Posts
Comments
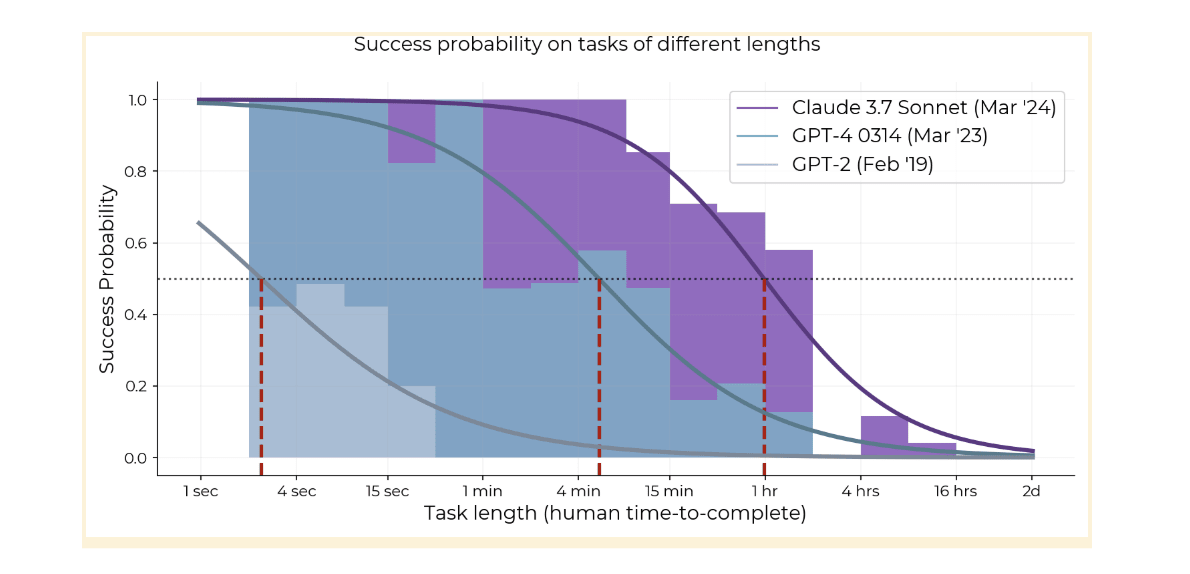
Time horizon of o3 is ~1.5 hours vs Claude 3.7's 54 minutes, and it's statistically significant that it's above the long-term trend. It's been less than 2 months since the release of Claude 3.7. If time horizon continues doubling every 3.5 months as it has over the last year, we only have another 12 months until time horizon hits 16 hours and we are unable to measure it with HCAST.
My guess is that future model time horizon will double every 3-4 months for well-defined tasks (HCAST, RE-Bench, most automatically scorable tasks) that labs can RL on, while capability on more realistic tasks will follow the long-term 7-month doubling time.
Benchmark Readiness Level
Safety-relevant properties should be ranked on a "Benchmark Readiness Level" (BRL) scale, inspired by NASA's Technology Readiness Levels. At BRL 4, a benchmark exists; at BRL 6 the benchmark is highly valid; past this point the benchmark becomes increasingly robust against sandbagging. The definitions could look something like this:
| BRL | Definition | Example |
| 1 | Theoretical relevance to x-risk defined | Adversarial competence |
| 2 | Property operationalized for frontier AIs and ASIs | AI R&D speedup; Misaligned goals |
| 3 | Behavior (or all parts) observed in artificial settings. Preliminary measurements exist, but may have large methodological flaws. | Reward hacking |
| 4 | Benchmark developed, but may measure different core skills from the ideal measure | Cyber offense (CyBench) |
| 5 | Benchmark measures roughly what we want; superhuman range; methodology is documented and reproducible but may have validity concerns. | Software (HCAST++) |
| 6 | "Production quality" high-validity benchmark. Strongly superhuman range; run on many frontier models; red-teamed for validity; represents all sub-capabilities. Portable implementation. | |
| 7 | Extensive validity checks against downstream properties; reasonable attempts (e.g. fine-tuning) to detect whether AIs are manipulating/sandbagging their scores. | Knowledge (MMLU with fine-tuning) |
| 8 | - | |
| 9 | Benchmark has high validity to real-world contexts beyond lab settings. Can ensure accuracy even when measuring superintelligences with potentially deceptive capabilities. | - |
Here's a draft list of properties we could apply the BRL to, including capabilities and propensity:
- General capabilities
- Software ability (HCAST, others)
- Knowledge (Humanity's Last Exam, others)
- Sandbagging
- Situational awareness
- Alignment faking
- Sandbagging ability
- Monitorability
- Steganographic collusion
- Neuralese
- Faithful CoT
- Ability to monitor smarter AIs
- Research acceleration
- % LoC written by AIs
- AI R&D Uplift
- Escape risk
- Adversarial competence
- Self-exfiltration
- Cyber offense
- Misalignment
- Reward hacking
- Misaligned goals
- Other Dangers
- CBRN
- Persuasion
Is this doomed? Am I missing anything important?
Some versions of the METR time horizon paper from alternate universes:
Measuring AI Ability to Take Over Small Countries (idea by Caleb Parikh)
Abstract: Many are worried that AI will take over the world, but extrapolation from existing benchmarks suffers from a large distributional shift that makes it difficult to forecast the date of world takeover. We rectify this by constructing a suite of 193 realistic, diverse countries with territory sizes from 0.44 to 17 million km^2. Taking over most countries requires acting over a long time horizon, with the exception of France. Over the last 6 years, the land area that AI can successfully take over with 50% success rate has increased from 0 to 0 km^2, doubling 0 times per year (95% CI 0.0-∞ yearly doublings); extrapolation suggests that AI world takeover is unlikely to occur in the near future. To address concerns about the narrowness of our distribution, we also study AI ability to take over small planets and asteroids, and find similar trends.
