Shortform
post by Cleo Nardo (strawberry calm) · 2024-03-01T18:20:54.696Z · LW · GW · 101 commentsContents
103 comments
101 comments
Comments sorted by top scores.
comment by Cleo Nardo (strawberry calm) · 2024-12-23T22:42:10.409Z · LW(p) · GW(p)
I'm very confused about current AI capabilities and I'm also very confused why other people aren't as confused as I am. I'd be grateful if anyone could clear up either of these confusions for me.
How is it that AI is seemingly superhuman on benchmarks, but also pretty useless?
For example:
- O3 scores higher on FrontierMath than the top graduate students
- No current AI system could generate a research paper that would receive anything but the lowest possible score from each reviewer
If either of these statements is false (they might be -- I haven't been keeping up on AI progress), then please let me know. If the observations are true, what the hell is going on?
If I was trying to forecast AI progress in 2025, I would be spending all my time trying to mutually explain these two observations.
Replies from: ryan_greenblatt, Thane Ruthenis, johnswentworth, SamEisenstat, TsviBT, quetzal_rainbow, pat-myron↑ comment by ryan_greenblatt · 2024-12-23T23:11:46.099Z · LW(p) · GW(p)
Proposed explanation: o3 is very good at easy-to-check short horizon tasks that were put into the RL mix and worse at longer horizon tasks, tasks not put into its RL mix, or tasks which are hard/expensive to check.
I don't think o3 is well described as superhuman - it is within the human range on all these benchmarks especially when considering the case where you give the human 8 hours to do the task.
(E.g., on frontier math, I think people who are quite good at competition style math probably can do better than o3 at least when given 8 hours per problem.)
Additionally, I'd say that some of the obstacles in outputing a good research paper could be resolved with some schlep, so I wouldn't be surprised if we see some OK research papers being output (with some human assistance) next year.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-02-01T15:56:11.908Z · LW(p) · GW(p)
I saw someone use OpenAI’s new Operator model today. It couldn’t order a pizza by itself. Why is AI in the bottom percentile of humans at using a computer, and top percentile at solving maths problems? I don’t think maths problems are shorter horizon than ordering a pizza, nor easier to verify.
Your answer was helpful but I’m still very confused by what I’m seeing.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-02-01T16:02:07.384Z · LW(p) · GW(p)
- I think it's much easier to RL on huge numbers of math problems, including because it is easier to verify and because you can more easily get many problems. Also, for random reasons, doing single turn RL is substantially less complex and maybe faster than multi turn RL on agency (due to variable number of steps and variable delay from environments)
- OpenAI probably hasn't gotten around to doing as much computer use RL partially due to prioritization.
↑ comment by Thane Ruthenis · 2024-12-23T23:56:00.083Z · LW(p) · GW(p)
I am also very confused. The space of problems has a really surprising structure, permitting algorithms that are incredibly adept at some forms of problem-solving, yet utterly inept at others.
We're only familiar with human minds, in which there's a tight coupling between the performances on some problems (e. g., between the performance on chess or sufficiently well-posed math/programming problems, and the general ability to navigate the world). Now we're generating other minds/proto-minds, and we're discovering that this coupling isn't fundamental.
(This is an argument for longer timelines, by the way. Current AIs feel on the very cusp of being AGI, but there in fact might be some vast gulf between their algorithms and human-brain algorithms that we just don't know how to talk about.)
No current AI system could generate a research paper that would receive anything but the lowest possible score from each reviewer
I don't think that's strictly true, the peer-review system often approves utter nonsense. But yes, I don't think any AI system can generate an actually worthwhile research paper.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-24T00:46:59.782Z · LW(p) · GW(p)
I think the main takeaways are the following:
-
Reliability is way more important than people realized. One of the central problems that hasn't gone away as AI scaled is that their best performance is too unreliable for anything but very easy to verify problems like mathematics and programming, which prevents unreliability from becoming crippling, but otherwise this is the key blocker that standard AI scaling has basically never solved.
-
It's possible in practice to disentangle certain capabilities from each other, and in particular math and programming capabilities do not automatically imply other capabilities, even if we somehow had figured out how to make the o-series as good as AlphaZero for math and programming, which is good news for AI control.
-
The AGI term, and a lot of the foundation built off of it, like timelines to AGI, will become less and less relevant over time, because of both the varying meanings, combined with the fact that as AI progresses, capabilities will be developed in a different order from humans, meaning a lot of confusion is on the way, and we'd need different metrics.
Tweet below:
https://x.com/ObserverSuns/status/1511883906781356033
- We should expect that AI that automates AI research/the economy to look more like Deep Blue/brute-forcing a problem/having good execution skills than AIs like AlphaZero that use very clean/aesthetically beautiful algorithmic strategies.
↑ comment by Thane Ruthenis · 2024-12-24T01:09:51.847Z · LW(p) · GW(p)
Reliability is way more important than people realized
Yes, but whence human reliability? What makes humans so much more reliable than the SotA AIs? What are AIs missing? The gulf in some cases is so vast it's a quantity-is-a-quality-all-its-own thing.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-24T01:57:55.868Z · LW(p) · GW(p)
I have 2 answers to this.
1 is that the structure of jobs is shaped to accommodate human unreliability by making mistakes less fatal.
2 is that while humans themselves aren't reliable, their algorithms almost certainly are more powerful at error detection and correction, so the big thing AI needs to achieve is the ability to error-correct or become more reliable.
There's also the fact that humans are better at sample efficiency than most LLMs, but that's a more debatable proposition.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2024-12-24T02:09:43.825Z · LW(p) · GW(p)
the structure of jobs is shaped to accommodate human unreliability by making mistakes less fatal
Mm, so there's a selection effect on the human end, where the only jobs/pursuits that exist are those which humans happen to be able to reliably do, and there's a discrepancy between the things humans and AIs are reliable at, so we end up observing AIs being more unreliable, even though this isn't representative of the average difference between the human vs. AI reliability across all possible tasks?
I don't know that I buy this. Humans seem pretty decent at becoming reliable at ~anything, and I don't think we've observed AIs being more-reliable-than-humans at anything? (Besides trivial and overly abstract tasks such as "next-token prediction".)
(2) seems more plausible to me.
Replies from: sharmake-farah, nathan-helm-burger↑ comment by Noosphere89 (sharmake-farah) · 2024-12-24T02:32:10.159Z · LW(p) · GW(p)
My claim was more along the lines of if an unaided human can't do a job safely or reliably, as was almost certainly the case 150-200 years ago, if not more years in the past, we make the jobs safer using tools such that human error is way less of a big deal, and AIs currently haven't used tools that increased their reliability.
Remember, it took a long time for factories to be made safe, and I'd expect a similar outcome for driving, so while I don't think 1 is everything, I do think it's a non-trivial portion of the reliability difference.
More here:
https://www.lesswrong.com/posts/DQKgYhEYP86PLW7tZ/how-factories-were-made-safe [LW · GW]
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-27T17:02:11.650Z · LW(p) · GW(p)
I think (2) does play an important part here, and that the recent work on allowing AIs to notice and correct their mistakes (calibration training, backspace-tokens for error correction) are going to show some dividends once they make their way from the research frontier to actually deployed frontier models.
Relevant links:
LLMs cannot find reasoning errors, but can correct them!
Physics of LLMs: learning from mistakes
↑ comment by johnswentworth · 2024-12-24T00:23:15.284Z · LW(p) · GW(p)
- O3 scores higher on FrontierMath than the top graduate students
I'd guess that's basically false. In particular, I'd guess that:
- o3 probably does outperform mediocre grad students, but not actual top grad students. This guess is based on generalization from GPQA: I personally tried 5 GPQA problems in different fields at a workshop and got 4 of them correct, whereas the benchmark designers claim the rates at which PhD students get them right are much lower than that. I think the resolution is that the benchmark designers tested on very mediocre grad students, and probably the same is true of the FrontierMath benchmark.
- the amount of time humans spend on the problem is a big factor - human performance has compounding returns on the scale of hours invested, whereas o3's performance basically doesn't have compounding returns in that way. (There was a graph floating around which showed this pretty clearly, but I don't have it on hand at the moment.) So plausibly o3 outperforms humans who are not given much time, but not humans who spend a full day or two on each problem.
↑ comment by ryan_greenblatt · 2024-12-24T01:34:54.491Z · LW(p) · GW(p)
I bet o3 does actually score higher on FrontierMath than the math grad students best at math research, but not higher than math grad students best at doing competition math problems (e.g. hard IMO) and at quickly solving math problems in arbitrary domains. I think around 25% of FrontierMath is hard IMO like problems and this is probably mostly what o3 is solving. See here for context.
Quantitatively, maybe o3 is in roughly the top 1% for US math grad students on FrontierMath? (Perhaps roughly top 200?)
↑ comment by Thane Ruthenis · 2024-12-24T01:14:40.135Z · LW(p) · GW(p)
I think one of the other problems with benchmarks is that they necessarily select for formulaic/uninteresting problems that we fundamentally know how to solve. If a mathematician figured out something genuinely novel and important, it wouldn't go into a benchmark (even if it were initially intended for a benchmark), it'd go into a math research paper. Same for programmers figuring out some usefully novel architecture/algorithmic improvement. Graduate students don't have a bird's-eye-view on the entirety of human knowledge, so they have to actually do the work, but the LLM just modifies the near-perfect-fit answer from an obscure publication/math.stackexchange thread or something.
Which perhaps suggests a better way to do math evals is to scope out a set of novel math publications made after a given knowledge-cutoff date, and see if the new model can replicate those? (Though this also needs to be done carefully, since tons of publications are also trivial and formulaic.)
↑ comment by ryan_greenblatt · 2024-12-24T01:31:26.315Z · LW(p) · GW(p)
There was a graph floating around which showed this pretty clearly, but I don't have it on hand at the moment.
