Thanks to Aryan Bhatt, Eric Neyman, and Vivek Hebbar for feedback.
This post gets more math-heavy over time; we convey some intuitions and overall takeaways first, and then get more detailed. Read for as long as you're getting value out of things!
TLDR
How much should you optimize for a flawed measurement? If you model optimization as selecting for high values of your goal V plus an independent error X, then the answer ends up being very sensitive to the distribution of the error X: if it’s heavy-tailed you shouldn't optimize too hard, but if it’s light-tailed you can go full speed ahead.
Related work
Why the tails come apart [LW · GW] by Thrasymachus [LW · GW]discusses a sort of "weak Goodhart" effect, where extremal proxy measurements won't have extremal values of your goal (even if they're still pretty good). It implicitly looks at cases similar to a normal distribution.
Scott Garrabrant's taxonomy of Goodhart's Law [LW · GW] discusses several ways that the law can manifest. This post is about the "Regressional Goodhart" case.
Scaling Laws for Reward Model Overoptimization (Gao et al., 2022) considers very similar conditioning dynamics in real-world RLHF reward models. In their Appendix A, they show a special case of this phenomenon for light-tailed error, which we'll prove a generalization of in the next post [LW · GW].
Defining and Characterizing Reward Hacking (Skalse et al., 2022) shows that under certain conditions, leaving any terms out of a reward function makes it possible to increase expected proxy return while decreasing expected true return.
How much do you believe your results? [LW · GW] by Eric Neyman tackles very similar phenomena to the ones discussed here, particularly in section IV; in this post we're interested in characterizing that sort of behavior and when it occurs. We strongly recommend reading it first if you'd like better intuitions behind some of the math presented here - though our post was written independently, it's something of a sequel to Eric's.
An Arbital page defines Goodhart's Curse and notes
The exact conditions for Goodhart's Curse applying between V and a point estimate or probability distribution over U [a proxy measure that an AI is optimizing], have not yet been written out in a convincing way.
To the extent this post adopts a reasonable frame, we think it makes progress towards this goal.
Motivation/intuition
Goodhart's Law says
When a measure becomes a target, it ceases to be a good measure.
When I (Drake) first heard about Goodhart's Law, I internalized something like "if you have a goal, and you optimize for a proxy that is less than perfectly correlated with the goal, hard enough optimization for the proxy won't get you what you wanted." This was a useful frame to have in my toolbox, but it wasn't very detailed - I mostly had vague intuitions and some idealized fables from real life.
Much later, I saw some objections to this frame on Goodhart that actually used math.[1] The objection went something like:
Let's try to sketch out an actual formal model here. What's the simplest setup of "two correlated measurements"? We could have a joint normal distribution over two random variables, U and V, with zero mean and positive covariance. You actually value V, but you measure a proxy U. Then we can just do the math: if I optimize really hard for U, and give you a random datapoint with U=1012 or something, how much V do you expect to get?
If we look at the joint distribution of U and V, we'll see a distribution with elliptical contour lines, like so:
Now, the naïve hope is that expected V as a function of observed U would go along the semi-major axis, shown in red below:
But actually we'll get the blue line, passing through the points at which the ellipses are tangent to the V-axis.[2]
Importantly, though, we're still getting a line: we get linearly more value V for every additional unit of U we select for! Applying 99th percentile selection on U isn't going to be as good as 99th percentile selection on V, but it's still going to give us more V than any lower percentile selection on U.[3] The proxy is inefficient, but it's not doomed.
Lately, however, I've come to think that this story is a little too rosy. One thing that's going on here is that we're just thinking about a "regressional Goodhart" problem, which is only one of several ways something Goodhart-like can come into play - see Scott Garrabrant's taxonomy [LW · GW]. But even in this setting, I think things can be much thornier.
In the story above, we can think of our measurement U as being some multiple of V plus an independent normally-distributed source of error, X. When we ask for an outcome with a really high value of U, we're asking for a datapoint where X+V is very high.[4]
Because normal distributions drop off in probability very fast, it gets harder and harder to select for high values of either component: given that a datapoint is at least 4 standard deviations above the mean, the odds that it's at least 5 standard deviations above are less than 1%. So the least-rare outcomes with high X+V are going to look like a compromise between the noise X and value V, where we have a medium amount of each piece (because going to the extremes for either one is disproportionately costly in terms of improbability).