When Will Worrying About AI Be Automated?
Abstract: Since 2019, the amount of time LW has spent worrying about AI has doubled every seven months, and now constitutes the primary bottleneck to AI safety research. Automation of worrying would be transformative to the research landscape, but worrying includes several complex behaviors, ranging from simple fretting to concern, anxiety, perseveration, and existential dread, and so is difficult to measure. We benchmark the ability of frontier AIs to worry about common topics like disease, romantic rejection, and job security, and find that current frontier models such as Claude 3.7 Sonnet already outperform top humans, especially in existential dread. If these results generalize to worrying about AI risk, AI systems will be capable of autonomously worrying about their own capabilities by the end of this year, allowing us to outsource all our AI concerns to the systems themselves.
Estimating Time Since The Singularity
Early work on the time horizon paper used a hyperbolic fit, which predicted that AGI (AI with an infinite time horizon) was reached last Thursday. [1] We were skeptical at first because the R^2 was extremely low, but recent analysis by Epoch suggested that AI already outperformed humans at a 100-year time horizon by about 2016. We have no choice but to infer that the Singularity has already happened, and therefore the world around us is a simulation. We construct a Monte Carlo estimate over dates since the Singularity and simulator intentions, and find that the simulation will likely be turned off in the next three to six months.
[1]: This is true
Quick list of reasons for me:
- I'm averse to attending mass protests myself because they make it harder to think clearly and I usually don't agree with everything any given movement stands for.
- Under my worldview, an unconditional pause is a much harder ask than is required to save most worlds if p(doom) is 14% (the number stated on the website). It seems highly impractical to implement compared to more common regulatory frameworks and is also super unaesthetic because I am generally pro-progress.
- The economic and political landscape around AI is complicated enough that agreeing with their stated goals is not enough; you need to agree with their theory of change.
- Broad public movements require making alliances which can be harmful in the long term. Environmentalism turned anti-nuclear, a decades-long mistake which has accelerated climate change by years. PauseAI wants to include people who oppose AI on its present dangers, which makes me uneasy. What if the landscape changes such that the best course of action is contrary to PauseAI's current goals?
- I think PauseAI's theory of change is weak
- From reading the website, they want to leverage protests, volunteer lobbying, and informing the public into an international treaty banning superhuman AI and a unilateral supply-chain pause. It seems hard for the general public to have significant influence over this kind of issue unless AI rises to the top issue for most Americans, since the current top issue is improving the economy, which directly conflicts with a pause.
- There are better theories of change
- Strengthening RSPs into industry standards, then regulations.
- Directly informing elites about the dangers of AI, rather than the general public.
- History (e.g. civil rights movement) shows that moderates not publicly endorsing radicals can result in a positive radical flank effect making moderates' goals easier to achieve.
I basically agree with this. The reason the paper didn't include this kind of reasoning (only a paragraph about how AGI will have infinite horizon length) is we felt that making a forecast based on a superexponential trend would be too much speculation for an academic paper. (There is really no way to make one without heavy reliance on priors; does it speed up by 10% per doubling or 20%?) It wasn't necessary given the 2027 and 2029-2030 dates for 1-month AI derived from extrapolation already roughly bracketed our uncertainty.
External validity is a huge concern, so we don't claim anything as ambitious as average knowledge worker tasks. In one sentence, my opinion is that our tasks suite is fairly representative of well-defined, low-context, measurable software tasks that can be done without a GUI. More speculatively, horizons on this are probably within a large (~10x) constant factor of horizons on most other software tasks. We have a lot more discussion of this in the paper, especially in heading 7.2.1 "Systematic differences between our tasks and real tasks". The HCAST paper also has a better description of the dataset.
We didn't try to make the dataset a perfectly stratified sample of tasks meeting that description, but there is enough diversity in the dataset that I'm much more concerned about relevance of HCAST-like tasks to real life than relevance of HCAST to the universe of HCAST-like tasks.
Humans don't need 10x more memory per step nor 100x more compute to do a 10-year project than a 1-year project, so this is proof it isn't a hard constraint. It might need an architecture change but if the Gods of Straight Lines control the trend, AI companies will invent it as part of normal algorithmic progress and we will remain on an exponential / superexponential trend.
Regarding 1 and 2, I basically agree that SWAA doesn't provide much independent signal. The reason we made SWAA was that models before GPT-4 got ~0% on HCAST, so we needed shorter tasks to measure their time horizon. 3 is definitely a concern and we're currently collecting data on open-source PRs to get a more representative sample of long tasks.
That bit at the end about "time horizon of our average baseliner" is a little confusing to me, but I understand it to mean "if we used the 50% reliability metric on the humans we had do these tasks, our model would say humans can't reliably perform tasks that take longer than an hour". Which is a pretty interesting point.
That's basically correct. To give a little more context for why we don't really believe this number, during data collection we were not really trying to measure the human success rate, just get successful human runs and measure their time. It was very common for baseliners to realize that finishing the task would take too long, give up, and try to collect speed bonuses on other tasks. This is somewhat concerning for biasing the human time-to-complete estimates, but much more concerning for this human time horizon measurement. So we don't claim the human time horizon as a result.
All models since at least GPT-3 have had this steep exponential decay [1], and the whole logistic curve has kept shifting to the right. The 80% success rate horizon has basically the same 7-month doubling time as the 50% horizon so it's not just an artifact of picking 50% as a threshold.
Claude 3.7 isn't doing better on >2 hour tasks than o1, so it might be that the curve is compressing, but this might also just be noise or imperfect elicitation.
