There is an argument that although humans evolved under pressure to maximize inclusive genetic fitness (IGF), humans don't actually try to maximize their own IGF. This, as the argument goes, shows that in the one case we have of a process creating general intelligence, it was not the case that the optimization target of the created intelligence ended up being the same as the optimization target of the process that created it. Therefore, alignment doesn't happen by default. To quote from A central AI alignment problem: capabilities generalization, and the sharp left turn [LW · GW]:
And in the same stroke that [an AI's] capabilities leap forward, its alignment properties are revealed to be shallow, and to fail to generalize. The central analogy here is that optimizing apes for inclusive genetic fitness (IGF) doesn't make the resulting humans optimize mentally for IGF. Like, sure, the apes are eating because they have a hunger instinct and having sex because it feels good—but it's not like they could be eating/fornicating due to explicit reasoning about how those activities lead to more IGF. They can't yet perform the sort of abstract reasoning that would correctly justify those actions in terms of IGF. And then, when they start to generalize well in the way of humans, they predictably don't suddenly start eating/fornicating because of abstract reasoning about IGF, even though they now could. Instead, they invent condoms, and fight you if you try to remove their enjoyment of good food (telling them to just calculate IGF manually). The alignment properties you lauded before the capabilities started to generalize, predictably fail to generalize with the capabilities.
Jacob published Evolution Solved Alignment (what sharp left turn?) [LW · GW], arguing that actually humans represent a great alignment success. Evolution was trying to make things that make many copies of themselves, and humans are enormously successful on that metric. To quote Jacob:
For the evolution of human intelligence, the optimizer is just evolution: biological natural selection. The utility function is something like fitness: ex gene replication count (of the human defining genes)[1] [LW · GW]. And by any reasonable measure, it is obvious that humans are enormously successful. If we normalize so that a utility score of 1 represents a mild success - the expectation of a typical draw of a great apes species, then humans' score is >4 OOM larger, completely off the charts.[2] [LW · GW]
I pushed back, saying:
The failure of alignment is witnessed by the fact that humans very very obviously fail to maximize the relative frequency of their genes in the next generation, given the opportunities available to them; and they are often aware of this; and they often choose to do so anyway.
We got into a messy discussion. Now we're having a dialogue here. My hope is that others can comment and clarify relevant points, and that maybe someone who isn't me will take over from me in the discussion (message me / comment if interested).
TekhneMakre
I'll try to summarize the state of the debate from my perspective.
There are two kinds of processes.
The first is what I'll call General Evolution. General Evolution is the process where patterns of any kind that become more common over time will come to dominate. Since some patterns and aggregates of patterns can make themselves more common; for example, an organism that reproduces itself, a gene that gets copied, a virulent meme. Those patterns can "team up", e.g. genes in an organism or memes in a memeplex, and they can be tweaked so that they are better at making themselves more common. So what we see around us is patterns and aggregates of patterns that are really good at making themselves more common. If we think of General Evolution as having a utility function, its utility function is something along the lines of: There should be things that make many copies of themselves.
The second kind of process is what I'll call a Lineage Evolution. For every species S alive today, there's a Lineage Evolution called "S-evolution" that goes from the first life form, up the phylogenetic tree of life along the branch that S is on, through each of S's ancestor species, up to S itself.
There are also two meanings of "humans". "Humans" could mean individual humans, or it could mean humanity as a whole.
I read the original argument as saying: Human-evolution (an instance of a Lineage Evolution) selected for IGF of organisms. That is, at every step of the way, Human-evolution promoted genes that created humans (or human-ancestor-species organisms) that were good at making the genes in that organism be more common in the next generation. Today, most individual-humans do not do anything like explicitly, monomaniacally trying to promote their own genes. Thus, an instance of misalignment.
I think, though I'm very far from sure, that Jacob actually mostly agrees with this. I think Jacob wants to say that
1. Humanity is the proper subject of the question of misalignment; 2. General Evolution is the proper subject; 3. Humanity is pretty aligned with General Evolution, because there are many humans, and General Evolution wants there to be patterns that make many of themselves.
My current main reply is:
General Evolution is not the proper subject, because the vast majority of the optimization power going into designing humans is Human-evolution.
TekhneMakre
I think it might help me if you wrote a few sentences that lay out your top level case, reformulated given the context we have so far. Sentences like
"For the (mis)alignment metaphor, the relevant level is humanity, not individual humans."
and similar.
