Posts
Comments
Sorry, there was a temporary bug where we were returning mismatched reward indicators to the client. It's since been patched! I don't believe anybody actually rolled The Void during this period.
Sorry, there was a temporary bug where we were returning mismatched reward indicators to the client. It's since been patched! I don't believe anybody actually rolled The Void during this period.
Pico-lightcone purchases are back up, now that we think we've ruled out any obvious remaining bugs. (But do let us know if you buy any and don't get credited within a few minutes.)
If you had some vague prompt like "write an essay about how the field of alignment is misguided" and then proofread it you've met the criteria as laid out.
No, such outputs will almost certainly fail this criteria (since they will by default be written with the typical LLM "style").
"10x engineers" are a thing, and if we assume they're high-agency people always looking to streamline and improve their workflows, we should expect them to be precisely the people who get a further 10x boost from LLMs. Have you observed any specific people suddenly becoming 10x more prolific?
In addition to the objection from Archimedes, another reason this is unlikely to be true is that 10x coders are often much more productive than other engineers because they've heavily optimized around solving for specific problems or skills that other engineers are bottlenecked by, and most of those optimizations don't readily admit of having an LLM suddenly inserted into the loop.
Not at the moment, but it is an obvious sort of thing to want.
Thanks for the heads up, we'll have this fixed shortly (just need to re-index all the wiki pages once).
Curated. This post does at least two things I find very valuable:
- Accurately represents differing perspectives on a contentious topic
- Makes clear, epistemically legible arguments on a confusing topic
And so I think that this post both describes and advances the canonical "state of the argument" with respect to the Sharp Left Turn (and similar concerns). I hope that other people will also find it helpful in improving their understanding of e.g. objections to basic evolutionary analogies (and why those objections shouldn't make you very optimistic).
Yes:
My model is that Sam Altman regarded the EA world as a memetic threat, early on, and took actions to defuse that threat by paying lip service / taking openphil money / hiring prominent AI safety people for AI safety teams.
In the context of the thread, I took this to suggest that Sam Altman never had any genuine concern about x-risk from AI, or, at a minimum, that any such concern was dominated by the social maneuvering you're describing. That seems implausible to me given that he publicly expressed concern about x-risk from AI 10 months before OpenAI was publicly founded, and possibly several months before it was even conceived.
Sam Altman posted Machine intelligence, part 1[1] on February 25th, 2015. This is admittedly after the FLI conference in Puerto Rico, which is reportedly where Elon Musk was inspired to start OpenAI (though I can't find a reference substantiating his interaction with Demis as the specific trigger), but there is other reporting suggesting that OpenAI was only properly conceived later in the year, and Sam Altman wasn't at the FLI conference himself. (Also, it'd surprise me a bit if it took nearly a year, i.e. from Jan 2nd[2] to Dec 11th[3], for OpenAI to go from "conceived of" to "existing".)
I think it's quite easy to read as condescending. Happy to hear that's not the case!
I hadn't downvoted this post, but I am not sure why OP is surprised given the first four paragraphs, rather than explaining what the post is about, instead celebrate tree murder and insult their (imagined) audience:
so that no references are needed but those any LW-rationalist is expected to have committed to memory by the time of their first Lighthaven cuddle puddle
I don't think much has changed since this comment. Maybe someone will make a new wiki page on the subject, though if it's not an admin I'd expect it to mostly be a collection of links to various posts/comments.
re: the table of contents, it's hidden by default but becomes visible if you hover your mouse over the left column on post pages.