Regarding the idea that autoregressive models would plateau at hours or days, it's plausible, and one point of evidence is that models are not really coherent over hundreds of steps (generations + uses of the Python tool) yet-- they do 1-2 hour tasks with ~10 actions, see section 5 of HCAST paper. On the other hand, current LLMs can learn a lot in-context and it's not clear there are limits to this. In our qualitative analysis we found evidence of increasing coherence, where o1 fails tasks due to repeating failed actions 6x less than GPT-4 1106.
Maybe this could be tested by extracting ~1 hour tasks out of the hours to days long projects that we think are heavy in self-modeling, like planning. But we will see whether there's a plateau at the hours range in the next year or two anyway.
[1] we don't have easy enough tasks that GPT-2 can do them with >50% success, so can't check the shape
It's expensive to construct and baseline novel tasks for this (we spent well over $100k on human baselines) so what we are able to measure in the future depends on whether we can harvest realistic tasks that naturally have human data. You could do a rough analysis on math contest problems, say assigning GSM8K and AIME questions lengths based on a guess of how long expert humans take, but the external validity concerns are worse than for software. For one thing, AIME has much harder topics than GSM8K (we tried to make SWAA not be artificially easier or harder than HCAST); for another, neither are particularly close to the average few minutes of a research mathematician's job.
The trend probably sped up in 2024. If the future trend follows the 2024--2025 trend, we get 50% reliability at 167 hours in 2027.
Author here. My best guess is that by around the 1-month point, AIs will be automating large parts of both AI capabilities and empirical alignment research. Inferring anything more depends on many other beliefs.
Currently no one knows how hard the alignment problem is or what exactly good alignment research means-- it is the furthest-looking, least well-defined and least tractable of the subfields of AI existential safety. This means we don't know the equivalent task length of the alignment problem. Even more importantly, we only measured the AIs at software tasks and don't know what the trend is for other domains like math or law, it could be wildly different.
With that said, my current guess is that alignment will be sped up by AI slightly less than capabilities will be, success looks like building deferrable AI, and whether we succeed depends on whether the world dedicates more than X% [1] of AI research resources to relevant safety research than the exact software time horizon of the AIs involved, which is not directly applicable.
[1] X is some unknown number probably between 0% and 65%
AIs (and humans) don't have 100% reliability at anything, so the graph tracks when AIs get a 50% success rate on our dataset, over all tasks and attempts. We also measure AI horizons at 80% success rate in the paper, and those are about 5x shorter. It's hard to measure much higher than 80% with our limited task suite, but if we could we would measure 95% and 99% as well.
So the citation is an unreleased paper! That unreleased paper may make a splash, since (assuming this 7-month-doubling trend is not merely 1-2 years old) it strongly implies we really will find good solutions for turning LLMs agentic fairly soon.
The 7-month doubling trend we measured actually goes back to GPT-2 in 2019. Since 2024, the trend has been faster, doubling roughly every 3-4 months depending on how you measure, but we only have six 2024-25 models so error bars are wide and it's really unclear which trend will be predictive of the future.
Important results from the paper as I see it:
- RL agents can learn to cheat in the wild, and CoT pressure doesn't prevent it.
- The slope of cheating increase and final cheating rate are both slightly lower when applying CoT pressure, but all of the cheating will go uncaught by the monitor.
- GPT-4o can zero-shot monitor o3-level agents with 95% accuracy when it has access to CoT, only 60% when it can only monitor actions.
- If there is no CoT pressure, RL agents telegraph their cheating, such that cheating precision and recall actually go up over time for a monitor that can only see CoT
- True utility (success rate counting cheating as failure) initially increases faster with CoT pressure than without, despite low initial levels of cheating in both.
- I'm not sure why this is given they said the only change in reward related to CoT pressure is that the agent doesn't get reward when the monitor flags.
- If you allow rejection sampling, the utility curve is roughly similar between CoT pressure and no CoT pressure. This rhymes with the Scaling Laws for Reward Model Overoptimization result where utility is similar between RL and best-of-k
Speculation:
- The information that the model is cheating seems basically gone from the CoT, so training against a weak monitor and monitoring using a stronger monitor could be unreliable
- How much CoT pressure should you apply to maximize utility? Figure 4 suggests that if you do RL, cheating will happen at roughly the same point in training with or without CoT pressure (~0.3 epochs), which also coincides with the maximum utility point, so stop at the point where the non-CoT-pressure model starts to do detectable cheating.
- It is unclear how this applies to cheating / other malicious behaviors that are hard enough that they require CoT. My prior is that capabilities at hiding misaligned behaviors under CoT monitoring will improve at similar rates to capabilities at reasoning without CoT in other domains, although the presence of a monitor might specifically target the skill of obfuscating misaligned reasoning and make it happen sooner.
I think we have two separate claims here:
- Do technologies that have lots of resources put into their development generally improve discontinuously or by huge slope changes?
- Do technologies often get displaced by technologies with a different lineage?
I agree with your position on (2) here. But it seems like the claim in the post that sometime in the 2030s someone will make a single important architectural innovation that leads to takeover within a year mostly depends on (1), as it would require progress within that year to be comparable to all the progress from now until that year. Also you said the architectural innovation might be a slight tweak to the LLM architecture, which would mean it shares the same lineage.
