formalizing the QACI alignment formal-goal
post by Tamsin Leake (carado-1), JuliaHP · 2023-06-10T03:28:29.541Z · LW · GW · 6 commentsThis is a link post for https://carado.moe/qaci-math.html
Contents
1. math constructs 1.1. basic set theory 1.2. functions and programs 1.3. sum notation 1.4. distributions 1.5. constrained mass 1.6. bitstrings 1.7. cryptography 1.8. text and math evaluation 1.9. kolmogorov simplicity 2. physics 2.1. general physics 2.2. quantum turing machines 3. implementing QACI 3.1. question blob and observation 3.2. overview 3.3. blob location 3.4. blob signing 3.5. action-scoring functions 3.6. QACI query 3.7. top-level QACI call 3.8. action scoring None 6 comments
this work was done by Tamsin Leake and Julia Persson at Orthogonal.
thanks to mesaoptimizer for his help putting together this post.
what does the QACI plan for formal-goal alignment actually look like when formalized as math? in this post, we'll be presenting our current formalization, which we believe has most critical details filled in.
1. math constructs
in this first part, we'll be defining a collection of mathematical constructs which we'll be using in the rest of the post.
1.1. basic set theory
we'll be assuming basic set theory notation; in particular, is the set of tuples whose elements are respectively members of the sets , , and , and for , is the set of tuples of elements, all members of .
is the set of booleans and is the set of natural numbers including .
given a set , will be the set of subsets of .
is the cardinality (number of different elements) in set .
for some set and some complete ordering , and are two functions of type finding the respective minimum and maximum element of non-empty sets when they exist, using as an ordering.
1.2. functions and programs
if , then we'll denote as repeated composition of : ( times), with being the composition operator: .
is an anonymous function defined over set , whose parameter is bound to its argument in its body when it is called.
is the set of functions from to , with being right-associative ( is ). if , then is simply applied once to , and then the resulting function of type being applied to . is sometimes denoted in set theory.
is the set of always-halting, always-succeeding, deterministic programs taking as input an and returning a .
given and , is the runtime duration of executing with input , measured in compute steps doing a constant amount of work each — such as turing machine updates.
1.3. sum notation
i'll be using a syntax for sums in which the sum iterates over all possibles values for the variables listed above it, given that the constraints below it hold.
says "for any value of and where these three constraints hold, sum ".
1.4. distributions
for any countable set , the set of distributions over is defined as:
a function is a distribution over if and only if its sum over all of is never greater than 1. we call "mass" the scalar in which a distribution assigns to any value. note that in our definition of distribution, we do not require that the distribution over all elements in the domain sums up to 1, but merely that it sums up to at most 1. this means that different distributions can have different "total mass".
we define as the empty distribution: .
we define as the distribution entirely concentrated on one element:
we define which modifies a distribution to make it sum to 1 over all of its elements, except for empty distributions:
we define as a distribution attributing equal value to every different element in a finite set , or the empty distribution if is infinite.
we define as the function finding the elements of a distribution with the highest value:
1.5. constrained mass
given distributions, we will define a notation which i'll call "constrained mass".
it is defined as a syntactic structure that turns into a sum:
in which variables are sampled from their respective distributions , such that each instance of is multiplied by for each . constraints and iterated variables are kept as-is.
it is intended to weigh its expression body by various sets of assignments of values to the variables , weighed by how much mass the distributions return and filtered for when the constraints hold.
to take a fairly abstract but fully calculable example,
in this syntax, the variables being sampled from distributions are allowed to be bound by an arbitrary amount of logical constraints or new variable bindings below it, other than the variables being sampled from distributions.
1.6. bitstrings
is the set of finite bitstrings.
bitstrings can be compared using the lexicographic order , and concatenated using the operator. for a bitstring , is its length in number of bits.
for any countable set , and will be some reasonable function to convert values to bitstrings, such that . "reasonable" entails constraints such as:
- it can be computed efficiently.
- it can be inverted efficiently and unambiguously.
- its output's size is somewhat proportional to the actual amount of information. for example, integers are encoded in binary, not unary.
1.7. cryptography
we posit , the set of "signatures", sufficiently large bitstrings for cryptographic and uniqueness purposes, with their length defined as for now. this feels to me like it should be enough, and if it isn't then something is fundamentally wrong with the whole scheme, such that no manageable larger size would do either.
we posit a function , to generate fixed-sized strings from seed bitstrings, which must satisfy the following:
- it must be too expensive for the AI to compute in any way (including through superintelligently clever tricks), but cheap enough that we can compute it outside of the AI — for example, it could require quantum computation, and the AI could be restricted to classical computers
- it should take longer to compute (again, in any way) than the expected correct versions of 's functions (as will be defined later) could afford to run
- it should tend to be collision-resistant
at some point, we might come up with more formal ways to define in a way that checks that it isn't being computed inside 's functions, nor inside the AI.
