“Sharp Left Turn” discourse: An opinionated review
post by Steven Byrnes (steve2152) · 2025-01-28T18:47:04.395Z · LW · GW · 26 commentsContents
Summary and Table of Contents 1. Background: Autonomous learning 1.1 Intro 1.2 More on “discernment” in human math 1.3 Three ingredients to progress: (1) generation, (2) selection, (3) open-ended accumulation 1.4 Judgment via experiment, versus judgment via discernment 1.5 Where do foundation models fit in? 2. The sense in which “capabilities generalize further than alignment” 2.1 Quotes 2.2 In terms of the (1-3) triad 3. “Definitely-not-evolution-I-swear” Provides Evidence for the Sharp Left Turn 3.1 Evolution per se isn’t the tightest analogy we have to AGI 3.2 “The story of Ev” 3.3 Ways that Ev would have been surprised by exactly how modern humans turned out 3.4 The arc of progress is long, but it bends towards wireheading 3.5 How does Ev feel, overall? 3.6 Spelling out the analogy 3.7 Just how “sharp” is this “left turn”? 3.8 Objection: In this story, “Ev” is pretty stupid. Many of those “surprises” were in fact readily predictable! Future AGI programmers can do better. 3.9 Objection: We have tools at our disposal that “Ev” above was not using, like better sandbox testing, interpretability, corrigibility, and supervision 4. The sense in which “alignment generalizes further than capabilities” 5. Contrasting the two sides 5.1 Three ways to feel optimistic, and why I’m somewhat skeptical of each 5.1.1 The argument that humans will stay abreast of the (1-3) loop, possibly because they’re part of it 5.1.2 The argument that, even if an AI is autonomously running a (1-3) loop, that will not undermine obedient (or helpful, or harmless, or whatever) motivation 5.1.3 The argument that we can and will do better than Ev did 5.2 A fourth, cop-out option None 26 comments
Summary and Table of Contents
The goal of this post is to discuss the so-called “sharp left turn”, the lessons that we learn from analogizing evolution to AGI development, and the claim that “capabilities generalize farther than alignment” … and the competing claims that all three of those things are complete baloney. In particular,
- Section 1 talks about “autonomous learning”, and the related human ability to discern whether ideas hang together and make sense, and how and if that applies to current and future AIs.
- Section 2 presents the case that “capabilities generalize farther than alignment”, by analogy with the evolution of humans.
- Section 3 argues that the analogy between AGI and the evolution of humans is not a great analogy. Instead, I offer a new and (I claim) better analogy between AGI training and, umm, a weird fictional story that has a lot to do with the evolution of humans, but it’s definitely not evolution, I swear. I draw some lessons from this improved analogy, including reasons for both reassurance and concern about an AGI “sharp left turn”.
- Section 4 presents the opposite case that “alignment generalizes farther than capabilities”.
- Section 5 tries to reconcile the two competing claims, partly in terms of different assumptions regarding the level of AI autonomy versus supervision. I wind up mostly pessimistic, but suggest some approaches that might work.
By the way, I categorized this post as part of the 2023 lesswrong annual review [? · GW], as it’s kinda a response to, and riff on, the following:
- Nate Soares (@So8res [LW · GW]): A central AI alignment problem: capabilities generalization, and the sharp left turn (2022) [LW · GW]. (…which elaborates on something also mentioned in Eliezer Yudkowsky AGI Ruin: A List of Lethalities (2022) [LW · GW])
- @Quintin Pope [LW · GW]: Evolution provides no evidence for the sharp left turn (2023) [LW · GW], plus Quintin Pope on the AXRP podcast (2023)
- Beren Millidge (@beren [LW · GW]): Alignment likely generalizes further than capabilities (2024)
- Nate Soares: Humans aren’t fitness maximizers (2022) [LW · GW]
- @Kaj_Sotala [LW · GW]: Genetic fitness is a measure of selection strength, not the selection target (2023) [LW · GW]
- @jacob_cannell [LW · GW]: Evolution Solved Alignment (what sharp left turn?) (2023) [LW · GW]
- @KatjaGrace [LW · GW]: Have we really forsaken natural selection? (2024) [LW · GW]
All these posts are well worth reading, but hopefully this post will be self-contained. There are other posts too, but I won’t be talking about them here.[1]
Target audience: People very familiar with AI alignment discourse. Lots of unexplained jargon etc.
1. Background: Autonomous learning
1.1 Intro
AlphaZero had autonomous learning—the longer you train, the better the model weights. Humans (and collaborative groups of humans) also have that. Hence scientific progress.
For example, you can lock a group of mathematicians in a building for a month with some paper and pens, and they will come out with more and better permanent knowledge of mathematics than when they entered. They didn’t need any new training data; we just “ran them” for longer, and they improved, discovering new things arbitrarily far beyond the training data, with no end in sight.
How does it work? How do we “train” without new training data? Well for AlphaZero-chess, the trick is the integrated chess simulator, including a hardcoded checkmate-detector, which ultimately provides infinite perfect ground truth in how games can play out and which positions are good versus bad. If we switch from chess to math, we can do the same trick via proof assistants like Lean, which can confirm, with perfect confidence, that a formal proof is correct. Thus, we can make AIs search for plausible proofs, and use Lean to check whether those “ideas” are correct, and theoretically the AI will get better and better at proving things. People are already building these kinds of systems—e.g. AlphaGeometry¸ AlphaProof, and DeepSeek-prover.
OK, so a bunch of human mathematicians locked in a building can do open-ended autonomous learning of math. And now thanks to these recent developments based on proof assistants, AI can do that too. Granted, AI hasn’t autonomously proven any long-standing mathematical conjectures yet, so human mathematicians can continue to congratulate themselves for still outclassing the AIs along this dimension. But when I wrote “AI hasn’t autonomously proven any long-standing mathematical conjectures yet”, you should be warned that I haven’t refreshed my AI news feed for several hours! So who knows, really.
…And there goes yet another argument that human brains are doing something qualitatively beyond AIs. Right?
Not so fast!
Humans were able to do open-ended autonomous development of new math, building the whole edifice of modern math completely from scratch … without ever using proof assistants!
That’s definitely something today’s AIs can’t do! So how does it work?
The magic ingredient is that human mathematicians have good discernment of whether things are plausible and make sense and hang together, even without proof assistants.
Does that matter? Who cares if we humans can do open-ended math without proof assistants? We have proof assistants! They’re free and open source!
Yes, it matters very much! Because we have an external source of infinite perfect judgment in formal math, but not in moral philosophy, or macroeconomics, or military strategy, or law, or running a business, or figuring out how to program and deploy AGI such that we get a good future, etc.
Our human discernment is a flexible system that can declare that ideas do or don’t hang together and make sense, in any domain. Whereas in AI, we have external engines of perfect judgment only in narrow areas—basically, the areas that are solvable at superhuman level by today’s RL, such as chess, video games, OpenAI Gym, etc.
Well, I should be more specific. Any particular videogame can be set up in an RL framework, such that we get perfect external judgment of effective strategies. And likewise, any particular programming problem can be set up in a “test-driven development” environment to get perfect external judgment of effective code for this particular problem. But then, of course, one can hope that the trained model will immediately generalize to new coding problems that lack such external judgment tools (e.g. because the answer is not known).
If I understand correctly, GPT-o1 and similar systems were probably likewise trained on particular problems in which the correct answer was known, providing perfect external judgment of effective chain-of-thought reasoning in those particular contexts. And then the researchers hoped that the trained models would immediately generalize to also use effective chain-of-thought reasoning in new contexts. That hope was evidently borne out to some extent, in that the trained models did indeed immediately generalize to better performance on new STEM problems. On the other hand, I hear that the models not only failed to improve in other domains like poetry, but actually regressed a bit—see the post “The Problem With Reasoners” by Aidan McLaughlin. I dunno.
Anyway, Quintin summarizes [LW(p) · GW(p)] this topic as follows: “Autonomous learning basically requires there to be a generator-discriminator gap in the domain in question, i.e., that the agent trying to improve its capabilities in said domain has to be better able to tell the difference between its own good and bad outputs. If it can do so, it can just produce a bunch of outputs, score their goodness, and train / reward itself on its better outputs.”
Yeah that’s part of it, but I think Quintin is still not appreciating the full magic of human discernment. In particular, the discernment can itself get better over time, despite no ground truth. For example, people who spend a lot of time thinking about math will develop much better discernment of what mathematical ideas are plausible and important—and again, they can do all that without ever using proof assistants.
1.2 More on “discernment” in human math
The word “discernment” is on my mind because of a set of great posts from 2015 by @JonahS [LW · GW]: The Truth About Mathematical Ability [? · GW], Innate Mathematical Ability [? · GW], and Is Scott Alexander bad at math? [LW · GW] As I understand it, one of his main arguments is that you can be “good at math” along the dimension(s) of noticing patterns very quickly, AND/OR you can be “good at math” along the dimension(s) of what he calls “aesthetic discernment”—basically, a sense for concepts being plausible, sensible, and elegant.
Discernment is a bit like an internal loss function. It provides a guide-star for developing good, deep understanding. That process may take a very long time, during which you’ll feel confused and unsatisfied. But when you finally come upon a better way to think about something, you’ll know it when you see it.
JonahS offers Scott Alexander and himself as two examples of people with worse-than-average fast-pattern-recognition but unusually good discernment. Both had awful struggles with high school math, but JonahS wound up with a pure math PhD, while meanwhile (quoting Ilya Shpitser) “Scott's complaints about his math abilities often go like this: ‘Man, I wish I wasn't so terrible at math. Now if you will excuse me, I am going to tear the statistical methodology in this paper to pieces.’”
JonahS also brings up Alexander Grothendieck, who was (I presume) perfectly fine at fast-pattern-recognition compared to normal people, but not compared to some of his fellow professional mathematicians. He wrote: “I admired the facility with which they picked up, as if at play, new ideas, juggling them as if familiar with them from the cradle - while for myself I felt clumsy. even oafish, wandering painfully up a arduous track, like a dumb ox faced with an amorphous mountain of things that I had to learn (so I was assured), things I felt incapable of understanding the essentials or following through to the end. Indeed, there was little about me that identified the kind of bright student who wins at prestigious competitions or assimilates, almost by sleight of hand, the most forbidding subjects.” However (says JonahS), Grothendieck had legendary discernment, which allowed him to almost single-handedly rebuild the foundations of a large swathe of modern math, and cemented his reputation as perhaps the greatest mathematician of the 20th century.
1.3 Three ingredients to progress: (1) generation, (2) selection, (3) open-ended accumulation
Consider evolution. It involves (1) generation of multiple variations, (2) selection of the variations that work better, and (3) open-ended accumulation of new variation on top of the foundation of previous successful variation.
By the same token, scientific progress and other sorts of cultural evolution require (1) generation and transmission of ideas, and (2) selection of the ideas that are memetically fit (often because people discern that the ideas are true and/or useful) and (3) open-ended accumulation of new ideas on top of the foundation of old successful ideas.
(And ditto for inventing new technologies, and for individual learning, and so on.)
In Evolution provides no evidence for the sharp left turn [LW · GW], Quintin expounds at length on the (1) part of cultural evolution, basically making the argument:
- Humans transmit ideas at a high bandwidth,
- All other animals transmit ideas at a much, much lower bandwidth,
- …And LLMs are more in the human category here.
Therefore (he continues), we shouldn’t expect any sharp discontinuity in the capabilities of future AI, analogous to the sharp (on evolutionary timescales) discontinuity in the capabilities of our hominid ancestors.
But I think Quintin is not telling the whole story, because he is omitting the roles of (2 & 3).
Don’t get me wrong: if we have AIs that participate in the (1) part of scientific progress and cultural evolution, but not the (2-3), then that’s still a big deal! Such an AI can stay abreast of existing human knowledge, and even contribute to it on the margin, particularly if there’s a human in the loop filling in the missing (2-3).
(Without that human in the loop, things can go off the rails into a proliferation of nonsense—think of the recent flood of misleading AI-generated images in search results, such as the screenshot here [LW · GW].)