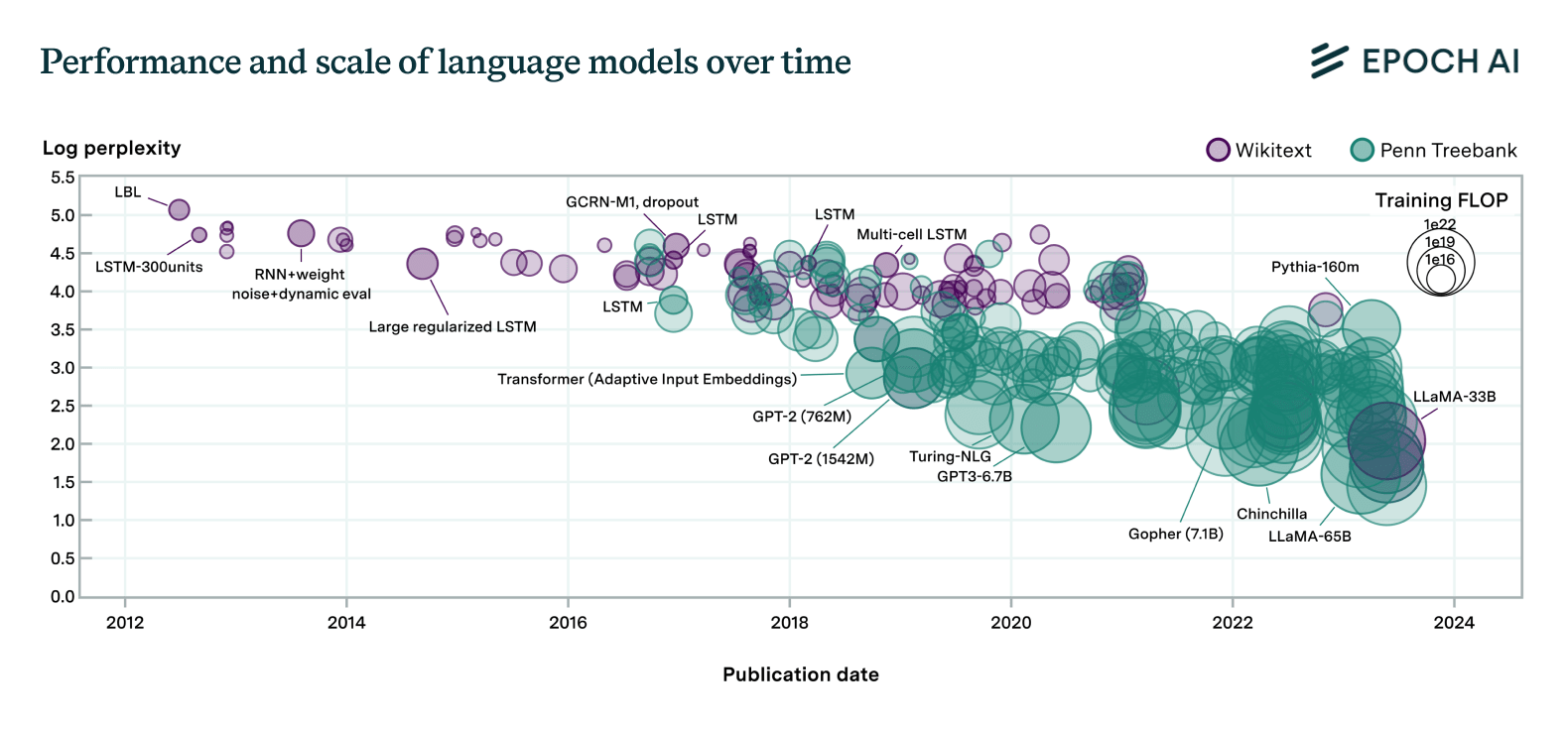
The history of machine learning seems pretty continuous wrt advance prediction. In the Epoch graph, the line fit on loss of the best LSTM up to 2016 sees a slope change of less than 2x, whereas a hypothetical innovation that causes takeover within a year with not much progress in the intervening 8 years would be ~8x. So it seems more likely to me (conditional on 2033 timelines and a big innovation) that we get some architectural innovation which has a moderately different lineage in 2027, it overtakes transformers' performance in 2029, and afterward causes the rate of AI improvement to increase by something like 1.5x-2x.
2 out of 3 of the technologies you listed probably have continuous improvement despite the lineage change
- 1910-era cars were only a little better than horses, and the overall speed someone could travel long distances in the US probably increased in slope by <2x after cars due to things like road quality improvement before cars and improvements in ships and rail (though maybe railroads were a discontinuity, not sure)
- Before refrigerators we had low-quality refrigerators that would contaminate the ice with ammonia, and before that people shipped ice from Maine, so I would expect the cost/quality of refrigeration to have much less than an 8x slope change at the advent of mechanical refrigeration
- Only rockets were actually a discontinuity
Tell me if you disagree.
Easy verification makes for benchmarks that can quickly be cracked by LLMs. Hard verification makes for benchmarks that aren't used.
Agree, this is one big limitation of the paper I'm working on at METR. The first two ideas you listed are things I would very much like to measure, and the third something I would like to measure but is much harder than any current benchmark given that university takes humans years rather than hours. If we measure it right, we could tell whether generalization is steadily improving or plateauing.
Though the fully connected -> transformers wasn't infinite small steps, it definitely wasn't a single step. We had to invent various sub-innovations like skip connections separately, progressing from RNNs to LSTM to GPT/BERT style transformers to today's transformer++. The most you could claim is a single step is LSTM -> transformer.
Also if you graph perplexity over time, there's basically no discontinuity from introducing transformers, just a possible change in slope that might be an artifact of switching from the purple to green measurement method. The story looks more like transformers being more able to utilize the exponentially increasing amounts of compute that people started using just before its introduction, which caused people to invest more in compute and other improvements over the next 8 years.
We could get another single big architectural innovation that gives better returns to more compute, but I'd give a 50-50 chance that it would be only a slope change, not a discontinuity. Even conditional on discontinuity it might be pretty small. Personally my timelines are also short enough that there is limited time for this to happen before we get AGI.
A continuous manifold of possible technologies is not required for continuous progress. All that is needed is for there to be many possible sources of improvements that can accumulate, and for these improvements to be small once low-hanging fruit is exhausted.
