Posts
Comments
This post begins:
I've been trying to avoid the terms "good faith" and "bad faith". I'm suspicious that most people who have picked up the phrase "bad faith" from hearing it used, don't actually know what it means—and maybe, that the thing it does mean doesn't carve reality at the joints.
People get very touchy about bad faith accusations: they think that you should assume good faith, but that if you've determined someone is in bad faith, you shouldn't even be talking to them, that you need to exile them.
The second paragraph uses the term "bad faith" or "good faith" three times. What substance is it pointing to?
AFAICT the post never fleshes this out. The 'hidden motives' definition that Zack gave fleshes out his understanding of the term, which is different from what these people mean.
Tabooing words, when different people are using the word differently, typically means giving substance to both meanings (e.g. "acoustic vibrations" and "auditory experiences" for sound).
If Zack wanted to set aside the question of what other people mean by "bad faith" and just think about some things using his understanding of the term, then he could've done that. (To me that seems less interesting than also engaging with what other people mean by the term, and it would've made it a bit strange to start the post this way, but it still seems like a fine direction to go.) That's not what this post did, though. It keeps coming back to what other people think about bad faith, without tracking that there are different meanings.
Consider this from Zack: "The conviction that "bad faith" is unusual contributes to a warped view of the world". This is more on the topic of what other people think about "bad faith". Which meaning of "bad faith" is it using? If it means Zack's 'hidden motives' definition then it's unclear if people do have the conviction that that's unusual, because when people use the words "bad faith" that's not what they're talking about. If it means whatever people do mean by the words "bad faith", then we're back to discussing some substance that hasn't been fleshed out, and it's unclear if their conviction that it's rare contributes to a warped view of the world because it's unclear what that conviction even is.
The "Taboo bad faith" title doesn't fit this post. I had hoped from the opening section that it was going in that direction, but it did not.
Most obviously, the post kept relying heavily on the terms "bad faith" and "good faith" and that conceptual distinction, rather than tabooing them.
But also, it doesn't do the core intellectual work of replacing a pointer with its substance. In the opening scenario where someone accuses their conversation partner of bad faith, conveying something along the lines of 'I disapprove of how you're approaching this conversation so I'm leaving', tabooing "bad faith" would mean articulating what pattern of behavior (they thought that) they saw and why disapproval & departure is an appropriate response. Zack doesn't try to do this, he just abandons this scenario to talk about other things involving his definition of "bad faith". (And similarly with "assume good faith".) I briefly hoped that the post would go in the "taboo your words" direction, describing what was happening in that sort of scenario with a clarity and precision that would make the label "bad faith" seem crude by comparison, but it did not.
This post also doesn't manage to avoid the main pitfall that tabooing a word is meant to prevent, where people talk past each other because they're using the same word with different definitions. Even though he says at the start of the post that other people are using the term "bad/good faith" wrong according his understanding of the term, when he talks about the advice "assume good faith" he just plugs in his definition of "good faith" (and "assume") without noting that he's making an interpretation of what other people mean when they use the phrase and that they might mean something else. And similarly in other places like "being touchy about bad faith accusations seems counterproductive" and "the belief that persistent good faith disagreements are common would seem to be in bad faith". When someone says "you're acting in bad faith" are they claiming that you're showing the thing that Zack means by "bad faith"? Keeping that sort of thing straight is rationality 101 stuff that tabooing words helps with, and which this post repeatedly stumbles over.
I'm voting against including this in the Review, at max level, because I think it too-often mischaracterizes the views of the people it quotes. And it seems real bad for a post that is mainly about describing other people's views and the drawing big conclusions from that data to inaccurately describe those views and then draw conclusions from inaccurate data.
I'd be interested in hearing about this from people who favor putting this post in the review. Did you check on the sources for some of Elizabeth's claims and think that she described them well? Did you see some inaccuracies but figure that the post is still good enough? Did you trust Elizabeth's descriptions without checking yourself on what the person said?