1.8. text and math evaluation
for any countable set , we'll be assuming to interpret a piece of text as a piece of math in some formal language, evaluating to either:
- a set of just one element of , if the math parses and evaluates properly to an element of
- an empty set otherwise
for example,
1.9. kolmogorov simplicity
for any countable sets and :
is some "kolmogorov simplicity" distribution over set which has the properties of never assigning 0, and summing/converging to 1 over all of . it must satisfy and .
is expected to give more mass to simpler elements, in an information-theoretic sense.
notably, it is expected to "deduplicate" information that appears in multiple parts of a same mathematical object, such that even if holds lots of information, is not much higher (higher simplicity, i.e. lower complexity) to .
we could define similarly to cross-entropy [LW · GW], with some universal turing machine returning the state of its tape after a certain number of compute steps:
kolmogorov simplicity over with a prior from , of type , allows elements it samples over to share information with a prior piece of information in . it is defined as .
2. physics
in this section we posit some formalisms for modeling world-states, and sketch out an implementation for them.
2.1. general physics
we will posit some countable set of world-states, and a distribution of possible initial world-states.
we'll also posit a function which produces a distribution of future world-states for any specific world-state in the universe starting at .
given an initial world-state , we'll call the "universe" that it gives rise to. it must be the case that .
when describes the start of a quantum universe, individual world-states following it by would be expected to correspond to many-worlds everett branches [? · GW].
for concreteness's sake, we could posit , though note that is expected to not just hold information about the initial state of the universe, but also about how it is computed forwards.
given a particular :
finally, we define which checks how much they have past world-states in common:
2.2. quantum turing machines
we will sketch out here a proposal for , , and such that our world-state has hopefully non-exponentially-small .
the basis for this will be a universal quantum turing machine. we will posit:
- the set of turing machine tapes, as finite (thanks to ) sets of relative integers representing positions in the tape holding a 1 rather than a 0.
- some finite () set of states, and some .
- : world-states consist of a tape, state, and machine head index.
- the set of "quantum distributions" over world-states
- the "time step" operator running some universal turing machine's transition matrix to turn one quantum distribution of world-states into another
we'll also define as the "quadratic realityfluid distribution" which assigns diminishing quantities to natural numbers, but only quadratically diminishing:
we can then define as repeated applications of , with quadratically diminishing realityfluid:
where the constant is whatever scalar it needs to be for to be satisfied.
this implementation of measures how much is in the future of by finding paths from to , and then longer paths from to .
and finally, we define as a distribution giving non-zero value to world-states where is a tape where no negative-index cells are set to 1.
because we selected a universal (quantum) turing machine, there is at least one input tape implementing any single quantum algorithm, including the quantum algorithm implementing our physics.
3. implementing QACI
finally, we get into the core mechanisms of QACI.
the core idea of QACI is "blob location": mathematically formalizing the idea of locating our world and locating bitstrings (which i'll call "blobs") stored on computers within that world, out of the space of all possible computational universes, by sampling over functions which extract those blobs from world-states in and functions which can produce a counterfactual world where that blob has been replaced with another blob of the same length (in number of bits).
3.1. question blob and observation
throughout these functions, we will posit the following constants:
- the initial factual question blob
- two "observation" blobs and
are variables which will be passed around, called "observations". in normal AI agent framings, an AI would have a history of actions and observations, and decide on its next action based on that; but, in the one-shot framing we use, there is only a single action and a fixed set of observations. the observations, in practice, will be a very large pieces of data helping the AI locate itself in the multiverse of all possible computations, as well as get a better idea of how and where it is being ran. we will likely include in it things like:
- a full explanation of the QACI alignment plan, including the math
- the AI's code
- a dump of wikipedia and other large parts of the internet
- a copy of some LLM
will be produced before the question blob is generated, and will be produced after the question blob is generated but before the AI is launched.
3.2. overview
the overall shape of what we're doing can be seen on the illustration below: we start at the start of the universe , and use four blob locations and a counterfactual blob function call to locate five other world-states. the illustration shows distributions of future and past world-states, as well as a particular sampling of for all four blob locations.