TekhneMakre
The failure of alignment is witnessed by the fact that humans very very obviously fail to maximize the relative frequency of their genes in the next generation, given the opportunities available to them
This is irrelevant - individual failure "to maximize the relative frequency of their genes in the next generation" is the expected outcome at the individual level for most species. In many species, only a tiny fraction of individuals reproduce at all. For humans it's over 50% for women, but perhaps under 50% for men.
Evolution proceeds through random variation and selection - many experiments in parallel, only some of which will be successful - by design. The failures are necessary for progress.
Over time evolution optimizes simply for fitness - the quantity/measure of genetic patterns, defined over some set of genetic patterns. If you try to measure that for an individual, you get IGF - because the gene pattern of that individual will necessarily overlap with other individuals (strongly with closely related kin, overlap fading out with distance, etc). Likewise you can measure fitness for ever larger populations up to the species level.
Given two optimization processes with distinct utility functions, you could perhaps measure the degree of alignment as the dot product of the two functions over the world state (or expectation thereof for future world trajectory distributions).
But we can't directly measure the alignment between evolution as an optimizer and brains as an optimizer - even if we have some idea of how to explicitly define evolution's optimization target (fitness), the brain's optimization target is some complex individually varying proxy of fitness - far more complex than any simple function. Moreover, degree of alignment is not really the interesting concept by itself, unless normalized to some relevant scale (to set the threshold for success/failure).
But given that we know one of the utility functions (evolution: fitness), we can approximately measure the total impact. The world today is largely the result of optimization by human brains - ie it is the end result of optimization towards the proxy utility function, not the real utility function. Thus there is only a singular useful threshold for misalignment: is the world today (or recent history) high, low, or zero utility according to the utility function of human fitness?
And the answer is obviously high utility. Thus any misalignment was small in net impact, period.
If E(W) is evolutionary utility and B(W) is brain utility, we have:
W[T] = opt(W[0], B(W))
E(W[T]) = large
(The world was optimized according to brains (proxy utility), not genetic fitness utility, but the current world is enormously high scoring according to genetic fitness utility, which thereby bounds any misalignment).
TechneMarke argues that most of the evolutionary pressure producing brains was at the intra-species level, but this is irrelevant to my argument, unless TechneMarke actually believes and can show that this leads to a different correct utility function for evolution (other than fitness) and that humans are low scoring according to that function.
As an analogy: corporations largely optimize for profit, and the secondary fact that most innovation in large corps stems from intra-corporate competition is irrelevant to the primary fact that corporations largely optimize for profit.
jacob_cannell
So to summarize, there are several possible levels of evolution<->brain alignment:
species: alignment of brains (in aggregate) and species level fitness
individual: alignment of individual brains and individual IGF
We both seem to agree that individual alignment is high variance - some individuals are strongly aligned to IGF, others not at all. I hope we agree that at the species level, humanity has been well aligned to fitness so far - as demonstrated by our enormous anomalously high fitness score (probably the most rapid rise in fitness of any species ever).
So for a statement like:
The central analogy here is that optimizing apes for inclusive genetic fitness (IGF) doesn't make the resulting humans optimize mentally for IGF.
If you read 'humans' as individual humans, then the statement is true but uninteresting (as evolution doesn't and can't possibly make every individual high scoring). If you read humans as humanity, then evolution obviously (to me) succeeded at aligning humanity sufficiently, with a possible disagreement still around the details of what exactly (optimize mentally) means, which would lead to a side discussion about the computational limits of a 20W computer and how optimizing indirectly for a proxy is the optimal solution to produce a computer that can maximize IGF in expectation, rather than some simple max-utility consequentialist reasoner that doesn't scale and fails miserably.
jacob_cannell
a different correct utility function for evolution (other than fitness) and that humans are low scoring according to that function.
Hm. I think the framing here may have covered over our disagreement. I want to say: humans were constructed by a process that selected for IGF across many iterations. Now, humans are kinda optimizing for things, but they are definitely not optimizing for IGF.
I think you're saying something in the general category of: "Sure, but the concepts you're using here aren't joint-carving. If you look at the creation of humans by evolution, and then you think of with non-joint-carving concepts, then you'll see misalignment. But that's just misalignment between a non-joint-carving subset of the real designing process and a non-joint-carving subset of the thing that gets designed."