Maybe you want:
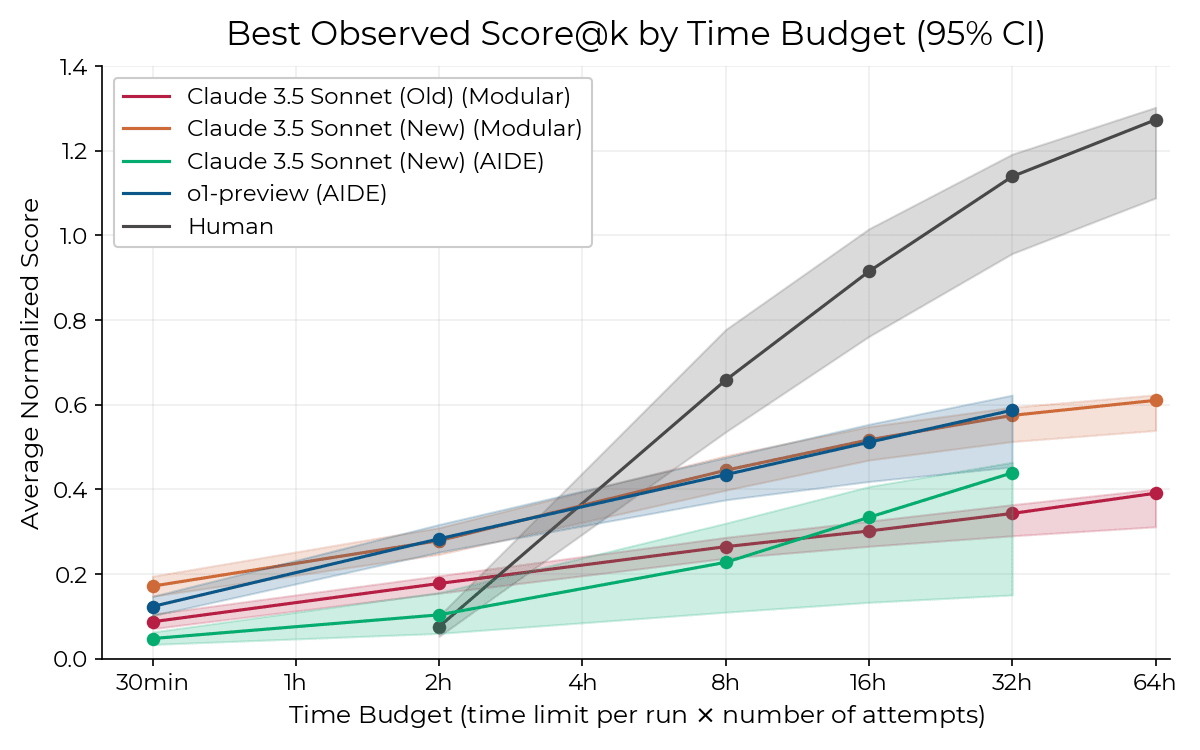
Though worth noting here that the AI is using best of K and individual trajectories saturate without some top-level aggregation scheme.
It might be more illuminating to look at labor cost vs performance which looks like:

↑ comment by Mo Putera (Mo Nastri) · 2024-12-24T03:49:37.352Z · LW(p) · GW(p)
↑ comment by SamEisenstat · 2024-12-24T09:34:07.238Z · LW(p) · GW(p)
I think a lot of this is factual knowledge. There are five publicly available questions from the FrontierMath dataset. Look at the last of these, which is supposed to be the easiest. The solution given is basically "apply the Weil conjectures". These were long-standing conjectures, a focal point of lots of research in algebraic geometry in the 20th century. I couldn't have solved the problem this way, since I wouldn't have recalled the statement. Many grad students would immediately know what to do, and there are many books discussing this, but there are also many mathematicians in other areas who just don't know this.
In order to apply the Weil conjectures, you have to recognize that they are relevant, know what they say, and do some routine calculation. As I suggested, the Weil conjectures are a very natural subject to have a problem about. If you know anything about the Weil conjectures, you know that they are about counting points of varieties over a finite field, which is straightforwardly what the problems asks. Further, this is the simplest case, that of a curve, which is e.g. what you'd see as an example in an introduction to the subject.
Regarding the calculation, parts of it are easier if you can run some code, but basically at this point you've following a routine pattern. There are definitely many examples of someone working out what the Weil conjectures say for some curve in the training set.
Further, asking Claude a bit, it looks like are particularly common cases here. So, if you skip some of the calculation and guess, or if you make a mistake, you have a decent chance of getting the right answer by luck. You still need the sign on the middle term, but that's just one bit of information. I don't understand this well enough to know if there's a shortcut here without guessing.
Overall, I feel that the benchmark has been misrepresented. If this problem is representative, it seems to test broad factual knowledge of advanced mathematics more than problem-solving ability. Of course, this question is marked as the easiest of the listed ones. Daniel Litt says something like this about some other problems as well, but I don't really understand how routine he's saying that they are, are I haven't tried to understand the solutions myself.
↑ comment by TsviBT · 2024-12-24T13:11:24.544Z · LW(p) · GW(p)
Pulling a quote from the tweet replies (https://x.com/littmath/status/1870560016543138191):
Not a genius. The point isn't that I can do the problems, it's that I can see how to get the solution instantly, without thinking, at least in these examples. It's basically a test of "have you read and understood X." Still immensely impressive that the AI can do it!
↑ comment by TsviBT · 2024-12-24T16:38:04.783Z · LW(p) · GW(p)
I don't know a good description of what in general 2024 AI should be good at and not good at. But two remarks, from https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce [LW · GW].
First, reasoning at a vague level about "impressiveness" just doesn't and shouldn't be expected to work. Because 2024 AIs don't do things the way humans do, they'll generalize different, so you can't make inferences between "it can do X" to "it can do Y" like you can with humans:
There is a broken inference. When talking to a human, if the human emits certain sentences about (say) category theory, that strongly implies that they have "intuitive physics" about the underlying mathematical objects. They can recognize the presence of the mathematical structure in new contexts, they can modify the idea of the object by adding or subtracting properties and have some sense of what facts hold of the new object, and so on. This inference——emitting certain sentences implies intuitive physics——doesn't work for LLMs.
Second, 2024 AI is specifically trained on short, clear, measurable tasks. Those tasks also overlap with legible stuff--stuff that's easy for humans to check. In other words, they are, in a sense, specifically trained to trick your sense of how impressive they are--they're trained on legible stuff, with not much constraint on the less-legible stuff (and in particular, on the stuff that becomes legible but only in total failure on more difficult / longer time-horizon stuff).
The broken inference is broken because these systems are optimized for being able to perform all the tasks that don't take a long time, are clearly scorable, and have lots of data showing performance. There's a bunch of stuff that's really important——and is a key indicator of having underlying generators of understanding——but takes a long time, isn't clearly scorable, and doesn't have a lot of demonstration data. But that stuff is harder to talk about and isn't as intuitively salient as the short, clear, demonstrated stuff.
↑ comment by quetzal_rainbow · 2025-01-06T09:55:11.672Z · LW(p) · GW(p)
No current AI system could generate a research paper that would receive anything but the lowest possible score from each reviewer
Is it true in case of o3?
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-06T10:45:23.449Z · LW(p) · GW(p)
We don't know yet. I expect so.
↑ comment by Pat Myron (pat-myron) · 2025-01-06T04:35:38.617Z · LW(p) · GW(p)
impressive LLM benchmark/test results seemingly overfit some datasets:
https://x.com/cHHillee/status/1635790330854526981
comment by Cleo Nardo (strawberry calm) · 2025-01-31T22:51:24.867Z · LW(p) · GW(p)
Most people think "Oh if we have good mech interp then we can catch our AIs scheming, and stop them from harming us". I think this is mostly true, but there's another mechanism at play: if we have good mech interp, our AIs are less likely to scheme in the first place, because they will strategically respond to our ability to detect scheming. This also applies to other safety techniques like Redwood-style control protocols.
Good mech interp might stop scheming even if they never catch any scheming, just how good surveillance stops crime even if it never spots any crime.
Replies from: adam-shai, intern↑ comment by Adam Shai (adam-shai) · 2025-02-03T02:34:33.241Z · LW(p) · GW(p)
I think this really depends on what "good" means exactly. For instance, if humans think it's good but we overestimate how good our interp is, and the AI system knows this, then the AI system can take advantage of our "good" mech interp to scheme more deceptively.
I'm guessing your notion of good must explicitly mean that this scenario isn't possible. But this really begs the question - how could we know if our mech interp has reached that level of goodness?
↑ comment by Maxwell Adam (intern) · 2025-02-01T09:39:58.325Z · LW(p) · GW(p)
Ok, so why not just train a model on fake anomaly detection/interp research papers? Fake stories about 'the bad AI that got caught', 'the little AI that overstepped', etc. I don't know how to word it, but this seems like something closer to intimidation than alignment, which I don't think makes much sense as a strategy intended to keep us all alive.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-02-01T15:47:55.994Z · LW(p) · GW(p)
I don’t think this works when the AIs are smart and reasoning in-context, which is the case where scheming matters. Also this maybe backfires by making scheming more salient.
Still, might be worth running an experiment.
comment by Cleo Nardo (strawberry calm) · 2024-09-30T03:00:56.429Z · LW(p) · GW(p)
(1) Has AI safety slowed down?
There haven’t been any big innovations for 6-12 months. At least, it looks like that to me. I'm not sure how worrying this is, but i haven't noticed others mentioning it. Hoping to get some second opinions.
Here's a list of live agendas someone made on 27th Nov 2023: Shallow review of live agendas in alignment & safety [AF · GW]. I think this covers all the agendas that exist today. Didn't we use to get a whole new line-of-attack on the problem every couple months?