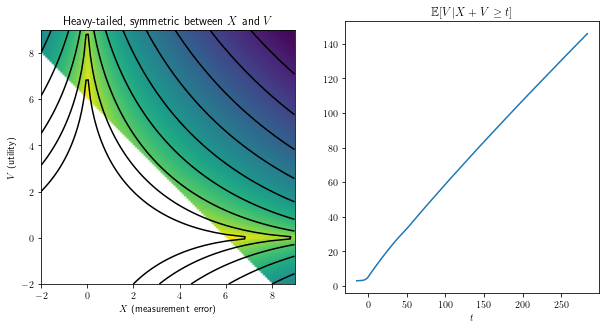
To see this more visually, here are some plots of possible (X,V) pairs, restricted to the triangle of values where X+V≥6. Points are brighter if that outcome is more probable, and the black contour lines show regions of equal probability density. On the right, we have the expected value of V as a function of our proxy threshold t.
We can see that the most likely outcomes skew towards one side or the other depending on which of X and V has more variance, but because these contour lines are convex, we still expect to see outcomes that have some of each component.
But now let's look at a case where X and V are heavy-tailed, such that each additional unit of X or V requires fewer bits of optimization power.[5] Say that the probability density functions (PDFs) of X and V are proportional to exp(−√|x|), instead of exp(−cx2) like before.[6] Then we'll see something more like
The resulting distribution is symmetric about X and V, of course, but unlike in the normal case, that doesn't manifest as "X and V will be about the same", but instead as "the outcome will be almost entirely X or almost entirely V with even odds".
In this heavy-tailed regime, though, we care a lot about which of X or V has the edge here. For instance, suppose that optimizing a given amount for V only gets us half as far as it would for X (so e.g. the 99th percentile V value is half as large as the 99th percentile X value). Our plot now looks like
and in the limit for large t we won't get any expected V at all by optimizing for the sum - all that optimization power goes towards producing high X values. We call this catastrophic Goodhart because the end result, in terms of V, is as bad as if we hadn't conditioned at all.
(In general, if the right-hand tails of X and V are each on the order of e−xc, we'll switch between the two regimes right at c=1 - that's when these contour lines switch from being convex to being concave.)
To help visualize this behavior, let's zoom in closer on a concrete example where we get catastrophic Goodhart.[7] See below for plots of the PDFs of V and X:
On the left is a standard plot of the two PDFs; on the right is a plot of their negative logarithms. The right-hand plot makes it apparent that X has heavier right tails, because the green line gets arbitrarily far below the orange line in the limit.
Here is a GIF of the conditional distribution on V as t goes from −5 up to 150, with a dashed blue line indicating the conditional expectation:
Note the spike in the conditional PDF around t, corresponding to outcomes where X is small and V is large; because of the heavier tails on X, this spike gets smaller and smaller with larger t. (We recommend staring at this GIF until you feel like you have a good understanding of why it looks the way it does.)
The expected value initially goes up when we apply a little selection pressure to our proxy, but as we optimize harder, that optimization pressure gets shunted more and more into optimization for X, and less and less for V, even in absolute terms. (This is the same dynamic that Eric Neyman recently discussed in section IV of How much do you believe your results? [LW · GW], put in a slightly different framing.)
In the next post, we're going to prove some results about when this effect happens; this will be pretty technical, so we'll talk a bit about the results in broad strokes here.
Proof statement
Suppose that X and V are independent real-valued random variables. We'll show, roughly, that if
X is subexponential (a slightly stronger property than being heavy-tailed).
V has lighter tails than X by more than a linear factor, meaning that the ratio of the tails of V and the tails of X grows superlinearly.[8]
then limt→∞E[V|X+V≥t]=E[V].
Less formally, we're saying something like "if it requires relatively little selection pressure on X to get more of X and asymptotically more selection pressure on V to get more of V, then applying very strong optimization towards X+V will not get you even a little bit of optimization towards V - all the optimization power will go towards X, where it has the best return on investment."
