Multiple stages of fallacy - justifications and non-justifications for the multiple stage fallacy
post by AronT (Aron Thomas) · 2023-06-13T17:37:20.762Z · LW · GW · 2 commentsThis is a link post for https://coordinationishard.substack.com/p/multiple-stages-of-fallacy
Contents
Disjunctive alternatives Conditional probabilities are more correlated than you expect Inside view failures Outside view failures Logical induction None 2 comments
[Epistemic status: I am reasonably confident (75%) that these claims are largely correct.]
To estimate the probability of something happening, e.g. AI takeover, one approach is to break this down into stages and multiply the (conditional) probabilities together. I claim this approach yields systematically low answers. This is often referred to as the multiple stage fallacy - however - the term ‘fallacy’ in its label shouldn’t be viewed as an indisputable verdict [LW · GW]. Smart people disagree [EA(p) · GW(p)] with whether it truly is a fallacy, and it is the default method for even very good forecasters - so what’s going on? I haven’t been able to find a source that does this justice[1], and my impression is that consensus opinion on this overestimates the importance of disjunctive alternatives whilst underestimating the importance of correlated conditional probabilities. On a meta/ Bayesian level, I’ve seen it claimed several times that this is a fallacy because, empirically, it produces systematically low probabilities, but haven’t seen good evidence of this.
Disjunctive alternatives
What I see cited most often is that multiplying conditional probabilities fails to account for disjunctive routes. If are events, and you are trying to estimate , then doesn’t give the probability , it gives the probability .
If you want to compute the probability , you have to sum over all possible combinations of and being true/ false. As the number of events grows, the number of combinations grows exponentially. In theory, this sounds like a problem, but in practice I believe the effect is smaller than claimed. In most situations where this fallacy appears to apply, I think it’s often reasonable to claim that the conclusion does actually imply the premises with reasonably high probability.
To take a concrete example, consider Carlsmith’s report on the risk of AI takeover. He lists 5 premises:
- Timelines are short enough to build AGI by 2070.
- There will be sufficient incentives to build AGI.
- Alignment will be hard.
- Systems will be deployed in ways that expose them to inputs that lead to them trying to seek power.
- This will lead to AI takeover.
He computes the conditional probabilities of each premise, and then finally a conditional probability of an existential catastrophe conditional on these premises occurring.
In theory, there are disjunctive routes to existential catastrophe here, but in practice I believe it’s reasonable to place fairly small probability mass on routes to catastrophe where the premises do not all occur[2].
Conditional probabilities are more correlated than you expect
Where the real fallacy lies is in incorrectly estimating conditional probabilities. The central claim is that in almost all cases, you should expect to underestimate how correlated the conditional probabilities you assign to each stage are.
As an example, consider the sample correlation matrix[3] of the logits assigned to each stage by each of the Carlsmith report reviewers:
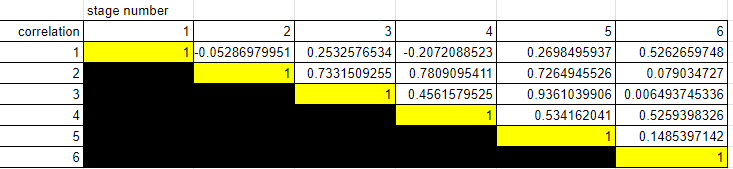
[Of the nontrivial coefficients, are positive. What is the probability of this occurring by chance? If , then which is significant at the significance level. How much should you trust this? Obviously, almost not[4] at[5] all[6], but it does illustrate my point.]
There are two ways through which this happens, which roughly correspond to a failure of inside and outside views respectively:
Inside view failures
When we make predictions about the world, our predictions stem from an interplay of heuristics, biases, instincts, and in some cases formal models. These heuristics will often influence predictions of various seemingly independent statements, and it’s extremely easy to fail to account for this when conditioning on earlier steps. Yudkowsky puts this as: “We don't realize how much we'd need to update our current model if we were already that surprised?”. Returning to the Carlsmith report, concrete examples of such biases are:
- Stages 5 (AI will take over conditional on stages 1 to 4) and stage 3 (alignment will be hard conditional on stages 1, 2) appear correlated. This isn’t surprising - heuristics such as “many things are discontinuous, and you should expect to see phase changes across many domains” influence models of stage 3 (e.g. through thinking sharp left turns are likely) and stage 5 (e.g. through viewing discontinuous capabilities jumps enabling rapid takeover/ foom).
- Stages 4 (AI will be deployed in ways that expose it to inputs that lead it to wanting to seek power conditional on stages 1-3) and stage 2 (there will be incentives to develop AGI conditional on timelines) appear correlated, and this is explained through heuristics such as “incentives are powerful and human society is not robust to powerful incentives that have large negative externalities”.