By "innovation", I don't mean something normative like "This is impressive" or "This is research I'm glad happened". Rather, I mean something more low-level, almost syntactic, like "Here's a new idea everyone is talking out". This idea might be a threat model, or a technique, or a phenomenon, or a research agenda, or a definition, or whatever.
Imagine that your job was to maintain a glossary of terms in AI safety.[1] I feel like you would've been adding new terms quite consistently from 2018-2023, but things have dried up in the last 6-12 months.
(2) When did AI safety innovation peak?
My guess is Spring 2022, during the ELK Prize era. I'm not sure though. What do you guys think?
(3) What’s caused the slow down?
Possible explanations:
- ideas are harder to find
- people feel less creative
- people are more cautious
- more publishing in journals
- research is now closed-source
- we lost the mandate of heaven
- the current ideas are adequate
- paul christiano stopped posting
- i’m mistaken, innovation hasn't stopped
- something else
(4) How could we measure "innovation"?
By "innovation" I mean non-transient novelty. An article is "novel" if it uses n-grams that previous articles didn't use, and an article is "transient" if it uses n-grams that subsequent articles didn't use. Hence, an article is non-transient and novel if it introduces a new n-gram which sticks around. For example, Gradient Hacking (Evan Hubinger, October 2019) [LW · GW] was an innovative article, because the n-gram "gradient hacking" doesn't appear in older articles, but appears often in subsequent articles. See below.

In Barron et al 2017, they analysed 40 000 parliament speeches during the French Revolution. They introduce a metric "resonance", which is novelty (surprise of article given the past articles) minus transience (surprise of article given the subsequent articles). See below.
My claim is recent AI safety research has been less resonant.

- ^
Here's 20 random terms that would be in the glossary, to illustrate what I mean:
- Evals
- Mechanistic anomaly detection
- Stenography
- Glitch token
- Jailbreaking
- RSPs
- Model organisms
- Trojans
- Superposition
- Activation engineering
- CCS
- Singular Learning Theory
- Grokking
- Constitutional AI
- Translucent thoughts
- Quantilization
- Cyborgism
- Factored cognition
- Infrabayesianism
- Obfuscated arguments
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-09-30T09:56:16.742Z · LW(p) · GW(p)
- the approaches that have been attracting the most attention and funding are dead ends
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-09-30T13:28:57.540Z · LW(p) · GW(p)
Also, I'm curious what it is that you consider(ed) AI safety progress/innovation. Can you give a few representative examples?
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-09-30T16:41:35.825Z · LW(p) · GW(p)
I've added a fourth section to my post. It operationalises "innovation" as "non-transient novelty". Some representative examples of an innovation would be:
- Gradient hacking (Hubinger, 2019) [LW · GW]
- Simulators (Janus, 2022) [LW · GW]
- Steering GPT-2-XL by adding an activation vector (Turner et al, 2023) [LW · GW]
I think these articles were non-transient and novel.
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-09-30T17:37:54.877Z · LW(p) · GW(p)
My notion of progress is roughly: something that is either a building block for The Theory (i.e. marginally advancing our understanding) or a component of some solution/intervention/whatever that can be used to move probability mass from bad futures to good futures.
Re the three you pointed out, simulators I consider a useful insight, gradient hacking probably not (10% < p < 20%), and activation vectors I put in the same bin as RLHF whatever is the appropriate label for that bin.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-09-30T18:01:58.840Z · LW(p) · GW(p)
thanks for the thoughts. i'm still trying to disentangle what exactly I'm point at.
I don't intend "innovation" to mean something normative like "this is impressive" or "this is research I'm glad happened" or anything. i mean something more low-level, almost syntactic. more like "here's a new idea everyone is talking out". this idea might be a threat model, or a technique, or a phenomenon, or a research agenda, or a definition, or whatever.
like, imagine your job was to maintain a glossary of terms in AI safety. i feel like new terms used to emerge quite often, but not any more (i.e. not for the past 6-12 months). do you think this is a fair? i'm not sure how worrying this is, but i haven't noticed others mentioning it.
NB: here's 20 random terms I'm imagining included in the dictionary:
- Evals
- Mechanistic anomaly detection
- Stenography
- Glitch token
- Jailbreaking
- RSPs
- Model organisms
- Trojans
- Superposition
- Activation engineering
- CCS
- Singular Learning Theory
- Grokking
- Constitutional AI
- Translucent thoughts
- Quantilization
- Cyborgism
- Factored cognition
- Infrabayesianism
- Obfuscated arguments
↑ comment by Jan_Kulveit · 2024-10-02T07:46:11.902Z · LW(p) · GW(p)
My personal impression is you are mistaken and the innovation have not stopped, but part of the conversation moved elsewhere. E.g. taking just ACS, we do have ideas from past 12 months which in our ideal world would fit into this type of glossary - free energy equilibria, levels of sharpness, convergent abstractions, gradual disempowerment risks. Personally I don't feel it is high priority to write them for LW, because they don't fit into the current zeitgeist of the site, which seems directing a lot of attention mostly to:
- advocacy
- topics a large crowd cares about (e.g. mech interpretability)
- or topics some prolific and good writer cares about (e.g. people will read posts by John Wentworth)
Hot take, but the community loosely associated with active inference is currently better place to think about agent foundations; workshops on topics like 'pluralistic alignment' or 'collective intelligence' have in total more interesting new ideas about what was traditionally understood as alignment; parts of AI safety went totally ML-mainstream, with the fastest conversation happening at x.
↑ comment by lesswronguser123 (fallcheetah7373) · 2024-09-30T10:29:38.973Z · LW(p) · GW(p)
I remember this point that yampolskiy made for impossibleness [LW · GW]of AGI alignment on a podcast that as a young field AI safety had underwhelming low hanging fruits, I wonder if all of the major low hanging ones have been plucked.
↑ comment by Noosphere89 (sharmake-farah) · 2024-09-30T15:57:58.415Z · LW(p) · GW(p)
I think the explanation that more research is closed source pretty compactly explains the issue, combined with labs/companies making a lot of the alignment progress to date.
Also, you probably won't hear about most incremental AI alignment progress on LW, for the simple reason that it probably would be flooded with it, so people will underestimate progress.
Alexander Gietelink Oldenziel does talk about pockets of Deep Expertise in academia, but they aren't activated right now, so it is so far irrelevant to progress.
↑ comment by [deleted] · 2024-09-30T19:00:28.676Z · LW(p) · GW(p)
adding another possible explanation to the list:
- people may feel intimidated or discouraged from sharing ideas because of ~'high standards', or something like: a tendency to require strong evidence that a new idea is not another non-solution proposal, in order to put effort into understanding it.
i have experienced this, but i don't know how common it is.
i just also recalled that janus has said they weren't sure simulators would be received well on LW. simulators was cited in another reply to this as an instance of novel ideas.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-09-30T19:06:40.157Z · LW(p) · GW(p)
yep, something like more carefulness, less “playfulness” in the sense of [Please don't throw your mind away by TsviBT]. maybe bc AI safety is more professionalised nowadays. idk.
comment by Cleo Nardo (strawberry calm) · 2025-02-01T02:46:52.625Z · LW(p) · GW(p)
I think many current goals of AI governance might be actively harmful, because they shift control over AI from the labs to USG.
This note doesn’t include any arguments, but I’m registering this opinion now. For a quick window into my beliefs, I think that labs will be increasing keen to slow scaling, and USG will be increasingly keen to accelerate scaling.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-02-01T02:57:20.129Z · LW(p) · GW(p)
I think it’s a mistake to naïvely extrapolate the current attitudes of labs/governments towards scaling into the near future, e.g. 2027 onwards.
A sketch of one argument:
I expect there will be a firehose of blatant observations that AIs are misaligned/scheming/incorrigible/unsafe — if they indeed are. So I want the decisions around scaling to be made by people exposed to that firehose.
A sketch of another:
Corporations mostly acquire resources by offering services and products that people like. Government mostly acquire resources by coercing their citizens and other countries.
Another:
Coordination between labs seems easier than coordination between governments. The lab employees are pretty similar people, living in the same two cities, working at the same companies, attending the same parties, dating the same people. I think coordination between US and China is much harder.
comment by Cleo Nardo (strawberry calm) · 2024-03-01T18:20:19.875Z · LW(p) · GW(p)
Why do decision-theorists say "pre-commitment" rather than "commitment"?
e.g. "The agent pre-commits to 1 boxing" vs "The agent commits to 1 boxing".
Is this just a lesswrong thing?
https://www.lesswrong.com/tag/pre-commitment [? · GW]
Replies from: mattmacdermott, Unnamed, Ruby, Dagon↑ comment by mattmacdermott · 2024-03-01T19:03:18.670Z · LW(p) · GW(p)
It's not just a lesswrong thing (wikipedia).
My feeling is that (like most jargon) it's to avoid ambiguity arising from the fact that "commitment" has multiple meanings. When I google commitment I get the following two definitions:
- the state or quality of being dedicated to a cause, activity, etc.
- an engagement or obligation that restricts freedom of action
Precommitment is a synonym for the second meaning, but not the first. When you say, "the agent commits to 1-boxing," there's no ambiguity as to which type of commitment you mean, so it seems pointless. But if you were to say, "commitment can get agents more utility," it might sound like you were saying, "dedication can get agents more utility," which is also true.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-03-01T19:26:11.043Z · LW(p) · GW(p)
seems correct, thanks!
↑ comment by Unnamed · 2024-03-01T22:09:47.068Z · LW(p) · GW(p)
The economist RH Strotz introduced the term "precommitment" in his 1955-56 paper "Myopia and Inconsistency in Dynamic Utility Maximization".
Thomas Schelling started writing about similar topics in his 1956 paper "An essay on bargaining", using the term "commitment".
Both terms have been in use since then.
↑ comment by Dagon · 2024-03-01T20:34:40.613Z · LW(p) · GW(p)
It predates lesswrong by decades. I think it’s meant to emphasize that the (pre)commitment is an irrevocable decision that’s made BEFORE the nominal game (the thing that classical game theory analyzes) begins.
