them, or require the AI to provide a mathematical proof that "this action won't kill all humans"
- "There's lots of places where we'd expect adversarial searches to be incentivized"
- none of these are unique to AGI. We have the same problem with nuclear weapons, biological weapons and any number of other technologies. AGI is uniquely friendly in the sense that at first it's merely software: it has no impact on the real world unless we choose to let it
- "The current situation for war/national security is already super precarious due to nukes, and I tend to reason by an assumption that if a nuke is used again then that's going to be the end of society. "
- How is this an argument for AGI risk?
- "and it's unclear how to generalize this to other case. For instance, outlawing propaganda would seem to interfere with free speech"
- Something being unclear is not an argument for doom. At best it's a restatement of my original weak argument: AGI will be powerful, therefore it might be bad
- "So a plausible model seems to me to be, people are gradually developing ways of integrating computers with the physical world, by giving them deeper knowledge of how the world works and more effective routines for handling small tasks. "
- even if this is a plausible model, it is by no means the only model or the default path.
- "but as it gets more and more robust and well-understood, it becomes more and more feasible to run searches over it to find more powerful activities."
- it is equally plausible (in my opinion more so) that there is a limit to how far ahead intelligence can predict and science is fundamentally rate-limited by the speed of physical experimentation
- "thus can just "do the thing" you're asking them to, but in adversarial circumstances, the adversaries will exploit your weakness "
- why are we assuming the adversaries will exploit your weakness? Why not assume we build corrigible AI that tries to help you instead.
- "similar to a dangerous utility-maximizer."
- A utility-maximizer is a specific design of AGI, and moreover totally different from the next-token-prediction AIs that currently exists. Why should I assume that this particular design will suddenly become popular (despite the clear disadvantages that you have already stated)?
↑ comment by tailcalled · 2024-10-13T13:57:23.322Z · LW(p) · GW(p)
this is empirically false. genocide and slavery have been the norm across human history.
You need to not mix up conflicts between different human groups with the inability for humans to thrive. The fact that there has been a human history at all requires people to have the orientation to know what's going on, the capacity to act on it, and the care to do so. Humanity hasn't just given up or committed suicide, leaving just a nonhuman world.
Now it's true that generally, there was a self-centered thriving that favored the well-being of oneself and one's friends and family over others, and this would lead to various sorts of conflicts, often wrecking a lot of good people. We can only hope society becomes more discriminatory over time, to better nurture the goodness and only destroy the badness. But you can only say that genocide was bad because there was something that created good people who it was wrong to kill.
We are currently in the process of modifying our atmosphere in a way that is deadly to humans and almost did so recently in the past
But critically, various historical environmental problems had lead to the creation of environmentalist groups, which enabled society to notice these atmospheric problems. Contrast this with prior environmental changes that there was no protection against.
> AI is going to loosen up this default pull.
this assumes a specific model for AI: humans use the AI to do highly adversarial search and then blindly implement the results.
You are misunderstanding. By "loosen up this default pull", I mean, let's say you implement a bot to handle food production, from farm to table. Right now, food production needs to be human-legible because it involves a collaborative effort between lots of people. With the bot, even if it handles food production perfectly fine, you've now removed the force that generates human legibility for food production.
As you remove human involvement from more and more places, humans become able to do fewer and fewer things. Maybe humans can still thrive under such circumstances, but surely you can see that strong people have a by-default better chance than weak people do? Notably, this is a separate part of the argument from adversarial search, and it applies even if we limit ourselves to reflex-like methods. The point here is to highlight what currently allows humans to thrive, and how that gets weakened by AI.
Suppose instead humans only implement the results after verifying them, or require the AI to provide a mathematical proof that "this action won't kill all humans"
none of these are unique to AGI. We have the same problem with nuclear weapons, biological weapons and any number of other technologies. AGI is uniquely friendly in the sense that at first it's merely software: it has no impact on the real world unless we choose to let it
If you wait until humans have manually checked them all through, then you incentivize adversaries to develop military techniques that can destroy your country faster than you can wake up your interpretability researchers. (I expect this to be possible with only weak, reflex-based AI, like if you set up a whole bunch of automated bots to wreck havoc in various ways once triggered.)