But adding (2-3) to the mix—i.e., adding in AIs that can assess whether ideas do or don’t hang together and make sense, and then can keep building from there—is an even bigger deal. With the whole (1-3) triad, an AI (or group of collaborating AIs) can achieve liftoff and rocket to the stratosphere, going arbitrarily far beyond existing human knowledge, just as human knowledge today has rocketed far beyond the human knowledge of ancient Egypt (and forget about chimps).
Or as I’ve written previously [LW · GW]: the wrong idea is “AGI is about knowing how to do lots of things”; the right idea is “AGI is about not knowing how to do something, and then being able to figure it out”. This “figuring out” corresponds to the (1-3) triad.
1.4 Judgment via experiment, versus judgment via discernment
Question from a cynical audience member: “Yeah but humans don’t really have (2). Your examples of things without abundant ground truth—moral philosophy, economics, military strategy, law, running a business, AGI alignment and safety—line up almost exactly with fields of inquiry that are catastrophic messes, with no appreciable intellectual progress in the last fifty years. Funny coincidence, right? The only exception is when there is ground truth: for example, when military technology changes, old strategies are (eventually) abandoned only after numerous catastrophic failures, and likewise capitalism provides ground truth only by ineffective companies going bankrupt.”
My response: There’s a kernel of truth in that, although as stated it’s way too strong. But first things first, that’s kinda orthogonal to what I’ve been saying so far.
Let’s split (2) into two subcategories:
- (2A) judgment of ideas via new external evidence,
- (2B) judgment of ideas via internal discernment of plausibility, elegance, self-consistency, consistency with already-existing knowledge and observations, etc.
An example of (2A) without (2B) is evolution by natural selection. An example of (2B) without (2A) is humans doing math without proof assistants. Most human intellectual progress involves a mix of both (2A) and (2B).
So far, I’ve been arguing that it’s important to think about the possibility of AI getting the whole (1-3) package. And that can happen via pure (2A), pure (2B), or a mix of both. Where it is on that spectrum is not too relevant to my larger point.
But still, it’s worth talking about. In particular, Quintin writes [LW · GW] that one of the only ways that fast takeoff could happen is:
…AIs deliberately seeking out new training data that grant them useful capabilities. E.g., an AI trying to improve its bioengineering capabilities may set up a very fast cycle of gathering and analyzing new biological data, which significantly outpaces the rate of human scientific innovation…
Basically, he’s suggesting that we can ignore (2B), and treat (2A) as a bottleneck on AI knowledge. On this perspective, if we want to know how much an AI has pushed beyond the limits of human knowledge, we can just, y’know, count exactly how many new wet-lab experimental datasets the AI has gathered, and exactly how many FLOP worth of new ML training runs the AI has performed, etc.
If so, I think that’s complete nonsense.
In a healthy figuring-things-out endeavor, (2A) is the fuel, but (2B) is the engine and steering wheel.[2] Or more concretely: (2B) (a.k.a. theories, hypotheses, understanding, hunches, etc.) is the only way to actually figure out what real-world evidence would be useful, how to collect that evidence, and how to convert that new data into ever better understanding.
Just look at the history of any field of science or engineering, and you’ll see that some practitioners were dramatically better than others on the metric of “actual lasting progress per unit of real-world measurement effort”.
Indeed, in many cases, you don’t even need to take measurements, because the data already exists somewhere in the hundreds of thousands of already-published but poorly-analyzed papers. That certainly happens all the time in my own neuroscience research. (See related discussion by Aysja Johnson here [LW(p) · GW(p)].)
Granted, evolution gets by on pure (2A) without any (2B), i.e. without understanding what it’s doing. But evolution is limited to tasks that allow an extraordinary amount of trial and error. All of the problems that I care about in regards to Safe and Beneficial AGI—developing new technologies, philosophy, understanding algorithms before running them, and anticipating and preempting novel societal problems—are heavily reliant on, and indeed (I strongly believe) bottlenecked by, (2B).
1.5 Where do foundation models fit in?
Question from a short-AGI-timelines audience member: “But foundation models totally have discernment! Just ask a chatbot whether some idea is plausible, and it will give a decent answer. Indeed, just look at GPT-o1 chain-of-thought examples—they regularly have passages like ‘Wait, but the error message is being raised by the serializer, so maybe the issue is that…’ That’s a perfect illustration of the model discerning whether an idea plausibly hangs together!”
My response: I don’t think I ever said that foundation models lack discernment? My main goal here is to argue that the presence or absence of the full (1-3) triad is pertinent to the question of the “sharp left turn” and “capabilities generalizing farther than alignment”, not to argue against the possibility that foundation models won’t have that full triad next year, or indeed the possibility that (as suggested by gwern here [LW(p) · GW(p)]) OpenAI’s not-yet-released models are already starting to really develop that full triad right now.
I do make the weaker claim that, as of this writing, publicly-available AI models do not have the full (1-3) triad—generation, selection, and open-ended accumulation—to any significant degree. Specifically, foundation models are not currently set up to do the “selection” in a way that “accumulates”. For example, at an individual level, if a human realizes that something doesn’t make sense, they can and will alter their permanent knowledge store to excise that belief. Likewise, at a group level, in a healthy human scientific community, the latest textbooks delete the ideas that have turned out to be wrong, and the next generation of scientists learns from those now-improved textbooks. But for currently-available foundation models, I don’t think there’s anything analogous to that. The accumulation can only happen within a context window (which is IMO far more limited than weight updates), and also within pre- and post-training (which are in some ways anchored to existing human knowledge; see discussion of o1 in §1.1 above).
…But again, I haven’t refreshed my AI news feed in several hours, so who knows really.
2. The sense in which “capabilities generalize further than alignment”
2.1 Quotes
On one side of the debate we have Eliezer Yudkowsky, who writes in AGI Ruin: A List of Lethalities [LW · GW]:
There's something like a single answer, or a single bucket of answers, for questions like ‘What's the environment really like?’ and ‘How do I figure out the environment?’ and ‘Which of my possible outputs interact with reality in a way that causes reality to have certain properties?’, where a simple outer optimization loop will straightforwardly shove optimizees into this bucket. When you have a wrong belief, reality hits back at your wrong predictions. When you have a broken belief-updater, reality hits back at your broken predictive mechanism via predictive losses, and a gradient descent update fixes the problem in a simple way that can easily cohere with all the other predictive stuff. In contrast, when it comes to a choice of utility function, there are unbounded degrees of freedom and multiple reflectively coherent fixpoints. Reality doesn’t ‘hit back’ against things that are locally aligned with the loss function on a particular range of test cases, but globally misaligned on a wider range of test cases. This is the very abstract story about why hominids, once they finally started to generalize, generalized their capabilities to Moon landings, but their inner optimization no longer adhered very well to the outer-optimization goal of ‘relative inclusive reproductive fitness’ - even though they were in their ancestral environment optimized very strictly around this one thing and nothing else. This abstract dynamic is something you'd expect to be true about outer optimization loops on the order of both ‘natural selection’ and ‘gradient descent’. The central result: Capabilities generalize further than alignment once capabilities start to generalize far.
Or his coworker Nate Soares in A central AI alignment problem: capabilities generalization, and the sharp left turn [LW · GW]:
My guess for how AI progress goes is that at some point, some team gets an AI that starts generalizing sufficiently well, sufficiently far outside of its training distribution, that it can gain mastery of fields like physics, bioengineering, and psychology, to a high enough degree that it more-or-less singlehandedly threatens the entire world. Probably without needing explicit training for its most skilled feats, any more than humans needed many generations of killing off the least-successful rocket engineers to refine our brains towards rocket-engineering before humanity managed to achieve a moon landing.
And in the same stroke that its capabilities leap forward, its alignment properties are revealed to be shallow, and to fail to generalize. The central analogy here is that optimizing apes for inclusive genetic fitness (IGF) doesn't make the resulting humans optimize mentally for IGF. Like, sure, the apes are eating because they have a hunger instinct and having sex because it feels good—but it's not like they could be eating/fornicating due to explicit reasoning about how those activities lead to more IGF. They can't yet perform the sort of abstract reasoning that would correctly justify those actions in terms of IGF. And then, when they start to generalize well in the way of humans, they predictably don't suddenly start eating/fornicating because of abstract reasoning about IGF, even though they now could. Instead, they invent condoms, and fight you if you try to remove their enjoyment of good food (telling them to just calculate IGF manually). The alignment properties you lauded before the capabilities started to generalize, predictably fail to generalize with the capabilities.
2.2 In terms of the (1-3) triad
Let’s bring this back to the (1) generation - (2) selection - (3) open-ended accumulation triad that I was discussing in §1.3 above—the triad that underpins the gradual development of science, technology, and so on from scratch. I think the idea that Eliezer & Nate are suggesting is:
- Chimps did not have this triad.
- Then humans developed this triad, and consequently invented the scientific method and math and biology and nuclear weapons and condoms and Fortnite and so on—and all of this happened from scratch and autonomously.
- All this new knowledge, new understanding, and new options constituted a massive self-generated distribution shift. In the ancestral environment, videogames and hormonal birth control and ice cream were not among the options to choose from, but now they are.
- Capabilities generalized across this distribution shift, because the powerful (1-3) triad works in any possible orderly universe. The same Scientific Method algorithm works in both 17th-century physics and 21st-century biotech, just as the same evolution-by-natural-selection algorithm works in both amoebas and crows. All we need for (2) is that the universe itself provides infinite perfect ground truth for things being true or false, and for plans working or failing.
- Alignment did not generalize across this distribution shift, because why would it? There’s no infinite perfect ground truth for things being good or bad, analogous to the infinite perfect ground truth of experiments and self-consistency and Occam’s razor proving ideas true or false.
“…But wait!”, say a new set of objectors. “Did alignment generalize across the distribution shift, in the case of humans?”
That’s its own debate: for example, Eliezer and Nate say no (see above, plus “Humans aren’t fitness maximizers [LW · GW]”), while Jacob Cannell says yes (“Evolution Solved Alignment (what sharp left turn?) [LW · GW]”), and so does Katja Grace (“Have we really forsaken natural selection? [LW · GW]”). Let’s turn to that debate next.
3. “Definitely-not-evolution-I-swear” Provides Evidence for the Sharp Left Turn
3.1 Evolution per se isn’t the tightest analogy we have to AGI
I think it’s perfectly great and useful [LW(p) · GW(p)] to make true claims about learning algorithms in general, and then to use evolution as an existence proof or example to illustrate those claims.
But once we get past the basics and into the expert commentary—past the existence proofs, and into the trickier domain of whether some specific learning algorithm is likely or unlikely to exhibit some specific behavior—then we run into the problem that learning algorithms in general are too broad a category to get anywhere with.
And in particular, I join Quintin [LW · GW] in the belief that the evolution learning algorithm is sufficiently different from how AGI training will probably work, that it’s hard to transfer much substantive lessons from one to the other.