I spent a fair amount of time spot checking Elizabeth's first section, on Martin Soto, which got my attention because it seemed like it could be one of her strongest and it was the first. This claim from Elizabeth in that section seems clearly false: "The charitable explanation here is that my post focuses on naive veganism, and Soto thinks that’s a made-up problem". The first few paragraphs quoted in this post are sufficient to falsify this interpretation, and the first comment that Martin left on Elizabeth's post is too. Other parts of the description of Martin's views which are more central to Elizabeth's argument also seem off, though sorting them out requires getting more in the weeds. e.g. AFAICT he didn't say he opposed talking about the whole topic of vegan nutrition; he did say something along the lines of 'you didn't say anything false, but I don't like the way you presented things because it'll have bad consequences', but that's a pretty normal type of opinion - Elizabeth said something like that about Will MacAskill in another post in this series.
Other places where this post felt off include Elizabeth's description of what people were trying to claim when they brought up the Adventist study, and the claim that this comment by Wilkox involved frame control (it doesn't look like Wilkox was trying to force their frame on the conversation; rather, it looks like Elizabeth brought a strong frame to the "Change my mind" post, Wilkox didn't immediately buy into it and was trying to think through the overall frame that Elizabeth brought and the specific concrete claims that Elizabeth made).
There are other examples in the comments, e.g. this comment by Wilkox (currently at +12 net agree-vote, w/o a vote from me) gives 6 examples where the post's "description of what was said seems to misrepresent the source text", with some overlap with my examples and some I haven't looked into.
Before doing these spot checks I was inclined to vote against this post for the review at -1 because it didn't seem to live up to the title. It was trying to do a hard thing and didn't pull it off -- or at least, I didn't get a particularly clear sense of the nature and extent of epistemic problems within EA vegan advocacy and had just cached the post as 'Elizabeth's upset about EA vegan epistemics'. After digging in to some of it more closely, it looks like it did a worse job than I'd thought, so I've moved my vote downward and written this review.
As I understand it, Scott's post was making basically the same conceptual distinction as this Andrew Gelman post, where Gelman writes:
One of the big findings of baseball statistics guru Bill James is that minor-league statistics, when correctly adjusted, predict major-league performance. James is working through a three-step process: (1) naive trust in minor league stats, (2) a recognition that raw minor league stats are misleading, (3) a statistical adjustment process, by which you realize that there really is a lot of information there, if you know how to use it.
Scott labels the first two of Gelman's categories "clueless" and the third "savvy".
savvy don't (just) have more skills to extract signal from a "naturally" occurring source of lies. They're collaborating with it!
This (from your tweet) is false, and your post here even has a straightforward argument against it (with the honest cop and the corrupt cop both savvy enough to discern a lightly veiled bribery attempt). Savviness about extracting information from a source does not imply complicity with the source.
Trying to make this more intuitive: consider a prediction market which is currently priced at x, where each share will pay out $1 if it resolves as True.
If you think it's underpriced because your probability is y, where y>x, then your subjective EV from buying a share is y-x. e.g., If it's priced at $0.70 and you think p=0.8, your subjective EV from buying a share is $0.10.
If you think it's overpriced because your probability is z, where z<x, then your subjective EV from selling a share is x-z. e.g., If it's priced at $0.70 and you think p=0.56, your subjective EV from selling a share is $0.14.
Those two will be equal if x is halfway between y and z, at their arithmetic mean.
So if two people disagree on whether the price should be y or z, then they will have equal EV by setting a price at the arithmetic mean of y & z, and trading some number of prediction market shares at that price. i.e., The fair (equal subjective EV) betting odds are at the arithmetic mean of their probabilities.
This is a bet at 30% probability, as 42.86/142.86 = .30001.
That is the average of Alice's probability and Bob's probability. The fair bet according to equal subjective EV is at the average of the two probabilities; previous discussion here.
The first two puzzles got some discussion on LW long ago here, and a bit more here.
I don't buy the way that Spencer tried to norm the ClearerThinking test. It sounds like he just assumed that people who took their test and had a college degree as their highest level of education had the same IQ as the portion of the general population with the same educational level, and similarly for all other education levels. Then he used that to scale how scores on the ClearerThinking test correspond to IQs. That seems like a very strong and probably inaccurate assumption.