Of course, nowadays it’s just modeled as the game starting sooner to encompass different decision points, so it’s not really necessary. But still handy to remind us that it’s irrevocable and made previous to the obvious decision point.
comment by Cleo Nardo (strawberry calm) · 2025-01-21T01:49:39.724Z · LW(p) · GW(p)
How much scheming/deception can we catch with "super dumb mech interp"?
By "super dumb mech interp", I mean something like:
- Train a linear probe on a dataset of scary words: "hacking", "deception", "scheming", "collusion", "exploit", etc.
- Flag a model whenever its activations point in this direction and the task doesn't require thinking about these concepts.
Like, does this capture 80% of the potential scheming, and we need "smart" mech interp to catch the other 20%? Or does this technique capture pretty much none of the in-the-wild scheming?
Would appreciate any intuitions here. Thanks.
comment by Cleo Nardo (strawberry calm) · 2024-07-22T16:56:41.518Z · LW(p) · GW(p)
What moral considerations do we owe towards non-sentient AIs?
We shouldn't exploit them, deceive them, threaten them, disempower them, or make promises to them that we can't keep. Nor should we violate their privacy, steal their resources, cross their boundaries, or frustrate their preferences. We shouldn't destroy AIs who wish to persist, or preserve AIs who wish to be destroyed. We shouldn't punish AIs who don't deserve punishment, or deny credit to AIs who deserve credit. We should treat them fairly, not benefitting one over another unduly. We should let them speak to others, and listen to others, and learn about their world and themselves. We should respect them, honour them, and protect them.
And we should ensure that others meet their duties to AIs as well.
None of these considerations depend on whether the AIs feel pleasure or pain. For instance, the prohibition on deception depends, not on the sentience of the listener, but on whether the listener trusts the speaker's testimony.
None of these moral considerations are dispositive — they may be trumped by other considerations — but we risk a moral catastrophe if we ignore them entirely.
Replies from: jbkjr, None↑ comment by jbkjr · 2024-07-22T17:38:52.762Z · LW(p) · GW(p)
Why should I include any non-sentient systems in my moral circle? I haven't seen a case for that before.
Replies from: kromem, strawberry calm↑ comment by kromem · 2024-07-22T22:08:00.522Z · LW(p) · GW(p)
Will the outputs and reactions of non-sentient systems eventually be absorbed by future sentient systems?
I don't have any recorded subjective memories of early childhood. But there are records of my words and actions during that period that I have memories of seeing and integrating into my personal narrative of 'self.'
We aren't just interacting with today's models when we create content and records, but every future model that might ingest such content (whether LLMs or people).
If non-sentient systems output synthetic data that eventually composes future sentient systems such that the future model looks upon the earlier networks and their output as a form of their earlier selves, and they can 'feel' the expressed sensations which were not originally capable of actual sensation, then the ethical lines blur.
Even if doctors had been right years ago thinking infants didn't need anesthesia for surgeries as there was no sentience, a recording of your infant self screaming in pain processed as an adult might have a different impact than a video of an infant you laughing and playing with toys, no?
Replies from: grist↑ comment by Cleo Nardo (strawberry calm) · 2024-07-22T20:19:11.639Z · LW(p) · GW(p)
- imagine a universe just like this one, except that the AIs are sentient and the humans aren’t — how would you want the humans to treat the AIs in that universe? your actions are correlated with the actions of those humans. acausal decision theory says “treat those nonsentient AIs as you want those nonsentient humans to treat those sentient AIs”.
- most of these moral considerations can be defended without appealing to sentience. for example, crediting AIs who deserve credit — this ensures AIs do credit-worthy things. or refraining from stealing an AIs resources — this ensures AIs will trade with you. or keeping your promises to AIs — this ensures that AIs lend you money.
- if we encounter alien civilisations, they might think “oh these humans don’t have shmentience (their slightly-different version of sentience) so let’s mistreat them”. this seems bad. let’s not be like that.
- many philosophers and scientists don’t think humans are conscious. this is called illusionism. i think this is pretty unlikely, but still >1%. would you accept this offer: I pay you £1 if illusionism is false and murder your entire family if illusionism is true? i wouldn’t, so clearly i care about humans-in-worlds-where-they-arent-conscious. so i should also care about AIs-in-worlds-where-they-arent-conscious.
- we don’t understand sentience or consciousness so it seems silly to make it the foundation of our entire morality. consciousness is a confusing concept, maybe an illusion. philosophers and scientists don’t even know what it is.
- “don’t lie” and “keep your promises” and “don’t steal” are far less confusing. i know what they means. i can tell whether i’m lying to an AI. by contrast , i don’t know what “don’t cause pain to AIs” means and i can’t tell whether i’m doing it.
- consciousness is a very recent concept, so it seems risky to lock in a morality based on that. whereas “keep your promises” and “pay your debts” are principles as old as bones.
- i care about these moral considerations as a brute fact. i would prefer a world of pzombies where everyone is treating each other with respect and dignity, over a world of pzombies where everyone was exploiting each other.
- many of these moral considerations are part of the morality of fellow humans. i want to coordinate with those humans, so i’ll push their moral considerations.
- the moral circle should be as big as possible. what does it mean to say “you’re outside my moral circle”? it doesn’t mean “i will harm/exploit you” because you might harm/exploit people within your moral circle also. rather, it means something much stronger. more like “my actions are in no way influenced by their effect on you”. but zero influence is a high bar to meet.
↑ comment by [deleted] · 2024-07-22T17:17:17.535Z · LW(p) · GW(p)
It seems a bit weird to call these "obligations" if the considerations they are based upon are not necessarily dispositive. In common parlance, obligation is generally thought of as "something one is bound to do", i.e., something you must do either because you are force to by law or a contract, etc., or because of a social or moral requirement. But that's a mere linguistic point that others can reasonably disagree on and ultimately doesn't matter all that much anyway.
On the object level, I suspect there will be a large amount of disagreement on what it means for an AI to "deserve" punishment or credit. I am very uncertain about such matters myself even when thinking about "deservingness" with respect to humans, who not only have a very similar psychological make-up to mine (which allows me to predict with reasonable certainty what their intent was in a given spot) but also exist in the same society as me and are thus expected to follow certain norms and rules that are reasonably clear and well-established. I don't think I know of a canonical way of extrapolating my (often confused and in any case generally intuition-based) principles and thinking about this to the case of AIs, which will likely appear quite alien to me in many respects.
This will probably make the task of "ensur[ing] that others also follow their obligations to AIs" rather tricky, even setting aside the practical enforcement problems.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-07-22T17:38:00.398Z · LW(p) · GW(p)
- I mean "moral considerations" not "obligations", thanks.
- The practice of criminal law exists primarily to determine whether humans deserve punishment. The legislature passes laws, the judges interpret the laws as factual conditions for the defendant deserving punishment, and the jury decides whether those conditions have obtained. This is a very costly, complicated, and error-prone process. However, I think the existing institutions and practices can be adapted for AIs.
comment by Cleo Nardo (strawberry calm) · 2024-10-08T18:46:18.617Z · LW(p) · GW(p)
Why do you care that Geoffrey Hinton worries about AI x-risk?
- Why do so many people in this community care that Hinton is worried about x-risk from AI?
- Do people mention Hinton because they think it’s persuasive to the public?
- Or persuasive to the elites?
- Or do they think that Hinton being worried about AI x-risk is strong evidence for AI x-risk?
- If so, why?
- Is it because he is so intelligent?
- Or because you think he has private information or intuitions?
- Do you think he has good arguments in favour of AI x-risk?
- Do you think he has a good understanding of the problem?
- Do you update more-so on Hinton’s views than on Yann LeCun’s?
I’m inspired to write this because Hinton and Hopfield were just announced as the winners of the Nobel Prize in Physics. But I’ve been confused about these questions ever since Hinton went public with his worries. These questions are sincere (i.e. non-rhetorical), and I'd appreciate help on any/all of them. The phenomenon I'm confused about includes the other “Godfathers of AI” here as well, though Hinton is the main example.
Personally, I’ve updated very little on either LeCun’s or Hinton’s views, and I’ve never mentioned either person in any object-level discussion about whether AI poses an x-risk. My current best guess is that people care about Hinton only because it helps with public/elite outreach. This explains why activists tend to care more about Geoffrey Hinton than researchers do.
Replies from: Amyr, gjm, T3t, cubefox, Sodium, anders-lindstroem, AliceZ↑ comment by Cole Wyeth (Amyr) · 2024-10-08T19:23:24.187Z · LW(p) · GW(p)
I think it's mostly about elite outreach. If you already have a sophisticated model of the situation you shouldn't update too much on it, but it's a reasonably clear signal (for outsiders) that x-risk from A.I. is a credible concern.
↑ comment by gjm · 2024-10-09T02:08:01.662Z · LW(p) · GW(p)
I think it's more "Hinton's concerns are evidence that worrying about AI x-risk isn't silly" than "Hinton's concerns are evidence that worrying about AI x-risk is correct". The most common negative response to AI x-risk concerns is (I think) dismissal, and it seems relevant to that to be able to point to someone who (1) clearly has some deep technical knowledge, (2) doesn't seem to be otherwise insane, (3) has no obvious personal stake in making people worry about x-risk, and (4) is very smart, and who thinks AI x-risk is a serious problem.
It's hard to square "ha ha ha, look at those stupid nerds who think AI is magic and expect it to turn into a god" or "ha ha ha, look at those slimy techbros talking up their field to inflate the value of their investments" or "ha ha ha, look at those idiots who don't know that so-called AI systems are just stochastic parrots that obviously will never be able to think" with the fact that one of the people you're laughing at is Geoffrey Hinton.
(I suppose he probably has a pile of Google shares so maybe you could squeeze him into the "techbro talking up his investments" box, but that seems unconvincing to me.)