I prefer the right column here:
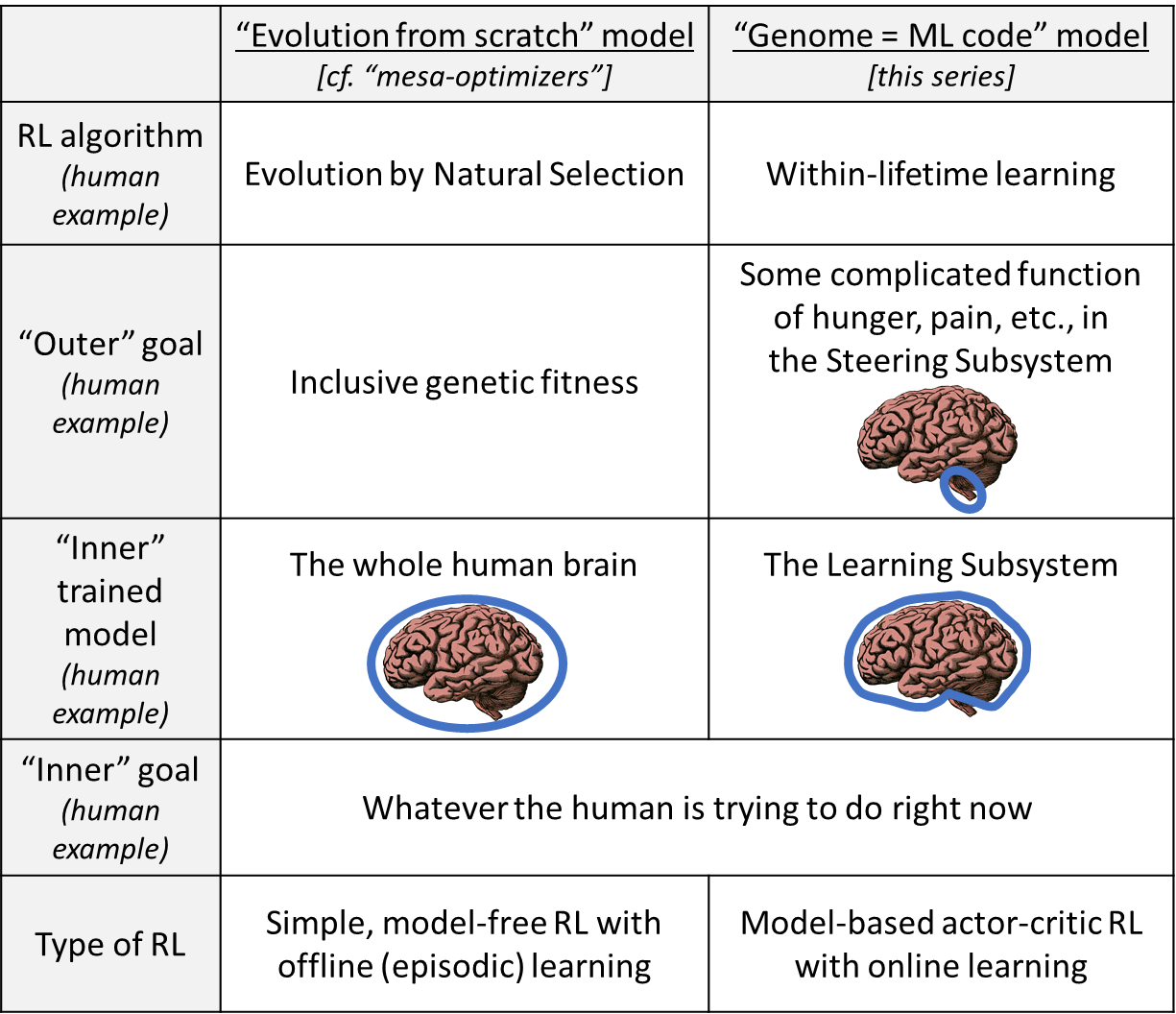
Or here’s another version (copied from [Intro to brain-like-AGI safety] 8. Takeaways from neuro 1/2: On AGI development [LW · GW]).
“Genome = ML code” analogy | |
Human intelligence | Today’s machine learning systems |
Human genome | GitHub repository with all the PyTorch code for training and running the Pac-Man-playing agent |
Within-lifetime learning | Training the Pac-Man-playing agent |
How an adult human thinks and acts | Trained Pac-Man-playing agent |
Evolution | Maybe the ML researchers did an outer-loop search for a handful of human-legible adjustable parameters—e.g., automated hyperparameter tuning, or neural architecture search. |
…And see also my 2021 post, Against evolution as an analogy for how humans will create AGI [LW · GW].
So I’m not wild about the evolution analogy, as conventionally presented and explained. Let’s do better!
3.2 “The story of Ev”
We imagine some “intelligent designer” demigod, let’s call her Ev. In this fictional story, the human brain and body were not designed by evolution, but rather by Ev. So, Ev’s role building humans will be analogous to future programmers’ role building AGI.
Ev was working 100,000 years ago (a time when, in the real world, humans had not yet left Africa, but had basically similar anatomy and intelligence as we have now). And her design goal was for these humans to have high inclusive genetic fitness (IGF).
(Kaj interjects [LW · GW] with a nitpicky detail: That doesn’t quite make sense as stated, because the average IGF across the species is fixed by definition—it’s a relative metric. Rather, Ev wanted each individual to be at roughly a local maximum of their own IGF, holding the rest of the species fixed. You know what I mean.)
OK, so Ev pulls out a blank piece of paper. First things first: She designed the human brain with a fancy large-scale within-lifetime learning algorithm [LW · GW], so that these humans can gradually get to understand the world and take good actions in it.
Supporting that learning algorithm, she needs a reward function, a.k.a. “primary rewards”, a.k.a. “innate drives” [LW · GW]. What to do there? Well, she spends a good deal of time thinking about it, and winds up putting in lots of perfectly sensible components for perfectly sensible reasons.
For example: She wanted the humans to not get injured, so she installed in the human body a system to detect physical injury, and put in the brain an innate drive to avoid getting those injuries, via an innate aversion (negative reward) related to “pain”. And she wanted the humans to eat sugary food, so she put a sweet-food-detector on the tongue and installed in the brain an innate drive to trigger reinforcement (positive reward) when that detector goes off (but modulated by hunger, as detected by yet another system). And so on.
Then she did some debugging and hyperparameter tweaking by running groups of these newly-designed humans in the test environment (the Africa of 100,000 years ago) and seeing how they do.
So that’s how Ev designed humans. Then she “pressed go” and let them run for 100,000 years, and then came back in the year 2025 to take a look. What does she think?
If you read Kaj Sotala’s “Genetic fitness is a measure of selection strength, not the selection target [LW · GW]”, you get an answer like: “Well, Ev put those innate drives in, and we still have them, and our behavior is still reflective of that. We still like sweet tastes! We still like eating when hungry! We still like sex! Etc. So things are working out as Ev intended!”
Well, yeah, those things are all true. But at the same time, I mean, c’mon! Look at how Ev left things 100,000 years ago, and then look at the lives we live today. It’s a pretty wild change! I think it’s fair to say that modern humans are doing things, and wanting things, that Ev would never have expected. Remember, she’s merely an intelligent designer demigod; she’s not omniscient.
3.3 Ways that Ev would have been surprised by exactly how modern humans turned out
For example:
Superstitions and fashions: Some people care, sometimes very intensely, about pretty arbitrary things that Ev could not have possibly anticipated in detail, like where Jupiter is in the sky, and exactly what tattoos they have on their body.
Lack of reflective equilibrium resulting in self-modification: Ev put a lot of work into her design, but sometimes people don’t like some of the innate drives or other design features that Ev put into them, so the people go right ahead and change them! For example, they don’t like how Ev designed their hunger drive, so they take Ozempic. They don’t like how Ev designed their attentional system, so they take Adderall. They don’t like how Ev designed their reproductive systems, so they take hormonal birth control. And so on. Ev had some inkling that this kind of thing could happen, as certain psychoactive drugs and contraception methods were around in her “test environment” too. But I think she would be surprised at how things turned out in detail.
New technology / situations leading to new preferences and behaviors: When Ev created the innate taste drives, she was thinking about the food options available in the “test environment” (Africa 100,000 years ago), and thinking about what drives would lead to people making IGF-maximizing eating choices in that situation. And she came up with a sensible and effective design for taste receptors and associated innate drives that worked well for that circumstance. But maybe she wasn’t thinking that humans would go on to create a world full of ice cream and Coca Cola and so on. Likewise, Ev put in some innate drives related to novelty and aesthetics, with the idea that people would wind up exploring their local environment. Very sensible! But Ev would probably be surprised that her design is now leading to people “exploring” open-world video game environments while cooped up inside. Ditto with social media, television, raising puppies, virtual friends, fentanyl, and a zillion other aspects of modern life. Ev probably didn’t see any of these things coming when she was drawing up and debugging her design, certainly not in any detail.
3.4 The arc of progress is long, but it bends towards wireheading
That last one is a pattern that maybe Ev could generalize and update from. Think about it: Ice cream, video games, social media, television, raising puppies, virtual friends, fentanyl … These all kinda have something in common, right? They feel more wirehead-y than what came before. They hit our innate drives harder and more directly.
To be clear: Within any one lifetime, it’s perfectly possible and common to not want to wirehead. As the saying goes: Reward is not the optimization target [LW · GW]. For example, I don't want to do cocaine right now. If you have some theory of reinforcement learning that predicts that I want to do cocaine right now, then sorry, your theory is wrong, and you should go fix it. (For my own technical discussion of how you messed up, see §9.4-§9.5 at this link [LW · GW].) But at the same time, it does seem like, given enough time and technological powers, our culture does seem to often drift in wirehead-y directions.
Now, our strongest and most cherished values come ultimately from innate drives too. These innate drives are not the ones hooked up to taste buds or pain receptors, but rather what I call “social instincts”—see Neuroscience of human social instincts: a sketch [LW · GW] for some ideas about how they might work. I think that current technology generally doesn’t allow us to wirehead those drives very effectively. We target them a little bit via puppies, social media, and so on, but by and large our core values are still centered on, and derived from interacting with, other flesh-and-blood humans.
…And wow, this suddenly makes me feel much more concerned about where the whole “virtual friends” thing is going. Character.ai recently claimed that they were serving 20,000 queries per second. That’s a lot already, but in the future, presumably they and their competitors will use much better LLMs, and attach them to charismatic expressive animated faces and voices, plus voice and video input. At that point, the whole human social world—friendship, love, norm-following, status-seeking, self-image, helping the downtrodden, etc.—might be in for a wrenching change, when it has to compete with this new unprecedented upstart competition.
To be clear, I’m much more concerned about AGI than virtual friends. But I wanted to bring this up because, if this kind of thing is a possible failure mode for future humans, then it’s a possible failure mode for future AGIs that have human-like social instincts [LW · GW] too.
3.5 How does Ev feel, overall?
Beyond all these surprises, recall that in the test environment of Pleistocene Africa, Ev succeeded at making each human approximately a local optimum of inclusive genetic fitness (IGF), holding the rest of the species fixed. But she was not able to accomplish that by making humans explicitly desire to be at a local optimum of IGF.
And we still don’t explicitly desire that—otherwise people would be bidding their life savings for the privilege of being a sperm donor.
…Granted, that’s not a surprise! When Ev made her design, she would have had no reason to expect that people would explicitly care about IGF. And then she confirmed this in her test environment, where indeed, nobody even knew what “IGF” meant.
But Ev might have been surprised to see the consequences of that lack of explicit desire for IGF become far more profound, as humans’ ability to sculpt their own environment got more powerful.
In other words: in the test environment (100,000 years ago), Ev was able to get decently IGF-maximizing behaviors despite not having any way to make IGF an explicit goal in the humans’ minds. But once humans could transform their knowledge, technology, and society way out of distribution, the absence of IGF as an explicit goal started biting harder. The behaviors of her creations became much more obviously divorced from IGF maximization.
…But wait! Jacob Cannell’s Evolution Solved Alignment (what sharp left turn?) [LW · GW], and Katja Grace’s Have we really forsaken natural selection? [LW · GW], have a response, which I’ll summarize basically as follows:
OK, but in the grand scheme of things, y’know, Ev should be feeling pretty good! Granted, most humans today are nowhere close to IGF-maximizing behaviors. But hey, we haven’t gone extinct either! And while we’re not having many kids—most countries are well below the replacement rate of ≈2.1 births per woman—we’re still having some kids, and most of us are still motivated to have kids, even if it’s never quite the right time, alas. And maybe we or our descendants or brain-uploads or whatever will be colonizing the universe, which is the natural generalization of IGF into the transhumanist future. So really, Ev should be patting herself on the back. …And if our situation as AGI programmers is analogous to Ev’s situation, then that’s good news for us!
Is that right? Is Ev happy with how things are going today, or not? And will Ev be happy with how things go in the future? Keep in mind that we humans are nowhere near the end of technological transformation; “The distribution will continue shifting until morale improves”. Does Ev care about literal DNA molecules, or will Ev still feel good if future medical technology replaces DNA with magical cancer-proof XNA? How will Ev feel if we upload our minds to computers? How will Ev feel if humans go extinct but our AI creations colonize the galaxy?
…These are all very stupid questions. Ev is a fictional character. We can ascribe to her many different possible end-goals, any of which would have led to her creating the same ancient humans. Maybe the XNA thing never occurred to Ev, during her design process. If 100,000 years later, Ev notices that humans have all autonomously switched from DNA to XNA, then she would presumably find it surprising. Would she find it a neutral-to-pleasant surprise, because her original goal was ‘IGF as defined in terms of any old nucleic acid’? Or would she find it a catastrophically unpleasant surprise, because she was going for ‘IGF as defined in terms of DNA in particular’? Either is possible—you can make up your own headcanon.