Much of what this post and Scott's post are using the ClearerThinking IQ numbers for relies on this norming.
It occurs to me that the ClearerThinking data provides a way to check this assumption. It included data from 2 different groups, crowdworkers and people in Spencer's social network. If college-degree-level crowdworkers did just as well on the ClearerThinking test as college-degree-level people in Spencer's network, then it becomes more plausible that both did about as well as college-degree-level people in the general population would have. Whereas if the college-degree-level crowdworkers and Spencer's network people scored differently, then obviously they can't both match the college-degree-level general population, so there'd be an open question about how the groups compare and direct evidence against the accuracy of Spencer's method of norming the test.
I think that the way that Scott estimated IQ from SAT is flawed, in a way that underestimates IQ, for reasons given in comments like this one. This post kept that flaw.
There can be no consequentialist argument for lying to yourself or allies1 because without truth you can’t make accurate utility calculations2.
Seems false.
"Can crimes be discussed literally?":
- some kinds of hypocrisy (the law and medicine examples) are normalized
- these hypocrisies are / the fact of their normalization is antimemetic (OK, I'm to some extent interpolating this one based on familiarity with Ben's ideas, but I do think it's both implied by the post, and relevant to why someone might think the post is interesting/important)
- the usage of words like 'crime' and 'lie' departs from their denotation, to exclude normalized things
- people will push back in certain predictable ways on calling normalized things 'crimes'/'lies', related to the function of those words as both description and (call for) attack
- "There is a clear conflict between the use of language to punish offenders, and the use of language to describe problems, and there is great need for a language that can describe problems. For instance, if I wanted to understand how to interpret statistics generated by the medical system, I would need a short, simple way to refer to any significant tendency to generate false reports. If the available simple terms were also attack words, the process would become much more complicated."
Does it bother you that this is not what's happening in many of the examples in the post? e.g., With "the American hospital system is built on lies."
This post reads like it's trying to express an attitude or put forward a narrative frame, rather than trying to describe the world.
Many of these claims seem obviously false, if I take them at face value at take a moment to consider what they're claiming and whether it's true.
e.g., On the first two bullet points it's easy to come up with counterexamples. Some successful attempts to steer the future, by stopping people from doing locally self-interested & non-violent things, include: patent law ("To promote the progress of science and useful arts, by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries") and banning lead in gasoline. As well as some others that I now see that other commenters have mentioned.
In America, people shopped at Walmart instead of local mom & pop stores because it had lower prices and more selection, so Walmart and other chain stores grew and spread while lots of mom & pop stores shut down. Why didn't that happen in Wentworld?
I made a graph of this and the unemployment rate, they're correlated at r=0.66 (with one data point for each time Gallup ran the survey, taking the unemployment rate on the closest day for which there's data). You can see both lines spike with every recession.
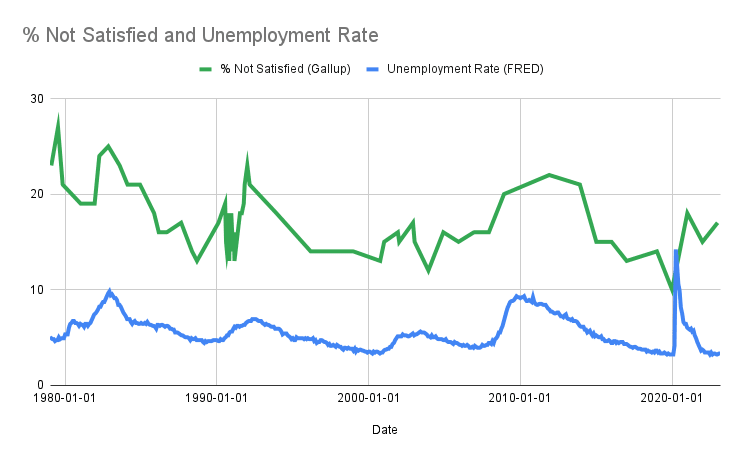
Are you telling me 2008 did actual nothing?