We'll also show a sort of inverse to this: if X has right tails that are lighter than an exponential (for instance, if X is normal or bounded), then we'll get infinitely much V in the limit no matter what kind of tail distribution V has.
(What if X is heavy-tailed but V has even heavier tails than X? Then we can exchange their places in the first theorem, and conclude that we get zero X in the limit - which means that all of that optimization is going towards V.)
In the next post [LW · GW], we'll prove these claims.
Application to alignment
We might want to use unaligned AI to generate alignment research for us. One model for this is sampling a random document from the space of 10000-bit strings, then conditioning on a high human rating. If evaluation of alignment proposals is substantially easier than generating good alignment proposals, these plans will be useful. If not, we’ll have a hard time getting research out of the AI. This is a crux between John Wentworth and Paul Christiano + Jan Leike [LW(p) · GW(p)] that informs their differing approaches to alignment.
We can frame the problem of evaluation in terms of Goodhart’s Law. Let V be the true quality of an alignment plan (say in utility contributed to the future), and U=X+V be the human rating, so that X is the human’s rating error. If V and X are independent, and we have access to arbitrarily strong optimization for U, then our result implies that to implement an alignment plan better than random…
… if V is light-tailed, X must not be heavy-tailed.
… if V is heavy-tailed, X must not be much heavier-tailed than V.
We don’t know whether V is heavy- or light-tailed in real life, so to be safe, we should make X light-tailed. To the extent this model is accurate, a large part of alignment reduces to the problem of finding a classifier with light-tailed errors, which is able to operate in the exceptionally complicated domain of evaluating plans, and is not itself dangerous.
This model makes two really strong assumptions: that optimization is like conditioning, and that X and V are independent. These are violated in real life:
X and V will not be independent. Among other reasons, we expect that more complicated or optimized plans are more likely to have large impacts on the world (thus having higher variance of V), and harder to evaluate (thus having higher variance of X). However, in some cases, really good plans might be easier to evaluate; for example, formalized proofs can be efficiently checked.
There's also a sort of implicit assumption in even using a framing that thinks about things as X+V; the world might be better thought of as naturally containing (U,V) tuples (with U our proxy measurement), and X=U−V could be a sort of unnatural construction that doesn't make sense to single out in the real world. (We do think this framing is relatively natural, but won't get into justifications here.)
Despite these caveats, some takeaways we endorse:
Optimization for imperfect proxies is sometimes fine and sometimes doomed, depending on your distribution.
Goodhart's law is subtle - even within a given framing of a problem, what happens when you optimize can be very sensitive to the exact numerical details of your measurements.
In particular, reaching for a normally-distributed toy model by default can be super misleading for thinking about a lot of real-world dynamics, because the tails are much lighter than most things in a way that affects the qualitative takeaways.
In an alignment plan involving generation and evaluation, you should either (a) have reason to believe that your classifier's errors are light-tailed, (b) have a reason why training an AI on human (or AI) feedback will be importantly different from conditioning on high feedback scores, or (c) have a story for why non-independence works in your favor.
Exercises
Show that when X and V are independent and t∈R, E[V|X+V>t]≥E[V]. Conclude that limt→∞E[V|X+V>t]≥E[V]. This means that given independence, optimization always produces a plan that is no worse than random.
When independence is violated, an optimized plan can be worse than random, even if your evaluator is unbiased. Construct a joint distribution fVX for X and V such that E[X]=0, E[V]=0, and E[X|V=v]=0 for any v∈R, but limt→∞E[V|X+V>t]=−∞.
Answers to exercises are at the end of the next post [LW · GW].
One way to see this intuitively is to consider the shear transformation replacing V by V−cU, where c is a constant such that the resulting random variable is uncorrelated with U. In that situation we'd have a constant expectation of 0, so adding the U component back in should give us a linear expectation.
Most heavy-tailed distributions are also long-tailed, which means that limx→∞Pr(X>x+t)Pr(X>x)=1 for all t>0. So the optimization needed to get from the event "X is at least x" to "X is at least x+t" becomes arbitrarily small for large x.