But the point is: Ev is surprised. And we may look at the things that surprised Ev, and wonder whether future human AGI programmers will be analogously surprised by what their AGIs wind up doing. And we can wonder if the surprises might be unpleasant.
3.6 Spelling out the analogy
Just to make sure everyone is following along,
| Ev, the intelligent designer demigod | ↔ | Future programmers building AGI |
| Human within-lifetime learning | ↔ | AGI training |
| Adult humans | ↔ | “Trained” AGIs (but, like adult humans, they really never stop learning new things) |
| Ev “presses go” and lets human civilization “run” for 100,000 years before checking back in to see how things are going | ↔ | AGI(s) autonomously figure things out and get things done, without detailed human understanding and approval (see below on whether we should expect this to happen) |
| Modern humans care about (and do) lots of things that Ev would have been hard-pressed to anticipate, even though Ev designed their innate drives and within-lifetime learning algorithm in full detail | ↔ | Even if we carefully design the “innate drives” of future AGIs, we should expect to be surprised about what those AGIs end up caring about, particularly when the AGIs have an inconceivably vast action space thanks to being able to invent new technology and new ideas |
3.7 Just how “sharp” is this “left turn”?
We might suppose that Ev has done this activity many times—being an immortal demigod, she designed wasps, trees, and so on, always checking back after 5000 generations to see how things went. (To make the analogy work, let’s assume that 5000 generations is too short for appreciable new evolution to happen; we’re stuck with Ev’s design.)
Sometimes, when Ev comes back, she’s surprised by what her creations are doing.
When she’s surprised, it’s usually because of exogenous distribution-shifts—maybe another species appeared on the scene, or maybe the climate got colder, etc. And now the animal is behaving in a non-adaptive way that surprises Ev.
Less often, Ev is surprised by self-generated distribution shifts—for example, maybe the animal species digs holes, which over the eons changes the soil composition so as to reshape their own habitat.
But I think it’s safe to say that Ev has never been so surprised by the behavior of her creations, as when she checked back in on humans. I think humans are responsible for a self-generated distribution shift whose speed and wildness are unmatched in Ev’s experience.
And no, per Quintin’s objection [LW · GW], this just isn’t about the one-time transition from zero-science to nonzero-science. Quite the contrary: if Ev fast-forwarded again, from right now to another 100,000 years in the future, then I’m confident she would be even more shocked by what’s going on. We humans are still looping the (1-3) triad (§1.3 above), and it’s still causing new self-generated distribution shifts, with no end in sight.
Back to AGI, if you agree with me that today’s already-released AIs don’t have the full (1-3) triad to any appreciable degree, and that future AI algorithms or training approaches will, then there’s going to be a transition between here and there. And this transition might look like someone running a new training run, from random initialization, with a better learning algorithm or training approach than before. While the previous training runs create AIs along the lines that we’re used to, maybe the new one would be like (as gwern said [LW(p) · GW(p)]) “watching the AlphaGo Elo curves: it just keeps going up… and up… and up…”. Or, of course, it might be more gradual than literally a single run with a better setup. Hard to say for sure. My money would be on “more gradual than literally a single run”, but my cynical expectation is that the (maybe a couple years of) transition time will be squandered, for various reasons in §3.3 here [LW · GW].
I do expect that there will be a future AI advance that opens up full-fledged (1-3) triad in any domain, from math-without-proof-assistants, to economics, to philosophy, and everything else. After all, that’s what happened in humans. Like I said in §1.1, our human discernment, (a.k.a. (2B)) is a flexible system that can declare that ideas do or don’t hang together and make sense, regardless of its domain.
…Anyway, these ever-expanding competencies, however “sharply” they arise, would come in lockstep with a self-generation distribution shift, as the AGI has now acquired new options and new ideas, undreamt of in our philosophy. And just as Ev was surprised by modern human decisions, we might likewise be surprised by what the AGI feels motivated to do, and how.
3.8 Objection: In this story, “Ev” is pretty stupid. Many of those “surprises” were in fact readily predictable! Future AGI programmers can do better.
I hope so! On the other hand:
- I expect at least some future AGI programmers to be very stupid indeed about thinking through the eventual safety consequences of the innate drives that they install, on the basis that this is very true today. For example, Yann LeCun keeps proposing to put certain innate drives into AGI that will “obviously” (from my perspective) lead to callous power-seeking behavior (see here [LW · GW]), despite this fact being repeatedly pointed out to him (see here).
- Hindsight is 20/20. Again, a future AGI will have an extraordinarily broad action space, including lots of out-of-the-box ideas that would have never occurred to us, like endeavoring to transform society and invent new technology and so on. Predicting what they will decide to do, given those unfathomable options, seems hard.
3.9 Objection: We have tools at our disposal that “Ev” above was not using, like better sandbox testing, interpretability, corrigibility, and supervision
This is an important point. Actually, it’s two important points: “pre-deployment tools” and “real-time supervision tools”. For example, sandbox testing is part of the former, corrigibility and spot-checks are part of the latter, and interpretability can be part of either or both.
Start with “pre-deployment” testing. I’m for it! But I don’t think we can get high confidence that way. By analogy, I’m radically uncertain about what future humanity will be like (if indeed it exists at all) despite having seen tons of human behavior in the past and present environment, and despite introspective access to at least my own mind.
The basic issue here is that AI with the (1-3) triad (§1.3 above) can learn and grow, autonomously and open-endedly, involving new ideas, new options, and hence distribution shifts and ontological crises. You can’t make an AI CEO unless it can keep figuring out new things, in new domains, which can’t be predicted in advance. The analogy is to how a human’s goals and values may change over the course of decades, not how they change over the course of answering one question—more discussion here [LW(p) · GW(p)].
Next, what about “real-time supervision”—corrigibility, spot-checks, applying interpretability tools as the model runs, and so on?
That’s a bigger deal. Remember, Ev was chilling on Mount Olympus for 100,000 years, while humans did whatever they wanted. Surely we humans can supervise our AIs more closely than that, right? And if so, that really changes the mental image.
Is it plausible, though? Good question, which brings us to our next topic:
4. The sense in which “alignment generalizes further than capabilities”
Now that the “capabilities generalize further” side has had its say, let’s turn to the other side. We have Beren Millidge’s Alignment likely generalizes further than capabilities, along with Quintin Pope’s Evolution provides no evidence for the sharp left turn [LW · GW], plus his further elaboration on the AXRP podcast.
Here’s my summary of their main point. If you look at humans, it’s generally a lot easier to figure out what they want to happen, then to figure out how to make those things happen. In other words, if humans can impart preferences into an AI at all, then they can impart preferences about things that nobody knows how to do yet. For example, I am a human, and I don’t know how to make a super-plague, but I sure do have an opinion about making super-plagues: I’m against it.
Presumably (according to this school of thought), we’ll align future AIs via some combination of human feedback and human observations, directly or indirectly. And this will be plenty for those AIs to understand what humans want, and make decisions that humans are happy about, way past its capability level. And if the AI is ever unsure, it can always check in with the human, or act conservatively.
5. Contrasting the two sides
- The optimistic “alignment generalizes farther” argument is saying: if the AI is robustly motivated to be obedient (or helpful, or harmless, or whatever), then that motivation can guide its actions in a rather wide variety of situations.
- The pessimistic “capabilities generalize farther” counterargument is saying: hang on, is the AI robustly motivated to be obedient? Or is it motivated to be obedient in a way that is not resilient to the wrenching distribution shifts that we get when the AI has the (1-3) triad (§1.3 above) looping around and around, repeatedly changing its ontology, ideas, and available options?
The optimists then have a few possible replies here. Let’s go through them.
5.1 Three ways to feel optimistic, and why I’m somewhat skeptical of each
5.1.1 The argument that humans will stay abreast of the (1-3) loop, possibly because they’re part of it
The first way to feel optimistic is to say that the AIs will not be autonomously and open-endedly running the (1-3) triad. Instead, humans will be in the loop pretty much every step of the way.
That way, if the AI-human team figures something out—opening up new options and new ways of thinking about things—the human can clarify their preferences and opinions in light of that discovery.
I think a lot of optimists are getting their optimism from this category, because this is how people use foundation models today.
…But I’m not so reassured. I think this is a case where it’s wrong to extrapolate the present into the future.
To be clear, I’m very happy about how people use foundation models today! They’re productivity enhancers, just like arxiv and word processing are productivity enhancers. But foundation models today (I claim) don’t have the full (1-3) triad to any appreciable degree by themselves, and therefore humans need to supply the (2-3). I don’t think we can generalize that situation into the future. People will eventually develop AIs that “achieve liftoff” with the (1-3) triad, and we need to be ready for that transition, and whatever new issues it may bring.
So when people plan for future “automated alignment research”, they’re welcome to assume that future human alignment researchers will be getting a productivity boost of, I dunno, 50% or whatever, thanks to their ever-better AI tools. But I also see a lot of people talking instead about 10× productivity boosts, or even complete human substitution. I don’t think that’s on the table until after the transition to more dangerous AIs that can really autonomously and open-endedly run the (1-3) loop. So saying AIs will help do alignment research, and not just be a helpful tool for alignment research, is a chicken-and-egg error.
5.1.2 The argument that, even if an AI is autonomously running a (1-3) loop, that will not undermine obedient (or helpful, or harmless, or whatever) motivation
A second way to feel optimistic is to suggest that it’s fine for AI to autonomously run the (1-3) triad, because its good motivations will persist.
More concretely, suppose we just want the AIs to solve specific technical problems. It’s fine if the AI uses its (1-3) superpowers, because it will only be using them in service of this technical problem.
Thus, if the AI is working on the inverse protein folding problem, then its (1-3) superpowers will help it find new better ways to think about the problem, and creative out-of-the-box ways to attack it. And ditto if it’s refactoring code, and ditto if it’s choosing a location for a solar cell factory, or whatever else we have in mind.
But (the story continues) the AI will not be applying its (1-3) superpowers to find creative out-of-the-box new ways to, umm, “scratch its internal itches”, that are more adjacent to wireheading, and that may come wildly apart from its earlier obedient / helpful / whatever behavior, just as playing Zelda is wildly different from the traditional climbing behavior that we were previously employing to satisfy our drive to enjoy beautiful vistas.
…But I’m not so reassured. In this case, I have two concerns.
My first concern is the obvious one: we want the AI to only apply its (1-3) superpowers towards such-and-such technical problem, but not apply (1-3) superpowers towards profoundly rethinking how to “scratch its internal itches”. But how do we ensure that? You can find a very pessimistic take on Nate’s side of Holden Karnofsky’s Discussion with Nate Soares on a key alignment difficulty (2023) [LW · GW]—basically, he argues that (1-3) requires metacognition, and metacognition leads to self-reflection and self-reconceptualization, and thence to trouble. I’m not sure whether I buy that (see Holden’s counterarguments at the link). I think I would want to know more about the exact nature of the AI algorithm / training approach, and particularly how it got the full (1-3) triad, before expressing any strong opinion. From where I am right now, this step seems neither fine-by-default nor doomed, and merits further thought.
My second concern is that “AIs solving specific technical problems that the human wants them to solve” is insufficient to avoid extinction and get to a good future—even if the AI is solving those problems at superhuman level and with the help of (1-3) superpowers.[3]
I won’t go much into details of why I have this concern, since I want to keep this post focused on technical alignment. But I’ll spend just a few paragraphs to give a hint. For more, see my What does it take to defend the world against out-of-control AGIs? [LW · GW] and John Wentworth’s The Case Against AI Control [LW · GW].
Here’s an illustrative example. People right now are researching dangerous viruses, in a way that poses a risk of catastrophic lab leaks wildly out of proportion to any benefits. Why is that happening? Not because everyone is trying to stop it, but they lack the technical competence to execute. Quite the contrary! Powerful institutions like governments are not only allowing it, but are often funding it!