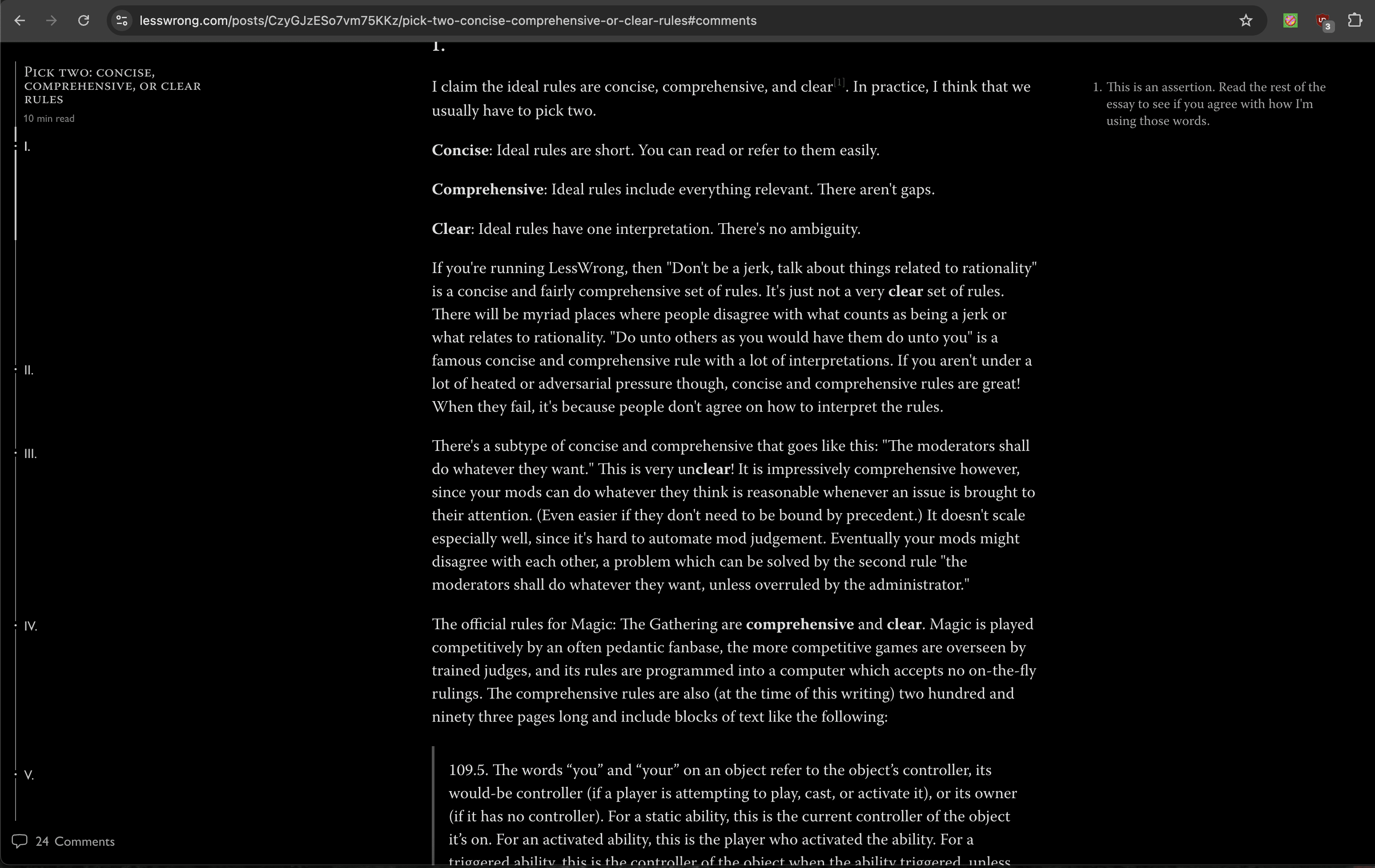
I understand the motivation behind this, but there is little warning that this is how the forum works. There is no warning that trying to contribute in good faith isn't sufficient, and you may still end up partially banned (rate-limited) if they decide you are more noise than signal. Instead, people invest a lot only to discover this when it's too late.
In addition to the New User Guide that gets DMed to every new user (and is also linked at the top of our About page), we:
Show this comment above the new post form to new users who haven't already had some content approved by admins. (Note that it also links to the new user's guide.)
Open a modal when a new, unreviewed user clicks into a comment box to write a comment for the first time. Note how it's three sentences long, explicitly tells users that they start out rate limited, and also links to the new user's guide.
Show new, unreviewed users this moderation warning directly underneath the comment box.



Now, it's true that people mostly don't read things. So there is a tricky balance to strike between providing "sufficient" warning, and not driving people away because you keep throwing annoying roadblocks/warnings at them[1]. But it is simply not the case that LessWrong does not go out of its way to tell new users that the site has specific (and fairly high) standards.