How is this an argument for AGI risk?
It's not, it's registering my assumption in case you want to object to it. If you think nukes might be used in a more limited way, then maybe you also think adversarial searches might be used in a more limited way.
Something being unclear is not an argument for doom. At best it's a restatement of my original weak argument: AGI will be powerful, therefore it might be bad
Registering something being unclear is helpful for where to take it. Like if we agreed on the overall picture, but you were more optimistic about the areas that were unclear, and I was more pessimistic about them, then I could continue the argument into those areas as well. Like I'm sort of trying to comprehensively enumerate all the relevant dynamics for how this is gonna develop, and explicitly mark off the places that are relevant to consider but which I haven't properly addressed.
Right now, though, you seem to be assuming that humans by-default thrive, and only exogenous dangers like war or oppression can prevent this. Meanwhile, I'm more using a sort of "inertial" model, where certain neuroses can drive humans to spontaneously self-destruct, sometimes taking a lot of their neighbors with them. As such it seems less relevant to explore these subtrees until the issue of self-destructive neuroses are addressed.
even if this is a plausible model, it is by no means the only model or the default path.
Looks like the default path to me? Like AI companies are dumping lots of knowledge and skills into LLMs, for instance, and at my job we've started integrating them with our product. Are there any other relevant dynamics you are seeing?
it is equally plausible (in my opinion more so) that there is a limit to how far ahead intelligence can predict and science is fundamentally rate-limited by the speed of physical experimentation
You need physical experimentation to test how well your methods for unleashing energy/flow into a particular direction works, so building reflex-like/tool AIs is going to be fundamentally rate-limited by the speed of physical experimentation.
However, as you build up a library of tricks to interact with the world, you can use compute to search through ways to combine these tricks to make bigger things happen. This is generally bounded by whatever the biggest "energy source" you can tap into is, because it is really hard to bring multiple different "energy sources" together into some shared direction.
why are we assuming the adversaries will exploit your weakness? Why not assume we build corrigible AI that tries to help you instead.
We'll build corrigible AI that tries to help us with ordinary stuff like transporting food from farms to homes.
However, the more low-impact it is, the more exploitable it is. If you want food from a self-driving truck, maybe you could just stand in front of it, and it will stop, and then some of your friends can break in to it and steal the food it is carrying.
To prevent this, we need to incapacitate criminals. But criminals don't want to be incapacitated, so they will exploit whatever weaknesses the system for incapacitating them has. As part of this, the more advanced criminals will presumably build AIs to try to seek out weaknesses in the system. That's what I'm referring to with adversaries exploiting your weakness.
A utility-maximizer is a specific design of AGI, and moreover totally different from the next-token-prediction AIs that currently exists. Why should I assume that this particular design will suddenly become popular (despite the clear disadvantages that you have already stated)?
Being robust to exploitation from adversaries massively restricts your options. Whether the exact implementation includes an explicit utility function or not is less relevant than the fact that as it spontaneously adapts to undermine its adversaries, it needs to do so in a way that doesn't undermine humanity in general. I.e. you need to build some system that can unleash massive destruction towards sufficiently unruly enemies, without unleashing massive destruction towards friends. I think the classic utility maximizer instrumental convergence risk gives a pretty accurate picture for how that will look / how that gives you dangers, but if you think next-token-predictors can unleash destruction in a more controlled way, I'm all ears.
I realize I should probably add a 3rd category of argument: arguments which assume a specific (unlikely) path for AGI development and then argue this particular path is bad.
Any path for history needs to account for security and resource flow/allocation. These are the most important part of everything. My position doesn't really assume that much beyond this.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T16:46:13.104Z · LW(p) · GW(p)
Making a point-by-point refutation misses the broader fact that any long sequence of argument like this adds up to very little evidence.