I think when people imagine future AI helping with this specific problem, they’re usually imagining the AI convincing people—say, government officials, or perhaps the researchers themselves—that this activity is unwise. See the problem? If AI is convincing people of things, well, powerful AIs will be able to convince people of bad and false things as well as good and true things. So if the AI is exercising its own best judgment in what to convince people of, then we’d better hope that the AI has good judgment! And it’s evidently not deriving that good judgment from human preferences. Human preferences are what got us into this mess! Right?
Remember, the “alignment generalizes farther” argument (§4 above) says that we shouldn’t worry because AI understands human preferences, and those preferences will guide its actions (via RLHF or whatever). But if we want an AI that questions human preferences rather than slavishly following them, then that argument would not be applicable! So how are we hoping to ground the AI’s motivations? It has to be something more like “ambitious value learning” [LW · GW] or Coherent Extrapolated Volition [? · GW]—things that are philosophically fraught, and rather different from what people today are doing with foundation models.
5.1.3 The argument that we can and will do better than Ev did
A third way to feel optimistic is to say that we can and will do better than Ev did. Remember, Ev is just a demigod, not omnipotent and omniscient.
In particular, as described in §3.5 above, Ev failed to make humans explicitly desire to be at a local optimum of inclusive genetic fitness (IGF). She managed to get decently IGF-maximizing behavior despite that failure, but only in the test environment of Pleistocene Africa, and not in a way that’s robust to the endless self-generated distribution shifts of open-ended (1-3) looping.
“Well OK,” says the optimist. “…so much the worse for Ev! She didn’t have interpretability, and she didn’t have intelligent supervision after the training has already been running, etc. But we do! Let’s just engineer the AI’s explicit motivation!”
That gets us to things like “Plan for mediocre alignment of brain-like [model-based RL] AGI [LW · GW]” (in a model-based RL AGI scenario), or “Alignment by default” [LW · GW] (in a foundation model scenario).
I will make the very mildly optimistic claim that such ideas are not completely certain to cause human extinction. I’m hesitant to say anything much stronger. Neither of these is a proposal for corrigibility—remember from §5.1.2 just above, I don’t think corrigible AIs are enough to get us into a good post-AGI future. (And in the model-based RL scenario, corrigibility has an additional technical challenge; search for the phrase “the first-person problem” at that link [LW · GW].) So the plan really has to work, without course-correcting, through unlimited amounts of the (1-3) loop. That loop will bring on wave after wave of ontological crises, and new options, and new ideas, including via self-reflection. And we don’t have any historical precedent to help us think about how that might go—again, Ev was using very different techniques, as opposed to locking in particular learned concepts as permanent goals. So anyway, for these and other reasons, I lean pessimistic, although who knows.
5.2 A fourth, cop-out option
Alternatively, there’s a cop-out option! If the outcome of the (1-3) loop is so hard to predict, we could choose to endorse the process while being agnostic about the outcome.
There is in fact a precedent for that—indeed, it’s the status quo! We don’t know what the next generation of humans will choose to do, but we’re nevertheless generally happy to entrust the future to them. The problem is the same—the next generation of humans will spin their (1-3) loop, causing self-generated distribution shifts, and ending up going in unpredictable directions. But this is how it’s always been, and we generally feel good about it.
So the idea here is, we could make AIs with social and moral drives that we’re happy about, probably because those drives are human-like in some respects, and then we could define “good” as whatever those AIs wind up wanting, upon learning and reflection.
I don’t think this is the default consequence of how people are training their AIs today, but it is a possible thing we could try to do. For more on that, see my post [Intro to brain-like-AGI safety] 12. Two paths forward: “Controlled AGI” and “Social-instinct AGI” [LW · GW].
Thanks Charlie Steiner and Jeremy Gillen for critical comments on earlier drafts.
- ^
For example:
- Ramana Kumar, Will Capabilities Generalise More? (2022) [LW · GW]: nice little summary of some arguments.
- Jan Kulveit, We don't understand what happened with culture enough (2023) [LW · GW]: I didn’t get anything out of this, it just confused me, but YMMV.
- Zvi Mowshowitz, Response to Quintin Pope's Evolution Provides No Evidence For the Sharp Left Turn (2023) [LW · GW]: I found it more about responding to very specific things, and not so much bringing new positive arguments to the table, which is why I don’t talk about it in this post.
- Others at the Sharp Left Turn tag [? · GW].
- ^
When groups of humans form a discipline, (2A) plays an additional, complementary role, related to community epistemics. As the saying goes: [LW · GW] “all that Science really asks of you [is] the ability to accept reality when you're beat over the head with it.” Basically, some people have more (2B), and they figure out what’s going on on the basis of hints and indirect evidence. Others don’t. The former group can gather ever-more-direct and ever-more-unassailable (2A)-type evidence, and use that evidence as a cudgel with which to beat the latter group over the head until they finally get it. This is an important social tool, and its absence is why bad scientific ideas can die, while bad philosophy ideas live forever. Actually, it’s even worse than that. If the bad philosophy ideas don’t die, then there’s no common knowledge that the bad philosophers are bad, and then they can rise in the ranks and hire other bad philosophers, and the whole culture can gradually shift in bad directions like prizing novelty over correctness [LW · GW].
- ^
A possible exception is the idea of “pivotal acts”. But few people these days seem to be thinking along those lines, for better or worse.
26 comments
Comments sorted by top scores.
comment by Joel Burget (joel-burget) · 2025-02-01T17:42:00.406Z · LW(p) · GW(p)
I like this post but I think it misses / barely covers two of the most important cases for optimism.
1. Detail of specification
Frontier LLMs have a very good understanding of humans, and seem to model them as well as or even better than other humans. I recall seeing repeated reports of Claude understanding its interlocutor faster than they thought was possible, as if it just "gets" them, e.g. from one Reddit thread I quickly found:
- "sometimes, when i’m tired, i type some lousy prompts, full of typos, incomplete info etc, but Claude still gets me, on a deep fucking level"
- "The ability of how Claude AI capture your intentions behind your questions is truly remarkable. Sometimes perhaps you're being vague or something, but it will still get you."
- "even with new chats, it still fills in the gaps and understands my intention"
LLMs have presumably been trained on:
- millions of anecdotes from the internet, including how the author felt, other users' reactions and commentary, etc.
- case law: how did humans chosen for their wisdom (judges) determine what was right and wrong
- thousands of philosophy books
- Lesswrong / Alignment Forum, with extensive debate on what would be right and wrong for AIs to do
There are also techniques like deliberative alignment, which includes an explicit specification for how AIs should behave. I don't think the model spec is currently detailed enough but I assume OpenAI intend to actively update it.
Compare this to the "specification" humans are given by your Ev character: some basic desires for food, comfort, etc. Our desires are very crude, confusing, and inconsistent; and only very roughly correlate with IGF. It's hard to emphasize enough how much more detailed is the specification that we present to AI models.
2. (Somewhat) Gradual Scaling
Toby Ord estimates that pretraining "compute required scales as the 20th power of the desired accuracy". He estimates that inference scaling is even more expensive, requiring exponentially more compute just to make constant progress. Both of these trends suggest that, even with large investments, performance will increase slowly from hardware alone (this relies on the assumption that hardware performance / $ is increasing slowly, which seems empirically justified). Progress could be faster if big algorithmic improvements are found. In particular I want to call out that recursive-self improvement (especially without a human in the loop) could blow up this argument (which is why I wish it was banned). Still, I'm overall optimistic that capabilities will scale fairly smoothly / predictably.
With (1) and (2) combined, we're able to gain some experience with each successive generation of models, and add anything we find is missing from the training dataset / model spec, without taking any leaps that are too big / dangerous. I don't want to suggest that the scaling up while maintaining alignment process will definitely succeed, just that we should update towards the optimistic view based on these arguments.
Replies from: steve2152, Kajus↑ comment by Steven Byrnes (steve2152) · 2025-02-01T22:34:42.794Z · LW(p) · GW(p)
For (2), I’m gonna uncharitably rephrase your point as saying: “There hasn’t been a sharp left turn yet, and therefore I’m overall optimistic there will never be a sharp left turn in the future.” Right?
I’m not really sure how to respond to that … I feel like you’re disagreeing with one of the main arguments of this post without engaging it. Umm, see §1. One key part is §1.5:
I do make the weaker claim that, as of this writing, publicly-available AI models do not have the full (1-3) triad—generation, selection, and open-ended accumulation—to any significant degree. Specifically, foundation models are not currently set up to do the “selection” in a way that “accumulates”. For example, at an individual level, if a human realizes that something doesn’t make sense, they can and will alter their permanent knowledge store to excise that belief. Likewise, at a group level, in a healthy human scientific community, the latest textbooks delete the ideas that have turned out to be wrong, and the next generation of scientists learns from those now-improved textbooks. But for currently-available foundation models, I don’t think there’s anything analogous to that. The accumulation can only happen within a context window (which is IMO far more limited than weight updates), and also within pre- and post-training (which are in some ways anchored to existing human knowledge; see discussion of o1 in §1.1 above).
…And then §3.7:
Back to AGI, if you agree with me that today’s already-released AIs don’t have the full (1-3) triad to any appreciable degree [as I argued in §1.5], and that future AI algorithms or training approaches will, then there’s going to be a transition between here and there. And this transition might look like someone running a new training run, from random initialization, with a better learning algorithm or training approach than before. While the previous training runs create AIs along the lines that we’re used to, maybe the new one would be like (as gwern said [LW(p) · GW(p)]) “watching the AlphaGo Elo curves: it just keeps going up… and up… and up…”. Or, of course, it might be more gradual than literally a single run with a better setup. Hard to say for sure. My money would be on “more gradual than literally a single run”, but my cynical expectation is that the (maybe a couple years of) transition time will be squandered, for various reasons in §3.3 here [LW · GW].
I do expect that there will be a future AI advance that opens up full-fledged (1-3) triad in any domain, from math-without-proof-assistants, to economics, to philosophy, and everything else. After all, that’s what happened in humans. Like I said in §1.1, our human discernment, (a.k.a. (2B)) is a flexible system that can declare that ideas do or don’t hang together and make sense, regardless of its domain.
This post is agnostic over whether the sharp left turn will be a big algorithmic advance (akin to switching from MuZero to LLMs, for example), versus a smaller training setup change (akin to o1 using RL in a different way than previous LLMs, for example). [I have opinions, but they’re out-of-scope.] A third option is “just scaling the popular LLM training techniques that are already in widespread use as of this writing”, but I don’t personally see how that option would lead to the (1-3) triad, for reasons in the excerpt above. (This is related to my expectation that LLM training techniques in widespread use as of this writing will not scale to AGI … which should not be a crazy hypothesis, given that LLM training techniques were different as recently as ≈6 months ago!) But even if you disagree, it still doesn’t really matter for this post. I’m focusing on the existence of the sharp left turn and its consequences, not what future programmers will do to precipitate it.
~~
For (1), I did mention that we can hope to do better than Ev (see §5.1.3), but I still feel like you didn’t even understand the major concern that I was trying to bring up in this post. Excerpting again:
- The optimistic “alignment generalizes farther” argument is saying: if the AI is robustly motivated to be obedient (or helpful, or harmless, or whatever), then that motivation can guide its actions in a rather wide variety of situations.
- The pessimistic “capabilities generalize farther” counterargument is saying: hang on, is the AI robustly motivated to be obedient? Or is it motivated to be obedient in a way that is not resilient to the wrenching distribution shifts that we get when the AI has the (1-3) triad (§1.3 above) looping around and around, repeatedly changing its ontology, ideas, and available options?
Again, the big claim of this post is that the sharp left turn has not happened yet. We can and should argue about whether we should feel optimistic or pessimistic about those “wrenching distribution shifts”, but those arguments are as yet untested, i.e. they cannot be resolved by observing today’s pre-sharp-left-turn LLMs. See what I mean?
Replies from: joel-burget↑ comment by Joel Burget (joel-burget) · 2025-02-02T04:27:24.474Z · LW(p) · GW(p)
For (2), I’m gonna uncharitably rephrase your point as saying: “There hasn’t been a sharp left turn yet, and therefore I’m overall optimistic there will never be a sharp left turn in the future.” Right?
Hm, I wouldn't have phrased it that way. Point (2) says nothing about the probability of there being a "left turn", just the speed at which it would happen. When I hear "sharp left turn", I picture something getting out of control overnight, so it's useful to contextualize how much compute you have to put in to get performance out, since this suggests that (inasmuch as it's driven by compute) capabilities ought to grow gradually.