It looks like 2008 led to about a 1.3x increase in the number of people who said they were dissatisfied with their life.
It's common for much simpler Statistical Prediction Rules, such as linear regression or even simpler models, to outperform experts even when they were built to predict the experts' judgment.
Or "Defense wins championships."
With the ingredients he has, he has gotten a successful Barkskin Potion:
1 of the 1 times (100%) he brewed together Crushed Onyx, Giant's Toe, Ground Bone, Oaken Twigs, Redwood Sap, and Vampire Fang.
19 of the 29 times (66%) he brewed together Crushed Onyx, Demon Claw, Ground Bone, and Vampire Fang.
Only 2 other combinations of the in-stock ingredients have ever produced Barkskin Potion, both at under a 50% rate (4/10 and 18/75).
The 4-ingredient, 66% success rate potion looks like the best option if we're just going to copy something that has worked. That's what I'd recommend if I had to make the decision right now.
Many combinations that used currently-missing ingredients reliably (100%) produced Barkskin Potion many times (up to 118/118). There may be a variant on one of those, which he has never tried, that could work better than 66% of the time using ingredients that he has. Or there may be information in there about the reliability of the 6-ingredient combination which worked once.
Being Wrong on the Internet: The LLM generates a flawed forum-style comment, such that the thing you've been wanting to write is a knockdown response to this comment, and you can get a "someone"-is-wrong-on-the-internet drive to make the points you wanted to make. You can adjust how thoughtful/annoying/etc. the wrong comment is.
Target Audience Personas: You specify the target audience that your writing is aimed at, or a few different target audiences. The LLM takes on the persona of a member of that audience and engages with what you've written, with more explicit explanation of how that persona is reacting and why than most actual humans would give. The structure could be like comments on google docs.
Heat Maps: Color the text with a heat map of how interested the LLM expects the reader to be at each point in the text, or how confused, how angry, how amused, how disagreeing, how much they're learning, how memorable it is, etc. Could be associated with specific target audiences.
I don't think that the key element in the aging example is 'being about value claims'. Instead, it's that the question about what's healthy is a question that many people wonder about. Since many people wonder about that question, some people will venture an answer. Even if humanity hasn't yet built up enough knowledge to have an accurate answer.
Thousands of years ago many people wondered what the deal is with the moon and some of them made up stories about this factual (non-value) question whose correct answer was beyond them. And it plays out similarly these days with rumors/speculation/gossip about the topics that grab people's attention. Where curiosity & interest exceeds knowledge, speculation will fill the gaps, sometimes taking on a similar presentation to knowledge.
Note the dynamic in your aging example: when you're in a room with 5+ people and you mention that you've read a lot about aging, someone asks the question about what's healthy. No particular answer needs to be memetic because it's the question that keeps popping up and so answers will follow. If we don't know a sufficiently good/accurate/thorough answer then the answers that follow will often be bullshit, whether that's a small number of bullshit answers that are especially memetically fit or whether it's a more varied and changing froth of made-up answers.
There are some kinds of value claims that are pretty vague and floaty, disconnected from entangled truths and empirical constraints. But that is not so true of instrumental claims about things like health, where (e.g.) the claim that smoking causes lung cancel is very much empirical & entangled. You might still see a lot of bullshit about these sorts of instrumental value claims, because people will wonder about the question even if humanity doesn't have a good answer. It's useful to know (e.g.) what foods are healthy, so the question of what foods are healthy is one that will keep popping up when there's hope that someone in the room might have some information about it.
7% of the variance isn't negligible. Just look at the pictures (Figure 1 in the paper):
I got the same result: DEHK.
I'm not sure that there are no patterns in what works for self-taught architects, and if we were aiming to balance cost & likelihood of impossibility then I might look into that more (since I expect A,L,N to be the the cheapest options with a chance to work), but since we're prioritizing impossibility I'll stick with the architects with the competent mentors.