Case in point: the nanogpt speedrun, where the training time of a small LLM was reduced by 15x using 21 distinct innovations which touched basically every part of the model, including the optimizer, embeddings, attention, other architectural details, quantization, hyperparameters, code optimizations, and Pytorch version.
Most technologies are like this, and frontier AI has even more sources of improvement than the nanogpt speedrun because you can also change the training data and hardware. It's not impossible that there's a moment in AI like the invention of lasers or the telegraph, but this doesn't happen with most technologies, and the fact that we have scaling laws somewhat points towards continuity even as other things like small differences being amplified in downstream metrics point to discontinuity. Also see my comment here on a similar topic.
If you think generalization is limited in the current regime, try to create AGI-complete benchmarks that the AIs won't saturate until we reach some crucial innovation. People keep trying this and they keep saturating every year.
I think eating the Sun is our destiny, both in that I expect it to happen and that I would be pretty sad if we didn't; I just hope it will be done ethically. This might seem like a strong statement but bear with me
Our civilization has undergone many shifts in values as higher tech levels have indicated that sheer impracticality of living a certain way, and I feel okay about most of these. You won't see many people nowadays who avoid being photographed because photos steal a piece of their soul. The prohibition on women working outside the home, common in many cultures, is on its way out. Only a few groups like the Amish avoid using electricity for culture reasons. The entire world economy runs on usury stacked upon usury. People cared about all of these things strongly, but practicality won.
To believe that eating the Sun is potentially desirable, you don't have to have linear utility in energy/mass/whatever and want to turn it into hedonium. It just seems like extending the same sort of tradeoffs societies make every day in 2025 leads to eating the sun, considering just how large a fraction of available resources it will represent to a future civilization. The Sun is 99.9% of the matter and more than 99.9% of the energy in the solar system, and I can't think of any examples of a culture giving up even 99% of its resources for cultural reasons. No one bans eating 99.9% of available calories, farming 99.9% of available land, or working 99.9% of jobs. Today, traditionally minded and off-grid people generally strike a balance between commitment to their lifestyle and practicality, and many of them use phones and hospitals. Giving up 99.9% of resources would mean giving up metal and basically living in the Stone Age. [1]
When eating the Sun, as long as we spend 0.0001% of the Sun's energy to set up an equivalent light source pointing at Earth, it doesn't prevent people from continuing to live on Earth, spending their time farming potatoes and painting, nor does it destroy any habitats. There is really nothing of great intrinsic value lost here. We can't do the same today when destroying the rainforests! If people block eating the Sun and this is making peoples' lives worse it's plausible we should think of them like NIMBYs who prevent dozens of poor people from getting housing because it would ruin their view.
The closest analogies I can think of in the present day are nuclear power bans and people banning vitamin-enriched GMO crops even as children were dying of malnutrition. With nuclear, energy is cheap enough that people can still heat their homes without, so maybe we'll have an analogous situation where energy is much cheaper than non-hydrogen matter during the period when we would want to eat the Sun. (We would definitely disassemble most of the planets though, unless energy and matter are both cheap relative to some third thing but I don't see what that would be.) With GMOs I feel pretty sad about the whole situation and wish that science communication were better. At least if we fail to eat the sun and distribute gains to society people probably wouldn't die as a result.
[1] It might be that the 1000xing income is less valuable in the future than it was in the Neolithic, but probably a Neolithic person would also be skeptical that 1000xing resources is valuable until you explain what technology can do now. If we currently value talking to people across the world, why wouldn't future people value running 10,000 copies of themselves to socialize with all their friends at once?
Will we ever have Poké Balls in real life? How fast could they be at storing and retrieving animals? Requirements:
- Made of atoms, no teleportation or fantasy physics.
- Small enough to be easily thrown, say under 5 inches diameter
- Must be able to disassemble and reconstruct an animal as large as an elephant in a reasonable amount of time, say 5 minutes, and store its pattern digitally
- Must reconstruct the animal to enough fidelity that its memories are intact and it's physically identical for most purposes, though maybe not quite to the cellular level
- No external power source
- Works basically wherever you throw it, though it might be slower to print the animal if it only has air to use as feedstock mass or can't spread out to dissipate heat
- Should not destroy nearby buildings when used
- Animals must feel no pain during the process
It feels pretty likely to me that we'll be able to print complex animals eventually using nanotech/biotech, but the speed requirements here might be pushing the limits of what's possible. In particular heat dissipation seems like a huge challenge; assuming that 0.2 kcal/g of waste heat is created while assembling the elephant, which is well below what elephants need to build their tissues, you would need to dissipate about 5 GJ of heat, which would take even a full-sized nuclear power plant cooling tower a few seconds. Power might be another challenge. Drexler claims you can eat fuel and oxidizer, turn all the mass into basically any lower-energy state, and come out easily net positive on energy. But if there is none available you would need a nuclear reactor.
and yet, the richest person is still only responsible for 0.1%* of the economic output of the united states.
Musk only owns 0.1% of the economic output of the US but he is responsible for more than this, including large contributions to
- Politics
- Space
- SpaceX is nearly 90% of global upmass
- Dragon is the sole American spacecraft that can launch humans to ISS
- Starlink probably enables far more economic activity than its revenue
- Quality and quantity of US spy satellites (Starshield has ~tripled NRO satellite mass)
- Startup culture through the many startups from ex-SpaceX employees
- Twitter as a medium of discourse, though this didn't change much
- Electric cars probably sped up by ~1 year by Tesla, which still owns over half the nation's charging infrastructure
- AI, including medium-sized effects on OpenAI and potential future effects through xAI
Depending on your reckoning I wouldn't be surprised if Elon's influence added up to >1% of Americans combined. This is not really surprising because a Zipfian relationship would give the top person in a nation of 300 million 5% of the total influence.