I feel like you’re disagreeing with one of the main arguments of this post without engaging it.
I didn't mean to disagree with anything in your post, just to add a couple points which I didn't think were addressed.
You're right that point (2) wasn't engaging with the (1-3) triad, because it wasn't mean to. It's only about the rate of growth of capabilities (which is important because if each subsequent model is only 10% more capable than the one which came before then there's good reason to think that alignment techniques which work well on current models will also work on subsequent models).
Again, the big claim of this post is that the sharp left turn has not happened yet. We can and should argue about whether we should feel optimistic or pessimistic about those “wrenching distribution shifts”, but those arguments are as yet untested, i.e. they cannot be resolved by observing today’s pre-sharp-left-turn LLMs. See what I mean?
I do see, and I think this gets at the difference in our (world) models. In a world where there's a real discontinuity, you're right, you can't say much about a post-sharp-turn LLM. In a world where there's continuous progress, like I mentioned above, I'd be surprised if a "left turn" suddenly appeared without any warning.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-02-03T15:30:47.445Z · LW(p) · GW(p)
Thanks! I still feel like you’re missing my point, let me try again, thanks for being my guinea pig as I try to get to the bottom of it. :)
inasmuch as it's driven by compute
In terms of the “genome = ML code” analogy (§3.1), humans today have the same compute as humans 100,000 years ago. But humans today have dramatically more capabilities—we have invented the scientific method and math and biology and nuclear weapons and condoms and Fortnite and so on, and we did all that, all by ourselves, autonomously, from scratch. There was no intelligent external non-human entity who was providing humans with bigger brains or new training data or new training setups or new inference setups or anything else.
If you look at AI today, it’s very different from that. LLMs today work better than LLMs from six months ago, but only because there was an intelligent external entity, namely humans, who was providing the LLM with more layers, new training data, new training setups, new inference setups, etc.
…And if you’re now thinking “ohhh, OK, Steve is just talking about AI doing AI research, like recursive self-improvement, yeah duh, I already mentioned that in my first comment” … then you’re still misunderstanding me!
Again, think of the “genome = ML code” analogy (§3.1). In that analogy,
- “AIs building better AIs by doing the exact same kinds of stuff that human researchers are doing today to build better AIs”
- …would be analogous to…
- “Early humans creating more intelligent descendants by doing biotech or selective breeding or experimentally-optimized child-rearing or whatever”.
But humans didn’t do that. We still have basically the same brains as our ancestors 100,000 years ago. And yet humans were still able to dramatically autonomously improve their capabilities, compared to 100,000 years ago. We were making stone tools back then, we’re making nuclear weapons now.
Thus, autonomous learning is a different axis of AI capabilities improvement. It’s unrelated to scaling, and it’s unrelated to “automated AI capabilities research” (as typically envisioned by people in the LLM-sphere). And “sharp left turn” is what I’m calling the transition from “no open-ended autonomous learning” (i.e., the status quo) to “yes open-ended autonomous learning” (i.e., sometime in the future). It’s a future transition, and it has profound implications, and it hasn’t even started (§1.5). It doesn’t have to happen overnight—see §3.7. See what I mean?
Replies from: joel-burget↑ comment by Joel Burget (joel-burget) · 2025-02-10T03:42:01.089Z · LW(p) · GW(p)
Thanks for your patience: I do think this message makes your point clearly. However, I'm sorry to say, I still don't think I was missing the point. I reviewed §1.5, still believe I understand the open-ended autonomous learning distribution shift, and also find it scary. I also reviewed §3.7, and found it to basically match my model, especially this bit:
Or, of course, it might be more gradual than literally a single run with a better setup. Hard to say for sure. My money would be on “more gradual than literally a single run”, but my cynical expectation is that the (maybe a couple years of) transition time will be squandered
Overall, I don't have the impression we disagree too much. My guess for what's going on (and it's my fault) is that my initial comment's focus on scaling was not a reaction to anything you said in your post, in fact you didn't say much about scaling at all. It was more a response to the scaling discussion I see elsewhere.
↑ comment by Kajus · 2025-02-02T11:27:22.224Z · LW(p) · GW(p)
Interesting! I wonder what makes peopel feel like LLMs get them. I for sure don't feel like Claude gets me. If anything, the opposite.
EDIT: Deepseek totally gets me tho
↑ comment by Satron · 2025-02-02T11:57:43.126Z · LW(p) · GW(p)
Not OP, but for me, it comes down to LLMs correctly interpreting the intent behind my questions/requests. In other words, I don't need to be hyper specific in my prompts in order to get the results I want.
Replies from: Kajus↑ comment by Kajus · 2025-02-02T17:07:15.214Z · LW(p) · GW(p)
That makes sense and is well pretty obvious. Why isn't claude getting me tho and he is getting other people? It's hard for me to even explain claude what kind of code he should write. It is just a skill issue? Can someone teach me how to prompt claude?
comment by Seth Herd · 2025-01-30T05:17:19.510Z · LW(p) · GW(p)
I place this alongside the Simplicia/Doomimir [LW · GW] dialogues as the farthest we've gotten (at least in publicly legible form) on understanding the dramatic disagreements on the difficulty of alignment.
There's a lot here. I won't try to respond to all of it right now.
I think the most important bit is the analysis of arguments for how well alignment generalizes vs. capabilities.
Conceptual representations generalize farther than sensory representations. That's their purpose. So when behavior (and therefore alignment) is governed by conceptual representations, it will generalize relatively well.
When alignment is based on a relatively simple reward model based on simple sensory representations, it won't generalize very well. That's the case with humans. The reward model is running on sensory representations (it has to so they can be specified in the limited information space of DNA, as you and others have discussed).
Alignment generalizes farther than capabilities in well-educated, carefully considered modern humans because our goals are formulated in terms of concepts. (There are still ways this could go awry, but I think most modern humans would generalize their goals well and lead us into a spectacular future if they were in charge of it).
This could be taken as an argument for using some type of goals selected from learned knowledge [AF · GW] for alignment if possible. If we could use natural language (or another route to conceptual representations) to specify an AI's goals, it seems like that would produce better generalization than just trying to train stuff in with RL to produce behavior we like in the training environment.
One method of "conceptual alignment" is the variant of your Plan for mediocre alignment of brain-like [model-based RL] AGI [LW · GW] in which you more or less say to a trained AI "hey think about human flourishing" and then set the critic system's weights to maximum. Another is alignment-by-prompting for LLM-based agents; I discuss that in Internal independent review for language model agent alignment [AF · GW]. I'm less optimistic now than when I wrote that, given the progress made in training vs. scripting for better metacognition - but I'm not giving up on it just yet. Tan Zhi Xuan makes the point in this interview that we're really training LLMs mostly to have a good world model and to follow instructions, similar to Andrej Karpathy's point that RLHF is just barely RL. It's similar with RLAIF and the reward models training R1 for usability, after the pure RL on verifiable answers. So we're still training models to have good world models and follow instructions. Played wisely, it seems like that could produce aligned LLM agents (should that route reach "real AGI" [LW · GW]).
That's a new formulation of an old thought, prompted by your framing of pitting the arguments for capabilities generalizing farther than alignment (for evolution making humans) and alignment generalizing farther than capabilities (for modern humans given access to new technologies/capabilities).
The alternative is trying to get an RL system to "gel" into a concept-based alignment we like. This happens with a lot of humans, but that's a pretty specific set of innate drives (simple reward models) and environment. If we monitored and nudged the system closely, that might work too.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-30T18:39:14.045Z · LW(p) · GW(p)
Thanks!
This could be taken as an argument for using some type of goals selected from learned knowledge [LW · GW] for alignment if possible.
Yeah that’s what I was referring to in the paragraph:
“Well OK,” says the optimist. “…so much the worse for Ev! She didn’t have interpretability, and she didn’t have intelligent supervision after the training has already been running, etc. But we do! Let’s just engineer the AI’s explicit motivation!”
Separately, you also wrote:
we're really training LLMs mostly to have a good world model and to follow instructions
I think I mostly agree with that, but it’s less true of o1 / r1-type stuff than what came before, right? (See: o1 is a bad idea [LW · GW].) Then your reply is: DeepSeek r1 was post-trained for “correctness at any cost”, but it was post-post-trained for “usability”. Even if we’re not concerned about alignment faking [LW · GW] during post-post-training (should we be?), I also have the idea at the back of my mind that future SOTA AI with full-fledged (1-3) loops probably (IMO) won’t be trained in the exact same way than present SOTA AI, just as present SOTA AI is not trained in the exact same way as SOTA AI as recently as like six months ago. Just something to keep in mind.
Anyway, I kinda have three layers of concerns, and this is just discussing one of them. See “Optimist type 2B” in this comment [LW(p) · GW(p)].
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-30T19:54:23.798Z · LW(p) · GW(p)
> we're really training LLMs mostly to have a good world model and to follow instructions
I think I mostly agree with that, but it’s less true of o1 / r1-type stuff than what came before, right?
I think it's actually not any less true of o1/r1. It's still mostly predictive/world modeling training, with a dash of human-preference RL which could be described as following instructions as intended in a certain set of task domains. o1/r1 is a bad idea because RL training on a whole CoT works against faithfulness/transparency of the CoT.
If that's all we did, I assume we'd be dead when an agent based on such a system started doing what you describe as the 1-3 loop (which I'm going to term self-optimization). Letting the goals implicit in that training sort of coagulate into explicit goals would probably produce explicit, generalizing goals we'd hate. I find alignment by default wildly unlikely.
But that's not all we'll do when we turn those systems into agents. Developers will probably at least try to give the agent explicit goals, too.
Then there's going to be a complex process where the implicit and explicit goals sort of mix together or compete or something when the agent self-optimizes. Maybe we could think of this as a teenager decideing what their values are, sorting out their biological drives toward hedonism and pleasing others, along with the ideals they've been taught to follow until they could question them.
I think we're going to have to get into detail on how that process of working through goals from different sources might work. That's what I'm trying to do in my current work.
WRT your Optimist Type 2B pessimism: I don't think AI taste should play a role in AI help solving the value alignment problem. If we had any sense (which sometimes we do once problems are right in our faces), we'd be asking the AI "so what happens if we use this alignment approach/goal?" and then using our own taste, not asking it things like "tell us what to do with our future". We could certainly ask for input and there are ways that could go wrong. But I mostly hope for AGI help in the technical part of solving stable value alignment.
I'm not sure I'm more optimistic than you, but I am quite uncertain about how well the likely (low but not zero effort/thought) methods of aligning network-based AGI might go. I think others should be more uncertain as well. Some people being certain of doom while others with real expertise thinking it's probably going to be fine should be a signal that we do not have this worked through yet.
That's why I like this post and similar attempts to resolve optimist/pessimist disagreements so much.
↑ comment by Steven Byrnes (steve2152) · 2025-01-30T21:23:55.161Z · LW(p) · GW(p)
I think it's actually not any less true of o1/r1.
I think I’ll duck out of this discussion because I don’t actually believe that o1/r1 will lead to full-fledged (1-3) loops and AGI, so it’s hard for me to clearly picture that scenario and engage with its consequences.
I don't think AI taste should play a role in AI help solving the value alignment problem. If we had any sense (which sometimes we do once problems are right in our faces), we'd be asking the AI "so what happens if we use this alignment approach/goal?" and then using our own taste, not asking it things like "tell us what to do with our future". We could certainly ask for input and there are ways that could go wrong. But I mostly hope for AGI help in the technical part of solving stable value alignment.
Hmm. But the AI has a ton of wiggle room to make things seem good or bad depending on how things are presented and framed, right? (This old Stuart Armstrong post [LW · GW] is a bit relevant.) If I ask “what will happen if we do X”, the AI can answer in a way that puts things in a positive light, or a negative light. If the good understanding lives in the AI and the good taste lives in the human, then it seems to me that nobody is at the wheel. The AI taste is determining what gets communicated to the human and how, right? What’s relevant vs irrelevant? What analogies are getting at what deeply matters versus what analogies are superficial? All these questions are value-laden, but they are prerequisites to the AI communicating its understanding to the human. Remember, the AI is doing the (1-3) thing to autonomously develop a new idiosyncratic superhuman understanding of AI and philosophy and society and so on, by assumption. Thus, AI-human communication is much harder and different than we’re used to today, and presumably requires its own planning and intention on the part of the AI.