Moore & Schatz (2017) made a similar point about different meanings of "overconfidence" in their paper The three faces of overconfidence. The abstract:
Overconfidence has been studied in 3 distinct ways. Overestimation is thinking that you are better than you are. Overplacement is the exaggerated belief that you are better than others. Overprecision is the excessive faith that you know the truth. These 3 forms of overconfidence manifest themselves under different conditions, have different causes, and have widely varying consequences. It is a mistake to treat them as if they were the same or to assume that they have the same psychological origins.
Though I do think that some of your 6 different meanings are different manifestations of the same underlying meaning.
Calling someone "overprecise" is saying that they should increase the entropy of their beliefs. In cases where there is a natural ignorance prior, it is claiming that their probability distribution should be closer to the ignorance prior. This could sometimes mean closer to 50-50 as in your point 1, e.g. the probability that the Yankees will win their next game. This could sometimes mean closer to 1/n as with some cases of your points 2 & 6, e.g. a 1/30 probability that the Yankees will win the next World Series (as they are 1 of 30 teams).
In cases where there isn't a natural ignorance prior, saying that someone should increase the entropy of their beliefs is often interpretable as a claim that they should put less probability on the possibilities that they view as most likely. This could sometimes look like your point 2, e.g. if they think DeSantis has a 20% chance of being US President in 2030, or like your point 6. It could sometimes look like widening their confidence interval for estimating some quantity.
You can go ahead and post.
I did a check and am now more confident in my answer, and I'm not going to try to come up with an entry that uses fewer soldiers.
Just got to this today. I've come up with a candidate solution just to try to survive, but haven't had a chance yet to check & confirm that it'll work, or to try to get clever and reduce the number of soldiers I'm using.
10 Soldiers armed with: 3 AA, 3 GG, 1 LL, 2 MM, 1 RR
I will probably work on this some more tomorrow.
Building a paperclipper is low-value (from the point of view of total utilitarianism, or any other moral view that wants a big flourishing future) because paperclips are not sentient / are not conscious / are not moral patients / are not capable of flourishing. So filling the lightcone with paperclips is low-value. It maybe has some value for the sake of the paperclipper (if the paperclipper is a moral patient, or whatever the relevant category is) but way less than the future could have.
Your counter is that maybe building an aligned AI is also low-value (from the point of view of total utilitarianism, or any other moral view that wants a big flourishing future) because humans might not much care about having a big flourishing future, or might even actively prefer things like preserving nature.
If a total utilitarian (or someone who wants a big flourishing future in our lightcone) buys your counter, it seems like the appropriate response is: Oh no! It looks like we're heading towards a future that is many orders of magnitude worse than I hoped, whether or not we solve the alignment problem. Is there some way to get a big flourishing future? Maybe there's something else that we need to build into our AI designs, besides "alignment". (Perhaps mixed with some amount of: Hmmm, maybe I'm confused about morality. If AI-assisted humanity won't want to steer towards a big flourishing future then maybe I've been misguided in having that aim.)
Whereas this post seems to suggest the response of: Oh well, I guess it's a dice roll regardless of what sort of AI we build. Which is giving up awfully quickly, as if we had exhausted the design space for possible AIs and seen that there was no way to move forward with a large chance at a big flourishing future. This response also doesn't seem very quantitative - it goes very quickly from the idea that an aligned AI might not get a big flourishing future, to the view that alignment is "neutral" as if the chances of getting a big flourishing future were identically small under both options. But the obvious question for a total utilitarian who does wind up with just 2 options, each of which is a dice roll, is Which set of dice has better odds?
Is this calculation showing that, with a big causal graph, you'll get lots of very weak causal relationships between distant nodes that should have tiny but nonzero correlations? And realistic sample sizes won't be able to distinguish those relationships from zero.
Andrew Gelman often talks about how the null hypothesis (of a relationship of precisely zero) is usually false (for, e.g., most questions considered in social science research).
A lot of people have this sci-fi image, like something out of Deep Impact, Armageddon, Don't Look Up, or Minus, of a single large asteroid hurtling towards Earth to wreak massive destruction. Or even massive vengeance, as if it was a punishment for our sins.