Even if you somehow convince me that each of your (10) arguments was like 75% true, they're still going to add up to nothing because
Unless you can summarize you argument in at most 2 sentences (with evidence), it's completely ignoreable.
Replies from: green_leaf, niplav, tailcalled↑ comment by green_leaf · 2024-10-14T18:06:44.073Z · LW(p) · GW(p)
Unless you can summarize you argument in at most 2 sentences (with evidence), it's completely ignoreable.
This is not how learning any (even slightly complex) topic works.
↑ comment by niplav · 2024-10-14T17:53:37.226Z · LW(p) · GW(p)
Yudkowsky 2017, AronT 2023 [LW · GW] and Gwern 2019, if you're curious why you're getting downvoted.
(I tried to figure out whether this method of estimation works, and it seemed more accurate than I thought, but then I got distracted).
↑ comment by tailcalled · 2024-10-13T17:13:24.780Z · LW(p) · GW(p)
Cope. Here you're taking a probabilistic perspective, but that perspective sucks [LW · GW].
The fact is that there are certain robust resources (like sunlight etc.) which exert constant pressure on the world, and which everything is dependent on. Whatever happens, these resources must go somewhere, so any forecast for the future that's worth its salt must ultimately make predictions about those.
Each part of my argument addresses a different factor involved in these resource flows. Often you can just inspect the world and see that clearly that's how the resources are flowing. Other times, my argument is disjunctive. Yet other times, sure maybe I'm wrong, but the way I might be wrong would imply the possibility of a lot of resources rushing out into some other channel, which again is worth exploring.
Plus, let's remember, Strong Evidence Is Common [LW · GW]. If there's some particular parts of the argument where you don't know how to inspect the world to get plenty of evidence, then I can try to guide you. But blinding yourself because of "muh evidence" is just makes your opinion worthless.
↑ comment by tailcalled · 2024-10-13T20:28:07.245Z · LW(p) · GW(p)
Ideally, what one would like to do is "average over all possible paths for AGI development". But I don't know of a better way to do that average than to just use an expert-survey/prediction market.
How about, whatever method the experts or the prediction market participants are using, but done better?
comment by Vladimir_Nesov · 2024-10-12T12:46:54.231Z · LW(p) · GW(p)
I start with a very low prior of AGI doom ... I give 1 bit of evidence collectively for the weak arguments
Imagine that you have to argue with someone who believes in 50% doom[1] on priors. Then you'd need to articulate the reasons for adopting your priors. Priors are not arguments, it's hard to put them into arguments. Sometimes priors are formed by exposure to arguments, but even then they are not necessarily captured by those arguments. Articulation of your priors might then look similarly tangential and ultimately unconvincing to those who don't share them, if it doesn't form a larger narrative that's no longer a specific argument.
a very low pDoom (2-20%) compared to most people on LessWrong
Were there surveys that put most people on LW higher than that? My impression is that lower bounds of 10-20% are not too low for most, at least for doom in the sense of extinction.
Worth distinguishing doom in the sense of extinction and doom in the sense of existential risk short of extinction, getting most of the cosmic wealth taken away. I have very high doom expectations in the sense of loss of cosmic wealth, but only 20-40% for extinction. ↩︎
↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-12T22:37:11.765Z · LW(p) · GW(p)
Worth distinguishing doom in the sense of extinction and doom in the sense of existential risk short of extinction, getting most of the cosmic wealth taken away. I have very high doom expectations in the sense of loss of cosmic wealth, but only 20-40% for extinction.
By doom I mean the universe gets populated by AI with no moral worth (e.g. paperclippers). I expect humans to look pretty different in a century or two even if AGI was somehow impossible, so I don't really care about preserving status-quo humanity.
Replies from: Vladimir_Nesov, tup99↑ comment by Vladimir_Nesov · 2024-10-13T02:22:11.195Z · LW(p) · GW(p)
I don't really care about preserving status-quo humanity
By non-extinction I don't mean freezing the status quo of necessarily biological Homo sapiens on Earth, though with ASI I expect that non-extinction in particular keeps most individual people alive indefinitely in the way they individually choose. I think this is a more natural reading of non-extinction (as a sense of non-doom) than a perpetual state of human nature preserve.