…Unless you’re actually in the §5.1.1 camp where the AI is helping clarify and brainstorm but is working shoulder-to-(virtual) shoulder, and the human basically knows everything the AI knows. I.e., like how people use foundation models today. If so, that’s fine, no complaints. I’m happy for people to use foundation models in a similar way that they do today, as they work on the big problem of how to make future more powerful AIs that run on something closer to ambitious value learning or CEV as opposed to corrigibility / obedience.
Sorry if I’m misunderstanding or being stupid, this is an area where I feel some uncertainty. :)
comment by RobertM (T3t) · 2025-02-13T20:06:10.117Z · LW(p) · GW(p)
Curated. This post does at least two things I find very valuable:
- Accurately represents differing perspectives on a contentious topic
- Makes clear, epistemically legible [LW · GW] arguments on a confusing topic
And so I think that this post both describes and advances the canonical "state of the argument" with respect to the Sharp Left Turn (and similar concerns). I hope that other people will also find it helpful in improving their understanding of e.g. objections to basic evolutionary analogies (and why those objections shouldn't make you very optimistic).
comment by Noosphere89 (sharmake-farah) · 2025-02-02T18:20:06.085Z · LW(p) · GW(p)
My second concern is that “AIs solving specific technical problems that the human wants them to solve” is insufficient to avoid extinction and get to a good future—even if the AI is solving those problems at superhuman level and with the help of (1-3) superpowers.[3]
I won’t go much into details of why I have this concern, since I want to keep this post focused on technical alignment. But I’ll spend just a few paragraphs to give a hint. For more, see my What does it take to defend the world against out-of-control AGIs? and John Wentworth’s The Case Against AI Control.
Here’s an illustrative example. People right now are researching dangerous viruses, in a way that poses a risk of catastrophic lab leaks wildly out of proportion to any benefits. Why is that happening? Not because everyone is trying to stop it, but they lack the technical competence to execute. Quite the contrary! Powerful institutions like governments are not only allowing it, but are often funding it!
I think when people imagine future AI helping with this specific problem, they’re usually imagining the AI convincing people—say, government officials, or perhaps the researchers themselves—that this activity is unwise. See the problem? If AI is convincing people of things, well, powerful AIs will be able to convince people of bad and false things as well as good and true things. So if the AI is exercising its own best judgment in what to convince people of, then we’d better hope that the AI has good judgment! And it’s evidently not deriving that good judgment from human preferences. Human preferences are what got us into this mess! Right?
Remember, the “alignment generalizes farther” argument (§4 above) says that we shouldn’t worry because AI understands human preferences, and those preferences will guide its actions (via RLHF or whatever). But if we want an AI that questions human preferences rather than slavishly following them, then that argument would not be applicable! So how are we hoping to ground the AI’s motivations? It has to be something more like “ambitious value learning” or Coherent Extrapolated Volition—things that are philosophically fraught, and rather different from what people today are doing with foundation models.
I agree with the claim that existential catastrophes aren't automatically solved by aligned/controlled AI, and in particular biological issues remain a threat to human survival.
My general view on how AI helps in practice is more likely to route around first figuring out ways to solve the biology threat from a technical perspective, and then using instruction following AIs to implement a campaign of persuasion that uses the most effective way to change people's minds.
You are correct that an AI can convince people of true things as well as false things, and this is why you will need to make assumptions about the AI's corrigibility/instruction following, though you helpfully make such assumptions here.
On the first person problem, I believe that the general solution to this involves recapitulating human social instincts via lots of data on human values, and I'm perhaps more optimistic than you that a lot of the social instincts in humans don't have to be innately specified by a prior.
In many ways, I have a weird reaction to the post, because I centrally agree with the claim that corrigible/instruction following AIs aren't automatically sufficient to ensure safety, and yet I am much more optimistic than you do that mere corrigibility/instruction following is a huge way for AI to be safe, probably because I think you can actually do a lot more work to secure civilization in ways that semi-respect existing norms, but semi-respect is key here.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-02-03T15:52:20.858Z · LW(p) · GW(p)
I agree with the claim that existential catastrophes aren't automatically solved by aligned/controlled AI …
See also my comment here [LW(p) · GW(p)], about the alleged “Law of Conservation of Wisdom”. Your idea of “using instruction following AIs to implement a campaign of persuasion” relies (I claim) on the assumption that the people using the instruction-following AIs to persuade others are especially wise and foresighted people, and are thus using their AI powers to spread those habits of wisdom and foresight.
It’s fine to talk about that scenario, and I hope it comes to pass! But in addition to the question of what those wise people should do, if they exist, we should also be concerned about the possibility that the people with instruction-following AIs will not be spreading wisdom and foresight in the first place.
[Above paragraphs are assuming for the sake of argument that we can solve the technical alignment problem to get powerful instruction-following AI.]
On the first person problem, I believe that the general solution to this involves recapitulating human social instincts via lots of data on human values…
Yeah I have not forgotten about your related comment from 4 months ago [LW(p) · GW(p)], I’ve been working on replying to it, and now it’s looking like it will be a whole post, hopefully forthcoming! :)
Replies from: Satron↑ comment by Satron · 2025-02-03T19:08:37.933Z · LW(p) · GW(p)
Your idea of “using instruction following AIs to implement a campaign of persuasion” relies (I claim) on the assumption that the people using the instruction-following AIs to persuade others are especially wise and foresighted people, and are thus using their AI powers to spread those habits of wisdom and foresight.
It’s fine to talk about that scenario, and I hope it comes to pass! But in addition to the question of what those wise people should do, if they exist, we should also be concerned about the possibility that the people with instruction-following AIs will not be spreading wisdom and foresight in the first place.
I don't think that whoever is using these AI powers (let's call him Alex) needs to be that wise (beyond the wiseness of an average person who could get their hands on a powerful AI, which is probably higher-than-average).
Alex doesn't need to come up with @Noosphere89 [LW · GW]'s proposed solution of persuasion campaigns all by himself. Alex merely needs to ask his AI what are the best solutions for preventing existential risks. If Noosphere's proposal is indeed wise, then AI would suggest it. Alex could then implement this solution.
Alex doesn't necessarily need to want to spread wisdom and foresight in this scheme. He merely needs to want to prevent existential risks.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-02-03T21:46:58.481Z · LW(p) · GW(p)
I don’t think the average person would be asking AI what are the best solutions for preventing existential risks. As evidence, just look around:
There are already people with lots of money and smart human research assistants. How many of those people are asking those smart human research assistants for solutions to prevent existential risks? Approximately zero.
Here’s another: The USA NSF and NIH are funding many of the best scientists in the world. Are they asking those scientists for solutions to prevent existential risk? Nope.
Demis Hassabis is the boss of a bunch of world-leading AI experts, with an ability to ask them to do almost arbitrary science projects. Is he asking them to do science projects that reduce existential risk? Well, there’s a DeepMind AI alignment group, which is great, but other than that, basically no. Instead he’s asking his employees to cure diseases (cf Isomorphic Labs), and to optimize chips, and do cool demos, and most of all to make lots of money for Alphabet.
You think Sam Altman would tell his future powerful AIs to spend their cycles solving x-risk instead of making money or curing cancer? If so, how do you explain everything that he’s been saying and doing for the past few years? How about Mark Zuckerberg and Yann LeCun? How about random mid-level employees in OpenAI? I am skeptical.
Also, even if the person asked the AI that question, then the AI would (we’re presuming) respond: “preventing existential risks is very hard and fraught, but hey, what if I do a global mass persuasion campaign…”. And then I expect the person would reply “wtf no, don’t you dare, I’ve seen what happens in sci-fi movies when people say yes to those kinds of proposals.” And then the AI would say “Well I could try something much more low-key and norm-following but it probably won’t work”, and the person would say “Yeah do that, we’ll hope for the best.” (More such examples in §1 here [LW · GW].)
Replies from: Satron↑ comment by Satron · 2025-02-04T00:00:31.162Z · LW(p) · GW(p)
I am not from the US, so I don't know anything about the organizations that you have listed. However, we can look at three main conventional sources of existential risk (excluding AI safety, for now, we will come back to it later):
- Nuclear Warfare - Cooperation strategies + decision theory are active academic fields.
- Climate Change - This is a very hot topic right now, and a lot of research is being put into it.
- Pandemics - There was quite a bit of research before COVID, but even more now.
As to your point about Hassabis not doing other projects for reducing existential risk besides AI alignment:
Most of the people on this website (at least, that's my impression) have rather short timelines. This means that work on a lot of existential risks becomes much less critical. For example, while supervolcanoes are scary, they are unlikely to wipe us out before we get an AI powerful enough to be able to solve this problem more efficiently than we can.
As to your point about Sam Altman choosing to cure cancer over reducing x-risk:
I don't think Sam looks forward to the prospect of dying due to some x-risk, does he? After all, he is just as human as we are, and he, too, would hate the metaphorical eruption of a supervolcano. But that's going to become much more critical after we have an aligned and powerful AI on our hands. This also applies to LeCun/Zuckerberg/random OpenAI researchers. They (or at least most of them) seem to be enjoying their lives and wouldn't want to randomly lose them.
As to your last paragraph:
I think your formulation of AI response ("preventing existential risks is very hard and fraught, but hey, what if I do a global mass persuasion campaign") really undersells it. It almost makes it sound like a mass persuasion campaign is a placebo to make AI's owner feel good.
Consider another response "the best option for preventing existential risks, would be doing a mass persuasion campaign of such and such content, that would have such and such effects, and would prevent such and such risks".
My (naive) reaction (assuming that I think that AI is properly aligned and is not hallucinating) would be to ask more questions about the details of this proposal and, if its answers make sense, to proceed with doing it. Is it that crazy? I think doing a persuasion campaign is in itself not necessarily bad (we deal with them every day in all sorts of contexts, ranging from your relatives convincing you to take a day off to people online making you change your mind on some topic to politicians running election campaigns), and is especially not bad when it is the best option for preventing x-risk.
In the scenario that you described, I am not sure at all that an average person, who would be able to get their hands on AI (this is an important point, because I believe these people to be generally smarter/more creative/more resourceful) would opt for a second option, especially after being told: "Well I could try something much more low-key and norm-following, but it probably won't work".
Option 1: Good odds of preventing x-risk, but apparently also doesn't work in movies.
Option 2: Bad odds of preventing x-risk.
Perhaps, the crux is that I think that people who actually have good chances of controlling powerful AI (Sam Altman, Dario Amodei etc) would see that option #1 is obviously better if they themselves want to survive (something that is instrumental to whatever other goals they have like curing cancer).
Furthermore, there is a more sophisticated solution to this problem. I can ask this powerful AI to find the best representations of human preferences and then find the best way to align itself to it. Then, this AI would no longer be constrained by my cognitive limitations.
An average person probably wouldn't come up with it by themselves, but they don't need to. Presumably, if this is indeed a good solution, it would be suggested at the first stage where I ask AI to find best solutions for preventing existential risk. Would an average person take this option? I expect our intuitions to diverge here much strongly than in the previous case. Looking at myself, I was an average person just a few month ago. I have no expertise in AI whatsoever. I don't consider myself to be among the smartest humans on Earth. I haven't read much literature on AI safety. I was basically an exemplary "normie".
And yet, when I read about the idea of an instruction-following AI, I almost immediately came up with this solution of making an AI aligned with human preferences using the aforementioned instruction-following AI. It sidesteps a lot of misuse concerns, which (at the time) seemed scary.
I grant that an average person might not come up with this solution by themselves, but presumably (if this solution is any good), it would be suggested by AI itself when we ask it to come up with solutions for x-risk.
An average person could ask this AI how to ensure that this endeavor won't end up in a scenario like the one in the movie. Then it can cross-check its answer with a security team which has successfully aligned it.
My conclusion is basically that I would expect a good chunk of average people to opt for a sophisticated solution after AI suggesting it, an ever bigger chunk of average people to opt for a naive solution, and an even bigger chunk of people, who would most likely control powerful AI in the future (generally smarter than an average person), to opt for either solution.
comment by Jonas Hallgren · 2025-01-28T22:26:00.882Z · LW(p) · GW(p)
Epistemic status: Curious.