In particular, these heuristics are pretty general. The key point here is not that it is impossible to account for them whilst conditioning. Rather, when conditioning on object level facts you expect to be true being false, it’s very hard to update the more fundamental parts of your world model that made these object level predictions. This is especially true when what you are explicitly trying to compute is another object level prediction.
Outside view failures
But what if you are very confident that you’ve accounted for essentially all shared heuristics and biases when computing conditional probabilities? Is everything ok now? I claim no - the situation is more insidious than it seems.
The key idea here is that on subjects like AI risk, you’re often not considering these probabilities in isolation, but rather you are computing these probabilities because someone else disagrees with you[7]. So when stages 1 to 3 disagree with your prediction - this isn’t just Bayesian evidence against your world model, it’s Bayesian evidence for other world models that assign higher probabilities to each stage. Unfortunately - it’s extremely hard to update your inside view on this kind of evidence. Knowing that there exists another world model that makes (say) better predictions is very different to knowing what that world model is, especially when the underlying heuristics and intuitions of other people’s world models may not be particularly legible. You can update towards deferring to a black box that makes correct predictions - but it’s much harder to update towards thinking like the black box.
This is analogous to how if on Monday you lose money trading Microsoft, on Tuesday you lose money trading Walmart, and on Wednesday lose money trading Pfizer, you’re far more hesitant on Thursday to bet against the market on Boeing. This is true even if your inside view reasons for wanting to trade come from truly independent models each day, and it’s also the case that your inside view models for valuing stocks don’t improve. The Bayesian update isn’t to some better inside view model for valuing Boeing - it’s towards deferring to a process that has output multiple correct predictions. Similarly, when trying to condition on intermediate stages of a prediction being false, you don’t get to know why you may be wrong - you just get to condition on some other process making better predictions.
I think this is the biggest factor in explaining what is actually going on with the multiple stage fallacy. Concretely, in almost all situations where it applies, you are not estimating probabilities in isolation, but are optimising against other minds with correlated world models - and should be prepared to update your beliefs towards them pretty quickly when evidence appears in their favour.
Logical induction
It’s even possible to demonstrate this behaviour in a formal setting. The statement is as follows:
Let the sequence be a logical inductor [LW · GW] over some theory , and sentences generated by some polynomial time algorithm consistent with .
Then the sequence as .
The proof is an application of theorems 4.7.2 and 4.2.1 here.
Intuitively: suppose a ‘simple’ process outputs many statements (which may even be logically independent[8]!). Then after conditioning on [the first statements output by ] being correct - regardless of the unconditional probabilities - “ideal” reasoners learn to trust - and you should too!
[Thanks to Gavin Leech and Arthur Conmy for useful feedback on a draft of this post]
- ^
The arbital page is good, but I feel it only gestures at what I see is the core problem.
- ^
The 3rd premise is an exception - I can imagine worlds in which we lose control to takeover due to agentic behaviour that emerges through large distributed systems of individually aligned AGIs.
- ^
Data cleaning: I ignored anon 2 and assigned to stages 2, 3 and stages 4, 5, 6 of Soares’ model respectively.
- ^
is not Binomial since the correlation coefficients are not independent.
- ^
- ^
- ^
The very fact we are talking about is a consequence of the fact that some people consider to be high.
- ^
I find this remarkable - to me this really does feel like logical inductors are doing purely ‘outside view reasoning’. From the perspective of , actually is a black box - all knows is that there is a ‘simple’ process that outputs a sequence of predictions.
2 comments
Comments sorted by top scores.
comment by DaemonicSigil · 2023-06-14T02:50:05.089Z · LW(p) · GW(p)
To put it another way:
If you break an outcome up into 6 or more stages and multiply out all the probabilities to get a tiny number, then there's at least a 90% chance that you've severely underestimated the true odds. Why?
Well, estimating probabilities is hard, but let's say you're really good at it. So for the first probability in your sequence, you have a full 90% chance of not underestimating. The next probability is conditional on the first one. This is harder to reason about, so your chance of not underestimating drops to 80%. Estimating probabilities that are conditional on more events gets harder and harder the more events there are, so the subsequent probabilities go: 70%, 60%, 55%, 50%. If we multiply all these out, that's only an 8% chance that you managed to build a correct model!
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-06-14T01:44:28.654Z · LW(p) · GW(p)
This is one of the errors I think this argument is making: Transformative AGI by 2043 is <1% likely
Ari Allyn-Feuer, Ted Sanders