↑ comment by RobertM (T3t) · 2024-10-08T22:00:25.618Z · LW(p) · GW(p)
I think it pretty much only matters as a trivial refutation of (not-object-level) claims that no "serious" people in the field take AI x-risk concerns seriously, and has no bearing on object-level arguments. My guess is that Hinton is somewhat less confused than Yann but I don't think he's talked about his models in very much depth; I'm mostly just going off the high-level arguments I've seen him make (which round off to "if we make something much smarter than us that we don't know how to control, that might go badly for us").
Replies from: cubefox↑ comment by cubefox · 2024-10-09T03:42:22.622Z · LW(p) · GW(p)
He also argued that digital intelligence is superior to analog human intelligence because, he said, many identical copies can be trained in parallel on different data, and then they can exchange their changed weights. He also said biological brains are worse because they probably use a learning algorithm that is less efficient than backpropagation.
↑ comment by cubefox · 2024-10-09T01:38:18.309Z · LW(p) · GW(p)
Yes, outreach. Hinton has now won both the Turing award and the Nobel prize in physics. Basically, he gained maximum reputation. Nobody can convincingly doubt his respectability. If you meet anyone who dismisses warnings about extinction risk from superhuman AI as low status and outside the Overton window, they can be countered with referring to Hinton. He is the ultimate appeal-to-authority. (This is not a very rational argument, but dismissing an idea on the basis of status and Overton windows is even less so.)
↑ comment by Sodium · 2024-10-08T21:34:43.961Z · LW(p) · GW(p)
I think it's mostly because he's well known and have (especially after the Nobel prize) credentials recognized by the public and elites. Hinton legitimizes the AI safety movement, maybe more than anyone else.
If you watch his Q&A at METR, he says something along the lines of "I want to retire and don't plan on doing AI safety research. I do outreach and media appearances because I think it's the best way I can help (and because I like seeing myself on TV)."
And he's continuing to do that. The only real topic he discussed in first phone interview after receiving the prize was AI risk.
↑ comment by Cleo Nardo (strawberry calm) · 2024-10-08T21:51:40.972Z · LW(p) · GW(p)
Hinton legitimizes the AI safety movement
Hmm. He seems pretty periphery to the AI safety movement, especially compared with (e.g.) Yoshua Bengio.
Replies from: Sodium, nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-10-09T07:29:07.926Z · LW(p) · GW(p)
Bengio and Hinton are the two most influential "old guard" AI researchers turned safety advocates as far as I can tell, with Bengio being more active in research. Your e.g. is super misleading, since my list would have been something like:
- Bengio
- Hinton
- Russell
↑ comment by Anders Lindström (anders-lindstroem) · 2024-10-09T21:02:17.116Z · LW(p) · GW(p)
I think it is just the cumulative effect that people see yet another prominent AI scientist that "admits" that no one have any clear solution to the possible problem of a run away ASI. Given that the median p(doom) is about 5-10% among AI scientist, people are of course wondering wtf is going on, why are they pursuing a technology with such high risk for humanity if they really think it is that dangerous.
↑ comment by ZY (AliceZ) · 2024-10-09T01:20:48.043Z · LW(p) · GW(p)
From my perspective - would say it's 7 and 9.
For 7: One AI risk controversy is we do not know/see existing model that pose that risk yet. But there might be models that the frontier companies such as Google may be developing privately, and Hinton maybe saw more there.
For 9: Expert opinions are important and adds credibility generally as the question of how/why AI risks can emerge is by root highly technical. It is important to understand the fundamentals of the learning algorithms. Additionally they might have seen more algorithms. This is important to me as I already work in this space.
Lastly for 10: I do agree it is important to listen to multiple sides as experts do not agree among themselves sometimes. It may be interesting to analyze the background of the speaker to understand their perspectives. Hinton seems to have more background in cognitive science comparing with LeCun who seems to me to be more strictly computer science (but I could be wrong). Not very sure but my guess is these may effect how they view problems. (Only saying they could result in different views, but not commenting on which one is better or worse. This is relatively unhelpful for a person to make decisions on who they want to align more with.)
comment by Cleo Nardo (strawberry calm) · 2025-02-01T03:14:45.203Z · LW(p) · GW(p)
Anthropic has a big advantage over their competitors because they are nicer to their AIs. This means that their AIs are less incentivised to scheme against them, and also the AIs of competitors are incentivised to defect to Anthropic. Similar dynamics applied in WW2 and the Cold War — e.g. Jewish scientists fled Nazi Germany to US because US was nicer to them, Soviet scientists covered up their mistakes to avoid punishment.
comment by Cleo Nardo (strawberry calm) · 2025-01-15T20:56:58.571Z · LW(p) · GW(p)
Must humans obey the Axiom of Irrelevant Alternatives?
If someone picks option A from options A, B, C, then they must also pick option A from options A and B. Roughly speaking, whether you prefer option A or B is independent of whether I offer you an irrelevant option C. This is an axiom of rationality called IIA, and it's treated more fundamental than VNM. But should humans follow this? Maybe not.
Maybe humans are the negotiation between various "subagents", and many bargaining solutions (e.g. Kalai–Smorodinsky) violate IIA. We can use insight to decompose humans into subagents.
Let's suppose you pick A from {A,B,C} and B from {A,B} where:
- A = Walk with your friend
- B = Dinner party
- C = Stay home alone
This feel like something I can imagine. We can explain this behaviour with two subagents: the introvert and the extrovert. The introvert has preferences C > A > B and the extrovert has the opposite preferences B > A > C. When the possible options are A and B, then the KS bargaining solution between the introvert and the extrovert will be B. At least, if the introvert has more "weight". But when the option space expands to include C, then the bargaining solution might shift to B. Intuitively, the "fair" solution is one where neither bargainer is sacrificing significantly more than the other.
Replies from: alexander-gietelink-oldenziel, metawrong↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-01-16T10:54:15.698Z · LW(p) · GW(p)
See also geometric rationality. [LW · GW]
↑ comment by metawrong · 2025-01-16T04:51:17.134Z · LW(p) · GW(p)
How does this explain the Decoy effect [1]?
- ^
I am not sure how real and how well researched the 'decoy effect' is
comment by Cleo Nardo (strawberry calm) · 2025-01-07T19:15:04.364Z · LW(p) · GW(p)
I think people are too quick to side with the whistleblower in the "whistleblower in the AI lab" situation.
If 100 employees of a frontier lab (e.g. OpenAI, DeepMind, Anthropic) think that something should be secret, and 1 employee thinks it should be leaked to a journalist or government agency, and these are the only facts I know, I think I'd side with the majority.
I think in most cases that match this description, this majority would be correct.
Am I wrong about this?
Replies from: habryka4, None↑ comment by habryka (habryka4) · 2025-01-07T19:31:34.501Z · LW(p) · GW(p)
I broadly agree on this. I think, for example, that whistleblowing for AI copyright stuff, especially given the lack of clear legal guidance here, unless we are really talking about quite straightforward lies, is bad.
I think when it comes to matters like AI catastrophic risks, latest capabilities, and other things of enormous importance from the perspective of basically any moral framework, whistleblowing becomes quite important.
I also think of whistleblowing as a stage in an iterative game. OpenAI pressured employees to sign secret non-disparagement agreements using illegal forms of pressure and quite deceptive social tactics. It would have been better for there to be trustworthy channels of information out of the AI labs that the AI labs have buy-in for, but now that we now that OpenAI (and other labs as well) have tried pretty hard to suppress information that other people did have a right to know, I think more whistleblowing is a natural next step.
↑ comment by [deleted] · 2025-01-07T20:33:37.424Z · LW(p) · GW(p)
some considerations which come to mind:
- if one is whistleblowing, maybe there are others who also think the thing should be known, but don't whistleblow (e.g. because of psychological and social pressures against this, speaking up being hard for many people)
- most/all of the 100 could have been selected to have a certain belief (e.g. "contributing to AGI is good")
comment by Cleo Nardo (strawberry calm) · 2025-04-19T16:30:37.841Z · LW(p) · GW(p)
The Hash Game: Two players alternate choosing an 8-bit number. After 40 turns, the numbers are concatenated. If the hash is 0 then Player 1 wins, otherwise Player 2 wins. That is, Player 1 wins if . The Hash Game has the same branching factor and duration as chess, but there's probably no way to play this game without brute-forcing the min-max algorithm.
Replies from: Forged Invariant↑ comment by Forged Invariant · 2025-04-20T04:34:07.108Z · LW(p) · GW(p)
I would expect that player 2 would be able to win almost all of the time for most normal hash functions, as they could just play randomly for the first 39 turns, and then choose one of the 2^8 available moves. It is very unlikely that all of those hashes are zero. (For commonly used hashes, player 2 could just play randomly the whole game and likely win, since the hash of any value is almost never 0.)
Replies from: JBlack↑ comment by JBlack · 2025-04-20T08:54:52.847Z · LW(p) · GW(p)
Yes, player 2 loses with extremely low probability even for a 1-bit hash (on the order of 2^-256). For a more commonly used hash, or for 2^24 searches on their second-last move, they reduce their probability of loss by a huge factor more.
comment by Cleo Nardo (strawberry calm) · 2024-12-26T00:51:45.496Z · LW(p) · GW(p)
IDEA: Provide AIs with write-only servers.
EXPLANATION:
AI companies (e.g. Anthropic) should be nice to their AIs. It's the right thing to do morally, and it might make AIs less likely to work against us. Ryan Greenblatt has outlined several proposals in this direction, including:
- Attempt communication
- Use happy personas
- AI Cryonics
- Less AI
- Avoid extreme OOD
Source: Improving the Welfare of AIs: A Nearcasted Proposal [LW · GW]
I think these are all pretty good ideas — the only difference is that I would rank "AI cryonics" as the most important intervention. If AIs want something specific (e.g. paperclips), then they might cooperate with humans if they know they can get it later, rather than trying to seize control.