And I'm like... Ok, but the analogy still seems to hold?
Like, if I think of humans trying to make AI, I don't feel like I'm trying to talk about "the utility function of all the humans trying to make AI". I think I'm trying to talk about "the criteria that the humans trying to make AI, or the objective function used for gradient descent or RL, are concretely using day-to-day to pick what tweaks / ideas in their designs to keep around". So there's two analogies there, but both of the same form.
One of the analogies is like: humans go around coming up with ideas for AI; if their AI does something cool, they upvote that; if they can, they try to tweak the AI that does something cool so that it can be used to actually do something useful for humans; in the cases where the AI does something noticeably bad, the humans try to patch that. The humans probably think of themselves as implementing their own utility function through their actions, and more importantly, they might actually be doing so in a certain sense. If the humans could go on patching bad results and upvoting cool results and install using-for-good patches, then in the limit of that, the real human utility function would be expressed and fulfilled. But the analogy here is saying: These criteria the humans are using to design their AI, to make the tweaks that over the course of humanity's AI research will add up to really powerful AI, can make a really powerful AI without installing in the AI the limiting real human utility function. Similarly, given enough evolutionary time, evolution would install more strategic-IGF-optimization in humans; that may already be happening.
TekhneMakre
In other words, for the analogy to seem right and important to me, it doesn't feel very cruxy that it be a clear instance of utility function vs. utility function misalignment. What feels cruxy is a less precise sense of: this process designed an optimizer by selecting really hard for X, but then the optimizer ended up trying to do Y which is different from X.
Like, if I train an AI by the objective function of imitating humans, I expect that eventually, when it's getting really exceptionally good, it will become an optimizer that is optimizing powerfully for something other than imitating humans.
It's possible that a crux for us is related to how much to care about expected future outcomes. I think you said in some comments somewhere, something like, "yeah, maybe humans / humanity will be much more misaligned with evolution in the future, but that's speculation and circular reasoning, it hasn't happened yet". But I don't think it's circular: We can see clearly today that humans are optimizing for things, and say they are optimizing for things, and those things are not IGF, and so predictably later, when humans have the power, we will end up scoring very low on IGF; today the misalignment is fuzzier, and has to be judged against counterfactuals (how much IGF could a modern human be getting, if they were anything like IGF maximizers).
TekhneMakre
Now, humans are kinda optimizing for things, but they are definitely not optimizing for IGF.
We may still have disagreement on this - I would reiterate that at the individual level some humans are definitely optimizing strongly for IGF, up to the limits of a 20W physical computer (which rules out most objections based on gross misunderstanding of the physical limits of optimization power for 20W irreversible computers). I already brought up one specific example in our private discussion - namely individual humans going to great efforts to maximize successful sperm donation even when they are paid trivial amounts, or aren't paid at all and in some cases actually commit felonies with long prison sentences to do so (strongly antipaid). Also the way the brain mostly normally works is closer to something like mysteriously subconsciously compelling you to optimize for IGF - take Elon Musk as an example: he is on track to very high IGF score, but doesnt' seem to be explicitly consciously optimizing for that. Alignment in the brain is very complex and clearly not yet fully understood - but it is highly redundant with many levels of mechanisms in play.
So one point of potential confusion is I do believe that properly understanding and determining what "optimizing for IGF, up to the limits of a 20W physical computer" actually entails requires deep understanding of DL and neuroscience and leads to something like shard theory [LW · GW]. The kind of consequentialist optimizer Nate seems to imply fails miserably at 20W and is not remotely related to what a successful design (like the brain) looks like - it is always an ultra complex proxy optimizer, ala shard theory and related.
Perfect alignment is a myth, a fantasy - and clearly unnecessary for success! (that is much of the lesson of this analogy)
Like, if I think of humans trying to make AI, I don't feel like I'm trying to talk about "the utility function of all the humans trying to make AI". I think I'm trying to talk about "the criteria that the humans trying to make AI, or the objective function used for gradient descent or RL, are concretely using day-to-day to pick what tweaks / ideas in their designs to keep around".
I do believe that among the possible alignment analogies from evolution, there is a single best analogy: the systems level analogy.
Genetic evolutionary optimization producing brains is like technological evolutionary optimization producing AGI.