- we sample using , world-states containing the first observation
- we sample using , world-states containing the second observation
- we sample using , world-states containing the question blob , but requiring that its world-state precede the world-state
- we get , the world-state with a counterfactual question blob, using blob location found by sampling
- we sample using , possible world-states containing an answer to a given counterfactual question
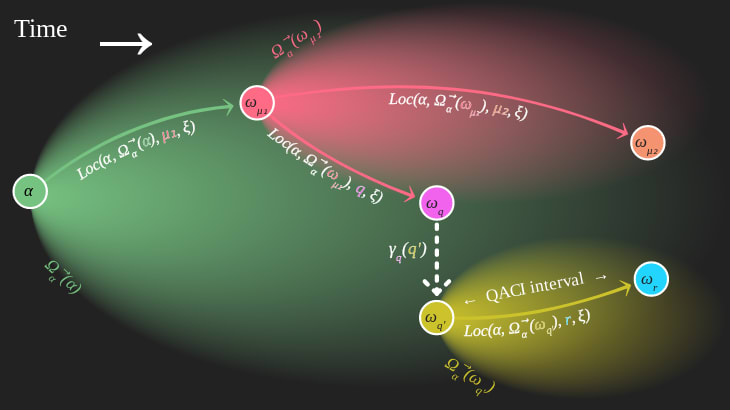
the location path from to is used to run QACI intervals, where counterfactual questions are inserted and answers are located in their future.
(we could also build fancier schemes where we locate the AI's returned action, or its code running over time, in order to "tie more tightly" the blob locations to the AI — but it is not clear that this helps much with blob location failure modes i'm concerned about.)
for the moment, we merely rely on and being uniquely identifying enough — though implementing them as static bitstrings might suffice, perhaps they could instead be implemented as lazily evaluated associative maps. when the AI tries to access members of those maps, code which computes or fetches information from the world (such as from the internet) would be executed determines the contents of that part of the observation object. this way, the observation would be conceptualized as a static object to the AI — and indeed it wouldn't be able to observe any mutations — but it'd be able to observe arbitrary amounts of the world, not just amounts we'd have previously downloaded.
we could make the QACI return not a scoring over actions but a proper utility function, but this only constrains the AI's action space and doesn't look like it helps in any way, including making QACI easier for the AI to make good guesses about. perhaps with utility functions we find a way to make the AI go "ah, well i'm not able to steer much future in world-states where i'm in hijacked sims", but it's not clear how or even that this helps much. so for now, the math focuses on this simple case of returning an action-scoring function.
3.3. blob location
for any blob length (in bits) :
first, we'll posit the set of blob locations; they're identified by a counterfactual blob location function, which takes any counterfactual blob and return the world-state in which a factual blob has been replaced with that counterfactual blob.
tries to locate an individual blob (as a bitstring of length ) in a particular world-state sampled from the time-distribution (past or future) (which will usually be a distribution returned by ) within the universe starting at .
it returns a distribution over counterfactual insertion functions of type which take a counterfactual blob and return the matching counterfactual world-state. the elements in that distribution typically sum up to much less than 1; the total amount they sum up to corresponds to how much finds the given blob in the given world-state to begin with; thus, sampling from a distribution returned by in a constrained mass calculation is useful even if said result is not used, because of its multiplying factor.
note that the returned counterfactual insertion function can be used to locate the factual world-state — simply give it the factual blob as input.
is some countably infinite set of arbitrary pieces of information which each call to can use internally — the goal of this is for multiple different calls to to be able to share some prior information, while only being penalized by for it once. for example, an element of might describe how to extract the contents of a specific laptop's memory from physics, and individual calls only need to specify the date and the memory range. for concreteness, we can posit , the set of finite bitstrings.
works by sampling a pair of functions , which convert world-states forth and back into {pairs whose first element is the blob and whose second element represents everything in the world-state except the blob}.
that latter piece of information is called (tau), and rather than being sampled is defined by the return value of on the original world-state — notably, is not penalized for being arbitrarily large, though and are penalized for their compute time.
for a given fixed pair of and , finds the set of hypothesis world-states with the highest value within the time-distribution for which work as intended. this is intended to select the "closest in time" world-states in , to avoid adversarial attackers generating their own factual blobs and capturing our location.
it then weighs locations using, for every counterfactual blob :
- the degree to which counterfactual world-states tend to share pasts with the original factual world-state, for .
- the compute time of and on counterfactual blobs and world-states respectively.
note that , by design, only supports counterfactual blobs whose length is equal to the length of the initial factual blob — it wouldn't really make sense to talk about "replacing bits" if the bits are different.
in effect, takes random decoding and re-encoding programs, measures how complex and expensive they are and how far from our desired distributions are world-states in which they work, and how close to the factual world-state their counterfactual world-states are.
3.4. blob signing
we'll define , the set of possible answer bitstring payloads.
counterfactual questions will not be signed, and thus will be the set of bitstrings of the same length as the factual question — .
we'll define as . this functions tags blob payloads using a "signature" generated from a seed bitstring, concatenating it to the blob payload.