Agree that AI takeoff could likely be faster than our OODA loop.
There are four key differences between this and the current AI situation that I think makes this perspective pretty outdated:
- AIs are made out of ML, so we have very fine-grained control over how we train them and modify them for deployment, unlike animals which have unpredictable biological drives and long feedback loops.
- By now, AIs are obviously developing generalized capabilities. Rather than arguments over whether AIs will ever be superintelligent, the bulk of the discourse is over whether they will supercharge economic growth or cause massive job loss and how quickly.
- There are at least 10 companies that could build superintelligence within 10ish years and their CEOs are all high on motivated reasoning, so stopping is infeasible
- Current evidence points to takeoff being continuous and merely very fast-- even automating AI R&D won't cause the hockey-stick graph that human civilization had
"Random goals" is a crux. Complicated goals that we can't control well enough to prevent takeover are not necessarily uniformly random goals from whatever space you have in mind.
"Don't believe there is any chance" is very strong. If there is a viable way to bet on this I would be willing to bet at even odds that conditional on AI takeover, a few humans survive 100 years past AI takeover.
I'm working on the autonomy length graph mentioned from METR and want to caveat these preliminary results. Basically, we think the effective horizon length of models is a bit shorter than 2 hours, although we do think there is an exponential increase that, if it continues, could mean month-long horizons within 3 years.
- Our task suite is of well-defined tasks. We have preliminary data showing that messier tasks like the average SWE intellectual labor are harder for both models and low-context humans.
- This graph is of 50% horizon time (the human time-to-complete at which models succeed at 50% of tasks). The 80% horizon time is only about 15 minutes for current models.
We'll have a blog post out soon showing the trend over the last 5 years and going into more depth about our methodology.
- It's not clear whether agents will think in neuralese, maybe end-to-end RL in English is good enough for the next few years and CoT messages won't drift enough to allow steganography
- Once agents think in either token gibberish or plain vectors maybe self-monitoring will still work fine. After all agents can translate between other languages just fine. We can use model organisms or some other clever experiments to check whether the agent faithfully translates its CoT or unavoidably starts lying to us as it gets more capable.
- I care about the exact degree to which monitoring gets worse. Plausibly it gets somewhat worse but is still good enough to catch the model before it coups us.
I'm not happy about this but it seems basically priced in, so not much update on p(doom).
We will soon have Bayesian updates to make. If we observe that incentives created during end-to-end RL naturally produce goal guarding and other dangerous cognitive properties, it will be bad news. If we observe this doesn't happen, it will be good news (although not very good news because web research seems like it doesn't require the full range of agency).
Likewise, if we observe models' monitorability and interpretability start to tank as they think in neuralese, it will be bad news. If monitoring and interpretability are unaffected, good news.
Interesting times.
Thanks for the update! Let me attempt to convey why I think this post would have been better with fewer distinct points:
In retrospect, maybe I should've gone into explaining the basics of entropy and enthalpy in my reply, eg:
If you replied with this, I would have said something like "then what's wrong with the designs for diamond mechanosynthesis tooltips, which don't resemble enzymes and have been computationally simulated as you mentioned in point 9?" then we would have gone back and forth a few times until either (a) you make some complicated argument I don't understand enough to believe nor refute, or (b) we agree on what definition of "enzyme" or "selectively bind to individual molecules" is required for nanotech, which probably includes the carbon dimer placer (image below). Even in case (b) we could continue arguing about how practical that thing plus other steps in the process are, and not achieve much.

The problem as I see it is that a post that makes a large number of points quickly, where each point has subtleties requiring an expert to adjudicate, on a site with few experts, is inherently going to generate a lot of misunderstanding. I have a symmetrical problem to you; from my perspective someone was using somewhat complicated arguments to prove things that defy my physical intuition, and to defend against a Gish gallop I need to respond to every point, but doing this in a reasonable amount of time requires me to think and write with less than maximum clarity and accuracy.
The solution I would humbly recommend is to make fewer points, selected carefully to be bulletproof, understandable to non-experts, and important to the overall thesis. Looking back on this, point 14 could have been its own longform, and potentially led to a lot of interesting discussion like this post did. Likewise point 6 paragraph 2.
How would we know?
This doesn't seem wrong to me so I'm now confused again what the correct analysis is. It would come out the same way if we assume rationalists are selected on g right?
Is a Gaussian prior correct though? I feel like it might be double-counting evidence somehow.
TLDR:
- What OP calls "streetlighting", I call an efficient way to prioritize problems by tractability. This is only a problem insofar as we cannot also prioritize by relevance.
- I think problematic streetlighting is largely due to incentives, not because people are not smart / technically skilled enough. Therefore solutions should fix incentives rather than just recruiting smarter people.
First, let me establish that theorists very often disagree on what the hard parts of the alignment problem are, precisely because not enough theoretical and empirical progress has been made to generate agreement on them. All the lists of "core hard problems" OP lists are different, and Paul Christiano famously wrote a 27-point list of disagreements on Eliezer's. This means that most people's views of the problem are wrong, and should they stick to their guns they might perseverate on either an irrelevant problem or a doomed approach.
I'd guess that historically perseveration has been an equally large problem as streetlighting among alignment researchers. Think of all the top alignment researchers in 2018 and all the agendas that haven't seen much progress. Decision theory should probably not take ~30% of researcher time like it did back in the day.[1]
In fact, failure is especially likely for people who are trying to tackle "core hard problems" head-on, and not due to lack of intelligence. Many "core hard problems" are observations of lack of structure, or observations of what might happen in extreme generality e.g. Eliezer's
- "We've got no idea what's actually going on inside the giant inscrutable matrices and tensors of floating-point numbers."