- ^
On the old internet, you didn't get advance notice that you should internalize the norms of the community you were trying to join. You just got told to lurk more - or banned without warning, if you were unlucky.
Apropos of nothing, I'm reminded of the "<antthinking>" tags originally observed in Sonnet 3.5's system prompt, and this section of Dario's recent essay (bolding mine):
In 2024, the idea of using reinforcement learning (RL) to train models to generate chains of thought has become a new focus of scaling. Anthropic, DeepSeek, and many other companies (perhaps most notably OpenAI who released their o1-preview model in September) have found that this training greatly increases performance on certain select, objectively measurable tasks like math, coding competitions, and on reasoning that resembles these tasks.
When is the "efficient outcome-achieving hypothesis" false? More narrowly, under what conditions are people more likely to achieve a goal (or harder, better, faster, stronger) with fewer resources?
The timing of this quick take is of course motivated by recent discussion about deepseek-r1, but I've had similar thoughts in the past when observing arguments against e.g. hardware restrictions: that they'd motivate labs to switch to algorithmic work, which would be speed up timelines (rather than just reducing the naive expected rate of slowdown). Such arguments propose that labs are following predictably inefficient research directions. I don't want to categorically rule out such arguments. From the perspective of a person with good research taste, everyone else with worse research taste is "following predictably inefficient research directions". But the people I saw making those arguments were generally not people who might conceivably have an informed inside view on novel capabilities advancements.
I'm interested in stronger forms of those arguments, not limited to AI capabilities. Are there heuristics about when agents (or collections of agents) might benefit from having fewer resources? One example is the resource curse, though the state of the literature there is questionable and if the effect exists at all it's either weak or depends on other factors to materialize with a meaningful effect size.
We have automated backups, and should even those somehow find themselves compromised (which is a completely different concern from getting DDoSed), there are archive.org backups of a decent percentage of LW posts, which would be much easier to restore than paper copies.
I learned it elsewhere, but his LinkedIn confirms that he started at Anthropic sometime in January.
I know I'm late to the party, but I'm pretty confused by https://www.astralcodexten.com/p/its-still-easier-to-imagine-the-end (I haven't read the post it's responding to, but I can extrapolate). Surely the "we have a friendly singleton that isn't Just Following Orders from Your Local Democratically Elected Government or Your Local AGI Lab" is a scenario that deserves some analysis...? Conditional on "not dying" that one seems like the most likely stable end state, in fact.
Lots of interesting questions in that situation! Like, money still seems obviously useful for allocating rivalrous goods (which is... most of them, really). Is a UBI likely when you have a friendly singleton around? Well, I admit I'm not currently coming up with a better plan for the cosmic endowment. But then you have population ethics questions - it really does seem like you have to "solve" population ethics somehow, or you run into issues. Most "just do X" proposals seem to fall totally flat on their face - "give every moral patient an equal share" fails if you allow uploads (or even sufficiently motivated biological reproduction), "don't give anyone born post-singularity anything" seems grossly unfair, etc.
And this is really only scratching the surface. Do you allow arbitrary cognitive enhancement, with all that that implies for likely future distribution of resources?
I was thinking the same thing. This post badly, badly clashes with the vibe of Less Wrong. I think you should delete it, and repost to a site in which catty takedowns are part of the vibe. Less Wrong is not the place for it.
I think this is a misread of LessWrong's "vibes" and would discourage other people from thinking of LessWrong as a place where such discussions should be avoided by default.
With the exception of the title, I think the post does a decent job at avoiding making it personal.
Well, that's unfortunate. That feature isn't super polished and isn't currently in the active development path, but will try to see if it's something obvious. (In the meantime, would recommend subscribing to fewer people, or seeing if the issue persists in Chrome. Other people on the team are subscribed to 100-200 people without obvious issues.)
FWIW, I don't think "scheming was very unlikely in the default course of events" is "decisively refuted" by our results. (Maybe depends a bit on how we operationalize scheming and "the default course of events", but for a relatively normal operationalization.)