By doom I mean the universe gets populated by AI with no moral worth
So losing cosmic wealth is sufficient to qualify an outcome as doom, as in Bostrom's existential risk. What if Earth literally remains untouched by machines, protected from extinction level events but otherwise left alone, is it still doom in this sense? What if aliens that hold moral worth but currently labor under an unkind regime exterminate humanity, but then the aliens themselves spread to the stars (taking them for themselves) and live happily ever after, is that still not a central example of doom?
My point is that the term is highly ambiguous, resolution criteria for predictions that involve it are all over the place, so it's no good for use in predictions or communication. There is illusion of transparency where people keep expecting it to be understood, and then others incorrectly think that they've understood the intended meaning. Splitting doom into extinction and loss of cosmic wealth seems less ambiguous.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T10:57:15.496Z · LW(p) · GW(p)
So losing cosmic wealth is sufficient to qualify an outcome as doom
My utility function roughly looks like:
- my survival
- the survival of the people I know and care about
- the distant future is populated by beings that are in some way "descended" from humanity and share at least some of the values (love, joy, curiosity, creativity) that I currently hold
Basically, if I sat down with a human from 10,000 years ago, I think there's a lot we would disagree about, but at the end of the day I think they would get the feeling that I'm an "okay person". I would like to imagine the same sort of thing holding for whatever follows us.
I don't find the hair-splitting arguments like "what if the AGI takes over the universe but leaves Earth intact" particularly interesting except insofar as it allows for all 3 of the above. I also don't think most people have a huge faction of P(~doom) on such weird technicalities.
↑ comment by tup99 · 2024-10-12T22:56:50.907Z · LW(p) · GW(p)
I (on average) expect to be treated about as well by our new AGI overlords as I am treated by the current batch of rulers.
...
By doom I mean the universe gets populated by AI with no moral worth (e.g. paperclippers).
Well, at least we've unearthed the reasons that your p(doom) differs!
Most people do not expect #1(unless we solve alignment), and have a broader definition of #2. I certainly do.
comment by avturchin · 2024-10-13T17:23:18.658Z · LW(p) · GW(p)
I think the cumulative argument works:
- There are dozens of independent ways in which AI can cause a mass extinction event at different stages of its existence.
- While each may have around a 10 percent chance a priori, cumulatively there is more than a 99 percent chance that at least one bad thing will happen.
This doesn't mean that all humans will go extinct for sure, everywhere and forever. Some may survive the mass extinction event.
comment by AnthonyC · 2024-10-13T22:19:36.596Z · LW(p) · GW(p)
As an aside, most arguments for almost anything are bad or weak, whether the conclusion is true/real or not. Science, politics, economics, really any field where there's room for uncertainty and a lot of people interested in the answer. As such, this is not strong evidence in and of itself. One sufficiently strong argument can outweigh all the bad ones. At least in terms of logical evidence. There are many, many, many people who understand your points about nuclear power, for example, but they have been unable to sway political processes for the past few decades and the bad arguments to the contrary are still bandied about constantly. I do think the theoretical minimum price of solar is lower than nuclear for a given level of safety and reliability, though.
That said: I think you'll find there's a lot more people with similar estimates of p(doom) here than you are expecting. I'm one of them. I also think the appropriate reaction to "I believe there's a 2-20% chance that anyone born today will see human extinction before they turn 25" is not to say that number is low, but to say, "We need to mobilize the entire planet as though for total war, if that would help, in order to make sure that doesn't happen."
I do think completely ignoring long lists is a mistake, especially when it's something like the list of lethalities [LW · GW]. When you're dealing with extinction-level events, we don't get to be wrong even once. We don't get to overlook even one plausible case. We must be prepared to to avoid extinction in every instance that might lead to it.
Replies from: AnthonyC↑ comment by AnthonyC · 2024-10-13T23:32:02.524Z · LW(p) · GW(p)
To be clear, that last paragraph is a summary of the argument that I find most convincing. I consider the following to each be self-evident.