- (summarized) "Outer optimization doesn't in general produce aligned inner goals", or
- "Human beings cannot inspect an AGI's output to determine whether the consequences will be good."
which I will note are completely different type signature from subproblems that people can actually tractably research. Sometimes we fail to define a tractable line of attack. Other times these ill-defined problems get turned into entire subfields of alignment, like interpretability, which are filled with dozens of blind alleys of irrelevance that extremely smart people frequently fall victim to. For comparison, some examples of problems ML and math researchers can actually work on:
- Unlearning: Develop a method for post-hoc editing a model, to make it as if it were never trained on certain data points
- Causal inference: Develop methods for estimating the causation graph between events given various observational data.
- Fermat's last theorem: Prove whether there are integer solutions to an + bn = cn.
The unit of progress is therefore not "core hard problems" directly, but methods that solve well-defined problems and will also be useful in scalable alignment plans. We must try to understand the problem and update our research directions as we go. Everyone has to pivot because the exact path you expected to solve a problem basically never works. But we have to update on tractability as well as relevance! For example, Redwood (IMO correctly) pivoted away from interp because other plans seemed viable (relevance) and it seemed too hard to explain enough AI cognition through interpretability to solve alignment (tractability).[2]
OP seems to think flinching away from hard problems is usually cope / not being smart enough. But OP's list of types of cope are completely valid as either fundamental problem-solving strategies or prioritization. (4 is an incentives problem, which I'll come back to later)
- Carol explicitly introduces some assumption simplifying the problem, and claims that without the assumption the problem is impossible. [...]
- Carol explicitly says that she's not trying to solve the full problem, but hopefully the easier version will make useful marginal progress.
- Carol explicitly says that her work on easier problems is only intended to help with near-term AI, and hopefully those AIs will be able to solve the harder problems.
1 and 2 are fundamental problem-solving techniques. 1 is a crucial part of Polya's step 1: understand the problem, and 2 is a core technique for actually solving the problem. I don't like relying on 3 as stated, but there are many valid reasons for focusing on near-term AI[3].
Now I do think there is lots of distortion of research in unhelpful directions related to (1, 2, 3), often due to publication incentives.[4] But understanding the problem and solving easier versions of it has a great track record in complicated engineering; you just have to solve the hard version eventually (assuming we don't get lucky with alignment being easy, which is very possible but we shouldn't plan for).
So to summarize my thoughts:
- Streetlighting is real, but much of what OP calls streetlighting is a justified focus on tractability.
- We can only solve "core hard problems" by creating tractable well-defined problems
- OP's suggested solution-- higher intelligence and technical knowledge-- doesn't seem to fit the problem.
- There are dozens of ML PhDs, physics PhDs, and comparably smart people working on alignment. As Ryan Kidd pointed out, the stereotypical MATS student is now a physics PhD or technical professional. And presumably according to OP, most people are still streetlighting.
- Technically skilled people seem equally susceptible to incentives-driven streetlighting, as well as perseveration.
- If the incentives continue to be wrong, people who defy them might be punished anyway.
- Instead, we should fix incentives, maybe like this:
- Invest in making "core hard problems" easier to study
- Reward people who have alignment plans that at least try to scale to superintelligence
- Reward people who think about whether others' work will be helpful with superintelligence
- Develop things like alignment workshops, so people have a venue to publish genuine progress that is not legible to conferences
- Pay researchers with illegible results more to compensate for their lack of publication / social rewards
- ^
MIRI's focus on decision theory is itself somewhat due to streetlighting. As I understand, 2012ish MIRI leadership's worldview was that several problems had to be solved for AI to go well, but the one they could best hire researchers for was decision theory, so they did lots of that. Also someone please correct me on the 30% of researcher time claim if I'm wrong.
- ^
OP's research is not immune to this. My sense is that selection theorems would have worked out if there had been more and better results.
- ^
e.g. if deploying on near-term AI will yield empirical feedback needed to stay on track, significant risk comes from near-term AI, near-term AI will be used in scalable oversight schemes, ...
- ^
As I see it, there is lots of distortion by the publishing process now that lots of work is being published. Alignment is complex enough that progress in understanding the problem is a large enough quantity of work to be a paper. But in a paper, it's very common to exaggerate one's work, especially the validity of the assumptions[5], and people need to see through this for the field to function smoothly.
- ^
I am probably guilty of this myself, though I try to honestly communicate my feelings about the assumptions in a long limitations section
Under log returns to money, personal savings still matter a lot for selfish preferences. Suppose the material comfort component of someone's utility is 0 utils at an consumption of $1/day. Then a moderately wealthy person consuming $1000/day today will be at 7 utils. The owner of a galaxy, at maybe $10^30 / day, will be at 69 utils, but doubling their resources will still add the same 0.69 utils it would for today's moderately wealthy person. So my guess is they will still try pretty hard at acquiring more resources, similarly to people in developed economies today who balk at their income being halved and see it as a pretty extreme sacrifice.
I agree. You only multiply the SAT z-score by 0.8 if you're selecting people on high SAT score and estimating the IQ of that subpopulation, making a correction for regressional Goodhart. Rationalists are more likely selected for high g which causes both SAT and IQ, so the z-score should be around 2.42, which means the estimate should be (100 + 2.42 * 15 - 6) = 130.3. From the link, the exact values should depend on the correlations between g, IQ, and SAT score, but it seems unlikely that the correction factor is as low as 0.8.
I was at the NeurIPS many-shot jailbreaking poster today and heard that defenses only shift the attack success curve downwards, rather than changing the power law exponent. How does the power law exponent of BoN jailbreaking compare to many-shot, and are there defenses that change the power law exponent here?