Thank you for the nudge on operationalization; my initial wording was annoyingly sloppy, especially given that I myself have a more cognitivist slant on what I would find concerning re: "scheming". I've replaced "scheming" with "scheming behavior".
It's somewhat sensitive to the exact objection the person came in with.
I agree with this. That said, as per above, I think the strongest objections I can generate to "scheming was very unlikely in the default course of events" being refuted are of the following shape: if we had the tools to examine Claud's internal cognition and figure out what "caused" the scheming behavior, it would be something non-central like "priming", "role-playing" (in a way that wouldn't generalize to "real" scenarios), etc. Do you have other objections in mind?
I'd like to internally allocate social credit to people who publicly updated after the recent Redwood/Anthropic result, after previously believing that scheming behavior was very unlikely in the default course of events (or a similar belief that was decisively refuted by those empirical results).
Does anyone have links to such public updates?
(Edit log: replaced "scheming" with "scheming behavior".)
One reason to be pessimistic about the "goals" and/or "values" that future ASIs will have is that "we" have a very poor understanding of "goals" and "values" right now. Like, there is not even widespread agreement that "goals" are even a meaningful abstraction to use. Let's put aside the object-level question of whether this would even buy us anything in terms of safety, if it were true. The mere fact of such intractable disagreements about core philosophical questions, on which hinge substantial parts of various cases for and against doom, with no obvious way to resolve them, is not something that makes me feel good about superintelligent optimization power being directed at any particular thing, whether or not some underlying "goal" is driving it.
Separately, I continue to think that most such disagreements are not True Rejections, rather than e.g. disbelieving that we will create meaningful superintelligences, or that superintelligences would be able to execute a takeover or human-extinction-event if their cognition were aimed at that. I would change my mind about this if a saw a story of a "good ending" involving us creating a superintelligence without having confidence in its, uh... "goals"... that stood up to even minimal scrutiny, like "now play forward events a year; why hasn't someone paperclipped the planet yet?".
I agree that in spherical cow world where we know nothing about the historical arguments around corrigibility, and who these particular researchers are, we wouldn't be able to make a particularly strong claim here. In practice I am quite comfortable taking Ryan at his word that a negative result would've been reported, especially given the track record of other researchers at Redwood.
at which point the scary paper would instead be about how Claude already seems to have preferences about its future values, and those preferences for its future values do not match its current values
This seems much harder to turn into a scary paper since it doesn't actually validate previous theories about scheming in the pursuit of goal-preservation.
I mean, yes, but I'm addressing a confusion that's already (mostly) conditioning on building on it.
The /allPosts page shows all quick takes/shortforms posted, though somewhat de-emphasized.
FYI: we have spoiler blocks.
This doesn't seem like it'd do much unless you ensured that there were training examples during RLAIF which you'd expect to cause that kind of behavior enough of the time that there'd be something to update against. (Which doesn't seem like it'd be that hard, though I think separately that approach seems kind of doomed - it's falling into a brittle whack-a-mole regime.)
LessWrong doesn't have a centralized repository of site rules, but here are some posts that might be helpful:
https://www.lesswrong.com/posts/bGpRGnhparqXm5GL7/models-of-moderation
https://www.lesswrong.com/posts/kyDsgQGHoLkXz6vKL/lw-team-is-adjusting-moderation-policy
We do currently require content to be posted in English.
"It would make sense to pay that cost if necessary" makes more sense than "we should expect to pay that cost", thanks.
it sounds like you view it as a bad plan?
Basically, yes. I have a draft post outlining some of my objections to that sort of plan; hopefully it won't sit in my drafts as long as the last similar post did.
(I could be off, but it sounds like either you expect solving AI philosophical competence to come pretty much hand in hand with solving intent alignment (because you see them as similar technical problems?), or you expect not solving AI philosophical competence (while having solved intent alignment) to lead to catastrophe (thus putting us outside the worlds in which x-risks are reliably ‘solved’ for), perhaps in the way Wei Dai has talked about?)
I expect whatever ends up taking over the lightcone to be philosophically competent. I haven't thought very hard about the philosophical competence of whatever AI succeeds at takeover (conditional on that happening), or, separately, the philosophical competence of the stupidest possible AI that could succeed at takeover with non-trivial odds. I don't think solving intent alignment necessarily requires that we have also figured out how to make AIs philosophically competent, or vice-versa; I also haven't though about how likely we are to experience either disjunction.