- The human brain was coughed up by natural selection which was only weakly selecting for intelligence in the able-to-shape-the-world sense. It runs at about 100Hz on about 20 watts of glucose and communicates with the outside world with sensory and motor channels that provide kB/s to several MB/s range bandwidths at best.
- The above is as true for Einstein and von Neuman as anyone else. Given the limits of natural selection, it is unreasonable to think we've ever seen anything like the limit of what is possible with human brain level hardware and resource consumption.
- If we achieve anything like AI with human-level reasoning, the possibility of which is certain due to humans as existence proof, it will be unavoidably superhuman at the moment of its creation, no need for anything like RSI/FOOM. At minimum it will be on hardware several OOMs faster, with several OOMs more working memory and probably long-term memory, and able to increase its available hardware and energy consumption many OOMs beyond what humans possess. Let's say it starts able to handle 1000 threads in parallel.
- If I were facing an entity as smart as me, which had an hour subjective thinking time per second and could have a thousand parallel trains of thought for that hour, I would lose to it in any contest that relies on reaction time or thinking.
- In the time it takes me to read a book, such a system would have enough time to read a million books. It can watch videos and listen to audio at a rate of years-per-minute. Possibly millennia-per-minute if higher working memory enables absorbing an entire video at once the way we can glance at a single photo. It knows everything humans have ever recorded and digitized online, with as much understanding as any human can extract from those recordings. It possesses all learnable mental skills at the highest level that can be taught to the smartest student.
- If we succeed in aligning AI to human interests, the result will include systems that understand what we want, and how we think, as well as or better than we ever could. As such we cannot, in general, surprise it with any plan we can come up with. It will have long since anticipated all plausible such plans, estimate their likelihoods, and developed appropriate countermeasures if it is possible in principle to do so.
If such a system wants humans to thrive, we will. If it doesn't, there's not a whole lot we could do about it. So, for humans to thrive, at minimum, we need to first ensure the system starts out wanting humans to thrive by the time it becomes AGI with human level reasoning. Then, we need to ensure that no such system is ever in a position where it would take an action that can result in human extinction, whether we're able to anticipate the scenario or not. Otherwise, eventual extinction is a near certainty with enough rolls of the dice. The arguments offered to date that suggest ways of attaining such assurances are, for now, at least as weak and bad as the arguments for doom, and in my opinion more so.
comment by frontier64 · 2024-10-13T13:34:25.712Z · LW(p) · GW(p)
Have you read the sequences? My response depends on whether you have or haven't.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T16:47:04.448Z · LW(p) · GW(p)
If your answer depends on me reading 500 pages of EY fan-fiction, it's not a good answer.
Replies from: habryka4, tup99, frontier64↑ comment by habryka (habryka4) · 2024-10-14T05:36:58.347Z · LW(p) · GW(p)
What are you talking about? The Sequences are a pretty standard non-fiction book, mostly filled with technical explanations and clear prose. If you aren't familiar with it, I do agree that I am kind of confused how you feel comfortable dismissing the arguments. It's kind of like showing up on a computational complexity forum, saying that the arguments for P != NP are bad, without ever having read a computational complexity textbook.
↑ comment by tup99 · 2024-10-13T19:58:53.194Z · LW(p) · GW(p)
A lot of your responses make you sound like you're more interested in arguing and being contrarian than in seeking the truth with us. This one exemplifies it, but it's a general pattern of the tone of your responses. It'd be nice if you came across as more truth-seeking than argument-seeking.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-14T14:26:01.925Z · LW(p) · GW(p)
I came and asked "the expert concensus seems to be that AGI doom is unlikely. This is the best argument I am aware of and it doesn't seem very strong. Are there any other arguments?"