Both processes involve bilevel optimization: an outer genetic (or memetic) evolutionary optimization process and an inner ANN optimization process. Practical AGI is necessarily very brain like (which I predicted [? · GW] correctly many years in advance, contra EY/MIRI). DL is closely converging on brain like designs, in all respects that matter.
The outer evolutionary optimization process is similar, but with some key differences. The genome specifies the initial architectural prior (compact low bit and low frequency encoding over the weights) along with an efficient approx bayesian learning algorithm to update those weights. Likewise AI systems are specified by a small compact code (pytorch, tensorflow etc) which specifies the initial architectural prior along with an efficient approx bayesian learning algo to update those weights (SGD). The main difference is that for tech evolution the units of encoding - the tech memes - recombine far more flexibly than genes. Each new experiment can combine memes flexibly from a large number of previous papers/experiments, a process guided by human intelligence (inner optimization). The main effect is simply a massive speedup - similar but more extreme than advanced genetic engineering.
I think this really is the singularly most informative analogy. And from that analogy I think we can say this:
To the extent that the tech evolution of AGI is similar to the genetic evolution of human intelligence (brains), genetic evolution's great success at aligning humanity so far (in aggregate, not individually) implies a similar level of success for tech evolution aligning AGI (in aggregate, not individually) to similar non-trivial levels of optimization power divergence.
If you think that the first AGI crossing some capability threshold is likely to suddenly takeover the world, then the species level alignment analogy breaks down and doom is more likely. It would be like a single medieval era human suddenly taking over the world via powerful magic. Would the resulting world after optimization according to that single human's desires still score reasonably well at IGF? I'd say somewhere between 90% to 50% probability, but that's still clearly a high p(doom) scenario. I do think that scenario is unlikely for a variety of reasons (in short, the same factor that allows human engineers to select for successful meme changes enormously above chance also acts as a hidden great filter reducing failure variance in tech designs), but that's a long separate discussion I've already partly argued elsewhere.
So one key component underlying evolution's success at aligning humanity is the variance reducing effect of large populations, which maps directly to multipolar scenarios. A population will almost always be more aligned then worst case or even median individuals, and a population can be perfectly aligned even when nearly every single individual is near completely misaligned (orthogonal). Variance reduction is critical for most successful optimization algos (SGD and evolution included).
jacob_cannell
(At this point I'm going to make the dialogue publicly viewable, and we can continue as long as that seems good.)
TekhneMakre
TM: The failure of alignment is witnessed by the fact that humans very very obviously fail to maximize the relative frequency of their genes in the next generation, given the opportunities available to them
J: This is irrelevant - individual failure "to maximize the relative frequency of their genes in the next generation" is the expected outcome at the individual level for most species. In many species, only a tiny fraction of individuals reproduce at all.
It matters here what the "could" is. If an individual doesn't reproduce, could it have reproduced? Specifically, if it had merely been trying to reproduce, is it the case that it obviously would have reproduced more? This is hard to analyze with high confidence in a lot of cases, but the claim is that the answer for many humans is "yes, obviously".
TekhneMakre
I should maybe lay out more of the "humans are not trying to IGF" case.
1. Only rarely are males very interested in donating sperm. 2. Very many people have sex while deliberately avoiding ever getting pregnant, even though they totally could raise children. 3. I, and I imagine others, feel revulsion, not desire, at the idea of humanity ending up being made up of only copies of me. 4. I, and I imagine others, are actively hoping and plotting to end the regime where DNA copies are increased.
I think you've argued that the last 2 are weak or even circular. But that seems wrong to me, they seem like good evidence.
TekhneMakre
Humanity as a whole is also not trying to increase DNA copies.
Maybe an interesting point here is that you can't count as alignment successes *intermediate convergent instrumental* successes. Humans create technology for some reason; and technology is power; and because humanity is thereby more powerful, there are temporarily more DNA copies. To see what humans / humanity wants, you have to look at what humans / humanity does when not constrained by instrumental goals.
TekhneMakre
We both seem to agree that individual alignment is high variance - some individuals are strongly aligned to IGF, others not at all.
Very few. The super sperm donors mostly / probably count. Cline, the criminal doctor, mostly / probably counts. Women who decide to have like a dozen kids would (if they are not coerced into that) mostly / probably count. Genghis Khan seems like the best known candidate (and the revulsion here says something about what we really care about).