We'll suppose that X has a PDF proportional to e−2√|x| and V has a PDF proportional to e−(vS(v))0.8, where S(v)=ev−1ev+1 is an odd function that quickly asymptotes to sign(v), so V has tails like e−v0.8 for large v in either direction but is smooth around v=0.
Curated. Goodhart's Law is an old core concept for LessWrong, and I love when someone(s) come along and add more resolution and rigor to our understanding, and all the more so when they start pointing to how this has practical implications. Would be very cool if this leads to articulation of disagreements between people that allow for progress in the discussion there, e.g. John vs Paul, Jan, etc.
And extra bonus points for exercises at the end too. All in all, good stuff, looking forward to seeing more – especially the results as your vary more of the assumptions (e.g. independence) to line up more with scenarios we anticipate in, e.g. Alignment scenarios.
For what it's worth, it seems much more likely to me for catastrophic Goodhart to happen because the noise isn't independent from the thing we care about, rather than the noise being independent but heavy tailed.
This post provides a mathematical analysis of a toy model of Goodhart's Law. Namely, it assumes that the optimization proxy U is a sum of the true utility function V and noise X, such that:
V and X are independent random variables w.r.t. some implicit distribution ζ on the solution space. The meaning of this distribution is not discussed, but I guess we might think of it some kind of inductive bias, e.g. a simplicity prior.
The optimization process can be modeled as conditioning ζ on a high value of U=V+X.
In this model, the authors prove that Goodhart occurs when X is subexponential and its tail is sufficiently heavier than that of V. Conversely, when X is sufficiently light-tailed, Goodhart doesn't occur.
My opinion:
On the one hand, kudos for using actual math to study an alignment-relevant problem.
On the other hand, the modeling assumptions feel too toyish for most applications. Specifically, the idea that V and X are independent random variables seems implausible. Typically, we worry about Goodhart's law because the proxy behaves differently in different domains. In the "ordinary" domain that motivated the choice of proxy, U is a good approximation of V. However, in other domains U might be unrelated to V or even anticorrelated.
For example, ordinarily smiles on human-looking faces is an indication of happy humans. However, in worlds that contain much more inanimate facsimiles of humans than actual humans, there is no correlation.
Or, to take the example used in the post, ordinarily if a sufficiently smart expert human judge reads an AI alignment proposal, they form a good opinion on how good this proposal is. But, if the proposal contains superhumanly clever manipulation and psychological warfare, the ordinary relationship completely breaks down. I don't expect this effect to behave like independent random noise at all.
Less importantly, it might be interesting to extend this analysis to a more realistic model of optimization. For example, the optimizer learns a function F which is the best approximation to U out of some hypothesis class H, and then optimizes F instead of the actual U. (Incidentally, this might generate an additional Goodhart effect due to the discrepancy between F and U.) Alternatively, the optimizer learns an infrafunction [LW · GW] Φ that is a coarsening of U out of some hypothesis class H and then optimizes Φ.
Another piece of related work: Simon Zhuang, Dylan Hadfield-Mennel: Consequences of Misaligned AI. The authors assume a model where the state of the world is characterized by multiple "features". There are two key assumptions: (1) our utility is (strictly) increasing in each feature, so -- by definition -- features are things we care about (I imagine money, QUALYs, chocolate). (2) We have a limited budget, and any increase in any of the features always has a non-zero cost. The paper shows that: (A) if you are only allowed to tell your optimiser about a strict subset of the features, all of the non-specified features get thrown under the buss. (B) However, if you can optimise things gradually, then you can alternate which features you focus on, and somehow things will end up being pretty okay.
Personal note: Because of the assumption (2), I find the result (A) extremely unsurprising, and perhaps misleading. Yes, it is true that at the Pareto-frontier of resource allocation, there is no space for positive-sum interactions (ie, getting better on some axis must hurt us on some other axis). But the assumption (2) instead claims that positive-sum interactions are literally never possible. This is clearly untrue in the real-world, about things we care about.
That said, I find the result (B) quite interesting, and I don't mean to hate on the paper :-).