Responses I have gotten are:
- I don't trust the experts, I trust my friends
- You need to read the sequences
- You should rephrase the argument in a way that I like
And 1 actual attempt at giving an answer (which unfortunately includes multiple assumptions I consider false or at least highly improbable)
If I seem contrarian, it's because I believe that the truth is best uncovered by stating one's beliefs and then critically examining the arguments. If you have arguments or disagree with me fine, but saying "you're not allowed to think about this, you just have to trust me and my friends" is not a satisfying answer.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-14T15:33:13.692Z · LW(p) · GW(p)
If I seem contrarian, it's because I believe that the truth is best uncovered by stating one's beliefs and then critically examining the arguments.
That's your error. You should be aiming to let the important parts of reality imprint marks of themselves and their dynamics in your worldview.
Consensus might be best reached by stating one's beliefs and then critically examining the arguments. But if you want to reach consensus, you also need to absorb other's angles, e.g. their friends and the sequences and their framings and so on. (Assuming everyone trusts each other. In cases of distrust, stating one's beliefs and critically examining arguments might simply deepen the distrust.)
If you have arguments or disagree with me fine, but saying "you're not allowed to think about this, you just have to trust me and my friends" is not a satisfying answer.
If you think without contact with reality, your wrongness is just going to become more self-consistent.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-14T16:34:57.266Z · LW(p) · GW(p)
If you think without contact with reality, your wrongness is just going to become more self-consistent.
Please! I'm begging you! Give me some of this contact with reality! What is the evidence you have seen and I have not? Where?
Replies from: tailcalled↑ comment by tailcalled · 2024-10-14T16:50:45.247Z · LW(p) · GW(p)
I don't know, because you haven't told me which of the forces that are present in my world-model are absent from your world-model. Without knowing what to add, I can't give you a pointer.
↑ comment by frontier64 · 2024-10-13T16:59:14.944Z · LW(p) · GW(p)
Ok, then my answer is read the sequences.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-14T14:03:44.435Z · LW(p) · GW(p)
"Can you explain in a few words why you believe what you believe"
"Please read this 500 pages of unrelated content before I will answer your question"
No.
comment by Seth Herd · 2024-10-13T00:38:12.208Z · LW(p) · GW(p)
Here's an entirely separate weak argument, improving on your straw man:
AGI will be powerful. Powerful agentic things do whatever they want. People will try to make AGI do what they want. They might succeed or fail. Nobody has tried doing this before, so we have to guess what the odds of their succeeding are. We should notice that they won't get many second chances because agents want to keep doing what they want to do. And notice that humans have screwed up big projects in surprisingly dumb (in retrospect) ways.
If some people do succeed at making AGI do what they want, they might or might not want things the rest of humanity wants. So we have to estimate the odds that the types of people who will wind up in charge of AGI (not the ones that start out in charge) are "good people". Do they want things that would be better described as doom or flourishing for humanity? This matters, because they now have AGI which we agree is powerful. It may be powerful enough that a subset of power-hungry people now control the future - quite possibly all of it.
If you look at people who've held power historically, the appear to often be pretty damned selfish, and all too often downright sadistic toward their perceived enemies and sometimes toward their own subjects.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T01:10:57.950Z · LW(p) · GW(p)
I don't think it's an improvement to say the same thing with more words. It gives the aura of sophistication without actually improving on the reasoning.
comment by Amalthea (nikolas-kuhn) · 2024-10-12T12:54:03.681Z · LW(p) · GW(p)
I basically only believe the standard "weak argument" you point at here, and that puts my probability of doom given strong AI at 10-90% ("radical uncertainty" might be more appropriate).
It would indeed seem to me that either I) you are using the wrong base-rate or 2) you are making unreasonably weak updates given the observation that people are currently building AI, and it turns out it's not that hard.
I'm personally also radically uncertain about correct base rates (given that we're now building AI) so I don't have a strong argument for why yours is wrong. But my guess is your argument for why yours is right doesn't hold up.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-12T22:25:26.641Z · LW(p) · GW(p)
given that we're now building AI
I'm not sure how this affects my base rates. I'm already assuming like a 80% chance AGI gets built in the next decade or two (and so is Manifold, so I consider this common-knowledge)
you are using the wrong base-rate
Pretend my base rate is JUST the manifold market. That means any difference from that would have to be in the form of a valid argument with evidence that isn't common knowledge among people voting on Manifold.