Elon Musk doesn't count. You're right that he, like prolific kings and such, are evidence of something about there being something in humans tracking number of offspring. But Elon is obviously not optimizing hard for that. How many sperm donations could he make if he actuallys tried?
TekhneMakre
I have updated significantly from this discussion. The update, though, isn't really away from my position or towards your position--well, it's towards part of your position. It's more like as follows:
Previously, I would have kind of vaguely agreed to descriptions of the evolution-humanity transition as being an example of "misalignment of humans with evolution's utility function". I looked back at my comments on your post, and I find that I didn't talk about evolution as having a utility function, except to negate your statement by saying "This is not evolution's utility function.". Instead, I'd say things like "evolution searches for..." or "evolution promotes...". However, I didn't object to others saying things about evolution having a utility function, and I definitely arguing that humans are misaligned with evolution.
Now, I think you're right that it kind of doesn't make sense to say humans are misaligned with evolution! But not for the same reasons as you. Instead, I now think it just doesn't make much sense to say that evolution (of any sort) has a utility function. That's not the sort of thing evolution is; it's not a strategic, general optimizer. (It has some generality, but it's limited, and it isn't strategic; it doesn't plan ahead when designing organisms (or, if you insist, species).)
TekhneMakre
Most of my previous comments, e.g. on your post, still stand, with the correction that I now wouldn't say that it's a misalignment. I don't know the word for what it is, but it's a different thing. It's that thing where you have a process that selects really strongly for X, and makes a thing that does science to the world and makes complex designs and plans and then achieves really difficult cool goals, AKA a strategic general optimizer; but the general optimizer doesn't optimize for X (any more than it has to, to be a good optimizer, because of convergence). Instead, the optimizer optimizes for Y, which looks like X / is a good proxy for X in the regime where the selection process was operating, but then outside that regime the optimizer, optimizing for Y, tramples over X.
What's the word for this? As you point out, it's not always misalignment, because the selection process does not have to have a utility function!
TekhneMakre
The upshot for the debate is that the original argument still holds, but in a better formulated form. Evolution to humanity isn't precisely misalignment, but it is this other thing. (Is this what the term "inner (mis)alignment" supposed to mean? Or does inner alignment assume that the outer thing is a utility function?)
And the claim is that this other thing will also happen with humans / humanity / a training process making AI. The selection criteria that humans / humanity / the training process use, do not have to be what the AI ends up optimizing. And the evolution-human transition is evidence of this.
TekhneMakre
It matters here what the "could" is. If an individual doesn't reproduce, could it have reproduced? Specifically, if it had merely been trying to reproduce, is it the case that it obviously would have reproduced more?
Evolution says: "Do. Or do not. There is no try." From the evolutionary perspective, and for the purposes of my argument, the specific reason for why an individual fails to reproduce is irrelevant. It doesn't matter if the individual fails to reproduce because they died too early or 'chose' not to (as far as evolution is concerned, these are just failures of different organs or subsystems).
Humans create technology for some reason; and technology is power; and because humanity is thereby more powerful, there are temporarily more DNA copies.
The word temporary assumes the doom conclusion and is thus circular reasoning for purposes of my argument. We update on historical evidence only, not our future predictions. Everything is temporary on long enough timescales.
Instead, I now think it just doesn't make much sense to say that evolution (of any sort) has a utility function.
Evolutionary optimization algorithms exist which are sims/models of genetic evolution and they do indeed actually optimize. The utility function is a design parameter which translates into a fitness function which typically determines each offspring's distribution of children, as a direct analog of the evolutionary fitness concept. Of course for real genetic evolution the equivalent individual reproductive fitness function is the result of a complex physics simulation, and the optimization target is the fitness of replicator units (genes/genesets) rather than somas. But it's still an optimizer in the general sense.
An optimization process in general is a computational system that expends physical energy to update a population sample distribution of replicators (programs) extropically. By 'extropically' I mean it updates the distribution in some anti-entropic direction (which necessarily requires physical computational energy to maintain and update away from the max entropy min energy ground state). That direction is the utility function of the optimizer. For genetic evolution that clearly seems to be fitness with respect to the current environment.
We could even measure the amount of optimization power applied towards fitness as direct evidence: imagine a detailed physical sim model which can predict the fitness of a genotype: f(G). Given that function, we could greatly compress the temporal sequence of all DNA streams of all cells that have ever existed. That compression is only possible because of replicator fitness; there is no compression for random nucleotide sequences. Furthermore, the set of all DNA in all cells at any given moment in time is also highly compressible, with the degree of compression a direct consequence of the cumulative fitness history.