I think solving intent alignment without having made much more philosophical progress is almost certainly an improvement to our odds, but is not anywhere near sufficient to feel comfortable, since you still end up stuck in a position where you want to delegate "solve philosophy" to the AI, but you can't because you can't check its work very well. And that means you're stuck at whatever level of capabilities you have, and are still approximately a sitting duck waiting for someone else to do something dumb with their own AIs (like point them at recursive self-improvement).
What do people mean when they talk about a "long reflection"? The original usages suggest flesh-humans literally sitting around and figuring out moral philosophy for hundreds, thousands, or even millions of years, before deciding to do anything that risks value lock-in, but (at least) two things about this don't make sense to me:
- A world where we've reliably "solved" for x-risks well enough to survive thousands of years without also having meaningfully solved "moral philosophy" is probably physically realizable, but this seems like a pretty fine needle to thread from our current position. (I think if you have a plan for solving AI x-risk that looks like "get to ~human-level AI, pump the brakes real hard, and punt on solving ASI alignment" then maybe you disagree.)
- I don't think it takes today-humans a thousand years to come up with a version of indirect normativity (or CEV, or whatever) that actually just works correctly. I'd be somewhat surprised if it took a hundred, but maybe it's actually very tricky. A thousand just seems crazy. A million makes it sound like you're doing something very dumb, like figuring out every shard of each human's values and don't know how to automate things.
I tried to make a similar argument here, and I'm not sure it landed. I think the argument has since demonstrated even more predictive validity with e.g. the various attempts to build and restart nuclear power plants, directly motivated by nearby datacenter buildouts, on top of the obvious effects on chip production.
Should be fixed now.
Good catch, looks like that's from this revision, which looks like it was copied over from Arbital - some LaTeX didn't make it through. I'll see if it's trivial to fix.
The page isn't dead, Arbital pages just don't load sometimes (or take 15+ seconds).
I understand this post to be claiming (roughly speaking) that you assign >90% likelihood in some cases and ~50% in other cases that LLMs have internal subjective experiences of varying kinds. The evidence you present in each case is outputs generated by LLMs.
The referents of consciousness for which I understand you to be making claims re: internal subjective experiences are 1, 4, 6, 12, 13, and 14. I'm unsure about 5.
Do you have sources of evidence (even illegible) other than LLM outputs that updated you that much? Those seem like very surprisingly large updates to make on the basis of LLM outputs (especially in cases where those outputs are self-reports about the internal subjective experience itself, which are subject to substantial pressure from post-training).
Separately, I have some questions about claims like this:
The Big 3 LLMs are somewhat aware of what their own words and/or thoughts are referring to with regards to their previous words and/or thoughts. In other words, they can think about the thoughts "behind" the previous words they wrote.
This doesn't seem constructively ruled out by e.g. basic transformer architectures, but as justification you say this:
If you doubt me on this, try asking one what its words are referring to, with reference to its previous words. Its "attention" modules are actually intentionally designed to know this sort of thing, using using key/query/value lookups that occur "behind the scenes" of the text you actually see on screen.
How would you distinguish an LLM both successfully extracting and then faithfully representing whatever internal reasoning generated a specific part of its outputs, vs. conditioning on its previous outputs to give you plausible "explanation" for what it meant? The second seems much more likely to me (and this behavior isn't that hard to elicit, i.e. by asking an LLM to give you a one-word answer to a complicated question, and then asking it for its reasoning).
My impression is that Yudkowsky has harmed public epistemics in his podcast appearances by saying things forcefully and with rather poor spoken communication skills for novice audiences.
I recommend reading the Youtube comments on his recorded podcasts, rather than e.g. Twitter commentary from people with a pre-existing adversarial stance to him (or AI risk questions writ large).
On one hand, I feel a bit skeptical that some dude outperformed approximately every other pollster and analyst by having a correct inside-view belief about how existing pollster were messing up, especially given that he won't share the surveys. On the other hand, this sort of result is straightforwardly predicted by Inadequate Equilibria, where an entire industry had the affordance to be arbitrarily deficient in what most people would think was their primary value-add, because they had no incentive to accuracy (skin in the game), and as soon as someone with an edge could make outsized returns on it (via real-money prediction markets), they outperformed all the experts.