But realistically, as the field of asteroid collection gradually advances, we're going to be facing many incoming asteroids which will interact with each other in complicated ways, and whose forces will to a large extent balance each other out.
Yet doomers are somehow supremely confident in how the future will go, foretelling catastrophe. And if you poke at their justifications, they won't offer precise physical models of these many-body interactions, just these mythic stories of Earth vs. a monolithic celestial body.
They're critical questions, but one of the secret-lore-of-rationality things is that a lot of people think criticism is bad, because if someone criticizes you, it hurts your reputation. But I think criticism is good, because if I write a bad blog post, and someone tells me it was bad, I can learn from that, and do better next time.
I read this as saying 'a common view is that being criticized is bad because it hurts your reputation, but as a person with some knowledge of the secret lore of rationality I believe that being criticized is good because you can learn from it.'
And he isn't making a claim about to what extent the existing LW/rationality community shares his view.
Seems like the main difference is that you're "counting up" with status and "counting down" with genetic fitness.
There's partial overlap between people's reproductive interests and their motivations, and you and others have emphasized places where there's a mismatch, but there are also (for example) plenty of people who plan their lives around having & raising kids.
There's partial overlap between status and people's motivations, and this post emphasizes places where they match up, but there are also (for example) plenty of people who put tons of effort into leveling up their videogame characters, or affiliating-at-a-distance with Taylor Swift or LeBron James, with minimal real-world benefit to themselves.
And it's easier to count up lots of things as status-related if you're using a vague concept of status which can encompass all sorts of status-related behaviors, including (e.g.) both status-seeking and status-affiliation. "Inclusive genetic fitness" is a nice precise concept so it can be clear when individuals fail to aim for it even when acting on adaptations that are directly involved in reproduction & raising offspring.
The economist RH Strotz introduced the term "precommitment" in his 1955-56 paper "Myopia and Inconsistency in Dynamic Utility Maximization".
Thomas Schelling started writing about similar topics in his 1956 paper "An essay on bargaining", using the term "commitment".
Both terms have been in use since then.
On one interpretation of the question: if you're hallucinating then you aren't in fact seeing ghosts, you're just imagining that you're seeing ghosts. The question isn't asking about those scenarios, it's only asking what you should believe in the scenarios where you really do see ghosts.
My updated list after some more work yesterday is
96286, 9344, 107278, 68204, 905, 23565, 8415, 62718, 83512, 16423, 42742, 94304
which I see is the same as simon's list, with very slight differences in the order
More on my process:
I initially modeled location just by a k nearest neighbors calculation, assuming that a site's location value equals the average residual of its k nearest neighbors (with location transformed to Cartesian coordinates). That, along with linear regression predicting log(Performance), got me my first list of answers. I figured that list was probably good enough to pass the challenge: the sites' predicted performance had a decent buffer over the required cutoff, the known sites with large predicted values did mostly have negative residuals but they were only about 1/3 the size of the buffer, there were some sites with large negative residuals but none among the sites with high predicted values and I probably even had a big enough buffer to withstand 1 of them sneaking in, and the nearest neighbors approach was likely to mainly err by giving overly middling values to sites near a sharp border (averaging across neighbors on both sides of the border) which would cause me to miss some good sites but not to include any bad sites. So it seemed fine to stop my work there.
Yesterday I went back and looked at the residuals and added some more handcrafted variables to my model to account for any visible patterns. The biggest was the sharp cutoff at Latitude +-36. I also changed my rescaling of Murphy's Constant (because my previous attempt had negative residuals for low Murphy values), added a quadratic term to my rescaling of Local Value of Pi (because the dropoff from 3.15 isn't linear), added a Shortitude cutoff at 45, and added a cos(Longitude-50) variable. Still kept the nearest neighbors calculation to account for any other location relevance (there is a little but much less now). That left me with 4 nines of correlation between predicted & actual performance, residuals near zero for the highest predicted sites in the training set, and this new list of sites. My previous lists of sites still seem good enough, but this one looks better.