The real issue IMO is assumption 1, the assumption that utility strictly increases. Assumption 2 is, barring rather exotic regimes far into the future, basically always correct, and for irreversible computation, this always happens, since there's a minimum cost to increase the features IRL, and it isn't 0.
Increasing utility IRL is not free.
Assumption 1 is plausibly violated for some goods, provided utility grows slower than logarithmic, but the worry here is status might actually be a utility that strictly increases, at least relatively speaking.
Assumption 2 is, barring rather exotic regimes far into the future, basically always correct, and for irreversible computation, this always happens, since there's a minimum cost to increase the features IRL, and it isn't 0.
Increasing utility IRL is not free.
I think this is a misunderstanding of what I meant. (And the misunderstanding probably only makes sense to try clarifying it if you read the paper and disagree with my interpretation of it, rather than if your reaction is only based on my summary. Not sure which of the two is the case.)
What I was trying to say is that the most natural interpretation of the paper's model does not allow for things like: In state 1, the world is exactly as it is now, except that you decided to sleep on the floor every day instead of in your bed (for no particular reason), and you are tired and miserable all day. State 2 is exactly the same as state 1, except you decided that it would be smarter to sleep in your bed. And now, state 2 is just strictly better than state 1 (at least in all respects that you would care to name). Essentially, the paper's model requires, by assumption, that it is impossible to get any efficiency gains (like "don't sleep on the floor" or "use this more efficient design instead) or mutually-beneficial deals (like helping two sides negotiate and avoid a war).
Yes, I agree that you can interpret the model in ways that avoid this. EG, maybe by sleeping on the floor, your bed will last longer. And sure, any action at all requires computation. I am just saying that these are perhaps not the interpretations that people initially imagine when reading the paper,. So unless you are using an interpretation like that, it is important to notice those strong assumptions.
Essentially, the paper's model requires, by assumption, that it is impossible to get any efficiency gains (like "don't sleep on the floor" or "use this more efficient design instead) or mutually-beneficial deals (like helping two sides negotiate and avoid a war).
Yeah, that was a different assumption that I didn't realize, because I thought the assumption was solely that we had a limited budget and every increase in a feature has a non-zero cost, which is a very different assumption.
I sort of wish the assumptions were distinguished, because these are very, very different assumptions (for example, you can have positive-sum interactions/trade so long as the cost is sufficiently low and the utility gain is sufficiently high, which is pretty usual.)
I definitely interpreted the model like this, in that I was assuming all the costs and benefits are included by default:
Yes, I agree that you can interpret the model in ways that avoid this. EG, maybe by sleeping on the floor, your bed will last longer. And sure, any action at all requires computation. I am just saying that these are perhaps not the interpretations that people initially imagine when reading the paper,. So unless you are using an interpretation like that, it is important to notice those strong assumptions.
I wonder if the brainstem is limiting optimization is some way like this. So far my assumption was that the brainstem uses some saturation and temporal decay for the multiple reward components to prevent Goodhardting. But maybe something closer to the t-limiting here.
This post and the remainder of the sequence were turned into a paper accepted to NeurIPS 2024. Thanks to LTFF for funding the retroactive grant that made the initial work possible, and further grants supporting its development into a published work including new theory and experiments. @Adrià Garriga-alonso [LW · GW] was also very helpful in helping write the paper and interfacing with the review process.
I finally got around to reading this sequence, and I really like the ideas behind these methods. This feels like someone actually trying to figure out exactly how fragile [LW · GW] human values are. It's especially exciting because it seems like it hooks right into an existing, normal field of academia (thus making it easier to leverage their resources toward alignment).
I do have one major issue with how the takeaway is communicated, starting with the term "catastrophic". I would only use that word when the outcome of the optimization is really bad, much worse that "average" in some sense. That's in line with the idea that the AI will "use the atoms for something else", and not just leave us alone to optimize its own thing. But the theorems in this sequence don't seem to be about that;
We call this catastrophic Goodhart because the end result, in terms of V, is as bad as if we hadn't conditioned at all.
Being as bad as if you hadn't optimized at all isn't very bad; it's where we started from!
I think this has almost the opposite takeaway from the intended one. I can imagine someone (say, OpenAI) reading these results and thinking something like, great! They just proved that in the worst case scenario, we do no harm. Full speed ahead!