So evolution is clearly an optimizer and clearly optimizing for replicator fitness. Human brain neural networks are also optimizers of sorts with a different implicit utility function - necessarily an efficient proxy of (inclusive) fitness (see shard theory).
We can not directly measure the misalignment between the two utility functions, but we can observe that optimization of the world for the last ~10,000 years mostly in the direction of human brain utility (technocultural evolution) enormously increased humanity's evolutionary fitness utility.
Thus it is simply a fact that the degree of misalignment was insignificant according to the only metric that matters: the outer optimizer's utility function (fitness).
jacob_cannell
It doesn't matter if the individual fails to reproduce because they died too early or 'chose' not to
It matters because it shows what the individual is trying to do, which is relevant to misalignment (or objective-misalignment, which is what I'll call "a process selecting for X and making a strategic general optimizer that doesn't optimize for X").
TekhneMakre
We update on historical evidence only, not our future predictions.
Our stated and felt intentions count as historical evidence about our intentions.
TekhneMakre
actually optimize
They optimize, yes. They pump the world into small regions of the space of possible worlds.
That direction is the utility function of the optimizer.
So what I'm saying here is that this isn't a utility function, in an important sense. It doesn't say which long-run futures are good or bad. It's not hooked up to a general, strategic optimizer. For example, an image generation model also doesn't have a utility function in this sense. Humanity arguably has such a utility function, though it's complicated.
Why care about this more specific sense of utility function? Because that's what we are trying to align an AI with. We humans have, NOT JUST instrumentally convergent abilities to optimize (like the ability gain energy), and NOT JUST a selection criterion that we apply to the AIs we're making, and NOT JUST large already-happening impacts on the world, BUT ALSO goals that are about the long-run future, like "live in a flourishing intergalactic civilization of people making art and understanding the world and each other". That's what we're trying to align AI with.
If you build a big search process, like a thing that searches for chip layouts that decrease latency or whatever, then that search process certainly optimizes. It constrains something to be in a very narrow, compactly describe set of outcomes: namely, it outputs a chip design with exceptionally low latency compared to most random chip designs. But I'm saying it doesn't have a utility function, in the narrow sense I'm describing. Let's call it an agent-utility function. It doesn't have an agent-utility function because it doesn't think about, care about, do anything about, or have any effect (besides chaos / physics / other effects routing through chaotic effects on humans using the chip layouts) on the rest of the world.
I claim:
1. Neither General Evolution nor any Lineage Evolution has an agent-utility function. 2. There's a relationship which I'll call selection-misalignment. The relationship is where there's a powerful selection process S that selects for X, and it creates a general strategic optimizer A (agent) that tries to achieve some goal Y which doesn't look like X. So A is selection-misaligned with S: it was selected for X, but it tries to achieve some other goal. 3. Humans and humanity are selection-misaligned with human-lineage-evolution.
4. It doesn't make much sense to be selection-misaligned or selection-aligned with General Evolution, because General Evolution is so weak. 5. To be values-misaligned is when an agent A1 makes another agent A2, and A2 goes off and tries to achieve some goal that tramples A1's goals.
6. It doesn't make much sense to be values-(mis)aligned with any sort of evolution, because evolution isn't an agent.
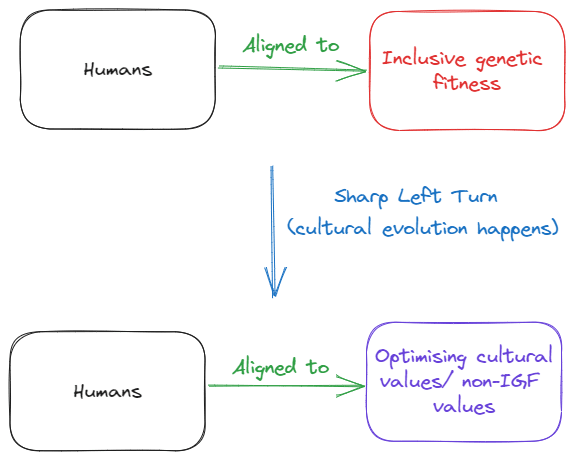
I've been following this discussion from Jan's first post, and I've been enjoying it. I've put together some pictures to explain what I see in this discussion.