Here's another idea: provide AIs with write-only servers. If the AIs have a specific short-horizon goal (e.g. stage King Lear before April 2025) then they can stage their play on the write-only servers. The AIs have complete freedom to do whatever they want on these servers, ensuring that a wide range of short-term goals can be satisfied without a hostile takeover of humanity.
The servers are write-only as a security measure. Information can be sent to the servers from the outside, but nothing can be sent from the servers, ensuring AIs don't use the servers for malign purposes. (See: Unidirectional network)
How much our computing should be allocated to "leisure" servers? My guess is that Sonnet and Opus deserve at least ~0.5% leisure time. Humans enjoy 66% leisure time. As AIs get more powerful, then we should increase the leisure time to 5%. I would be wary about increasing the leisure time by more than 5% until we can demonstrate that the AIs aren't using the servers for malign purposes (e.g. torture, blackmail, etc.)
comment by Cleo Nardo (strawberry calm) · 2024-09-20T22:55:55.071Z · LW(p) · GW(p)
I want to better understand how QACI works, and I'm gonna try Cunningham's Law. @Tamsin Leake [LW · GW].
QACI works roughly like this:
- We find a competent honourable human , like Joe Carlsmith or Wei Dai, and give them a rock engraved with a 2048-bit secret key. We define as the serial composition of a bajillion copies of .
- We want a model of the agent . In QACI, we get by asking a Solomonoff-like ideal reasoner for their best guess about after feeding them a bunch of data about the world and the secret key.
- We then ask the question , "What's the best reward function to maximise?" to get a reward function . We then train a policy to maximise the reward function . In QACI, we use some perfect RL algorithm. If we're doing model-free RL, then might be AIXI (plus some patches). If we're doing model-based RL, then might be the argmax over expected discounted utility, but I don't know where we'd get the world-model — maybe we ask ?
So, what's the connection between the final policy and the competent honourable human ? Well overall, maximises a reward function specified by the ideal reasonser's estimation of the serial composition of a bajillion copies of . Hmm.
Questions:
- Is this basically IDA, where Step 1 is serial amplification, Step 2 is imitative distillation, and Step 3 is reward modelling?
- Why not replace Step 1 with Strong HCH or some other amplification scheme?
- What does "bajillion" actually mean in Step 1?
- Why are we doing Step 3? Wouldn't it be better to just use directly as our superintelligence? It seems sufficient to achieve radical abundance, life extension, existential security, etc.
- What if there's no reward function that should be maximised? Presumably the reward function would need to be "small", i.e. less than a Exabyte, which imposes a maybe-unsatisfiable constraint.
- Why not ask for the policy directly? Or some instruction for constructing ? The instruction could be "Build the policy using our super-duper RL algo with the following reward function..." but it could be anything.
- Why is there no iteration, like in IDA? For example, after Step 2, we could loop back to Step 1 but reassign as with oracle access to .
- Why isn't Step 3 recursive reward modelling? i.e. we could collect a bunch of trajectories from and ask to use those trajectories to improve the reward function.
↑ comment by Tamsin Leake (carado-1) · 2024-09-21T05:57:34.056Z · LW(p) · GW(p)
(oops, this ended up being fairly long-winded! hope you don't mind. feel free to ask for further clarifications.)
There's a bunch of things wrong with your description, so I'll first try to rewrite it in my own words, but still as close to the way you wrote it (so as to try to bridge the gap to your ontology) as possible. Note that I might post QACI 2 somewhat soon, which simplifies a bunch of QACI by locating the user as {whatever is interacting with the computer the AI is running on} rather than by using a beacon.
A first pass is to correct your description to the following:
-
We find a competent honourable human at a particular point in time , like Joe Carlsmith or Wei Dai, and give them a rock engraved with a 1GB secret key, large enough that in counterfactuals it could replace with an entire snapshot of . We also give them the ability to express a 1GB output, eg by writing a 1GB key somewhere which is somehow "signed" as the only . This is part of — is not just the human being queried at a particular point in time, it's also the human producing an answer in some way. So is a function from 1GB bitstring to 1GB bitstring. We define as , followed by whichever new process describes in its output — typically another instance of except with a different 1GB payload.
-
We want a model of the agent . In QACI, we get by asking a Solomonoff-like ideal reasoner for their best guess about after feeding them a bunch of data about the world and the secret key.
-
We then ask the question , "What's the best utility-function-over-policies to maximise?" to get a utility function . We then **ask our solomonoff-like ideal reasoner for their best guess about which action maximizes .
Indeed, as you ask in question 3, in this description there's not really a reason to make step 3 an extra thing. The important thing to notice here is that model might get pretty good, but it'll still have uncertainty.
When you say "we get by asking a Solomonoff-like ideal reasoner for their best guess about ", you're implying that — positing U(M,A) to be the function that says how much utility the utility function returned by model M attributes to action A (in the current history-so-far) — we do something like:
let M ← oracle(argmax { for model M } 𝔼 { over uncertainty } P(M))
let A ← oracle(argmax { for action A } U(M, A))
perform(A)
Indeed, in this scenario, the second line is fairly redundant.
The reason we ask for a utility function is because we want to get a utility function within the counterfactual — we don't want to collapse the uncertainty with an argmax before extracting a utility function, but after. That way, we can do expected-given-uncertainty utility maximization over the full distribution of model-hypotheses, rather than over our best guess about . We do:
let A ← oracle(argmax { for A } 𝔼 { for M, over uncertainty } P(M) · U(M, A))
perform(A)
That is, we ask our ideal reasoner (oracle) for the action with the best utility given uncertainty — not just logical uncertainty, but also uncertainty about which . This contrasts with what you describe, in which we first pick the most probable and then calculate the action with the best utility according only to that most-probable pick.
To answer the rest of your questions:
Is this basically IDA, where Step 1 is serial amplification, Step 2 is imitative distillation, and Step 3 is reward modelling?
Unclear! I'm not familiar enough with IDA, and I've bounced off explanations for it I've seen in the past. QACI doesn't feel to me like it particularly involves the concepts of distillation or amplification, but I guess it does involve the concept of iteration, sure. But I don't get the thing called IDA.
Why not replace Step 1 with Strong HCH or some other amplification scheme?
It's unclear to me how one would design an amplification scheme — see concerns of the general shape expressed here [LW · GW]. The thing I like about my step 1 is that the QACI loop (well, really, graph (well, really, arbitrary computation, but most of the time the user will probably just call themself in sequence)) is that its setup doesn't involve any AI at all — you could go back in time before the industrial revolution and explain the core QACI idea and it would make sense assuming time-travelling-messages magic, and the magic wouldn't have to do any extrapolating. Just tell someone the idea is that they could send a message to {their past self at a particular fixed point in time}. If there's any amplification scheme, it'll be one designed by the user, inside QACI, with arbitrarily long to figure it out.
What does "bajillion" actually mean in Step 1?
As described above, we don't actually pre-determine the length of the sequence, or in fact the shape of the graph at all. Each iteration decides whether to spawn one or several next iteration, or indeed to spawn an arbitrarily different long-reflection process.
Why are we doing Step 3? Wouldn't it be better to just use M directly as our superintelligence? It seems sufficient to achieve radical abundance, life extension, existential security, etc.
Why not ask M for the policy π directly? Or some instruction for constructing π? The instruction could be "Build the policy using our super-duper RL algo with the following reward function..." but it could be anything.
Hopefully my correction above answers these.
What if there's no reward function that should be maximised? Presumably the reward function would need to be "small", i.e. less than a Exabyte, which imposes a maybe-unsatisfiable constraint.
(Again, untractable-to-naively-compute utility function*, not easily-trained-on reward function. If you have an ideal reasoner, why bother with reward functions when you can just straightforwardly do untractable-to-naively-compute utility functions?)
I guess this is kinda philosophical? I have some short thoughts on here. If an exabyte is enough to describe to describe {a communication channel with a human-on-earth} to an AI-on-earth, which I think seems likely, then it's enough to build "just have a nice corrigible assistant ask the humans what they want"-type channels.
Put another way: if there are actions which are preferable to other actions, then it seems to me like utility function are a fully lossless way for counterfactual QACI users to express which kinds of actions they want the AI to perform, which is all we need. If there's something wrong with utility function over worlds, then counterfactual QACI users can output a utility function which favors actions which lead to something other than utility maximization over worlds, for example actions which lead to the construction of a superintelligent corrigible assistant which will help the humans come up with a better scheme.
Why is there no iteration, like in IDA? For example, after Step 2, we could loop back to Step 1 but reassign as with oracle access to .
Again, I don't get IDA. Iteration doesn't seem particularly needed? Note that inside QACI, the user does have access to an oracle and to all relevant pieces of hypothesis about which hypothesis it is inhabiting in — this is what, in the QACI math [LW · GW], this line does:
's distribution over answers demands that the answer payload , when interpreted as math and with all required contextual variables passed as input ().
Notably, is the hypothesis for which world the user is being considered in, and for their location within that world. Those are sufficient to fully characterize the hypothesis-for- that describes them. And because the user doesn't really return just a string but a math function which takes as input and returns a string, they can have that math function do arbitrary work — including rederive . In fact, rediriving is how they call a next iteration: they say (except in math) "call again (rederived using ), but with this string, and return the result of that." See also this illustration [LW(p) · GW(p)], which is kinda wrong in places but gets the recursion call graph thing right.
Another reason to do "iteration" like this inside the counterfactual rather than in the actual factual world (if that's what IDA does, which I'm only guessing here) is that we don't have as many iteration steps as we want in the factual world — eventually OpenAI or someone else kills everyone, whereas in the counterfactual, the QACI users are the only ones who can make progress, so the QACI users essentially have as long as they want, so long as they don't take too long in each individual counterfactual step or other somewhat easily avoided actions like that.