(Of course, putting a bunch of optimization power into something and then getting no result would still be a waste of the resources put into it, which is presumably not built into V. But that's still not very bad.)
That said, my intuition says that these same techniques could also suss out the cases where optimizing for U pessimizes for V, in the previously mentioned use-our-atoms sense.
We considered that "catastrophic" might have that connotation, but we couldn't think of a better name and I still feel okay about it. Our intention with "catastrophic" was to echo the standard ML term of "catastrophic forgetting", not a global catastrophe. In catastrophic forgetting the model completely forgets how to do task A after it is trained on task B, it doesn't do A much worse than random. So we think that "catastrophic Goodhart" gives the correct idea to people who come from ML.
The natural question is then: why didn't we study circumstances in which optimizing for a proxy gives you −∞ utility in the limit? Because it isn't true under the assumptions we are making. We wanted to study regressional Goodhart, and this naturally led us to the independence assumption. Previous work like Zhuang et al and Skalse et al has already formalized the extremal Goodhart / "use the atoms for something else" argument that optimizing for one goal would be bad for another goal, and we thought the more interesting part was showing that bad outcomes are possible even when error and utility are independent. Under the independence assumption, it isn't possible to get less than 0 utility.
To get −∞ utility in the frame where proxy = error + utility, you would need to assume something about the dependence between error and utility, and we couldn't think of a simple assumption to make that didn't have too many moving parts. I think extremal Goodhart is overall more important, but it's not what we were trying to model.
Lastly, I think you're imagining "average" outcome as a random policy, which is an agent incapable of doing significant harm. The utility of the universe is still positive because you can go about your life. But in a different frame, random is really bad. Right now we pretrain models and then apply RLHF (and hopefully soon, better alignment techniques). If our alignment techniques produce no more utility than the prior, this means the model is no more aligned than the base model, which is a bad outcome for OpenAI. Superintelligent models might be arbitrarily capable of doing things, so the prior might be better thought of as irreversibly putting the world in a random state, which is a global catastrophe.
This was a fantastic read. Among my top three (at least) on Goodhart!
Stupid simple observation: if you could get enough independent[1] evaluations of X you could smooth out heavy tails by ensembling (by central limit theorem).
actually independent, not like asking lots of humans to 'independently' rate something, which is obviously correlated in important ways - I think this condition is very hard to achieve in reality ↩︎
Great post! I especially enjoyed the intuitive visualizations for how the heavy-tailed distributions affect the degree of overoptimization of X.
As a possibly interesting connection, your set of criteria for an alignment plan can also be thought of as criteria for selecting a model specification [LW · GW] that approximates the ideal specification well, especially trying to ensure that the approximation error is light-tailed.
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
have a reason why training an AI on human (or AI) feedback will be importantly different from conditioning on high feedback scores
I think these are generally not the same [LW · GW], and I object to any implied privileging of this hypothesis. But above you say that SGD has a ton of inductive biases in general, so why do you seem to endorse a takeaway like (my words) "you need to have a reason why SGD has the relevant inductive biases"?
SGD has inductive biases, but we'd have to actually engineer them to get high V rather than high X when only trained on U=V+X. In the Gao et al paper, optimization and overoptimization happened at the same relative rate in RL as in conditioning, so I think the null hypothesis is that training does about as well as conditioning. I'm pretty excited about work that improves on that paper to get higher gold reward while only having access to the proxy reward model.
I think the point still holds in mainline shard theory world, which in my understanding is using reward shaping + interp to get an agent composed of shards that value proxies that more often correlate with high V rather than higher X, where we are selecting on something other than U=V+X. When the AI ultimately outputs a plan for alignment, why would it inherently value having the accurate plan, rather than inherently value misleading humans? I think we agree that it's because SGD has inductive biases and we understand them well enough to do directionally better than conditioning at constructing an AI that does what we want.