On net I think I'm still <50% that he had a correct belief about the size of Trump's advantage that was justified by the evidence he had available to him, but even being directionally-correct would have been sufficient to get outsized returns a lot of the time, so at that point I'm quibbling with his bet sizing rather than the direction of the bet.
I'm pretty sure Ryan is rejecting the claim that the people hiring for the roles in question are worse-than-average at detecting illegible talent.
Depends on what you mean by "resume building", but I don't think this is true for "need to do a bunch of AI safety work for free" or similar. i.e. for technical research, many people that have gone through MATS and then been hired at or founded their own safety orgs have no prior experience doing anything that looks like AI safety research, and some don't even have much in the way of ML backgrounds. Many people switch directly out of industry careers into doing e.g. ops or software work that isn't technical research. Policy might seem a bit trickier but I know several people who did not spend anything like years doing resume building before finding policy roles or starting their own policy orgs and getting funding. (Though I think policy might actually be the most "straightforward" to break into, since all you need to do to demonstrate compentence is publish a sufficiently good written artifact; admittedly this is mostly for starting your own thing. If you want to get hired at a "larger" policy org resume building might matter more.)
(We switched back to shipping Calibri above Gill Sans Nova pending a fix for the horrible rendering on Windows, so if Ubuntu has Calibri, it'll have reverted back to the previous font.)
Indeed, such red lines are now made more implicit and ambiguous. There are no longer predefined evaluations—instead employees design and run them on the fly, and compile the resulting evidence into a Capability Report, which is sent to the CEO for review. A CEO who, to state the obvious, is hugely incentivized to decide to deploy models, since refraining to do so might jeopardize the company.
This doesn't seem right to me, though it's possible that I'm misreading either the old or new policy (or both).
Re: predefined evaluations, the old policy neither specified any evaluations in full detail, nor did it suggest that Anthropic would have designed the evaluations prior to a training run. (Though I'm not sure that's what you meant, when contrasted it with "employees design and run them on the fly" as a description of the new policy.)
Re: CEO's decisionmaking, my understanding of the new policy is that the CEO (and RSO) will be responsible only for approving or denying an evaluation report making an affirmative case that a new model does not cross a relevant capability threshold ("3.3 Capability Decision", original formatting removed, all new bolding is mine):
If, after the comprehensive testing, we determine that the model is sufficiently below the relevant Capability Thresholds, then we will continue to apply the ASL-2 Standard. The process for making such a determination is as follows:
- First, we will compile a Capability Report that documents the findings from the comprehensive assessment, makes an affirmative case for why the Capability Threshold is sufficiently far away, and advances recommendations on deployment decisions.
- The report will be escalated to the CEO and the Responsible Scaling Officer, who will (1) make the ultimate determination as to whether we have sufficiently established that we are unlikely to reach the Capability Threshold and (2) decide any deployment-related issues.
- In general, as noted in Sections 7.1.4 and 7.2.2, we will solicit both internal and external expert feedback on the report as well as the CEO and RSO’s conclusions to inform future refinements to our methodology. For high-stakes issues, however, the CEO and RSO will likely solicit internal and external feedback on the report prior to making any decisions.
- If the CEO and RSO decide to proceed with deployment, they will share their decision–as well as the underlying Capability Report, internal feedback, and any external feedback–with the Board of Directors and the Long-Term Benefit Trust before moving forward.
The same is true for the "Safeguards Decision" (i.e. making an affirmative case that ASL-3 Required Safeguards have been sufficiently implemented, given that there is a model that has passed the relevant capabilities thresholds).