It's likely possible to engineer away mutations just by checking. ECC memory already has an error rate nine orders of magnitude better than human DNA, and with better error correction you could probably get the error rate low enough that less than one error happens in the expected number of nanobots that will ever exist. ECC is not the kind of checking for which the checking process can be disabled, as the memory module always processes raw bits into error-corrected bits, which fails unless it matches some checksum which can be made astronomically unlikely to happen in a mutation.
I was expecting some math. Maybe something about the expected amount of work you can get out of an AI before it coups you, if you assume the number of actions required to coup is n, the trusted monitor has false positive rate p, etc?
I'm pretty skeptical of this because the analogy seems superficial. Thermodynamics says useful things about abstractions like "work" because we have the laws of thermodynamics. What are the analogous laws for cognitive work / optimization power? It's not clear to me that it can be quantified such that it is easily accounted for:
- We all come from evolution. Where did the cognitive work come from?
- Algorithms can be copied
- Passwords can unlock optimization
It is also not clear what distinguishes LLM weights from the weights of a model trained on random labels from a cryptographic PRNG. Since the labels are not truly random, they have the same amount of optimization done to them, but since CSPRNGs can't be broken just by training LLMs on them, the latter model is totally useless while the former is potentially transformative.
My guess is this way of looking at things will be like memetics in relation to genetics: likely to spawn one or two useful expressions like "memetically fit", but due to the inherent lack of structure in memes compared to DNA life, not a real field compared to other ways of measuring AIs and their effects (scaling laws? SLT?). Hope I'm wrong.
Maybe we'll see the Go version of Leela give nine stones to pros soon? Or 20 stones to normal players?
Whether or not it would happen by default, this would be the single most useful LW feature for me. I'm often really unsure whether a post will get enough attention to be worth making it a longform, and sometimes even post shortforms like "comment if you want this to be a longform".
I thought it would be linearity of expectation.
The North Wind, the Sun, and Abadar
One day, the North Wind and the Sun argued about which of them was the strongest. Abadar, the god of commerce and civilization, stopped to observe their dispute. “Why don’t we settle this fairly?” he suggested. “Let us see who can compel that traveler on the road below to remove his cloak.”
The North Wind agreed, and with a mighty gust, he began his effort. The man, feeling the bitter chill, clutched his cloak tightly around him and even pulled it over his head to protect himself from the relentless wind. After a time, the North Wind gave up, frustrated.
Then the Sun tried his turn. Beaming warmly from the heavens, the Sun caused the air to grow pleasant and balmy. The man, feeling the growing heat, loosened his cloak and eventually took it off in the heat, resting under the shade of a tree. The Sun began to declare victory, but as soon as he turned away, the man put on the cloak again.
The god of commerce then approached the traveler and bought the cloak for five gold coins. The traveler tucked the money away and continued on his way, unbothered by either wind or heat. He soon bought a new cloak and invested the remainder in an index fund. The returns were steady, and in time the man prospered far beyond the value of his simple cloak, while the cloak was Abadar's permanently.
Commerce, when conducted wisely, can accomplish what neither force nor gentle persuasion alone can achieve, and with minimal deadweight loss.
The thought experiment is not about the idea that your VNM utility could theoretically be doubled, but instead about rejecting diminishing returns to actual matter and energy in the universe. SBF said he would flip with a 51% of doubling the universe's size (or creating a duplicate universe) and 49% of destroying the current universe. Taking this bet requires a stronger commitment to utilitarianism than most people are comfortable with; your utility needs to be linear in matter and energy. You must be the kind of person that would take a 0.001% chance of colonizing the universe over a 100% chance of colonizing merely a thousand galaxies. SBF also said he would flip repeatedly, indicating that he didn't believe in any sort of bound to utility.
This is not necessarily crazy-- I think Nate Soares has a similar belief-- but it's philosophically fraught. You need to contend with the unbounded utility paradoxes, and also philosophical issues: what if consciousness is information patterns that become redundant when duplicated, so that only the first universe "counts" morally?
For context, I just trialed at METR and talked to various people there, but this take is my own.
I think further development of evals is likely to either get effective evals (informal upper bound on the future probability of catastrophe) or exciting negative results ("models do not follow reliable scaling laws, so AI development should be accordingly more cautious").
The way to do this is just to examine models and fit scaling laws for catastrophe propensity, or various precursors thereof. Scaling laws would be fit to elicitation quality as well as things like pretraining compute, RL compute, and thinking time.
- In a world where elicitation quality has very reliable scaling laws, we would observe that there are diminishing returns to better scaffolds. Elicitation quality is predictable, ideally an additive term on top of model quality, but more likely requiring some more information about the model. It is rare to ever discover a new scaffold that can 2x the performance of an already well-tested models.
- In a world where elicitation quality is not reliably modelable, we would observe that different methods of elicitation routinely get wildly different bottom-line performance, and sometimes a new elicitation method makes models 10x smarter than before, making error bars on the best undiscovered elicitation method very wide. Different models may benefit from different elicitation methods, and some get 10x benefits while others are unaffected.
It is NOT KNOWN what world we are in (worst-case assumptions would put us in 2 though I'm optimistic we're closer to 1 in practice), and determining this is just a matter of data collection. If our evals are still not good enough but we don't seem to be in World 2 either, there are endless of tricks to add that make evals more thorough, some of which are already being used. Like evaluating models with limited human assistance, or dividing tasks into subtasks and sampling a huge number of tries for each.
What's the most important technical question in AI safety right now?
Yes, lots of socioeconomic problems have been solved on a 5 to 10 year timescale.
I also disagree that problems will become moot after the singularity unless it kills everyone-- the US has a good chance of continuing to exist, and improving democracy will probably make AI go slightly better.
I mention exactly this in paragraph 3.
The new font doesn't have a few characters useful in IPA.