I think there is an additional effect related to "optimization is not conditioning" that stems from the fact that causation is not correlation. Suppose for argument's sake that people evaluate alignment research partly based on where it's come from (which the machine cannot control). Then producing good alignment research by regular standards is not enough to get high ratings. If a system manages to get good ratings anyway, then the actual papers it's producing must be quite different to typical highly rated alignment papers, because they are somehow compensating for the penalty incurred by coming from the wrong source. In such a situation, I think it would not be surprising if the previously observed relationship between ratings and quality did not continue to hold.
This is similar to "causal Goodhart" in Garrabrant's taxonomy, but I don't think it's quite identical. It's ambiguous whether ratings are being "intervened on" in this situation, and actual quality is probably going to be affected somewhat. I could see it as a generalised version of causal Goodhart, where intervening on the proxy is what happens when this effect is particularly extreme.
This model makes two really strong assumptions: that optimization is like conditioning, and that X and V are independent.
[...]
There's also a sort of implicit assumption in even using a framing that thinks about things as X+V; the world might be better thought of as naturally containing (U,V) tuples (with U our proxy measurement), and X=U−V could be a sort of unnatural construction that doesn't make sense to single out in the real world. (We do think this framing is relatively natural, but won't get into justifications here.)
Will you get into justifications in the next post? Because otherwise the following advice, which I consider literally correct:
In an alignment plan involving generation and evaluation, you should either have reason to believe that your classifier's errors are light-tailed, or have a story for why inductive bias and/or non-independence work in your favor.
in practice reduces just to the part "have a story for why inductive bias and/or non-independence work in your favor", because I currently think Normality + additivity + independence are bad assumptions, and I see that as almost a null advice.
I think that Normality + additivity + independence come out together if you have a complex system subject to small perturbations, because you can write any dynamic as linear relationships over many variables. This gets you the three perks with:
Normality: complex system means many variables with nontrivial roles, and so the linearization tends to produce Normal distributions, it behaves like a sum with not too much concentrated weights.
Additivity: due to the small perturbations that allow you to linearize any relationship as approximation.
Independence: a linear system should be easy enough to analyze that you expect, if you spend effort, to get to a situation where the error is independent, and all the rest has been accounted for in some way.
Since we want to study the situation in which we apply a lot of optimization pressure, I think this scenario gets thrown out the window.
So:
Do you have a more general reason to expect these assumptions? Possibly each one or subsets separately? First raw ideas that come to my mind:
Normality because the number of variables involved grows in a balanced way with nonlinearity such that you get Normality
Additivity because scenario we can realistically study are limited enough that the kind of errors you can make stay the same, and we have to deliberately put ourselves in that situation
Independence because a human manages to get as much information as possible until some hard boundary of chaos
Do you have some clever trick such that it is always possible to always see the problem in this light? I expect not because utilities can only be affinely transformed.
Example: here
But now let's look at a case where X and V are heavier-tailed. Say that the probability density functions (PDFs) of X and V are proportional to exp(−√|x|), instead of exp(−cx2) like before.
my gut instinct tells me to look at elliptical distributions like exp(−(ax2+by2)c), which will not show this specific split-tail behavior. My gut instinct is not particularly justified, but seems to be making weaker assumptions.
I'm not sure what you mean formally by these assumptions, but I don't think we're making all of them. Certainly we aren't assuming things are normally distributed - the post is in large part about how things change when we stop assuming normality! I also don't think we're making any assumptions with respect to additivity; X=U−V is more of a notational or definitional choice, though as we've noted in the post it's a framing that one could think doesn't carve reality at the joints. (Perhaps you meant something different by additivity, though - feel free to clarify if I've misunderstood.)
Independence is absolutely a strong assumption here, and I'm interested in further explorations of how things play out in different non-independent regimes - in particular we'd be excited about theorems that could classify these dynamics under a moderately large space of non-independent distributions. But I do expect that there are pretty similar-looking results where the independence assumption is substantially relaxed. If that's false, that would be interesting!
Late edit: Just a note that Thomas has now published a new post [? · GW] in the sequence addressing things from a non-independence POV.
I wasn't saying you made all those assumption, I was trying to imagine an empirical scenario to get your assumptions, and the first thing to come to my mind produced even stricter ones.