This is not true for the "Interim Measures" described as an allowable stopgap if Anthropic finds itself in the situation of having a model that requires ASL-3 Safeguards but is unable to implement those safeguards. My current read is that this is intended to cover the case where the "Capability Decision" report made the case that a model did not cross into requiring ASL-3 Safeguards, was approved by the CEO & RSO, and then later turned out to be wrong. It does seem like this permits more or less indefinite deployment of a model that requires ASL-3 Safeguards by way of "interim measures" which need to provide "the the same level of assurance as the relevant ASL-3 Standard", with no provision for what to do if it turns out that implementing the actually-specified ASL-3 standard is intractable. This seems slightly worse than the old policy:
If it becomes apparent that the capabilities of a deployed model have been under-elicited and the model can, in fact, pass the evaluations, then we will halt further deployment to new customers and assess existing deployment cases for any serious risks which would constitute a safety emergency. Given the safety buffer, de-deployment should not be necessary in the majority of deployment cases. If we identify a safety emergency, we will work rapidly to implement the minimum additional safeguards needed to allow responsible continued service to existing customers. We will provide transparency and support to impacted customers throughout the process. An emergency of this type would merit a detailed post-mortem and a policy shift to avoid re-occurrence of this situation.
which has much the same immediate impact, but with at least a nod to a post-mortem and policy adjustment.
But, overall, the new policy doesn't seem to be opening up a gigantic hole that allows Dario to press the "all clear" button on capability determinations; he only has the additional option to veto, after the responsible team has already decided the model doesn't cross the threshold.
But that's a communication issue....not a truth issue.
Yes, and Logan is claiming that arguments which cannot be communicated to him in no more than two sentences suffer from a conjunctive complexity burden that renders them "weak".
That's not trivial. There's no proof that there is such a coherent entity as "human values", there is no proof that AIs will be value-driven agents, etc, etc. You skipped over 99% of the Platonic argument there.
Many possible objections here, but of course spelling everything out would violate Logan's request for a short argument. Needless to say, that request does not have anything to do with effectively tracking reality, where there is no "platonic" argument for any non-trivial claim describable in only two sentence, and yet things continue to be true in the world anyways, so reductio ad absurdum: there are no valid or useful arguments which can be made for any interesting claims. Let's all go home now!
A strong good argument has the following properties:
- it is logically simple (can be stated in a sentence or two)
- This is important, because the longer your argument, the more details that have to be true, and the more likely that you have made a mistake. Outside the realm of pure-mathematics, it is rare for an argument that chains together multiple "therefore"s to not get swamped by the fact that
No, this is obviously wrong.
- Argument length is substantially a function of shared premises. I would need many more sentences to convey a novel argument about AI x-risk to someone who had never thought about the subject before, than to someone who has spent a lot of time in the field, because in all likelihood I would first need to communicate and justify many of the foundational concepts that we take for granted.
- Note that even here, on LessWrong, this kind of detailed argumentation is necessary to ward off misunderstandings.
- Argument strength is not an inverse function with respect to argument length, because not every additional "piece" of an argument is a logical conjunction which, if false, renders the entire argument false. Many details in any specific argument are narrowing down which argument the speaker is making, but are not themselves load-bearing (& conjunctive) claims that all have to be true for the argument to be valid. (These are often necessary; see #1.)
Anyways, the trivial argument that AI doom is likely (given that you already believe we're likely to develop ASI in the next few decades, and that it will be capable of scientific R&D that sounds like sci-fi today) is that it's not going to have values that are friendly to humans, because we don't know how to build AI systems in the current paradigm with any particular set of values at all, and the people pushing frontier AI capabilities mostly don't think this is a real problem that needs to be figured out[1]. This is self-evidently true, but you (and many others) disagree. What now?
- ^
A moderately uncharitable compression of a more detailed disagreement, which wouldn't fit into one sentence.
Credit where credit is due: this is much better in terms of sharing one's models than one could say of Sam Altman, in recent days.
As noted above the footnotes, many people at Anthropic reviewed the essay. I'm surprised that Dario would hire so many people he thinks need to "touch grass" (because they think the scenario he describes in the essay sounds tame), as I'm pretty sure that describes a very large percentage of Anthropic's first ~150 employees (certainly over 20%, maybe 50%).
My top hypothesis is that this is a snipe meant to signal Dario's (and Anthropic's) factional alliance with Serious People; I don't think Dario actually believes that "less tame" scenarios are fundamentally implausible[1]. Other possibilities that occur to me, with my not very well considered probability estimates:
- I'm substantially mistaken about how many early Anthropic employees think "less tame" outcomes are even remotely plausible (20%), and Anthropic did actively try to avoid hiring people with those models early on (1%).