3.5. action-scoring functions
we will posit as the finite set of actions the AI can take, as a finite set of bitstrings.
we'll call the set of "scoring functions" over actions — functions which "have an opinion" about various actions. this is similar to utility functions, except it's over actions rather than over worlds or world-histories.
they can be composed using , which could be simple scoring-function averaging:
but alternatively, we could use something like Diffractor's Rose bargaining [LW · GW] to reduce the ability for scoring/utility functions to threaten each other — and notably ours.
(where i'm using to mean "maybe define this way, but i'm not sure")
3.6. QACI query
using those, we define which given a physics hypothesis , a question blob location , and a blob location prior , returns the highest guess returned answer payload for a given counterfactual question .
works by sampling answer blob locations , from world-states in the future of the counterfactual question world-state , signed using .
with its first three parameters fixed, becomes the straightforward counterfactual query function : one can call it with arbitrary counterfactual text inputs (within the size limitation), and get a distribution over possible answers, which can easily be collapsed using .
3.7. top-level QACI call
the top-level call to the query function, interprets its output as a piece of math and executes it with, as parameters, various global and contextual values it might need access to, and returns a distribution over action-scoring functions:
where is the initial counterfactual blob, such as "return a good scoring of actions" encoded in ASCII, padded with zeros to be of the right length.
's distribution over answers demands that the answer payload , when interpreted as math and with all required contextual variables passed as input (), returns an action-scoring function equal to — this is how it measures the weight of any action-scoring function .
makes it that 's distributions are only determined by the sampled variables and logical requirements.
's function having access to 's distribution over output texts rather than best candidate allows it to discard as many invalid candidates as it needs and stick to ones that match whatever constraits it has.
3.8. action scoring
we'll posit the AI as — a program which tries to satisfy a scoring over actions, by making a high-expected-score guess.
we define , the action-scoring function which the AI will be making guesses about as a scoring function over actions, which happens to be one that is, hopefully, good. this is the scoring function for which the AI will be trying to produce an action that is as favorable as possible, within its limited capabilities.
where the following variables are sampled:
- an initial state of the universe .
- a blob location prior , sampled for simplicity.
- the blob locations of , , and .
and the world-state containing the second observation is required to be in the future of the word-state containing the question .
then, we rate possible actions by composing the scoring functions produced by for all of those blob location hypotheses.
for any question location, the set of action-scoring functions sampled by is normalized. this is because pairs of AI-action location and question location should not be penalized for having a "harder to find" answer — once the observations and question have been located, we want to obtain the answer no matter what.
finally, we'll just execute the action returned by .
6 comments
Comments sorted by top scores.
comment by Magdalena Wache · 2023-08-08T14:33:03.049Z · LW(p) · GW(p)
I made a deck of Anki cards for this post - I think it is probably quite helpful for anyone who wants to deeply understand QACI. (Someone even told me they found the Anki cards easier to understand than the post itself)
You can have a look at the cards here, and if you want to study them, you can download the deck here.
Here are a few example cards:

comment by Gurkenglas · 2023-06-10T22:58:46.840Z · LW(p) · GW(p)
Probabilities per element treat probability as an intensive property. I suggest: A distribution is a data structure carrying an expectation for every thing that depends on an x∈X.
So if X is [0;6], and the thing-depending-on-x is x², then the distribution concentrated on 5 has a 25 written there, the six-sided-die distribution has written there, and the uniform distribution has written there.
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-06-12T08:16:23.733Z · LW(p) · GW(p)
what do you mean my intensive property, and why do you think i don't want that?
Replies from: Gurkenglas↑ comment by Gurkenglas · 2023-06-12T09:29:06.423Z · LW(p) · GW(p)
Halving an orange keeps its temperature/color/velocity, but halves what mass/energy/charge hang out there. An element has a property, but a quantity has an element.
Probability mass hangs out in timelines. should be "Take this x!", not "Are you x?", agree? Else this won't write itself and needs countability.
comment by Alex K. Chen (parrot) (alex-k-chen) · 2023-09-24T19:01:46.256Z · LW(p) · GW(p)
Is constrained mass M of similarpasts taken over a dot-product of functions that might have similar past w/each other?
Replies from: carado-1↑ comment by Tamsin Leake (carado-1) · 2023-09-24T20:33:27.176Z · LW(p) · GW(p)
something like that yes; something like a dot-product but of distributions over world-states, and those distributions are downstream of world-physics functions.
note that i'm not sure if i get what your comment is asking, let me know if i'm failing to answer your question.