Did a little robustness check, and I'm going to swap out 3 of these to make it:
96286, 23565, 68204, 905, 93762, 94408, 105880, 9344, 8415, 62718, 80395, 65607
To share some more:
I came across this puzzle via aphyer's post, and got inspired to give it a try.
Here is the fit I was able to get on the existing sites (Performance vs. Predicted Performance). Some notes on it:
Seems good enough to run with. None of the highest predicted existing sites had a large negative residual, and the highest predicted new sites give some buffer.
Three observations I made along the way.
First (which is mostly redundant with what aphyer wound up sharing in his second post):
Almost every variable is predictive of Performance on its own, but none of the continuous variables have a straightforward linear relationship with Performance.
Second:
Modeling the effect of location could be tricky. e.g., Imagine on Earth if Australia and Mexico were especially good places for Performance, or on a checkerboard if Performance was higher on the black squares.
Third:
The ZPPG Performance variable has a skewed distribution which does not look like what you'd get if you were adding a bunch of variables, but does look like something you might get if you were multiplying several variables. And multiplication seems plausible for this scenario, e.g. perhaps such-and-such a disturbance halves Performance and this other factor cuts performance by a quarter.
My current choices (in order of preference) are
96286, 23565, 68204, 905, 93762, 94408, 105880, 8415, 94304, 42742, 92778, 62718
What's "Time-Weighted Probability"? Is that just the average probability across the lifespan of the market? That's not a quantity which is supposed to be calibrated.
e.g., Imagine a simple market on a coin flip, where forecasts of p(heads) are made at two times: t1 before the flip and t2 after the flip is observed. In half of the cases, the market forecast is 50% at t1 and 100% at t2, for an average of 75%; in those cases the market always resolves True. The other half: 50% at t1, 0% at t2, avg of 25%, market resolves False. The market is underconfident if you take this average, but the market is perfectly calibrated at any specific time.
Have you looked at other ways of setting up the prior to see if this result still holds? I'm worried that they way you've set up the prior is not very natural, especially if (as it looks at first glance) the Stable scenario forces p(Heads) = 0.5 and the other scenarios force p(Heads|Heads) + p(Heads|Tails) = 1. Seems weird to exclude "this coin is Headsy" from the hypothesis space while including "This coin is Switchy".
Thinking about what seems most natural for setting up the prior: the simplest scenario is where flips are serially independent. You only need one number to characterize a hypothesis in that space, p(Heads). So you can have some prior on this hypothesis space (serial independent flips), and some prior on p(Heads) for hypotheses within this space. Presumably that prior should be centered at 0.5 and symmetric. There's some choice about how spread out vs. concentrated to make it, but if it just puts all the probability mass at 0.5 that seems too simple.
The next simplest hypothesis space is where there is serial dependence that only depends on the most recent flip. You need two numbers to characterize a hypothesis in this space, which could be p(Heads|Heads) and p(Heads|Tails). I guess it's simplest for those to be independent in your prior, so that (conditional on there being serial dependence), getting info about p(Heads|Heads) doesn't tell you anything about p(Heads|Tails). In other words, you can simplify this two dimensional joint distribution to two independent one-dimensional distributions. (Though in real-world scenarios my guess is that these are positively correlated, e.g. if I learned that p(Prius|Jeep) was high that would probably increase my estimate of p(Prius|Prius), even assuming that there is some serial dependence.) For simplicity you could just give these the same prior distribution as p(Heads) in the serial independence case.
I think that's a rich enough hypothesis space to run the numbers on. In this setup, Sticky hypotheses are those where p(Heads|Heads)>p(Heads|Tails), Switchy are the reverse, Headsy are where p(Heads|Heads)+p(Heads|Tails)>1, Tails are the reverse, and Stable are where p(Heads|Heads)=p(Heads|Tails) and get a bunch of extra weight in the prior because they're the only ones in the serial independent space of hypotheses.
Try memorizing their birthdates (including year).