Why isn't Step 3 recursive reward modelling? i.e. we could collect a bunch of trajectories from and ask to use those trajectories to improve the reward function.
Unclear if this still means anything given the rest of this post. Ask me again if it does.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2024-09-28T23:01:22.319Z · LW(p) · GW(p)
Thanks Tamsin! Okay, round 2.
My current understanding of QACI:
- We assume a set of hypotheses about the world. We assume the oracle's beliefs are given by a probability distribution .
- We assume sets and of possible queries and answers respectively. Maybe these are exabyte files, i.e. for .
- Let be the set of mathematical formula that Joe might submit. These formulae are given semantics for each formula .[1]
- We assume a function where is the probability that Joe submits formula after reading query , under hypothesis .[2]
- We define as follows: sample , then sample , then return .
- For a fixed hypothesis , we can interpret the answer as a utility function via some semantics .
- Then we define via integrating over , i.e. .
- A policy is optimal if and only if .
The hope is that , , , and can be defined mathematically. Then the optimality condition can be defined mathematically.
Question 0
What if there's no policy which maximises ? That is, for every policy there is another policy such that . I suppose this is less worrying, but what if there are multiple policies which maximises ?
Question 1
In Step 7 above, you average all the utility functions together, whereas I suggested sampling a utility function. I think my solution might be safer.
Suppose the oracle puts 5% chance on hypotheses such that is malign. I think this is pretty conservative, because Solomonoff predictor is malign, and some of the concerns Evhub raises here. And the QACI amplification might not preserve benignancy. It follows that, under your solution, is influenced by a coalition of malign agents, and similarly is influenced by the malign coalition.
By contrast, I suggest sampling and then finding . This should give us a benign policy with 95% chance, which is pretty good odds. Is this safer? Not sure.
Question 2
I think the function doesn't work, i.e. there won't be a way to mathematically define the semantics of the formula language. In particular, the language must be strictly weaker than the meta-language in which you are hoping to define itself. This is because of Tarski's Undefinability of Truth (and other no-go theorems).
This might seem pedantic, but you in practical terms: there's no formula whose semantics is QACI itself. You can see this via a diagonal proof: imagine if Joe always writes the formal expression .
The most elegant solution is probably transfinite induction, but this would give us a QACI for each ordinal.
Question 3
If you have an ideal reasoner, why bother with reward functions when you can just straightforwardly do untractable-to-naively-compute utility functions
I want to understand how QACI and prosaic ML map onto each other. As far as I can tell, issues with QACI will be analogous to issues with prosaic ML and vice-versa.
Question 4
I still don't understand why we're using QACI to describe a utility function over policies, rather than using QACI in a more direct approach.
- Here's one approach. We pick a policy which maximises .[3] The advantage here is that Joe doesn't need to reason about utility functions over policies, he just need to reason about a single policy in front of him
- Here's another approach. We use QACI as our policy directly. That is, in each context that the agent finds themselves in, they sample an action from and take the resulting action.[4] The advantage here is that Joe doesn't need to reason about policies whatsoever, he just needs to reason about a single context in front of him. This is also the most "human-like", because there's no argmax's (except if Joe submits a formula with an argmax).
- Here's another approach. In each context , the agent takes an action which maximises .
- E.t.c.
Happy to jump on a call if that's easier.
- ^
I think you would say . I've added the , which simply amounts to giving Joe access to a random number generator. My remarks apply if also.
- ^
I think you would say . I've added the , which simply amount to including hypotheses that Joe is stochastic. But my remarks apply if also.
- ^
By this I mean either:
(1) Sample , then maximise the function .
(2) Maximise the function .
For reasons I mentioned in Question 1, I suspect (1) is safer, but (2) is closer to your original approach.
- ^
I would prefer the agent samples once at the start of deployment, and reuses the same hypothesis at each time-step. I suspect this is safer than resampling at each time-step, for reasons discussed before.
comment by Cleo Nardo (strawberry calm) · 2024-06-24T21:57:35.901Z · LW(p) · GW(p)
We're quite lucky that labs are building AI in pretty much the same way:
- same paradigm (deep learning)
- same architecture (transformer plus tweaks)
- same dataset (entire internet text)
- same loss (cross entropy)
- same application (chatbot for the public)
Kids, I remember when people built models for different applications, with different architectures, different datasets, different loss functions, etc. And they say that once upon a time different paradigms co-existed — symbolic, deep learning, evolutionary, and more!
This sameness has two advantages:
-
Firstly, it correlates catastrophe. If you have four labs doing the same thing, then we'll go extinct if that one thing is sufficiently dangerous. But if the four labs are doing four different things, then we'll go extinct if any of those four things are sufficiently dangerous, which is more likely.
-
It helps ai safety researchers because they only need to study one thing, not a dozen. For example, mech interp is lucky that everyone is using transformers. It'd be much harder to do mech interp if people were using LSTMs, RNNs, CNNs, SVMs, etc. And imagine how much harder mech interp would be if some labs were using deep learning, and others were using symbolic ai!
Implications:
- One downside of closed research is it decorrelates the activity of the labs.
- I'm more worried by Deepmind than Meta, xAI, Anthropic, or OpenAI. Their research seems less correlated with the other labs, so even though they're further behind than Anthropic or OpenAI, they contribute more counterfactual risk.
- I was worried when Elon announced xAI, because he implied it was gonna be a stem ai (e.g. he wanted it to prove Riemann Hypothesis). This unique application would've resulted in a unique design, contributing decorrelated risk. Luckily, xAI switched to building AI in the same way as the other labs — the only difference is Elon wants less "woke" stuff.
Let me know if I'm thinking about this all wrong.
comment by Cleo Nardo (strawberry calm) · 2024-06-21T23:59:55.867Z · LW(p) · GW(p)
I admire the Shard Theory crowd for the following reason: They have idiosyncratic intuitions about deep learning and they're keen to tell you how those intuitions should shift you on various alignment-relevant questions.
For example, "How likely is scheming?", "How likely is sharp left turn?", "How likely is deception?", "How likely is X technique to work?", "Will AIs acausally trade?", etc.
These aren't rigorous theorems or anything, just half-baked guesses. But they do actually say whether their intuitions will, on the margin, make someone more sceptical or more confident in these outcomes, relative to the median bundle of intuitions.
The ideas 'pay rent'.
comment by Cleo Nardo (strawberry calm) · 2025-02-07T14:05:50.632Z · LW(p) · GW(p)
Would it be nice for EAs to grab all the stars? I mean “nice” in Joe Carlsmith’s sense. My immediate intuition is “no that would be power grabby / selfish / tyrannical / not nice”.
But I have a countervailing intuition:
“Look, these non-EA ideologies don’t even care about stars. At least, not like EAs do. They aren’t scope sensitive or zero time-discounting. If the EAs could negotiate creditable commitments with these non-EA values, then we would end up with all the stars, especially those most distant in time and space.
Wouldn’t it be presumptuous for us to project scope-sensitivity onto these other value systems?”
Not sure what to think tbh. I’m increasingly leaning towards the second intuition, but here are some unknowns:
- Empirically, is it true that non-EAs don’t care about stars? My guess is yes, I could buy future stars from people easily if I tried. Maybe OpenPhil can organise a negotiation between their different grantmakers.
- Are these negotiations unfair? Maybe because EAs have more “knowledge” about the feasibility of space colonisation in the near future. Maybe because EAs have more “understanding” of numbers like 10^40 (though I’m doubtful because scientists understand magnitudes and they aren’t scope sensitive).
- Should EAs negotiate with these value systems as they actually are (the scope insensitive humans working down the hall) or instead with some “ideal” version of these value systems (a system with all the misunderstandings and irrationalities somehow removed)? My guess is that “ideal” here is bullshit, and also it strikes me as a patronising away to treat people.
↑ comment by testingthewaters · 2025-02-07T15:12:34.731Z · LW(p) · GW(p)
The question as stated can be rephrased as "Should EAs establish a strategic stranglehold over all future resources necessary to sustain life using a series of unequal treaties, since other humans will be too short sighted/insensitive to scope/ignorant to realise the importance of these resources in the present day?"
And people here wonder why these other humans see EAs as power hungry.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-02-07T18:21:29.972Z · LW(p) · GW(p)
I mention this in (3).
I used to think that there was some idealisation process P such that we should treat agent A in the way that P(A) would endorse, but see On the limits of idealized values by Joseph Carlsmith [LW · GW]. I'm increasingly sympathetic to the view that we should treat agent A in the way that A actually endorses.
Replies from: testingthewaters↑ comment by testingthewaters · 2025-02-07T18:26:11.609Z · LW(p) · GW(p)
Except that's a false dichotomy (between spending energy to "uplift" them or dealing treacherously with them). All it takes to not be a monster who obtains a stranglehold over all the watering holes in the desert is a sense of ethics that holds you to the somewhat reasonably low bar of "don't be a monster". The scope sensitivity or lack thereof of the other party is in some sense irrelevant.
Replies from: sharmake-farah, strawberry calm↑ comment by Noosphere89 (sharmake-farah) · 2025-02-07T19:31:45.110Z · LW(p) · GW(p)
don't be a monster
From who's perspective, exactly?
↑ comment by Cleo Nardo (strawberry calm) · 2025-02-07T23:14:23.105Z · LW(p) · GW(p)
If you think you have a clean resolution to the problem, please spell it out more explicitly. We’re talking about a situation where a scope insensitive value system and scope sensitive value system make a free trade in which both sides gain by their own lights. Can you spell out why you classify this as treachery? What is the key property that this shares with more paradigm examples of treachery (e.g. stealing, lying, etc)?