Simply asserting "you're using the wrong base rate" without explaining what such an argument is doesn't move the needle for me.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T07:18:42.265Z · LW(p) · GW(p)
Fair! I've mostly been stating where I think your reasoning looks suspicious to me, but that does end up being points that you already said wouldn't convince you. (I'm also not really trying to)
Relatedly, this question seems especially bad for prediction markets (which makes me consider the outcome only in an extremely weak sense). First, it is over an extremely long time span so there's little incentive to correct. Second, and most importantly, it can only ever resolve to one side of the issue, so absent other considerations you should assume that it is heavily skewed to that side.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T10:37:04.573Z · LW(p) · GW(p)
it can only ever resolve to one side of the issue, so absent other considerations you should assume that it is heavily skewed to that side.
Prediction markets don't give a noticeably different answer from expert surveys, I doubt the bias is that bad. Manifold isn't a "real money" market anyway, so I suspect most people are answering in good-faith.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T11:01:56.572Z · LW(p) · GW(p)
It eliminates all the aspects of prediction markets that theoretically make them superior to other forms of knowledge aggregation (e.g. surveys). I agree that likely this is just acting as a (weirdly weighted) poll in this case, so the biased resolution likely doesn't matter so much (but that also means the market itself tells you much less than a "true" prediction market would).
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T11:04:32.090Z · LW(p) · GW(p)
but that also means the market itself tells you much less than a "true" prediction market would
This doesn't exempt you from the fact that if your prediction is wildly different from what experts predict you should be able to explain your beliefs in a few words.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T12:27:11.295Z · LW(p) · GW(p)
I mostly try to look around to who's saying what and why and find that the people I consider most thoughtful tend to be more concerned and take "the weak argument" or variations thereof very seriously (as do I). It seems like the "expert consensus" here (as in the poll) is best seen as some sort of evidence rather than a base rate, and one can argue how much to update on it.
That said, there's a few people who seem less overall concerned about near-term doom and who I take seriously as thinkers on the topic. Carl Shulman being perhaps the most notable.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T12:33:23.339Z · LW(p) · GW(p)
I mostly try to look around to who's saying what and why and find that the people I consider most thoughtful tend to be more concerned and take "the weak argument" or variations thereof very seriously
We apparently have different tastes in "people I consider thoughtful". "Here are some people I like and their opinions" is an argument unlikely to convince me (a stranger).
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T12:42:36.732Z · LW(p) · GW(p)
Who do you consider thoughtful on this issue?
It's more like "here are some people who seem to have good opinions", and that would certainly move the needle for me.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T12:51:37.977Z · LW(p) · GW(p)
No one. I trust prediction markets far more than any single human being.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T14:24:47.356Z · LW(p) · GW(p)
In general, yes - but see the above (I.e. we don't have a properly functioning prediction market on the issue).
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-10-13T16:42:22.289Z · LW(p) · GW(p)
metaculus did a study where they compared prediction markets with a small number of participants to those with a large number and found that you get most of the benefit at relative small numbers (10 or so). So if you randomly sample 10 AI experts and survey their opinions, you're doing almost as good as a full prediction market. The fact that multiple AI markets (metaculus, manifold) and surveys all agree on the same 5-10% suggests that none of these methodologies is wildly flawed.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-13T18:04:40.266Z · LW(p) · GW(p)
I mean it only suggests that they're highly correlated. I agree that it seems likely they represent the views of the average "AI expert" in this case. (I should take a look to check who was actually sampled)
My main point regarding this is that we probably shouldn't be paying this particular prediction market too much attention in place of e.g. the survey you mention. I probably also wouldn't give the survey too much weight compared to opinions of particularly thoughtful people, but I agree that this needs to be argued.
comment by rotatingpaguro · 2024-10-13T12:55:44.345Z · LW(p) · GW(p)
I start with a very low prior of AGI doom (for the purpose of this discussion, assume I defer to consensus).