That might be different enough from what you've previously tried to memorize (month & day) to not get caught in the tangle that has developed.
My answer to "If AI wipes out humanity and colonizes the universe itself, the future will go about as well as if humanity had survived (or better)" is pretty much defined by how the question is interpreted. It could swing pretty wildly, but the obvious interpretation seems ~tautologically bad.
Agreed, I can imagine very different ways of getting a number for that, even given probability distributions for how good the future will be conditional on each of the two scenarios.
A stylized example: say that the AI-only future has a 99% chance of being mediocre and a 1% chance of being great, and the human future has a 60% chance of being mediocre and a 40% chance of being great. Does that give an answer of 1% or 60% or something else?
I'm also not entirely clear on what scenario I should be imagining for the "humanity had survived (or better)" case.
The time on a clock is pretty close to being a denotative statement.
Batesian mimicry is optimized to be misleading, "I"ll get to it tomorrow" is denotatively false, "I did not have sexual relations with that woman" is ambiguous as to its conscious intent to be denotatively false.
Structure Rebel, Content Purist: people who disagree with me are lying (unless they say "I think that", "My view is", or similar)
Structure Rebel, Content Neutral: people who disagree with me are lying even when they say "I think that", "My view is", or similar
Structure Rebel, Content Rebel: trying to unlock the front door with my back door key is a lie
How do you get a geocentric model with ellipses? Venus clearly does not go in an ellipse around the Earth. Did Riccioli just add a bunch of epicycles to the ellipses?
Googling... oh, it was a Tychonic model, where Venus orbits the sun in an ellipse (in agreement with Kepler), but the sun orbits the Earth.
Kepler's ellipses wiped out the fully geocentric models where all the planets orbit around the Earth, because modeling their orbits around the Earth still required a bunch of epicycles and such, while modeling their orbits around the sun now involved a simple ellipse rather than just slightly fewer epicycles. But it didn't straightforwardly, on its own wipe out the geoheliocentric/Tychonic models where most planets orbit the sun but the sun orbits the Earth.
Here is Yudkowsky (2008) Artificial Intelligence as a Positive and
Negative Factor in Global Risk:
Friendly AI is not a module you can instantly invent at the exact moment when it is first needed, and then bolt on to an existing, polished design which is otherwise completely unchanged.
The field of AI has techniques, such as neural networks and evolutionary programming, which have grown in power with the slow tweaking of decades. But neural networks are opaque—the user has no idea how the neural net is making its decisions—and cannot easily be rendered unopaque; the people who invented and polished neural networks were not thinking about the long-term problems of Friendly AI. Evolutionary programming (EP) is stochastic, and does not precisely preserve the optimization target in the generated code; EP gives you code that does what you ask, most of the time, under the tested circumstances, but the code may also do something else on the side. EP is a powerful, still maturing technique that is intrinsically unsuited to the demands of Friendly AI. Friendly AI, as I have proposed it, requires repeated cycles of recursive self-improvement that precisely preserve a stable optimization target.
The most powerful current AI techniques, as they were developed and then polished and improved over time, have basic incompatibilities with the requirements of Friendly AI as I currently see them. The Y2K problem—which proved very expensive to fix, though not global-catastrophic—analogously arose from failing to foresee tomorrow’s design requirements. The nightmare scenario is that we find ourselves stuck with a catalog of mature, powerful, publicly available AI techniques which combine to yield non-Friendly AI, but which cannot be used to build Friendly AI without redoing the last three decades of AI work from scratch.
Also, chp 25 of HPMOR is from 2010 which is before CFAR.
There are a couple errors in your table of interpretations. For "actual score = subjective expected", the second half of the interpretation "prediction = 0.5 or prediction = true probability" got put on a new line in the "Comparison score" column instead of staying together in the "Interpretation" column, and similarly for the next one.
I posted a brainstorm of possible forecasting metrics a while back, which you might be interested in. It included one (which I called "Points Relative to Your Expectation") that involved comparing a forecaster's (Brier or other) score with the score that they'd expect to get based on their probability.