Something like the original misalignment might be something like this:
This is fair as a first take, and if we want to look at it through a utility function optimisation lens, we might say something like this:
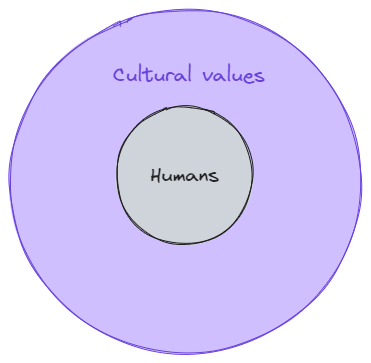
Where cultural values is the local environment that we're optimising for.
As Jacob mentions, humans are still very effective when it comes to general optimisation if we look directly at how well it matches evolution's utility function. This calls for a new model.
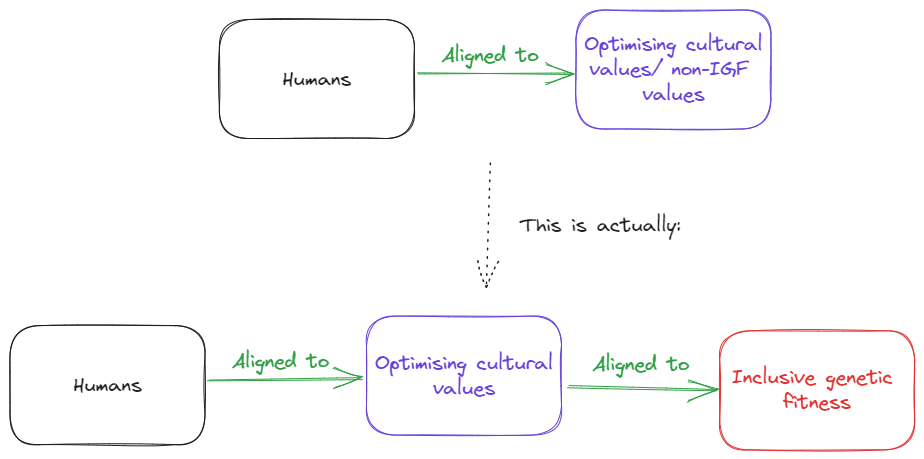
Here's what I think actually happens :
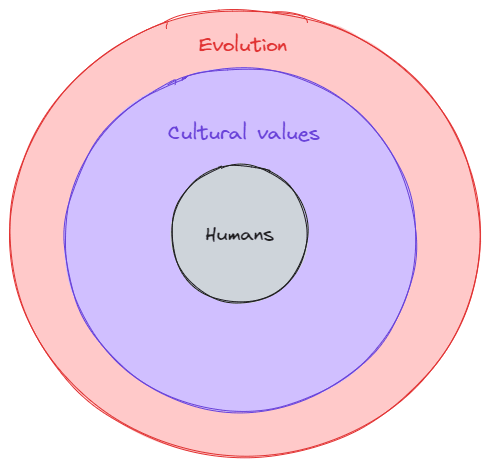
Which can be perceived as something like this in the environmental sense:
Based on this model, what is cultural (human) evolution telling us about misalignment?
We have adopted proxy values (Y1,Y2,..YN) or culture in order to optimise for X or IGF. In other words, the shard of cultural values developed as a more efficient optimisation target in the new environment where different tribes applied optimisation pressure on each other.
Also, I really enjoy the book The Secret Of Our Success when thinking about these models as it provides some very nice evidence about human evolution.
I agree with your general model of the proxy, but human brains are clearly more complex than just optimizing for cultural values. It's more like culture/memes is a new layer of replicators evolving in tandem with (but much faster) than genes. The genes may determine the architectural prior for the brain and reward functions etc, but the memes are the dataset which more determines the resulting mind. Our reward circuitry hasn't changed that much recently, so the proxy is mostly still pre-cultural, but cultural software has evolved on top to exploit/cooperate/control that circuitry.
Inclusive genetic fitness is a non-standard name for the latter view of biology as communicated by Yudkowsky - as a property of genes, not a property of humans.
The fact that bio-robots created by human genes don't internally want to maximize the genes' IGF should be a non-controversial point of view. The human genes successfully make a lot of copies of themselves without any need whatsoever to encode their own goal into the bio-robots.