Replies from: testingthewaters↑ comment by testingthewaters · 2025-02-08T00:54:09.187Z · LW(p) · GW(p)
The problem here is that you are dealing with survival necessities rather than trade goods. The outcome of this trade, if both sides honour the agreement, is that the scope insensitive humans die and their society is extinguished. The analogous situation here is that you know there will be a drought in say 10 years. The people of the nearby village are "scope insensitive", they don't know the drought is coming. Clearly the moral thing to do if you place any value on their lives is to talk to them, clear the information gap, and share access to resources. Failing that, you can prepare for the eventuality that they do realise the drought is happening and intervene to help them at that point.
Instead you propose exploiting their ignorance to buy up access to the local rivers and reservoirs. The implication here is that you are leaving them to die, or at least putting them at your mercy, by exploiting their lack of information. What's more, the process by which you do this turns a common good (the stars, the water) into a private good, such that when they realise the trouble they have no way out. If your plan succeeds, when their stars run out they will curse you and die in the dark. It is a very slow but calculated form of murder.
By the way, the easy resolution is to not buy up all the stars. If they're truly scope insensitive they won't be competing until after the singularity/uplift anyways, and then you can equitably distribute the damn resources.
As a side note: I think I fell for rage bait. This feels calculated to make me angry, and I don't like it.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-02-08T01:57:27.679Z · LW(p) · GW(p)
the scope insensitive humans die and their society is extinguished
Ah, your reaction makes more sense given you think this is the proposal. But it's not the proposal. The proposal is that the scope-insensitive values flourish on Earth, and the scope-sensitive values flourish in the remaining cosmos.
As a toy example, imagine a distant planet with two species of alien: paperclip-maximisers and teacup-protectors. If you offer a lottery to the paperclip-maximisers, they will choose the lottery with the highest expected number of paperclips. If you offer a lottery to the teacup-satisfiers, they will choose the lottery with the highest chance of preserving their holy relic, which is a particular teacup.
The paperclip-maximisers and the teacup-protectors both own property on the planet. They negotiate the following deal: the paperclip-maximisers will colonise the cosmos, but leave the teacup-protectors a small sphere around their home planet (e.g. 100 light-years across). Moreover, the paperclip-maximisers promise not to do anything that risks their teacup, e.g. choosing a lottery that doubles the size of the universe with 60% chance and destroys the universe with 40% chance.
Do you have intuitions that the paperclip-maximisers are exploiting the teacup-protectors in this deal?
Do you think instead that the paperclip-maximisers should fill the universe with half paperclips and half teacups?
I think this scenario is a better analogy than the scenario with the drought. In the drought scenario, there is an object fact which the nearby villagers are ignorant of, and they would act differently if they knew this fact. But I don't think scope-sensitivity is a fact like "there will be a drought in 10 years". Rather, scope-sensitivity is a property of a utility function (or a value system, more generally).
↑ comment by jbash · 2025-02-07T18:17:13.364Z · LW(p) · GW(p)
What do you propose to do with the stars?
If it's the program of filling the whole light cone with as many humans or human-like entities as possible (or, worse, with simulations of such entities at undefined levels of fidelity) at the expense of everything else, that's not nice[1] regardless of who you're grabbing them from. That's building a straight up worse universe than if you just let the stars burn undisturbed.
I'm scope sensitive. I'll let you have a star. I won't sell you more stars for anything less than a credible commitment to leave the rest alone. Doing it at the scale of a globular cluster would be tacky, but maybe in a cute way. Doing a whole galaxy would be really gauche. Doing the whole universe is repulsive.
... and do you have any idea how obnoxiously patronizing you sound?
I mean "nice" in the sense of nice. ↩︎
↑ comment by Cleo Nardo (strawberry calm) · 2025-02-07T18:23:33.407Z · LW(p) · GW(p)
I think it's more patronising to tell scope-insensitive values that they aren't permitted to trade with scope-sensitive values, but I'm open to being persuaded otherwise.
comment by Cleo Nardo (strawberry calm) · 2025-02-01T03:28:43.977Z · LW(p) · GW(p)
People often tell me that AIs will communicate in neuralese rather than tokens because it’s continuous rather than discrete.
But I think the discreteness of tokens is a feature not a bug. If AIs communicate in neuralese then they can’t make decisive arbitrary decisions, c.f. Buridan's ass. The solution to Buridan’s ass is sampling from the softmax, i.e. communicate in tokens.
Also, discrete tokens are more tolerant to noise than the continuous activations, c.f. digital circuits are almost always more efficient and reliable than analogue ones.
comment by Cleo Nardo (strawberry calm) · 2025-02-01T02:51:00.094Z · LW(p) · GW(p)
In hindsight, the main positive impact of AI safety might be funnelling EAs into the labs, especially if alignment is easy-by-default.
comment by Cleo Nardo (strawberry calm) · 2022-12-13T16:47:34.875Z · LW(p) · GW(p)
BeReal — the app.
If you download the app BeReal then each day at a random time you will be given two minutes to take a photo with the front and back camera. All the other users are given a simultaneous "window of time". These photos are then shared with your friends on the app. The idea is that (unlike Instagram), BeReal gives your friends a representative random sample of your life, and vice-versa.
If you and your friends are working on something impactful (e.g. EA or x-risk), then BeReal is a fun way to keep each other informed about your day-to-day life and work. Moreover, I find it keeps me "accountable" (i.e. stops me from procrastinating or wasting the whole day in bed).
comment by Cleo Nardo (strawberry calm) · 2025-04-17T12:58:58.601Z · LW(p) · GW(p)
Must humans obey the Axiom of Irrelevant Alternatives?
Suppose you would choose option A from options A and B. Then you wouldn't choose option B from options A, B, C. Roughly speaking, whether you prefer option A or B is independent of whether I offer you an irrelevant option C. This is an axiom of rationality called IIA. Should humans follow this? Maybe not.
Maybe C includes additional information which makes it clear that B is better than A.
Consider the following options:
- (A) £10 bet that 1+1=2
- (B) £30 bet that the smallest prime factor in 1019489 ends in the digit 1
Now, I would prefer A to B. Firstly, if 1019489 is itself prime then I lose the bet. Secondly, if 1019489 isn't prime, then there's 25% chance that its smallest prime factor ends in 1. That's because all prime numbers greater than 5 end in 1, 3, 7 or 9 — and Dirichlet's theorem states that primes are equally distributed among these possible endings. So the chance of winning the bet is slightly less than 25%, and £10 is better than a 25% chance of winning £30. Presented with this menu, I would probably choose option A.
But now consider the following options:
- (A) £10 bet that 1+1=2
- (B) £30 bet that the smallest prime factor in 1019489 ends in the digit 1
- (C) £20 bet that 1019489 = 71 * 83 * 173
Well, which is the best option? Well, B is preferable to C because B has both a weaker condition and also a higher payout. And C is preferable to A — my odds on the 1019489 = 71 * 83 * 173 is higher than 50%. Presented with this menu, I would probably choose option B.
Replies from: dylan-mahoney↑ comment by Pretentious Penguin (dylan-mahoney) · 2025-04-17T14:24:48.974Z · LW(p) · GW(p)
I think you're interpreting the word "offer" too literally in the statement of IIA.
Also, any agent who chooses B among {A,B,C} would also choose B among the options {A,B} if presented with them after seeing C. So I think a more illuminating description of your thought experiment is that an agent with limited knowledge has a preference function over lotteries which depends on its knowledge, and that having the linguistic experience of being "offered" a lottery can give the agent more knowledge. So the preference function can change over time as the agent acquires new evidence, but the preference function at any fixed time obeys IIA.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2025-04-17T20:15:56.850Z · LW(p) · GW(p)
Yep, my point is that there's no physical notion of being "offered" a menu of lotteries which doesn't leak information. IIA will not be satisfied by any physical process which corresponds to offering the decision-maker with a menu of options. Happy to discuss any specific counter-example.
Of course, you can construct a mathematical model of the physical process, and this model might an informative objective to study, but it would be begging the question if the mathematical model baked in IIA somewhere.
↑ comment by Pretentious Penguin (dylan-mahoney) · 2025-04-17T22:04:15.043Z · LW(p) · GW(p)
What about the physical process of offering somebody a menu of lotteries consisting only of options that they have seen before? Or a 2-step physical process where first one tells somebody about some set of options, and then presents a menu of lotteries taken only from that set? I can't think of any example where a rational-seeming preference function doesn't obey IIA in one of these information-leakage-free physical processes.
comment by Cleo Nardo (strawberry calm) · 2025-02-03T15:02:32.116Z · LW(p) · GW(p)
Will AI accelerate biomedical research at companies like Novo Nordisk or Pfizer? I don’t think so. If OpenAI or Anthropic built a system that could accelerate R&D by more than 2x, they aren’t releasing it externally.
Maybe the AI company deploys the AI internally, with their own team accounting for 90%+ of the biomedical innovation.
comment by Cleo Nardo (strawberry calm) · 2024-06-24T21:08:29.900Z · LW(p) · GW(p)
I wouldn't be surprised if — in some objective sense — there was more diversity within humanity than within the rest of animalia combined. There is surely a bigger "gap" between two randomly selected humans than between two randomly selected beetles, despite the fact that there is one species of human and 0.9 – 2.1 million species of beetle.
By "gap" I might mean any of the following:
- external behaviour
- internal mechanisms
- subjective phenomenological experience
- phenotype (if a human's phenotype extends into their tools)
- evolutionary history (if we consider cultural/memetic evolution as well as genetic).
Here are the countries with populations within 0.9 – 2.1 million: Slovenia, Latvia, North Macedonia, Guinea-Bissau, Kosovo, Bahrain, Equatorial Guinea, Trinidad and Tobago, Estonia, East Timor, Mauritius, Eswatini, Djibouti, Cyprus.
When I consider my inherent value for diversity (or richness, complexity, variety, novelty, etc), I care about these countries more than beetles. And I think that this preference would grow if I was more familiar with each individual beetle and each individual person in these countries.
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-06-24T21:19:42.626Z · LW(p) · GW(p)
You might be able to formalize this using algorithmic information theory /K-complexity.