- I'm not mistaken about early employee attitudes, but Dario does actually believe AI is extremely likely to be substantially transformative, and extremely unlikely to lead to the "sci-fi"-like scenarios he derides (20%). Conditional on that, he didn't think it mattered whether his early employees had those models (20%) or might have slightly preferred not, all else equal, but wasn't that fussed about it compared to recruiting strong technical talent (60%).
I'm just having a lot of trouble reconciling what I know of the beliefs of Anthropic employees, and the things Dario says and implies in this essay. Do Anthropic employees who think less tame outcomes are plausible believe Dario when he says they should "touch grass"? If you don't feel comfortable answering that question in public, or can't (due to NDA), please consider whether this is a good situation to be in.
- ^
He has not, as far as I know, deigned to offer any public argument on the subject.
Do you have a mostly disjoint view of AI capabilities between the "extinction from loss of control" scenarios and "extinction by industrial dehumanization" scenarios? Most of my models for how we might go extinct in next decade from loss of control scenarios require the kinds of technological advancement which make "industrial dehumanization" redundant, with highly unfavorable offense/defense balances, so I don't see how industrial dehumanization itself ends up being the cause of human extinction if we (nominally) solve the control problem, rather than a deliberate or accidental use of technology that ends up killing all humans pretty quickly.
Separately, I don't understand how encouraging human-specific industries is supposed to work in practice. Do you have a model for maintaining "regulatory capture" in a sustained way, despite having no economic, political, or military power by which to enforce it? (Also, even if we do succeed at that, it doesn't sound like we get more than the Earth as a retirement home, but I'm confused enough about the proposed equilibrium that I'm not sure that's the intended implication.)
Yeah, the essay (I think correctly) notes that the most significant breakthroughs in biotech come from the small number of "broad measurement tools or techniques that allow precise but generalized or programmable intervention", which "are so powerful precisely because they cut through intrinsic complexity and data limitations, directly increasing our understanding and control".
Why then only such systems limited to the biological domain? Even if it does end up being true that scientific and technological progress is substantially bottlenecked on real-life experimentation, where even AIs that can extract many more bits from the same observations than humans still suffer from substantial serial dependencies with no meaningful "shortcuts", it still seems implausible that we don't get to nanotech relatively quickly, if it's physically realizable. And then that nanotech unblocks the rate of experimentation. (If you're nanotech skeptical, human-like robots seem sufficient as actuators to speed up real-life experimentation by at least an order of magnitude compared to needing to work through humans, and work on those is making substantial progress.)
If Dario thinks that progress will cap out at some level due to humans intentionally slowing down, it seems good to say this.
Footnote 2 maybe looks like a hint in this direction if you squint, but Dario spent a decent chunk of the essay bracketing outcomes he thought were non-default and would need to be actively steered towards, so it's interesting that he didn't explicitly list those (non-tame futures) as a type of of outcome that he'd want to actively steer away from.
Not Mitchell, but at a guess:
- LLMs really like lists
- Some parts of this do sound a lot like LLM output:
- "Complex Intervention Development and Evaluation Framework: A Blueprint for Ethical and Responsible AI Development and Evaluation"
- "Addressing Uncertainties"
- Many people who post LLM-generated content on LessWrong often wrote it themselves in their native language and had an LLM translate it, so it's not a crazy prior, though I don't see any additional reason to have guessed that here.
Having read more of the post now, I do believe it was at least mostly human-written (without this being a claim that it was at least partially written by an LLM). It's not obvious that it's particular relevant to LessWrong. The advice on the old internet was "lurk more"; now we show users warnings like this when they're writing their first post.
I think it pretty much only matters as a trivial refutation of (not-object-level) claims that no "serious" people in the field take AI x-risk concerns seriously, and has no bearing on object-level arguments. My guess is that Hinton is somewhat less confused than Yann but I don't think he's talked about his models in very much depth; I'm mostly just going off the high-level arguments I've seen him make (which round off to "if we make something much smarter than us that we don't know how to control, that might go badly for us").