You link to a prediction market (Manifold's "Will AI wipe out humanity before the year 2100", curretly at 13%).
Problems I see with using it for this question, in random order:
- It ends in 2100 so the incentive is effectively about what people will believe a few years from now, not about the question. It is a Keynesian beauty contest. (Better than nothing.)
- Even with the stated question, you win only if it resolves NO, so it is strategically correct to bet NO.
- It is dynamically inconsistent, if you think that humans have power over the outcome and that such markets influence what humans do about it. Illustrative story: "The market says P(doom)=1%, ok I can relax and not work on AI safety" => everyone says that => the market says P(doom)=99% because no AI safety work => "AAAAH SOMEONE DO SOMETHING" => marker P(doom)=1% => ...
↑ comment by AnthonyC · 2024-10-13T22:08:10.801Z · LW(p) · GW(p)
(3) is not necessarily a flaw. Every prediction market is an action market unless the outcome is completely outside human influence. If there were a prediction market where a concerned group of billionaires could invest a huge sum on the "No" side of "Will humans solve how to make AGI and ASI safety to ensure continued human thriving?" (or some much better operationalization of the idea), that would be great.
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2024-10-14T08:50:53.755Z · LW(p) · GW(p)
I agree it's not a flaw in the grand scheme of things. It's a flaw for using it for consensus for reasoning.
comment by Tarnish · 2024-10-12T12:36:17.779Z · LW(p) · GW(p)
Note that some of the best arguments are of the shape "AI will cause doom because it's not that hard to build the following..." followed by insights about how to build an AI that causes doom. Those arguments are best rederived privately rather than shared publicly, and by asking publicly you're filtering the strength of arguments you might get exposed to.
Replies from: faul_sname, ABlue↑ comment by faul_sname · 2024-10-13T02:18:21.675Z · LW(p) · GW(p)
I note that if software developers used that logic for thinking about software security, I expect that almost all software in the security-by-obscurity world would have many holes that would be considered actual negligence in the world we live in.
comment by Odd anon · 2024-10-14T03:56:46.344Z · LW(p) · GW(p)
Get a dozen AI risk skeptics together, and I suspect you'll get majority support from the group for each and every point that the AI risk case depends on. You, in particular, seem to be extremely aligned with the "doom" arguments.
The "guy-on-the-street" skeptic thinks that AGI is science fiction, and it's silly to worry about it. Judging by your other answers, it seems like you disagree, and fully believe that AGI is coming. Go deep into the weeds, and you'll find Sutton and Page and the radical e/accs who believe that AI will wipe out humanity, and that's a good thing, and that wanting to preserve humanity and human control is just another form of racism. A little further out, plenty of AI engineers believe that AGI would normally wipe out humanity, but they're going to solve the alignment problem in time so no need to worry. Some contrarians like to argue that intelligence has nothing to do with power, and that superintelligence will permanently live under humanity's thumb because we have better access to physical force. And then, some optimists believe that AI will inevitably be benevolent, so no need to worry.
If I'm understanding your comments correctly, your position is something like "ASI can and will take over the world, but we'll be fine", a position so unusual I didn't even think to include it detail in my lengthy taxonomy [LW · GW] of "everything turns out okay" arguments. I am unable to make even a basic guess as to how you arrived at the position (though I would be interested in learning).
Please notice that your position is extremely non-intuitive to basically everyone. If you start with expert consensus regarding the basis of your own position in particular, you don't get 87% chance that you're right, you get a look of incredulity and an arbitrarily small number. If you instead want to examine the broader case for AI risk, most of the "good arguments" are going to look more like "no really, AI keeps getting smarter, look at this graph" and things like Yudkowsky's "The Power of Intelligence", both of which (if I understand correctly) you already think are obviously correct.
If you want to find good arguments for "humanity is good, actually", don't ask AI risk people, ask random "normal" people.
My apologies if I've completely misunderstood your position.
(PS: Extinction markets do not work, since they can't pay out after extinction.)