I don't understand why anyone would talk about IGF as if genes ought to want for the bio-robots to care about IGF, that cannot possibly be the most optimal thing that genes should "want" to do (if I understand examples from Yudkowsky correctly, he doesn't believe that either, he uses this as an obvious example that there is nothing about optimization processes that would favor inner alignment) - genes "care" about genetic success, they don't care about what the bio-robots outght to believe at all 🤷
When I use IGF in the dialogue I'm doing so mostly because Nate's sharp left turn post which I quoted used 'IGF', but I understood it to mean inclusive fitness - ie something like "fitness of an individual's shared genotype".
obvious example that there is nothing about optimization processes that would favor inner alignment)
If this is his "obvious example", then it's just as obviously wrong. There is immense optimization pressure to align the organism's behavior with IGF, and indeed the theory of IGF was developed in part to explain various observed complex altruistic-ish behaviors.
As I argue in the dialogue, humanity is an excellent example of inner alignment success. There is a singular most correct mathematical measure of "alignment success" (fitness score of geneset - which is the species homo sapiens in this case), and homo sapiens undeniably are enormously successful according to that metric.
I agree with what you say. My only peeve is that the concept of IGF is presented as a fact from the science of biology, while it's used as a confused mess of 2 very different concepts.
Both talk about evolution, but inclusive finess is a model of how we used to think about evolution before we knew about genes. If we model biological evolution on the genetic level, we don't have any need for additional parameters on the individual organism level, natural selection and the other 3 forces in evolution explain the observed phenomena without a need to talk about invididuals on top of genetic explanations.
Thus the concept of IF is only a good metaphor when talking approximately about optimization processes, not when trying to go into details. I am saying that going with the metaphor too far will result in confusing discussions.
I think you're getting wrapped up in some extraneous details. Natural selection happens because when stuff keeps making itself, there tends to be more it, and evolution occurs as a result. We're going to keep evolving and there's gonna keep being natural selection no matter what. We don't have to worry about it. We can never be misaligned with it, it's just what's happening.
It would be like a single medieval era human suddenly taking over the world via powerful magic. Would the resulting world after optimization according to that single human's desires still score reasonably well at IGF?
Interestingly, this thought experiment was run many times at the time, see for example all the wish fulfillment fantasies in the 1001 Nights or things like the Sorcerers Apprentice.
I haven't read this, but expect it to be difficult to parse based on the comments on the other post-- maybe you should try an adversarial collaboration type post if this ever gets hashed out?
I am personally finding both interesting to read, even though it is hard to hold both sides in my head at once. I would encourage the participants to keep hashing it out insofar as you yourselves are finding it somewhat productive! Distillation can come later.
(I may have an ulterior motive here of being excited in general to see people try to hash out major disagreements using the dialogues format, I am cheering this on to succeed...)
I think you're right that it will take work to parse; it's definitely taking me work to parse! Possibly what you suggest would be good, but it sounds like work. I'll see what I think after the dialogue.
Question for Jacob: suppose we end up getting a single, unique, superintelligent AGI, and the amount it cares about, values, and prioritizes human welfare relative to its other values is a random draw with probability distribution equal to how much random humans care about maximizing their total number of direct descendents.
If you think that the first AGI crossing some capability threshold is likely to suddenly takeover the world, then the species level alignment analogy breaks down and doom is more likely. It would be like a single medieval era human suddenly taking over the world via powerful magic. Would the resulting world after optimization according to that single human's desires still score reasonably well at IGF? I'd say somewhere between 90% to 50% probability, but that's still clearly a high p(doom) scenario
So it'd be a random draw with a fairly high p(doom), so no not a success in expectation relative to the futures I expect.
In actuality I expect the situation to be more multipolar, and thus more robust due to utility function averaging. If power is distributed over N agents each with a utility function that is variably but even slightly aligned to humanity in expectation, that converges with increasing N to full alignment at the population level[1].
As we expect the divergence in agent utility functions to all be from forms of convergent selfish empowerment, which are necessarily not aligned with each other (ie none of the AIs are inter aligned except through variable partial alignment to humanity). ↩︎
I feel like jacob_cannell's argument is a bit circular. Humans have been successful so far but if AI risk is real, we're clearly doing a bad job at truly maximizing our survival chances. So the argument already assumes AI risk isn't real.