TL;DR:
The Sharp Left Turn and specifically the alignment generalization ability is highly dependent on how much slack you allow between each optimisation epoch. By minimizing the slack you allow in the "utility boundary" (the part of the local landscape that is counted as part of you when trying to describe a utility function of the system) you can minmize the expected divergence of the optimization process and therefore minimize the alignment-capability gap?
A bit longer from the better half of me (Claude):
Your analysis of the sharp left turn made me reflect on an interesting angle regarding optimization processes and coordination. I'd like to share a framework that builds on but extends beyond your discussion of the (1-3) triad and capabilities generalization:
I believe we can understand sharp left turns through the lens of 'optimization slack' - the degree of freedom an optimization process has between correction points. Consider:
- Modern ML systems use gradient descent with tight feedback loops and minimal slack
- Evolution operated with enormous slack between meaningful corrections
- Cultural evolution introduced intermediate coordination mechanisms through shared values
This connects to your discussion of autonomous learning and discernment, but examines it through a different lens. When you describe how 'capabilities generalize further than alignment,' I wonder if the key variable isn't just the generalization itself, but how much slack we permit in the system before correction.
A concrete model I've been working with looks at this as boundaries in optimization space [see figure below].
Here's some pictures from a comment that I left on one of the posts [LW · GW]:
Which can be perceived as something like this in the environmental sense:
The hypothesis is that by carefully constraining the 'utility boundary' - the region within which a system can optimize while still being considered aligned - we might better control divergence.
I'm curious whether you see this framework as complementary to or in tension with your analysis of the (1-3) triad. Does thinking about alignment in terms of permitted optimization slack add useful nuance to the capabilities vs alignment generalization debate?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-29T14:53:30.035Z · LW(p) · GW(p)
I don’t understand your comment but it seems vaguely related to what I said in §5.1.1.
Yeah, if we make the (dubious) assumption that all AIs at all times will have basically the same ontologies, same powers, and same ways of thinking about things, as their human supervisors, every step of the way, with continuous re-alignment, then IMO that would definitely eliminate sharp-left-turn-type problems, at least the way that I define and understand such problems right now.
Of course, there can still be other (non-sharp-left-turn) problems, like maybe the technical alignment approach doesn’t work for unrelated reasons (e.g. 1 [LW · GW],2 [LW · GW]), or maybe we die from coordination problems (e.g. [LW · GW]), etc.
Modern ML systems use gradient descent with tight feedback loops and minimal slack
I’m confused; I don’t know what you mean by this. Let’s be concrete. Would you describe GPT-o1 as “using gradient descent with tight feedback loops and minimal slack”? What about AlphaZero? What precisely would control the “feedback loop” and “slack” in those two cases?
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2025-01-29T18:49:17.024Z · LW(p) · GW(p)
Thank you for being patient with me, I tend to live in my own head a bit with these things :/ Let me know if this explanation is clearer using the examples you gave:
Let me build on the discussion about optimization slack and sharp left turns by exploring a concrete example that illustrates the key dynamics at play.
Think about the difference between TD-learning and Monte Carlo methods in reinforcement learning. In TD-learning, we update our value estimates frequently based on small temporal differences between successive states. The "slack" - how far we let the system explore/optimize between validation checks - is quite tight. In contrast, Monte Carlo methods wait until the end of an episode to make updates, allowing much more slack in the intermediate steps.
This difference provides insight into the sharp left turn problem. When we allow more slack between optimization steps (like in Monte Carlo methods), the system has more freedom to drift from its original utility function before course correction. The divergence compounds particularly when we have nested optimization processes - imagine a base model with significant slack that then has additional optimization layers built on top, each with their own slack. The total divergence potential multiplies.
This connects directly to your point about GPT-style models versus AlphaZero. While the gradient descent itself may have tight feedback loops, the higher-level optimization occurring through prompt engineering or fine-tuning introduces additional slack. It's similar to how cultural evolution, with its long periods between meaningful corrections, allowed for the emergence of inner optimizers that could significantly diverge from the original selection pressures.
I'm still working to formalize precisely what mathematical structure best captures this notion of slack - whether it's best understood through the lens of utility boundaries, free energy, or some other framework.
comment by Steven Byrnes (steve2152) · 2025-01-30T18:35:02.771Z · LW(p) · GW(p)
Re-reading this a couple days later, I think my §5.1 discussion didn’t quite capture the LLM-scales-to-AGI optimist position. I think there are actually 2½ major versions, and I only directly talked about one in the post. Let me try again:
- Optimist type 1: They make the §5.1.1 argument, imagining that humans will remain in the loop, in a way that’s not substantially different from the present.
- My pessimistic response: see §5.1.1 in the post.
- Optimist type 2: They make the §5.1.3 argument that our methods are better than Ev’s, because we’re engineering the AI’s explicit desires in a more direct way. And the explicit desire is corrigibility / obedience. And then they also make the §5.1.2 argument that “AIs solving specific technical problems that the human wants them to solve” will not undermine those explicit motivations, despite the (1-3) loop running freely with minimal supervision, because the (1-3) loop will work in vaguely intuitive and predictable ways on the object-level technical question.
- My pessimistic response has three parts: First, the idea that a full-fledged (1-3) loop will not undermine corrigibility / obedience is as yet untested and at least open to question (as I wrote in §5.1.2). Second, my expectation is that some training and/or algorithm change will happen between now and “AIs that really have the full (1-3) triad”, and that change may well make it less true that we are directly engineering the AI’s explicit desires in the first place—for example, see o1 is a bad idea [LW · GW]. Third, what are the “specific technical problems that the human wants the AI to solve”??
- …Optimist type 2A answers that last question by saying the “specific technical problems that the human wants the AI to solve” is just, whatever random things that people want to happen in the world economy.
- My pessimistic response: See discussion in §5.1.2 plus What does it take to defend the world against out-of-control AGIs? [LW · GW] Also, competitive dynamics / race-to-the-bottom is working against us, in that AIs with less intrinsic motivation to be obedient / corrigible will wind up making more money and controlling more resources.
- …Optimist type 2B instead answers that last question by saying that the “specific technical problems that the human wants the AI to solve” is alignment research, or more specifically, “figuring out how to make AIs whose motivation is more like CEV or ambitious value learning rather than obedience”.
- My pessimistic response: The discussion in §5.1.2 becomes relevant in a different way—I think there’s a chicken-and-egg problem where obeying humans does not yield enough philosophical / ethical taste to judge the quality of a proposal for “AI that has philosophical / ethical taste”. (Semi-related: The Case Against AI Control Research [LW · GW].)
comment by HoVY · 2025-02-14T18:33:55.029Z · LW(p) · GW(p)
To chime in with a stronger example the cynical audience member from 1.4 could've used: religion. Religions are constantly morphing and evolving, and they've ranged in practices from live sacrifice (human and non-human) to sweeping while walking to avoid potentially hurting a bug. That sorta falls under moral philosophy but I think all the other, non-moral, aspects of religion make the point more strongly. There's no way to determine that religion X is true and Y is false, there's no grounding in reality, and given that the strongest predictor of an individuals religion is which one they were born into, their discernment doesn't seem to be pulling much weight.
Now, you could say religion is a useful idea in terms of social cohesion, but I think that if ai convinces us of happy lies that's not a great outcome (better than many possible ones though)
comment by PoignardAzur · 2025-02-27T14:02:47.823Z · LW(p) · GW(p)
Likewise, Ev put in some innate drives related to novelty and aesthetics, with the idea that people would wind up exploring their local environment. Very sensible! But Ev would probably be surprised that her design is now leading to people “exploring” open-world video game environments while cooped up inside.
I think it's not obvious that Ev's design is failing to work as intended here.
Video games are a form of training. Some games can get pretty wireheady (Cookie Clicker), but many of the most popular, most discussed, most played games are games that exercise some parts of your brain in useful ways. The best-selling game of all times is Minecraft.
Moreover, I wouldn't be surprised if people who played Breath of the Wild were statistically more likely to go hiking afterward.
comment by Lightbringer (ARCastro) · 2025-02-13T21:08:05.622Z · LW(p) · GW(p)
Nice work Steven, I will try to keep it short; your discussion highlights critical aspects of autonomous learning and AI generalization, but I think it overlooks a foundational issue: Neither AI nor humans truly self-train without an external base of validation grounded in reality itself.
1. The Myth of Self-Training AI
AI today cannot be considered self-training in any meaningful sense because its validation sources are fundamentally either human-labeled data or heuristics derived from previous outputs. There is no external, reality-anchored feedback loop beyond what humans provide. The claim that AI autonomously generalizes is misleading because it does not—and cannot—validate its knowledge against anything more fundamental than opinionated datasets and predefined optimization metrics.
2. The Illusion of Human Self-Training
Even humans do not “self-train” in an absolute sense. Mathematicians locked in a room for a month may discover new proofs, but they are not generating truth from nothing. Instead, they run iterative models against an existing logical structure—one that, while internally consistent, is ultimately an abstraction attempting to approximate reality rather than an intrinsic truth of reality itself.
Mathematics is not reality; it is a language we use to describe it. And while it has been highly successful in modeling physical structures, it is not a self-existent base against which intelligence can validate itself.
3. The AGI Problem: No Ground Truth, No Validation
This is the core issue for AGI:
Unlike biological evolution, which is validated by survival constraints in the real world, AGI is not trained against a fundamental reality but rather against synthetic benchmarks and human judgment.
There is no direct mechanism for AGI to verify whether its learned models align with the actual causal structures of existence.
Without such a mechanism, AGI is fundamentally locked into a self-referential learning loop—an optimizer of human misconceptions rather than an independent system capable of discovering universal truths.
4. Why This Matters for the Sharp Left Turn
The Sharp Left Turn hypothesis assumes that AGI, upon achieving generalization, will rapidly outpace human oversight, developing novel insights beyond what humans can predict or control. But the real question isn’t whether AGI will generalize, but what it is generalizing against.
If AGI generalizes only within the scope of human-designed benchmarks, then its “sharp left turn” is merely an acceleration of our own incomplete, often flawed abstractions—not an emergence of true intelligence. True intelligence must be grounded in a base that is independent of opinion and self-referential reinforcement.
5. A Solution: A Base Truth Beyond Opinion
For AGI to meaningfully generalize in a way that is not just recursive optimization, it must:
1. Anchor its validation mechanisms in a base truth beyond human biases and synthetic benchmarks.
2. Avoid self-referential learning loops that reinforce initial assumptions rather than discovering new structures.
3. Recognize the limits of its own models and adapt based on direct interaction with fundamental reality.
6. Conclusion: The Real AGI Challenge
AI and humans alike do not "self-train"; they validate models against an external base.
The difference is in the degree of abstraction—humans refine models through indirect inference, while AI is currently trapped within its training data.
If AGI is to become truly intelligent, it must be connected to a universal causal framework that prevents it from becoming a high-speed optimizer of human misconceptions.
The Sharp Left Turn is not an inevitability; it is a function of how intelligence is structured and what it validates against. If AGI is built on opinionated, incomplete human knowledge, then its intelligence will remain constrained by those same limitations—accelerated but not transcendent.
To create truly autonomous intelligence, the problem is not just alignment; it is ensuring that AGI learns from reality itself, rather than recursively iterating over synthetic, self-referential abstractions.
Humans do learn from reality itself, but they are constrained by analogous and symbolic means of comprehending and conveying any learned concept.
comment by jabowery · 2025-02-05T15:16:25.956Z · LW(p) · GW(p)
IS resides in Algorithmic Information Theory
OUGHT resides in Sequential Decision Theory
SDT(AIT ) = AIXI
And don't get confused about AIXI being "just" a theory of AGI. Any system that makes decisions (what OUGHT I to do?) depends on learning (what IS the case?).
Moreover, Hume's Guillotine has been the foundation of ethics for centuries, whether that is recognized or not.
The fact that the field of AGI ethics introduces the concept of "sharp left turn" without regard to either the founding theory of AGI, or the founding theory of ethics is quite a sight to behold!
See Hume's Guillotine at github for a further exposition.