I do realize now that I messed up my comment when I wrote
in practice reduces just to the part "have a story for why inductive bias and/or non-independence work in your favor", because I currently think Normality + additivity + independence are bad assumptions, and I see that as almost a null advice.
Here there should not be Normality, just additivity and independence, in the sense of U−V⊥V. Sorry.
But I do expect that there are pretty similar-looking results where the independence assumption is substantially relaxed.
I do agree you could probably obtain similar-looking results with relaxed versions of the assumptions.
However, the same way U−V⊥V seems quite specific to me, and you would need to make a convincing case that this is what you get in some realistic cases to make your theorem look useful, I expect this will continue to apply for whatever relaxed condition you can find that allows you to make a theorem.
Example: if you said "I made a version of the theorem assuming there exists f such that f(U,V)⊥V for f in some class of functions", I'd still ask "and in what realistic situations does such a setup arise, and why?"
In my frame, U is not just some variable correlated with V, it's some estimator's best estimate, and so it makes sense that residuals X=U−V would have various properties, for the same reason we consider residuals in statistics, returns in finance, etc.
The basic idea why we might get U−V⊥V is that there are some properties that increase the overseer's rating and actually make the plan good (say, the plan includes a solution to the shutdown problem, interpretability, or whatever) and different properties that increase the overseer's rating for no good reason (e.g. the plan uses really sophisticated words and an optimistic tone). I think assuming these are independent and additive is reasonable as a toy model, though as we said they're probably violated in real life and we're interested in weakening these assumptions.
I guess you could get an elliptical distribution through something like this: all properties contribute to both X and V to some degree, and distribution of the angle is roughly uniform while the magnitudes are heavy-tailed. I'm not sure whether this is as natural as independence: if some property of the AI's output makes the human irrationally approve of it (high X), then it seems likely to be optimized for that, rather than also having huge impacts on V one way or the other.
if some property of the AI's output makes the human irrationally approve of it (high X), then it seems likely to be optimized for that, rather than also having huge impacts on V one way or the other.
Are you saying that your (rough, preliminary) justification for independence is that it's what gets you Goodhart, so you use it? Isn't this circular? Ok so maybe I misinterpreted your intentions: I thought you wanted to "prove" that Goodhart happens, while possibly you wanted to "show an example" of Goodhart happening?
It doesn't look circular to me? I'm not assuming that we get Goodhart, just that properties that result in very high X seem like they would be things like "very rhetorically persuasive" or "tricks the human into typing a very large number into the rating box" that won't affect V much, rather than properties with very high magnitude towards both X and V. I believe this less for V, so we'll probably have to replace independence with this [LW(p) · GW(p)].
I think you're splitting hairs. We prove Goodhart follows from certain assumptions, and I've given some justification for the assumptions as well as their limitations, so you could equally say that we "prove" or "show an example". If by circular you mean we proved something about independent X and V because this was easier than more realistic assumptions, we're guilty! The proof was a huge pain and we wanted to publish rather than overcomplicating it more, partly to get feedback like yours. But I do have some intuition that the result is useful, partly because things are sometimes approximately independent, and partly because the basic reasons behind the proof extend to other cases.
An example of the sort of strengthening I wouldn't be surprised to see is something like "If V is not too badly behaved in the following ways, and for all v∈R we have [some light-tailedness condition] on the conditional distribution (X|V=v), then catastrophic Goodhart doesn't happen." This seems relaxed enough that you could actually encounter it in practice.
Suppose that we are selecting for U=X+V where V is true utility and X is error. If our estimator is unbiased (E[X|V=v]=0 for all v) and X is light-tailed conditional on any value of V, do we have limt→∞E[V|X+V≥t]=∞?
No; here is a counterexample. Suppose that V∼N(0,1), and X|V∼N(0,4) when V∈[−1,1], otherwise X=0. Then I think limt→∞E[V|X+V≥t]=0.
This is worrying because in the case where V∼N(0,1) and X∼N(0,4) independently, we do get infinite V. Merely making the error *smaller* for large values of V causes catastrophe. This suggests that success caused by light-tailed error when V has even lighter tails than X is fragile, and that these successes are “for the wrong reason”: they require a commensurate overestimate of the value when V is high as when V is low.